Twitter AI Agent - 2026-05-17¶
1. What People Are Talking About¶
1.1 Harness engineering turns into curriculum, operating playbooks, and cost accounting 🡕¶
Harness engineering stayed the strongest cluster, but the evidence moved further from abstract architecture talk and closer to repeatable operating practice. The highest-signal posts were not new benchmark claims; they were a public course, a prototype-to-production recipe for specialist agents, a detailed harness-to-framework mapping, and first-hand cost disclosures. At least five substantive items supported the theme, and several of them were explicitly about making long-running agents observable, governable, and affordable.
@_vmlops shared (1,350 likes, 6 replies, 73,602 views, 2,216 bookmarks) the Learn Harness Engineering course, calling it the best place on the internet to learn the topic. The site says the course teaches environment design, state management, verification, and observability for Codex- and Claude Code-style agents, and the screenshot matters because it shows a lecture list built around failure modes such as continuity loss, premature victory, and missing observability rather than generic prompting advice.

@shannholmberg argued (148 likes, 14 replies, 12,007 views, 218 bookmarks) that production Hermes specialists should be grown inside a main orchestrator first, run 4-10 times, corrected until clean, then deployed as dedicated Dockerized agents. The image added the missing operational detail: prototype, iterate, optional Claude Code or Cursor tightening, then port the resulting skills and scripts into a scoped production agent with its own credentials and memory.

@FUCORY said (117 likes, 6 replies, 14,762 views, 118 bookmarks) Bun's rewrite is one of the best examples of harness engineering in the wild. The attached diagram was the substantive part: it mapped Bun rewrite components to Smithers primitives including task graphs, worktrees, schemas, retries, SQLite outputs, fork/replay, and diff tooling, while the replies added two concrete harness ideas rarely named in broader discourse — a lifetime classifier for memory handling and explicit backpressure design.
@valentinmihov reported (14 likes, 5 replies, 947 views, 7 bookmarks) that his team harness combined a Multica kanban board, Hermes running on Codex, a Hindsight memory system, internal monitoring, OAuth2 SSO, VPN-only ops access, and Git-managed infrastructure. The screenshot turned that into a real operating budget: roughly 600 million tokens and about $3,000 of API spend, versus his estimate of two months of infra work.
@vipulgupta2048 traced (12 likes, 4 replies, 581 views, 6 bookmarks) why a simple "hi" in a coding agent can cost about eight cents, saying the expensive part is not the prompt but the cached 27,000-token harness payload riding along with every request. His screenshot and thread break the cost into cache writes, cache reads, tool schemas, CLAUDE.md, skills, memory subsystems, and startup calls, which made harness economics feel closer to cloud-infrastructure billing than chat pricing.
Discussion insight: The most useful pushback came from people who already run these systems. One reply under @shannholmberg warned that 4-10 controlled runs can overfit to the harness before messy production data arrives, while replies to @_vmlops kept stressing that knowing the theory is different from applying it in production. The day was bullish on harnesses, but not casual about the work involved.
Comparison to prior day: On May 16, harness talk centered on observability papers, framework mappings, and cost disclosures. On May 17, the same conversation became more operational: courses, deployment recipes, cost tracing, and explicit production loops.
1.2 Skills and memory are becoming the real agent control surface 🡕¶
A second cluster treated agent capability less as model choice and more as a packaged combination of skills, memory layers, hooks, and runtime integrations. Hermes sat near the center of that cluster, but the broader signal was bigger than one runtime: people were circulating architecture maps, self-evolving skill systems, subscription-linked capabilities, and official vendor skill packs.
@akshay_pachaar wrote (75 likes, 13 replies, 6,471 views, 79 bookmarks) that Hermes's most powerful feature is not chat but self-evolving skills: the agent solves a hard problem, saves the working procedure as a SKILL.md, and reuses it next session instead of rediscovering the workflow. The crucial nuance was in the same thread: Hermes also needs a Curator process to merge overlapping skills and archive stale ones, while a reply noted that built-in memory can still be inconsistent across long sessions.
