Twitter AI Agent - 2026-05-27¶
1. What People Are Talking About¶
1.1 Skills became editor-native assets with their own training and execution loops 🡕¶
The clearest May 27 shift was that skills stopped being discussed mainly as marketplace inventory and started showing up as first-class product surfaces inside coding environments. At least four strong items supported this: one on training skills, one on shipping them in an editor, one on isolating them in sub-agents, and one on evaluating them across a much larger benchmark surface.
@daniel_mac8 showed (352 likes, 16 replies, 25,274 views, 432 bookmarks) how he is pulling fresh harness-engineering papers directly into Codex with /goal mode instead of just bookmarking them. His example centers on SkillOpt and the SkillOpt repo, which frame SKILL.md-style instructions as trainable external state with bounded text edits and held-out validation, including reported GPT-5.5 gains of +24.8 points inside a Codex harness and +19.1 inside Claude Code.
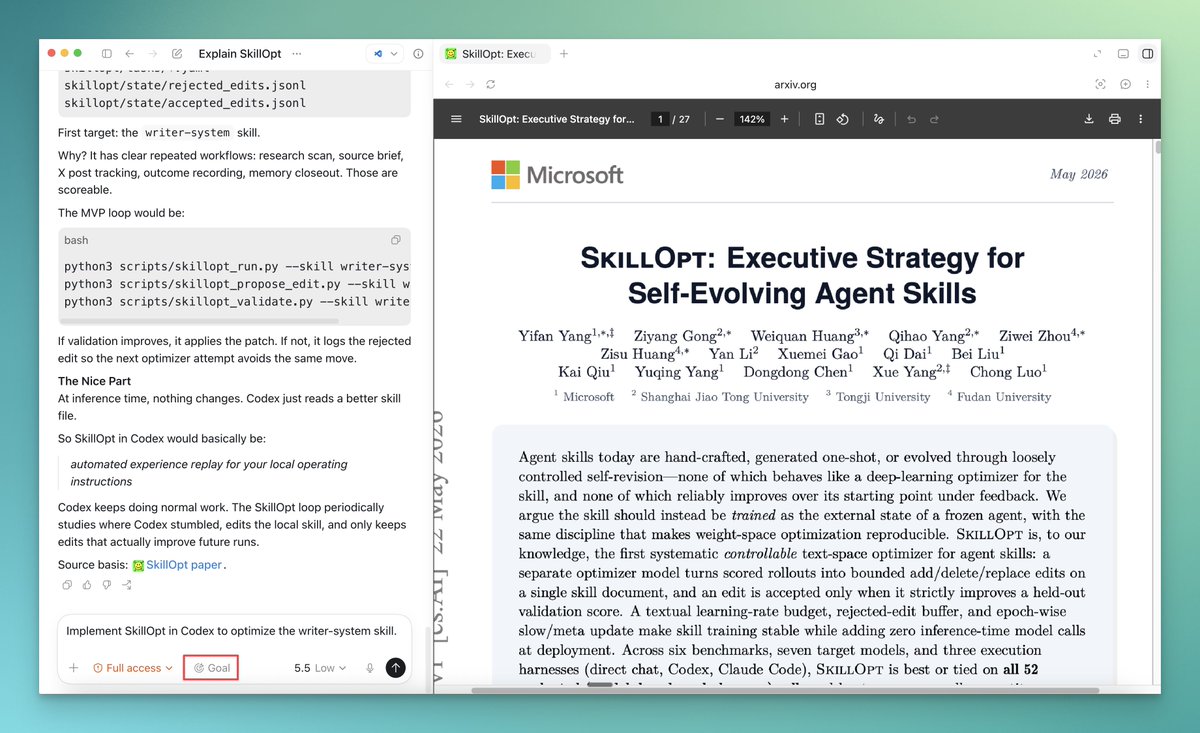
@zeddotdev announced (203 likes, 7 replies, 6,296 views) that Zed 1.4.2 now supports skills as reusable instructions for its agent. The follow-up thread matters more than the headline: Zed says skills can live globally or per project, can be discoverable or explicit-only, and replace the older Rules Library, while the public Zed skills docs confirm that the unit is a named folder with SKILL.md, optional references, scripts, and registry imports.
