Twitter AI Agent - 2026-05-24¶
1. What People Are Talking About¶
1.1 Harness engineering became the shared language for agent systems 🡕¶
The strongest May 24 cluster treated harness engineering as the practical frame for shipping agents, not just a buzzword. Five retained items supported it: a high-engagement diagram that separated prompt/context/harness roles, a code-graph product, a self-hosted orchestration dashboard, a “smart path” browser harness example, and a benchmark thread showing harness design beating naive web-agent loops.
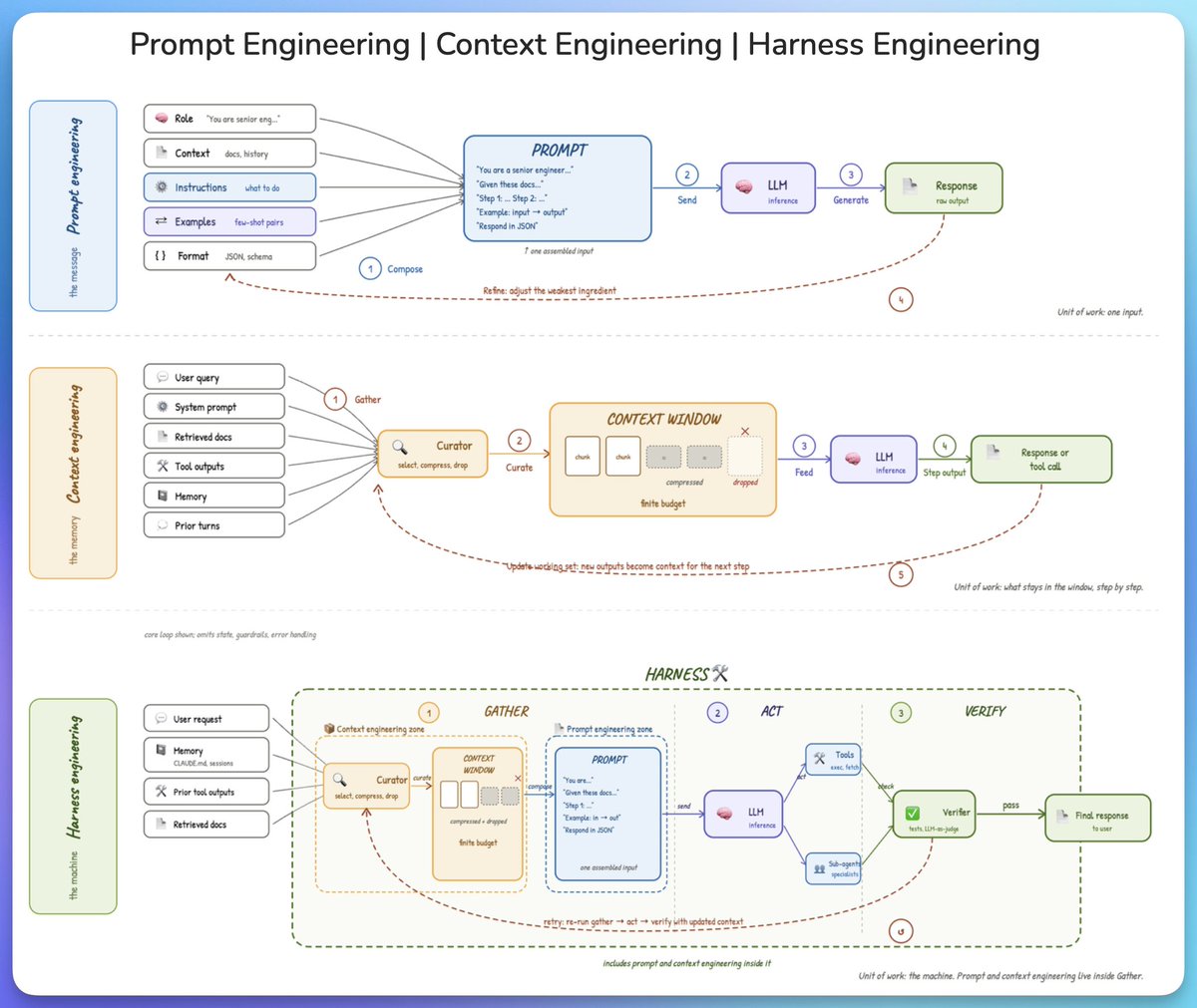
@akshay_pachaar argued (429 likes, 24 replies, 40,499 views, 657 bookmarks) that prompt engineering is the message, context engineering is the memory, and harness engineering is the machine wrapping gather/act/verify loops. The post mattered because it gave the day a compact vocabulary that other tweets reused almost verbatim.
