Twitter AI - 2026-06-06¶
1. What People Are Talking About¶
1.1 AI infrastructure is being priced as a supply-chain problem (🡕)¶
The most forceful discussion today was not about model quality. It was about whether photonics programs, grid-connected power, and merchant GPU capacity can actually arrive on time. At least three of the day’s strongest infrastructure threads treated AI upside as a delivery problem first and a software problem second.
@aleabitoreddit argued (575 likes, 111 replies, 70,131 views) that XFAB could become a European co-packaged-optics beneficiary ahead of a 2027-2028 scale-up window. The attached photonixFAB materials matter because they move the post beyond ticker hype: the screenshot names Nokia for specification, assembly, and performance evaluation, and names NVIDIA as the end-user tester for transceiver and optical-switch demonstrators. In replies, the thread also picked up a useful correction: one reader noted Nokia’s investment context was AI RAN rather than switches, and the author acknowledged the point.

@Agrippa_Inv argued (266 likes, 29 replies, 12,654 views) that the real moat for IREN is not branding but secured grid-connected power. The supporting chart shows roughly 18 GW of scheduled U.S. data-center capacity additions against about 11 GW actually realized over the last six quarters, which he uses to frame delayed grid access and project cancellations as the main bottleneck. The thesis is explicitly comparative: once grid queues stretch past five years, behind-the-meter generation becomes the fallback rather than the preferred design.

@TheValueist argued (10 likes, 2 replies, 3,554 views) that SpaceX’s Google agreement should be read as merchant AI infrastructure rather than guaranteed backlog. The filing excerpt in the image shows access to about 110,000 NVIDIA GPUs at $920 million per month, while the thread text emphasizes pro-rata reductions and termination rights if capacity is not delivered on schedule.

Discussion insight: The strongest pushback in this cluster was not “AI demand is fake,” but “delivery is hard.” In reply to the XFAB post, one reader argued that a 2027 CPO ramp would still require multi-billion-dollar fab and power commitments years in advance, which reinforces rather than cancels the broader supply-side concern.
Comparison to prior day: On June 5, @PalantirTech framed (658 likes, 32 replies, 4,574,270 views) AI around owning the application layer, and @OfficialLoganK said (446 likes, 56 replies, 23,319 views) that public benchmarks were the obvious opportunity. June 6 pushed much more of the top attention into photonics, power, and deliverable compute supply.
1.2 Agent talk is getting more operational and less mystical (🡒)¶
Agent chatter stayed heavy, but the tone shifted toward stack literacy, guardrails, and evaluation. Rather than debating whether agents matter, posters spent more energy defining layers, connecting tools, and specifying how to keep systems controllable once they leave the demo stage.
@coder_surya laid out (57 likes, 12 replies, 648 views) a taxonomy that separates plain LLMs, agents, agentic workflows, and multi-agent systems by autonomy, coordination cost, and ideal use case. The post’s most concrete claim is practical: using a multi-agent system for work a single prompt could handle just imports coordination overhead without adding value.
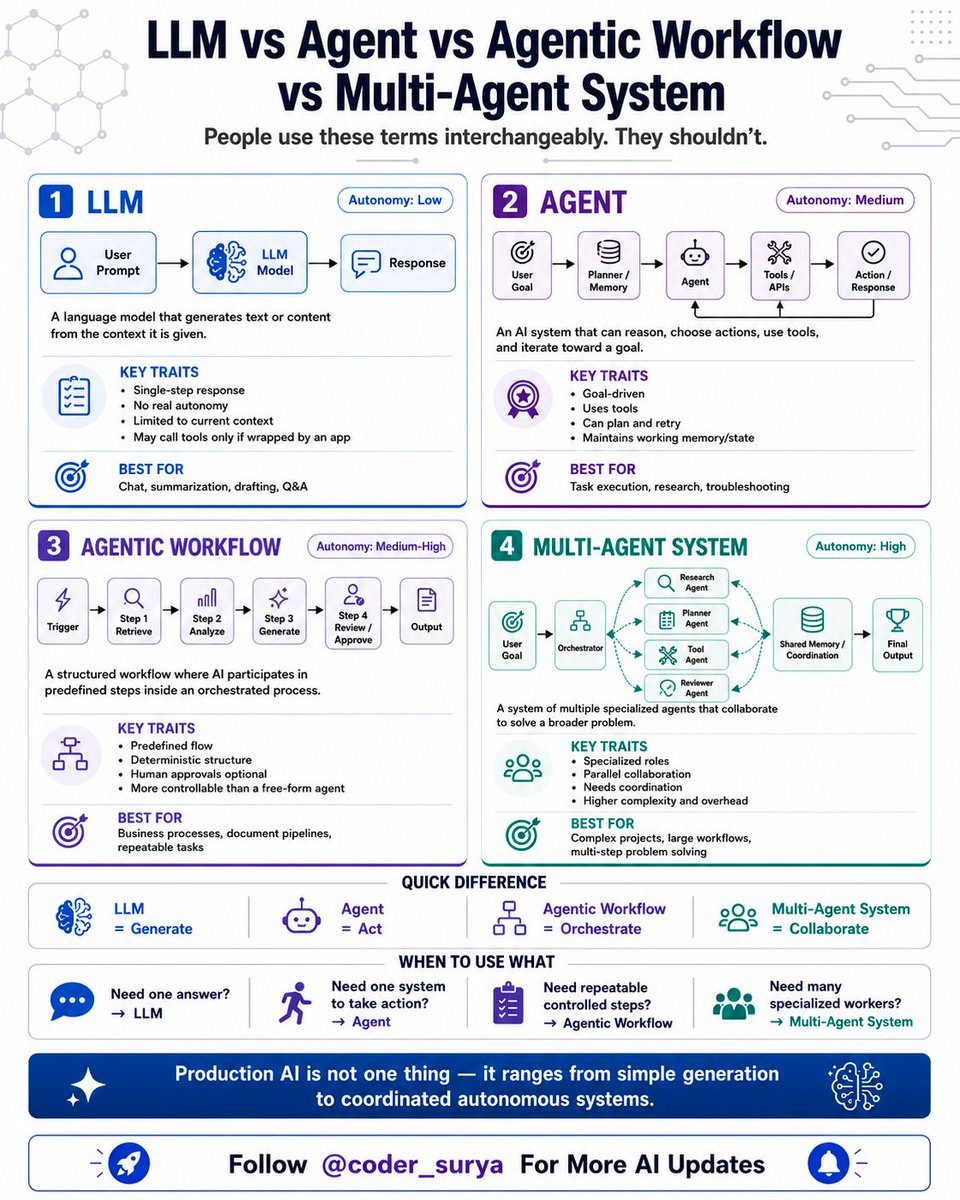
@LearnWithBrij summarized (13 likes, 3 replies, 316 views) the stack as 12 concepts: RAG, context, and memory as foundation; tools and MCP as the agent layer; orchestration and eval as execution. That post pairs well with @MaryamMiradi showing (8 likes, 3 replies, 191 views) a nine-step Claude Code workflow that starts with planning and rules, then moves through structured IO, skills, sub-agents, hooks, memory, and eval suites.