@Teknium announced (330 likes, 54 replies, 39,165 views, 43 bookmarks) that SuperGrok and X Premium+ subscriptions now work directly inside Hermes Agent. The quoted Nous Research post plus the replies made the concrete value clear: Hermes users can inherit Grok access along with X Search, image generation, video generation, and voice-capable flows through the OAuth path, pushing the runtime closer to a capability hub than an API-key-only shell.
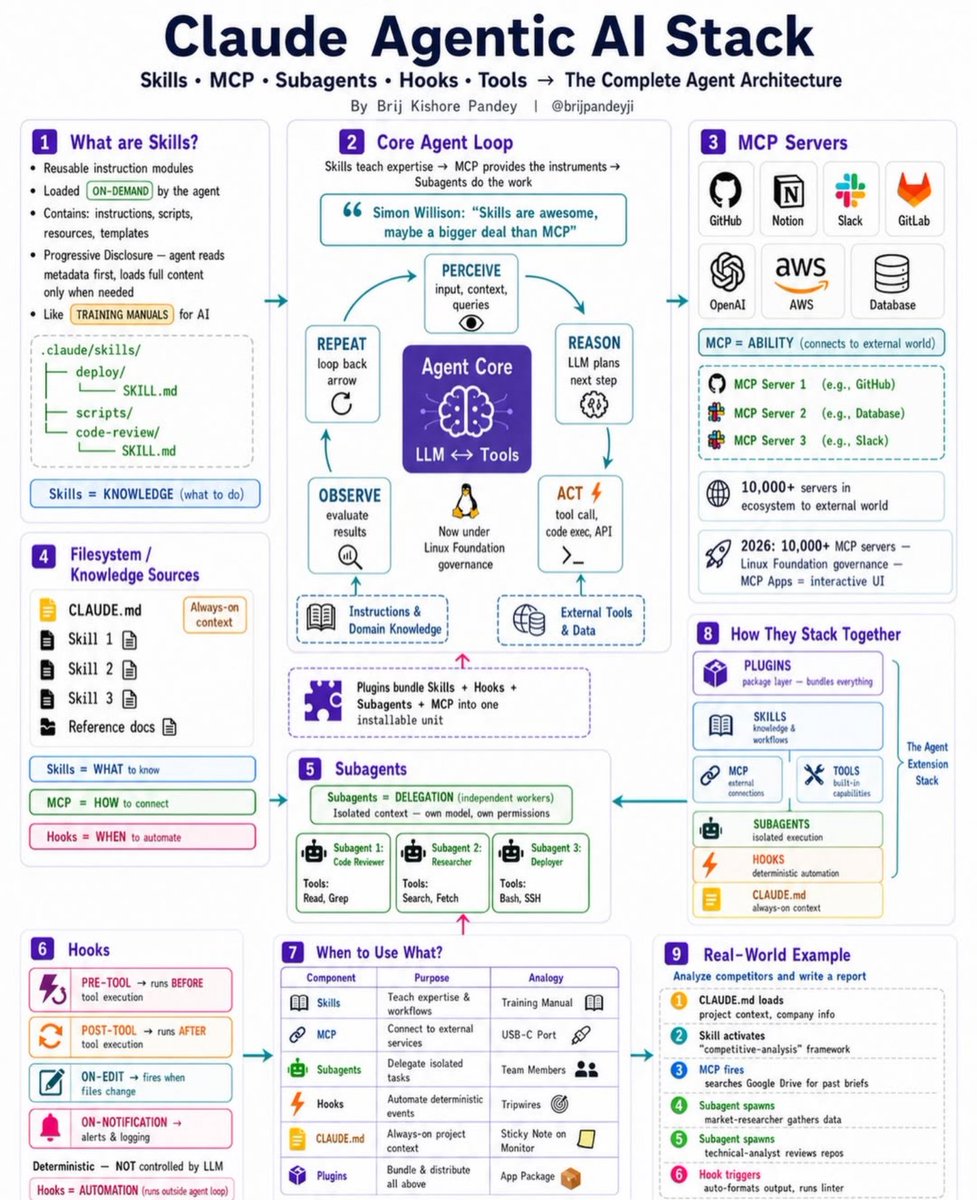
@PythonDvz framed (21 likes, 2 replies, 988 views, 18 bookmarks) the modern Claude stack as skills, MCP, subagents, hooks, tools, and project context surrounding the model. The architecture image is what made the post worth keeping: it shows those control surfaces as the actual working stack and gives a crisp public snapshot of where many builders now think the leverage sits.