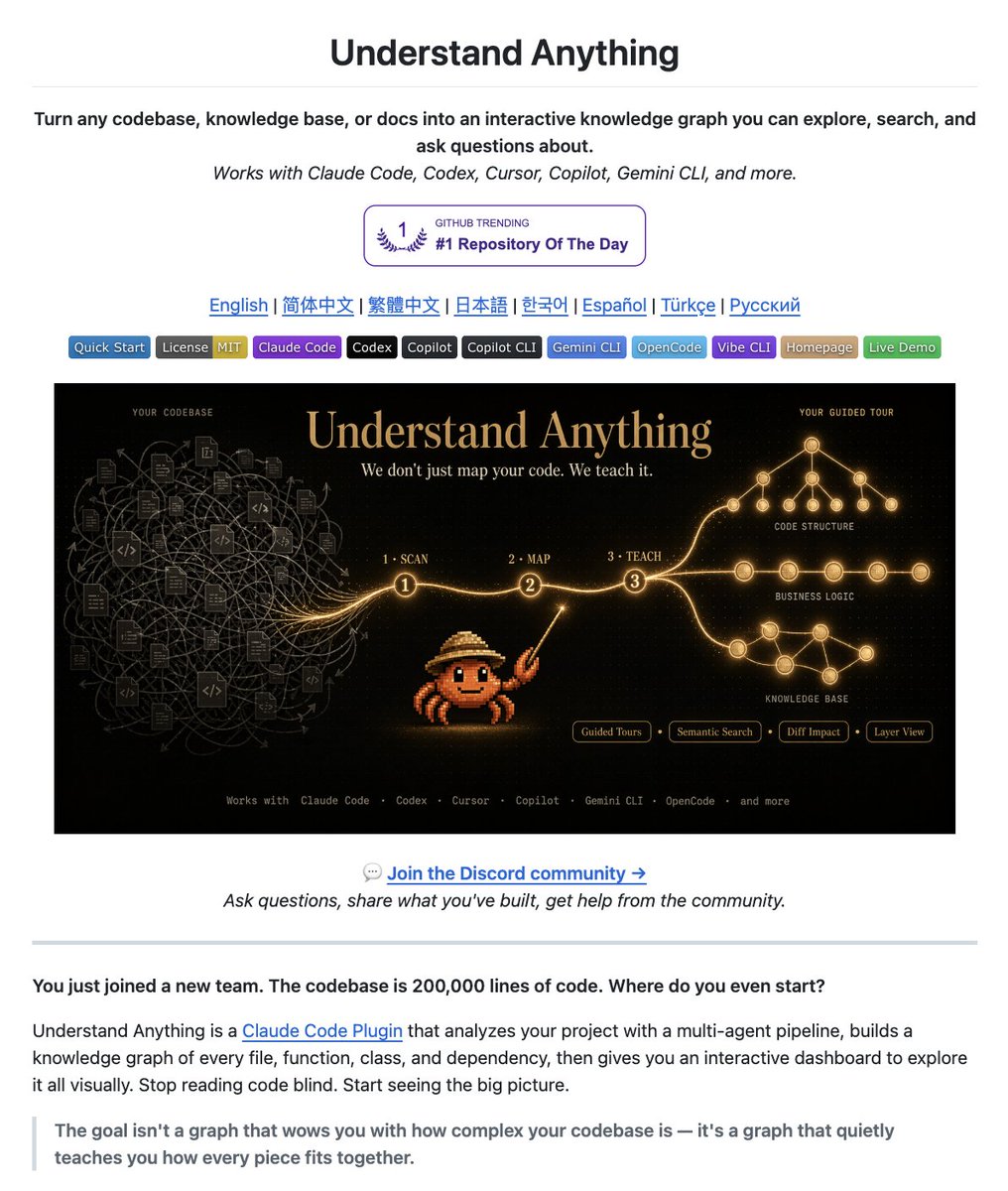
@Saboo_Shubham_ posted (117 likes, 18 replies, 7,918 views, 209 bookmarks) that Understand Anything turns a codebase into an interactive graph an agent can query. The site says it adds hierarchical drill-down, fuzzy and semantic search, domain mapping, guided tours, and support for 26+ file types; the most useful reply came from @SynabunAI, who warned that the graph is only as fresh as its last index.
