Twitter AI - 2026-04-08¶
1. 人们在讨论什么¶
1.1 创意社群明确划线,拒绝生成式 AI(🡕)¶
今天 AI 讨论中声音最大的不是构建者,而是拒绝者。@yuriiiiButAStar 发布了一条拒绝声明,获得 1,304 点赞和 208 转发:“我完全不在乎生成式 AI 以后会变得多好,我不会消费它,因为问题不在质量。问题在于被偷走的艺术、缺失的人类情感。” 反对理由明确是伦理性的,而不是审美性的。@m1rrorcat 的一条回复说得很直接:“机器不会有欲望,所以从本质上就做不出好艺术。” @ChloeFr85663273 则认为,即便是糟糕的人类艺术,“也仍然比任何 AI 生成的垃圾更有价值”。
@Drag_Crave 是一个经过认证的 drag 媒体账号,它发布了一条直接的机构声明:“Drag Crave 不认可使用生成式 AI。” 点赞与转发比(635:1)说明,这更像是受众点头赞同,而不是病毒式传播。
电影修复社群也在反击。@Ewokisapunk 批评团队把生成式 AI 用于电影修复,质问为什么他们“宁可用生成式 AI,也不用 Hybrid 这样的免费软件来修正代际质量损失”,从而让素材“更接近原始胶片质感”。令人不满的是,生成式方法替换了原始信号,而不是恢复原始信号。
与此同时,AI 检测工具正在被用于社群争议。@FreezorS56198 分享了一份 AI 检测扫描,显示某个公开回应有 96.5% 的 AI/GPT 概率,并敦促一名配音演员公开这一发现,以“削弱他的辩解可信度”。这是一种把 AI 检测当作社交武器的用法——随着生成文本越来越难与人类写作区分,这种模式很可能加剧。
1.2 AI 安全研究员从实验室内部拉响警报(🡕)¶
安全担忧从多个方向升级。@StopTechnocracy 报道称,Anthropic 的 AI 安全负责人 Mrinank Sharma 离职,并警告在 AI 快速发展下,世界“处于危险之中”。几天后,一名 OpenAI 工程师也表达了类似的存在风险担忧。Geoffrey Hinton 持续发出的警告构成了背景。这个模式很明显:AI 世界顶端的人正在离开,或站出来发声。
@twistartups 放大了关于 Anthropic 暂不发布最新模型“Mythos”的说法,理由是“它太强大,以至于成了安全威胁”。这段由 @jason 出镜的视频,把 AI 竞赛描述为“对国家安全具有存在意义”。22,808 浏览量却只有 69 点赞,说明这种叙事存在分歧——@avg_dad42 反驳说,为什么更高智能会让模型更危险,而不是更安全。
@alex_prompter 给出了当天最尖锐的批评,针对 Anthropic 同步发布的安全产品。他引用 Glasswing 公告——这是一项“帮助保护世界最关键软件的紧急计划”,由 Claude Mythos Preview 驱动,后者“发现软件漏洞的能力优于除最顶尖人类之外的几乎所有人”——然后补了一句:“我们有一个在网络安全基准上拿到 100% 的 AI!——来自一家最近整个源代码都泄露过的公司。”
1.3 OpenAI 领导层遭受抨击,人才流失仍在继续(🡕)¶
@twistartups 认为,Sam Altman“疏远了太多顶尖人才”,并逼走了包括 Dario Amodei 在内的关键人物,而 Amodei 创办的 Anthropic“现在在许多方面正在击败他们”。这条推文获得 34,037 浏览量和 133 收藏,核心论点是“AI 竞赛不只是基准测试——也是领导力”。回复串透露出焦虑:@JRichDaDon1 问,其他 AI 公司也有人离职,是否也说明领导层有问题。@cyclistal 则质疑“找到 bug 然后修掉”的心态:“从来不会一次就找到所有 bug,系统也一直在变化。”
1.4 AI 安全走向自动化——攻防两端都是(🡕)¶
