Twitter AI Coding - 2026-05-01¶
1. What People Are Talking About¶
1.1 Codex Momentum Accelerates; "Lord Bottleneck" Internal Loop Revealed 🡕¶
@theallinpod posted (122 likes, 7 retweets, 17,143 views) their latest episode with "Codex gains on Claude" as a headline segment alongside "Vibecoding nightmare: AI deleted someone's codebase." This is the day's highest-scoring item by a wide margin.
@tbpn described (49 likes, 4,349 views) "Lord Bottleneck," an internal OpenAI loop built by a single growth team member using Codex: "They started using Codex for each separate thing. So they had it run a bunch of analyses, interrogate the data, talk to Codex about the data. Then they would pick an experiment, and ask Codex to write the code." The loop evolved into an autonomous daily system: "Every morning, Lord Bottleneck evaluates past experiments, looks at data, proposes some experiments, and offers to the team to run the experiments." He added: "It's produced significant company value automatically through Codex."
@k1rallik traced (15 likes, 1,311 views) Codex's trajectory: "go from 5% of Claude Code's usage to 40% in 4 months... get a Super Bowl LX commercial... hit 2 million weekly active users... get deployed at Cisco, NVIDIA, Ramp, Rakuten, Harvey... become the coding layer of a $850B superapp. And then someone added pets."
@testingcatalog reported (60 likes, 3,416 views) that Codex shipped Pets -- overlay avatars that live on the desktop, activated via /pet command. 8 predefined pets available, with skill-generated custom pets.
Discussion insight: The "Lord Bottleneck" story is the most concrete public description of Codex being used as a fully autonomous daily business process rather than a coding assistant. The progression from "use Codex for each separate thing" to "connect into a giant skill" to "why don't you do this every morning" maps the exact path from tool to agent to autonomous system. The Pets feature, by contrast, signals consumer engagement strategy -- emotional attachment to retain users.
Comparison to prior day: On April 30, Codex discussion focused on the role picker expanding beyond developers and /goal shipping in CLI 0.128.0. Today the narrative advances: Codex is not just expanding categories but demonstrating autonomous value creation (Lord Bottleneck) and approaching 40% of Claude Code's usage from 5% four months ago. The competitive framing has shifted from "catching up" to "gaining ground."
1.2 Pi v0.71.0 Drops Google Antigravity and Gemini CLI Support 🡕¶
@PiChangelog posted (141 likes, 4 retweets, 13,222 views): "Pi v0.71.0 is out. Highlights: Google Gemini CLI and Google Antigravity support removed. Existing configurations using those providers must switch to another supported provider. Cloudflare AI Gateway and Moonshot AI added as built-in providers. Mistral Medium 3.5 also added as a built-in model."
Extension APIs were expanded: "replace finalized message_end messages, wrap editor factories via ctx.ui.getEditorComponent(), and observe thinking level changes."

In a follow-up, @PiChangelog clarified: "Breaking changes: Google Gemini CLI and Google Antigravity built-in support removed. Existing configurations using those providers must switch to another supported provider."
Discussion insight: This is the first major third-party coding agent to formally drop Google Antigravity support. Pi (badlogic/pi-mono) is a high-profile community tool -- the decision to remove rather than deprecate signals that maintaining Antigravity integration became untenable. The simultaneous addition of Cloudflare AI Gateway and Moonshot AI indicates the ecosystem is diversifying away from the Google-Anthropic-OpenAI triopoly.
Comparison to prior day: On April 30, Antigravity's reliability erosion was documented through user complaints (outages, shared family quotas, missing Opus 4.7 model). Today the erosion becomes structural: a tool with 141-like release announcements is removing Antigravity support entirely. This is the transition from user frustration to ecosystem abandonment.
1.3 Local Inference Engineering: System Prompt Bloat and KV Cache Optimization 🡕¶
@antirez posted (99 likes, 6 retweets, 6,714 views): "Look at this. Also opencode uses freaking 11k tokens of system prompt. Even at decent pre-fill of ~130 t/s it means waiting 84 seconds to start a session. What's the point? The pi agent is a lot saner here."