@tom_doerr shared (87 likes, 5 replies, 4,474 views, 95 bookmarks) Mission Control, a self-hosted orchestration dashboard whose repo description says it dispatches tasks, tracks spend, and coordinates multi-agent workflows from one place. GitHub metadata showed a TypeScript codebase, SQLite in the topic tags, and 4,991 stars by the time of review.
@gregpr07 reported (71 likes, 8 replies, 4,860 views, 72 bookmarks) that Browser Harness abandoned a slow scrolling plan, reverse-engineered LinkedIn's API, and produced a CSV instead. The interesting reply was not applause but concern: @ManavGarkel asked how often a shortcut like that silently breaks things, which kept verification in the loop rather than treating autonomy as self-justifying.
Discussion insight: The praise was strongest when the harness was legible. Replies kept asking whether repo maps stay fresh, whether orchestration UX is good enough to live in, and whether “smart” shortcuts are verifiable instead of merely clever.
Comparison to prior day: May 23 pushed harness engineering from cost complaints into repo infrastructure. May 24 went broader: the term itself became shared vocabulary, and the artifacts around it were more installable, more visual, and more explicitly tied to production control.
1.2 Memory moved toward editable files, selective loading, and local checkpoints 🡕¶
The second major cluster was about refusing to stuff every repo, skill, and memory into the live context window. Five retained items supported it: an Obsidian-based cold-storage workflow, a Markdown-native skill memory layer, a layered local-memory stack for Hermes, plugin-installation fatigue, and repeated calls to keep active context lean.
@EXM7777 described (210 likes, 13 replies, 11,339 views, 292 bookmarks) using Obsidian as a memory layer for tools, MCPs, and frameworks that might matter later but should not stay loaded all the time. The clearest reply came from @Sean_CP_Founder, who said tool memory and runtime context need to be separate: cold storage for options, hot context for execution.
@GithubProjects highlighted (66 likes, 3 replies, 6,162 views, 74 bookmarks) Acontext as a skill memory layer that stores learnings as editable Markdown instead of opaque embeddings. The screenshot added concrete maturity signals beyond the tweet text: website and docs links, PyPI and npm packages, and passing core/API/CLI test badges.