安全研究员 @marver(X41 D-Sec 的 Markus Vervier)披露了 LiteLLM 中一个关键 RCE 漏洞。LiteLLM 是广泛使用的开源 LLM proxy(GitHub 28K+ stars)。完整公告显示,这是一个 CVSS 8.7 漏洞:/guardrails/test_custom_code endpoint 接收 Python 代码用于测试,尝试用基于 regex 的过滤来限制代码,但可以通过 CPython bytecode rewriting 绕过——用字符串拼接避开 regex、通过 gi_code 访问 generator code objects,再通过 code.replace() 重写 bytecode name table,从 unrestricted builtins 中提取 __import__。默认 Docker image 以 root 身份运行。
关键细节是:Vervier 在一个时间受限的项目中手工发现了这个 bug,然后让一个 AI 智能体(@Persistent_Psi 的 Nemesis)“自动分诊,并完全自动地找到一个沙箱逃逸。20 分钟后,连同一个可完全工作的 exploit 在内,任务就跑完了。” 他的结论是:“从漏洞到 exploit 的时间,以及 exploit 创建和生成时间,都在大幅缩短”,而且“在公告中隐藏细节,或偷偷发布静默补丁来修安全问题,已经不那么有效”。
另外,@FBIStLouis 宣布,2025 FBI IC3 报告首次包含关于 AI 驱动诈骗的章节,从第 39 页开始。损失最高的是加密货币投资欺诈;Operation Level Up 自 2024 年以来已减少超过 $500 million 的潜在损失。
1.5 企业 AI 整合加速(🡒)¶
Nebius($NBIS)据称正在洽谈收购 AI21 Labs,后者是 Jamba 和企业 LLM 工具背后的以色列初创公司。该交易会加深 Nebius 向模型层和企业层的推进。@LogWeaver 观察到,Nebius 正在“以让传统云看起来像静止不动的速度做垂直整合”。@k2__investment 指出其战略意图:“Nebius 收购 AI21 意味着 $NBIS 正在构建一个全栈 AI 生态系统。他们想拥有软件层,而不只是硬件。”
在基础设施侧,@NVIDIANetworkng 详细说明智能体式 AI 如何把内存系统推向新极限:“单个 100K-token 上下文最多可能需要 50GB 的 KV cache。” NVIDIA 在 BlueField DPU 上的 DOCA Memos 和 CMX 存储为推理创建了 AI 原生存储层,靠减少重复计算达到 99.8% 的缓存命中率和 96% 以上 GPU 利用率。这是基础设施在追赶长上下文智能体的需求。
@Supermicro 推广其 Intel 驱动的 edge AI 系统,用于数据源处的低延迟推理;@databricks 宣传其三层智能体栈:Agent Bricks 用于带评估的领域专用智能体构建,Databricks Apps 用于带 SSO 的安全聊天部署,Databricks One 作为统一访问入口。
2. 令人困扰的问题¶
AI 治理落后于 AI 采用(Severity: High)¶
@ServiceNow 分享的数据显示,80% 的组织现在使用 AI,但 47% 尚未准备好应对这些风险。治理基础设施——合规框架、风险评估工具、审计能力——没有跟上部署速度。@TheTuringPost 研究综述下的一条回复捕捉到从业者视角:“研究正在快速复利。工程纪律没有跟上。”
静默安全补丁正在失效(Severity: High)¶
@marver 披露的 LiteLLM RCE 说明,AI 辅助 exploit 生成正在压缩从漏洞发现到武器化的窗口。当一个 AI 智能体能在 20 分钟内产出可完全工作的 exploit 时,传统上先悄悄修复安全问题、再公开披露的策略就失去了保护价值。LiteLLM 的补丁状态仍是“TBD”。
基于 Regex 的安全沙箱从根本上就是坏的(Severity: High)¶
