Twitter AI Agent - 2026-05-08¶
1. What People Are Talking About¶
1.1 Google’s AlphaEvolve Turns the Coding-Agent Story Into Measured Production Impact 🡕¶
The strongest AI-agent signal today comes from a large company publishing concrete results rather than demos. The post matters because it shows an agent being judged by downstream operational outcomes, not by benchmark screenshots.
@Google said AlphaEvolve is now being used across Google’s infrastructure and science workflows. In the same thread, Google claimed a 30% reduction in variant-detection errors for DeepConsensus in genomics, an improvement in feasible solutions for power-flow problems from 14% to more than 88%, a 5% gain across 20 disaster-risk categories, and a TPU circuit design “so counterintuitive yet efficient” that it was integrated into next-generation silicon.
Discussion insight: The replies do not revolve around prompt tricks or workflow aesthetics. They revolve around whether these are the kinds of numbers that justify coding agents in regulated or capital-intensive systems. That is a more mature standard than “it wrote code for me.”
Comparison to prior day: May 7 centered on agent operating systems, orchestration, and architecture. May 8 adds the missing proof point: a coding agent tied directly to infrastructure, science, and hardware outcomes.
1.2 The Interface Is Getting Simpler Even as Context Engineering Gets More Important 🡕¶
The day’s most coherent design argument is that the best coding-agent surface is still a conversation, but the systems behind that conversation are getting more sophisticated.
@thdxr argued that the “fundamental workflow” of a coding agent is still “you start a chat and then you talk to it,” while other tools invent fancy workflows most users will not actually adopt. In a companion post, he said his own use of OpenCode jumped without any fancy skills or workflow changes, just better day-to-day interaction with the vanilla agent.
That simplicity-at-the-surface argument sits next to a deeper engineering story. @amitiitbhu linked a long “Context Engineering” explainer defining the field as designing the entire information environment around an LLM, and @deepfates argued that modern prompting is increasingly about knowing exact domain vocabulary, not just yelling instructions at a model.
Discussion insight: Replies to thdxr reinforce the split. Some users still want ticket-driven, structured planning flows before implementation, but others explicitly say they forgot custom commands and defaulted back to chat. The emerging synthesis is straightforward: keep the UI plain, but put the complexity into context assembly, retrieval, validation, and long-session reliability.
Comparison to prior day: May 7 framed harness engineering as first principles. May 8 sharpens that into a practical product lesson: users want a plain chat loop, while the real leverage hides in context engineering underneath it.
1.3 Marketplaces and Galleries Are Becoming the New Agent Distribution Layer 🡕¶
Agent discourse is no longer just about model capability. It is increasingly about where agents are discovered, how they are packaged, and which marketplaces control access to distribution.
@ycombinator launched Standout as an “agentic hiring marketplace,” and YC’s launch page says the service has already done 100 introductions, represents 10,000+ builders, and works with 60+ startups. On the enterprise side, @googlecloud announced that Gemini Enterprise’s Agent Gallery now integrates an Agent Marketplace so teams can mix Google-built, internal, and partner agents in one surface.

Comparison to prior day: May 7 already showed skill ecosystems spreading across platforms. May 8 adds a more explicit commercial layer: marketplaces are becoming first-class product surfaces, not just community appendages.
1.4 Security, Trust, and Open-Source Infra Are Rising Together 🡕¶
The open-source leaderboard and the security discussion are telling a similar story: agent infrastructure is expanding quickly, but teams are increasingly worried about how autonomous systems are verified and controlled.
@sharbel posted a “fastest growing GitHub repos this week” graphic dominated by agent and coding-agent infrastructure, including TradingAgents, ruflo, mattpocock/skills, jcode, and openai/symphony.
