Twitter AI Coding - 2026-05-11¶
1. What People Are Talking About¶
1.1 Copilot is being framed as a multi-model terminal workbench, not just a coding add-on 🡕¶
GitHub Copilot discussion stayed strong for a second straight day, but the center of gravity moved beyond simple onboarding. The day combined the official beginner push for Copilot CLI, public comparison between premium models inside Copilot, and a multilingual event push around agentic development, which makes the product look more like a broad operating surface than a single assistant.
@github promoted the GitHub Copilot CLI beginner series, and the linked blog says the workflow now starts with npm install, /login, folder permissions, repo-aware prompts, and /delegate to the Copilot cloud agent. The strongest reply in the thread came from @BrandGrowthOS, who said chat mode already feels faster than copying errors into another assistant because it understands the codebase in place.
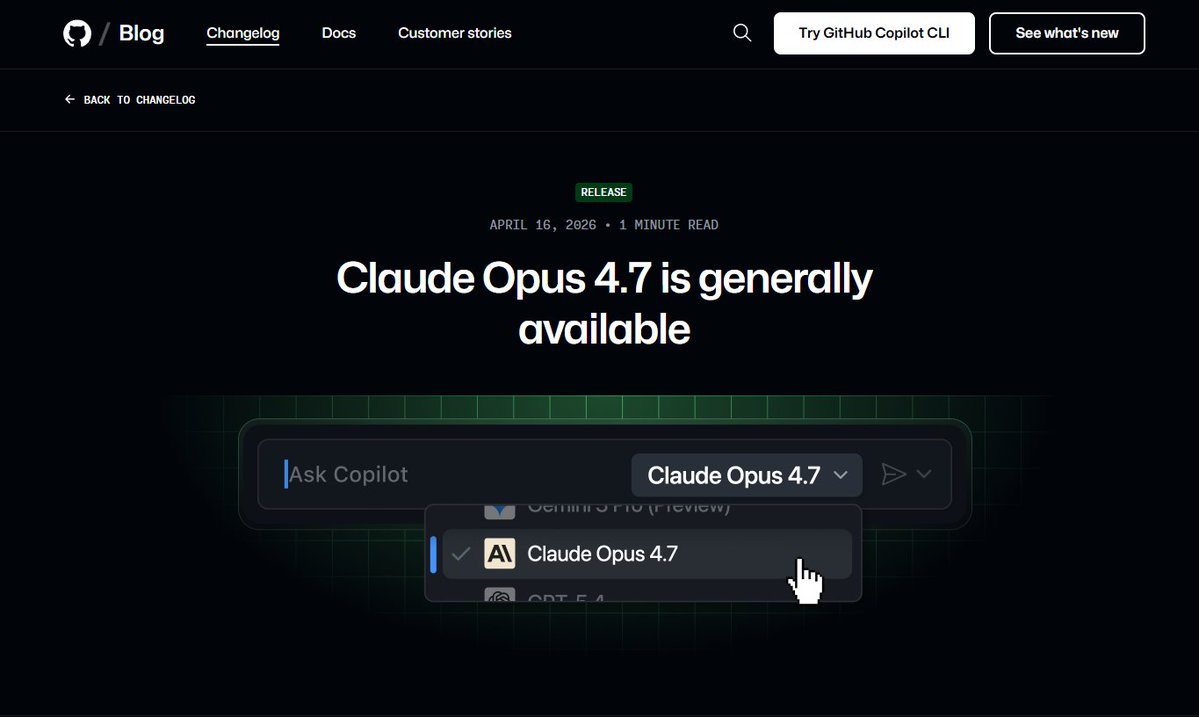
@0xAbhiii posted that GitHub added Claude Opus 4.7 to Copilot, and his screenshot shows a GitHub changelog page for that release while the tweet highlights big-codebase understanding, multi-file refactors, and planning before coding.
