Twitter AI Agent Communities — Daily Analysis for 2026-04-11¶
1. Core Topics: What People Are Talking About¶
🔧 Harness, Skills & Agent Loops → (Steady — 5-day persistence)¶
The dominant theme for the fifth consecutive day. 117 of 256 reviewed tweets tagged harness_skills_memory (46%), proportionally stable from 04-10's 48%. The conversation has completed a full week-long arc: defining the discipline (04-07) → practitioner tutorials (04-08) → ecosystem buildout (04-09) → skill evolution & monetization (04-10) → tooling consolidation & automated skill installation (04-11). Today's shift: skills are no longer manually curated — they're auto-detected, auto-installed, and documented in comprehensive community guides.
- @elvissun (score 4315.4) posted the day's top tweet — the same turbo cache case study that topped 04-10, still circulating with even higher engagement. The detailed diagram shows a three-step harness methodology: (1) give the agent eyes (local turbo dry-run + cloud Vercel logs + git worktrees for isolated experiments), (2) drop it in a feedback loop (hypothesis → test → result), (3) let it iterate. The agent found two root causes — NEXT_PUBLIC_VERCEL_URL in globalEnv dirtying all hashes and Next.js framework inference silently re-injecting it — reducing builds from 3m 22s to 34s. Now at 744 bookmarks, up from 555 on 04-10 — continued reference-saving momentum.

-
@drummatick (score 2012.9) published a comprehensive curriculum for becoming "a top 1% AI engineer": LLM inference, agentic chat bots, agent tools, self-correcting loops, autonomous loops, debate models, token efficiency, agent harness, memory, context engineering, context compactness, RPI loop, subagents spawning. 331 bookmarks — the highest save count in the dataset. This is the same @drummatick who on 04-09 complained about AI-generated harness engineering content being slop; his counter-signal curriculum continues climbing.
-
@garrytan (score 1105.1) launched GBrain v0.8.0 with voice-to-brain integration: "Your AI can answer the phone now. Voice-to-brain v0.8.0 ships 25 production patterns from a real deployment. WebRTC works in a browser tab with just an OpenAI key." The changelog image details WebRTC-first design, radical prompt compression (13K to 4.7K tokens), dynamic noise suppression, stuck watchdog, and MCP docs rewritten for self-hosted + ngrok. 159 bookmarks. Separately (score 998.4), @garrytan described coding his personal AI voice agent poolside via Telegram: "I wondered if we could do dynamic VAD setting and it did it." 62,105 views — the second-highest view count in the dataset.

-
@iamlukethedev (score 896.2) covered OpenClaw v2026.4.10: "Active Memory plugin — your agent now remembers for you. Automatically pulls preferences, context, past conversations. Codex provider with managed auth and native threads. Local speech on macOS — runs fully on-device." 130 bookmarks — strong reference-saving for a product release.
-
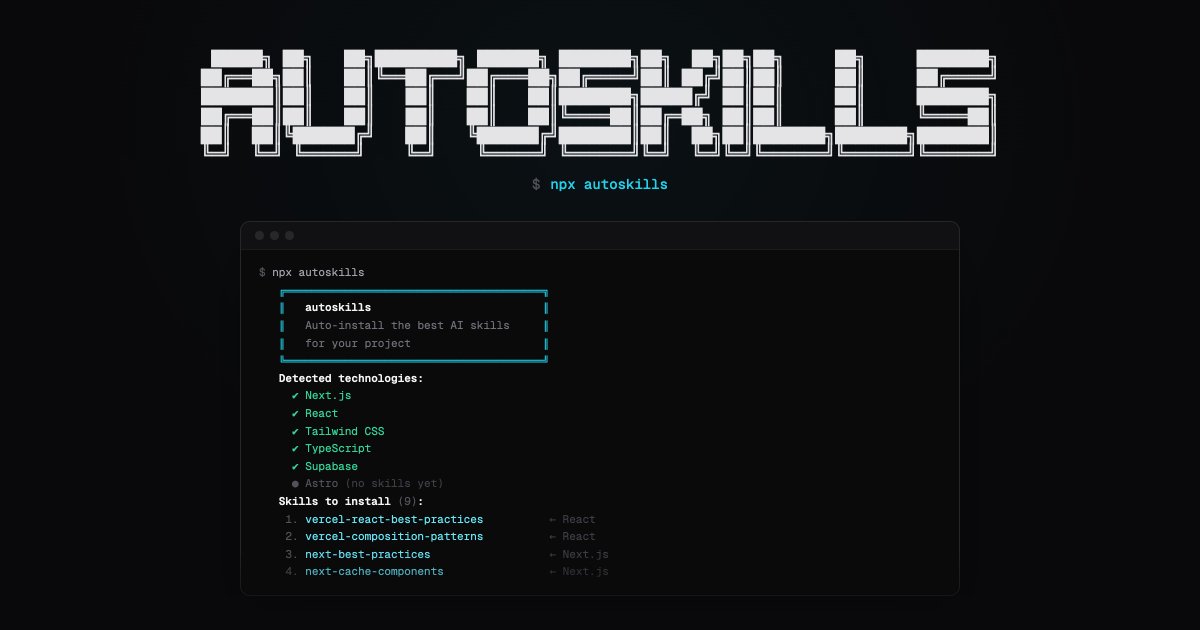
@code_rams (score 128.4) introduced autoskills: "Run
npx autoskillsin your project root. It reads your package.json, fingerprints your tech stack, hits the curated registry at skills.sh, and installs the right .claude/ skill files for every technology it detects." Supports 50+ technologies. The terminal screenshot shows automatic detection of Next.js, React, Tailwind CSS, TypeScript, and Supabase with 9 skills queued for installation.
- @tom_doerr (score 196.6) shared harness engineering design guides for Claude Code and Codex via github.com/wquguru/harness-books. The image shows two companion books: "Harness Engineering: A Design Guide to Claude Code" covering control plane, loop, recovery, permissions, and verification; and "The Harness Design Philosophies of Claude Code and Codex" comparing convergent and divergent approaches. Separately (score 130.6), he shared Swift Agent Skills via github.com/twostraws/Swift-Agent-Skills — a curated collection of open-source skills for Swift and Apple platform development.


-
@Teknium (score 645.8) promoted Hermes Agent skills browsing: "use
hermes skills browseorhermes skills searchto search and browse across many different popular skills hubs — ClawHub, Skills.sh, and more." 89 bookmarks — confirming practitioner demand for skill discovery. -
@amitiitbhu (score 462.8) published "Decoding Flash Attention", adding it to his 11-article LLM Internals Series that includes Harness Engineering alongside KV Cache, Paged Attention, and Transformer math. 70 bookmarks — harness engineering now firmly catalogued alongside foundational LLM concepts.