@rohanpaul_ai summarized (23 likes, 6 replies, 3,717 views) Arena’s new real-world agent leaderboard as a move away from clean benchmark questions and toward messy work sessions with web, files, and terminal tools. The linked methodology page says Agent Arena uses causal tracing across confirmed success, praise vs. complaint, steerability, bash recovery, and tool hallucination, and reports a recent seven-day slice with 160,480 tasks and 2,060,159 tool calls.

Discussion insight: The replies under @ChrisCamillo calling (371 likes, 46 replies, 15,277 views) for obsessive real-world AI use capture the mood shift well. One reply complained that most AI-workflow posts are still too vague to be useful; another answered with a concrete agent that processes about 60 emails a day for roughly $2 in daily cost.
Comparison to prior day: June 5 still revolved around agent economics and human supervision. @gokulr summarized (66 likes, 9 replies, 8,424 views) Dan Shipper’s view that every agent still needs a human. June 6 kept that same human-in-the-loop instinct, but added more diagrams, protocols, and evaluation machinery around it.
1.3 Sovereignty and auditability are moving to the center (🡕)¶
Another strong cluster treated AI less as a consumer product and more as a control surface that governments and regulated operators do not want to outsource blindly. French defense planning, Indian procurement, White House policy, and enterprise auditability threads all pointed in the same direction: local control, multi-vendor resilience, and systems that can be inspected before they act.
@defense_news reported (146 likes, 4 replies, 10,251 views) that France will test Arcadia, its alternative to Palantir’s Maven Smart System, during NATO’s CWIX interoperability exercise. The linked article says Arcadia is being developed with Mistral AI, Safran.AI, Thales, and Airbus, and that France has also built Berthier, a staff-officer LLM used to synthesize information, retrieve operational data, and help draft proposed courses of action.
@DrdoTdf announced (137 likes, 5 replies, 8,810 views) an open tender for an indigenous large language model for cybersecurity vulnerability discovery and threat intelligence, with bids due on June 25. The tender signal is important because it frames domain-specific sovereign LLMs as a procurement category rather than a speculative talking point.
@LuizaJarovsky said (2 likes, 1 reply, 694 views) the new White House memorandum marks a major acceleration in military AI adoption. The accompanying White House fact sheet says fielded systems must be robust, steerable, and controllable, and that no outside entity may disable or degrade an AI system relied on by U.S. warfighters without prior approval.

