Twitter AI Coding - 2026-05-26¶
1. What People Are Talking About¶
1.1 Antigravity CLI became a migration and onboarding story, not just a launch story 🡕¶
The strongest cluster was about moving existing workflows onto Google's new harness. Google used its official developer account to package Antigravity 2.0 as part of a broader developer update, while the rest of the feed immediately filled in the practical layer with long tutorials, migration threads, and correction posts responding to confusion about whether Antigravity was expanding or being abandoned. The important shift was that AI-coding competition looked less like "whose model is best" and more like "whose terminal workflow can absorb a migration without breaking habits."
@googledevs announced (117 likes, 5 replies, 8,582 views, 27 bookmarks) that Google had shipped Gemini 3.5 Flash improvements and Antigravity 2.0 as a CLI for building local agents. The replies were less excited about the headline than about practical readiness: one asked whether the CLI would work in production instead of demos, another said local agent tooling was finally polished enough to test seriously.
@minchoi framed (33 likes, 15 replies, 5,321 views, 13 bookmarks) the release as Google's answer to Claude Code, Codex, and Grok Build in the terminal. The quoted Antigravity post made the product positioning explicit: same harness, same models, but adapted to the command line with user-specific keybindings, themes, and workflows. The replies sharpened the real market question: if the models are close, the harness and switching cost become the product.
@RoundtableSpace posted (63 likes, 7 replies, 47,584 views, 55 bookmarks) a four-hour Antigravity tutorial, which is a stronger signal than another launch thread. Tutorial demand that long usually means users are trying to operationalize a tool, not just admire it.
@LyalinDotCom asked (29 likes, 15 replies, 3,106 views, 4 bookmarks) how to make the Gemini CLI to Antigravity CLI transition smoother for Google One users, quoting a request for ACP support, more robust headless mode, subagents, and Gemini CLI extensions. That is the most direct statement of the migration gap in the dataset.
@ravikiran_dev7 wondered (59 likes, 46 replies, 1,313 views, 3 bookmarks) whether Antigravity was being shut down because activity looked quiet. The replies corrected that interpretation and said Google was doubling down by folding Gemini CLI into Antigravity CLI instead.
Discussion insight: The replies did not treat the move as a clean upgrade. They focused on missing headless features, extension parity, production reliability, and whether teams would really switch if the harness did not offer more than a new UI surface.
Comparison to prior day: May 25 was still about Antigravity's cheaper tiers and quota resets. May 26 moved one layer deeper into migration mechanics, tutorials, and the operational friction of replacing Gemini CLI with Antigravity CLI.
1.2 Pricing, limits, and policy controls are shaping harness choice as much as capability 🡕¶
The feed still talked about capability, but the concrete evidence was increasingly administrative: org-level model rules, exhausted session limits, usage-credit screenshots, and budget threads asking which $20 tool was actually worth it. The AI-coding conversation is now visibly about how to control spend and model access, not only how to maximize output.
@lochan_twt claimed (626 likes, 21 replies, 254,432 views, 109 bookmarks) that Microsoft was canceling internal Claude Code licenses and moving teams back to GitHub Copilot, tying the story to Uber's public comments about AI spend getting harder to justify. The replies immediately split between correction and reinforcement, which is itself notable: the community was arguing over harness preference, cost control, and whether the change reflected reduced enthusiasm or a narrower product choice.
@DrNassiriAfshar countered (4 likes, 1 reply, 2,626 views) that the move was not an AI ban but a shift toward Copilot CLI for dogfooding, cost, and security consolidation. @trengriffin argued (1 like, 341 views) that the harness switch did not necessarily reduce Anthropic spend if Opus was still paid for via enterprise API usage. Together, those posts made the day's Microsoft discussion less about one verified fact pattern and more about a contested interpretation of harness economics.
@GHchangelog reported (5 likes, 983 views, 3 bookmarks) that GitHub Copilot model rules entered public preview for enterprise owners. The linked GitHub changelog says enterprises can now target specific Copilot models to specific organizations instead of relying on a single enterprise-wide default, which pushes cost and compliance control directly into the admin surface.
@HarshithLucky3 reported (48 likes, 5 replies, 2,286 views, 3 bookmarks) that Codex limits were dropping too quickly even for a simple frontend task. The replies turned into plan-management tactics, including one user saying Grok Build handled the same workload without throttling and another explicitly asking for a "subscription bench" to measure usage over time.
