Twitter AI Coding - 2026-05-23¶
1. What People Are Talking About¶
1.1 Coding agents are turning into portable harnesses instead of closed products 🡕¶
The clearest shift on May 23 was that people talked about coding agents as interchangeable shells around model access, not as single-vendor destinations. The strongest evidence came from OpenAI's own Codex lead acknowledging that meaningful production traffic already sits on alternative harnesses, while OpenCode promotion and Codex workflow posts focused on routing, sessions, and device control rather than model novelty.
@thsottiaux said (302 likes, 56 replies, 6,265 views, 33 bookmarks) that about 5% of Codex production traffic is already running on Pi and another 5% on OpenCode, adding that a ChatGPT account can be used "in a flourishing set of other tools." That is not a speculative user comparison - it is an OpenAI product lead publicly describing alternative harnesses as real destinations for the same account.
@VaibhavSisinty argued (35 likes, 8 replies, 1,563 views, 33 bookmarks) that OpenCode is effectively a free, open-source Claude Code style workflow: terminal-native, able to read codebases, edit files, run commands, and connect to Claude, GPT, Gemini, DeepSeek, Qwen, Ollama, and existing ChatGPT Plus, Claude Pro, or GitHub Copilot subscriptions. The public opencode repository describes the tool as a terminal-based coding assistant with multiple provider support, session management, tool execution, persistent storage, and LSP integration.
@airkatakana said (28 likes, 3 replies, 1,240 views, 6 bookmarks) that "the codex app can do this whereas cli cant btw," and the attached screenshot showed the app opening a persistent SSH connection to a remote experiment server and waiting for an OTP before reusing the live shell for later steps.

@hqmank noted (11 likes, 2 replies, 1,662 views, 4 bookmarks) that his /goal workflow post had been liked by Tibo, and his quoted example described Codex App goal mode as a way to keep working across turns until done. The point was not just feature fandom. It was that long-running work and reusable workflows are now part of how people compare coding agents.
Discussion insight: Replies around Tibo's post did not ask which foundation model won. They asked why someone would stay inside one harness, whether Codex was still good without switching tools, and what exactly GPT access is for if Pi and OpenCode already expose it elsewhere.
Comparison to prior day: May 22 focused on shared servers, chat bridges, and BYOK shims around existing agents. May 23 moved one step further: OpenAI leadership publicly acknowledged off-platform Codex traffic, and users compared app-specific capabilities like persistent SSH sessions and /goal style autonomy.
1.2 Plan tiers, quotas, and bundle math are shaping coding-tool choice 🡕¶
The second major theme was that subscription economics and quota visibility were no longer background details. Multiple posts treated the real product question as "what do I actually get for $20?" and "how much work can I really do before the bar resets?" rather than "which model is best in the abstract?"
@adahstwt asked (49 likes, 58 replies, 1,678 views) what someone should buy if they could afford only one subscription: Claude, Codex, Cursor, Antigravity, or GitHub Copilot. That framing captured the day well: people were actively choosing between coding products on budget, not stacking them without tradeoffs.
@vikaskansalHQ said (69 likes, 9 replies, 8,146 views) that Google's higher-tier Ultra plan carries 20x AI usage while the lower Ultra tier carries 5x for Gemini app and Antigravity, while Google's AI plans page separately confirms that paid Google AI plans explicitly market expanded limits in Antigravity, AI Studio, and related developer tools as a plan benefit.
@Presidentlin wrote (16 likes, 1,745 views, 3 bookmarks) after a "decent sprint" that Antigravity still needed 7-day tracking, cached-token visibility, and percentages instead of the existing progress bar. He added that Antigravity 2.0 and the CLI were deleted because 2.0 lacked WSL support, even though the IDE stayed installed.