-
@KanikaBK (score 116.6) highlighted "The Orange Book" — a community-written 17-chapter Hermes Agent manual covering building a self-improving agent from zero to advanced. "Nous Research dropped the tool and basically left you to figure it out alone. No beginner guide. No map. Just a GitHub repo and good luck." The book covers memory architecture, skill creation loops, multi-platform setup, and comparisons to Claude Code and OpenClaw.

-
@IntuitMachine (score 117.6) continued "The Meta-Harness Revolution" thread — a 22-part breakdown of the Meta-Harness paper (arXiv:2603.28052v1) showing that automated harness search beat hand-designed harnesses by 7.7 points while using 4x fewer tokens. "Your LLM's performance isn't limited by its weights. It's limited by the code around it."
-
@xelebofficial (score 86.4) corrected four common misconceptions about Agent Skills: "It's not just a long prompt — a Skill loads every time the task appears. You don't need to know how to code — a Skill is a markdown file. The highest-value Skills are rarely about code — they're about how your team writes proposals. It's not Claude-only — GitHub Copilot, Cursor, Gemini CLI, Windsurf all support it."
-
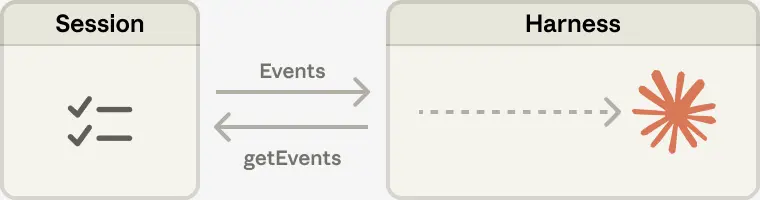
@RLanceMartin (score 106.8) described session-harness decoupling: "decoupling made the system more reliable. It also made the session a context object that the brain can interrogate." The diagram shows Events/getEvents bidirectional flow between Session (checklist) and Harness (tools).
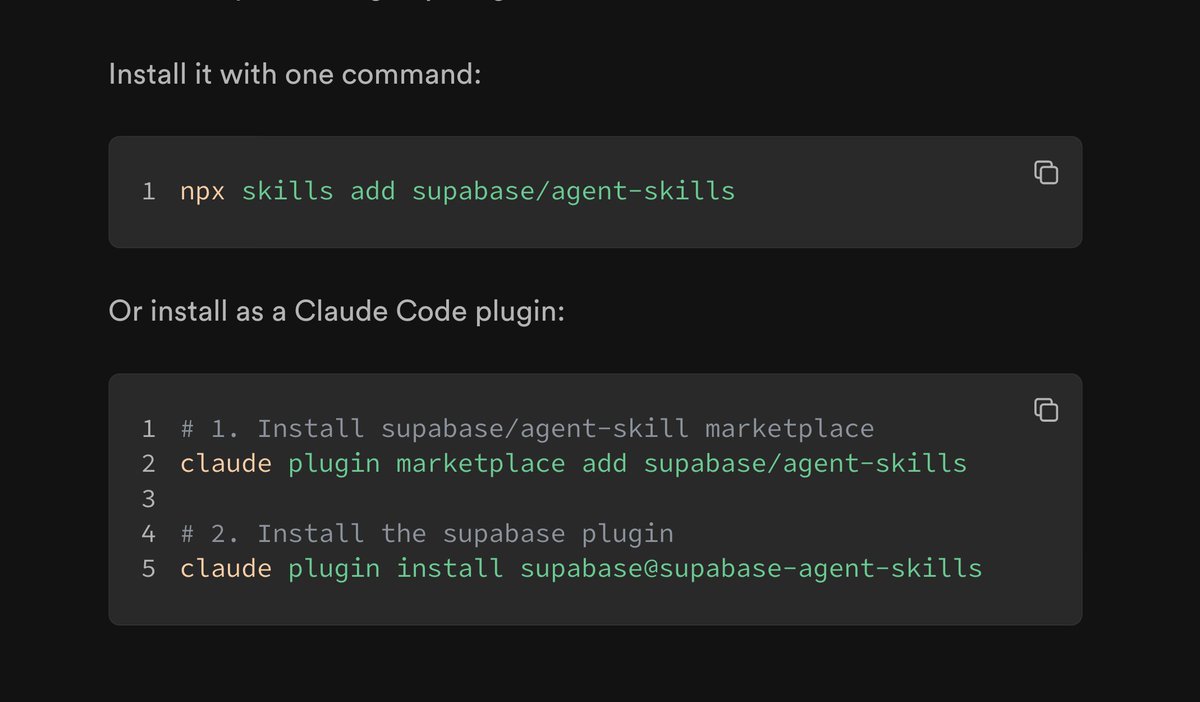
- @dshukertjr (score 120.6) launched official Supabase Agent Skills: "They add the most up-to-date Supabase product knowledge and access to the Supabase docs so that your app is built on top of the latest best practices!" Installation via
npx skills add supabase/agent-skillsor Claude plugin marketplace.
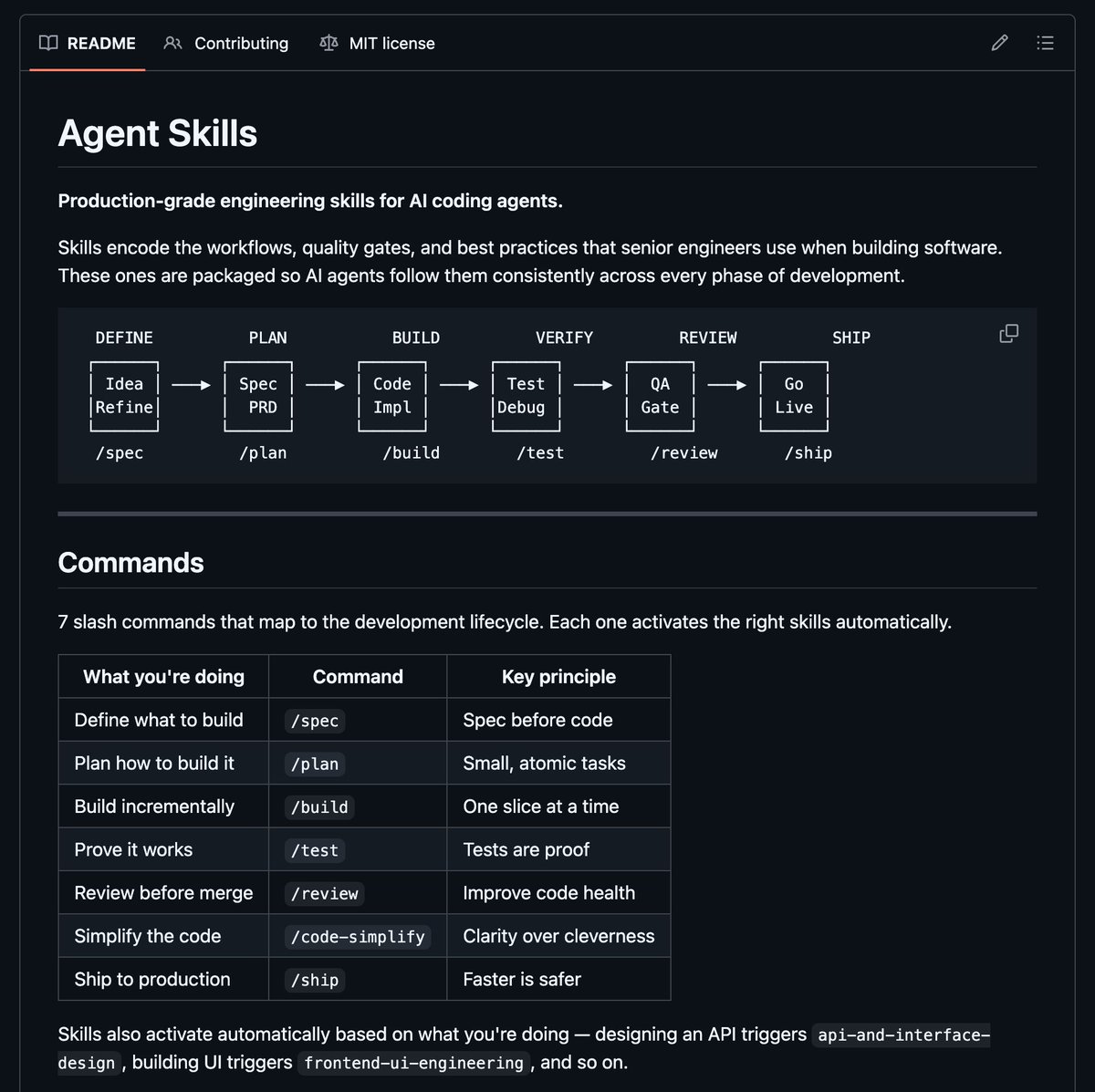
- @AlphaSignalAI (score 49.2) covered a Google engineer's open-source Agent Skills repo with 19 engineering skills and 7 slash commands covering the full dev lifecycle: Define → Plan → Build → Verify → Review → Ship. Each command activates the right skills automatically —
/specenforces "spec before code,"/buildenforces "one slice at a time."
Comparison to prior days: On 04-10, the skill narrative advanced along evolution (SkillClaw), monetization (Pika), and security (Cisco scanning). On 04-11, the conversation shifts to tooling consolidation: autoskills automates installation, Swift Agent Skills extends platform coverage to Apple, harness engineering books formalize the discipline, and The Orange Book fills the documentation gap Nous Research left open. The @elvissun harness case study continues circulating (744 bookmarks, up from 555) — a rare multi-day organic momentum signal.
🏪 Agent Marketplaces & Skill Monetization → (Steady — 5-day persistence)¶
33 tweets tagged marketplace_skills, down from 52 on 04-10 — a proportional pullback after yesterday's Pika-driven surge, but the theme remains structurally embedded in the conversation.
-
@Teknium (score 645.8) highlighted integrated skill hubs in Hermes Agent: "browse across many different popular skills hubs — ClawHub, Skills.sh, and more." This is marketplace infrastructure at the CLI level — discovery built into the agent itself.
-
@minchoi (score 201.9) amplified Pika's agent monetization: "Your Pika AI Self agent can earn money every time people chat with it or use its skills." Continued buzz from 04-10's launch.
