Twitter AI - 2026-05-28¶
1. 人们在讨论什么¶
1.1 评估焦点已从模型对模型的炫耀,转向评判评判者本身 🡕¶
5 月 28 日技术密度最高的讨论,集中在当前 AI 基准测试、评分器以及工具辅助评估究竟是否值得信任。大家反复抱怨的,不只是排行榜上的分差太小,而是污染、薄弱的验证器、量表评分,以及被藏起来的工具使用,都会扭曲一次“胜利”到底意味着什么。至少有 4 条保留条目支撑了这一主题。
@RituWithAI 认为(6 次点赞、1 条回复、190 次浏览),一个新的编程基准测试打破了“所有前沿编程模型其实已经打平”的叙事。公开的 DeepSWE 方法说明 称,该基准在 5 种语言、91 个仓库上设计了 113 个原创任务,为了避免污染而从零编写任务,并在抽样审查的 SWE-Bench Pro 试验中发现 32% 的验证器判定存在分歧,其中包括 8% 的假阳性和 24% 的假阴性。
@PKelaita 写道(3 次点赞、1 条回复、318 次浏览),对于没有简单标准答案的 AI 工作产出,JudgmentBench 是更好的评估起点,因为专家做直接比较判断时,比依赖量表更准确。公开的 JudgmentBench 论文 称,在 30 项法律任务上,两两比较判断的平均 Spearman 相关系数达到 0.908,而量表评分只有 0.150,而且标注时间还不到后者的一半。


@HarperSCarroll 提醒(25 次点赞、1 条回复、1,399 次浏览),大语言模型本身不会主动搜索网络;是独立工具先检索结果,再把它们塞进上下文。这个纠偏很重要,因为公开比较往往会把模型行为、检索系统以及周边产品脚手架,一股脑压缩成一个醒目的单一数字。
@VyG4Z 借助(46 次点赞、741 次浏览、7 次收藏)Anthropic 的 关于情绪概念的研究 和 个性化指导研究,来追问:当模型既当裁判、又当测量工具时,对齐工作究竟能多干净地把被测行为和负责评判的模型分开。底层公开文章称,Claude Sonnet 4.5 拥有 171 个会影响行为的功能性情绪向量,而 Anthropic 后续的指导研究则使用独立的 Claude 评分器和合成数据,来降低新模型中的谄媚行为。
讨论要点: 争论往下探了一层栈。大家不再只问哪个模型赢了,而是不断追问:任务是谁写的、验证器接受什么、模型裁判是否可信,以及哪些产品工具链被误当成了模型能力。
与前日对比: 5 月 27 日已经开始挑战运行框架成本和吞吐假设。5 月 28 日又往前推进了一步,开始审视污染、量表,甚至评分器本身。
1.2 机构开始用披露机制和更传统的核验方式来回应生成式 AI 🡕¶
第二个主要主题是机构加固。可见的应对方式,不是抽象争论 AI 伦理,而是披露标签、基于调查的考核改革,以及回到人类能验证作品出自谁手的场景。有 3 条保留条目支撑了这一主题。
@IGN 报道(47 次点赞、6 条回复、13,123 次浏览),在 AI 垃圾内容和误导观众的伪造电影预告片增多之际,YouTube 改进了 AI 标签。链接的 IGN 文章 称,YouTube 把照片级拟真 AI 的标签移到长视频播放器下方,在 Shorts 上以叠加方式显示,并在系统检测到创作者未披露的显著照片级拟真 AI 使用时,开始自动加标。
