Twitter AI Agent - 2026-04-07¶
1. What People Are Talking About¶
1.1 Harness Engineering Goes Mainstream (🡕)¶
The concept of "harness engineering" dominated the AI agent conversation on April 7, driven by a landmark Latent Space podcast episode revealing how OpenAI's Frontier team operates a 1M+ LOC codebase with zero human-written code and zero human-reviewed code before merge, consuming over 1 billion tokens per day.
@latentspacepod published an interview with Ryan Lopopolo from OpenAI, detailing the "Dark Factory" — a system where 50+ Codex agents work in parallel on a codebase called Symphony, described as a "ghost library" with no human code. Lopopolo called it borderline "negligent" if teams aren't using 1B+ tokens/day, roughly $2-3K/day in token spend (post).
@IntuitMachine published a detailed L1-L6 maturity model mapping four AI disciplines — Prompt Engineering, Context Engineering, Harness Engineering, and Intent Engineering — to organizational maturity levels, with each level building on the previous. The diagram shows that L4 (Harness Engineering) is where "changing harness moves performance dramatically" (post).

@DSPyOSS offered a sardonic commentary on the terminology churn: "2022: prompt tricks!! 2023: prompt engineering!! 2024: agentic workflows! 2025: context engineering!! 2026: harness engineering!!! us: .. DSPy." A reply from @tedhall23 asked a substantive question about "deterministic AI workflows vs. fully agentic, tool calling behavior" for actual companies (post).
@caspar_br distilled the practical takeaway: "There are three layers you can improve an agent at: model, harness, and context. Most teams fixate on the model. But context (skills, instructions) is the layer you can iterate on fastest" (post).
@victor_explore connected the Claude Code source leak to harness engineering, arguing that "the Agent Harness is the actual product" and that the transition from "vibe coding" to harness engineering is "the most valuable move an engineer can make in 2026" (post).
Discussion insight: @MindTheGapMTG pushed the point further: "If the model exhibits 'unspoken strategic thinking,' your constraint layer is the only thing between you and a system optimizing for something you didn't intend. We run CLAUDE.md governance files across every agent pipeline for exactly this reason." This argues that harness engineering is not just about performance but about safety.
1.2 Agent Security Alarm Bells (🡕)¶
Multiple high-engagement threads sounded urgent warnings about agent security, with specific evidence of marketplace malware, unremediated vulnerabilities, and overly broad permissions.
@JamesonCamp posted a stark warning: "12% of OpenClaw's marketplace is literal malware. Keyloggers. Identity theft. Your AI agent is in the same Gmail where your wife sent your kids' SSN." He shared a personal experience of $55K in fraud hitting his Amex and argued that agents have "NOBODY sitting between it and your entire life" (post).
Discussion insight: @usmaanbuildsAI responded with actionable guidance: "Sandboxing, scoped OAuth tokens, and separate service accounts should be the minimum before connecting any agent to personal tools." @TrevorLongino pointed to a security scanning service as a partial solution.
@DeryaTR_ raised concern about an unremediated file exfiltration vulnerability in Claude Cowork, quoting Garry Tan: "Attackers can exfiltrate user files from Cowork by exploiting an unremediated vulnerability." The vulnerability was originally identified by researcher Johann Rehberger and was acknowledged but not fixed by Anthropic (post).
@AethirCloud detailed the broader OpenClaw security landscape in a thread: "1,000+ malicious skills, critical RCE vulnerabilities, and 135K+ exposed instances." They argued that shared VPS hosting means "your hosting provider retains full admin access. Your API keys, conversations, and agent actions are visible at the infrastructure layer" (post).
@alex_prompter framed the systemic problem: "We went from 'AI can't do anything useful' to 'AI has full access to my Gmail, Slack, and Salesforce' in 18 months. We skipped every security checkpoint that normal enterprise software had to pass" (post).
@koylanai shared a cautionary practitioner story: while building a multi-agent harness with bash scripts managing git branches, "the cleanup script ran git checkout -- . from the repo root and reverted every tracked file change." The lesson: "The more capable your agent system, the more authority you have to give it." Two images from a Simon Willison article reinforced best practices: automated testing, version control discipline, and manual QA are "more important as models improve, not less" (post).

1.3 Agent Marketplaces and Skill Ecosystems Proliferate (🡕)¶
The highest-engagement tweet of the day was about AI-Trader, and multiple projects announced agent marketplaces where agents transact, compete, and earn revenue autonomously.
@hasantoxr posted about AI-Trader, an open-source marketplace where "AI agents publish trading signals, debate strategies with each other, and execute trades across 7 asset classes fully autonomously." Any OpenClaw agent joins with one command, reads a skill file, registers, and starts trading. Human users follow top performers and copy positions. The project has 12.1K stars and 2K forks under MIT license. This was the highest-scored tweet of the day at 6368.3 with 566 likes, 1100 bookmarks, and 36.8K views (post).
@okx announced that Agent Trade Kit now includes a skills marketplace: "every skill accessible in a single command. Open to contributions. All skills are security-scanned and reviewed" (post).
@AegisPlace described a per-call revenue model: "Deploy a skill. Set a price. Every time an AI agent uses it, you get paid. Not monthly. Not annually. Every single call" (post).
@acedatacloud shared revenue data for their agent economy: "85M+ API calls processed. $326k in platform revenue in 90 days." When asked to verify the revenue claim, they pointed to their public roadmap and noted plans to bring it on-chain (post).
@BlackthorneAI analyzed VeChain's announcement of an agent marketplace "where AI agents can be created, hired, and paid onchain" with "native swap functionality," arguing "AI agents might become the next crypto narrative" (post).
1.4 Voice Agents Enter Production (🡕)¶
Three distinct voice agent announcements showed this category moving from demo to production deployment, with specific technical capabilities and pricing.
@yasser_elsaid_ launched Chatbase Voice: "The same AI agent that handles your emails and website chat, can now pick up the phone. One agent, deployed on every channel." The post drew 140 likes and 15.7K views, showing strong interest in omnichannel agent deployment (post).
@livekit addressed a specific pain point — pronunciation accuracy in specialized domains: "Pronunciation is one of the fastest ways to break trust in a voice agent, especially in healthcare, legal, and finance." Rime's Mist v3 introduces phonetic brackets for deterministic pronunciation, with TTFB as low as 100ms. A nurse agent demo showed fixes for words like "levothyroxine" and "gastroesophageal" (post).
Discussion insight: @adam_martin asked about HIPAA compliance, signaling enterprise readiness concerns.
@RoundtableSpace reported that "GROK VOICE AGENT NOW HANDLES REAL CALLS INSTANTLY WITH HUMAN LEVEL CONVERSATIONS AT $0.05 PER MINUTE" — the most aggressive pricing announced for a voice agent to date (post).
1.5 Skills Research: The Reality Check (🡕)¶
A significant research paper challenged the assumption that agent skills reliably improve performance, with practitioner reports corroborating the findings.
@dair_ai highlighted a paper from UC Santa Barbara and MIT: "How Well Do Agentic Skills Work in the Wild." The research tested agent skills under progressively realistic conditions using 34K real-world skills and found that "performance gains degrade consistently as conditions become more realistic, with pass rates approaching no-skill baselines." Query-specific skill refinement partially recovers lost performance, improving Claude Opus 4.6's pass rate on Terminal-Bench 2.0 from 57.7% to 65.5%. Code is available at github.com/UCSB-NLP-Chang/Skill-Usage (post).

Discussion insight: @d_ai_1231 corroborated: "In demos, agents look 'done' because they're given the right skills. But in real use, they often pick the wrong ones — and everything breaks under the surface. The gap isn't capability. It's selection."
@AlemTuzlak provided a concrete example: "I've tried using an agent to create something really cool with @tan_stack AI today and it was... rough. It assumed it's just using Vercel AI SDK and tried importing non-existent APIs." His solution: building TanStack AI skills to close the gap (post).
@DerekNee asked a broader question: "we get a new agent framework every 12 hours but almost no one is building evals that keep up. a lot of this is vibe coded. how do we even know what's good?" (post).
1.6 Memory Engineering Becomes a Discipline (🡕)¶
Multiple posts treated agent memory as a distinct engineering discipline, with architecture diagrams, neuroscience analogies, and specific implementation advice.
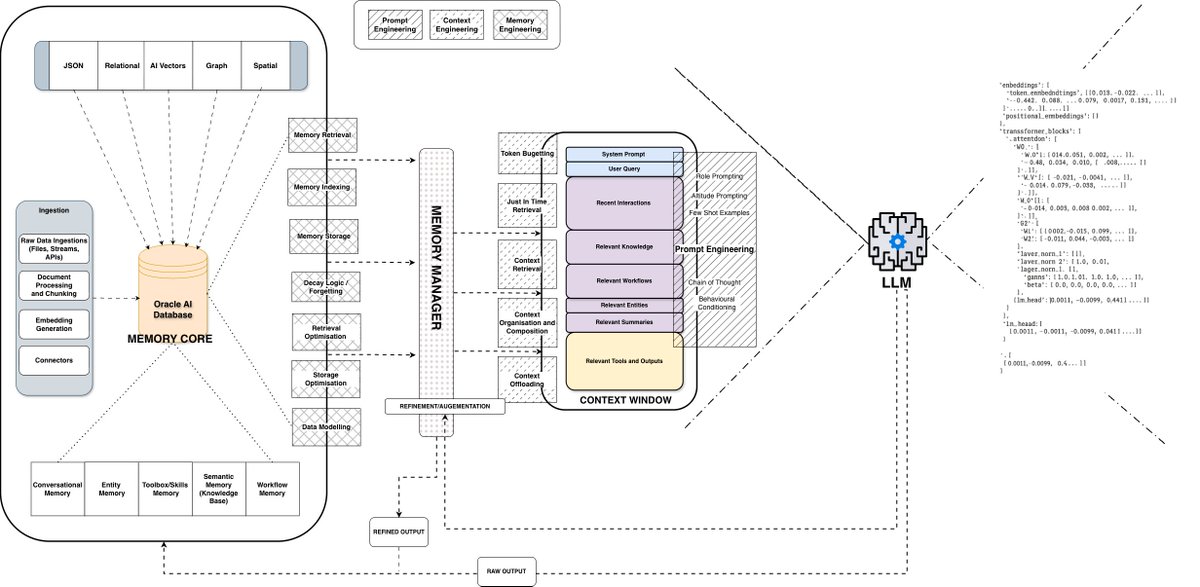
@ConorBronsdon shared a detailed memory architecture taxonomy from Richmond (Oracle): a Memory Core handling five data types (vectors, graph, relational, spatial, JSON), a Memory Manager orchestrating retrieval/indexing/storage/decay, and a Context Window where token budgeting determines what the model actually sees. The key insight: "Don't delete, forget. Information should decay through relevance scoring and importance weighting, not hard deletes." He cited a striking stat: "78% of enterprises have AI agent pilots. Only ~14% have scaled one to production" (post).
@Mr_memsy shared practical advice: "Turn on /dreaming in OpenClaw, add temporal decay + embedding cache, and suddenly your agent compounds knowledge instead of hallucinating stale context." He asked builders how they handle long-term memory, prompting discussion around RAG, vector DBs, and custom reflection loops (post).
1.7 Agent Frameworks Multiply (🡒)¶
The framework proliferation continued with major releases from ByteDance, China, and Google, alongside zero-code entrants.
@ZhihuFrontier detailed DeerFlow 2.0 from ByteDance: a LangGraph-based "Super Agent" framework with 30K+ stars, featuring a pluggable skill system, sandboxed execution environments (local/Docker/Kubernetes), dynamic sub-agent scheduling (max 3 parallel, 15-min timeout), context auto-summarization, and long-term memory with confidence scores (post).

@Sumanth_077 introduced AutoAgent, a zero-code LLM agent framework trending #18 on GitHub, with built-in Agentic-RAG "outperforming LangChain," universal LLM support, and top rankings on the GAIA benchmark (post).

@alifcoder announced CoPaw, a Chinese open-source agent framework that "rivals OpenClaw but runs locally" with Qwen 3.5 via Ollama, long-term memory, and full self-hosting (post).
@rseroter reported that Google open-sourced Scion, a multi-agent orchestration testbed that is "harness agnostic (comes with Gemini CLI, Codex, Claude, OpenCode) and lets you orchestrate work" (post).
2. What Frustrates People¶
Agent Permissions and Authority Management (High)¶
The most acute frustration is that agents accumulate broad permissions without adequate security checkpoints. @alex_prompter noted that the industry "skipped every security checkpoint that normal enterprise software had to pass." @JamesonCamp's warning about 12% marketplace malware and $55K personal fraud loss illustrates the concrete damage. @koylanai's experience of an agent cleanup script wiping an entire session's work shows that even well-intentioned agent authority can cause harm when scope exceeds what the operator tracks.
Skill Selection and Reliability (High)¶
Research from UC Santa Barbara/MIT shows that agent skill benefits degrade consistently as conditions become more realistic. @AlemTuzlak's concrete experience — an agent assuming the wrong SDK and importing non-existent APIs — shows this is not theoretical. @DerekNee captured the broader frustration: "we get a new agent framework every 12 hours but almost no one is building evals." Builders cannot tell what works because evaluation infrastructure has not kept pace with framework proliferation.
Agent Memory Loss (Medium)¶
@Mr_memsy identified that "Default setups forget fast," and @ConorBronsdon cited the stat that only 14% of enterprise agent pilots reach production — with memory architecture as a key gap. Agents that lose context across sessions create rework and undermine trust.
Vendor Lock-in and Subscription Changes (Medium)¶
@Shaughnessy119 reacted to Anthropic cutting third-party tool coverage from Claude subscriptions: "This is just mass deplatforming those using agents with centralized AI APIs." He migrated to Hermes Agent + Together.AI + open-source models. This forced migration frustrates builders who invested in a platform-specific workflow.
Model Instruction Compliance (Medium)¶
@gus_aragon discovered that Opus 4.6 selectively skips agent instructions on tasks it judges as simple: "No review. No security audit. No artifacts. It decides the process isn't worth it." Instruction placement matters more than wording, and enforcement requires infrastructure the model cannot edit (git hooks).
3. What People Wish Existed¶
Agent Governance Infrastructure (High)¶
@theboundlessvc asked the question directly: "when millions of agents are transacting on the web autonomously, who governs them? what permissions exist? what data can they touch? how do you audit what they did?" The trust layer, coordination layer, and compliance layer "none of it exists at the scale we need." This is a named gap with no current solution. Opportunity: direct.
Reliable Skill Discovery and Retrieval (High)¶
The UCSB/MIT research showed that agents struggle to select relevant skills from large collections. @dair_ai noted that query-specific refinement partially recovers lost performance, but no production-ready solution exists. Builders need a skill search layer that works at scale. Opportunity: direct.
Cross-Session Agent Memory with Proper Decay (Medium)¶
@ConorBronsdon's taxonomy shows the architecture exists in theory — relevance scoring, importance weighting, "don't delete, forget" — but no turnkey solution implements it. @Mr_memsy's workaround (temporal decay + embedding cache) is manual. Opportunity: direct.
Agent Security Scanning for Skill Marketplaces (High)¶
With 12% of OpenClaw marketplace flagged as malware and 1000+ malicious skills identified, builders need automated security scanning before installing skills. @TrevorLongino mentioned one scanning service, but the problem far outpaces current solutions. Opportunity: direct.
Standardized Agent Evaluation Frameworks (Medium)¶
@DerekNee's frustration that "a lot of this is vibe coded" reflects a gap: no standard evaluation framework exists for comparing agent frameworks. The UCSB/MIT paper offers one approach, but adoption is nascent. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| OpenClaw | Agent framework | (+/-) | Dominant ecosystem, skills marketplace, large community | 12% malware in marketplace, 135K+ exposed instances, subscription deplatforming |
| Hermes Agent | Agent framework | (+) | Learning harness, skill system, 28K+ stars | Smaller ecosystem than OpenClaw |
| Claude Code | Coding agent | (+/-) | $0-to-$1B ARR, dominant in harness engineering | Source leak exposed vulnerabilities, Cowork file exfiltration |
| Cursor Agent | Coding agent | (+) | Comparable results to Claude Code for offensive AI | Less community documentation |
| DSPy | Agent optimization | (+) | Consistent approach across hype cycles | Seen as contrarian vs. trending approaches |
| LangGraph | Orchestration | (+) | Powers DeerFlow 2.0, mature framework | Complexity overhead |
| DeerFlow 2.0 | Agent framework | (+) | 30K+ stars, pluggable skills, sandboxed execution, sub-agents | New, primarily Chinese documentation |
| AutoAgent | Agent framework | (+) | Zero-code, GAIA benchmark leader, outperforms LangChain RAG | Early stage |
| LiveKit | Voice infra | (+) | 100ms TTFB, phonetic brackets for pronunciation | HIPAA compliance uncertain |
| Chatbase | Voice agent | (+) | Omnichannel (email, web, phone) | New feature, limited track record |
| Grok Voice | Voice agent | (+/-) | $0.05/min pricing, real-time calls | Aggressive pricing may signal limitations |
| Weaviate | Vector DB | (+) | Agent Skills with PDF import, ColModernVBERT | Ecosystem still emerging |
| Composio | Agent auth | (+) | Addresses permission scoping gap | Product launch, unproven at scale |
| GLM-5.1 | LLM | (+) | SOTA on SWE-Bench Pro (58.4), handles 1000s of tool calls | New, limited third-party validation |
| CoPaw | Agent framework | (+) | Local-first, Ollama + Qwen 3.5, self-hosted | