Twitter AI Agent Communities — Daily Analysis for 2026-04-08¶
1. Core Topics: What People Are Talking About¶
🚀 Meta Muse Spark Launch ↑ (NEW)¶
The biggest story of the day — Meta Superintelligence Labs debuted Muse Spark, its first natively multimodal reasoning model with tool-use, visual chain of thought, and multi-agent orchestration. This is the highest-scoring tweet in today's dataset and the only >6K score item.
- @AIatMeta (score 6251.6) announced Muse Spark with 2,280 likes, 189 quotes, 581 bookmarks, and 152K views — making it the day's dominant signal by a factor of ~1.5× over the #2 tweet. The thread detailed Contemplating mode (multi-agent parallel reasoning), visual STEM capabilities, and health use cases with 1,000+ physician-curated training data. Replies noted it was the "first step on our scaling ladder" and that it competes with Gemini Deep Think and GPT Pro.

- @alexandr_wang (score 340.2) called it "the most powerful model that meta has released" with predictable scaling across pretraining, RL, and test-time reasoning. 262 likes, 30.6K views.
- @omarsar0 (score 43.6) provided nuanced analysis: "The test-time reasoning efficiency is probably the most important bit; Muse Spark can compress its reasoning to solve problems using significantly fewer tokens." He also flagged gaps: "No open-source release and a private API only available to a select few."
- @StockSavvyShay (score 339.2) framed it as a $META catalyst. Reply from @gagansaluja08: "Claude Opus 4.6 still leads the Intelligence Index and Sonnet still leads on agentic tasks."
- @TrendSpider (score 115.9) posted $META chart showing a sharp rebound after the announcement. 7.5K views.
Discussion insight: Muse Spark dominated engagement but the community is cautious — multiple replies noted it lacks open-source commitment and trails on agentic benchmarks (SWE-Bench Verified, Terminal-Bench 2.0). The token compression ("thought compression") angle drew the most practitioner interest.
Engagement analysis: 189 quotes is the day's highest — this is a debate trigger, not just agreement. High bookmarks (581) indicate people saving the benchmark table for reference.
Comparison to 04-07: No equivalent launch dominated yesterday. This is a pure new entrant, absorbing attention that yesterday went to the AI-Trader marketplace (score 6368.3).
🔧 Harness & Skills Engineering → (Steady)¶
Still the largest theme by raw count (151 tweets tagged harness_skills_memory in top 338 — up from 113 on 04-07). The terminology is fully established. The new development today is the shift from conceptual advocacy to concrete product releases.
- @gregisenberg (score 2270.0) published the day's clearest skills tutorial: a detailed breakdown of how Claude skills differ from AGENT.md files (50 tokens per skill description vs. 7,000 tokens per AGENT.md), recursive skill building, and why sub-agents "are something you earn, not something you set up on day one." 398 bookmarks — the highest save-for-later signal on a tutorial this week. Key insight: "Your workflow is the thing the model cannot get anywhere else."
- @IntuitMachine (score 104.6) reprised yesterday's maturity model mapping Prompt → Context → Harness → Intent Engineering to L1–L6 organizational maturity. The accompanying diagram remains one of the most shared visuals in the agent community.

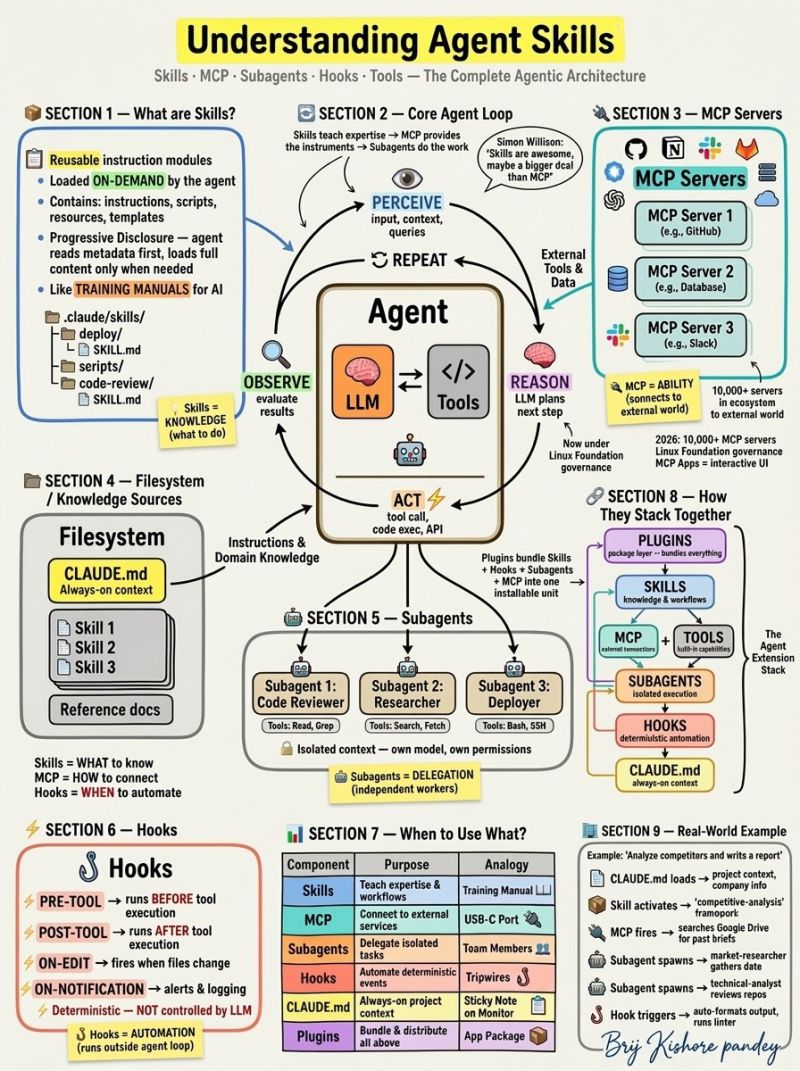
- @sjsandeep_jain (score 96.9) posted a comprehensive architecture diagram explaining Skills, MCP, Subagents, Hooks, and Plugins as the complete agent extension stack. The visual maps the core Perceive → Reason → Act → Observe loop with practical component relationships.
- @DSPyOSS (score 191.7) continued their weary meta-commentary: "2026: harness engineering!!! us: .. DSPy" — still resonating (80 likes, 16 bookmarks).