@KaiXCreator asked (28 likes, 44 replies, 1,956 views) which tool was the best use of a $20 budget across Claude, Codex, Cursor, Antigravity, and GitHub Copilot. The best reply rejected the one-winner framing and instead described a mixed stack of OpenCode, DeepSeek, Claude, ChatGPT, Gemini, and Manus, each assigned to a specific job.
Discussion insight: Replies consistently pulled against single-tool loyalty. They pushed toward portfolio usage, explicit bottleneck analysis, and admin-side controls instead of assuming that one premium harness should handle every task.
Comparison to prior day: May 25 already showed quota pain and premium-model multiplier anxiety. May 26 added harder governance evidence: Copilot model rules, exhausted Codex sessions, and public threads where even hobby budgets were framed as allocation problems.
1.3 The durable layer above the model is shipping as prompts, memory, automation, and telemetry 🡕¶
The most credible builder activity did not try to dethrone Claude Code, Codex, Copilot, or Antigravity directly. It wrapped them with reusable prompt libraries, durable markdown memory, NotebookLM automation, and endpoint telemetry. That is a strong sign the market sees the harness as stable enough that the next leverage sits one layer above it.
@_vmlops highlighted (11 likes, 2 replies, 541 views, 4 bookmarks) OpenAI's ready-to-use prompt library for Codex, arguing that the useful part was not one-line prompt snippets but project workflows and automations that can translate to Claude Code, Cursor, and other agents. A reply sharpened that idea further: prompt libraries matter when they behave like checklists a team can bend to its own stack.
@awakecoding asked (6 likes, 2 replies, 593 views) for a dedicated custom-instructions file just for Copilot review agents, separate from the instructions used for normal Copilot work. The linked GitHub Docs page confirms that Copilot already supports repository-wide instructions, path-specific instructions, and AGENTS.md files, which makes the absence of a clearly separated review-only surface more visible.
@PawelHuryn argued (1 like, 144 views, 2 bookmarks) that the learnable layer is larger than one skill file: data, hypotheses, rules, and procedures should evolve together across Claude Code, Codex, and Cowork. The linked PM Brain repo turns that into a product: a markdown-based second brain for product managers that stores hypotheses, decisions, stakeholders, and ingestion artifacts locally rather than in a hidden memory layer.
@GithubProjects shared (9 likes, 630 views, 6 bookmarks) notebooklm-py, and the repository README says it exposes NotebookLM through Python, CLI, and agent integrations for Claude Code, Codex, and OpenClaw, with research automation, artifact downloads, and export paths the web UI does not expose.

@jqdsouza said (5 likes, 3 replies, 115 views) Agent Beacon had already added Antigravity CLI support after Google's transition announcement. The Agent Beacon repository describes it as a local telemetry layer that captures prompts, tool use, and file edits across Claude Code, Codex CLI, Cursor, Copilot CLI, Antigravity CLI, and other harnesses, then forwards normalized events to local dashboards or SIEM pipelines.
@MichaelGannotti argued (8 likes, 5 replies, 160 views) that the real bottleneck in multi-agent coding is semantic coherence, not git mechanics, and that AGENTS.md files, skills, and structured memory are the current best pattern for sharing a world model across concurrent agents.
Discussion insight: The practical refrain was consistency, not cleverness. Prompt libraries needed to be adaptable, memory needed to be local and inspectable, and multi-agent systems needed a shared state model rather than a benchmark leaderboard.
Comparison to prior day: May 25 emphasized rules, skills, and memory as emerging advantages. May 26 showed those ideas taking product form in prompt packs, markdown brains, NotebookLM bridges, and cross-harness telemetry.
2. What Frustrates People¶
Migration clarity is still behind launch messaging¶
Severity: High. @LyalinDotCom asked (29 likes, 15 replies, 3,106 views, 4 bookmarks) what Google needed to fix so Gemini CLI users would actually move to Antigravity CLI, and the quoted thread named the missing pieces directly: ACP support, stronger headless mode, subagents, and extension compatibility. @ravikiran_dev7 showed (59 likes, 46 replies, 1,313 views, 3 bookmarks) how quickly launch silence can turn into shutdown rumors, while replies under @googledevs asked whether the CLI was ready for production rather than demos. The coping pattern is obvious: users reach for long tutorials, transition threads, and community corrections because the migration path still feels underexplained. This looks worth building for because the friction is attached to existing high-intent users, not casual observers.