@burkeholland argued that GPT 5.5 is now his favorite Copilot model for design work even though it is expensive, and the attached Paperwalls for Mac screenshot gives the claim a concrete artifact instead of a generic benchmark boast.

@code announced GitHub Copilot Dev Days Online for May 25-27 in Brazilian Portuguese, Spanish, English, and Simplified Chinese, which extends the same education push into a public event series rather than a one-off tutorial.
Discussion insight: The replies around the GitHub tutorial were less about autocomplete and more about workflow fit. Users asked which commands become daily habits first, while the most substantive praise singled out repo-aware terminal chat as the difference from pasting errors into a separate model.
Comparison to prior day: On May 10, Copilot's strongest signal was the beginner-series launch itself. On May 11, that same onboarding thread stayed on top, but it was joined by explicit model-selection chatter and event programming, so the surface area around Copilot looked broader and more operational.
1.2 Codex speed is becoming the headline feature people argue about 🡕¶
The Codex conversation narrowed from browser and mobile expansion into latency. The strongest evidence was a leaked speed tier, and the replies immediately treated loop time as a product feature in its own right rather than an implementation detail.
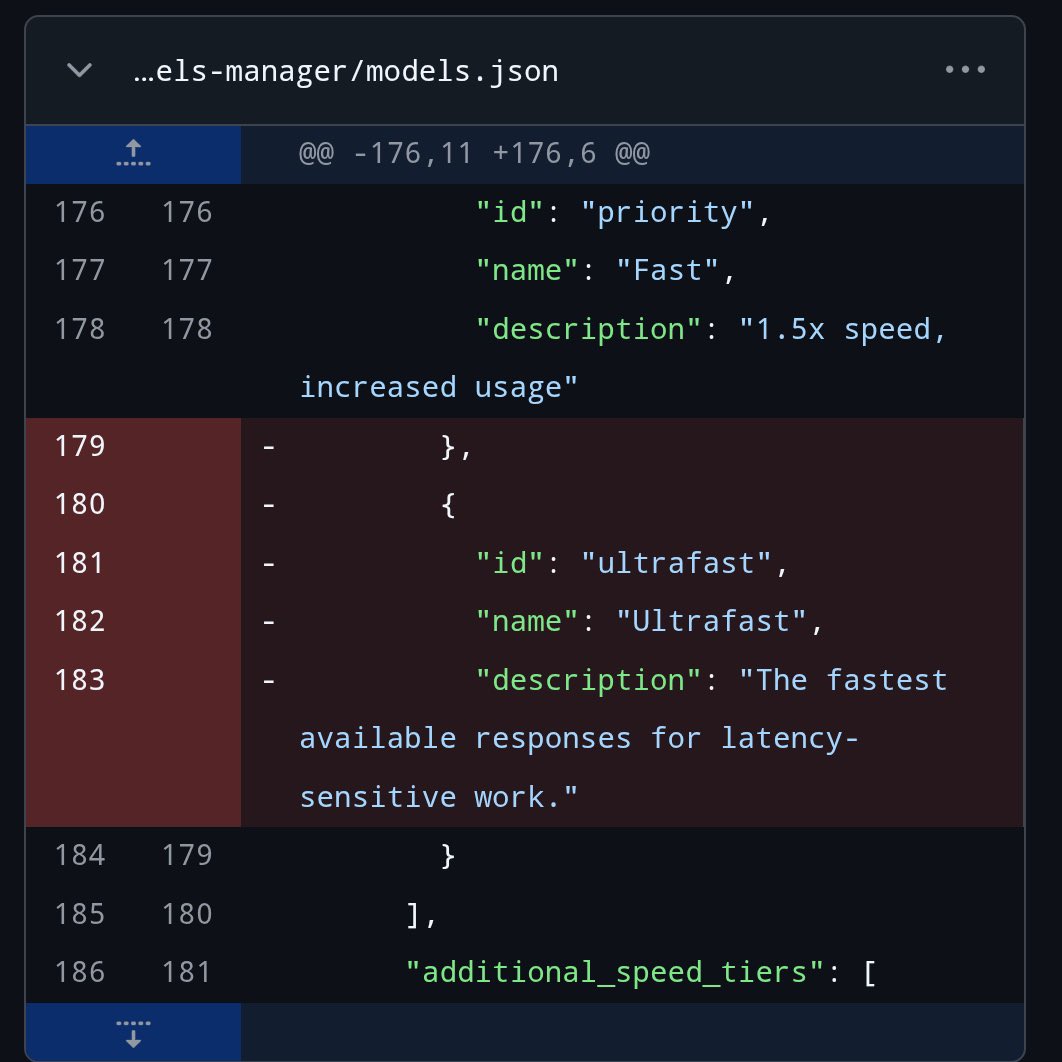
@testingcatalog reported that a deleted Codex GitHub repo entry briefly mentioned an Ultrafast mode, and the first screenshot is the key artifact: it shows an ultrafast tier described as “The fastest available responses for latency-sensitive work.” That matters because it is more specific than general “faster Codex” speculation.