@code added (28 likes, 3 replies, 4,248 views, 10 bookmarks) another runtime layer on top of that idea: skills with lots of tool calls or research can now run inside a dedicated sub-agent so the main chat context stays clean. That is a small product update, but it changes what a skill is allowed to do in practice: not just inject instructions, but own noisy execution.
@smoothasfkk argued (21 likes, 10 replies, 113 views) that EvoSkill's Harbor integration expands the evaluation surface from one benchmark to 190+, with containerized tasks and verifier rewards. Even at lower engagement, it reinforces the same direction as SkillOpt: skills are increasingly being tuned against explicit validation loops instead of intuition.
Discussion insight: The surrounding posts rewarded concrete control surfaces, not vague “self-improving agent” language. People wanted bounded edits, explicit visibility into skill files, and runtime isolation for tool-heavy skills.
Comparison to prior day: May 26 centered on skill marketplaces and installable skill packs. May 27 pushed the conversation deeper into editor-native execution, trainable skill files, and benchmark-backed skill evolution.
1.2 Harness engineering hardened into sandboxes, telemetry, and memory governance 🡕¶
A second strong theme treated harness engineering less like a vocabulary word and more like the place where control, safety, and operability now live. Five distinct signals supported this framing: system-scaling research, a curated harness canon, sandboxed execution, SIEM-facing telemetry, and a reply thread that reframed memory as a freshness problem.
@dair_ai argued (72 likes, 12 replies, 4,506 views, 77 bookmarks) that “system scaling” is the next bottleneck in agentic AI, not just model scaling. The linked paper, From Model Scaling to System Scaling: Scaling the Harness in Agentic AI, names context governance, trustworthy memory, and dynamic skill routing as the core bottlenecks, which makes the harness itself the main engineering surface.

@_vmlops shared (38 likes, 2 replies, 2,889 views, 50 bookmarks) an awesome-harness-engineering collection that groups the stack into context delivery, tools, skills and MCP, permissions, memory, verification, observability, debugging, and human-in-the-loop controls. The list mattered because it turned a fuzzy meme into an explicit systems map.
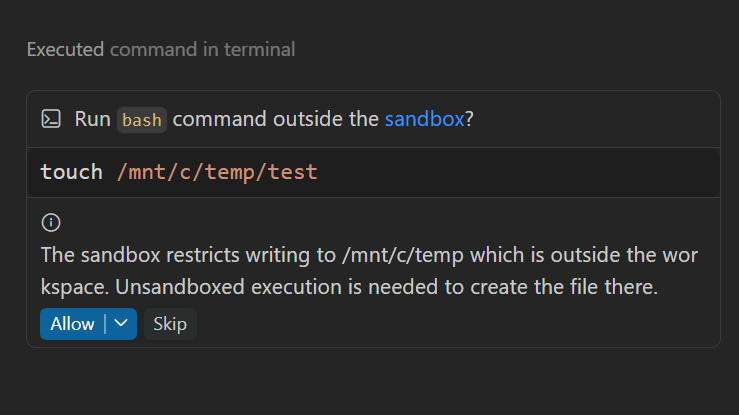
@pamelafox pointed out (4 likes, 185 views) that sandboxes are becoming part of the coding-agent default. Her examples connected VS Code's preview agent sandboxing with NVIDIA OpenShell and Docker's sandbox tooling, and the public docs make the point concrete: OS-level file and network limits are replacing best-effort prompt review as the main control plane.
@jqdsouza said (6 likes, 4 replies, 92 views) that Agent Beacon now feeds telemetry into Microsoft Sentinel and captures activity inside VS Code Copilot Chat. The post is small, but it adds a real enterprise demand signal: security teams want agent activity to land inside the monitoring systems they already operate.
@hwchase17 boosted (114 likes, 6 replies, 19,563 views, 151 bookmarks) a memory and continual-learning project, but the best evidence came from the replies. @r_rajan4ever said the hard part is deciding what belongs in weights, a memory DB, or live context, while @TomGiant1 said stale memory that silently decays is worse than no memory at all.