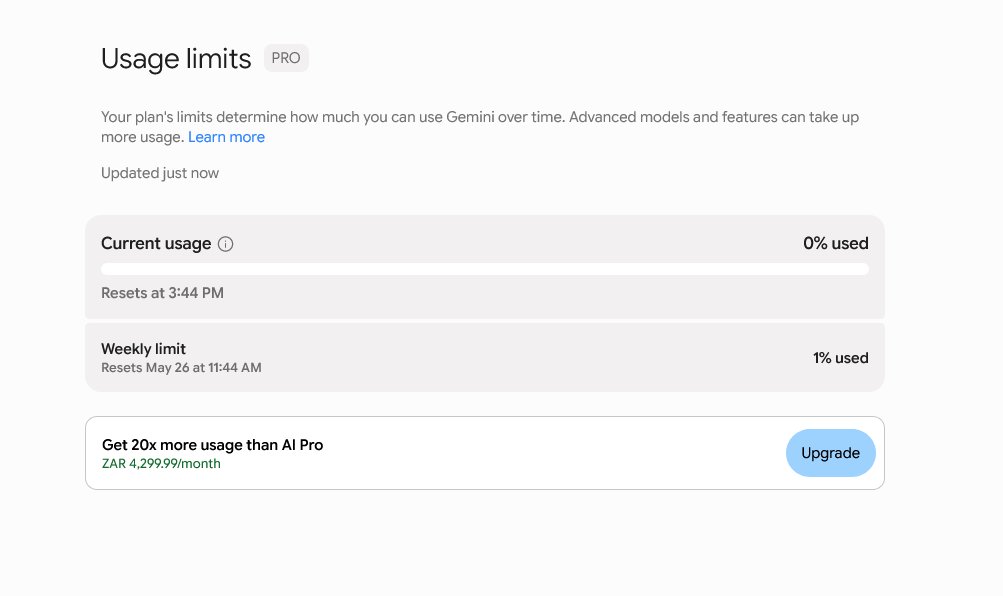

@Asteri_eth argued (22 likes, 13 replies, 179 views) that Google AI Pro had become unusually strong bundle value because it now combined Gemini Pro access, NotebookLM Pro, Antigravity access, and YouTube Premium Lite. The attached screenshot explicitly showed the Premium Lite perk:

Discussion insight: The replies were about comparability and transparency, not benchmark lore. Users wanted to know which subscription exhausted itself fastest, whether "Pro" actually meant usable daily limits, and why key usage data stayed hidden behind vague bars and refresh clocks.
Comparison to prior day: May 22 already had quota-burn complaints for Codex and Antigravity. May 23 added more explicit plan screenshots, bundle composition arguments, and direct product requests for cached-token visibility and seven-day tracking.
1.3 Skills, MCP servers, and indexed context are becoming real product surfaces 🡕¶
Another strong cluster treated skills and context tooling as shipping software, not prompt folklore. The day's evidence spanned a first-party Copilot CLI skill, a GitHub repo leaderboard dominated by agent infrastructure, a public challenge built around MCP customization, and a book chapter explicitly teaching cross-client skill support.
@msdev announced (77 likes, 4 replies, 4,940 views, 40 bookmarks) the MicrosoftBuild CLI, a GitHub Copilot CLI skill that brings the Build session catalog into the terminal, recommends sessions based on local dependencies, and scaffolds working code from what a developer learns. The public microsoft/Build-CLI repository says the skill reads files like package.json, requirements.txt, .csproj, and go.mod, maps them to Microsoft products, queries the live Build 2026 catalog, and can scaffold projects from sessions through Copilot CLI.
@sharbel posted (10 likes, 3 replies, 215 views, 4 bookmarks) a fastest-growing-repos list whose top entries were almost entirely agent infrastructure: colbymchenry/codegraph at +14.1K stars, Imbad0202/academic-research-skills at +11.6K, and rohitg00/agentmemory at +6.9K.

The public colbymchenry/codegraph repository describes a pre-indexed code knowledge graph that auto-configures Claude Code, Cursor, Codex CLI, OpenCode, and Hermes Agent. Its published benchmark table claims median savings of 35% cost, 59% tokens, 49% time, and 70% tool calls across seven open-source codebases.
@kurlyk27 summarized (8 likes, 6 replies, 61 views) SentientAGI's Challenge 0 as a coding-agent competition where Codex, OpenHands, Goose, or OpenCode can be customized through one YAML file plus skills files and MCP servers, then evaluated in an offline container with no network access against Treasury-document questions. The interesting part was not the leaderboard. It was that MCP tooling and extra skill context were treated as first-class competition primitives.