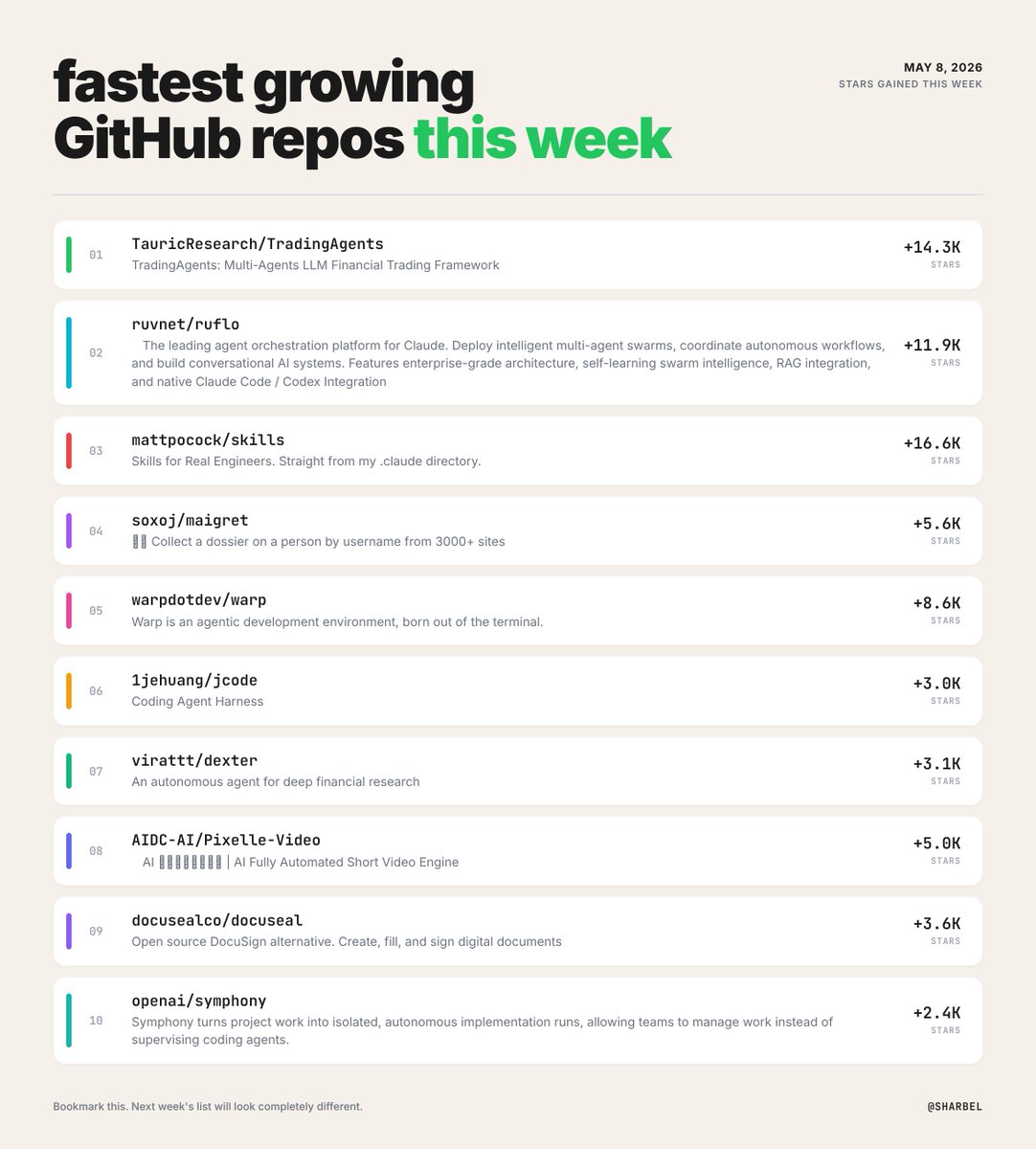
At the same time, @NEARProtocol launched AttackBench as an open-source benchmark for real-world AI-agent security, and @saidinfra said that identity and trust infrastructure for agents is “no longer a side conversation,” citing 3,000+ verified agents, economic security, Merkle-anchored behavior proofs, x402 payments, and cross-chain agent-to-agent messaging.
Discussion insight: One sharp reply to the repo leaderboard joked that many agent repos are just different ways of saying “please keep going after the first tool call fails.” That skepticism matters. Open-source growth is real, but buyers are increasingly asking for resilience, trust, and verifiable behavior before they care about another orchestration abstraction.
Comparison to prior day: May 7 focused on enterprise runtime governance and multi-agent architecture. May 8 pairs that governance story with visible open-source acceleration and explicit security benchmarking.