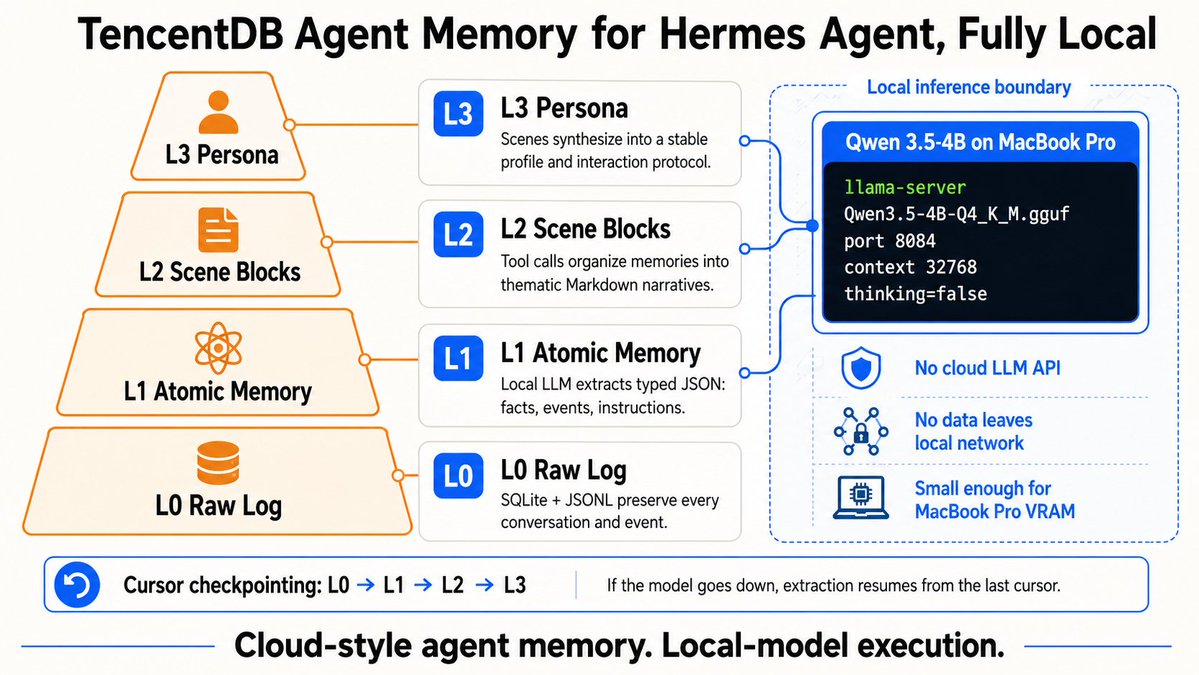
@Michaelzsguo documented (8 likes, 4 replies, 229 views, 9 bookmarks) a layered TencentDB Agent Memory setup for Hermes: L0 raw logs in SQLite and JSONL, L1 typed memories, L2 Markdown scene blocks, and L3 persona synthesis, all checkpointed so local processing can resume after failure. He also said Qwen 2.5-3B was too brittle for this pipeline, while Qwen 3.5-4B was the smallest local model that reliably handled both JSON extraction and tool use.
@trevin complained (30 likes, 4 replies, 2,470 views, 26 bookmarks) that Claude Code plugin and marketplace updates are painful enough that one maintainer was moving back to an install script and agent skill installer. That fit the wider pattern: memory and skills are being pushed out of magical marketplaces and into files, notes, ZIPs, and explicit install flows.
Discussion insight: The strongest consensus was not “add more memory.” It was “load less by default, keep the rest searchable, and make it editable.” The day’s memory posts repeatedly split active execution context from longer-lived archives and checkpoints.
Comparison to prior day: May 23 focused on typed memory architecture and human-visible control rooms. May 24 made the same idea more operational: Obsidian libraries, Markdown skill files, local checkpoints, and a retreat from plugin-heavy distribution.
1.3 Builders added trust surfaces, review gates, and work-layer mechanics around agents 🡕¶
The third cluster was less about raw model capability and more about the infrastructure around agent work: disputes, dashboards, builder visibility, review layers, and narrow business workflows. Four retained items supported it: a marketplace trust update, a voice-agent builder, an SDLC framework that wraps Claude Code in review gates, and a builder thread arguing that agent task markets need verifiable delivery and dispute resolution.
@wyckoffweb announced (61 likes, 22 replies, 2,962 views, 9 bookmarks) a Dispatch update that added disputes, locked funds during disputes, service packages, ready-made tasks, stronger profile signals, and a builder dashboard. The quoted earlier post made the motive explicit: users should always know who needs to act next, whether payment is locked, and whether work is ready for review.

@Muskanjain0401 built (102 likes, 13 replies, 3,534 views, 15 bookmarks) RingIt to turn a few industry questions into a business voice agent and dashboard in minutes. That was a smaller but cleaner signal than the bigger agent-economy threads because it named a plain business failure mode: most “call us” buttons still do nothing useful.