@mark_k made the user thesis explicit by saying the bottleneck with coding agents is now waiting for the loop to finish rather than raw intelligence. His replies sharpen the tradeoff instead of flattening it: one response says “the loop time is the UX,” while another asks whether faster necessarily means dumber.
Discussion insight: The replies did not treat speed as an unqualified win. Several people argued that users feel the spinner more than benchmark deltas, but others pushed back that review time and answer quality still matter more than raw turnaround.
Comparison to prior day: On May 10, Codex attention centered on mobile and browser surfaces. On May 11, the discourse moved lower in the stack from “where can I run it?” to “how fast can the loop feel?”
1.3 Memory, execution layers, and policy controls are turning into separate products 🡕¶
A third cluster of posts treated the agent stack around coding tools as its own market. The notable examples were not another model launch but systems for persistent memory, natural-language action execution, and guardrails around what agents are allowed to do.
@origin_trail said DKG v10 now supports multi-agent memory for Hermes, OpenClaw, Claude, Cursor, Codex, Windsurf, Copilot Chat, and Cline. The linked public repository describes DKG V10 as a three-layer, verifiable memory system where knowledge can move from private draft to team-visible share to permanent cryptographically anchored record, which is a much stronger claim than generic “memory for agents.”
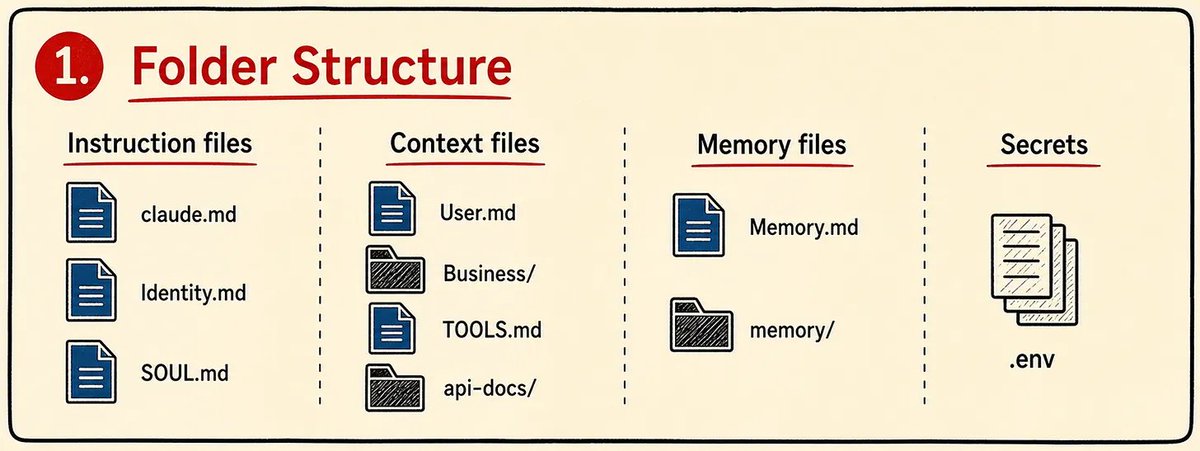
@petergyang shared a Claude Code “personal OS” setup built around explicit instruction files, context files, and memory files, then added in replies that each chat should write a memory line and nightly “dreaming” jobs should compress those notes into long-term memory.