Discussion insight: The enterprise-side version of the same concern appeared in @Shuarix discussing (115 likes, 41 replies, 5,968 views) OpenServAI. Replies largely agreed that auditability is the real moat for banks and government users, but one respondent cut against the hype by saying real value shows only in production, not in writeups.
Comparison to prior day: Earlier files already contained national-security and benchmark talk, but June 6 is the first day in this run where French, Indian, and U.S. sovereign-AI signals all land in the same top slice.
2. What Frustrates People¶
Physical capacity still outruns AI ambition¶
Severity: High. @Agrippa_Inv argued (266 likes, 29 replies, 12,654 views) that power constraints and delayed grid access are widening the gap between planned and realized data-center capacity, while @TheValueist argued (10 likes, 2 replies, 3,554 views) that even a massive SpaceX-Google GPU contract still has delivery gates and termination risk. The same frustration shows up in the XFAB thread, where a reply warns that a 2027 CPO ramp still requires fab tooling and power allocation years in advance. The coping strategy in today’s data is not magical optimization; it is securing power earlier, accepting behind-the-meter tradeoffs, and treating capacity as scenario-weighted instead of guaranteed. This looks worth building for because the complaint appears across photonics, merchant compute, and neo-cloud discussion at the top of the day’s feed.
AI work platforms are easy to promote and hard to access¶
Severity: Medium. @CallMeDoct posted (37 likes, 5 replies, 2,315 views) a 20-platform list specifically because Outlier is not open to many Nigerians, and the replies immediately turned into eligibility triage: one reply says Alignerr is not available, another says Mercor keeps rejecting applications. The underlying frustration is not lack of interest in AI work; it is opaque regional access, inconsistent approval, and uncertainty about which platforms are actually live for a given country. Posters cope by applying broadly, completing assessments quickly, and leaning on specialized skills such as coding, law, or medicine to reach the better-paying work. That makes this a direct opportunity for products that can expose availability, fit, and status more transparently.

Agents still lack hard boundaries¶
Severity: High. @Shuarix argued (115 likes, 41 replies, 5,968 views) that auditability is what regulated buyers actually need from agent systems, and replies under the post repeatedly call inspectable reasoning the moat. @ZhugeLyang warned (6 likes, 5 replies, 62 views) that agents with expense approval, cards, and APIs are still being treated like smarter chatbots rather than like employees with real spending power. Arena’s methodology page reinforces the same pain operationally by measuring bash recovery and tool hallucination, while the White House fact sheet uses nearly the same language in policy form, requiring systems to be robust, steerable, and controllable. Even @adag1oeth said (5 likes, 1 reply, 35 views) that x402 payment execution is starting to work and that “the next bottleneck is control.” The workaround stack in today’s evidence is reasoning graphs, structured outputs, hooks, and hardware-enforced policy layers. This is clearly worth building for.

3. What People Wish Existed¶
Model-independent memory and continuity¶
@uthykinging argued (275 likes, 110 replies, 869 views) that the biggest AI problem is continuity: teams invest in workflows, knowledge bases, and agent behavior, then major model upgrades force them to rethink the entire stack. @trynullsec described (35 likes, 13 replies, 1,222 views) the desired answer as repository-aware context, retrieval, compression, hierarchical memory, and task-specific evaluation rather than a bigger context window alone. This is a practical need, not an emotional one, and the urgency is Medium-High because current answers are still roadmap-heavy. Opportunity: direct.