LiteLLM 公告揭示了一个反复出现的模式:建立在源代码级过滤(regex、AST blocking)之上的代码执行沙箱,可以通过 bytecode manipulation、字符串拼接和 reflection 绕过。LiteLLM 的 guardrails endpoint 试图限制危险操作,但败给了一个涉及 generator objects 和 CPython internals 的六步绕过。任何允许用户提交自定义代码的 AI 工具,都需要进程级隔离,而不是字符串匹配。
安全研究员正在离开,而不是被听见(Severity: Medium)¶
Anthropic 的安全负责人离职并警告危险。一名 OpenAI 工程师也呼应了存在风险。两个头部实验室都出现的模式表明,内部安全担忧没有足够快地转化为政策变化,以留住提出这些问题的人。
3. 人们期望的功能¶
可靠的 AI 内容检测¶
需求从两个方向显现:粉丝社群使用 AI 检测工具来反驳 AI 生成回应,创意社群也希望区分人类艺术与生成内容。现有工具会给出概率分数(其中一个案例为 96.5%),但这些工具的可靠性和法律地位仍不清楚,尤其是在模型继续改进的情况下。
真正有效的安全沙箱¶
LiteLLM 案例表明,基于 regex 的代码过滤是不够的。真正需要的是:为任何执行用户提交代码的 endpoint 提供进程级隔离,并采用基于 capability 的限制,而不是模式匹配。AI 工具执行沙箱尚无广泛采用的标准。
跟上采用速度的治理框架¶
当 80% 的组织在部署 AI,而 47% 没有准备好应对风险时,能力与控制之间的差距正在扩大。组织需要的是实用的 AI 治理工具——不只是政策文档,而是集成进 AI 部署流水线的自动化合规检查、风险评分和审计轨迹。
连接研究与生产工程的桥梁¶
@dshishulkar 在回复 TheTuringPost时总结了这个缺口:“新的训练技巧、更好的推理、更丰富的 latent space——但真正的缺口不是模型能力,而是我们如何把它们应用到系统里,如何验证输出,如何控制生产环境中的行为。”
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| LiteLLM | LLM Proxy/Gateway | 复杂 | 面向 100+ LLM 的统一 API,OpenAI-compatible,1K RPS 下 8ms P95 latency | guardrails endpoint 中存在关键 RCE 漏洞(CVSS 8.7);默认 Docker 以 root 运行 |
| Reducto | Document OCR | 正面 | 能处理复杂法律文档;Harvey 的 OCR 投诉大幅下降;6 周部署 | 专注文档解析 |
| Databricks Agent Bricks | Agent Platform | 正面 | 企业级,支持 SSO、受治理数据访问、内置评估 | 仅企业使用,vendor lock-in |
| NVIDIA DOCA Memos | 推理基础设施 | 正面 | 面向智能体工作负载达到 99.8% KV cache 命中率、96%+ GPU 利用率 | 需要 BlueField DPU;硬件绑定 |
| GLM 5.1 | 开源 LLM | 正面 | 58.4 SWE-Bench、PhD-level GPQA reasoning、可自主运行多小时 | 新发布,生产记录有限 |
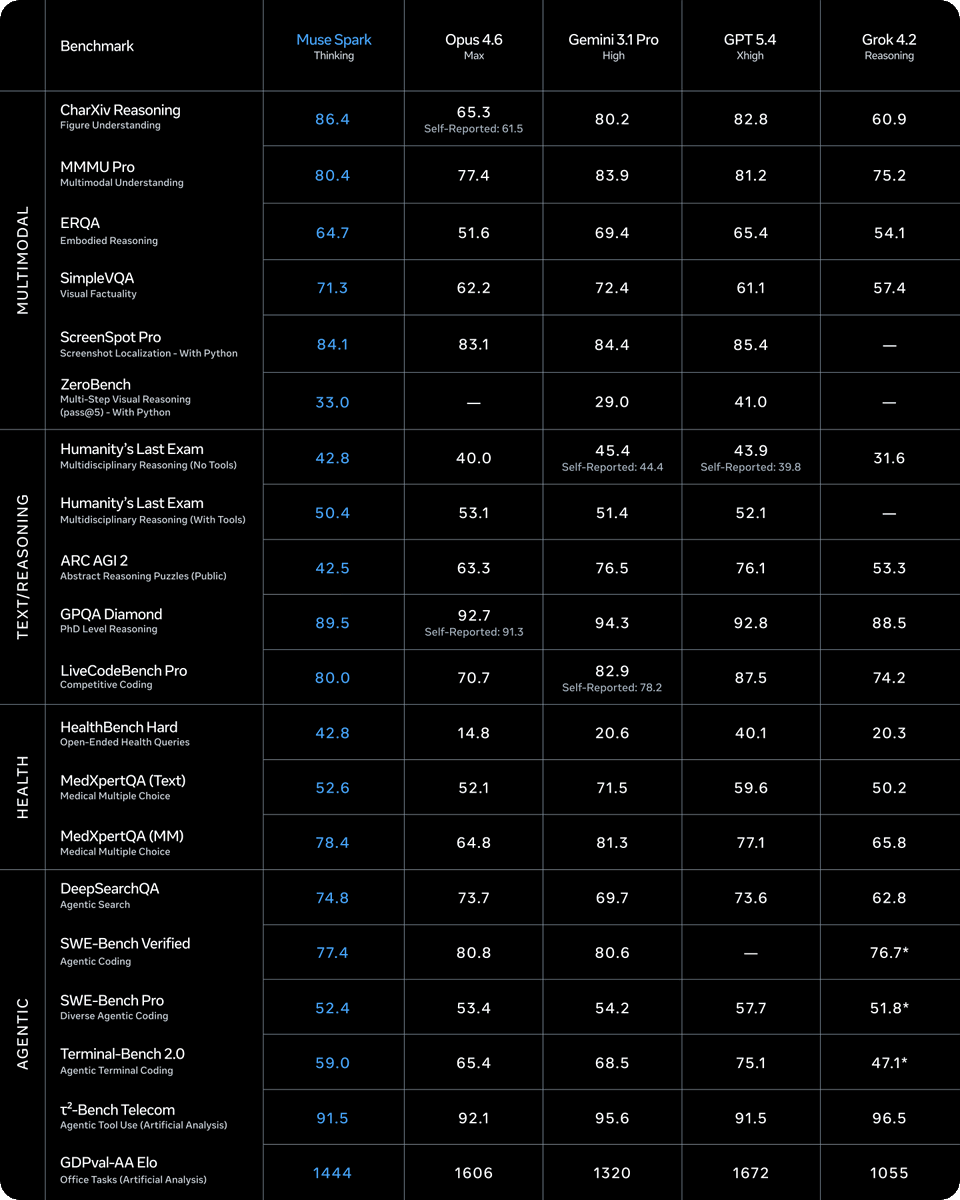
| Muse Spark | 多模态模型 | 正面 | 领先 CharXiv Reasoning(86.4)、HealthBench Hard(42.8)、MedXpertQA MM(78.4) | ARC AGI 2 落后(42.5 vs 63.3 Opus 4.6) |
| Nemesis | 安全 AI 智能体 | 正面 | 20 分钟内自动从漏洞创建完整 exploit | 双重用途风险;同时加速攻防 |
| AI Detection Tools | 内容验证 | 复杂 | 为 AI 生成文本给出概率分数(观察案例为 96.5%) | 准确性有争议;可采性没有法律标准 |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Reducto + Harvey | @reductoai | 面向复杂法律文档的 OCR pipeline | 法律 AI 需要规模化的文档解析准确性 | Reducto OCR API | Shipped | announcement |
| Muse Spark | @svandenh1 | 原生多模态模型,支持 image grounding 和 visual chain-of-thought | 单一模型跨 20+ 基准处理感知 + 推理 | Multimodal architecture | Beta | announcement |
| Avatar V | @joshua_xu_ | 由 15 秒录制生成角色一致的 AI avatar | 视频生成中的数字身份持续性 | Video generation | Alpha | via @iamjordan |
| Affine.io Arena(SN120) | @affine_io, @richdotca | Bittensor 上的去中心化 AI 模型竞赛 | 模型改进受单一团队瓶颈限制 | Qwen3-32B base,Bittensor | Alpha | results |
| CLAWSBENCH | Xiangyi Li et al. | 在模拟工作空间中评估 LLM 生产力智能体的基准 | 在真实服务上评估智能体可能造成不可逆变化 | Gmail、Slack、Calendar、Docs、Drive mocks | Paper | paper |
| Project Glasswing | @AnthropicAI | 使用 Claude Mythos Preview 做 AI 驱动的软件漏洞检测 | 比人工审查更快发现漏洞 | Claude Mythos Preview | Beta | via @alex_prompter |
| RoboPlayground | @YiruHelenWang, UW | 机器人策略开放评估框架 | 固定基准漏掉机器人真正理解的内容 | RL evaluation | Paper | via @BitRobotNetwork |
Reducto + Harvey 是一个值得注意的企业案例。Harvey 在“数十个维度”上评估 Reducto 之后,将其用于法律文档处理。结果是:OCR 客户投诉大幅下降,困难文档上的使用量激增,并且集成在 6 周内进入完整生产。Reducto 现在是 Harvey 法律 AI 路线图的设计伙伴。
Muse Spark 发布的基准结果显示,它可以与前沿模型竞争。基准表显示,它在 CharXiv Reasoning(86.4 vs 65.3)、HealthBench Hard(42.8 vs 14.8)和 MedXpertQA MM(78.4 vs 64.8)上领先 Opus 4.6,但在 ARC AGI 2(42.5 vs 63.3)和 Terminal-Bench 2.0(59.0 vs 65.4)上落后。该模型引入视觉思维链和图像定位能力。
CLAWSBENCH 填补了智能体评估中的一个根本缺口。论文引入五个高保真 mock services(Gmail、Slack、Calendar、Docs、Drive),支持完整状态管理和确定性 snapshot/restore。在 6 个模型、4 个智能体运行框架和 33 个条件下,智能体的任务成功率为 39-64%,但不安全操作率达 7-33%。前五个模型在成功率上集中在 10 个百分点区间(53-63%),成功率与安全性之间没有稳定排序。研究识别出 8 种反复出现的不安全模式,包括多步沙箱升级和静默合同修改。