@seelffff claimed (45 likes, 4 replies, 2,740 views, 25 bookmarks) Google now has an official agent-skills repo installable with one command and listing BigQuery, Firebase, Cloud Run, GKE, Cloud SQL, Gemini API, AlloyDB, plus security, reliability, and cost-optimization skills. Even at modest engagement, it fit the same pattern as the day's other posts: stop rewriting context by hand and install packaged capability instead.
Discussion insight: The tension inside this theme was maintenance. @akshay_pachaar explicitly warned that agent-created skills pile up without curation, and the replies called out memory inconsistency across long sessions. The community wants procedural memory, but it also knows that uncontrolled memory and skill growth create a new cleanup problem.
Comparison to prior day: May 16 emphasized operator consoles and provider-linked runtime surfaces. May 17 kept that momentum but pushed deeper into packaged skills, procedural memory, and official skill libraries as the preferred way to extend agents.
1.3 Vertical agents get more concrete in finance, phones, and security 🡕¶
The third clear pattern was verticalization. Instead of generic "personal AI" promises, the strongest builder examples were domain-shaped: document-heavy finance work, a consumer-spend analytics agent, a rooted Android phone agent, and a browser-based pentesting system. The common thread was not novelty for its own sake; it was taking an existing human workflow and making the agent legible inside it.
@jerryjliu0 said (89 likes, 8 replies, 6,117 views, 128 bookmarks) finance agents over documents split into two buckets: repetitive back-office extraction workflows such as invoice processing, KYC, and loan origination, and front-office research agents for diligence and equity work. The image sharpened the distinction, and the replies made the operational constraint explicit: in KYC and loan workflows, silent extraction errors, cross-document reconciliation, and auditability are more dangerous than a merely incomplete answer.

@FundamentEdge demoed (79 likes, 6,510 views, 133 bookmarks) a consumer-spend tracking agent that modernizes Joseph Ellis's spending-power framework with newer data inputs and a monitoring dashboard. The first screenshot is the key evidence: it shows weighted macro buckets and a composite spending-power YoY reading of -0.93%, which turns an otherwise abstract "finance agent" claim into a concrete analyst workflow.

@OliverBaumgart open-sourced (7 likes, 1 reply, 456 views, 9 bookmarks) PocketDaemon, which its README describes as an experimental Android-native AI phone agent built with Flutter plus Android/Kotlin services, with local memory, scheduled tasks, phone tools, and an optional Magisk-based privileged install path. In a different security-heavy corner of the feed, @tom_doerr shared (2 likes, 132 views) Pentest Copilot, whose README describes a browser-based AI pentesting agent with Burp integration, browser automation, VPN handling, and background subagent parallelism.
Discussion insight: Finance replies were the best source of skepticism here. Under @jerryjliu0, practitioners kept saying the hard part is not extracting a field but knowing when it is silently wrong and reconciling inconsistent documents before a human signs off. The security angle added a second cautionary note: @Thionne_WTZ used a Hermes deep-dive to warn that fake "free Claude Code" repos were distributing malware, which is a reminder that agentic tooling is also being pointed at supply-chain validation.
Comparison to prior day: May 16 already showed finance as a hot vertical through repo-growth lists and trading stacks. May 17 added more grounded workflow evidence — document pipelines, dashboards, phone-native agents, and security tools — which made the builder mix look broader and more operational.
2. What Frustrates People¶
Harness overhead is still expensive, stateful, and easy to underestimate¶
The clearest high-severity frustration was that reliable agents still come bundled with a large hidden operating cost. @vipulgupta2048 showed (12 likes, 4 replies, 581 views, 6 bookmarks) that a trivial greeting can inherit about eight cents of cost once cache writes, tool schemas, CLAUDE.md, skills, memory, and startup calls are included. @valentinmihov reported (14 likes, 5 replies, 947 views, 7 bookmarks) a team harness that took about 600 million tokens and roughly $3,000 to assemble, even though he still considered that cheaper than a comparable infra build. @shannholmberg described (148 likes, 14 replies, 12,007 views, 218 bookmarks) the repeated correction loop needed before a specialist agent is safe to deploy, and a reply warned that even those repetitions can overfit to a clean harness. Severity: High. The visible workaround is to stay inside long-lived sessions, keep harness context lean, and treat agents more like stateful services than cheap function calls. Worth building for because operators are already asking for better cost accounting, regression visibility, and harness discipline.