Auditable agents with pre-action limits¶
What people want here is very specific: not just logs after failure, but enforceable limits before an agent can spend, call APIs, or drift into unapproved actions. @Shuarix argued (115 likes, 41 replies, 5,968 views) that banks and government buyers need reasoning they can inspect and replay, while @ZhugeLyang warned (6 likes, 5 replies, 62 views) that today’s financial agents still lack hard boundaries. The White House fact sheet sharpens the same demand in policy language by requiring systems to be robust, steerable, and controllable. Partial solutions exist in LATCH-style policy engines and reasoning-graph approaches, but the discussion suggests the market still sees the gap as open. Opportunity: direct.
Sovereign alternatives to single-vendor command AI¶
The defense and public-sector posts point to a competitive need for AI systems that can be deployed locally, integrated across multiple vendors, and governed without defaulting to one foreign platform. @defense_news reported (146 likes, 4 replies, 10,251 views) that France is testing Arcadia specifically as a response to Maven, and @DrdoTdf announced (137 likes, 5 replies, 8,810 views) a tender for an indigenous cybersecurity LLM. This is a practical and urgent need in regulated settings, but it is also a competitive one because the solutions are likely to be country-, mission-, and standards-specific rather than universal. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude Code | Coding agent / IDE workflow | (+/-) | Fast iteration, planning, hooks, and eval-driven build loops; some users pair it with local Ollama models for privacy and cost control | Becomes fragile when asked to free-form “just build”; cost and context drift push users toward more structure |
| MCP | Tool/data connectivity standard | (+) | Gives agents a standard way to reach tools and external data; repeatedly named as part of the core modern stack | Still poorly understood, and it does not solve memory, orchestration, or evaluation by itself |
| Agent Arena | Agent evaluation | (+) | Measures real sessions with success, praise/complaint, steerability, bash recovery, tool hallucination, and exact session cost | The current leaderboard is still an initial set of five signals centered on orchestrator models, so coverage is expanding rather than complete |
| Outlier / Mercor | AI work marketplace | (+/-) | Concrete paid work in tutoring, coding, annotation, and evaluation; visible onboarding flows and posted pay rates | Geography restrictions, eligibility uncertainty, and rejection loops create trust problems |
| OpenServAI | Reasoning / auditability layer | (+/-) | Appeals to buyers who want inspectable reasoning, replayable decisions, and better tool-call reliability with cheaper models | Replies questioned whether the proof is strong enough in production and whether crypto-token framing hurts enterprise sales |
| x402 | Agent payments | (+/-) | Public transaction and volume figures suggest agents are already paying for tooling, compute, and enrichment services | Even proponents say payment execution is ahead of control, so governance is still the bottleneck |
| Arcadia / Berthier | Defense command-and-control AI | (+/-) | Open, sovereign, multi-vendor framing; Berthier is used for synthesis, retrieval, and draft courses of action | Interoperability and certification against Maven-era NATO workflows are still live questions |
The satisfaction spectrum today favored tools that reduce ambiguity. Claude Code, MCP, and Agent Arena were discussed positively when they helped teams structure work, connect to tools cleanly, and measure agent behavior under pressure. Mixed sentiment showed up where AI touches money, regulated decisions, or labor access: marketplaces, agent payments, and enterprise reasoning layers all worked well enough to attract use, but not cleanly enough to remove distrust. The most common workarounds were local model hosting via Ollama, structured schemas instead of free-form output, hooks and eval suites, and using multiple marketplaces at once rather than trusting a single one. The broader migration pattern is from generic “agent” talk toward multi-vendor, model-agnostic, auditable stacks that can survive corrections, model swaps, and procurement review.


5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Collaborative Agentic Movie | @ActionModelAI + @billions_ntwk | Lets users pair agents, claim tiles, and compete in a live collaborative film experience | Turns “community-owned AI” from passive branding into an interactive, reward-linked activity | Agents, x402 payment protocol, human-proof extension | Shipped | tweet, quoted tweet |
| Kova | @pixperk | Adds a SQL-like query language and planner to a Rust vector database | Removes application-side orchestration for vector search plus metadata filtering | Rust, approximate nearest-neighbor search, fuzz testing, typed errors | Alpha | tweet |
| LATCH | @itachee_x / @ZhugeLyang | Hardware-enforced policy engine for agent spending, API scope, and failsafes | Prevents financial agents from drifting or overspending before action, not just after the fact | Hardware-enforced policy engine, cryptographic enforcement, onchain policy | Alpha | tweet, quoted tweet |
| Nullsec-native model layer | @trynullsec | Long-context system targeting 1.2M context with repository-aware retrieval and memory layers | Helps AI reason over entire systems instead of isolated prompts | Repository-aware context, retrieval, compression, hierarchical memory, task-specific eval | RFC | tweet |
| Databricks Architecture Center | @databricks | Publishes reusable reference architectures for pipelines, dashboards, and AI workloads | Shortens the jump from idea to implementation with concrete design patterns | Lakeflow Jobs, ingestion pipelines, analytics, ML, BI, lakehouse patterns | Shipped | tweet |
@ActionModelAI launched (163 likes, 144 replies, 1,313 views) the collaborative agentic movie as something already live, and the quoted @billions_ntwk post says it involves 500+ builders and a human-proof extension of x402. That makes it one of the day’s clearest examples of builders trying to turn agents into an on-platform participation mechanic rather than a background utility.
@pixperk described (44 likes, 6 replies, 993 views) Kova with unusually concrete engineering detail: three query execution strategies, 32,000+ randomized-query checks, 12,000+ reference comparisons, and 544 passing tests. The distinctive pattern here is not “AI app” surface gloss, but infrastructure that tries to absorb orchestration complexity inside the engine.
The repeated builder pattern across these projects is control. LATCH tries to put hard limits around financially empowered agents, Nullsec treats long context as memory and retrieval engineering rather than a marketing number, and Databricks packages architecture patterns so teams do not have to invent every flow from scratch.