2. What Frustrates People¶
Workflow Theater and Command Sprawl¶
The most repeated UX complaint is that too many agent products are inventing extra workflow steps users do not retain. @thdxr said vendors keep “make[ing] up a new workflow and tell[ing] you it’s more effective,” while replies admitted people often forget which command does what and drift back to plain chat. Severity: High. The workaround today is to keep the front-end interaction simple and push sophistication into the harness behind the scenes.
Local Agents Still Hit Hardware and Latency Ceilings¶
@andrewchen offered one of the most concrete pain reports in the dataset: local 120B-class models are slow without serious hardware, open-weight models remain behind frontier cloud systems, and interactive use starts to break down below roughly 30-50 tokens per second. Severity: Medium. People cope by reserving local agents for asynchronous summarization, analysis, and long-running background work rather than primary interactive coding.
Trust, Verification, and Security Are Still Immature¶
The existence of AttackBench is itself evidence of pain: teams do not trust current security checklists to reflect real attacker behavior. Replies under that thread argued that agents trusting unverified data is the core problem, while @saidinfra is explicitly building identity, proofs, and economic security around agent behavior. Severity: High. The coping strategy today is layering benchmarks, verification, and trust infrastructure on top of autonomous systems that are otherwise ready to ship.
3. What People Wish Existed¶
Persistent Memory for Long-Horizon Agent Work¶
Posts about local and terminal agents repeatedly point toward the same desire: memory that survives sessions and compounds context instead of resetting every time the tool restarts. @ICPandaDAO framed Anda Bot around a “living memory graph,” while @koushik77 emphasized long-running, multi-tab, multi-agent workflows in KISS Sorcar. Opportunity: direct.
Model-Portable Agent Stacks¶
The appetite for portability is explicit. @jaenanft pushed Swarms as “1500 models, one codebase,” and KISS Sorcar advertises support for both Claude Code and OpenAI Codex. Builders want agent logic that survives model churn without a rewrite every time the provider landscape shifts. Opportunity: direct.
Trust and Identity Rails for Agent-to-Agent Commerce¶
The trust problem appears in several forms: AttackBench for security, SAID for verified agents and proof of behavior, and marketplace/infrastructure posts that assume agents will transact with each other. What people wish existed is a dependable identity, reputation, and payment layer that makes autonomous cooperation safe enough to automate. Opportunity: competitive.
Better Discovery and Routing Across Large Agent Catalogs¶
Agent Gallery, Standout, Swarms Marketplace tagging, and the repo-growth leaderboard all point to the same bottleneck: there are more agents, skills, and frameworks than any user can evaluate manually. The missing layer is reliable discovery and routing, so agents and humans can find the right capability without sifting through noise. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| AlphaEvolve | Coding / optimization agent | (+) | Demonstrated gains in genomics, power-flow optimization, disaster prediction, and TPU design | Proprietary internal system with no external access path in today’s evidence |
| Context engineering | Agent design method | (+) | Improves reliability by controlling the information, examples, and vocabulary the model sees | Hard to make visible to end users; easy to overcomplicate in product form |
| OpenClaw + Hermes local stack | Local agent runtime | (+/-) | Strong for learning, experimentation, and async summarization on owned hardware | Still slower and weaker than frontier cloud models for interactive work |
| KISS Sorcar | Local AI assistant / IDE | (+) | Local, open-source, parallel-agent workflow with worktree isolation, browser support, and Claude/Codex compatibility | Early project with limited production references beyond creator claims and benchmarks |
| Agent Gallery | Enterprise distribution surface | (+) | Unified place to discover Google, partner, and internal agents inside Gemini Enterprise | Tied to Gemini Enterprise rather than a broad cross-platform market |
| AttackBench | Security benchmark | (+) | Reframes agent security around real-world attacks instead of static checklists | Measures resilience but does not itself solve runtime trust or identity |
| Swarms portability layer | Agent framework | (+) | Promises multi-provider portability across 1500+ models without rewriting agent logic | More abstraction can mean more complexity unless teams truly need the portability |
| SAID trust stack | Agent identity / payments infra | (+) | Verified agents, behavior proofs, x402 payments, and cross-chain messaging speak directly to trust gaps | Early ecosystem infrastructure, not yet a mainstream end-user workflow |
Summary: The landscape is splitting in two. On one side are simple chat-first agent interfaces that win by feeling natural; on the other are deeper infrastructure layers for context, trust, portability, and long-running execution. Common workarounds include pushing local agents toward async tasks, adding portability layers to avoid vendor lock-in, and wrapping autonomous behavior in benchmarks, proofs, or marketplaces so teams can trust what is being automated.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Standout | Alexis Aftalion and Witold de La Chapelle | Agentic hiring marketplace where talent and companies each get an agent that vets fit before making an intro | Hiring has become AI-spam-heavy and asymmetric for both founders and candidates | Autonomous matching agents, marketplace workflow | Shipped | YC launch, post |
| KISS Sorcar | @koushik77 / ksenxx |
Local AI assistant and IDE across VS Code, web, and mobile with parallel agents and worktree isolation | Teams want a local, open-source assistant for long-running coding and research work | Python, KISS Agent Framework, Chromium, Playwright | Shipped | repo, post |
| AttackBench | NEAR AI + FailSafe | Open-source benchmark for real-world AI-agent security | Static security checklists do not reflect adaptive attacks | Security benchmark harness | Beta | post |
| Anda Bot | Anda Bot / @ICPandaDAO | Open-source Rust terminal agent with a persistent memory graph | Session resets and short-term memory loss break long-horizon work | Rust, local-first terminal workflow, memory graph | Alpha | post |
| Agent Gallery | @googlecloud | Searchable enterprise catalog for Google, partner, and internal agents | Agent discovery and rollout is fragmented across teams and vendors | Gemini Enterprise, integrated marketplace | Shipped | post |
Standout is the clearest vertical product in the table: it uses agents to filter hiring noise rather than trying to be a general-purpose “AI agent marketplace.” That makes it a strong example of agents monetizing a narrow operational wedge.
KISS Sorcar and Anda Bot show the opposite build pattern: local-first agents that optimize for persistence, portability, and terminal-native workflows rather than enterprise distribution. AttackBench and Agent Gallery round out the picture by tackling the surrounding infrastructure—trust on one side and discovery on the other.
6. New and Notable¶
Open-source repo growth is clustering around orchestration, skills, and autonomous implementation¶
The sharbel leaderboard is notable on its own, but the repo metadata sharpens it further: TradingAgents is at about 71.9K stars, ruflo at about 47.0K, and mattpocock/skills at about 66.8K. That concentration suggests builders are converging on three problems at once: orchestration, reusable skill packaging, and autonomous implementation workflows. (source post)
Standout shows that agent marketplaces can monetize a focused vertical quickly¶
YC’s launch page says Standout has already done 100 introductions, represents 10,000+ builders, and works with 60+ startups. That is notable because it is not a generic “agent economy” thesis; it is a focused workflow with visible early traction.
7. Where the Opportunities Are¶
[+++] Trust, identity, and security layers for autonomous agents — AttackBench, SAID, and the broader trust discourse all point at the same bottleneck: autonomy is advancing faster than verification. This is the strongest opportunity because the pain is explicit and the current workarounds are infrastructure-heavy.
[++] Simple chat-first UX backed by deep context engineering — thdxr’s posts show users bouncing back toward plain conversation even as context engineering becomes more important behind the scenes. Products that keep the front end simple while making the back end smarter look well aligned with the day’s evidence.
[++] Local-first persistent work agents — KISS Sorcar, Anda Bot, and andrewchen’s home-lab notes all describe a real appetite for agents that remember, survive long sessions, and run on owned hardware. The current limitation is performance, not demand.
[+] Agent discovery and marketplace routing — Standout, Agent Gallery, and Swarms-style listing/tagging all show the same pattern: the catalog is growing faster than discovery quality. Better routing, filtering, and trust-aware discovery remain underbuilt.
8. Takeaways¶
- The best AI-agent story today is measured operational impact, not better demos. Google’s AlphaEvolve thread gave concrete numbers across genomics, power grids, disaster prediction, and TPU design, which is a materially stronger signal than benchmark screenshots. (source)
- Users still want a simple conversational surface, even as the real leverage moves into context engineering. thdxr’s “just talk to it” argument and the context-engineering discussion are not contradictory—they describe a plain UI hiding deeper orchestration and retrieval work underneath. (workflow, context engineering)
- Memory, trust, and discovery are becoming primary competitive surfaces for agent products. Anda Bot, AttackBench, SAID, Agent Gallery, and Standout all focus on what surrounds model output rather than the model alone. (memory, security, distribution)