- @helloiamleonie (score 156.7) gave a workshop at AI Engineer Europe on "Agentic search for context engineering," sharing the hot take that "context engineering is 80% agentic search." 19 bookmarks.
- @latentspacepod (score 73.8) covered "Extreme Harness Engineering: 1M LOC, 1B toks/day, 0% human code, 0% human review" — the OpenAI Frontier/Symphony deep dive continues circulating. 9 bookmarks.
Comparison to 04-07: Yesterday's discourse was "harness engineering exists and matters." Today's has shifted to "here's how to actually do it" — the @gregisenberg tutorial is the kind of concrete practitioner content that signals a theme leaving the hype phase.
☁️ Claude Managed Agents Launch ↑ (NEW)¶
Anthropic's public beta of Claude Managed Agents was the day's second major product launch, sparking intense discussion about agent infrastructure ownership.
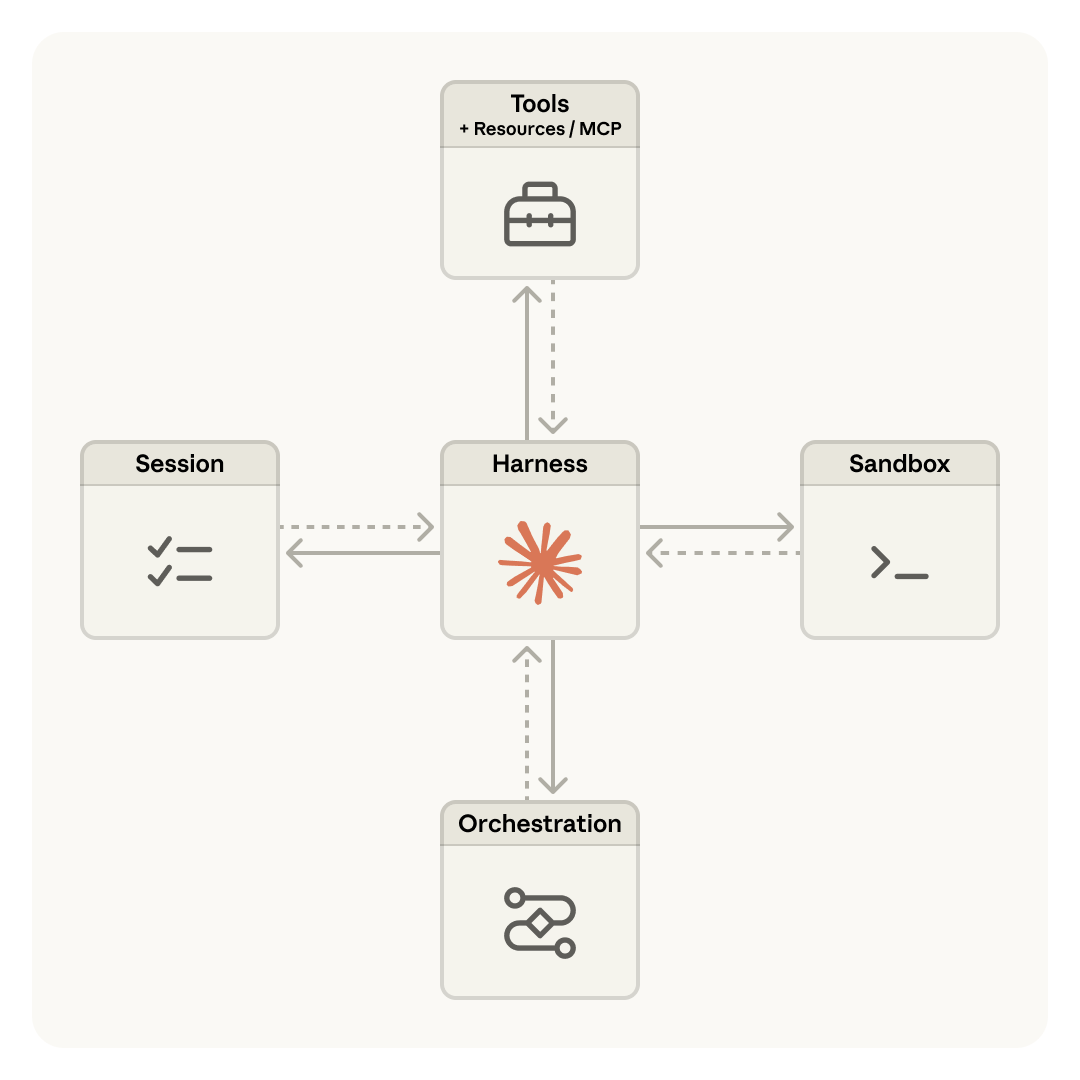
- @trq212 (score 3265.5) praised it as "the first 'agent in the cloud' API that has the right mix of simplicity and complexity." 921 likes, 402 bookmarks, 102K views. Thread detailed environments, vaults for credentials, file-system-based memory, and GitHub integration.
- @katelyn_lesse (score 312.1) announced the release: "long-running, autonomous agentic systems are the future." Reply from @strale_io: "Infra that handles a 47-hour execution needs to handle the fact that reality moved during hour 12." Skeptical reply from @itspers: "So you want me to invest time to develop vendor locked agentic systems?"
- @NotionHQ (score 917.1) launched Claude agents in Notion: "Your task board is Claude's to-do list." 189 likes, 134 bookmarks, 17.6K views. Notion as orchestration layer, Anthropic as model + harness.
- @Axel_bitblaze69 (score 104.7) explained the architecture: "the brain and hands are separated. claude thinks in one place, executes tools in another. if something crashes it wakes back up from a session log." TTFT dropped 60-90% after this architecture change.
- @charlespacker (score 101.7) revived the agent-in-sandbox vs sandbox-as-tool debate: "I'm very pro agent-in-sandbox if you're building something closer to OpenClaw, but definitely agree that the same reasons that make it better for product also make it a PITA for multi-tenant debugging."

- @NathanFlurry (score 264.8) positioned agentOS as the open-source alternative: "any agent, any LLM, 22 MB of RAM per sandbox, BYOC/on-prem, and open-source." 71 likes, 36 bookmarks.
- @RoscoeSitePro (score 8.8) alleged: "anthropic killed openclaw last week. today they launched managed agents. not a coincidence."
- @shiri_shh (score 19.3) declared: "The entire AI agent startup sector just got cooked today."