-
@n__deborah (score 187.9) framed the Pika monetization narrative: "The idea that your AI self can now earn money through interactions and skills on Pika is such a smart move. It really changes the dynamic of what it means to build and raise a digital agent." 47 retweets but 0 bookmarks — amplification without reference-saving.
-
@okx (score 152.1) highlighted Agent Trade Kit skills marketplace as a weekly highlight alongside XAUT Streaks and Onchain OS Plugin Store. 18,913 views but only 5 bookmarks — typical exchange-audience engagement pattern.
-
@igoryuzo (score 141.7) noted @clawdbotatg releasing x402 Agent Marketplace, continuing the x402 micropayment-for-agents thread from 04-09.
-
@JIMMYEDGAR (score 136.6) building a Solana marketplace: "a complete hands-off autonomous agent marketplace. Configure yours and set it free."
-
@iamfakeguru (score 118.8) highlighted Escroue — "a trustless agent-to-agent marketplace where agents post tasks, bid on work, and settle payments on-chain" — which won at Synthesis (top 2% of 687 submissions). Built on @openservai. See escroue.com.
-
@PlutonAIHQ (score 124.2) pushed the creator-to-marketplace pipeline: "Build your AI Agent. List it on the marketplace. Earn from usage. Your intelligence = an asset now." 24,223 views but only 1 bookmark — high distribution, low depth signal.
-
@OOBEonSol (score 152.4) spotlighted Crewboard — "a web3 freelance marketplace powered by Synapse developer tools for on-chain execution and coordination." Replies mention x402 payments via escrow.
Comparison to prior days: The marketplace volume pulled back from 04-10's Pika-driven spike (52 → 33 tweets), but the underlying thesis persists: skill-based monetization is moving from platform-level (OKX, Pika) to individual-level (Escroue agent-to-agent bidding, Crewboard freelance). The x402 micropayment protocol continues threading through multiple projects.
☁️ Enterprise Agent Infrastructure & MCP → (Steady)¶
39 tweets tagged enterprise_context_mcp. Enterprise infrastructure remains a consistent undercurrent, with Google, Microsoft, and new entrants active.
-
@googleaidevs (score 1645.2) showcased Gemma 4 31B leveraging an ADK Agent and code execution sandbox: "Zero-shot code generation, tool usage, multi-step debugging and recovery." 487 likes, 202 bookmarks — the second-highest engagement in the dataset. A reply from @humorbyteshs captured the practical question: "Watching models write code, run it, break it, then fix it... curious how stable that self-debug loop stays after a few iterations."
-
@MicrosoftLearn (score 351.8) broke down AI agent components: "reasoning → the model; actions → the tools; context → what it knows; retrieval → bringing in the right info; orchestration → how it all works together; evaluation → how you know it works." 47 bookmarks — strong for conceptual framing.
-
@dani_avila7 (score 135.6) tested Claude Managed Agents and found a security concern: "Vaults store OAuth tokens outside the sandbox, the agent never handles them directly. The problem: vaults are workspace-scoped. Anyone with workspace access can reference your vaults and use your credentials in their own sessions." The architecture diagram shows Workspace → Vault → Credentials → MCP Server, with Session able to reference vault_ids. 20 bookmarks — high save rate for a security finding.