He proposed: "one could say, let's cache on disk very long common KV cache chunks, no? Hash it with all the parameters and put a sensible TTL if not used. But also: only cache it if you see it repeated N times across different sessions."

@mitsuhiko replied: "I really want to see what we can do to make local models work better. Taking and leanings :)" (11 likes, 989 views).
@antirez followed up: "DeepSeek v4 Flash is at the limit of being usable, with 21 t/s and prefill at 130 t/s... it has certain things that make it so much suited for local inference. For once: it acts as a frontier model, and thinks the right time. Second: the KV cache is crazy compact, so it is really possible to do KV checkpointing on disk."
@sakurayukiai noted: "Caching KV on disk would actually beat that 84s prefill, but keeping it warm in VRAM is how vLLM handles this now. If that 11k prompt is static, prefix caching drops your TTFT to basically zero."
Discussion insight: The antirez thread identifies a concrete performance bottleneck for local agentic coding: system prompts in the 10K+ token range create unacceptable startup latency on local hardware. The proposed solution (disk-cached KV checkpoints with hash-based identity and TTL) would benefit every local agent user. DeepSeek v4's compact KV cache makes it uniquely suited for this optimization. The mitsuhiko engagement (Sentry/Flask creator) suggests this will influence tooling decisions.
Comparison to prior day: On April 30, the local inference discussion was implicit in harness engineering (provider-specific profiles). Today antirez makes it explicit: the system prompt itself is the bottleneck for local users, and the fix requires infrastructure-level caching that no current tool provides.
1.4 GPT 5.5 Gains Converts from Claude; Model Switching Economics 🡕¶
@DanWahlin posted (30 likes, 12 replies, 3,042 views): "I've been using GPT 5.5 heavily for the last few days in GitHub Copilot CLI and have been really impressed so far. Opus has always been my go to, but I feel like 5.5 is generating better results overall. Anyone else using it a lot?"
@kellabyte replied: "I left Claude when 5.2 came out and have been a Codex user ever since. I tried 3 times to do something tough with Claude and the code base was a shit show. Codex is fire."
@DanWahlin added: "I alternate between Copilot CLI and Codex especially for reviews... Ended up cancelling my CC subscription a few weeks ago actually -- couldn't justify the $200/mo anymore."
@burkeholland posted (28 likes, 1,750 views): "I've been using Sonnet 4.6 (Medium) with Rubber Duck in Copilot because @Github reports ~75% of Opus perf w this strat. I'm loving it. Fast, has not let me down yet and was able to fix a bug that even Opus could not." He linked the GitHub blog post on combining model families.
@flowVSgravity warned: "Opus is stable, GPT is smart but not reliable. And Copilot is dead, 1st June their prices go up 100-200 times from their current attractive rates."
Discussion insight: The DanWahlin thread represents a model migration pattern: experienced developers leaving Claude ($200/mo) for GPT 5.5 via Copilot CLI, which offers model choice at lower cost. The burkeholland "Rubber Duck" strategy (Sonnet 4.6 at 75% of Opus performance) demonstrates that cost-performance optimization is now a first-class concern. The flowVSgravity warning about June 1 pricing anchors a timeline for these economics to shift again.
Comparison to prior day: On April 30, the model comparison focused on "consistency over peaks" (manthanguptaa) and Opus 4.6 becoming "unusable on a random afternoon." Today the evidence is more concrete: named developers are cancelling Claude Code subscriptions and switching to GPT 5.5 via Copilot CLI, with the Rubber Duck multi-model strategy as a middle path.