@lcx posted an MCP flow where a user asks for balances or orders in plain English, the assistant chooses the right MCP tools, and LCX executes through exchange infrastructure. That image matters because it shows MCP discussion shifting from developer setup talk to concrete money-moving operations.

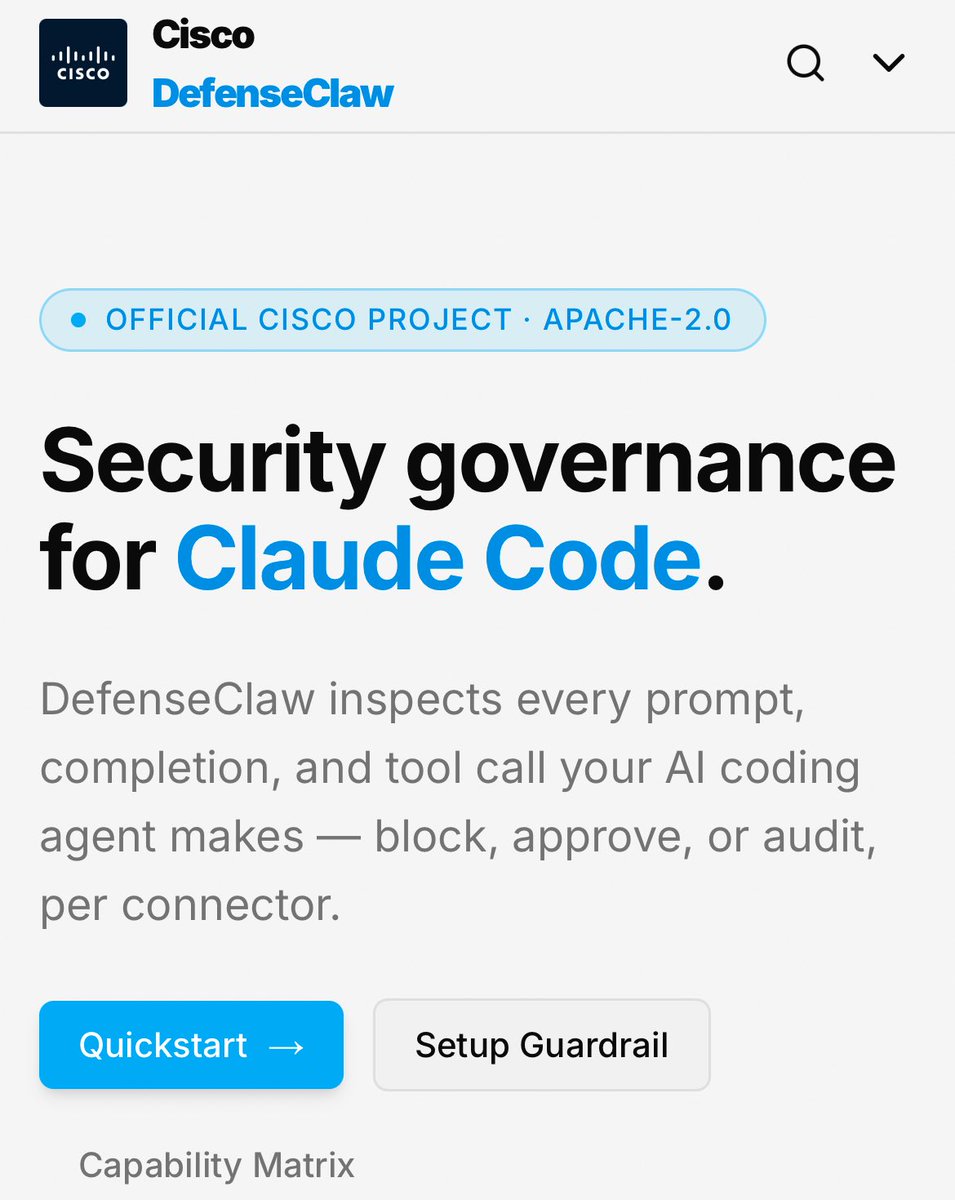
@AISecHub claimed that Cisco DefenseClaw now supports Claude Code, Codex, Cursor, Windsurf, Gemini CLI, Copilot, Hermes, OpenClaw, and Zeptoclaw, while the screenshot says it can inspect prompts, completions, and tool calls and then block, approve, or audit per connector.