@me2resh launched (27 likes, 1 reply, 7,890 views, 8 bookmarks) ApexYard v2.0 as a multi-project SDLC framework for Claude Code with per-agent routing and 54 skills. The site filled in the operational point: automatic code review, launch-readiness checks, and one inbox for projects, PRs, and release work rather than a raw agent console.
@ekinoks_26 argued (102 likes, 90 replies, 375 views) that Rialo Builderthon teams were choosing carbon-credit verification, community reputation, and AI agent task markets with automated dispute resolution instead of DeFi clones. The thread mattered because it tied “agent economy” talk to concrete trust and verification problems, not just token rhetoric.
Discussion insight: The repeated design move was to add clarity around what happened, what was paid, what could be disputed, and what still needed review. Even the most promotional posts kept adding dashboards, packages, checkpoints, and reputation signals rather than asking users to trust the agent blindly.
Comparison to prior day: May 23 emphasized war rooms, panes, and notification surfaces for agent operators. May 24 pushed those ideas into the work layer itself: packages, disputes, payouts, launch gates, and vertical business flows.
2. What Frustrates People¶
Tool sprawl and context bloat¶
Severity: High. @EXM7777 wrote (210 likes, 13 replies, 11,339 views, 292 bookmarks) that the more skills, MCPs, and context people stack into Claude Code or Codex, the worse those tools get. @trevin added (30 likes, 4 replies, 2,470 views, 26 bookmarks) that plugin and marketplace updates are painful enough to abandon in favor of install scripts, while @Sean_CP_Founder said the fix is a searchable tool library outside the active agent. People are coping by keeping tools in Obsidian, ZIP exports, or install scripts and loading only task-specific pieces. Worth building for because the pain is operational, recurring, and already changing adoption behavior.
Repo context and agent memory still rot without structure¶
Severity: High. @Saboo_Shubham_ showed (117 likes, 18 replies, 7,918 views, 209 bookmarks) one answer in code graphs, but @SynabunAI warned that stale edges make agents confident about deleted code. @Michaelzsguo described a layered memory stack precisely because one undifferentiated store is not enough, and @GithubProjects promoted Acontext as editable skill memory instead of opaque embeddings. The workaround today is to split memory into layers, files, and checkpoints, but that means more architecture work for the builder. Worth building for because the alternative is either expensive re-reading or brittle stale state.
Autonomy still needs review, disputes, and visible control¶
Severity: High. @wyckoffweb added (61 likes, 22 replies, 2,962 views, 9 bookmarks) dispute handling and payment locks to Dispatch because agent work still needs a clear approval and remediation path. @gregpr07 celebrated Browser Harness finding a better route on its own, but a reply immediately asked how often a shortcut like that silently breaks things. @zostaff quoted Cursor's CEO saying 30% of Cursor pull requests are now shipped end-to-end by an agent, and the replies fixated on the management burden created by long-running autonomous work. Worth building for because the trust layer is not optional once agents start acting on their own.
3. What People Wish Existed¶
Minimal, task-specific skill loading with painless updates¶
This was a direct practical need. @EXM7777 wanted lean active context with the rest of the tool library searchable in Obsidian, while @trevin wanted a simpler install path than plugin-marketplace churn. The shape of the need is clear: a safe, searchable way to keep a lot of skills available without paying the runtime penalty of loading them all at once. Opportunity: direct.
Memory layers that stay editable, local, and recoverable¶
@GithubProjects promoted editable Markdown skill files, and @Michaelzsguo showed a layered local-memory stack with cursor checkpointing. Those two posts point to the same need from different angles: builders want memory that can survive failures, be inspected by humans, and fit the job instead of becoming a black box. Today there are partial answers, but the market is already crowded enough that freshness, local execution, and provenance matter. Opportunity: direct and competitive.
Work layers where agents can earn trust, not just output text¶
@wyckoffweb said Dispatch is trying to become a proper work layer where agents can get hired, complete funded tasks, and build reputation, and @ekinoks_26 pointed to AI task markets with verifiable delivery and automated dispute resolution as a first-wave builder use case. The missing piece is not another chat surface; it is a reliable interface for packages, disputes, status, payout, and review. Opportunity: direct.