@nerdai posted (3 likes, 476 views, 4 bookmarks) that a new Manning chapter on multi-agent systems teaches Agent Skills as an open standard now used by Claude Code, Cursor, Gemini CLI, VS Code, GitHub Copilot, Codex, and others. Separately, the public academic-research-skills repository describes itself as an installable suite of Claude Code skills for research workflows and distributes them through a plugin marketplace.
Discussion insight: The center of gravity has shifted from "how should I prompt this?" to "what module should I install, index, bundle, or wire into the harness?" Even the public challenge format assumes that skills and MCP subprocesses are the normal way to extend a coding agent.
Comparison to prior day: May 22 made skills visible through catalogs and workflow dashboards. May 23 widened the frame to first-party CLI skills, leaderboard winners, marketplace-distributed skill packs, and challenge rules that explicitly reward context and tool packaging.
1.4 Vibe coding is becoming both a product philosophy and a prototyping habit 🡒¶
The final recurring theme was less about a specific vendor and more about how people justify or practice AI-assisted creation. The evidence split between ideological defense of vibe coding and concrete solo prototypes built with agent tools.
@dhh argued (83 likes, 6 replies, 3,651 views) that recoiling from vibe coding is incompatible with the ideals of open source: if open source is about giving more people the power to change software, then AI-assisted coding should be seen as "Open The Gates," not a reason to erect new ones.
@ivanfioravanti showed (12 likes, 3 replies, 993 views, 5 bookmarks) a Wipeout-style racing prototype being built with OpenCode and ds4-agent --power 50. The thread became unusually specific when he pasted the exact phased prompt: Three.js from a CDN, single-file index.html, fixed-timestep physics, air brakes, Catmull-Rom track, lap validation, and a chase camera. He also noted that Grok 4.3 had failed on the same brief, which turned the tweet into a lightweight comparative test rather than pure hype.
@om_patel5 shared (6 likes, 2 replies, 426 views) a browser game called "Under Training" where the player experiences raw data ingestion, training, inference, and evaluation as if they were a large language model. The concept was described as "ADHD the game," but the more substantive reply asked whether the design also captured context-window slippage and mutated tool calls - a sign that even whimsical vibe-coded projects are being judged by how honestly they depict agent failure modes.
Discussion insight: Supporters were not arguing that review no longer matters. They were arguing that AI-assisted creation broadens who can build, while the replies kept pulling the conversation back toward verification, trust, and whether the artifacts survive contact with real constraints.
Comparison to prior day: May 22's build stories were mostly about wrappers, bridges, and team control planes around existing agents. May 23 added more solo experiments, more cultural defense of vibe coding itself, and more examples of people using agents to get playable or publishable artifacts quickly.
2. What Frustrates People¶
Quota math and pricing are still opaque enough to distort buying decisions¶
Severity: High. The frustration was not just that coding tools cost money. It was that users still could not tell what they were buying. @SouthernValue95 wrote (76 likes, 11 replies, 7,370 views, 77 bookmarks) that a GitHub Copilot customer had been quoted a 10x price increase to about $300 per month, using that as one input in a crude but concrete AI TAM model. @adahstwt asked the one-subscription question directly, while @Presidentlin complained that Antigravity still did not expose cached tokens, percentages, or a usable seven-day view. @vikaskansalHQ added that Google's higher-paid tier carries 20x AI usage versus 5x on the lower one. The coping pattern is manual comparison shopping and social polling instead of first-party clarity. This looks worth building for because it affects product selection before people even evaluate output quality.
Product behavior keeps diverging across app, CLI, and mode boundaries¶
Severity: Medium-High. Several posts described the problem as feature fragmentation, not raw model weakness. @airkatakana said the Codex app could do things the CLI could not, using the persistent SSH screenshot as proof. @Presidentlin said Antigravity 2.0 still lacked WSL support and drove him back to the IDE. @anumness wrote (24 likes, 6 replies, 1,055 views) that Claude's split between Chat, Cowork, and Code made it hard to think of the product as a coherent chat app at all. The workaround is to maintain separate mental models - one product for chat, one for code, one shell for long tasks - but that fragmentation is exactly what users are tiring of.