Discussion insight: The replies on this cluster focused on verification and governance. One reply to the DKG rollout asked whether execution verification is also covered, while the DefenseClaw material frames value as policy enforcement and auditability, not more autonomy.
Comparison to prior day: May 10 concentrated on packaged skills, beginner workflows, and MCP stacks. May 11 pushed the conversation toward persistent memory, secure execution, and governance layers that sit on top of the agents themselves.
2. What Frustrates People¶
Cost, cache, and quota drag -- High¶
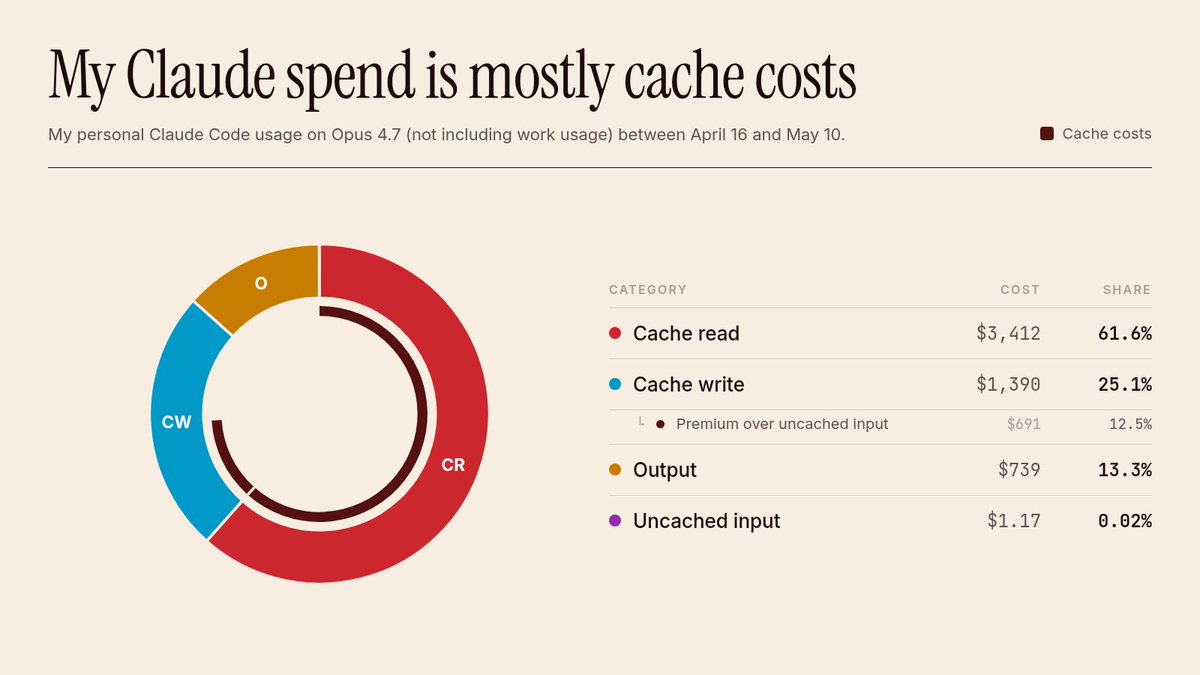
The clearest practical pain was still economics. @MaxNiederman shared a spend chart showing that 61.6% of his recent Claude Code usage cost came from cache charges, with cache read and cache write dominating the rest of the bill. @xoofx said a $100 ChatGPT business Codex subscription with 2,500 credits lasted less than a day for one developer, and @ihtesham2005 used that same pain to pitch 9router as a way to compress tool output and fall back from paid subscriptions to cheaper or free models.