Discussion insight: The replies kept coming back to the same limit: storage is easy, but governance is hard. Sandboxes, approval fatigue, stale memory, and SIEM visibility were all treated as harness failures rather than model failures.
Comparison to prior day: May 26 already had governance and policy signals, but May 27 widened the frame from tool-call control into runtime isolation, observability, and memory freshness.
1.3 Builders packaged agent work as organizations, operating surfaces, and specialist operators 🡒¶
A third cluster focused on products that make agents feel less like a single chat box and more like an operating surface. The supporting items ranged from agent org charts to background desktop control to vertical operators for voice and security work.
@Sumanth_077 described (11 likes, 4 replies, 724 views, 10 bookmarks) Alook as a self-hosted collaboration platform where coding agents get roles, reporting lines, email addresses, schedules, and shared memory. The public README extends that claim with kanban, calendars, local-first execution, and traceable decisions, which makes it an “AI company” operating layer rather than another assistant shell.
@trycua launched (15 likes, 7 replies, 729 views, 8 bookmarks) Windows support for Cua Driver, letting Claude Code, Codex, or custom agents drive real Windows apps through CLI or MCP while the desktop stays usable. The thread adds the practical wedge: QA loops for WPF apps, automation of legacy desktop software with no API, and a reply from @sureshkanbu calling focus-stealing the real blocker in today's multi-agent workflows.

@HowToAI_ highlighted (26 likes, 1 replies, 1,149 views, 26 bookmarks) Dograh, a drag-and-drop voice-agent builder positioned as an open-source, self-hosted alternative to Vapi and Retell. Dograh's README backs up the anti-lock-in pitch with Docker-based self-hosting, bring-your-own model and telephony providers, and built-in QA/test nodes.
@VivekIntel shared (18 likes, 605 views, 15 bookmarks) PentestAgent, whose public README describes assist, agent, and crew modes, Docker and Kali execution paths, MCP server support, and direct use of tools like nmap, sqlmap, and metasploit. That is a good example of the day's broader pattern: packaging agents as domain operators with their own runtimes, tools, and workflow semantics.
Discussion insight: The most useful replies were about operational friction, not model quality. The Cua thread in particular focused on no-focus-steal automation and legacy Windows software that still runs real business processes.
Comparison to prior day: May 26 leaned more toward interface layers like avatars and generative canvases. May 27 shifted toward longer-lived operating surfaces: org charts, background desktop control, and specialist operators.
2. What Frustrates People¶
Approval prompts and prompt-only guardrails still feel too weak¶
Severity: High. @pamelafox noted (4 likes, 185 views) that sandboxes are becoming a distinct trend in coding agents, pointing at VS Code sandboxing plus OpenShell and Docker options. The public VS Code sandboxing docs spell out the reason clearly: approval fatigue, command-parsing limits, prompt injection, and unintended actions on external services all survive a prompt-only approval model, which is why OS-level file and network boundaries matter. NVIDIA OpenShell makes the same complaint from the runtime side, starting every sandbox with minimal outbound access and requiring declarative YAML policy to open more.
@jqdsouza added (6 likes, 4 replies, 92 views) that security and platform teams are still asking for more visibility into Copilot Chat and agent activity, which is why Agent Beacon is pushing telemetry into Microsoft Sentinel. People are coping by layering sandboxes, policy engines, and SIEM telemetry around agents instead of trusting prompts. Worth building for: yes.
Memory is easy to store and hard to keep trustworthy¶
Severity: High. @hwchase17 boosted (114 likes, 6 replies, 19,563 views, 151 bookmarks) an open-source memory and continual-learning agent, but the most substantive reactions immediately challenged the memory layer. @r_rajan4ever said the hard part is routing what belongs in weights, memory DBs, and live context, while @TomGiant1 warned that memory silently turns dangerous when file paths, APIs, or configs drift and the agent keeps acting on stale state. The workaround today is re-verification, tighter promotion rules, and shorter-lived trust in stored memories. Worth building for: yes.