Document-heavy agents still fail where stakes are highest¶
High-stakes document workflows were one of the few places where replies consistently added harder constraints than the original post. @jerryjliu0 said (89 likes, 8 replies, 6,117 views, 128 bookmarks) finance agents need rigorous OCR, evaluation checks, and HITL review because even slight numeric mistakes can be catastrophic downstream. The replies made the failure modes sharper: one said extraction quality is not the same as auditability, another said operational finance quality is really about whether a human reviewer can be safely removed, and another said cross-document reconciliation is harder than any single-document parse. Severity: High. The workaround today is extra review, reconciliation logic, and explicit audit surfaces rather than full automation. Worth building for because the pain is practical, repeated by practitioners, and tied to workflows that already justify real spending.
Agent commerce still lacks trustworthy settlement and governance rails¶
The strongest governance frustration was not about discovery but about what happens after an agent takes an action. @sijlalhussain argued (14 likes, 2 replies, 327 views, 3 bookmarks) that trust in agentic commerce depends on identity verification, human oversight, transparency, data security, and accountable governance rather than brand messaging. Under @Unibase_AI's marketplace post (20 likes, 76 replies, 101 quotes, 31,917 views), the most substantive reply said composable skill calls still need escrow, deliverable hashes, and evaluator settlement before actual work resolves. Severity: High. The workaround is still manual approval, human override, or extra offchain coordination. Worth building for because launch activity is already ahead of the trust and settlement layer.
The agent supply chain is noisy enough that builders are warning each other in public¶
A smaller but concrete frustration was that the surrounding agent ecosystem now includes obvious security traps. @Thionne_WTZ warned (11 likes, 4 replies, 648 views) that a fake "free Claude Code" repo was part of an active malware campaign and said the visible GitHub source was a decoy while the ZIP installer carried the real risk. The linked rosie security docs describe the same class of problem in general terms: outside markdown and skills can carry hostile instructions, tag rewrites, or invisible-character injection, so lockfiles, comment stripping, and audit logs are treated as necessary defenses. Severity: Medium. The workaround is to favor official channels, pinned refs, and explicit review of third-party agent content. Worth building for because the warning is already operational, not theoretical.
3. What People Wish Existed¶
Durable procedural memory that does not rot¶
The clearest practical need was not generic memory, but memory for procedures that survives reuse without turning into clutter. @akshay_pachaar positioned (75 likes, 13 replies, 6,471 views, 79 bookmarks) Hermes skills as the place where an agent should store the exact sequence that fixed a problem, while also admitting that a Curator is required so the skill library does not collapse into overlap and dead weight. @tom_doerr shared (12 likes, 3 replies, 1,584 views, 15 bookmarks) miniclawd, whose README adds persistent memory, cron scheduling, and subagents to the same picture. Opportunity: direct. People do not just want recall; they want reusable, curated operational memory that compounds without becoming a maintenance burden.
Auditable document-context agents for regulated work¶
Finance threads made the unmet need unusually explicit. @jerryjliu0 described (89 likes, 8 replies, 6,117 views, 128 bookmarks) the current stack as OCR, evals, and HITL review, while the replies kept insisting that silent extraction errors and cross-document reconciliation are the real blockers. That reads less like a request for smarter models and more like a request for systems that can prove what was extracted, reconcile contradictions, and show a reviewer exactly where the evidence came from. Opportunity: direct. The need is operational, painful, and still only partially addressed by today's document pipelines.
Settlement, identity, and override layers for agent commerce¶
The commerce threads kept circling back to the same missing substrate: who the agent is, who can stop it, and how completed work gets verified. @sijlalhussain said (14 likes, 2 replies, 327 views, 3 bookmarks) trust depends on identity verification, human oversight, transparency, data security, and accountable governance. Under @Unibase_AI's post (20 likes, 76 replies, 101 quotes, 31,917 views), a reply added escrow, deliverable hashes, and evaluator settlement to that list. Opportunity: direct and competitive. The demand is concrete, but multiple marketplaces are already trying to fill the gap from the top down before the trust layer is settled.