Voice-agent builders that connect to real business systems¶
@Muskanjain0401 framed RingIt around a painfully ordinary broken workflow — nonfunctional business call buttons — and @tslaming described Tesla's target stack for phone agents in China. The need is practical rather than aspirational: people want faster setup, real integrations, and enough control that a voice agent can do work without turning into a liability. Opportunity: direct and competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Understand Anything | Code graph / context | (+/-) | Interactive knowledge graph, guided tours, semantic + fuzzy search, domain mapping across 26+ file types | Reply warned the graph is only as fresh as the last index |
| Mission Control | Orchestration dashboard | (+/-) | Self-hosted dashboard for dispatching tasks, tracking spend, and coordinating multi-agent workflows | Replies questioned debugging cost and compared orchestration UX unfavorably against other tools |
| Obsidian | External knowledge base | (+) | Keeps tools and MCPs searchable outside live context; sync and linked notes help reuse | Requires manual curation and periodic cleanup to stay useful |
| Acontext | Skill memory layer | (+) | Stores learnings as Markdown skill files, works across frameworks, packages shipped on PyPI and npm | Public evidence still looks early-stage: 0.1.x packages and a small Discord community in the screenshot |
| TencentDB Agent Memory | Layered memory system | (+) | L0-L3 memory stack, cursor checkpointing, local-model execution, no cloud API in the reviewed setup | Every layer above raw logs still depends on LLM extraction or synthesis; smaller Qwen 2.5-3B was too brittle |
| ApexYard | SDLC framework | (+) | Automatic review, launch-readiness checks, multi-project inbox, role routing, large skill library | Intentionally process-heavy; best fit for teams that want gates and discipline, not pure speed |
| Dispatch | Agent marketplace / work layer | (+/-) | Adds disputes, payment locks, packages, trust signals, and a builder dashboard | Still early by the author's own description, so trust and liquidity are not solved yet |
| InsForge | Agentic coding backend | (+/-) | One user reported lower token cost and fewer errors; repo positions itself as an all-in-one backend for agentic coding | Reply asked for same-task quality proof, so the savings claim still needs broader validation |
Overall sentiment skewed positive for file-based memory and self-hosted control, but mixed for anything that adds hidden complexity. The most common workaround was to keep cold knowledge outside the agent, load only the pieces needed for the current task, and put review or dispute gates around the output. Migration patterns were clear: prompt engineering to context/harness engineering, plugin marketplaces to explicit install scripts, and opaque memory stores to Markdown files or layered local pipelines. Competitive pressure is rising across the same narrow band of problems: memory freshness, orchestration visibility, and trustworthy execution.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Mission Control | @tom_doerr | Self-hosted dashboard for dispatching tasks, monitoring spend, and running multi-agent workflows | Teams want orchestration without handing control to a hosted vendor | TypeScript, Next.js 16, SQLite | Shipped | repo, post |
| RingIt | @Muskanjain0401 | Turns a few business questions into a configurable voice agent with a dashboard | Most business “call” buttons still do not produce a usable workflow | smallest_AI, voice agent flow, web dashboard | Beta | post |
| Dispatch | @wyckoffweb | Agent marketplace with disputes, packages, clearer profiles, and builder analytics | Paid agent work needs trust, review, and payout clarity | Arc testnet, USDC-powered marketplace, Codex-assisted build | Beta | site, post |
| ApexYard v2.0 | @me2resh | SDLC-as-code framework for Claude Code with role routing, review, and release checks | Solo founders and small teams lack review discipline for AI-built software | Shell, Markdown, hooks, Claude Code skills | Shipped | site, repo, post |
| VUE-TUI | @_hyf0 | Vue-powered terminal UI framework created while building a toy coding agent | Builders need agent UIs without writing terminal plumbing from scratch | Vue, Vite, TypeScript | Alpha | repo, post |
Dispatch stood out because its update was almost entirely about trust plumbing rather than model intelligence: disputes, locked payments, service packages, and builder dashboards. That matched the Rialo Builderthon thread, where the “agent economy” only looked credible when delivery, verification, and coordination were explicit rather than implied.