Limits and credit management are interrupting work before the task is done¶
Severity: High. @HarshithLucky3 showed (48 likes, 5 replies, 2,286 views, 3 bookmarks) that a simple frontend task could exhaust Codex limits faster than expected, and the replies immediately shifted to careful plan use, alternative harnesses, and a request for a subscription benchmark product. @KaiXCreator surfaced (28 likes, 44 replies, 1,956 views) the same issue from the buyer side by asking which tool was the best use of a $20 budget. Even a low-visibility complaint from @BlaineGrant85 included (1 like, 1 reply, 15 views, 1 bookmark) screenshots of a fully used current session, a $4.11 monthly spend meter, a $45 bulk-credit purchase option, and a $15.89 balance with prior $20 invoices. People are coping by spreading tasks across multiple subscriptions, buying credits, or switching harnesses for specific workloads. This is worth building for because the pain is task-breaking and continuous.
Multi-agent coding still lacks a reliable coordination layer¶
Severity: Medium. @MichaelGannotti argued (8 likes, 5 replies, 160 views) that the hard problem is not parallel execution itself but keeping several agents semantically coherent while they touch the same codebase. His examples were concrete: agents making isolated changes that conflict semantically, git solving merges but not world-model drift, and context windows acting as coordination limits. The coping pattern today is AGENTS.md files, skills, structured memory, and very explicit lane assignment. This is worth building for because it points to a deeper infrastructure gap than one-off model regressions.
3. What People Wish Existed¶
Separate review-agent instructions instead of one shared instruction surface¶
@awakecoding asked (6 likes, 2 replies, 593 views) for a dedicated file for Copilot review instructions rather than reusing the same instruction surface as normal Copilot work. GitHub's docs already document repository-wide custom instructions, path-specific instructions, and AGENTS.md files, so the remaining ask is not generic customization but cleaner scope separation for review behavior. Opportunity: direct.
Better quota forecasting and cross-plan usage benchmarks¶
The strongest unmet need was instrumentation that tells people what a task will cost before the session ends. The reply asking for a "subscription bench" under @HarshithLucky3 and the budget-shopping thread under @KaiXCreator both point to the same gap: users want a neutral way to compare real output per dollar across plans and harnesses, not just marketing claims. Opportunity: direct.
Migration kits that preserve extensions, headless mode, and habits¶
The quoted transition thread under @LyalinDotCom explicitly called out missing headless support, extensions, ACP, and subagents during the Gemini CLI to Antigravity CLI handoff. People are not asking for another launch video. They are asking for a way to carry established workflows across harnesses with minimal loss. Opportunity: direct and competitive.
Mobile-first vibe coding workflows¶
@aditiitwt asked (17 likes, 18 replies, 188 views) why vibe coding discourse keeps ending in web apps instead of Android or iOS builds. The post is small, but the engagement-to-view ratio is high enough to treat it as a real frustration rather than a joke. This looks like a practical need around better mobile scaffolds, testing loops, and deployment support rather than a purely emotional complaint. Opportunity: direct but still emerging.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Antigravity CLI / Antigravity 2.0 | Coding agent / CLI | (+/-) | Terminal-native harness, same-model continuity, strong tutorial demand, explicit migration path from Gemini CLI | Headless-mode gaps, extension questions, and production-readiness doubts keep surfacing |