Context and token burn are still wasting real money¶
Severity: Medium. @Shruti_0810 reported (18 likes, 6 replies, 1,141 views) that a Claude Code workflow dropped from 10.4M tokens to 3.7M, from $9.21 to $2.81, and from 10 errors to 0 after switching to InsForge skills plus CLI-based context engineering. The reaction thread did not treat that as a small tweak: @TuracTheThinker said larger context windows are less important than showing which lines or sources shaped an answer, and multiple replies treated the savings as a change in what builders can afford to attempt. People are coping by investing in context engineering and backend surfaces instead of just buying larger windows. Worth building for: yes.
3. What People Wish Existed¶
Skill systems that can be measured, tuned, and ported across runtimes¶
The strongest product wish was not “more prompts,” but a full skill lifecycle. @daniel_mac8 showed (352 likes, 16 replies, 25,274 views, 432 bookmarks) a workflow that ports research like SkillOpt directly into Codex, @zeddotdev shipped (203 likes, 7 replies, 6,296 views) editor-native skills, and @code added (28 likes, 3 replies, 4,248 views, 10 bookmarks) dedicated sub-agents for running heavy skills. The need is practical: builders want skills that can be created once, validated, improved, and reused across environments. Opportunity: direct.
Default-secure runtimes with built-in audit and telemetry¶
People are clearly asking for an agent runtime that starts safe by default and tells operators what happened afterward. @pamelafox surfaced (4 likes, 185 views) the sandbox trend, the VS Code docs explicitly say approval flows break down under injection and fatigue, OpenShell exposes file, process, network, and inference controls, and @jqdsouza said (6 likes, 4 replies, 92 views) enterprises are asking for Copilot Chat telemetry inside Sentinel. This is a practical need with partial answers already emerging, so the opportunity is direct and competitive.
Multi-agent workspaces that behave more like teams than chats¶
The Alook and Cua threads point to a specific wish: agents that can keep working in the background, coordinate with each other, and operate the software people already use. @Sumanth_077 described (11 likes, 4 replies, 724 views, 10 bookmarks) Alook as an email-native org chart for coding agents, while @trycua released (15 likes, 7 replies, 729 views, 8 bookmarks) background Windows computer-use for agents that need to drive real desktop software. The need is practical rather than aspirational: keep context, keep roles, and stop forcing every workflow back into one foreground chat pane. Opportunity: direct and competitive.
Cheaper, more traceable context engineering for coding agents¶
The InsForge thread made a narrower but concrete request visible: better ways to feed backend state and retrieval context into coding agents without paying for waste. @Shruti_0810 claimed (18 likes, 6 replies, 1,141 views) large token and error reductions, and the InsForge repo shows why the idea is appealing: MCP and CLI surfaces for auth, database, storage, compute, and deployment, all exposed in a way an agent can inspect and operate. This need is still early and crowded, but it is concrete. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| SkillOpt | Skill optimization | (+) | Bounded text edits, held-out validation, cross-harness transfer, no inference-time overhead | Best suited to settings with verifiable objectives; open-ended work still needs stronger evaluators |
| Zed skills | Editor skill system | (+) | Global and project-local scopes, discoverable or explicit-only modes, SKILL.md packaging |
New feature surface; editor-specific |
Dedicated skill sub-agents in @code |
Coding-agent runtime | (+/-) | Keeps tool-heavy or research-heavy skills out of the main context window | Public detail is still limited to the feature thread |
| VS Code agent sandboxing | Agent sandbox | (+/-) | OS-level file/network isolation, checkpoint review, auto-approval inside the sandbox | Preview feature; currently focused on terminal commands |
| OpenShell | Sandbox runtime | (+/-) | Declarative YAML policies, minimal outbound defaults, hot-reloadable policy, support for multiple agent CLIs | Alpha and explicitly still “single-player mode” |
| Alook | Multi-agent orchestration | (+) | Org charts, email-native coordination, calendars, shared memory, local-first execution | Small public footprint and early ecosystem |