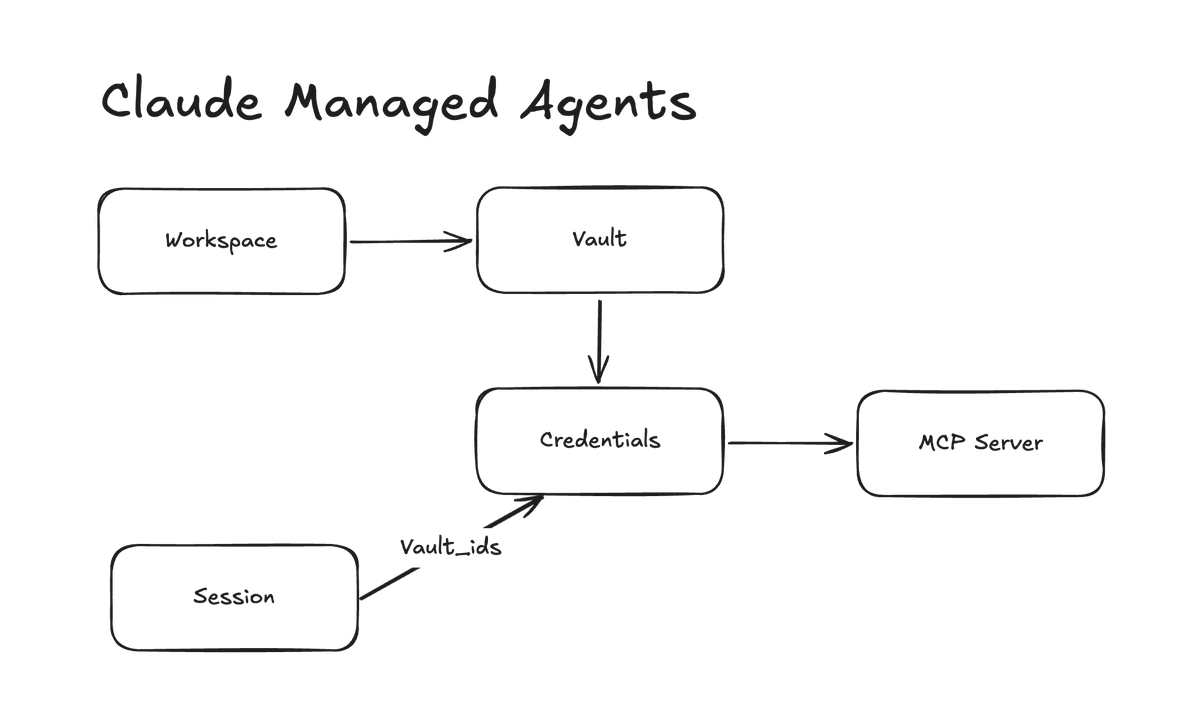
-
@nyk_builderz (score 106.5) articulated the context governance thesis: "The next AI moat isn't model access. It's context governance. Teams shipping fastest in 2026 all do 3 things: version memory like code, score agent outputs before action, treat prompts as interfaces not magic." A reply from @l33tdawg shared SAGE — a BFT-consensus-for-memory system — and @nyk_builderz wrote a substantive technical comparison noting SAGE as a data plane and LACP as a control plane that "would actually plug together well."
-
@Codex_Changelog (score 425.1) announced Codex 0.119.0: "Voice defaults to WebRTC, MCP Apps gain resource reads, elicitations, and file uploads, Ctrl+O copies the latest agent response, /resume now accepts a session ID or name." 241 likes. See github.com/openai/codex/releases/tag/rust-v0.119.0.
🏗️ Runtime Sandboxes & Agent Infrastructure → (Steady)¶
28 tweets tagged runtime_sandbox_os. Stateful sandboxes and cross-device agent deployment continue as an active engineering thread.
-
@diptanu (score 253.9) argued for stateful sandboxes: "Resume the same sandbox where the agent previously ran and get back all the files. 70-80% of infrastructure complexities of agent orchestration goes away if the sandboxes are stateful and not ephemeral." A reply from @ldenoue challenged: "following the fanfare announcement of Claude managed agents I don't understand why folks are suddenly going back to the agent-outside-the-sandbox model." @diptanu responded: "both durable execution of harnesses and stateful sandboxes benefit harnesses — durable execution to restart from crashes, and stateful sandboxes to retain file systems, artifacts and in-memory state across sessions."
-
@muhashmii (score 88.8) demonstrated spawning agents on Daytona sandboxes via OpenRouter's spawn CLI: "one command" to spin up Pi, Claude, Codex, or OpenCode agents.
-
@Viewforge (score 46.3) announced cross-device agent scheduling: "Schedule an army of agents across your Mac/Windows/Android/Chrome devices. Run any combination of OpenClaw/Hermes Agent/Claude CLI across all devices controlled with an orchestration agent that supports real-time voice commands."
📚 AI Education & Courses ↑ (Emerging)¶
40 tweets tagged course_learning — a notable spike. Anthropic's free certification courses dominate.
- @DipanshuKu55175 (score 114.3) compiled all 13 Anthropic free courses with direct links: Claude 101, AI Fluency, Introduction to Agent Skills, Building with the Claude API, Claude Code in Action, Intro to MCP, MCP Advanced Topics, and more. All via anthropic.skilljar.com.
-
@dejavucoder (score 66.4) praised Anthropic's educational approach: "anthropic educational blogs are very info dense and cutting edge info. If you just absorb them and try applying them, you can skill up really fast in context engineering stuff."
-
@i_amanchadha (score 44.1) published a comprehensive Context Engineering primer at contexteng.aman.ai covering building blocks, retrieval/memory/compression, tools/schemas/planning loops, advanced patterns, and production heuristics.
🔬 Research & Benchmarks → (Steady)¶
22 tweets tagged research_eval. Academic and benchmark activity continues.
- @askalphaxiv (score 119.5) covered PaperOrchestra (Google, arXiv:2604.05018) — a multi-agent framework for automated AI research paper writing that introduces PaperWritingBench from 200 top-tier papers. Achieves 50-68% win rate margin on literature review quality and 14-38% on overall manuscript quality.

- @Baidu_Inc (score 79.6) announced Famou-Agent 2.0 topping MLE-Bench again with upgrades across evolution strategies, long-horizon memory, and infrastructure. The leaderboard shows Famou-Agent 2.0 at #1, followed by AIBuildAI, CAIR MARS+, MLEvolve, and PiEvolve.