| GitHub Copilot / Copilot CLI | Coding assistant / harness | (+/-) | Enterprise model rules, broad deployment surface, reusable workflow stories | Review-specific customization still feels incomplete, and some adoption is framed as governance rather than preference |
| Claude Code | Coding agent | (+/-) | Still the reference harness in debates about capability, memory layers, and workflow quality | Budget and governance debates keep attaching to it, especially in enterprise settings |
| OpenAI Codex | Coding agent | (+/-) | Reusable prompt libraries, community momentum, broad comparison point in buyer threads | Users report faster-than-expected limit exhaustion and need to manage plans carefully |
| notebooklm-py + NotebookLM | Research automation / knowledge layer | (+) | Turns NotebookLM into a Python, CLI, and agent-friendly research pipeline with exports the web UI lacks | The repo warns it relies on undocumented Google APIs and can break or throttle |
| PM Brain | Memory / workflow layer | (+) | Local markdown memory for hypotheses, decisions, and stakeholders across multiple harnesses | Early-stage product that demands deliberate structure and human maintenance |
| Agent Beacon | Security / telemetry | (+) | Cross-harness endpoint visibility with local dashboard and SIEM forwarding, already updated for Antigravity CLI | Geared more toward security and IT operations than everyday individual productivity |
Overall sentiment was best for tools that made a harness more durable: memory layers, telemetry, or research automation that can survive a model change. Satisfaction dropped when the tool forced users into migration work, hidden limit management, or unclear review behavior. The main migration pattern was not one clean switch from tool A to tool B. It was multi-homing: people keep multiple harnesses active, assign them to different jobs, and increasingly judge them by control surfaces and policy knobs rather than only by model quality.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| notebooklm-py | teng-lin | Exposes NotebookLM through Python, CLI, and agent integrations | NotebookLM's web UI hides useful automation and export paths that researchers and agents want programmatically | Python, CLI, undocumented NotebookLM APIs, Claude Code, Codex, OpenClaw | Shipped | repo |
| PM Brain | @PawelHuryn | Builds a local markdown second brain for product work | Teams need persistent, inspectable context for decisions, hypotheses, and stakeholders instead of ephemeral session memory | Markdown, Claude Code skill, local files, companion skill modules | Beta | repo |
| Agent Beacon | Asymptote Labs | Captures prompts, tool use, and file edits across local agent harnesses | Security and IT teams need consistent endpoint visibility while agent workflows spread across CLIs and IDEs | Go, local dashboard, JSONL telemetry, SIEM integrations, hook adapters | Shipped | repo |
@GithubProjects shared (9 likes, 630 views, 6 bookmarks) notebooklm-py as a bridge from NotebookLM into coding-agent workflows. The repository description is unusually concrete: batch downloads, audio and video artifacts, quizzes, flashcards, mind maps, and research agents, all through Python, CLI, or agent integrations. That is the clearest example today of AI-coding builders expanding adjacent knowledge tools instead of building another general-purpose code chat.
@PawelHuryn wrote (1 like, 144 views, 2 bookmarks) that the learnable layer is broader than one skill file, and the PM Brain repo turns that into an explicit product thesis: markdown folders for durable context, provenance tags, and recurring sweep loops rather than invisible memory tricks. The distinction matters because it makes the "memory layer" inspectable and portable across Claude Code, Codex, and Cowork.