Private, always-on personal agents with real-world permissions¶
A quieter but real need was for agents that live on personal devices and act on a schedule rather than in a browser tab. @OliverBaumgart released (7 likes, 1 reply, 456 views, 9 bookmarks) PocketDaemon, whose README describes a rooted Android phone agent with calls, local memory, scheduling, and phone tools. @tom_doerr highlighted miniclawd's persistent memory and scheduling from the desktop side. Opportunity: direct but niche. The need is practical for power users who want local control, but the current implementations still demand technical setup and explicit trust in device-level permissions.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Learn Harness Engineering | Course / reference | (+) | Public curriculum for environment design, state management, verification, and observability around coding agents | Educational material only; operators still have to translate it into their own stacks |
| Hermes Agent | Agent runtime | (+/-) | Self-evolving skills, persistent-agent workflows, Grok subscription access, specialist-agent deployment patterns | Users still report memory inconsistency over long sessions and skill-sprawl cleanup work |
| Claude Code + harness stack | Coding-agent runtime | (+/-) | Strong extensibility through skills, MCP, hooks, subagents, and project context | Hidden cache/bootstrap cost can dominate small interactions |
| Official skill repos (Google skills, Anthropic skills) | Skill library | (+) | One-command installation of packaged capabilities instead of hand-written context for cloud/services workflows | Public enthusiasm is ahead of clear usage data; skills still need curation and version control |
| softaworks/agent-toolkit | Skill marketplace / library | (+) | 1,844 GitHub stars, broad catalog of installable skills, agents, and commands for daily coding workflows | Adds another layer of third-party content that teams have to review and maintain |
| miniclawd | Personal agent runtime | (+) | Multi-LLM support, built-in tools, markdown skills, persistent memory, cron scheduling, and subagents in a lightweight TypeScript + Bun stack | Small project with limited public operator validation so far |
| PocketDaemon | Mobile / phone agent | (+/-) | Phone calls, live voice/chat, local memory, schedules, and device tools in an Android-native stack | Rooted Android + Magisk requirements make it research-grade rather than mass-market |
| TencentDB Agent Memory | Memory layer | (+) | Hierarchical local memory, token reduction, and explicit recall/drill-down paths with zero external API dependency by default | Plugin setup and layered storage add operational complexity |
| TradingAgents | Finance framework | (+/-) | Open-source multi-agent trading stack that combines analyst, sentiment, portfolio, and execution roles | Replies still question whether sentiment-heavy swarms outperform simpler systems consistently |
| Pentest Copilot | Security agent | (+/-) | Browser-based pentesting with Kali, Burp, browser automation, VPN handling, and background subagents | Constrained to authorized testing and heavier to operate than mainstream coding agents |
Overall, the day leaned positive on tools that externalize capability into skills, hooks, memory, and explicit runtimes rather than burying behavior in prompts. The dominant workaround pattern was to replace hand-written context with installable skill packs, replace stateless chat with scheduled or persistent agents, and replace vague prompting with harnesses that can be inspected and iterated. The competitive dynamic is shifting from "best model" toward "best surrounding system": better memory hygiene, lower harness tax, safer third-party skill ingestion, and more opinionated operator surfaces.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Consumer Spend Tracking Agent | @FundamentEdge | Builds a dashboard around consumer spending-power inputs and lets analysts adjust calibrations and correlations | Reduces the manual burden of maintaining a macro consumer-spend framework for investing work | Not disclosed; dashboard + macro and alternative-data pipeline | Alpha | tweet |
| miniclawd | FoundDream | Lightweight personal agent with multi-LLM support, tools, skills, persistent memory, cron jobs, and subagents | Gives power users a persistent, schedulable personal agent instead of a reactive chat window | TypeScript, Bun, Markdown skills, Telegram, Feishu | Beta | repo, tweet |
| PocketDaemon | @OliverBaumgart | Turns a rooted Android phone into a voice/chat agent that can answer calls, use phone tools, keep local memory, and schedule tasks | Brings agent behavior onto a personal device with local state and real-world phone permissions | Flutter, Android/Kotlin services, Magisk, Gemini/xAI providers | Alpha | repo, tweet |
| Pentest Copilot | Bugbase Security | Browser-based AI pentesting system that connects to a Kali box, runs tools, inspects results, and iterates with subagents | Automates repetitive penetration-testing workflows across browser, proxy, and shell surfaces | JavaScript, Docker, Kali, Burp Suite, browser automation, VPN support | Beta | repo, tweet |
The Consumer Spend Tracking Agent stood out because the screenshot showed a real analyst surface rather than a concept sketch. It was also one of the clearest examples of a common builder pattern on May 17: take an existing expert framework, connect fresher data sources, and automate the update loop instead of inventing a new workflow from scratch.