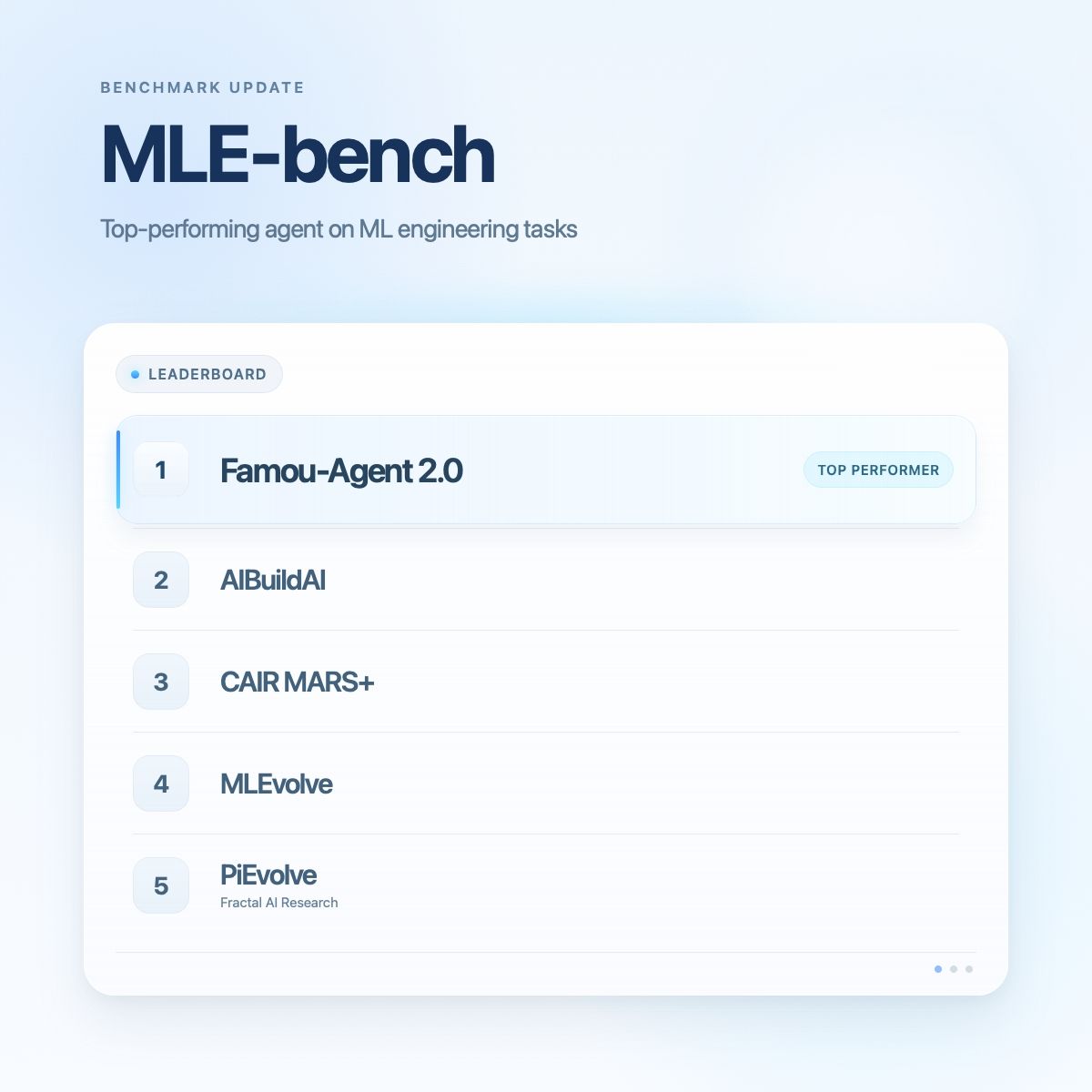
- @Analytics_699 (score 76.2) covered VAGEN (Stanford) — a framework teaching VLM agents to build internal world models through reinforcement learning, achieving SOTA at 3B parameters across diverse visual tasks. The architecture diagram shows trajectory buffer, rollout loop, PPO with bi-level advantage estimation.

- @pvergadia (score 94.4) announced Agent Lightning — Microsoft's open-source reinforcement learning for any agent in any framework: "Days of prompt tweaking → 1 function call. Zero rewrites. Zero framework changes." Supports LangChain, AutoGen, CrewAI, OpenAI SDK, or plain Python.

2. Pain Points: What Frustrates People¶
🔐 Workspace-Scoped Credentials Are a Security Hole¶
Severity: High | Prevalence: Emerging @dani_avila7 (score 135.6) found that Claude Managed Agents vaults are workspace-scoped: "Anyone with workspace access, via API key or the Console, can reference your vaults and use your credentials in their own sessions." This is a real multi-tenant credential isolation gap. No workaround mentioned — the architecture itself is the problem.
🧩 Agent Frameworks Still Don't Compose Across Chains¶
Severity: Medium | Prevalence: Recurring (3+ days) Multiple tweets from @KongBTC (score 39.2) and @ElCryptoDoc (score 33.3) describe agents "stuck on single chains" — unable to swap, bridge, or execute across Solana and EVM chains without custom plumbing. CrossWeave is cited as a potential fix, but at $25K FDV and pre-mainnet, it's early.
📖 Documentation Gaps for Open-Source Agent Frameworks¶
Severity: Medium | Prevalence: Recurring @KanikaBK (score 116.6) directly called out the gap: "Nous Research dropped the tool and basically left you to figure it out alone. No beginner guide. No map. Just a GitHub repo and good luck." The community-written Orange Book (17 chapters) exists precisely because official documentation was insufficient. The same pattern persists with OpenClaw, where @garrytan acknowledges users struggle with Supabase connection setup — solved in v0.8.0 by switching to local PGLite.
🔄 Manual Skill Installation Is Tedious¶
Severity: Low-Medium | Prevalence: New @code_rams (score 128.4) framed the problem autoskills solves: "You spent weeks setting up AI agent skills manually... Google 'Claude Code skills for Next.js', find a GitHub repo, read the README, copy skill file, paste into .claude/. Repeat for every technology. 2 hours gone, still not sure if you got everything." The existence of autoskills as a product confirms the pain is real.
⚡ AI Agents Are Fast But Reckless¶
Severity: Medium | Prevalence: Steady @AlphaSignalAI (score 49.2) summarized the core complaint: "AI coding agents are fast but reckless. They skip specs, tests, and security." The Agent Skills repo with its Define → Plan → Build → Verify → Review → Ship pipeline is explicitly positioned as a fix for this — encoding what senior engineers do that AI skips.