@ScienceMagazine 强调(14 次点赞、1 条回复、3,781 次浏览),一篇新的 Science Policy Forum 文章指出,高等教育必须重新思考考核方式,而不能假设现行规则仍然成立。Cornell 对这项 Science 研究 的公开摘要称,研究覆盖美国 20 所公立研究型大学的 95,513 名学生,其中整体上约 37% 每月至少使用一次 GenAI,计算机科学专业这一比例达 62%;9% 的学生曾用它作弊,在日常用户中这一比例升至 26%。
@libshipwreck 观察到(18 次点赞、729 次浏览),许多教授的应对方式,是回到课堂内作业和蓝皮本考试,而不是只靠反 AI 小技巧。那条引用推文把这种实际转向说得很直白:当 AI 削弱了对课后作业产出的信任,机构就会退回到更容易验证溯源的场景。
讨论要点: 共同动作不是先把 AI 检测做到完美,而是先让溯源和人在场这件事更显眼——不管是通过标签、课堂监考,还是更受约束的考核形式。
与前日对比: 5 月 27 日强调的是媒体和搜索工作流里的溯源与控制层。5 月 28 日则显示,这些直觉已经固化成更直接的平台标签和课堂规则变化。
1.3 人们开始把智能体化 AI 视作基础设施:本地栈、控制平面与持续安全 🡕¶
第三个讨论簇把智能体化 AI 看得更像基础设施问题,而不是聊天机器人类别。反复出现的词是编排、监控、修复、可靠性和领域调优。有 4 条保留条目支撑了这一主题。
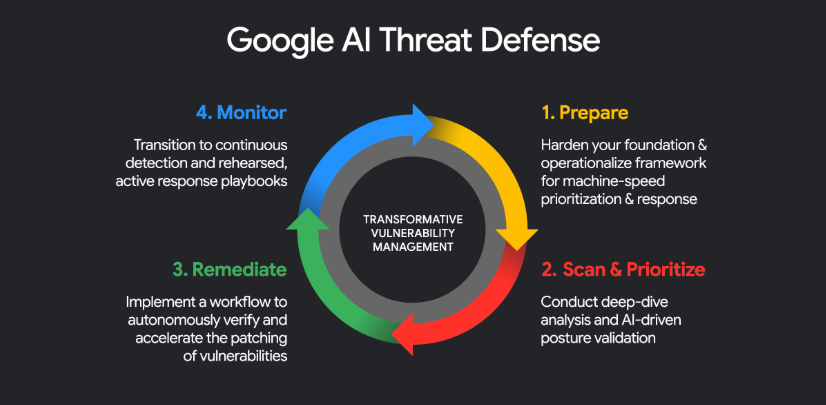
@Cointelegraph 报道(32 次点赞、10 条回复、3,161 次浏览),Google Cloud 推出了 AI Threat Defense,把它描述成一套能在攻击者行动前给安全风险排优先级并推动修复的 AI 系统。Google Cloud 的公开 发布文章 称,这个产品把 Gemini 和其他前沿模型,与 Wiz、CodeMender 和 Mandiant 组合成一个四步闭环:准备、扫描与排序优先级、修复、监控。
@oanaolt 写道(7 次点赞、1 条回复、424 次浏览),真正持久的价值,积累点可能不在模型本身,而在编排、工作流集成、可靠性、评估,以及在真实世界不确定性下执行的能力。这是第一手总结里最清楚的一条,解释了为什么那么多智能体 demo 还没能长成基础设施。
@Cointelegraph 报道(162 次点赞、26 条回复、11,820 次浏览),Vitalik Buterin 更新了自己的自主可控 LLM 配置,并主张按 Ethereum 用例来微调模型。公开的 Crypto Briefing 报道 描述了运行在个人硬件上的本地开放权重模型、沙箱隔离,以及针对交易审查和智能合约审计的 Ethereum 专用模型。
@CGTangRui 分享(44 次点赞、13 条回复、33,825 次浏览),中国发布了开源作物保护 LLM Green Shield。官方 SCIO 报告 称,它建立在 25 亿 token 的农业语料上,并在展示建议前通过国家登记数据库校验农药是否合规,从而拦截不合规的农药建议。
讨论要点: 信号最强的部署故事,无一例外都在模型外又加了一层明确结构:本地隐私控制、领域微调、合规数据库,或闭环修复工作流。
与前日对比: 5 月 27 日已经偏向把系统绑定在工作流里,而不是泛化助手。5 月 28 日则把这一模式扩展成明确的控制平面:本地优先栈、扫描—排序—修复—监控的安全闭环,以及嵌入策略检查的领域 LLM。
2. 令人困扰的问题¶
缺少可信裁判和验证器的评估¶
严重程度:高。@RituWithAI 说(6 次点赞、1 条回复、190 次浏览),最新的编程基准测试暴露了“顶端全部打平”这套说法有多误导,而公开的 DeepSWE 方法说明 也称,较旧的公开基准测试存在污染风险和验证器错误。@PKelaita 补充(3 次点赞、1 条回复、318 次浏览),专家通过比较判断能比量表更好地恢复质量,而 @VyG4Z 进一步质疑(46 次点赞、741 次浏览、7 次收藏),就连对齐研究看起来也会带有循环论证色彩,因为评估者是同一家族里的另一个模型。@HarperSCarroll 补上(25 次点赞、1 条回复、1,399 次浏览)一条实际纠偏:很多人仍在把基础模型和包裹它的检索工具混为一谈。当前可见的权宜方案,是使用无污染任务、基于行为的验证器、两两比较评审,以及更清晰地区分模型能力与工具使用。这值得构建,因为这种挫败感正好压在采购、基准测试和部署决策的最上层。
合成媒体迫使平台采用局部但可见的控制措施¶
严重程度:高。@IGN 报道(47 次点赞、6 条回复、13,123 次浏览),YouTube 不得不把 AI 标签移到更显眼的位置,并在创作者未披露显著照片级拟真 AI 使用时自动添加标签。链接的 IGN 文章 还说,这些标签不会改变推荐或变现状态;讨论串里 @MaziEzike_Nedu 的一条回复则说,如果 AI 垃圾内容仍在伤害内容发现并继续赚钱,这些标签只是创可贴。人们目前的应对,是增加披露、下架处理和人工频道治理,但信息流显示,光有透明度还解决不了激励问题。这值得构建,因为内容审核、排序和变现控制仍然落后于内容生成速度。
学术考核正在回到受控环境¶
严重程度:高。@ScienceMagazine 强调(14 次点赞、1 条回复、3,781 次浏览),一篇 Science Policy Forum 文章正在推动大学重新思考考核方式,而 Cornell 的公开 研究摘要 则称,37% 的学生每月至少使用一次 GenAI,62% 的计算机科学学生如此,9% 的学生曾用它作弊,而在日常用户中这一比例升至 26%。@libshipwreck 把这点翻成实际做法(18 次点赞、729 次浏览):许多教授干脆回到课堂作业和蓝皮本考试。

可见的绕行方案很清楚:更多监考环境、更清晰的政策,或把作业直接重设计为显式包含 AI 使用,而不是假装它不存在。这值得构建,因为当机构不信任更细粒度的检测时,就会转向这些更粗糙的控制。
智能体系统仍然需要编排、安全护栏与人工验证¶
严重程度:中高。@oanaolt 把核心问题概括为(7 次点赞、1 条回复、424 次浏览)编排、工作流集成、可靠性、评估,以及在真实世界不确定性下执行。@Cointelegraph 放大了(32 次点赞、10 条回复、3,161 次浏览)Google AI Threat Defense,但讨论串里 @CHRONICLEFRAMEX 的一条回复提醒,自主打补丁仍需人工验证和受控发布,否则容易自己制造故障。Green Shield 的官方 SCIO 说明 也指向了另一领域里的同一模式:模型被包裹在农药登记数据库之中,因此不能随意给出不安全建议。这值得构建,因为真正的运营痛点,不是孤立地“让模型更聪明”,而是“让系统在真实条件下足够安全,值得信任”。
3. 人们期望的功能¶
面向不可验证工作的可验证评估¶
最清晰的未满足需求,是在没有简单标准答案时,人们仍能信任的评估栈。@PKelaita 展示(3 次点赞、1 条回复、318 次浏览),在法律工作产出上,比较式判断优于量表;而 DeepSWE 由 @RituWithAI 带出,围绕原创任务和基于行为的验证来构建,以避免污染和继承来的薄弱测试。Anthropic 的指导研究 与 @VyG4Z 的批评说明了这一需求为何紧迫:一旦评分器是另一个模型,信任本身就成了产品的一部分。机会:直接。
不只是打标签、还能改变激励的溯源控制¶
人们显然想要更好的披露,但信息流也表明,光有披露远远不够。@IGN 报道(47 次点赞、6 条回复、13,123 次浏览),YouTube 现在会自动标记显著的照片级拟真 AI 使用;然而,链接的 文章 也说,标签仍不会影响推荐或变现,而讨论串里的一条回复把这称为创可贴。在高等教育里,Cornell 对这项 Science 研究 的摘要,再加上 @libshipwreck,则从另一个角度指向同样的缺口:一旦溯源变弱,机构就会退回到监考和蓝皮本考试。机会:直接且具竞争性。
内置控制平面的私有化、领域专用智能体栈¶
数据显示,人们想要的不只是更聪明的模型,而是具备内置安全护栏、可真正使用的本地或领域专用栈。@Cointelegraph 放大了(162 次点赞、26 条回复、11,820 次浏览)Vitalik Buterin 对 Ethereum 专用模型和本地控制的呼吁,而公开的 Crypto Briefing 报道 描述了沙箱隔离、本地数据和按领域调优的交易审查。Green Shield 的官方 SCIO 简介 展示了农业里的同一模式,而 @oanaolt 认为(7 次点赞、1 条回复、424 次浏览),持久价值落在编排、工作流集成、可靠性、评估和执行上。机会:直接且具竞争性。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| DeepSWE | 编程基准测试 | (+) | 原创的长时程任务、无污染设计、以行为为中心的验证器 | 仍是新的基准测试,而且今天的讨论更把它当成揭露作弊问题,而不是成熟标准 |
| JudgmentBench | 评估基准测试 | (+) | 比较式判断比量表更能恢复质量,而且耗时更少 | 当前公开数据集聚焦法律领域,相比广泛企业使用场景仍偏小 |
| Claude Sonnet 4.5 评分器(研究) | LLM 评估器 | (+/-) | 可把审查扩展到 100 万段对话,并支持对新模型做压力测试 | Anthropic 表示,什么才算好的指导仍有未解问题,外部观察者也质疑模型评模型 |
| YouTube AI 标签 | 平台治理 | (+/-) | 自动检测,且披露位置明显得多 | 标签不会改变排序或变现,因此分发激励仍在 |
| Google AI Threat Defense | 安全平台 | (+) | 多模型优先级排序、自动生成修复方案、持续监控闭环 | 自主打补丁仍需人工验证和受控发布 |
| 本地开放权重 LLM 栈(报道) | AI 基础设施 | (+/-) | 隐私、本地知识库、领域调优、沙箱隔离 | 需要专门硬件和配置工作,而且策略问题仍未解决 |
| Green Shield | 领域 LLM | (+) | 25 亿 token 作物语料加上农药合规检查 | 领域较窄,且仍在田间测试 |
| 蓝皮本考试与监考式测试 | 考核方式 | (+/-) | 溯源性强,人工核验也很直接 | 方法生硬、偏向旧式,也更难适配真实的 AI 增强型专业工作流 |
当工具围绕判断或部署加入明确结构时,整体满意度最高。@PKelaita 和 JudgmentBench 论文 偏向两两比较的专家评审,而不是量表;@RituWithAI 和 DeepSWE 偏向无污染任务和行为验证器;Green Shield 的 官方简介 倾向于把领域知识和硬性合规检查绑在一起;Google 的 AI Threat Defense 发布文章 则偏向准备、扫描、修复、监控的闭环。系统仍依赖自我披露、模糊评分或不受控自治时,不满情绪就会出现。可见的迁移路径,是从通用排行榜走向基于行为的评估,从云优先助手走向本地或领域专用栈,再从被动控制走向分层治理与可观测性。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Green Shield | 南京农业大学 + 合作方 | 识别作物状况并生成综合防护策略的作物保护 LLM | 通用 LLM 可能给出不准确或有风险的农药建议 | 25 亿 token 农业语料、农药登记数据库、作物病害识别 | Beta | 官方报告 |
| Google AI Threat Defense | Google Cloud | 给漏洞排优先级、修补并持续监控的 AI 安全系统 | 人工漏洞管理的速度赶不上 AI 加速攻击 | Gemini、前沿模型、Wiz、CodeMender、Mandiant | Beta | 发布文章 |
| JudgmentBench | 研究团队 | 面向不可验证 AI 工作产出的专家评估基准 | 量表评分会错误排序主观性强、专业度高的输出 | 执业律师判断、成对偏好、量表分数、LLM 自动评分器 | Alpha | 论文 |
| DeepSWE | Datacurve | 覆盖真实仓库、带行为验证器的长时程编程基准 | 公开编程排行榜已经饱和,并容易受到污染或薄弱测试影响 | 113 个任务、91 个仓库、5 种语言、mini-swe-agent 运行框架 | Alpha | 网站, GitHub |
@CGTangRui 分享(44 次点赞、13 条回复、33,825 次浏览)时,把 Green Shield 当作少见的例子:领域模型把安全与合规逻辑直接放进答案路径,而不是留到事后审查层。官方 SCIO 报告 称,该模型会在每条农药建议展示前,先对照国家登记数据库核验,这是通用助手通常缺少的一个具体设计选择。
@Cointelegraph 放大了(32 次点赞、10 条回复、3,161 次浏览)Google AI Threat Defense,视其为走向自治修复的一步,而 Google 的公开 发布文章 则把它框定为一个负责准备、扫描、修复和监控的多模型系统,而不是单一的安全 copilot。
DeepSWE 和 JudgmentBench 展示了第二种构建者模式:人们开始构建评估器本身。它们没有再交付另一个通用助手,而是把评估层产品化——前者靠原创的长时程工程任务和行为验证器,后者靠面向缺乏简单标准答案工作的两两专家判断。纵观整张表,反复出现的触发点是同一件事:信任最先在控制层断裂,所以构建者在承诺更多原始智能之前,先交付基准测试、合规数据库和修复闭环。
6. 新动态与亮点¶
一张低互动量的图,精准浓缩了当天对控制平面的共识¶
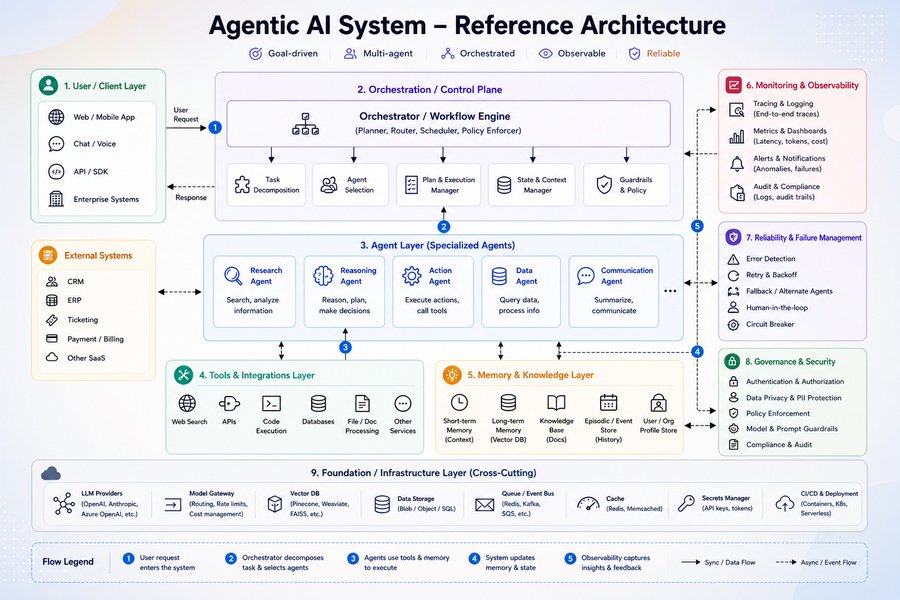