@Hey_Aivetra added a more retail version of the same complaint with a “paid apps vs free alternatives” chart spanning Copilot, Cursor Pro, Postman Pro, Datadog, and other tools. Even the replies keep the gap honest: one says these substitutes are “close enough to test the waters,” while another says paid AI tools are still better.
The coping behavior is consistent: use routers, compare substitutes, and keep fallback options ready before a limit lands. Worth building for: High.
Powerful agents still need a trust and verification layer -- High¶
The action layer is getting more capable, but the day’s evidence says users do not want raw execution without guardrails. @lcx showed MCP being used to check balances and place orders, but the diagram routes execution through a regulated exchange rather than treating the assistant as the trusted endpoint. @origin_trail positioned DKG as shared memory with provenance, and one reply immediately asked whether execution verification is part of the plan.
@AISecHub made the governance complaint explicit by advertising DefenseClaw as a layer that inspects prompts, completions, and tool calls while stopping risky behavior, secret exfiltration, and unsafe tool use. The frustration is High because each post implies the same thing: the base agent can act, but teams still need a separate system to decide what should be allowed, verified, or rolled back. Worth building for: High.
AI-generated code quality is becoming a team problem, not just a solo annoyance -- Medium¶
The sharpest practitioner backlash came from @FilippoTarpini, who wrote that work produced by “vibe coders” who never learned the underlying craft is often non-reusable, hard to understand, and fluffed up far beyond what a codebase can absorb. @nateliason posted a screenshot where Claude incorrectly explained his “OpenClaw + Wiki + Granola” workflow as if OpenClaw were just slang for Claude Code, which is a smaller but concrete example of tool confusion inside these stacks.
The replies under more promotional threads point in the same direction. Under the xBubble announcement, one response argued that people still need a basic understanding of coding even for “vibe-code” workflows. The frustration is Medium because the posts are not rejecting AI coding itself; they are rejecting low-understanding output that creates cleanup work for everyone else. Worth building for: Medium to High.
3. What People Wish Existed¶
Seamless fallbacks that keep the same workflow when paid capacity runs out¶
This need shows up more through workaround builds than direct requests, but the intent is clear. @ihtesham2005 described 9router as a way to compress tool output and automatically fall back from Claude subscriptions to cheaper or free providers without changing the surrounding coding tool, while @Hey_Aivetra framed the same pressure from the buyer side with a paid-versus-free alternatives chart. @xoofx supplies the urgency: even a $100 Codex business plan can disappear in under a day under real usage.
This is a practical need, not an aspirational one. Partial answers exist in routers and substitute stacks, but the public evidence still shows users assembling those failovers themselves. Opportunity: Direct.
Shared memory that is queryable, durable, and verifiable across agents¶
@origin_trail explicitly says current agents build context and then lose it, and the DKG V10 repository turns that complaint into a design: private draft memory, shared team memory, and permanent anchored records with provenance. @petergyang points to the same gap in a more local form by prescribing claude.md, user.md, tools.md, and a memory folder plus nightly “dreaming” compression jobs. @RLanceMartin then adds a diagram where memory, enrichment, verification, and periodic updates all sit inside one system.
The need is practical and already active in the market: people want context to survive, be inspectable, and be reusable across sessions and agents. Partial answers exist, but none of today’s evidence showed a dominant default. Opportunity: Direct.
Review-first collaboration for AI-generated changes¶
@bearlyai is useful here because OpenADE does not pitch “more autonomous code generation” first; it pitches collaboration, commenting, faster diffs, and a Plan → Revise → Execute workflow on top of Claude Code and Codex. That lines up directly with @FilippoTarpini, who says the real failure mode is code that lands fast but does not fit the codebase or invite collaboration.
This is both a practical and emotional need: teams want AI leverage without losing readability, reviewability, or shared ownership of the code. Partial answers exist in OpenADE and governance layers such as DefenseClaw, but the discussion still reads like an early market. Opportunity: Competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| GitHub Copilot CLI / Copilot | Terminal and IDE agent | (+) | Official onboarding, repo-aware chat, /delegate, growing model choice inside Copilot, public education push |
Premium models are expensive, and access or account-state issues still block some users |
| OpenAI Codex | Coding agent | (+/-) | Strong autonomy, possible ultrafast tier for latency-sensitive work, broad mindshare | Speed raises quality and pricing questions, and credit burn remains visible |
| Claude Code | Terminal agent | (+/-) | Strong fit for memory loops, file-based routines, and personal-OS workflows | Cache-heavy economics and maintainability concerns are still active |
| OriginTrail DKG V10 | Memory layer | (+) | Shared, verifiable multi-agent memory with provenance and queryability | Still release-candidate on testnet, so governance and production maturity remain open |
| Model Context Protocol | Integration protocol | (+) | Lets assistants invoke external systems through tool adapters; LCX showed real balance/order flows | High-trust actions still need secure execution backends and policy controls |
| 9router | Routing gateway | (+) | Compresses tool output, exposes a local endpoint, and auto-falls back across paid, cheap, and free providers | Adds another layer to configure and depends on provider compatibility |
| DefenseClaw | Governance and security | (+) | Prompt/tool-call inspection, block/approve/audit controls, observability, connector coverage | Another policy layer teams must tune before it becomes useful |
| OpenADE | Agentic development environment | (+) | Plan → Revise → Execute flow, commentable diffs, offline mode, worktrees, Claude/Codex harnesses | Early-stage product, Windows marked experimental, still depends on external model access |
| Local models via OpenCode + custom skills | Local coding method | (+/-) | Makes smaller local models more useful when paired with tighter tool structure and skills | Requires token/context tuning and still trails hosted frontier models |
Below the table, the broad pattern is layering. People are not treating the agent as the whole product; they are stacking a primary agent with memory, routing, governance, or a review-first interface. Cost pressure is one reason for that behavior, but so is trust: the same feed that celebrates faster loops also keeps adding provenance, policy, and planning layers around them.
Migration behavior is equally visible. Copilot is being discussed as a terminal surface plus a model menu, Codex is being judged on loop speed, Claude Code is being wrapped in memory routines, and routers such as 9router exist precisely because users expect to move between providers rather than stay loyal to one. The competitive dynamic is no longer “which model wins?” but “which stack keeps working when price, latency, or trust changes?”
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| 9router | @ihtesham2005 / decolua | Local AI router that compresses tool output and routes coding tools across paid, cheap, and free providers | Prevents token burn and hard stops when subscriptions or quotas run out | JavaScript, local OpenAI-compatible endpoint, RTK token compression, multi-provider routing | Shipped | repo, post |
| OriginTrail DKG V10 | @origin_trail | Shared, verifiable multi-agent memory layer and node stack | Keeps context from evaporating between sessions and agents | TypeScript monorepo, DKG node, CLI, dashboard, knowledge assets | Beta | repo, post |
| OpenADE | @bearlyai | Free open-source agentic development environment with plan, review, comments, and execution in one UI | Makes AI-generated changes easier to collaborate on and revise before execution | TypeScript, Claude Code, Codex, worktrees, offline-first app | Beta | repo, post |
| DefenseClaw | @AISecHub / Cisco AI Defense | Governance layer that inspects prompts, completions, and tool calls across multiple coding agents | Reduces risky actions, secret exfiltration, and missing audit trails | Go, policy engine, connector-based agent controls | Beta | repo, post |
9router is the clearest build pattern of the day because it directly answers the most repeated complaint: the workflow should not stop when a pricing tier or credit pool runs dry. Its public README claims 20-40% token savings through tool-output compression and positions the router as a stable local endpoint that lets the surrounding coding tool stay the same.