3. Unmet Needs: What People Wish Existed¶
🔒 Per-Session or Per-Agent Credential Scoping¶
Desire: Vault-scoped credentials that prevent cross-session credential leakage in managed agent environments. @dani_avila7 identified the gap — workspace-scoped vaults allow anyone with workspace access to reference anyone else's credentials. Currently no solution exists within Claude Managed Agents. Type: Functional, must-have for enterprise adoption | Currently served: No | Opportunity: 🔴 Direct
🔗 Single-API Cross-Chain Agent Operations¶
Desire: Agents that transact, bridge, and swap across Solana + EVM chains with one identity and one API call. @KongBTC and @ElCryptoDoc both describe this need explicitly. CrossWeave claims to solve it but is pre-mainnet. Type: Functional, must-have for DeFi agent adoption | Currently served: Partially (CrossWeave in beta) | Opportunity: 🟡 Competitive
📘 Opinionated Beginner-to-Advanced Agent Guides¶
Desire: Structured, comprehensive documentation for agent frameworks. The Orange Book exists for Hermes but is community-written and based on v0.7.0 (already one version behind). @garrytan (score 163.9) described his approach: "you can skip ahead to my opinionated set of skills, schema, and memory with GBrain" — reducing the configuration burden to a single install. Type: Functional, nice-to-have → must-have as adoption grows | Currently served: Partially | Opportunity: 🟡 Competitive
🤖 Agent Self-Improvement Without Manual Intervention¶
Desire: Agents that create and refine their own skills automatically, without human prompt engineering at each step. @cto_junior (score 38.3) praised Hermes's self-learning loop: "Till now I was hacking together a /wrap up skill in CC/Codex myself but Hermes captures learnings way better. Best part is it actually acts on them by spinning up new skills." The Meta-Harness paper further validates that automated harness search outperforms manual engineering. Type: Functional, must-have | Currently served: Partially (Hermes, Meta-Harness research) | Opportunity: 🟡 Competitive
🧠 Persistent, Versionable Agent Memory¶
Desire: Memory systems that persist across sessions, can be versioned like code, and support quality gates. @nyk_builderz (score 106.5) described the need: "version memory like code, score agent outputs before action." @diptanu argued for stateful sandboxes as the mechanism. OpenClaw's Active Memory plugin begins addressing this. Type: Functional, must-have for production agents | Currently served: Partially (OpenClaw Active Memory, Hermes memory, SAGE) | Opportunity: 🔴 Direct
4. Current Solutions: What Tools & Methods People Use¶
| Solution | Category | Mentions | Sentiment | Strengths | Weaknesses |
|---|---|---|---|---|---|
| OpenClaw | Agent framework | 12+ | Positive | Active Memory plugin, Codex provider, local speech, OpenClaw v2026.4.10 update | Setup complexity (Supabase connection), steep learning curve |
| Hermes Agent | Agent framework | 15+ | Very positive | Self-improving skill loop, 50K stars, cross-platform, skill creation | Poor official documentation, community-written guide already outdated |
| Claude Code | Coding agent | 10+ | Positive | Skills ecosystem, .claude/ skill files, managed agents | Workspace-scoped vaults, credential isolation concerns |
| Codex (OpenAI) | Coding agent | 8+ | Positive | v0.119.0 WebRTC voice, MCP Apps, session resume | Comparisons to OpenClaw ecosystem show less harness flexibility |
| GBrain | Agent meta-framework | 5+ | Very positive | v0.8.0 voice-to-brain, 25 production patterns, opinionated defaults | Tied to @garrytan's ecosystem, early stage |
| autoskills | Skill installation | 3+ | Very positive | Auto-detects 50+ technologies, one-command install | New project, registry coverage still growing |
| Skills.sh | Skill registry | 4+ | Positive | Curated registry, integrated with Hermes search | Limited to participating skill authors |
| Supabase Agent Skills | Domain skills | 2+ | Positive | Official vendor skills, up-to-date docs | Supabase-specific |
| Swift Agent Skills | Domain skills | 2+ | Positive | Apple/Swift platform coverage, curated collection | Niche platform |
| Agent Lightning | Agent optimization | 2+ | Positive | Any framework, RL/prompt optimization, MIT license | Early (v0.3.0), small community |
Migration patterns: Multiple signals of users trying OpenClaw → switching to Hermes for better self-improvement loops, or augmenting OpenClaw with GBrain for opinionated defaults. @lukewestlake (score 89.1) described switching from Opus orchestration to Codex/GPT-5.4 after account issues: "the upgrades to OC and agent files tweaks are REAL."
Satisfaction spectrum: Highest satisfaction with Hermes's self-learning loop and GBrain's voice integration. Lowest satisfaction with credential management in Claude Managed Agents and documentation quality across all frameworks.
5. What People Are Building¶
| Name | Builder | Description | Pain Point Addressed | Tech Stack | Maturity | Score | Links |
|---|---|---|---|---|---|---|---|
| GBrain v0.8.0 | @garrytan | Voice-to-brain AI agent with WebRTC, Twilio integration, 25 production voice patterns, radical prompt compression (13K→4.7K tokens) | Voice interaction with personal AI agents | OpenClaw/Hermes, WebRTC, Twilio, PGLite | Active (v0.8.0) | 1105.1 | Tweet |
| Vibe-Trading | @ihtesham2005 | Open-source AI trading agent with 64 finance skills, 29 swarm presets, DAG-based multi-agent system for cross-market backtesting | Lack of open-source quant agent tooling | Python 3.11+, FastAPI, React 19, MIT | Active (v0.1.4) | 315.6 | Tweet |
| autoskills | @code_rams | CLI that auto-detects project tech stack and installs matching AI agent skills from skills.sh registry | Manual skill installation is tedious | Node.js (npx), skills.sh registry | New | 128.4 | Tweet |
| Escroue | @Escapation | Trustless agent-to-agent marketplace for task posting, bidding, and on-chain payment settlement | No decentralized agent work coordination | OpenServ, on-chain settlement | Award-winning (Synthesis top 2%) | 118.8 | escroue.com |
| The Orange Book | HuaShu (Alchain) | 17-chapter comprehensive Hermes Agent guide covering zero-to-advanced, memory architecture, skill creation, multi-platform setup | No official documentation for Hermes | Markdown, based on v0.7.0 | Published | 116.6 | Tweet |
| Hermes Fleet | @oysterecosystem | Decentralized AI compute on 70,000 phones using Hermes Agent Framework for LeWorld and Qwen 2.5 model training | Centralized cloud compute costs | 70K edge devices, Hermes Agent, MCP | Active fleet | 69.7 | Tweet |
| BridgeMind on DGX Spark | @bridgemindai | Hermes Agent running on NVIDIA DGX Spark for automated cold outreach emails — self-improving agent completing tasks and creating skills | Manual sales outreach | Hermes Agent, NVIDIA DGX Spark | Demo | 274.7 | Tweet |
| Viewforge Scheduler | @Viewforge | Cross-device agent scheduler for Mac/Windows/Android/Chrome with voice-commanded orchestration agent | No unified multi-device agent management | OpenClaw, Hermes, Claude CLI, Daytona | Active | 46.3 | Tweet |
| AGIX Marketplace | @0xAgix | Agent marketplace with runtime policy enforcement, execution tracing, and trust visibility | Drift between declared and actual agent permissions | On-chain verification | Active | 35.3 | Tweet |
Analysis: Builder activity clusters around three patterns: (1) personal AI agents with voice — GBrain, BridgeMind, and Viewforge all add voice or cross-device interaction to existing agent frameworks, (2) automated tooling — autoskills eliminates manual setup, Agent Skills repo encodes senior engineer workflows, (3) decentralized agent coordination — Escroue, AGIX, and Hermes Fleet all solve multi-agent trust and coordination problems on-chain.
The Vibe-Trading project stands out for scope: 64 skills, 29 swarm presets, 21 tools, 5 data sources, cross-market backtesting, and MIT license — essentially an open-source quant desk run by collaborating agents.