@jqdsouza said (5 likes, 3 replies, 115 views) Agent Beacon had already added Antigravity CLI support. That is an important builder pattern: not replacing the harness, but making sure security and IT teams can keep their observability surface stable while the harness layer keeps changing.
The repeated build pattern was clear across all three projects: wrap the existing agent ecosystem with durable context, research automation, or operations telemetry instead of fighting to win the agent race outright.
6. New and Notable¶
Search attention still looks concentrated among power users¶
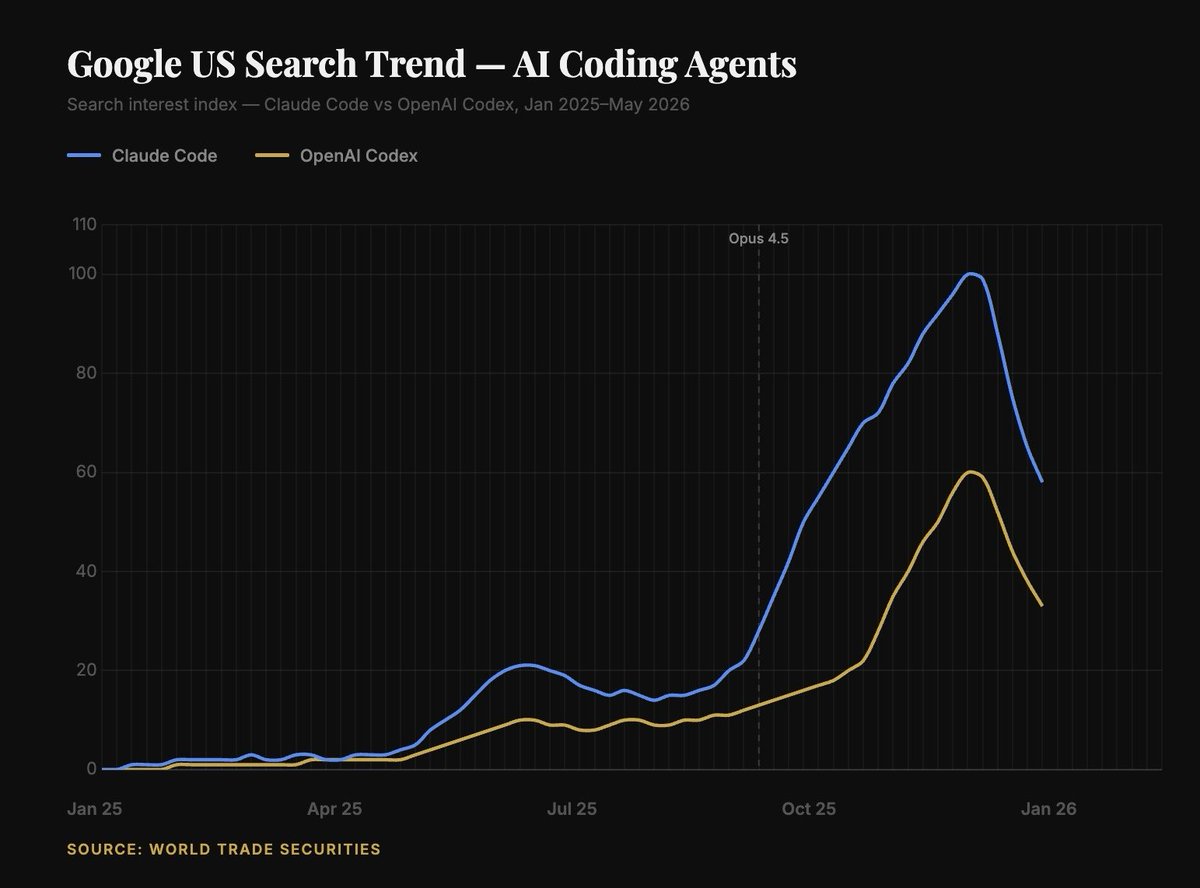
@RealNickMugalli argued (2 likes, 2 retweets, 826 views) that Claude Code search interest rose roughly 100x after Opus 4.5 and that Codex followed with a lag. The attached chart is not a broad labor-market measure, and he explicitly contrasted it with much lower self-reported everyday AI usage across all workers. That makes it a useful directional signal: AI-coding intensity still appears concentrated among a relatively small set of heavy users.
Security tooling is reacting almost immediately to harness churn¶
@jqdsouza noted (5 likes, 3 replies, 115 views) that customers were already asking whether Agent Beacon would support Antigravity CLI after Google's transition announcement, and the answer was yes in the latest release. That matters because it shows enterprise operations adapting to new harnesses on roughly the same time horizon as builders and power users.
7. Where the Opportunities Are¶
[+++] Migration, quota forecasting, and policy control for multi-harness teams — Section 1 showed the Gemini CLI to Antigravity CLI move turning into documentation and parity work, while Section 2 showed Codex limits, usage credits, and Copilot model rules entering everyday decision-making. The strongest opportunity is a control layer that helps teams move, meter, and govern several harnesses at once.
[++] Durable workflow memory and review-specific instruction layers — Section 1.3, Section 3, and Section 5 all pointed at the same gap: people want reusable prompts, scoped review behavior, and inspectable long-lived context that survives model and harness changes.
[++] Coordination tooling for multi-agent coding systems — Michael Gannotti's orchestration argument and the rise of AGENTS.md-style coordination suggest a moderate opportunity in shared world models, semantic conflict detection, and agent-to-agent coordination surfaces.
[+] Mobile-native vibe coding stacks — The evidence is thinner, but the Android and iOS gap appeared clearly enough to count as an emerging opening for better mobile-oriented scaffolds, test loops, and deployment tooling.
8. Takeaways¶
- Antigravity's competition story is now about migration, not just announcement-day novelty. The official Google update was quickly overshadowed by tutorials, transition threads, and parity questions for Gemini CLI users. (source)
- Budget and governance surfaces are becoming daily product surfaces. Codex limit screenshots, $20 tool-shopping debates, and Copilot model rules all point to users managing spend and model access more explicitly. (source)
- The strongest new products wrap existing agents instead of replacing them. notebooklm-py, PM Brain, and Agent Beacon all add automation, memory, or telemetry around existing harnesses. (source)
- Reusable instructions and durable context are still underbuilt. The Copilot review-instructions request, PM Brain, and Codex prompt-library discussion all point to demand for context that can be scoped, reused, and inspected. (source)
- Some important gaps are still very basic workflow gaps. The feed still lacked a convincing answer for mobile-first vibe coding and for multi-agent semantic coordination beyond manual lane assignment. (source)