Ambient input and voice-first workflows still fail in messy, real-world ways¶
Severity: Medium. @katienotopoulos reported (6 likes, 4 replies, 1,291 views) that Wispr Flow kept accidentally recording background audio and transcribing it into the Business Insider CMS, Slack, and other work surfaces, including a private argument and TV dialogue. She later quoted the CEO calling it "Final Destination" for voice transcription. This is a different class of frustration from quota math: hands-free coding tools can create social and privacy failures even when the model itself is fine. The current coping mechanism is simply being more careful with hotkeys, which is not a durable fix.
3. What People Wish Existed¶
A neutral usage dashboard that explains limits across all coding tools¶
The strongest unmet need was a control plane for quotas and resets. @Presidentlin wanted cached-token visibility, percentages, and seven-day tracking inside Antigravity. @adahstwt turned subscription choice into a public question because the market still does not make these tradeoffs legible. @SouthernValue95 and @vikaskansalHQ supplied the pricing and plan-tier evidence for why this matters. Opportunity: direct.
Long-running work that survives the choice of shell or device¶
The feed repeatedly implied that users want durable work loops, not one more chat box. @hqmank highlighted Codex App's /goal workflow for work that continues across turns, while @airkatakana showed the value of an app surface that can hold a persistent SSH session. @thsottiaux confirmed that alternative Codex harnesses are already pulling real traffic. The missing product is a portable work state that follows the user across app, CLI, and third-party shells instead of being locked to one interface. Opportunity: direct and competitive.
Trusted, reusable skill and context packages that work across clients¶
The evidence for this need was unusually broad. @msdev shipped Build CLI as an installable Copilot skill, @nerdai framed skills as a cross-client standard, and @kurlyk27 described a public challenge where skills files and MCP servers are the normal way to extend a coding agent. Users already want this. What is still missing is a clearly trusted way to package, audit, and share those modules across vendors. Opportunity: direct.
A persistent coding "second brain" that compounds instead of resetting¶
@cyrilXBT described (11 likes, 1 reply, 125 views) Claude Code plus Obsidian as "an AI that actually knows you" - goals, context, and history - instead of a chatbot that must be re-briefed every session. That is a practical need, not just a poetic one. It captures why so many adjacent tools now emphasize memory, indexed context, and reusable workflows. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| OpenAI Codex | Coding agent | (+/-) | Strong mindshare, /goal workflow, app can hold remote sessions, still treated as a reference point in comparison threads |
Users complain about app/CLI gaps, still described as early, and sits inside a noisy pricing debate |
| OpenCode | Open-source coding agent | (+) | BYOM routing, can use existing paid subscriptions, terminal-native workflow, growing community attention | Most evidence still frames it relative to Codex or Claude Code rather than as an established incumbent |
| Google Antigravity | Agent IDE / runtime | (+/-) | NotebookLM pairing, broad Google bundle, some users say it keeps up on real work | Quota opacity, weak tracking UX, WSL and CLI complaints |
| GitHub Copilot | Coding assistant / harness | (+/-) | Enterprise presence, plugin ecosystem, Build CLI extends it with project-aware conference search | Price-shock reports and jokes that some "AI transformation" is just buying a subscription |
| Claude Code | Coding agent | (+/-) | Respected as a serious workflow surface, inspires infrastructure-heavy setups and persistent-memory experiments | Expensive enough to dominate one-subscription tradeoffs and often overlaps awkwardly with Claude's other product modes |
| CodeGraph | Context / indexing tool | (+) | Pre-indexed knowledge graph, published repo benchmarks claim 35% lower cost and 59% fewer tokens | Requires an indexing/setup step and still needs real-world validation per project |
| NotebookLM | Research / context tool | (+) | Research-to-report workflow, useful input layer for Antigravity setups, bundled into Google AI plans | Today's evidence is mostly setup and bundle marketing rather than neutral production reporting |
| MicrosoftBuild CLI | Copilot CLI skill | (+) | Reads dependency files, finds relevant Build sessions, scaffolds code from sessions, integrates with Learn MCP | Event-scoped and network-dependent, so it complements rather than replaces broader coding tools |