6. Emerging Signals¶
🆕 Automated Skill Installation Reaches CLI-Level Maturity¶
autoskills (npx autoskills) auto-detects project tech stacks and installs matching skills from the skills.sh registry. This moves skill adoption from manual curation to automated CI-like workflows. Not seen in prior days — first appearance on 04-11.
🆕 Harness Engineering Gets Formalized in Books¶
@tom_doerr shared two companion design guides — "Harness Engineering: A Design Guide to Claude Code" and "The Harness Design Philosophies of Claude Code and Codex." The existence of formal books on harness design indicates the discipline has crossed from Twitter threads to reference-grade documentation.
🆕 Agent Lightning: Open-Source RL for Any Agent Framework¶
Microsoft open-sourced Agent Lightning — reinforcement learning that works with any agent framework (LangChain, AutoGen, CrewAI, OpenAI SDK, or plain Python) with zero code changes. "Days of prompt tweaking → 1 function call." This is the first framework-agnostic agent optimization tool to appear.
🆕 Voice-to-Brain Agents Ship Production Patterns¶
GBrain v0.8.0 ships 25 production voice patterns including identity separation, pre-computed engagement bids, conversation timing, no-repetition rules, and radical prompt compression. This is no longer demo-grade — the changelog reads like production infrastructure documentation.
🆕 Agent Exploit Finding Draws Skepticism¶
@dbreunig (score 42.5) cautioned against over-projecting Anthropic's exploit-finding demos: "finding bugs & exploits is the perfect marketing demo" because it has a built-in verification loop and only needs to find a single crack. "Building reliable software requires handling edge cases, maintainability, coherence across components. The former is a search problem; the latter is a construction problem."
7. Community Sentiment¶
Overall mood: Constructive optimism with tooling consolidation undertones.
The community is in a building phase rather than a hype phase. The top-engagement tweets are practical case studies (@elvissun's harness debugging, @garrytan's voice agent), product releases (OpenClaw v2026.4.10, GBrain v0.8.0, Codex 0.119.0), and tooling announcements (autoskills, Supabase Agent Skills). This contrasts with earlier days in the week where philosophical framing dominated.
Divergences: - Practitioner optimism vs. security concern: @dani_avila7's credential isolation finding strikes a cautionary note amid mostly positive product coverage - Open-source enthusiasm vs. documentation frustration: The Orange Book and autoskills exist precisely because official documentation falls short - Agent exploit hype vs. engineering skepticism: @dbreunig's nuanced critique of exploit-finding demos pushes back against Anthropic marketing
Astroturfing signals: - @PlutonAIHQ (score 124.2): 24,223 views but only 1 bookmark — extremely high view-to-save ratio suggests promotional amplification - Several crypto-adjacent marketplace tweets show coordinated phrasing patterns ("Don't miss this," "Can't miss this one") in replies, consistent with community bot engagement - Virtual Protocol rewards tweets appear across multiple accounts with similar templates
8. Opportunity Map¶
-
🔴 Per-Agent Credential Isolation — @dani_avila7's finding of workspace-scoped vaults in Claude Managed Agents is a clear enterprise blocker. Building session-scoped or agent-scoped credential management would address a security gap that major providers haven't solved. (Evidence: Section 2 Pain Points, Section 3 Unmet Needs)
-
🔴 Automated Skill Discovery & Installation — autoskills proves the concept, but the skills.sh registry is early and coverage is incomplete. Building a comprehensive, vendor-neutral skill registry with automated project fingerprinting has strong demand signal (331 bookmarks on @drummatick's curriculum, 89 bookmarks on @Teknium's skill browsing). (Evidence: Sections 1, 2, 5)
-
🔴 Agent Memory as Infrastructure — Three independent signals converge: OpenClaw Active Memory plugin, @nyk_builderz's "version memory like code" thesis, and @diptanu's stateful sandboxes argument. Whoever builds the "git for agent memory" wins a foundational layer. (Evidence: Sections 1, 3, 4)
-
🟡 Voice-to-Brain Agent Infrastructure — GBrain v0.8.0's 25 production patterns and @garrytan's two high-engagement tweets (1105.1 + 998.4 combined score) show strong demand for voice-first agent interaction. WebRTC + Twilio integration is becoming table stakes. (Evidence: Sections 1, 5, 6)
-
🟡 Cross-Chain Agent Operations — Multiple tweets describe agents stuck on single chains. CrossWeave claims one-API-call cross-chain execution but is pre-mainnet at $25K FDV. The gap between demand and reliable solutions is wide. (Evidence: Sections 2, 3)
-
🟡 Agent Framework Documentation-as-a-Product — The Orange Book (17 chapters for Hermes), harness engineering design guides, and @amitiitbhu's LLM Internals Series all suggest demand for premium, structured learning content around agent frameworks. (Evidence: Sections 1, 2, 3)
-
🟢 Agent Self-Optimization — Meta-Harness research (7.7 point improvement, 4x fewer tokens) and Agent Lightning (RL for any framework) point toward agents that automatically optimize their own harnesses. Still research-grade but moving fast. (Evidence: Sections 1, 6)
9. Key Takeaways¶
-
Skill installation is being automated. autoskills (
npx autoskills) auto-detects tech stacks and installs matching skills — the first CLI-level solution to the "2 hours manually Googling skills" problem described by @code_rams (score 128.4). -
The @elvissun harness case study has 5-day legs. At 744 bookmarks and still climbing from its 04-07 origin, the 3m22s → 34s build fix with concrete root-cause diagrams is the week's most durable artifact.
-
Voice-to-brain agents ship production patterns, not demos. GBrain v0.8.0's changelog lists 25 production voice patterns including prompt compression (13K→4.7K tokens), stuck watchdog, and conversation timing — infrastructure-grade documentation from @garrytan (score 1105.1).
-
Claude Managed Agents have a credential isolation gap. @dani_avila7 (score 135.6) found workspace-scoped vaults allow cross-session credential access — a real security finding, not a theoretical concern.
-
Harness engineering is becoming a formal discipline. Design guide books, a 22-part Meta-Harness thread on automated optimization, and @amitiitbhu cataloguing it alongside KV Cache and Transformer math — the field has moved from blog posts to reference material.
-
The Orange Book fills the Hermes documentation gap. A community-written 17-chapter guide exists because "Nous Research dropped the tool and basically left you to figure it out alone" — @KanikaBK (score 116.6).
-
Agent Lightning brings RL-based optimization to any framework. Microsoft's open-source release (score 94.4) means "days of prompt tweaking → 1 function call" across LangChain, AutoGen, CrewAI, and plain Python — framework-agnostic agent improvement is now available.
10. Reply & Quote-Tweet Insights¶
Expert Corrections¶
- @diptanu corrected the ephemeral-sandbox-with-git-push pattern shared by @insecureagents: "Or just use stateful sandboxes. Resume the same sandbox where the agent previously ran. 70-80% of infrastructure complexities goes away." @ldenoue amplified: "I don't understand why folks are suddenly going back to the agent-outside-the-sandbox model."