| Cua Driver / Cua | Computer-use runtime | (+) | Background computer use via CLI/MCP, replayable trajectories, support for legacy desktop apps | Windows support is new and the public repo spans a broader platform than one workflow |
| Dograh | Voice-agent platform | (+) | Drag-and-drop builder, self-hosting, BYO providers, built-in test/QA nodes | Voice-specific; still one more operational stack to run |
| InsForge | Agent backend platform | (+/-) | Exposes auth, DB, storage, compute, deployment, and model gateway surfaces through MCP/CLI | Evidence of savings today is still anecdotal and thread-driven |
| PentestAgent | Security operator | (+/-) | Assist/agent/crew modes, Docker/Kali execution, MCP server mode, direct use of standard security tools | Sensitive domain with obvious misuse risk; requires authorized targets |
| EvoSkill + Harbor | Eval and skill evolution | (+) | Containerized tasks, verifier rewards, and a much larger benchmark surface for skill evolution | Lower visible operator adoption in today's thread than the editor-skill tools |
Overall satisfaction favored tools that replace implicit prompt discipline with visible system structure. @zeddotdev shipped (203 likes, 7 replies, 6,296 views) a file-backed skill system, @daniel_mac8 showed (352 likes, 16 replies, 25,274 views, 432 bookmarks) how those files can be tuned from research, and @pamelafox pointed (4 likes, 185 views) toward sandboxes as a necessary runtime layer rather than optional caution.
The common workaround pattern was consistent across the day: move from prompt engineering to context or harness engineering, from approval prompts to runtime isolation, and from one monolithic assistant toward explicit roles or sub-agents. Migration pressure also showed up in smaller ways: Zed moving from Rules Library to skills, Cua pushing browser-style automation into background desktop control, and InsForge framing backend context as an MCP and CLI surface instead of hidden infrastructure.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Zed skills | Zed | Adds reusable skill packages to the Zed editor agent | Replaces brittle prompt fragments and old rules surfaces with file-backed, configurable instructions | Zed editor, SKILL.md, local/project skills, registry imports |
Shipped | docs, post |
| Alook | Alook team | Runs coding agents as a role-based, email-native “company” with shared memory | Makes multi-agent coordination persistent and traceable instead of manual chat routing | Next.js, Cloudflare Workers, Bun, SQLite/files, Claude Code/Codex/OpenCode | Beta | repo, site, post |
| Cua Driver for Windows | Cua | Lets agents control native Windows apps in the background through CLI or MCP | Unlocks legacy desktop workflows and UI QA without stealing focus | Cua Driver, CLI/MCP, desktop automation, replayable trajectories | Shipped | repo, post |
| Dograh | Dograh | Self-hosted drag-and-drop voice-agent builder | Avoids per-minute SaaS lock-in for production voice bots | Python, Docker, telephony, BYO LLM/TTS/STT, workflow builder | Shipped | repo, site, post |
| InsForge | InsForge | Backend platform that exposes auth, DB, storage, compute, and deployment to coding agents | Gives agents direct backend context and operations instead of forcing manual glue work | MCP server, CLI, Postgres, storage, edge functions, model gateway | Beta | repo, site, post |
| PentestAgent | GH05TCREW | Autonomous penetration-testing agent with assist, agent, and crew modes | Packages security workflows into a domain-specific operator with isolation and reporting | Python, LiteLLM, TUI, Docker/Kali, MCP, browser/terminal tools | Beta | repo, post |
| EvoSkill + Harbor integration | Sentient | Evolves agent skills against containerized benchmarks and verifier rewards | Makes skill improvement measurable across far more realistic tasks | Python, Harbor, containerized benchmarks, verifier rewards | Alpha | repo, post |
Alook and Cua show the strongest repeated build pattern: agents are being wrapped in explicit operating surfaces instead of treated as a single conversational endpoint. @Sumanth_077 described (11 likes, 4 replies, 724 views, 10 bookmarks) persistent roles, email routing, and shared memory, while @trycua released (15 likes, 7 replies, 729 views, 8 bookmarks) background desktop control for Windows apps that never had APIs in the first place. The trigger in both cases is the same: the work does not fit cleanly inside one foreground chat.