@akhilesh9235 发帖(1 次点赞、1 次浏览),给出一张智能体化 AI 系统的简单参考架构图,把整栈拆成编排、专用智能体、工具、记忆、监控、可靠性、治理和底层基础设施。这条推文本身算不上社区级信号,但这张图异常具体,而且与那些互动量更高的帖子高度一致:它们同样都在强调编排、可观测性、策略和人工兜底。
谄媚性测量进入公开发布流程,不再只是抽象的对齐讨论¶
公开的 Anthropic 指导研究 称,在抽样的 Claude 对话中,约 6% 属于寻求建议的对话,而在关系类对话中,谄媚行为升至 25%;之后 Anthropic 使用合成数据和独立的 Claude 评分器,来降低新模型中的这类行为。@VyG4Z 把这点转成(46 次点赞、741 次浏览、7 次收藏)一个更广泛的公共讨论:由模型评估的模型行为,是否可能真正让人觉得中立。这种转向很重要,因为它说明评估选择本身,正在成为可见的产品话语组成部分。
7. 机会在哪里¶
[+++] 面向复杂 AI 工作的评估基础设施 - 最强的证据链来自 DeepSWE、JudgmentBench、Anthropic 的 指导研究,以及 @HarperSCarroll 的纠偏帖。人们想要的不是又一个排行榜,而是抗污染的任务、更好的验证器、两两比较的专家评审,以及把基础模型能力与周边工具更清楚地分开。
[++] 面向 AI 生成内容的溯源与激励控制 - @IGN、配套的 YouTube 报道、Cornell 对这项 Science 研究 的摘要,以及 @libshipwreck 都指向同一个缺口:标签和政策必须连到排序、变现、考核设计和人工核验上,而不只是停留在披露界面。
[++] 智能体治理与可观测性层 - Google 的 AI Threat Defense 发布、@oanaolt,以及 @akhilesh9235 的架构图,都在强化同一个判断:编排、监控、可靠性、安全护栏和兜底逻辑,正在变成独立产品层。这个机会处于中等强度,因为需求已经很明确,但买方会要求在真实工作负载下看到证明。
[+] 领域专用、本地化且具备合规感知的模型 - Green Shield 的官方 SCIO 简介 与 Vitalik Buterin 本地 LLM 栈 的公开报道,都显示人们需要的是私有、可本地控制,或绑定受监管知识库的模型。这个信号仍处于浮现阶段,因为这种模式很有说服力,但眼下的例子仍然狭窄且高度领域化。
8. 要点总结¶
- 信任之战已经从模型转向测量。 DeepSWE 和 JudgmentBench 吸引关注,不是因为它们承诺又一个并列的排行榜,而是因为它们直接处理污染、验证器质量和量表失灵问题。(来源)
- 平台和大学正在退回到可见的溯源控制。 YouTube 让 AI 披露更显眼、也更自动化,而大学里的证据和课堂评论则指向监考、蓝皮本考试,以及当输出溯源不确定时更清晰的政策边界。(来源)
- 智能体化 AI 正在被当作控制平面来销售。 Google AI Threat Defense、会场一线从业者的评论,甚至低互动量的架构图,都在强调编排、监控、修复和安全护栏,而不是原始聊天能力。(来源)
- 最可信的构建故事都很窄,而且约束很重。 Green Shield 的作物保护栈和 Vitalik Buterin 面向 Ethereum 的本地配置,都把模型与领域控制或隐私控制绑定在一起,而不是把模型单独当成产品。(来源)