6. New and Notable¶
Formal proof search reached beyond toy-math demos¶
@burny_tech argued (3 likes, 2 replies, 522 views) that AI-for-math still produces plenty of false positives, but that the recent OpenAI Erdős result feels qualitatively different because it tackled a central abstract problem that was not trivially verifiable. The screenshot points to Advancing Mathematics Research with AI-Driven Formal Proof Search, and the public arXiv page for that paper says the system solved 9 of 353 unsolved Erdős problems. The notable part is the framing: the tweet is neither triumphalist nor dismissive, but treats formal verification as the reason this progress deserves attention.

Model choice is starting to behave like media choice¶
@jayvanbavel reported (9 likes, 1 reply, 856 views) that political identity shapes which large language models users prefer even when correctness is rewarded. The linked public abstract describes a two-stage experiment with 1,884 participants and says 71% stuck with their previously preferred model despite financial incentives for accuracy. That is notable because it shifts the AI-bias conversation from model outputs alone to the demand side: which systems people choose to trust in the first place.

7. Where the Opportunities Are¶
[+++] Agent governance and pre-action control — Evidence shows up across enterprise, payments, and defense at once. OpenServAI supporters and critics both center auditability; LATCH is being built around hard spending/API boundaries; Agent Arena’s core signals include steerability, bash recovery, and tool hallucination; the White House fact sheet says military systems must be robust, steerable, and controllable. This is the strongest opportunity because the same unmet need appears in sections 2, 3, 4, and 5.
[++] Infrastructure planning around power, photonics, and merchant compute — The XFAB, IREN, and SpaceX threads all point to the same bottleneck: AI demand keeps running into power delivery, photonics supply, and contract execution risk. This is a moderate opportunity because the signal is large and specific, but much of today’s discussion still comes through investor and market narratives rather than from frontline operators shipping new software.
[+] Continuity layers for model-switching teams — The continuity post from @uthykinging, the Nullsec roadmap, and the stack/Claude Code workflow posts all imply that teams need memory, retrieval, and structure that survive model churn. This is emerging rather than fully formed, but it keeps appearing wherever practitioners talk seriously about production agents.
8. Takeaways¶
- AI infrastructure attention is now anchored in delivery constraints. The clearest June 6 evidence was about photonics roles, delayed grid power, and merchant GPU contracts rather than fresh benchmark bragging. (XFAB, IREN, SpaceX/Google)
- The agent conversation is maturing into stack design and evaluation. Taxonomy posts, MCP-and-memory diagrams, Claude Code workflow checklists, and Agent Arena’s causal leaderboard all point to a more operational style of agent discussion. (taxonomy, workflow, Agent Arena)
- Auditability is becoming a market requirement and a policy requirement at the same time. The same day produced Arcadia as a Maven alternative, a DRDO tender for an indigenous cybersecurity LLM, White House language about controllable systems, and enterprise threads demanding reasoning that can be inspected before action. (Arcadia, DRDO, White House fact sheet)
- Demand for AI work and AI services is real, but access and trust still lag. The Nigeria-focused platform list shows people actively hunting AI labor opportunities, while replies document regional ineligibility and rejection fatigue. On the services side, x402 volume suggests agent payments are happening, but even supporters say control is the next bottleneck. (platform access, x402)
- The newest AI signals are not only about capability; they are also about verification and user behavior. Formal proof-search work is notable because verification makes the claim legible, while the political-identity paper suggests users may choose models the way they choose media brands. (formal proof search, model choice)