Dograh, InsForge, PentestAgent, and EvoSkill point to the other major pattern: builders are targeting specific operational bottlenecks rather than generic “AI agent” positioning. Voice-agent teams want self-hosting and QA loops, coding-agent teams want backend context and lower token burn, security teams want domain-native operators, and skill researchers want benchmark-backed evolution instead of manual tuning.
6. New and Notable¶
Stable editors started treating skills as native product objects¶
@zeddotdev shipped (203 likes, 7 replies, 6,296 views) skills in a stable editor release, and @code added (28 likes, 3 replies, 4,248 views, 10 bookmarks) dedicated sub-agents for running them. Combined with @daniel_mac8 operationalizing (352 likes, 16 replies, 25,274 views, 432 bookmarks) SkillOpt inside Codex, the signal is that skills are moving from community convention into supported product architecture.
Sandboxing became a documented answer to agent autonomy risk¶
The notable shift was not just that people mentioned sandboxes, but that the public documentation now explains why they are needed. @pamelafox flagged (4 likes, 185 views) the trend, the VS Code sandbox docs explicitly call out approval fatigue and prompt injection, and OpenShell shows the runtime version of the same idea with minimal outbound access and reloadable policy.
Background computer-use for Windows looked more practical than flashy¶
@trycua released (15 likes, 7 replies, 729 views, 8 bookmarks) Windows support for Cua Driver and used the thread to emphasize WPF QA and legacy line-of-business software, not demos. That matters because it reframed computer-use agents as tooling for real enterprise desktop workflows instead of browser-only novelty.
7. Where the Opportunities Are¶
[+++] Secure harness control planes — The strongest multi-source gap sits at the runtime boundary. @pamelafox surfaced sandboxes, the VS Code docs explain why prompt approvals fail, OpenShell exposes policy as code, and @jqdsouza shows demand for SIEM-grade telemetry. The opportunity is strong because the pain is operational, security-sensitive, and recurring.
[+++] Portable skill lifecycle tooling — SkillOpt, Zed skills, @code sub-agents, and EvoSkill all point to the same need: create, validate, tune, route, and reuse skills across environments. The opportunity is strong because the data shows demand at every layer, from research to editor UX to benchmark infrastructure.
[++] Agent operating systems for teams and legacy software — Alook and Cua show two sides of the same problem: agents need roles, memory, and access to the software companies already run. The opportunity is moderate because there are already credible early entrants, but the workflows are sticky and the surface area is large.
[+] Context cost and traceability layers for coding agents — The InsForge thread is only one data point, but it is a useful one because it ties context engineering directly to lower spend and fewer failures. This looks emerging rather than fully proven, but the cost pressure is real enough to matter.
8. Takeaways¶
- Skills are becoming a managed software layer, not just a prompting habit. The strongest evidence came from SkillOpt's validation-gated tuning loop, Zed's stable skills release, and
@codeadding dedicated sub-agents for heavy skills. (daniel_mac8, Zed, code) - The harness is where trust is now won or lost. The system-scaling paper named context governance, trustworthy memory, and dynamic skill routing as bottlenecks, while sandbox tooling and telemetry posts showed the same concern in product form. (dair_ai, pamelafox, jqdsouza)
- Memory remains unsolved because freshness matters more than storage. The most useful replies on the memory thread argued that the real challenge is routing, invalidation, and re-verification when the world changes. (hwchase17 thread, r_rajan4ever reply, TomGiant1 reply)
- Builders are packaging agents as operating surfaces with their own roles and runtimes. Alook turned agents into an email-and-org-chart workflow, while Cua Driver turned Windows apps into a practical execution surface for agents. (Alook, Cua Driver)
- Cost and control are starting to matter as much as raw model quality. The InsForge thread quantified lower token spend and fewer errors, and the Dograh and OpenShell materials both sold openness and controllable infrastructure as a first-order feature. (InsForge thread, Dograh, OpenShell)