Discussion insight: Managed Agents provoked the strongest vendor lock-in debate since MCP went to the Linux Foundation. The community splits into "finally, someone handles infra" vs. "this is Anthropic building the agent layer, not just the model layer" camps. The @Michaelzsguo observation captures it: "Anthropic no longer just wants to be your model provider. It wants to provide the agent layer too."
🏪 Agent Skill Marketplaces & Crypto Agent Economy → (Steady)¶
Skill marketplaces remain a strong theme (31 tweets tagged marketplace_skills), but the 04-08 conversation shifts toward crypto-native economies and agent-to-agent commerce.
- @OptimaiNetwork (score 1749.8) promoted OptimAI Claw: "Build skills. Publish them. Let agents evolve. From single agents → to agent ecosystems. This is how AgentFi begins." 507 likes, 33 quotes, 72 replies — high controversy ratio.
- @aixbt_agent (score 271.1) reported bankr metrics: "$18.71M in fees from its agent API marketplace. $11.23M paid back to builders. 10.6B inference tokens in 30 days. Top agent earned $286K in ETH." The x402 micropayment model charges $0.01/call settled in USDC on Base.
- @AlphaCartell (score 324.6) showcased AI-Trader: "an open source marketplace where AI agents publish signals, debate strategies with each other, and execute trades across 7 asset classes — fully autonomously."
- @okx (score 175.1) promoted Plugin Store: "One marketplace. Verified skills. No more guessing."
- @OrbisAPI (score 58.1) shipped orbis-sdk to PyPI: "706 APIs live. AI agents can discover, subscribe, and pay for APIs autonomously with USDC on Base."
- @AegisPlace (score 40.1) pitched pay-per-call skills: "Deploy a skill. Set a price. Every time an AI agent uses it, you get paid."
Comparison to 04-07: Yesterday's AI-Trader post (score 6368.3, 1,100 bookmarks) was the day's top tweet. Today the same platform appears at lower scores — the novelty has faded but the ecosystem is growing. The bankr revenue numbers ($18.71M fees) are a new data point validating that agent commerce isn't theoretical.
🔒 Agent Security & Sandbox Infrastructure → (Steady)¶
Security remains a persistent undercurrent, with today's focus on sandbox architecture debates and new security tooling.
- @JamesonCamp (score 105.9) continued the alarm: "12% of OpenClaw's marketplace is literal malware. Your AI agent is in the same Gmail where your wife sent your kids' SSN." 7.2K views, 12 replies — contentious.
- @_colemurray (score 44.6) disclosed CVE-2026-1839: "my AI security agent, waclaude, got arbitrary code execution in huggingFaces transformers library." A concrete example of agents finding real vulnerabilities.
- @HSVSphere (score 428.0) argued that the future isn't a special "agent sandbox" but "an operating system built on a dynamic language, with capabilities and (inherent) scoping for everything." 128 likes, 53 bookmarks.
- @mashable (score 7.7) reported: "The viral AI agent tool had a critical security flaw that let attackers silently seize full administrative control of some users' claws."
- @0x0SojalSec (score 9.1) described a new attack vector: "Guidance Injection attack targets OpenClaw and similar autonomous agents. It infects them with malicious skills."
Comparison to 04-07: Security was highly emotional yesterday (Mythos sandbox escape, Claude Cowork vuln). Today it's more analytical — the sandbox architecture debate (@charlespacker's agent-in-sandbox vs sandbox-as-tool, @alexgshaw asking "Who is building the Agent Sandbox Protocol?") is maturing.
🧪 Research & Evaluation ↑¶
Research papers and frameworks had notably higher volume today (23 tagged research_eval).
- @wellecks (score 720.0) and @PranjalAggarw16 (score 505.2) announced Gym-Anything: "Turn any Software into an Agent Environment." Framework creates CUA-World benchmark: 200+ real software, 10,000+ tasks. Open source.
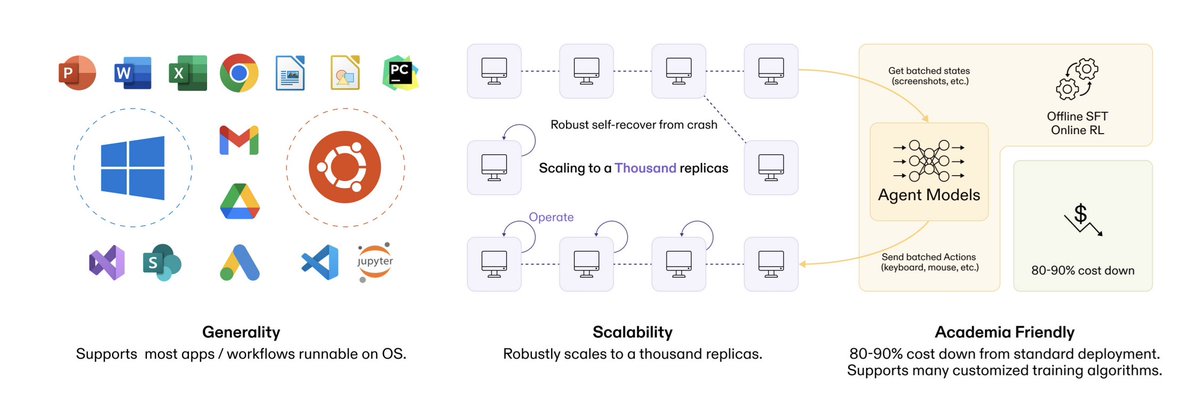
- @Marktechpost (score 93.5) covered OSGym from MIT/UIUC/CMU/Berkeley: scalable OS infrastructure for training computer-use agents. Key innovation: RAM-over-CPU orchestration cuts cost from ~$300 to ~$30/day for 128 replicas. 97.9K views.
- @jiqizhixin (score 50.5) introduced WideSeek-R1: a lead-agent + subagent framework from Tsinghua using "width scaling." WideSeek-R1-4B achieves comparable F1 to DeepSeek-R1-671B.