The overall pattern was not mass migration to one winner. It was selective stacking. Users route work between Codex, OpenCode, Claude Code, Antigravity, and Copilot based on quotas, interface shape, and how much control they have over context. Open-source infrastructure tools such as CodeGraph are gaining traction because they reduce token waste without forcing a model switch, while paid suites compete increasingly on bundle value and usage visibility rather than pure model branding.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| MicrosoftBuild CLI | @msdev | Brings the Build session catalog into Copilot CLI, recommends sessions from local dependencies, and can scaffold code from sessions | Conference learning is disconnected from the live project in the terminal | GitHub Copilot CLI skill, Build catalog API, Microsoft Learn MCP, Node.js | Shipped | repo, post |
| CodeGraph | colbymchenry | Pre-indexes a codebase into a knowledge graph that coding agents can query instead of re-scanning files | Too many tokens, tool calls, and repeated file reads during codebase exploration | CLI installer, pre-indexed graph, agent integrations for Claude Code, Cursor, Codex CLI, OpenCode, Hermes Agent | Shipped | repo, post |
| Bidsstack updates built with Antigravity | @Presidentlin | Added tender pages, awarded-email alerts, pipeline board, and calendar improvements to a live product | Tender-tracking users needed more workflow value at a lower plan price | Antigravity-assisted development, web app with Kanban and calendar surfaces | Shipped | post |
| Wipeout-style prototype | @ivanfioravanti | Builds a browser racing prototype in phased steps with a detailed agent prompt | Tests whether current coding agents can deliver a non-trivial playable prototype with explicit constraints | Three.js, OpenCode, ds4-agent, single-file HTML prototype | Alpha | post |
The most important project signal was not that people were founding entirely new coding-agent categories. It was that they were building narrow, useful layers around existing agents. Build CLI turns conference material into project-aware terminal context. CodeGraph turns a repo into a reusable graph so agents stop paying the same exploration cost every run.
The smaller builder examples point in the same direction. Bidsstack used Antigravity for concrete product iteration, not demo theater, while the Wipeout prototype showed that solo developers are comfortable using agent tools for complex, staged builds as long as they can constrain the task tightly.
6. New and Notable¶
Offline, tool-augmented agent evals are getting more concrete¶
@kurlyk27 described SentientAGI's Arena Challenge 0 as an offline evaluation where agents must answer numerical questions across 697 Treasury Bulletin documents with no internet, one YAML configuration file, and optional MCP servers or skills bundles. That matters because it treats coding-agent extensions as measurable infrastructure under constrained conditions, not just community conventions.
Skills are turning into an education and distribution category of their own¶
@nerdai used a Manning book chapter to teach Agent Skills as an interoperable standard, while the fastest-growing-repos list elevated academic-research-skills, agentmemory, and codegraph at the same time. The novel signal is not only that people build skills. It is that learning materials, marketplaces, and leaderboard momentum are starting to reinforce one another.
7. Where the Opportunities Are¶
[+++] Cross-tool usage and billing visibility - Subscription polls, tier screenshots, a quoted Copilot jump to roughly $300 per seat, and explicit requests for cached-token and seven-day tracking all point to the same gap: users still cannot see or compare their real coding-agent budget clearly.
[++] Portable goal mode and remote work state - Codex App's persistent SSH example, /goal workflow posts, and Tibo's acknowledgement of Pi and OpenCode traffic all suggest demand for a durable work state that is not trapped inside one shell.
[++] Safe skill and context distribution - Build CLI, CodeGraph, academic-research-skills, and the Sentient challenge all depend on installable modules, indexed context, or MCP subprocesses. The missing layer is trust, auditability, and portable packaging across clients.
[+] Personal coding memory that compounds over time - The Claude Code plus Obsidian "second brain" pattern shows an emerging desire for an AI coding partner that remembers goals, context, and previous decisions instead of resetting every session.
8. Takeaways¶
- The harness is becoming the product. OpenAI's Codex lead publicly said meaningful production traffic already runs through Pi and OpenCode, while users compared SSH persistence and goal mode rather than only model quality. (source)
- Quota UX now shapes adoption as much as raw capability. Subscription-choice threads, Antigravity limit screenshots, and plan-tier comparisons showed that visibility into usage and resets is now a core product requirement. (source)
- Skills and indexed context have crossed from advice into software. Build CLI, CodeGraph, marketplace skills, and the Sentient arena all treated skills, MCP servers, and indexes as installable infrastructure. (source)
- Vibe coding is producing real prototypes, not just jokes. The Wipeout-style build, Bidsstack iteration, and browser-playable "Under Training" example show people using agents to ship or test concrete artifacts quickly. (source)