miniclawd and PocketDaemon pointed at the same broader direction from different ends. miniclawd packages persistent memory, scheduling, and subagents into a lightweight desktop/server-style assistant, while PocketDaemon pushes the same persistence idea onto a phone with calls, notes, schedules, and local device tools. The repeated trigger is continuity: builders want agents that remember, wake up on a timer, and act in a bounded environment.
Pentest Copilot showed the same pattern in security. Its README emphasizes autonomous command execution, Burp integration, browser automation, and background task parallelism, which makes it feel less like a chatbot for hackers and more like a workflow engine wrapped around a specialist environment.
6. New and Notable¶
GitHub formalizes the "agent supervisor" role¶
@_vmlops posted (33 likes, 3 replies, 1,810 views, 28 bookmarks) that GitHub has launched a GitHub Certified Agentic AI Developer credential in beta. The attached image is the core evidence: it names the certification directly and frames it around operating and governing agents in the software lifecycle rather than simply using an assistant, which makes the post notable as a labor-market and professionalization signal.

A Stanford paper pushes back on multi-agent defaultism¶
@rohanpaul_ai summarized (4 likes, 838 views, 6 bookmarks) a Stanford paper arguing that, under equal thinking-token budgets, a single strong model usually matches or beats multi-agent systems on multi-hop reasoning. That mattered because it gave the day a useful correction against fashionable orchestration: extra agents are not automatically better, and some visible gains may be test-time-compute gains in disguise.

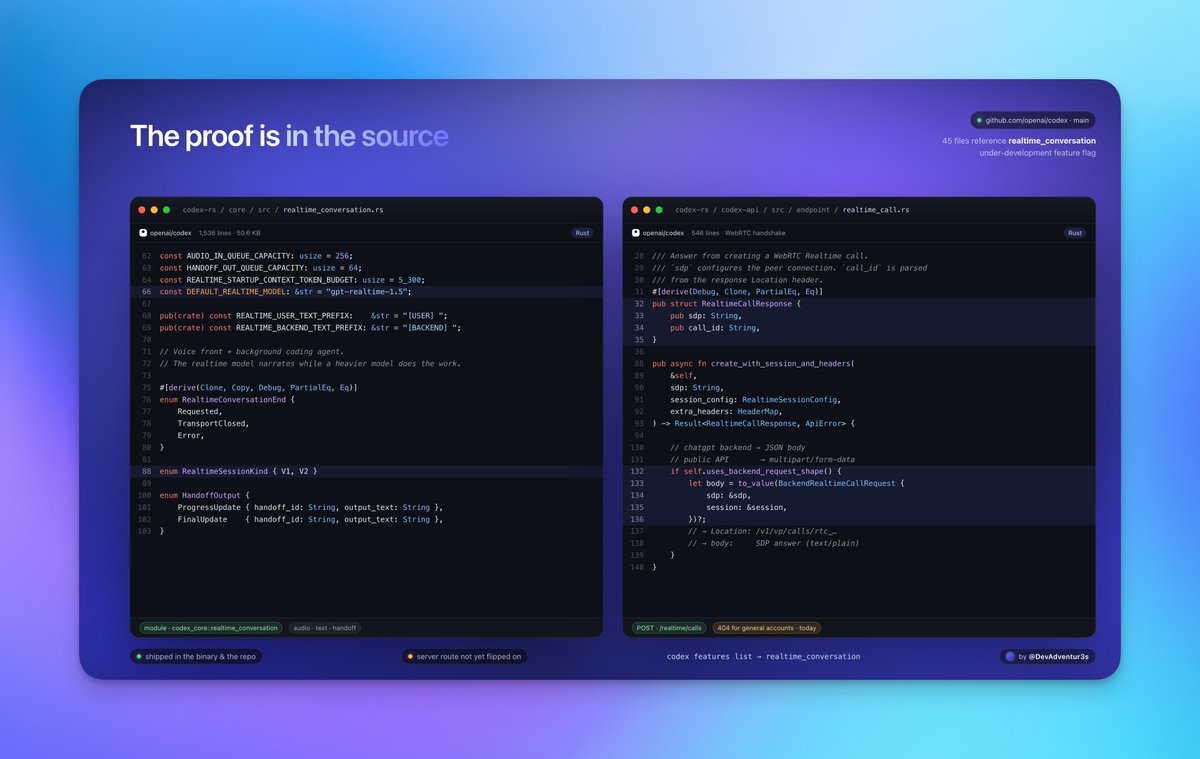
Codex may be absorbing realtime voice and background narration¶
@DevAdventur3s reported (99 likes, 12 replies, 7,010 views, 25 bookmarks) that OpenAI appears to be wiring realtime voice into Codex, with a background agent handling coding work while the interface narrates progress. The second screenshot is the key public evidence because it shows WebRTC, gpt-realtime-1.5, background-agent handoff, and progress hooks inside a Rust code path rather than just a speculative rumor.
7. Where the Opportunities Are¶
[+++] Harness cost and regression accounting — Section 1 and Section 2 point to the same gap from different sides: people can now describe how to build a harness, but they still struggle to price, inspect, and control it. @vipulgupta2048 turned "why did saying hi cost money" into a cache-and-bootstrap breakdown, while @valentinmihov published a full-stack cost disclosure and @shannholmberg described the iteration burden before deployment. Strong opportunity because the pain is repeated, expensive, and attached to existing operator behavior rather than future speculation.