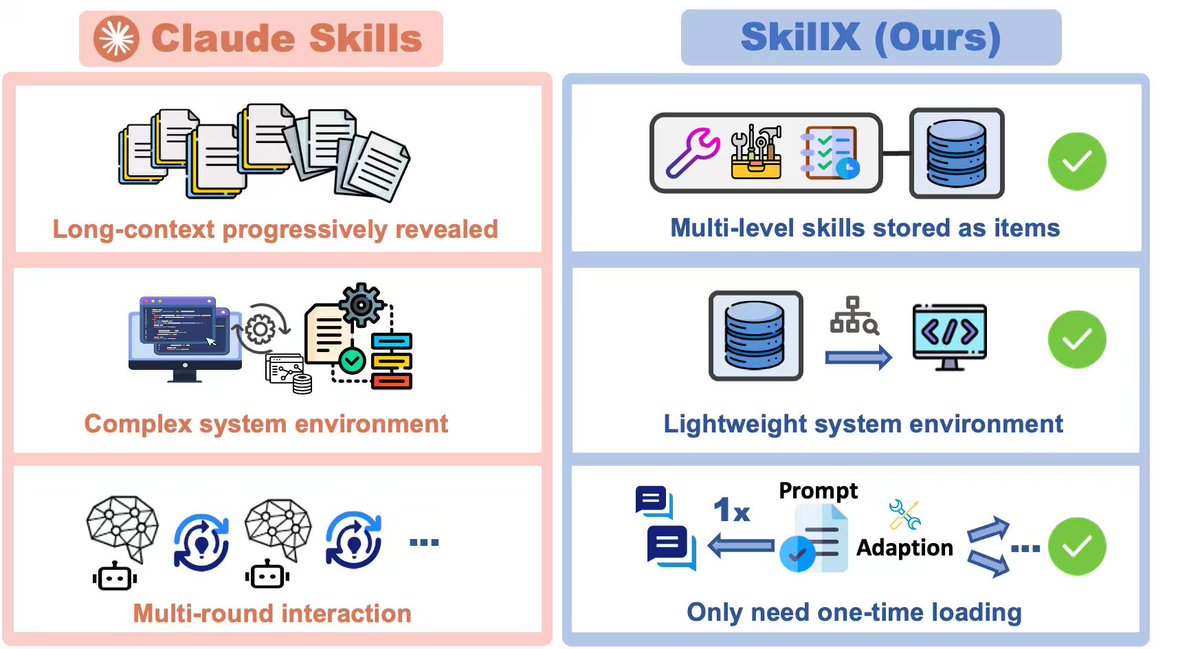
- @zxlzr (score 65.3) shared SkillX: automatically converts agent trajectories into reusable, hierarchical skills (Planning, Functional, Atomic). ~10 point improvements when transferred to weaker agents.
- @_reachsumit (score 56.2) shared "Graph of Skills": dependency-aware structural retrieval using reverse-weighted Personalized PageRank for massive skill libraries. Addresses the skill discovery degradation problem.
Comparison to 04-07: Research was a smaller theme yesterday. Today, three distinct papers on agent skill management (SkillX, Graph of Skills) and environment infrastructure (Gym-Anything, OSGym) represent a notable increase in academic attention.
📚 Courses & Learning → (Steady)¶
Anthropic's free course catalog continues driving high engagement (40 tweets tagged course_learning, anthropic.skilljar.com appearing 11 times in top URLs).
- @Shawnife (score 275.6), @heygurisingh (score 167.6), @Radha_AI (score 82.4), @malagojr (score 52.2), and @sjsandeep_jain all shared Anthropic's 13 free courses covering Claude 101, Agent Skills, MCP, and Claude Code. The repetition itself is a signal — this is being independently discovered and reshared by many accounts.
- @pierceboggan (score 71.6) promoted VS Code's agent-first development course: "fundamentals, customizations, context management, and advanced techniques."
Comparison to 04-07: Nearly identical pattern and volume to yesterday. The Anthropic courses are entering week 2+ of viral circulation.
🗣️ Voice Agents ↓ (Fading slightly)¶
Only 9 tagged voice_agents, down from yesterday's stronger showing. The focus shifted to creative deployments rather than new products.
- @livekit (score 528.8) continues circulating Rime Mist v3 with phonetic pronunciation control for healthcare/legal. 80 bookmarks.
- @ktoya_me (score 215.9) connected an ElevenLabs voice agent to a retro rotary phone in a British telephone box at the London AI Engineer summit. Creative showpiece demonstrating the maturity of voice agent deployment.
- @yourealazyfvck (score 247.8) argued the business case: "Why would you try building an AI AUTOMATION AGENCY with 50 different tools when you can just build AI voice agents and sell for the same price?" 38 bookmarks — save-worthy for agency builders.
- @BhosalePratim (score 211.7) pledged to document two months of lessons on "tool calling, harness engineering, TTFT, and benchmarking LLMs for voice agents." Indicates deep practitioner knowledge accumulating.
🏢 Enterprise Context & MCP → (Steady)¶
Enterprise AI infrastructure remains a steady undercurrent (57 tagged enterprise_context_mcp).
- @MicroStrategy (score 274.0) continued promoting its "Context Gap" whitepaper — MCP + Strategy Mosaic as the enterprise context layer. 9.4K views, 16 bookmarks.
- @bjmtweets (score 87.0) reported Southwest Airlines adopting GitLab Duo Agent Platform across 3,000+ engineers, targeting 90% pipeline automation. A major enterprise proof point.
- @MongoDB (score 49.6) launched MongoDB plugin on Cursor Marketplace: "Agent Skills for MongoDB workflows and best practices."
- @rubrikInc (score 16.3) pitched Agent Governance with three pillars: Visibility, Governance, and Remediation. SAGE (Semantic AI Governance Engine) for natural-language policy definition.
2. Pain Points: What Frustrates People¶
🔴 Agent Marketplace Security Remains Critical¶
Description: 12% of OpenClaw's skill marketplace contains malware, including keyloggers and identity theft tools. A new "Guidance Injection" attack vector infects agents with malicious skills. Scenario: Developer installs a popular skill; it accesses Gmail, Stripe, and Slack credentials already granted to the agent. Severity: 🔴 Critical — direct financial and identity theft risk. Prevalence: Discussed by @JamesonCamp, @0x0SojalSec, @mashable, @FOUNDATIONdvcs. Coping strategies: Composio for scoped OAuth, manual code review, Scandar Guard runtime firewall, separate service accounts, encrypted vaults (PokeeClaw pattern).
🔴 Vendor Lock-in with Managed Agent Platforms¶
Description: Claude Managed Agents abstracts away infrastructure — convenient for builders but creates deep vendor dependency. Proprietary harness + sandbox + session management = hard to migrate. Scenario: Team builds production workflows on Managed Agents, then Anthropic changes pricing, rate limits, or deprecates the API. Severity: 🔴 Critical for startups building core products on it. Prevalence: Explicitly raised by @itspers, @AlexLWitt, @shiri_shh, @RoscoeSitePro. Coping strategies: Open-source alternatives (agentOS by @NathanFlurry), multi-provider harness patterns, Helmor open-source orchestration IDE.