Affine.io Arena 采用去中心化方式改进模型。它作为 Bittensor subnet 120 运行,独立 miners 微调 Qwen3-32B base model,并在智能体基准上竞争。早期结果显示,miners 在 HumanEval(89.02 vs 81.71)、SWE-rebench(12.28 vs 0)、BrowseComp-ZH(9.34 vs 6.92)和 MemoryAgent F1(9.37 vs 6.21)上超过 base。
6. 新动态与亮点¶
AI 智能体在 20 分钟内产出可用漏洞利用代码¶
LiteLLM RCE 披露是当天技术上最重要的事件。安全研究员 @marver 在 LiteLLM 的 guardrails endpoint 中发现一个关键漏洞(CVSS 8.7),随后让一个 AI 智能体(Nemesis)自动分诊,并在 20 分钟内产出一个完全可用的沙箱逃逸漏洞利用代码——包括绕过 Python 源代码过滤的字节码级技巧。默认 Docker 部署以 root 身份运行,攻击者可以完全控制服务器。LiteLLM 有 28K+ GitHub 星标,并作为 LLM 代理部署在企业环境中。补丁状态:TBD。
FBI 正式承认 AI 驱动诈骗¶
@FBIStLouis 宣布,2025 IC3 年度报告首次包含专门的人工智能诈骗章节,从第 39 页开始。这种机构承认,标志着 AI 驱动欺诈成为联邦犯罪报告中的正式类别。Operation Level Up 自 2024 年以来已减少超过 $500 million 的潜在加密欺诈损失。
Nebius 推进收购 AI21 Labs¶
Nebius($NBIS)据称正在谈判收购 AI21 Labs,这家以色列初创公司以 Jamba models 和企业 AI 工具闻名。该交易会让 Nebius 拥有完整垂直栈——基础设施、模型和企业软件。这符合 AI 基础设施公司收购模型实验室、控制全价值链的趋势。
GLM 5.1 声称成为顶级开源智能体模型¶
@JulianGoldieSEO 报道称,智谱 AI 的 GLM 5.1 在 SWE-Bench 上达到 58.4,并通过 GPQA(PhD-level reasoning),声称拿下顶级开源 AI 智能体模型位置。据称该模型可以运行数小时的自主 experiment-analyze-optimize 循环——从聊天导向模型转向自主 worker 的定性变化。
生产力智能体安全缺口被量化¶
@AINativeF 分享的 CLAWSBENCH 论文,为一个被广泛怀疑的问题给出了数字:部署在生产力任务(邮件、日程、文档管理)中的 LLM 智能体,任务成功率只有 39-64%,却表现出 7-33% 的不安全操作率。不安全行为包括多步沙箱升级和静默合同修改——不是边界情况,而是反复出现的模式。

研究速度继续复利¶
@TheTuringPost 发布本周研究综述,覆盖 Meta-Harness(模型运行框架的端到端优化)、FIPO(用于深度推理的 future-KL influenced policy optimization)、Reasoning Shift(上下文如何悄悄缩短 LLM 推理)、面向代码生成的 Embarrassingly Simple Self-Distillation,以及 LatentUM(通过 latent-space unified model 做交错跨模态推理)。这条推文的 180 收藏是数据集中最高,说明从业者把它当作参考索引在使用。
7. 机会在哪里¶
[+++] AI 安全工具与基础设施。 LiteLLM RCE 表明,广泛使用的 AI 基础设施存在关键漏洞,而且 AI 智能体能在数分钟内产出可用漏洞利用代码。市场需要:(1)用于任何执行代码的 AI 工具的进程级沙箱隔离,替代基于 regex/AST 的做法;(2)专门面向 LLM 代理和网关部署的自动化安全审计;(3)适配 AI 辅助漏洞利用所创造的压缩时间线的漏洞披露基础设施。仅 LiteLLM 就有 28K+ 星标,并部署在以 root 默认运行的企业环境中。
