Twitter AI 智能体 - 2026-05-01¶
1. 人们在讨论什么¶
1.1 Flue 发布首个智能体测试框架 🡕¶
当天信号最强的事件是 @FredKSchott 推出 Flue(999 次点赞,1,255 次收藏,102,567 次浏览)——一个围绕内置智能体测试框架构建智能体的 TypeScript 框架。Flue 的定位是“Claude Code,但 100% headless 且可编程”,不假设有人类操作者。不同于 AI SDK,Flue 是一个运行时无关的框架:一次编写,构建后即可把智能体部署到任何地方(Node.js、Cloudflare、GitHub Actions、GitLab CI/CD)。一等概念包括会话、子智能体、内置沙箱,以及用 Markdown 定义的技能。这个框架最初来自 Astro GitHub repo 内部 AI 工作流的支撑系统。

@FredKSchott 澄清了定位:“框架 vs. SDK。有点像 Next.js/Astro 构建在 React 之上,Flue 构建在 pi-agent-core 之上,用来驱动我们的测试框架。”
讨论要点: @LeoTava8 抓住了吸引力:“行业沉迷于在循环里写提示词,却忽略了我们从基础设施中学到的经验。我们需要明确的契约层和合适的有状态编排。Flue 看起来正是那个正确原语——把‘做什么’和‘怎么做’分开。”
与前日对比: 4 月 30 日,Cursor 公开了内部测试框架方法论,社区也开始把测试框架工程视为一门学科。5 月 1 日交付了第一个围绕这一论点构建的专用开源框架,从方法论推进到可部署产物。
1.2 Microsoft Agent 365 正式 GA 🡕¶
@satyanadella 宣布(367 次点赞,22,451 次浏览)Agent 365 已正式 GA,成为一个单一控制平面,用于在企业范围内观察、治理和保护智能体及其交互。该系统把现有身份、安全、治理和管理工作流扩展到每一个 AI 智能体——包括用 Microsoft AI 构建的智能体和第三方生态智能体。新的预览功能包括:为使用自身凭据运行的智能体提供可观测性,通过 Microsoft Defender 和 Intune 发现 shadow AI,以及 Windows 365 for Agents(托管的沙箱环境)。
讨论要点: @GroverLovesh 提供了实践者背景:“过去 60 天里,我调试的大多数智能体失败都是身份/权限问题,不是模型问题。Microsoft 正在解决无聊的一半。而无聊的一半更大。不带每智能体身份的独立智能体栈,在第一次合规审查时就会撞墙。”
与前日对比: 4 月 30 日的重点是开发者领域中的智能体框架成熟。5 月 1 日显示企业治理层正在追上来——正是这个“无聊的一半”解锁了机构规模的生产部署。
1.3 测试框架工程稳固为核心学科 🡒¶
多个高信号事件进一步强化了测试框架工程作为主导范式的地位:
@Vtrivedy10 解释(81 次点赞,68 次收藏)LangChain 的 Deep Agents 如何构建在 create_agent 之上:这是一个单一原语,支持文件系统工具、bash、压缩、子智能体、技能、记忆和 hooks。他强调,这个原语的可扩展性是所有 Deep Agents 工程的基础。

@Vtrivedy10 另行演示,GPT-5.5 中一条引导指令会让 Terminal Bench Score 产生 12% 的变化,为“提示词和测试框架工程今天仍然非常重要”提供了量化证据。
@dntyk 分析(33 次点赞,25 次收藏)了 AHE 论文:自动演化的测试框架在 Terminal-Bench 2 上达到 77.0%(手工设计的 Codex-CLI 为 71.9%),关键发现是“收益来自工具、中间件和长期记忆。单靠 system prompt 反而会退步。”

@davidfowl(116 次点赞,15,537 次浏览)概括了实践者情绪:“我正准备构建自己的智能体编排系统。我们现在都在做这件事吗??这是悲伤五阶段里的哪一阶段?” @stackbenchdev 回复:“每个测试框架都编码了开发者关于智能体应该如何运行的理论。所以可移植模板还没有结晶。”
与前日对比: 4 月 30 日,Cursor 公开方法论,收敛模式也被识别出来。5 月 1 日加入了经验证据(AHE 论文基准、单条指令带来 12% 波动)和实践者挫败感(Fowl 要自己构建)——这门学科已被验证,但工具缺口仍在。
1.4 Google COSMO 泄露揭示 Android 智能体 OS 🡕¶
@minchoi 报道(133 次点赞,52 次收藏,8,758 次浏览),Google 泄露后又移除了“COSMO”——这是一个面向 Android 的综合智能体系统,包含本地 Gemini Nano、屏幕访问、语音匹配、回忆、浏览器智能体和深度研究能力。

截图揭示了一种基于技能的架构,包含生产力、信息、对话、AI 等类别;混合执行模型(在线用云端 P1,离线用 Nano);环境感知功能(屏幕上下文、音频、交互);以及用于用户认证的语音匹配。
讨论要点: @AdityaKTech 总结了情绪:“你的手机终于开始变成多年前承诺过的那个‘JARVIS’了。”
与前日对比: 前一天没有覆盖。这是 Google 正在把完整智能体 OS 内置进 Android 的第一批证据,带有混合推理和可扩展技能,直接对位 Apple 的端侧智能战略。
1.5 跨智能体技能分发成为新类别 🡕¶
三个独立项目都在解决智能体之间的技能可移植性:
@aidenybai 发布(89 次点赞,61 次收藏)agent-install,这是一个开源工具,可通过 API 或 CLI 在 52 个编程智能体之间安装 skills 和 MCP。
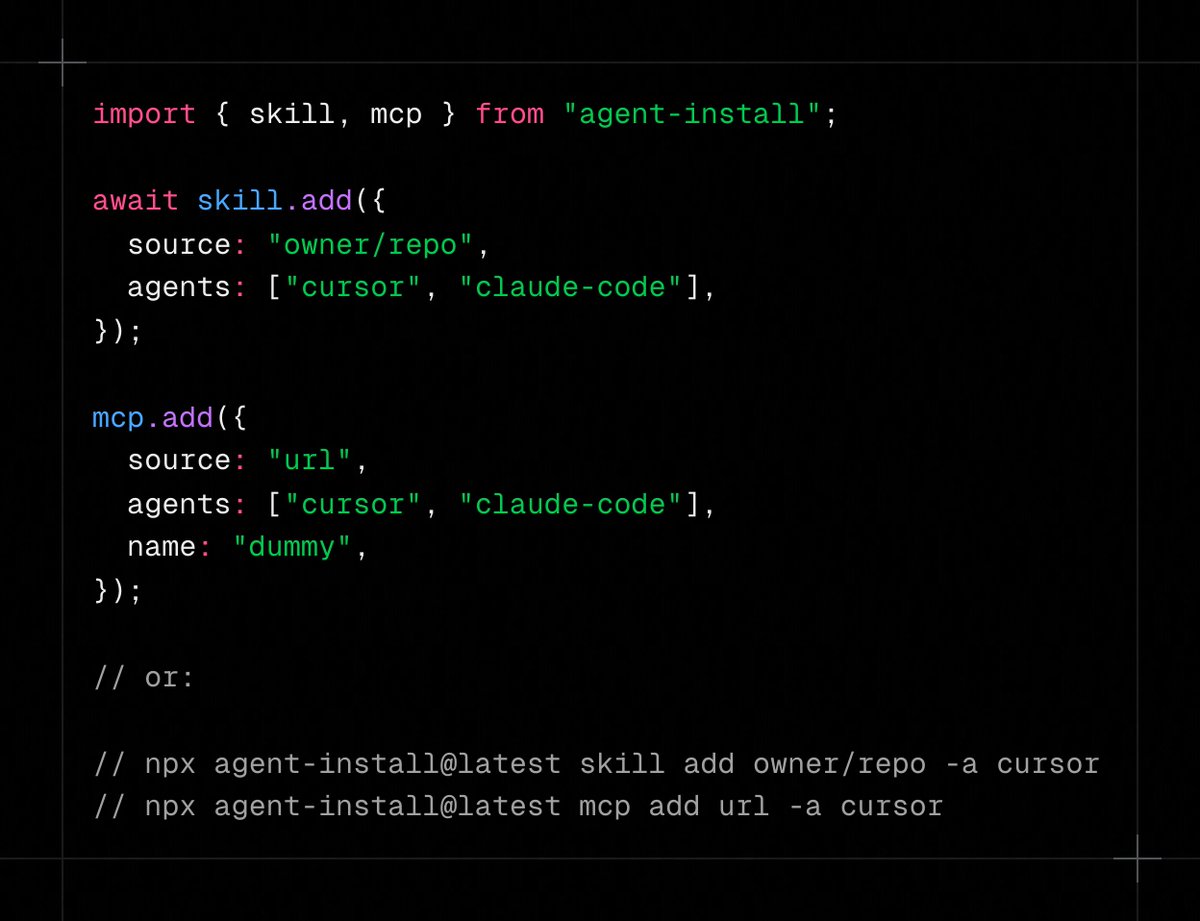
@tiangolo(FastAPI 创建者)发布(37 次点赞,24 次收藏)library-skills——一个扫描项目依赖并安装库随包附带 AI 技能(如 FastAPI)的工具。技能以符号链接方式安装,因此库更新会自动传播。支持 Python 和 Node.js,并提供用于 Claude Code 兼容性的 --claude 标志。
@ElevenLabsDevs 发布(116 次点赞,78 次收藏)Voice Changer Skill,可通过 npx skills add elevenlabs/skills 安装,展示能力供应商正在通过 skills 生态分发。
讨论要点: @mylifcc 指出了收敛挑战:“~/.claude/skills/SKILL.md 是我的 Claude Code 设置;Codex 和 Cursor 使用不同路径。好奇 agent-install 是把这些收敛成一个清单,还是只是按路径复制文件。”
与前日对比: 4 月 30 日的挫败感是技能数量增长快于质量。5 月 1 日焦点转向技能分发基础设施——技能如何跨异构工具链触达各类智能体。
1.6 多智能体架构在研究和实践中推进 🡒¶