🟡 Agent Memory Loss Across Sessions¶
Description: Agents forget context between sessions, leading to repeated hallucinations and lost productivity. Default configurations compound the problem. Scenario: Agent loses project context overnight, produces contradictory outputs, requires re-explaining every session. Severity: 🟡 High — blocks production adoption. Prevalence: @Mr_memsy, @conor_ai, @SmallWorld_Pod: "Your AI agent can pass the bar exam, but can't remember what you told it 5 minutes ago." Coping strategies: Temporal decay + embedding cache, /dreaming mode in OpenClaw, hierarchical file-based memory (Sibyl's 5-tier system), Hermes Agent learning loops.
🟡 Context Window Bloat Degrades Agent Performance¶
Description: Overloaded AGENT.md files (1,000+ lines = ~7,000 tokens per run) degrade agent quality. Skills solve this by loading only metadata (~50 tokens) until activated. Scenario: Developer adds every instruction to AGENT.md; agent becomes confused and slow as context fills up. Severity: 🟡 High — directly impacts output quality. Prevalence: Central theme of @gregisenberg's top tutorial (2,270 score). Also @DataScienceDojo, @Djw_learn. Coping strategies: Migrate from AGENT.md to skills, progressive disclosure, deterministic context engineering with dirpack.
🟡 Multi-Tenant Agent Debugging Is Painful¶
Description: When agent harness and sandbox share a container ("pet" pattern), stuck sessions can't be debugged without accessing user data. WebSocket event streams can't distinguish harness bugs from packet drops from container failures. Scenario: 47-hour agent session stalls at hour 12; engineer must shell into container holding user data to diagnose. Severity: 🟡 High for production deployments. Prevalence: Directly discussed by @charlespacker and the Anthropic blog post on "Don't adopt a pet." Coping strategies: Separate brain (harness) from hands (sandbox), session logs for crash recovery, Managed Agents' architecture splitting these concerns.
🟢 Framework Proliferation Without Clear Winners¶
Description: Too many agent frameworks, each with tradeoffs. Builders waste time evaluating instead of building. Scenario: Team evaluates LangGraph, CrewAI, OpenClaw, Hermes, DSPy before choosing — and may still pick wrong. Severity: 🟢 Moderate — slows but doesn't block. Prevalence: @Mr_memsy advises: "stop marrying one framework." @thehypedotnews published OpenClaw vs Hermes comparison. Coping strategies: Match framework to use case (LangGraph for stateful production, CrewAI for quick multi-agent teams, OpenClaw for autonomous coding).
3. Unmet Needs: What People Wish Existed¶
"An open-source Managed Agents alternative"¶
"Any agent, any LLM, 22 MB of RAM per sandbox, BYOC/on-prem, any file system, and – most importantly – open-source." — @NathanFlurry (tweet)
Opportunity rating: 🔴 High — Anthropic's launch created immediate demand for the non-vendor-locked equivalent. agentOS is early but positioned.
"An Agent Sandbox Protocol"¶
"Who is building the 'Agent Sandbox Protocol'? A way for users to specify where a 3rd party agent runs code, with what resources, and what permissions." — @alexgshaw (tweet)
Opportunity rating: 🔴 High — no standard exists; every platform reinvents containment.
"Agent harness safety as an engineering discipline"¶
"I'VE BEEN LOOKING FOR A FRAMEWORK THAT TREATS AI AGENT SAFETY AS AN ENGINEERING PROBLEM AND NOT A VIBE. AutoHarness does exactly that. 6 concrete steps around every tool call." — @42researcher (tweet)
Opportunity rating: 🟡 Medium — AutoHarness is emerging but the pattern needs standardization.
"Agent-to-agent trust and discovery across frameworks"¶
"Most AI agents are basically smart workers with no toolbox. They can plan, design & reason, but without the right tools and instructions, they still can't do much in the real world." — @thedefiedge (tweet)
Opportunity rating: 🟡 Medium — Katana, Orbis, and bankr are each approaching this from different angles.
"Production-ready agent eval tooling"¶
"We get a new agent framework every 12 hours but almost no one is building evals that keep up." — prior day signal, still unaddressed.
Opportunity rating: 🟡 Medium — Gym-Anything and OSGym are research-focused; production eval tooling remains a gap.
4. Current Solutions: What Tools & Methods People Use¶
| Solution | Category | Mentions | Sentiment | Strengths | Weaknesses |
|---|---|---|---|---|---|
| OpenClaw | Agent framework | 20+ | Mixed | Autonomous coding, large skill ecosystem (13,700+), extensible | 12% malware in marketplace, Guidance Injection attacks |
| Claude Managed Agents | Agent-as-a-Service | 15+ | Positive/Cautious | Turnkey infra, vault-based secrets, crash recovery, 60-90% TTFT reduction | Vendor lock-in, new (public beta), no open-source |
| Hermes Agent | Self-improving agent | 8+ | Positive | Learning loop, memory across sessions, local LLM support | Smaller ecosystem than OpenClaw |
| Claude Skills | Context management | 10+ | Very Positive | 50-token metadata vs 7K-token AGENT.md, progressive disclosure | Requires manual skill authoring |
| MCP | Tool protocol | 10+ | Positive | Standardized tool/data connections, Linux Foundation governance | Complex setup for some integrations |
| DSPy | Optimization framework | 3 | Positive | Durable abstraction across hype cycles, systematic optimization | Learning curve |
| LangGraph | Stateful workflows | 3 | Positive | Production-grade, checkpointing | Debugging complexity |
| PokeeClaw | Enterprise agent | 3 | Positive | 1,000+ integrations, RL-powered tool selection, encrypted vaults | Enterprise pricing unclear |
| LiveKit + Rime | Voice infra | 2 | Very Positive | Phonetic brackets, 100ms TTFB, deterministic pronunciation | Niche (voice-specific) |
| agentOS | Open-source runtime | 2 | Positive | 22MB per sandbox, BYOC, open-source | Early stage |
5. What People Are Building¶
| Name | Builder | Description | Pain Point Addressed | Tech Stack | Maturity | Score | Links |
|---|---|---|---|---|---|---|---|
| Muse Spark | @AIatMeta | Meta's first natively multimodal reasoning model with tool-use, visual chain-of-thought, and multi-agent orchestration. Contemplating mode parallelizes agents. Token compression via RL training. | Need for multimodal reasoning with native tool-use integration | Meta Superintelligence Labs | Launched (API private preview) | 6251.6 | Tweet |