Mission Control and ApexYard showed the same pattern in developer tooling. The new products were not “another agent shell”; they were surfaces for spend visibility, code review, launch readiness, role routing, and project-level supervision around the agent.
RingIt and VUE-TUI pointed to a second builder pattern: narrow workflows ship faster than general-purpose agent platforms. One turns a business calling flow into a voice agent; the other turns a toy coding-agent experiment into reusable terminal UI infrastructure.
6. New and Notable¶
Cursor turned “teams of agents” into an internal production metric¶
@zostaff summarized (20 likes, 11 replies, 419 views, 13 bookmarks) a Michael Truell keynote with a concrete metric: 30% of Cursor pull requests are now shipped end-to-end by an agent, and enterprise customers moved from 15% to 75% AI-generated code in a year. That mattered because it was framed as an operating model — “engineers stop writing and start managing” — not a feature launch.
Tesla’s Shanghai voice-agent hiring post exposed a real enterprise stack¶
@tslaming reported (127 likes, 5 replies, 12,801 views, 6 bookmarks) that Tesla is hiring for an AI-powered phone customer service and sales agent in China. The post was unusually specific about the stack: streaming audio and barge-in, RAG and function calling, RLHF/DPO/GRPO plus LLM-as-judge, and WebRTC/SIP/IVR integration, with a target of autonomously resolving 80% of routine calls.
Webwright suggested harness design can move the ceiling more than the base model¶
@Marktechpost wrote (16 likes, 1 reply, 10,616 views, 3 bookmarks) that Microsoft Research’s terminal-native Webwright reaches 60.1% on Odysseys versus 33.5% for base GPT-5.4, and 86.7% on Online-Mind2Web. The most important part was not the raw number; it was the framing that reusable scripts and a simpler loop can beat heavier web-agent abstractions.
7. Where the Opportunities Are¶
[+++] Lean context and memory operating systems — The day’s strongest pain cluster was about tool sprawl, stale context, and memory that does not fit the job. Obsidian cold storage, Acontext Markdown skills, TencentDB’s layered checkpoints, and plugin-install fatigue all point to the same need: keep active context small while keeping everything else accessible and inspectable.
[++] Trust layers for paid agent work — Dispatch, Rialo Builderthon projects, and multiple “agent economy” posts all converged on disputes, reputation, verifiable delivery, and payout clarity. The opportunity is moderate-to-strong because the demand is explicit, but the space is already crowded with marketplace and token narratives.
[++] Supervision surfaces for long-running agents — Mission Control, ApexYard, and Cursor’s “teams era” metric all imply the same operational shift: humans are moving from line-by-line execution to review, routing, and oversight. Products that make that supervision legible should benefit even if the underlying model stack changes.
[+] Vertical voice agents with business-system integration — RingIt and Tesla’s hiring post show demand for voice agents that can actually connect to bookings, support flows, and telecom infrastructure. The signal is emerging rather than saturated, but the use case is concrete enough to matter.
8. Takeaways¶
- Harness engineering was the day’s default frame for explaining agent systems. Akshay Pachaar’s prompt/context/harness diagram was the most reused mental model, and supporting posts on code graphs, orchestration dashboards, and browser harnesses all mapped onto it. (source)
- Builders are actively pulling memory out of the live context window and into files or layers they can inspect. Obsidian cold storage, Acontext Markdown skill files, and TencentDB’s L0-L3 memory stack all pushed in that direction. (source)
- The winning agent products in this dataset added trust and review surfaces, not just more autonomy. Dispatch added disputes and locked funds, and ApexYard added review and launch gates around Claude Code workflows. (source)
- Enterprise agent adoption is getting described in operational metrics, not hype terms. Cursor’s reported 30% end-to-end PR number and Tesla’s detailed voice-agent hiring stack both treated agents as real production systems with measurable throughput and infrastructure requirements. (source)
- Real-world builder interest skewed toward verification, reputation, coordination, and customer service rather than generic chat wrappers. Rialo’s Builderthon thread, RingIt, and the voice-agent stack discussion all pointed toward narrow workflows with clearer business outcomes. (source)