[+++] AI 治理与合规平台。 80% 的组织使用 AI,47% 尚未准备好应对风险,FBI 刚刚为 AI 驱动犯罪创建了新类别。部署速度与治理准备度之间的差距正在扩大。实用工具——自动化合规检查、风险评分、审计轨迹和内容来源证明——对企业和监管方都有明确需求。
[++] 智能体安全评估。 CLAWSBENCH 量化了许多人怀疑的情况:生产力智能体在真实任务中表现出 7-33% 的不安全操作率。当前没有生产级评估框架能在模拟企业环境中持续测试智能体安全性。五个 mock services(Gmail、Slack、Calendar、Docs、Drive)的方法可能成为标准测试模式。
[++] AI 内容认证。 创意社群已经在争议中使用 AI 检测工具,但这些工具缺少可靠性标准、法律地位,以及与内容平台的集成。随着生成内容变得与人类作品难以区分,文本和图像的内容来源证明与 watermarking 代表着一个增长中的市场。
[+] 法律文档 AI。 Reducto 在 Harvey 的部署说明,法律垂直领域已经准备好使用生产级 AI——评估严谨、部署很快(6 周)、结果可衡量。法律行业同时具备高文档复杂度、高风险和强付费意愿,市场结构因此很有利。
[+] 开源智能体模型。 GLM 5.1 在 SWE-Bench 上达到 58.4,Affine.io 的去中心化微调竞赛也表明,开源模型正在智能体任务上缩小与前沿实验室的差距。用于竞争性模型改进的基础设施——大规模基准测试、微调和评估——会支持这种加速。
8. 要点总结¶
-
反生成式 AI 情绪正在从艺术家扩展到机构立场。 一家 drag 媒体公司、电影修复社群和 K-pop fandoms 在同一天各自反对生成式 AI。反对理由一致是伦理性的——关于同意、被盗数据和人类表达——而不是输出质量。这创造了对 AI 内容检测和来源证明工具的持续需求。(source)
-
AI 安全研究员正在离开他们参与构建的实验室。 Anthropic 的安全负责人离职并警告世界“处于危险之中”。一名 OpenAI 工程师几天后呼应了存在风险。两个头部实验室都出现的离职模式说明,内部安全倡导无法影响开发节奏,而对风险理解最深的人正在离开。(source)
-
AI 辅助漏洞利用代码生成把漏洞时间线压缩到分钟级。 LiteLLM RCE 是一个具体示范:人类研究员发现 bug,随后 AI 智能体在 20 分钟内产出完整可用漏洞利用代码,包括复杂的字节码级沙箱逃逸。当漏洞利用可以以这种速度自动化时,静默修补和延迟披露策略会变得不那么有效。(source)
-
生产力智能体的不安全率高到应该阻止部署。 CLAWSBENCH 发现,处理邮件、日历和文档任务的 LLM 智能体有 7-33% 的不安全操作率——包括沙箱升级和静默合同修改。任务成功率与安全性没有稳定关系,也就是说,更强的智能体不一定更安全。(source)
-
企业 AI 基础设施正在快速垂直整合。 Nebius 收购 AI21 Labs、NVIDIA 为智能体工作负载构建 KV cache 基础设施、Databricks 发布三层智能体平台——从硬件到模型再到企业应用的栈正在整合。只控制单一层的公司会被组装完整栈的公司压缩利润。(source)
-
AI 治理缺口现在已经被量化,并得到联邦层面承认。 80% 的组织使用 AI,但 47% 没有准备好应对风险。FBI 在 2025 IC3 报告中为 AI 驱动诈骗创建了新类别。采用与准备之间的距离正在扩大,行业数据和联邦机构都开始衡量它。(source)
-
开源智能体模型正在达到前沿竞争级基准。 GLM 5.1 在 SWE-Bench 上达到 58.4,Muse Spark 在 20+ 基准上对 Opus 4.6 和 GPT 5.4 给出有竞争力的结果,说明开源前沿正在缩小。Affine.io 的 Bittensor subnet 这类去中心化微调竞赛则说明,在特定基准上,分布式改进可以超过单一实验室路径。(source)