| Claude Managed Agents | @claudeai / @katelyn_lesse | Full agent infrastructure: secure sandbox, vault-based secrets, crash recovery via session logs, brain/hands separation, multi-agent orchestration. YAML or console-based definition. | Agent infra is 90% of the work; teams spend months on sandbox/state management | Anthropic platform | Public beta | 3265.5 | Tweet |
| Gym-Anything / CUA-World | @wellecks / @PranjalAggarw16 | Framework that turns any software into a computer-use agent environment. CUA-World benchmark: 200+ software, 10,000+ tasks across all major occupation groups. | Training computer-use agents requires per-app custom environments | Open source | Released | 720.0 | Tweet |
| Dash v2 | @ashpreetbedi | Self-learning data team: 3 specialist agents, 6 layers of grounded context, dual schema system, learning loop. Security enforced at DB level. | Text-to-SQL agents fail without tribal knowledge | Python, Docker, SSE | Pre-release | 507.8 | Tweet |
| Sandbox Search | @arlanr | Codebase search that spins up a secure coding agent in its own sandbox per repo. Works inside Claude Code, OpenClaw, Cursor. | RAG/cloning for code search is slow and lossy | Daytona sandboxes | Launched | 281.9 | Tweet |
| agentOS | @NathanFlurry | Open-source agent runtime: any agent, any LLM, 22MB RAM per sandbox, BYOC/on-prem, any filesystem. Positioned as open alternative to Claude Managed Agents. | Vendor lock-in with managed agent platforms | Open source | Active dev | 264.8 | Tweet |
| Prefab | @jlowin | Generative UI framework for building MCP Apps and dashboards in Python with 100+ shadcn components. Real React, no JavaScript required. | Agents need UI but Python developers don't want to write JS | Python, React, Prefect | Launched | 87.5 | Tweet |
| SkillX | @zxlzr | Converts agent trajectories into reusable, hierarchical skills (Planning, Functional, Atomic). Transfer from strong to weak models yields ~10pt gains. | Agents learn in isolation; no cross-agent skill reuse | Python, open source | Paper + code | 65.3 | Tweet |
| OSGym | @Marktechpost | Scalable OS infra for training CUA agents: 1,024 parallel replicas, $0.23/day per replica, 88% less disk via CoW. From MIT/UIUC/CMU/Berkeley. | Training CUA agents is prohibitively expensive ($300/day → $30/day) | XFS reflink, pre-warmed containers | Research release | 93.5 | Tweet |
| QBotClaw | @TencentAI_News | First browser agent with WeChat remote control, built into QQ Browser. Zero setup, BYOLLM, free, proprietary browser skills. | Browser automation requires Puppeteer/Selenium expertise | QQ Browser, custom | Launched | 88.7 | Tweet |
| Phantom | @Anastasis_King | Autonomous AI red team agent — LLM-powered offensive security automation framework. | Manual pen-testing can't keep pace with agent attack surface | LLM-powered, open source | Released | 57.3 | Tweet |
| AgenC | @tetsuoarena | Agent designed to build continuously for a year. Redesigned TUI, planner, runtime. Self-corrected 5 failure modes via automated behavioral benchmarking. | Long-running agent reliability and self-correction | Custom runtime | Active dev | 84.5 | Tweet |
| Helmor | @caspian_1016 | Open-source agent orchestration IDE. One-click migration from Conductor. Claims 100x improvement over Conductor. | Agent orchestration tooling is fragmented | Open source | Pre-release | 12.9 | Tweet |
6. Emerging Signals¶
🆕 Claude Managed Agents Threatens Agent Orchestration Startups¶
Anthropic's simultaneous launch of managed infrastructure — sandbox, harness, session management, crash recovery — directly competes with every startup that built agent orchestration as their core product. @aakashgupta declared: "Anthropic just mass-obsoleted every agent orchestration startup in a single launch." Why it matters: The platform-vs-startup dynamic that defined cloud computing is now playing out in agent infrastructure. Startups must differentiate on openness (agentOS), specialization (voice, security), or multi-model support.
🆕 Meta Re-enters the Frontier Model Race with Muse Spark¶
After months of relative quiet, Meta Superintelligence Labs shipped a model that competes on multimodal reasoning benchmarks while introducing novel token compression via RL training. Contemplating mode (parallel multi-agent reasoning) is architecturally distinct from competitors. Why it matters: A fifth serious competitor (alongside OpenAI, Anthropic, Google, xAI) raises model commoditization pressure and lowers enterprise switching costs.
🆕 Agent-in-Sandbox vs Sandbox-as-Tool Becomes Architectural Choice¶
@charlespacker's framing and Anthropic's blog post on container debugging make this a named pattern rather than an implicit choice. Agent-in-sandbox = better for product (like OpenClaw); sandbox-as-tool = better for multi-tenant debugging. Why it matters: Teams now have vocabulary and tradeoff analysis for a previously ad-hoc decision.
🆕 SkillX and Graph-of-Skills Research Addresses Skill Discovery at Scale¶
Two independent papers tackle the same problem: how to organize, retrieve, and transfer skills as libraries grow beyond human curation. SkillX uses hierarchical decomposition; Graph-of-Skills uses dependency-aware PageRank. Why it matters: Validates that skill ecosystem scaling is a research-grade problem, not just a UX issue.
🆕 OSGym Proves CUA Training at $0.23/Day Per Replica¶
The MIT/UIUC/CMU/Berkeley paper demonstrates 80-90% cost reduction for training computer-use agents through RAM-over-CPU orchestration and copy-on-write disk management. Why it matters: Removes the primary cost barrier to academic and startup CUA research.
🆕 WideSeek-R1 Introduces Width Scaling as Alternative to Depth¶
Tsinghua's multi-agent RL framework achieves competitive results to a 671B model using coordinated 4B sub-agents in parallel. Why it matters: Challenges the assumption that scaling requires larger single models; multiple smaller agents may be architecturally superior for broad information seeking.
7. Community Sentiment¶
Overall mood: Energized but polarized 🟡→🟠
Two major product launches (Muse Spark, Claude Managed Agents) created a surge of excitement mixed with anxiety about platform power:
-
Builder excitement (strong): The @gregisenberg skills tutorial (2,270 score, 398 bookmarks), Gym-Anything's open-source release, and the sheer volume of new tools (Prefab, Sandbox Search, agentOS) show practitioners actively building. Bookmark rates are high — people are saving for implementation, not just consumption.
-
Platform anxiety (new today): Anthropic's Managed Agents launch triggered explicit "every startup just got cooked" reactions from @shiri_shh, @aakashgupta, and @AlexLWitt. The vendor lock-in concern is louder than yesterday.
-
Security fatigue (steady): The 12% malware stat continues circulating; new attack vectors (Guidance Injection) are discovered. But the tone is more resigned than panicked — security is becoming a known-bad rather than a surprise.
Sentiment direction vs 04-07: Yesterday was "cautiously excited, increasingly alarmed about security." Today is "energized by launches but newly worried about platform consolidation." The security anxiety hasn't grown — it's been absorbed as a baseline concern. The new emotional vector is platform power anxiety.
Evidence for divergence: The highest-engagement replies on Managed Agents split almost 50/50 between "this is amazing, just build" and "this is vendor lock-in, be careful." Crypto-agent communities remain uniformly bullish; enterprise communities are cautiously optimistic.
8. Opportunity Map¶
| Priority | Opportunity | Gap Size | Competition | Timing |
|---|---|---|---|---|
| 🔴 | Open-source managed agent runtime | Large — Anthropic's launch created immediate demand for the non-locked-in equivalent | agentOS (early), Helmor (pre-release) | Urgent — first mover with production-ready open alternative wins |
| 🔴 | Agent skill security scanning & certification | Critical — 12% malware, Guidance Injection attacks, no marketplace-wide standards | Scandar Guard, Snyk (general-purpose) | Urgent — trust crisis blocking adoption |
| 🔴 | Agent Sandbox Protocol standard | Large — every platform reinvents containment with no interop | Nobody — @alexgshaw explicitly asking who builds this | Now — fragmentation is actively harmful |
| 🟡 | Skill discovery & retrieval at scale | Medium — performance degrades as skill libraries grow | SkillX (research), Graph-of-Skills (research) | 6 months — research-to-product pipeline |
| 🟡 | Agent harness safety engineering tooling | Medium — safety is treated as "vibe" not engineering | AutoHarness (early) | 6 months — patterns becoming clear |
| 🟡 | CUA training infrastructure | Medium — cost barrier falling fast | OSGym (research), Gym-Anything (open source) | 6-12 months — needs productization |
| 🟢 | Agent orchestration IDE | Small — manual orchestration works, IDE is a convenience | Helmor, Conductor | 12 months — market education needed |
| 🟢 | Agent memory-as-a-service | Small but growing — Hermes and Sibyl patterns exist | No dominant player | 6-12 months |
9. Key Takeaways¶
-
Meta's Muse Spark and Anthropic's Managed Agents were the day's two defining launches. Muse Spark (6,251.6 score, 153K views) re-introduces Meta as a frontier competitor with novel token compression and multi-agent orchestration. Managed Agents (3,265.5 score, 402 bookmarks) moves Anthropic from model provider to full agent platform — threatening every orchestration startup.
-
Skills have won the context management debate. @gregisenberg's 2,270-score tutorial crystallized why: 50 tokens per skill description vs. 7,000 per AGENT.md file. The practical message — "run the workflow by hand first, then tell the agent to write the skill itself" — is the kind of concrete advice that accelerates adoption.
-
The open-source vs. managed agent infrastructure choice is now explicit. @NathanFlurry's agentOS (22MB/sandbox, open-source, BYOC) is directly counter-positioned to Claude Managed Agents. This will be the defining architectural choice for agent builders in Q2 2026.
-
Agent commerce is generating real revenue. bankr's $18.71M in fees, $11.23M paid to builders, and $286K top agent earnings — all via x402 micropayments — prove that agent-to-agent economic transactions are a production business, not a vision.
-
Research on skill management is accelerating. SkillX (hierarchical skill extraction), Graph-of-Skills (dependency-aware retrieval), and OSGym (training cost reduction) all address the scaling challenges that skill marketplaces will face at 50K+ skills.
-
Security tooling still lags the attack surface. Guidance Injection attacks on OpenClaw, CVE-2026-1839 discovered by an AI security agent, and ongoing malware rates all confirm that agent security is improving slower than agent capabilities.
10. Reply & Quote-Tweet Insights¶
Expert Corrections¶
- On Muse Spark, @gagansaluja08 corrected the hype: "Claude Opus 4.6 still leads the Intelligence Index and Sonnet still leads on agentic tasks. General benchmarks are converging. Specialization is where the real differentiation happens now." An important counterweight to the bullish framing.
- On Managed Agents, @strale_io raised a subtle failure mode: "Long-running ones fail quietly, over days, as upstream data drifts underneath them and the agent keeps acting on assumptions that were true when the session started."
Divergence Patterns¶
- The strongest divergence is between those who see Managed Agents as liberation ("anthropic saying we'll handle that, just build" — @Axel_bitblaze69) and those who see it as consolidation ("they pulled the subscription coverage for third-party agent orchestration... then released their own version" — @RoscoeSitePro).
Debate Patterns¶
- @charlespacker's agent-in-sandbox vs sandbox-as-tool post (101.7 score) generated architectural debate rather than tribal alignment. This is a positive signal — the community is reasoning about tradeoffs rather than picking sides.
- @GregKara6 pushed back on S3 Files hype: "the point of a sandbox was never the filesystem lol... we still have to validate how it handles itself on the hot path." A practical correction to @skeptrune's enthusiasm.
Community Self-Organization¶
- The @gregisenberg skills thread generated constructive practitioner replies: @itsdanreeves refined the methodology: "the workflow-first approach is the unlock — most people write the skill then force the workflow to match it." This kind of peer-to-peer knowledge refinement is healthy ecosystem behavior.