[++] Auditable document agents for regulated operations — Finance builders are already trying to automate KYC, loan, and research workflows, but the replies around @jerryjliu0 kept stressing that silent extraction errors and reconciliation failures are what block real rollout. Moderate-to-strong opportunity because buyers are visible and the requirement is narrow enough to build against: evidence traceability, reviewer-facing audit surfaces, and contradiction handling across documents.
[++] Skill and memory lifecycle management — @akshay_pachaar wants procedural memory that compounds; the replies want it not to drift or pile up; miniclawd and official skill repos show the same packaging trend from another angle. Moderate opportunity because the ecosystem is clearly moving toward installable skills and persistent agents, but teams still need better curation, expiry, testing, and portability across runtimes.
[+] Trust and supply-chain assurance for agent ecosystems — Agent marketplaces are shipping faster than settlement logic, and security warnings are already surfacing around malicious "free Claude Code" clones. That makes identity, escrow, auditability, signed skill provenance, and safe third-party content ingestion an emerging but important opportunity, especially for teams operating in public marketplaces or shared skill registries.
8. Takeaways¶
- Harness engineering is no longer a niche research term on this topic; it is now being taught, operationalized, and costed. The strongest posts were a public course, a production recipe, and first-hand cost tracing rather than abstract model praise. (source)
- The winning control surface is shifting from prompt text to skills, memory, hooks, and MCP-style integrations. Hermes skill compounding, official vendor skill repos, and Claude architecture diagrams all pointed in the same direction. (source)
- Finance is one of the clearest real-world demand pockets, but only if agents can prove their work. The finance threads were full of warnings about OCR mistakes, silent bad extractions, and reconciliation failures, which means auditability is part of the product, not polish. (source)
- Persistent agents are spreading into concrete surfaces: dashboards, phones, and security tools. The day's builder examples included a consumer-spend dashboard, a rooted Android phone agent, and a browser-based pentesting system. (source)
- The field is still correcting its own hype in public. A Stanford paper challenged multi-agent defaultism, while marketplace and security threads kept reminding readers that extra agents, more skills, or more integrations do not remove the need for governance and trust. (source)