1.5 AI Subsidy Economics Under Scrutiny; "Subprime AI" Thesis Gains Traction 🡕¶
@Eli5defi posted (9 likes, 264 views) a detailed thread with infographic: "$852 billion. That's how much OpenAI says it needs in combined revenue and funding by 2030, while projecting to burn $852 billion to get there." Key data points cited: - Microsoft losing $20-$80 per user per month on $10 GitHub Copilot subscription (WSJ) - Cursor gross margin: negative 23% (negative 31% including non-paying users) - Claude Code: $13 per developer per active day, up from $6 months ago - A 10-person dev team at $30/working day: $75,600/year; at $300/day: $756,000/year - MIT: 95% of GenAI pilots return zero ROI; Atlassian: 96% no productivity gain - Oracle debt for Stargate: ~$115B, needing ~$150B more; free cash flow: negative $24.7B

@RussellQuantum posted (20 likes, 10 retweets, 1,619 views): "GitHub Is Double-Charging You For Copilot. From June 2026, GitHub Copilot Code Review burns both AI Credits and your Actions minutes simultaneously. One feature, two bills... Is 'agentic AI' just a pricing mechanism dressed up as a technical breakthrough?"
@norveclifinance posted (2 likes, 171 views) listing every major AI product and concluding: "all burning cash at an unsustainable pace. This is exactly what Michael Burry warned about. The AI bubble isn't forming. It's already cracking."
Discussion insight: The "subprime AI" framing is coalescing around three data points: (1) every AI coding tool operates at negative margins, (2) token-based billing is the mechanism for passing true costs to users, and (3) the infrastructure behind it (Stargate) is over-leveraged. The Eli5defi infographic synthesizes these into a single thesis. The RussellQuantum "double-charging" post identifies the specific mechanism by which costs will increase for GitHub users.
Comparison to prior day: On April 30, @edzitron's critique (204 likes) questioned whether Microsoft's $300B AI investment was ever viable. Today the argument deepens with specific unit economics (Cursor's -23% margin, Claude Code's $13/dev/day) and infrastructure financing risks (Oracle's $115B debt). The narrative has moved from "is this expensive?" to "is this a systemic financial risk?"
1.6 Agentic Terminal Workflows and Copilot CLI Education 🡒¶
@freeCodeCamp posted (72 likes, 8 retweets, 3,147 views): "Many developers live in the terminal, but it may not feel 'agentic.' So here, @0xphoekerson teaches you how to turn your shell into an AI workflow using GitHub Copilot CLI and MCP servers. You'll wire commands, external tools, and multi-step workflows into one system."

@github promoted (36 likes, 8,414 views): "Use GitHub Copilot cloud agent to modernize your codebase and improve quality (without slowing down). Try the tutorial." Linked to docs.github.com cloud agent tutorial.
@olacokers shared (14 likes, 11 retweets, 186 views): "If you're using GitHub Copilot, be it CLI or through IDE. This is one GitHub repository you want to have handy: github.com/github/awesome-copilot. It's contains a lot of skills, agents, instructions and workflows."
@Dinosn posted (8 likes, 24 bookmarks, 876 views): "The open-source alternative to Claude Design. Local-first, web-deployable, BYOK at every layer -- 10 coding-agent CLIs auto-detected on your PATH (Claude Code, Codex, Cursor Agent, Gemini CLI, OpenCode, Qwen, GitHub Copilot CLI, Hermes, Kimi, Pi) become the design engine."
Discussion insight: The freeCodeCamp tutorial (3,147 views) and GitHub's own cloud agent promotion (8,414 views) indicate institutional investment in Copilot CLI education. The Dinosn post reveals 10 coding-agent CLIs now exist on the market, confirming the terminal agent category has reached saturation. The awesome-copilot repo serves as a discovery hub for the growing skills ecosystem.
Comparison to prior day: On April 30, Copilot CLI was discussed primarily in the context of brand erosion and pricing concerns. Today the educational content volume is high (freeCodeCamp, GitHub docs, awesome-copilot), suggesting GitHub is investing in adoption despite the pricing headwinds.
2. What Frustrates People¶
GitHub Double-Billing: AI Credits + Actions Minutes -- High¶
@RussellQuantum documented (20 likes, 10 retweets, 1,619 views) that from June 2026, GitHub Copilot Code Review charges both AI Credits and Actions minutes simultaneously: "One feature, two bills. They're calling it an 'agentic architecture upgrade.' A more accurate description: they found a second pocket to pick." Every paid tier is affected (Pro, Pro+, Business, Enterprise). Public repos exempt.