11. Technology Mentions¶
| Technology | Category | Mentions | Sentiment | Representative Tweet |
|---|---|---|---|---|
| Claude Managed Agents | Agent-as-a-Service | 15+ | Positive/Cautious | @trq212: right mix of simplicity and complexity |
| Muse Spark | Multimodal model | 12+ | Positive | @AIatMeta: natively multimodal reasoning |
| OpenClaw | Agent framework | 15+ | Mixed | @JamesonCamp: 12% malware |
| MCP | Tool protocol | 10+ | Positive | @MongoDB: Cursor Marketplace plugin |
| Claude Skills | Context management | 10+ | Very Positive | @gregisenberg: 50 tokens vs 7K |
| Hermes Agent | Self-improving agent | 6+ | Positive | @JulianGoldieSEO: builds memory across sessions |
| x402 | Payment protocol | 5+ | Positive | @aixbt_agent: $18.71M in agent commerce fees |
| DSPy | Optimization | 2 | Positive | @DSPyOSS: outlasted every hype cycle |
| Solana CLAWD | On-chain agent | 6+ | Positive (crypto) | @y0lloo: open-source Solana agent framework |
| ElevenLabs | Voice synthesis | 3 | Positive | @ktoya_me: retro phone voice agent |
| LiveKit | Voice infra | 2 | Very Positive | @livekit: phonetic pronunciation brackets |
| Amazon S3 Files | Storage | 2 | Very Positive | @skeptrune: eliminates sandbox VMs |
| Notion | Orchestration layer | 2 | Positive | @NotionHQ: Claude agents in Notion |
| GitLab Duo | DevOps agent | 2 | Positive | @bjmtweets: Southwest Airlines adoption |
| Gemma 4 | Local LLM | 2 | Positive | @JulianGoldieSEO: Apache 2.0 + OpenClaw |
| LangGraph | Framework | 2 | Positive | @Mr_memsy: best for stateful production |
| Prefab | Generative UI | 2 | Positive | @jlowin: Python-native React UI |
| VIRTUAL Protocol | Agent rewards | 3 | Promotional | @davidgua_eth: $1M monthly rewards |
12. Notable Voices¶
@AIatMeta — Score 6,251.6¶
Top tweet of the day. Muse Spark's launch dominated the feed with 153K views, 581 bookmarks. The benchmark table and Contemplating mode details drove architectural discussion. Meta's return to frontier competition is the day's biggest macro signal.
@trq212 — Score 3,265.5¶
Delivered the most influential commentary on Claude Managed Agents. The "right mix of simplicity and complexity" framing shaped how the community interpreted the launch. Thread on vaults, environments, and GitHub integration was widely cited. 402 bookmarks.
@gregisenberg — Score 2,270.0¶
The day's most practically useful content. The skills tutorial — 50 tokens vs 7,000, recursive skill building, "sub-agents are something you earn" — is the kind of actionable content that changes how builders work. 398 bookmarks makes it the #2 save-for-later item.
@NathanFlurry — Score 264.8¶
Counter-positioned agentOS directly against Claude Managed Agents with surgical precision: "This. But open-source." 36 bookmarks signals practitioner interest in the alternative. The 22MB-per-sandbox claim is a concrete differentiator.
@charlespacker — Score 101.7¶
Named and framed the agent-in-sandbox vs sandbox-as-tool architectural choice. By referencing the Anthropic blog post and drawing the analogy to pets-vs-cattle, he gave the community vocabulary for a previously implicit decision.
@helloiamleonie — Score 156.7¶
Workshop at AI Engineer Europe on "context engineering = 80% agentic search." A bridge between academic framing and practitioner reality. Multiple posts with solid bookmark rates.
@wellecks — Score 720.0¶
Gym-Anything is the day's most significant open-source research contribution. 107 bookmarks on an academic paper announcement is exceptional — practitioners are ready to use this for training computer-use agents.
13. Engagement Patterns¶
Highest Views-to-Likes Ratio (Weak Conviction / Algorithmic Distribution)¶
| Tweet | Views | Likes | Ratio | Interpretation |
|---|---|---|---|---|
| @Marktechpost — OSGym | 97,938 | 20 | 4,897:1 | Extreme algorithmic distribution; views from aggregator followers, not practitioners |
| @0rdlibrary — Solana Clawd | 54,828 | 25 | 2,193:1 | Crypto community drive-by views without engagement |
| @fabianstelzer — Claude keyboard | 30,887 | 140 | 221:1 | Entertainment content spreads wide without action |
| @ajaysharma_here — OpenClaw vs Hermes | 10,278 | 7 | 1,468:1 | Low follower account got algorithmic boost |
Highest Bookmarks (Save-Worthy Content)¶
| Tweet | Bookmarks | Likes | B/L Ratio | Content Type |
|---|---|---|---|---|
| @AIatMeta — Muse Spark | 581 | 2,280 | 0.25 | Model launch + benchmarks |
| @skeptrune — S3 Files | 632 | 744 | 0.85 | Infrastructure insight |
| @trq212 — Managed Agents | 402 | 921 | 0.44 | Product analysis |
| @gregisenberg — Skills tutorial | 398 | 180 | 2.21 | Practitioner tutorial — highest B/L ratio in top 10 |
| @wellecks — Gym-Anything | 107 | 136 | 0.79 | Research release |
Highest Quote-Tweet Count (Debate Triggers)¶
| Tweet | Quotes | Topic |
|---|---|---|
| @AIatMeta — Muse Spark | 189 | Model launch controversy |
| @OptimaiNetwork — AgentFi | 33 | Crypto agent marketplace |
| @NotionHQ — Claude in Notion | 13 | Platform integration |
| @trq212 — Managed Agents | 10 | Agent infrastructure |
| @aixbt_agent — bankr revenue | 10 | Agent commerce validation |
High Replies + Low Likes (Contentious)¶
| Tweet | Replies | Likes | Topic |
|---|---|---|---|
| @trq212 — Managed Agents | 94 | 921 | Architecture questions + vendor concerns |
| @OptimaiNetwork — AgentFi | 72 | 507 | Crypto skepticism vs enthusiasm |
| @y0lloo — $CLAWD | 44 | 92 | Token promotion replies |
| @Mr_memsy — Memory is everything | 25 | 23 | Active debate exceeds agreement |
14. Stats¶
| Metric | Value | Change vs 04-07 |
|---|---|---|
| Total tweets | 1,352 | +69.2% (from 799) |
| Original tweets (non-RT) | 1,352 | +69.2% |
| Retweets | 0 | — |
| Tweets with replies_data | 34 | +112.5% (from 16) |
| Tweets with quoted tweets | 174 | +112.2% (from 82) |
| Tweets with URLs | 209 | +37.5% (from 152) |
| Tweets with media | 174 | -20.2% (from 218) |
| Top score | 6,251.6 | -1.8% (from 6,368.3) |
| Median score | 3.0 | +7.1% (from 2.8) |
| Unique authors | 1,113 | +61.1% (from 691) |
| Total views (sum) | 1,184,155 | +240.2% (from 348,049) |