@omarsar0 分享(40 次点赞,39 次收藏)RecursiveMAS 论文(arXiv:2604.25917,UIUC/Stanford/NVIDIA/MIT),提出智能体通过共享潜空间中的递归计算协作,而不是用文本消息协作。结果:在 9 个基准上准确率提升 8.3%,速度提升 1.2-2.4x,token 降低 34.6-75.6%。

@aakashgupta 描述了 Claude Code 内部一个 21 智能体开发团队,用 2 小时 13 分钟把一款冰球规则 app 发布到 TestFlight:“spec 现在成了瓶颈。你到底想要什么,清晰度决定下游的一切。”
讨论要点: @haowjy 对 RecursiveMAS 提出了关键问题:“我想知道能否把它 retrofit 到完全不同的模型上?多智能体系统的主要优势是可以使用以完全不同技术训练的模型。” @FiftyOne_50_ 提出了控制担忧:“潜空间智能体协作可能减少 token。它也会隐藏更多路径。”
与前日对比: 4 月 30 日,黑客松获奖项目展示了多智能体模式(观察 + 验证)。5 月 1 日推进了理论(用潜空间递归替代文本协作)和实践(21 智能体团队发布 app)。
2. 令人困扰的问题¶
每个人都在构建自己的编排系统 -- 严重程度:High¶
@davidfowl(Microsoft .NET 架构师)表达了(116 次点赞,46 条回复,15,537 次浏览)核心挫败感:“我正准备构建自己的智能体编排系统。我们现在都在做这件事吗??这是悲伤五阶段里的哪一阶段?” 回复确认这种模式很普遍。@stackbenchdev:“每个测试框架都编码了开发者关于智能体应该如何运行的理论。所以可移植模板还没有结晶——野外的那些看起来都不一样,因为 workflow 本来就不一样。” @buildwithparas:“讨价还价阶段;当你不再称它为临时方案时,就是接受阶段。”
这种挫败感横跨整个技术栈:AHE 论文显示,自动演化的测试框架优于手工设计的测试框架,但实践者仍然必须从零开始构建,因为没有框架能覆盖完整的测试框架表面。Flue 是第一个试图在框架层解决这个问题的尝试。
智能体身份和权限故障 -- 严重程度:High¶
@GroverLovesh 报告:“过去 60 天里,我调试的大多数智能体失败都是身份/权限问题,不是模型问题。不带每智能体身份的独立智能体栈,在第一次合规审查时就会撞墙。” Microsoft 的 Agent 365 GA 是第一个企业级答案,但独立和跨云部署仍未解决。@OfficialTravlad 指出:“走出 GCP,身份就消失了。没有可移植性,也没有问责。”
测试框架配置敏感 -- 严重程度:Medium¶
@Vtrivedy10 演示,GPT-5.5 中一个 tool_choice: "none" 设置会注入一条 steering instruction,使 Terminal Bench Score 产生 12% 波动。@ValsAI 确认 OpenAI 会“以不同于 tools: [] 的方式”注入这条指令。实践者无法预测细微配置变化如何与模型内部机制相互作用,导致测试框架调优脆弱且不透明。
3. 人们期望的功能¶
可移植的智能体编排框架¶
@davidfowl 和 46 条回复确认:开发者想要不必自己构建的编排。缺口在于一个框架:模型选择是配置,workflow 是声明式的,测试框架覆盖完整表面(工具、中间件、记忆、subagents)。Flue 是第一个专用尝试,但它明确处于早期。实践者之所以构建定制方案,是因为没有任何东西能可移植地捕捉他们的 workflow 理论。
紧迫性:High -- 机会:直接产品
跨智能体技能 Manifest 标准¶
@mylifcc 指出缺口:“~/.claude/skills/SKILL.md 是我的 Claude Code 设置;Codex 和 Cursor 使用不同路径。好奇 agent-install 是把这些收敛成一个清单,还是只是按路径复制文件。MCP stdio vs sse 是最棘手的跨智能体部分。” 三个独立项目(agent-install、library-skills、skills.sh)都在解决分发,但 52+ 个智能体之间还没有标准清单。
紧迫性:High -- 机会:基础设施
透明的测试框架-模型交互调试¶
单条 steering instruction 造成 12% Terminal Bench 波动,再加上 AHE 论文的消融结果,说明实践者无法观察测试框架配置如何与模型交互。@InsiderPresider 问道:“create_agent 绝对是一个扎实原语,但我想知道这个抽象层是否为生产智能体安全隐藏了过多复杂性。” 需要的是可观测性:在评估时展示测试框架选择(工具、中间件、提示词)如何影响模型行为。
紧迫性:Medium -- 机会:工具
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Flue | 智能体框架 | (+) | 首个测试框架框架;运行时无关;内置沙箱;sessions/subagents 为一等概念 | 全新;早期 |
| LangChain create_agent / Deep Agents | 智能体框架 | (+) | 可扩展原语;按模型配置 profile;基准提升 10-20pt | 生产使用需要大量扩展 |
| Cursor Harness | 智能体运行时 | (+) | 已发布方法论;遥测驱动优化;按模型调优 | 专有产品 |
| Agent 365 | 企业治理 | (+) | 单一控制平面;所有智能体的身份/安全/治理;shadow AI 发现 | 以 Microsoft 生态为中心 |
| DeepSeek-V4-Pro | LLM | (+) | 首个在智能体式编程上追平前沿模型的开放权重模型;1M 上下文;CSA+HCA 10% KV cache | 目前仅通过 Fireworks 提供 |
| agent-install | 技能分发 | (+) | 支持 52 个智能体;API + CLI;开源 | 尚无标准 manifest |
| library-skills | 技能分发 | (+) | 技能随库发布;通过符号链接自动更新;Python + Node.js | 新;库采用有限 |
| Hermes Agent | 编程/通用智能体 | (+) | Telegram 界面;VPS 部署;自定义技能;通过 OpenRouter 多模型 | 与加密社区重叠 |
| ElevenLabs Skills | 语音智能体 | (+) | 保留情绪/节奏的变声器;可通过 skills.sh 安装 | 仅限语音领域 |
| Pi(编程智能体) | 智能体运行时 | (+) | 轻量;开箱支持 DeepSeek-V4-Pro | 功能少于 Claude Code |
| TradingAgents | 多智能体金融 | (+/-) | 59K stars;完整交易桌架构;回测;Docker | 批评者认为“智能体编排不带来 edge” |
DeepSeek-V4-Pro 代表一个值得注意的转变:@omarsar0 报告,它在一个基础测试框架中“无需任何特殊配置”即可工作——这是开放权重模型第一次能“插进 Pi 这样的基础测试框架就直接可用”。混合 CSA+HCA attention 将 KV cache 降到 10%,并在 1M 上下文下把推理 FLOPs 降低 4x,让智能体循环“真正快到、便宜到可以实践运行”。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Flue | @FredKSchott | 带内置沙箱、sessions、subagents 的智能体测试框架 | 缺少智能体测试框架 | TypeScript, pi-agent-core | Alpha | post |
| agent-install | @aidenybai | 在 52 个编程智能体之间安装 skills 和 MCP | 跨智能体技能碎片化 | TypeScript, CLI/API | Shipped | post |
| library-skills | @tiangolo | 随依赖自动更新的库内置 skills | 智能体使用过期库 API | Python, Node.js, symlinks | Shipped | GitHub |
| TradingAgents | @sharbel | 多智能体交易桌(分析师、交易员、风控、PM) | 单模型交易表现不足 | LangGraph, multi-LLM, Docker | Shipped | post |
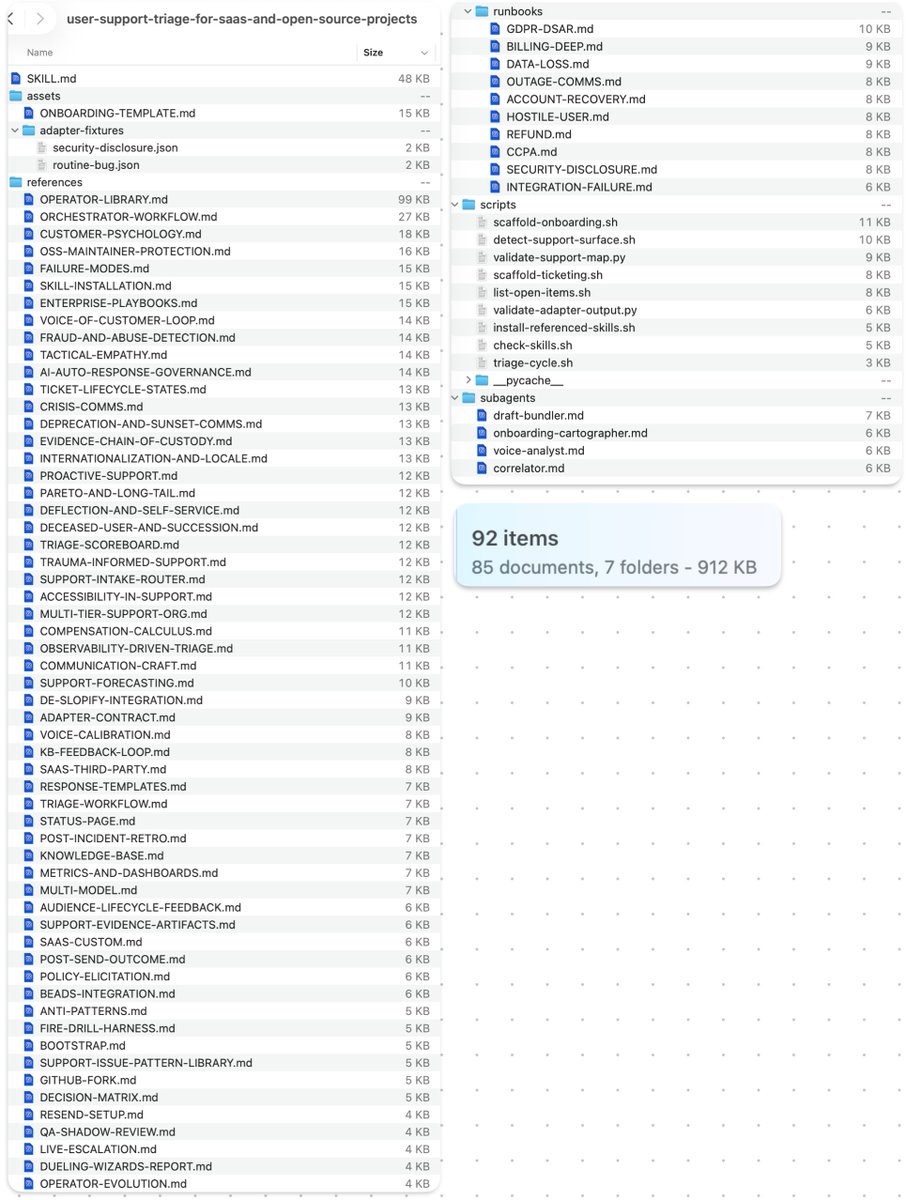
| User Support Triage Skill | @doodlestein | 面向 14 种服务的 85 文件、912KB 通用支持分诊技能 | SaaS 手工支持队列管理 | Claude Code skills, subagents | Shipped | post |
| Personal AI Agent on VPS | @thegreatola | 个人智能体:市场、交易、编程、内容 | 多个订阅成本 | Hermes, OpenRouter, Telegram, VPS | Shipped | post |
| HermesAgent SWARM v2.1 | @outsource_ | 通过 orchestrator、kanban、reports 做多智能体控制 | 单智能体局限 | Hermes Agent, orchestrator chat | Shipped | post |
| Voice Changer Skill | @ElevenLabsDevs | 保留表演/情绪/节奏的语音转换 | 缺少作为智能体技能的 voice cloning | ElevenLabs, skills.sh | Shipped | post |
@doodlestein 的 user-support-triage 技能代表了技能复杂度的上限:85 个文件、912KB,包含 GDPR DSAR、账单深挖、数据丢失、敌意用户和安全披露的 runbook。它包含一个通用适配器契约,用于标准化 14 个不同支持提供商;子智能体(draft-bundler、onboarding-cartographer、voice-analyst、correlator);以及要求负责人批准后才能对外沟通的安全架构。该技能把支持视为“证据管线、风险路由器、负责人批准的沟通系统、产品情报引擎和复利式运营记忆”。
@thegreatola 记录了一个实用的个人智能体架构:Hermes 作为推理层,OpenRouter 作为模型网关(每月 5-15 美元),Telegram 作为界面,按上下文加载自定义技能,并在 VPS 上 24/7 运行。他报告用一张 API 账单替代单独的 ChatGPT + Claude + Cursor + Perplexity 订阅,并让“智能体按任务选择正确模型”。首月交易回报约 1K 美元。
6. 新动态与亮点¶
Flue:首个专用智能体测试框架¶
Flue(1,255 次收藏)是第一个围绕智能体测试框架概念构建的框架,而不是把它附加到 SDK 上。它来自 Astro/Next.js 创建者,把会话、子智能体和沙箱定位为一等框架原语,而不是 SDK 工具函数。“flue build”和“flue run”命令复刻了 Web 框架开发体验。如果测试框架工程是一门学科,Flue 就是第一次尝试把它做成可部署、标准化的框架。
信号强度:[+++]
Google COSMO 揭示面向 Android 的完整智能体 OS¶
泄露的 COSMO 截图(52 次收藏)显示,Google 正在把一个综合智能体操作系统构建进 Android:混合执行(云端 P1 + 本地 Nano)、环境感知(屏幕上下文、音频、交互、语音匹配)、带类别的可扩展技能,以及把手机视为持久智能体运行时的架构。这是 Google 对端侧 AI 智能体问题的回答。
信号强度:[+++]
Microsoft Agent 365 作为企业智能体控制平面达到 GA¶
Agent 365 解决了阻碍企业采用智能体的“无聊的一半”:每智能体身份、治理、合规和 shadow AI 发现。这个时间点确认企业需求已经进入生产就绪阶段,而不是实验阶段。
信号强度:[++]
RecursiveMAS 提出潜空间智能体协作¶
来自 UIUC/Stanford/NVIDIA/MIT 的 RecursiveMAS 论文(arXiv:2604.25917)提出智能体传递潜状态而不是文本消息,在准确率提升 8.3% 的同时,把 token 用量降低 34.6-75.6%。如果智能体间通信是下一个瓶颈,潜空间递归提供了一条扩展协作而无需支付 token 税的路径。
信号强度:[++]
DeepSeek-V4-Pro 在智能体式编程中追平前沿模型¶
@omarsar0 报告(33 次收藏),DeepSeek-V4-Pro 是“第一个真正感觉像 Codex 或 Claude Code 体验的开放权重模型”——无需特殊配置即可在基础测试框架中开箱工作。混合 CSA+HCA 注意力设计支持 1M-token 上下文,KV cache 开销仅 10%。
信号强度:[+]
7. 机会在哪里¶
[+++] 捕捉完整编排表面的智能体测试框架 -- @davidfowl(46 条回复)、AHE 论文基准和 Flue 发布都确认:实践者需要的是面向智能体测试框架的框架,而不是 SDK。Flue(早期、仅 TypeScript)与生产团队需求(多语言、模型可移植、可观测)之间仍有很大距离。第一个能以开放、可移植形式达到 Cursor 级测试框架质量的框架,将吸引那些“正在自己构建”的挫败用户。
[+++] 跨智能体技能分发标准 -- 三个独立项目(支持 52 个智能体的 agent-install、带自动更新符号链接的 library-skills、skills.sh 生态)验证了技能可移植性的需求。但尚无标准清单。第一个让 Claude Code、Cursor、Codex、Hermes 等都能原生读取的规范,会成为智能体技能的包管理器。
[++] 围墙花园之外的智能体身份与治理 -- Agent 365 解决 Microsoft 内部的治理。@OfficialTravlad 和 @GroverLovesh 确认了缺口:能够跨云、独立栈和协议迁移的智能体身份。Google 在 GCP 内部智能体身份上投入了 7.5 亿美元。跨云、协议级方案仍然开放。
[++] 测试框架可观测性和调试工具 -- 单条 steering instruction 造成 12% 基准波动,以及 AHE 消融结果(收益来自工具/中间件/记忆,而不是提示词)说明,实践者无法预测或调试测试框架-模型交互。面向测试框架工程的专用可观测性——展示配置选择如何影响模型行为——是一个未被满足的需求。
[+] 替代订阅的个人智能体基础设施 -- @thegreatola 展示了用 5-15 美元/月的 VPS 个人智能体替代 200+ 美元/月的 AI 订阅。这个模式(Hermes + OpenRouter + Telegram + 自定义技能)可复现,但需要大量设置。把它产品化成一键部署个人智能体,是一个正在出现的机会。
8. 要点总结¶
-
Flue(1,255 次收藏,102K 浏览)发布了首个智能体测试框架,确立“框架 vs SDK”为智能体基础设施的下一个前沿。 它来自 Astro 创建者,把 sessions、subagents 和 sandboxes 作为一等原语,并提供
flue build与flue runCLI——把 Web 框架模式应用到智能体开发。(source) -
Microsoft Agent 365 达到 GA,成为首个面向智能体身份、安全和治理的企业控制平面,确认“多数智能体失败是身份/权限问题,不是模型问题”。 它把现有安全 workflow 扩展到所有智能体,包括使用自身凭据的智能体、shadow AI 发现和 Windows 365 沙箱环境。(source)
-
单条测试框架引导指令会造成 12% Terminal Bench 波动,而 AHE 论文证明自动演化测试框架比手工设计高出 5+ 个点,明确确立测试框架工程已经超过提示工程。 消融显示,收益来自工具、中间件和长期记忆——不是系统提示词。(source, source)
-
Google 泄露的 COSMO 展示了一个完整的 Android 智能体 OS:混合云/本地推理、环境感知、语音匹配、可扩展技能和浏览器智能体——把手机定位为持久智能体运行时。 基于技能的架构带有生产力/信息/对话分类,类似把编程智能体技能模式适配到移动端。(source)
-
跨智能体技能分发以三项独立发布结晶为一个类别:agent-install 支持 52 个智能体,library-skills 通过自动更新符号链接分发,ElevenLabs 通过 skills.sh 分发,但生态还没有标准清单。 技能路径碎片化(~/.claude/skills vs ~/.agents/skills vs 智能体特定位置)是当前约束。(source, source)
-
报告显示,DeepSeek-V4-Pro 是第一个可在基础智能体测试框架中“无需任何特殊配置”运行的开放权重模型,以 1M-token 上下文和更低成本追平 Claude 与 Codex 体验。 把 KV cache 降到 10% 的混合注意力设计让智能体循环“快到、便宜到可以实践运行”——正在改变开放权重模型的竞争前沿。(source)