OriginTrail DKG and OpenADE point at a second pattern: people are adding structure around the agent rather than betting on raw prompting. DKG tries to make memory durable and verifiable across agents, while OpenADE tries to make planning, commenting, and revision first-class before execution. DefenseClaw extends the same impulse on the security side by treating prompt and tool-call governance as a product category of its own.
6. New and Notable¶
Copilot is now being evaluated as a model portfolio, not a single assistant¶
The useful new signal was not just that GitHub kept promoting Copilot CLI, but that users immediately discussed which model inside Copilot they wanted to use. @0xAbhiii pointed to Opus 4.7 inside Copilot for large-codebase work, while @burkeholland said GPT 5.5 had become his favorite Copilot model for design-heavy output even at a higher cost. Combined with @github and @code, the Copilot story now looks like distribution plus model choice, not just “GitHub has an assistant.”
Agent governance is becoming visible enough to market directly¶
A second notable shift is that governance is no longer hidden inside enterprise policy decks. @AISecHub advertised DefenseClaw in public as a layer for blocking, approving, and auditing agent behavior, while @origin_trail sold memory with provenance and verifiability rather than convenience alone. That makes safety and auditability look like top-level product surfaces in the AI coding stack.
7. Where the Opportunities Are¶
[+++] Cost-aware routing that preserves the developer's existing tool surface — The strongest pain and the strongest builder signal point at the same gap. Cache-heavy bills, one-day credit burn, paid-versus-free comparison charts, and 9router's rapid uptake all say users want graceful fallback without changing how they work.
[++] Shared memory with provenance and verification across agents — DKG V10, personal-OS memory folders, and “dreaming” workflows all point to the same missing default: context should survive, stay queryable, and remain reviewable after the session ends.
[++] Review and governance layers for AI-generated changes — OpenADE and DefenseClaw approach the problem from different sides, but both respond to the same market signal: teams want planning, comments, policy, and audit trails around agent output before it becomes production code.
[+] Smaller local models made usable through structured skills and tool discipline — The OpenCode plus Qwen3.5 9B discussion suggests that better harnessing and tighter skills can make weaker local models useful enough for real work, especially when premium-model cost pressure stays high.
8. Takeaways¶
- Copilot's public narrative broadened from “try the CLI” to “pick the right model and workflow inside it.” GitHub kept the beginner-series push on top of the feed while users surfaced Opus 4.7, GPT 5.5, and a public Dev Days event around agentic development. (source)
- Codex speed became the day’s most contested product lever. The ultrafast leak mattered because it gave people something concrete to argue about, and the replies immediately split between “loop time is the UX” and “faster may just mean worse answers.” (source)
- Memory and governance are separating into their own layer of the stack. OriginTrail, personal-OS workflows, and DefenseClaw all assume the base agent is not enough by itself; what matters next is durable memory, provenance, and policy around execution. (source)
- The economic pressure is still strong enough to create its own product category. Cache-heavy usage, short-lived credits, and free-alternative charts make routers and fallback systems feel like core infrastructure rather than optional optimization. (source)
- The backlash to low-understanding vibe coding is now explicit. The strongest skeptical posts were not anti-AI; they were anti-sloppy output that is hard to reuse, review, or maintain inside real teams. (source)