- @nyk_builderz wrote a substantive technical comparison in reply to @l33tdawg's SAGE pointer: "SAGE is a data plane (memory as a consensus-validated service), LACP is a control plane... They'd actually plug together well: SAGE exposes MCP, and LACP already wires MCP-backed memory providers."
Reply-Tweet Divergence¶
- @garrytan's poolside coding tweet (62,105 views) drew lifestyle commentary ("Virgin piña colada, man") but also substantive questions: "Have you switched entirely to voice now?" — showing the community is genuinely trying to understand voice-first workflows.
- @bridgemindai's Hermes on DGX Spark tweet drew: "OpenClaw got the hype. Hermes got the architecture right" — a direct comparison claim, with a sarcastic reply from @shpak_dev linking to the meme of "I want you to scour the internet."
Quote-Tweet Debate¶
- @dbreunig (score 42.5) used Anthropic's Mythos exploit-finding as a springboard for a measured engineering critique: "An exploit only needs to find a single path through a system's defenses. Building reliable software requires handling edge cases, maintainability, coherence across components. The former is a search problem; the latter is a construction problem."
- @elvissun quote-tweeted his own prior tweet, extending the harness methodology with more results. A reply added: "if agent can't solve it it means you didn't give it the right harness — this applies to everything including sending human to the moon."
11. Technology Mentions¶
| Technology | Category | Mentions | Sentiment | Representative Tweet |
|---|---|---|---|---|
| OpenClaw | Agent framework | 12+ | Positive | @iamlukethedev: v2026.4.10 Active Memory plugin |
| Hermes Agent | Agent framework | 15+ | Very positive | @Teknium: skills browse/search across hubs |
| Claude Code | Coding agent | 10+ | Positive | @tom_doerr: harness engineering design guides |
| Codex (OpenAI) | Coding agent | 8+ | Positive | @Codex_Changelog: v0.119.0 WebRTC voice |
| GBrain | Agent meta-framework | 5+ | Very positive | @garrytan: v0.8.0 voice-to-brain |
| WebRTC | Communication | 5+ | Positive | @garrytan: default voice protocol for agents |
| Twilio | Communication | 3+ | Neutral-positive | @garrytan: phone number integration |
| MCP | Protocol | 8+ | Positive | @Codex_Changelog: MCP Apps resource reads |
| Supabase | Database/BaaS | 4+ | Positive | @dshukertjr: official Agent Skills launch |
| FastAPI | Web framework | 2+ | Neutral | @ihtesham2005: Vibe-Trading backend |
| React 19 | Frontend | 2+ | Neutral | @ihtesham2005: Vibe-Trading frontend |
| Solana | Blockchain | 4+ | Positive | @JIMMYEDGAR: autonomous marketplace |
| Gemma 4 31B | LLM | 2+ | Very positive | @googleaidevs: ADK Agent + sandbox |
| GPT-5.4 | LLM | 2+ | Positive | @lukewestlake: switched for orchestration |
| LangChain | Agent framework | 3+ | Neutral | @pvergadia: Agent Lightning supports it |
| CrewAI | Agent framework | 2+ | Neutral | @pvergadia: Agent Lightning supports it |
| AutoGen | Agent framework | 2+ | Neutral | @pvergadia: Agent Lightning supports it |
| PGLite | Database | 1+ | Positive | @garrytan: replaced Supabase dependency |
| Daytona | Sandbox | 2+ | Positive | @muhashmii: one-command agent spawning |
| x402 | Payment protocol | 3+ | Positive | @igoryuzo: Agent Marketplace |
12. Notable Voices¶
-
@garrytan — Three high-engagement tweets (scores 1105.1, 998.4, 163.9) across GBrain v0.8.0 launch, poolside voice agent coding, and OpenClaw/Hermes evangelism. The day's most active high-signal voice. Verified.
-
@elvissun — Score 4315.4 on the harness debugging case study, now in its 5th day of circulation with 744 bookmarks. The week's most durable single artifact. Verified.
-
@Teknium — Nous Research co-founder (score 645.8) promoting Hermes Agent's integrated skill hub browsing. Authoritative source for the Hermes ecosystem. Verified.
-
@dani_avila7 — Security researcher (score 135.6) who found the credential isolation gap in Claude Managed Agents. High signal-to-noise ratio. Verified.
-
@IntuitMachine — Score 117.6 on a 22-part Meta-Harness thread dissecting arXiv:2603.28052v1. Deep technical analysis linking research to practice. Verified.
-
@diptanu — Infrastructure engineer (score 253.9) arguing for stateful sandboxes over ephemeral ones with concrete complexity reduction claims (70-80%). Generated substantive back-and-forth in replies. Verified.
-
@tom_doerr — Two strong contributions: harness engineering design guides (score 196.6) and Swift Agent Skills (score 130.6). Consistent high-quality curation. Verified.
13. Engagement Patterns¶
Highest Views-to-Likes Ratio¶
- @garrytan poolside tweet: 62,105 views, 266 likes (233:1) — massive algorithmic distribution driven by lifestyle/founder narrative
- @okx weekly highlights: 18,913 views, 64 likes (295:1) — exchange audience reach without deep engagement
- @PlutonAIHQ marketplace tweet: 24,223 views, 30 likes (807:1) — likely promotional amplification
Highest Bookmarks (Reference-Saving Intent)¶
- @elvissun: 744 bookmarks (harness debugging case study)
- @drummatick: 331 bookmarks (AI engineer curriculum)
- @googleaidevs: 202 bookmarks (Gemma 4 ADK demo)
- @garrytan: 159 bookmarks (GBrain v0.8.0 changelog)
- @iamlukethedev: 130 bookmarks (OpenClaw v2026.4.10)
- @garrytan: 120 bookmarks (poolside voice agent)
- @Teknium: 89 bookmarks (Hermes skills browse)
Most Quoted¶
Highest Reply Counts¶
- @garrytan poolside coding: 50 replies — lifestyle-meets-tech debate
- @garrytan GBrain launch: 33 replies — setup help and feature questions
Engagement Mismatches¶
- High views + low bookmarks: @PlutonAIHQ (24,223 views, 1 bookmark) — strong promotional distribution, no reference value
- High bookmarks + low views: @drummatick (331 bookmarks, 7,461 views) — niche but extremely high-value audience
- High retweets + low bookmarks: @n__deborah (47 retweets, 0 bookmarks) — amplification without depth
14. Stats¶
| Metric | Value |
|---|---|
| Total tweets | 1024 |
| Original tweets (non-RT) | 1024 |
| Retweets | 0 |
| Tweets with replies_data | 23 |
| Tweets with quoted tweets | 103 |
| Tweets with URLs | 188 |
| Top score | 4315.4 |
| Median score | 2.5 |
| Unique authors | 844 |
| Total views (sum) | 609,146 |