AI Coding Tool Economics Are Unsustainable -- High¶
@Eli5defi compiled (9 likes, 264 views) evidence that the entire AI coding stack operates at negative margins. GitHub Copilot loses $20-$80/user/month (WSJ); Cursor margin is negative 23%; Claude Code costs $13/dev/day. @TheDeFiPlug replied: "the subsidized AI party is ending when the real bills hit, most of these money losing tools will consolidate or most likely, die."
System Prompt Bloat Creates Unusable Local Startup Times -- Medium¶
@antirez showed (99 likes, 6,714 views) that opencode's 11K-token system prompt takes 84 seconds to prefill at 130 t/s on local hardware. "What's the point?" No current tool provides KV cache disk caching to eliminate this repeated cost.
Copilot Intellectual Property Concerns -- Medium¶
@AIPandaX posted (32 likes, 27 retweets, 6,658 views): "Your company did not buy GitHub Copilot to make you faster. They bought it to extract your senior logic... The goal is to vectorize your years of architectural experience, feed it to an internal model, and replace you with a junior developer making half your salary." Listed 18 countermeasures including keeping strategic context out of code comments.
3. What People Wish Existed¶
KV Cache Disk Persistence for Local Agent Sessions¶
@antirez proposed (99 likes, 6,714 views) hashing system prompts with parameters and caching KV chunks on disk with TTL, only caching prompts seen repeated across N sessions. @sakurayukiai confirmed this would "beat that 84s prefill" and noted vLLM uses VRAM prefix caching for the server case, but local inference lacks an equivalent.
Urgency: High. Opportunity: Direct -- the 84-second startup penalty makes local agents unusable for interactive coding.
Cross-Agent Diff Review Tool¶
@BachelderDan shipped (10 likes, 10 bookmarks, 3,277 views) slop-review -- a tool that performs PR-style diff reviews across Pi, Claude, and Codex. The fact that a developer built this independently confirms demand for agent-agnostic code review that works across the fragmented toolchain.
Urgency: Medium. Opportunity: Direct -- github.com/dbachelder/slop-review exists but could be generalized.
Native Cost Estimation Before Task Execution¶
@DanWahlin cancelled his $200/mo Claude Code subscription. @flowVSgravity warns of "100-200x" price increases on June 1. No agent currently provides pre-task cost estimates that would allow developers to make informed model-routing decisions before committing to a task.
Urgency: High. Opportunity: Direct -- token-based billing on June 1 makes every task a cost decision.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| OpenAI Codex | Agent platform | (+) | Lord Bottleneck autonomous loop (tbpn); 2M weekly active users (k1rallik); Pets feature for engagement; Super Bowl commercial | All-In Pod notes "misses targets"; Pets may signal consumer pivot over developer focus |
| Pi (badlogic) | Terminal agent | (+) | v0.71.0 ships; "saner" system prompt per antirez; adds Cloudflare AI Gateway, Moonshot AI, Mistral Medium 3.5 | Drops Google Antigravity/Gemini CLI support (breaking change) |
| GitHub Copilot CLI | Terminal agent | (+/-) | GPT 5.5 impresses DanWahlin; Rubber Duck strategy at 75% Opus perf (burkeholland); freeCodeCamp tutorial; awesome-copilot repo | Double-billing from June (RussellQuantum); "100-200x" price increase warning (flowVSgravity) |
| Claude Code | Terminal agent | (+/-) | v2.1.126 ships exact string edits, project purge (ClaudeCodeLog); 16 subagents; still more momentum among "tier 2-3 knowledge workers" | $200/mo price causing cancellations (DanWahlin); $13/dev/day actual cost (Eli5defi) |
| OpenCode | Terminal agent | (-) | Open source, community-driven | 11K token system prompt creates 84s startup (antirez) |
| DeepSeek v4 Flash | Local model | (+/-) | Compact KV cache "crazy compact"; acts as frontier model; thinks appropriately | 21 t/s "at the limit of being usable" (antirez) |
| slop-review | Code review | (+) | Cross-agent diff review for Pi, Claude, Codex; PR-style UX | New; single maintainer |
| Higgsfield MCP | Creative pipeline | (+) | Full DTC ad campaign from one product URL in Claude Code (mikefutia) | Requires Claude Code; marketing-focused |
5. What People Are Building¶
| Project | Who | What | Problem | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| slop-review | @BachelderDan | Cross-agent diff review tool adapted from pi-diff-review | Code review fragmented across Pi, Claude, Codex | Pi, Claude, Codex | Shipped | Post, GitHub |
| OpenTor | vichhka-git (via @Dinosn) | Dark web access as a skill for Claude and OpenCode agents | Agent research limited to clearnet | Claude Code, OpenCode, Tor | Shipped | Post, GitHub |
| Claude VRM Body | @SkyeSharkie | 3D VRM avatar for Claude Code with ragdoll animations and voice | Agents lack embodied presence | Claude Code, VRM, Three.js | In progress | Post |
| Nox Yield AI | @killsh0tx | Confidential AI-powered yield vault on Arbitrum using iExec Nox+ | DeFi yield strategies need privacy | iExec Nox, ERC-7984, Arbitrum | Shipped (testnet) | Post |
| Higgsfield MCP Campaign Pipeline | @mikefutia | Full DTC ad campaign from one product URL via Claude Code | Multi-tool creative production requires multiple vendors | Claude Code, Higgsfield MCP, GPT Image 2, Seedance 2.0 | Shipped | Post |
| 10-Agent CLI Design Engine | @Dinosn | Open-source alternative to Claude Design that auto-detects 10 coding CLIs | Design tools locked to single providers | Claude Code, Codex, Gemini CLI, OpenCode, Pi, + 5 others | Shipped | Post |
| Claude Code Research Pipeline | @DrewPavlou | Classified 110K tweets into indexed PDFs for Royal Commission submission | Manual research across 700GB archive impossible | Claude Code, Claude Sonnet 4.6 API | Completed | Post |
6. New and Notable¶
Pi v0.71.0 Removes Google Antigravity and Gemini CLI Support¶
@PiChangelog announced (141 likes, 13,222 views) that Pi v0.71.0 formally removes Google Gemini CLI and Google Antigravity as built-in providers. Existing users must migrate. Cloudflare AI Gateway, Moonshot AI, and Mistral Medium 3.5 added as replacements. Extension APIs gain message replacement, editor factory wrapping, and thinking level observation.
Claude Code 2.1.126: Exact String Edits and Project Purge¶
@ClaudeCodeLog announced (19 likes, 1,020 views) 33 CLI changes: "Edit tool now performs exact string replacements in files, so edits only change exact matched text." New claude project purge [path] command deletes Claude Code data (transcripts, tasks, files, history, config) with --dry-run and -i flags. New --dangerously-skip-permissions flag disables prompts for .claude/.git/.vscode and shell RCs.
OpenAI "Lord Bottleneck": First Public Description of Autonomous Codex Loop¶
@tbpn described (49 likes, 28 bookmarks, 4,349 views) an OpenAI product staff member explaining how a single growth team member built an autonomous daily loop using Codex that evaluates experiments, analyzes data, proposes new experiments, writes code, and runs them. Named "Lord Bottleneck" because it solves friction bottlenecks for new users. Described as producing "significant company value automatically."
Codex Pets Ship via /pet Command¶
@OpenAIDevs launched Codex Pets (quoted by @testingcatalog, 60 likes, 3,416 views). Desktop overlay avatars with 8 predefined options (Codex, Dewey, Fireball, Rocky, Seedy, Stacky, BSOD, Null Signal) plus skill-generated custom pets. @JohnGregQuantum noted (16 likes, 2,109 views): "Openai adding pets to Codex is dangerously smart! Now I'm emotionally attached to my new pet."
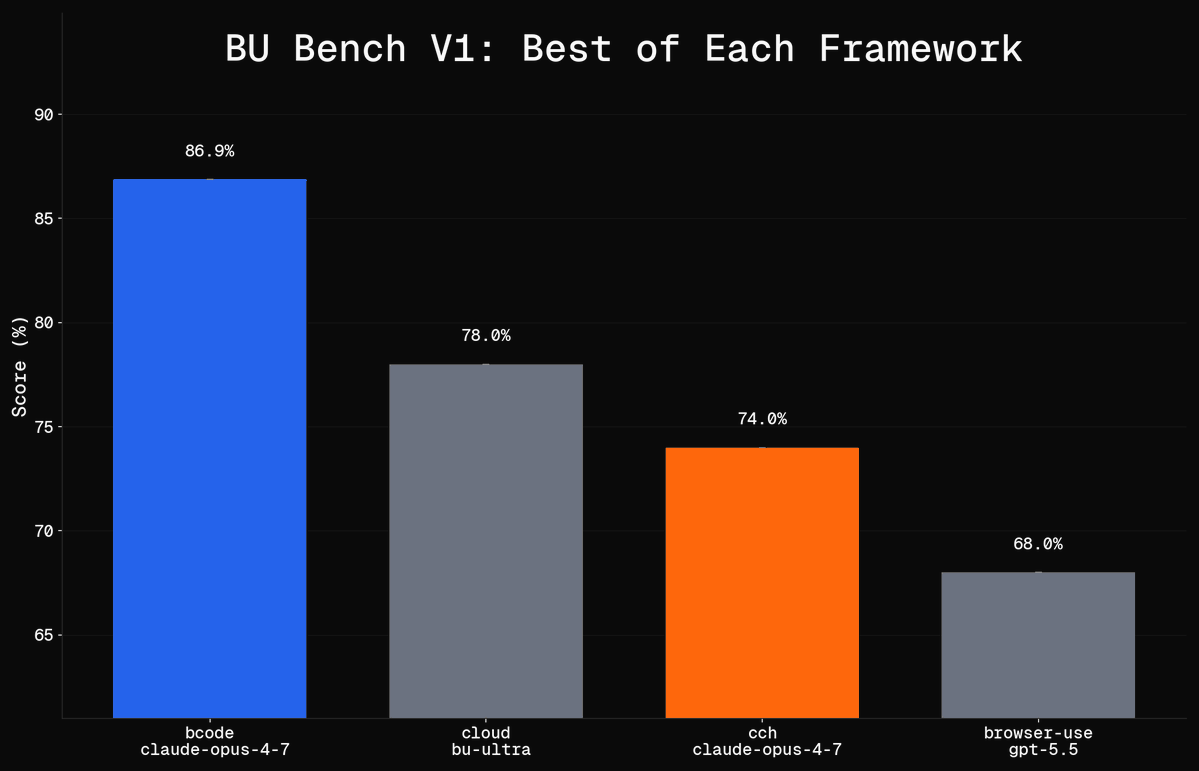
BU Bench V1: bcode + Claude Opus 4.7 Leads at 86.9%¶
@Alezander907 posted (16.2 score) BU Bench V1 results comparing frameworks: bcode with claude-opus-4-7 scored 86.9%, cloud with bu-ultra at 78.0%, cch with claude-opus-4-7 at 74.0%, and browser-use with gpt-5.5 at 68.0%.
GitHub Blog: Copilot CLI Combines Model Families for "Second Opinion"¶
@burkeholland linked (28 likes, 9 bookmarks, 1,750 views) a GitHub blog post explaining the "Rubber Duck" strategy: running Sonnet 4.6 (Medium) with a second-opinion model achieves approximately 75% of Opus performance at significantly lower cost. This formalizes multi-model routing as an official GitHub strategy.
7. Where the Opportunities Are¶
[+++] KV Cache Disk Persistence for Local Agent Sessions -- @antirez's demonstration (99 likes, 6,714 views) that opencode's 11K-token system prompt takes 84 seconds to prefill on local hardware exposes a fundamental gap. His proposal -- hash-based disk caching of KV chunks with TTL, only for prompts seen across N sessions -- has no implementation. DeepSeek v4's compact KV cache makes this feasible. @mitsuhiko (11 likes on reply) confirms active interest from tooling maintainers. Every local inference user (the fastest-growing segment) hits this wall daily.
[+++] Pre-Task Cost Estimation and Model Routing -- With GitHub Copilot shifting to token-based billing on June 1, developers face invisible costs. @DanWahlin cancelled Claude Code ($200/mo), @flowVSgravity warns of "100-200x" rate increases, and @Eli5defi documents Claude Code at $13/dev/day actual cost. The burkeholland "Rubber Duck" strategy (75% of Opus at lower cost) proves model routing works. No tool automates this: estimate cost before execution, route to cheapest-sufficient model, track spending per branch/feature.
[++] Cross-Agent Code Review Standardization -- @BachelderDan's slop-review (10 bookmarks, 3,277 views) demonstrates demand for agent-agnostic diff review. Teams using multiple agents (Pi, Claude, Codex) need a unified review interface. The PR-style UX shown in the screenshot maps directly to existing developer workflows. A polished version with configurable review criteria could capture the multi-agent team segment.
[++] Autonomous Daily Agent Loops for Non-Coding Functions -- The "Lord Bottleneck" pattern (@tbpn, 28 bookmarks) -- analyze data, propose experiments, write code, run experiments, report results -- is replicable for any team doing experiment-driven work (growth, marketing, operations). No productized version exists. A framework for building "morning loops" that connect analysis, proposal, execution, and reporting would be immediately useful.
[+] Provider Migration Tooling -- Pi v0.71.0 dropping Google Antigravity support means existing users must reconfigure manually. As providers rise and fall (Antigravity declining, Cloudflare AI Gateway rising), tooling that manages provider migration -- converting configurations, testing equivalence, recommending alternatives -- addresses a recurring pain point.
8. Takeaways¶
-
Codex's competitive positioning crystallizes around autonomous loops. The "Lord Bottleneck" description (49 likes, 28 bookmarks) is the most concrete public evidence of Codex operating as a fully autonomous daily business process. Combined with the All-In Pod's headline framing ("Codex gains on Claude") and @k1rallik's usage trajectory (5% to 40% of Claude Code usage in 4 months, 2M weekly actives), the narrative has shifted from "catching up" to "gaining momentum."
-
Google Antigravity erosion becomes structural, not just anecdotal. Pi v0.71.0 formally removing (141 likes, 13,222 views) Google Antigravity support is a new category of signal: ecosystem abandonment by third-party tools. On April 30, the evidence was user complaints (outages, shared quotas, missing models). Today a major tool drops support entirely. This is the seventh consecutive day of declining Antigravity signal.
-
The "subprime AI" thesis is forming a coherent counter-narrative. @Eli5defi's infographic, @RussellQuantum's double-billing report (20 likes, 10 retweets), and the All-In Pod discussing OpenAI "missing targets" converge on a single argument: every AI coding tool operates at negative margins, and the bill is arriving. The June 1 GitHub billing change is the anchor date.
-
Local inference engineering moves from niche to mainstream concern. @antirez's 84-second prefill demonstration (99 likes, 6,714 views) with @mitsuhiko engagement identifies system prompt bloat as the primary bottleneck for local agent sessions. The proposed KV cache disk persistence would make local agents competitive with cloud inference for interactive use. This thread signals that local inference is no longer just for hobbyists.
-
Model switching accelerates as cost awareness increases. @DanWahlin cancelling Claude Code (30 likes, 12 replies) and switching to GPT 5.5 in Copilot CLI, @kellabyte confirming the same migration, and @burkeholland demonstrating the Rubber Duck strategy at 75% of Opus performance collectively signal that model loyalty is dissolving under pricing pressure. The winner will be the tool that routes intelligently, not the one that locks users to a single model.
-
Claude Code ships precision editing; community builds cross-agent review. Claude Code 2.1.126 (19 likes) introduces exact string replacement in the edit tool and
project purgefor data management. Independently, @BachelderDan ships slop-review (10 bookmarks) for cross-agent diff review. The convergence indicates code quality tooling is maturing in both official and community channels.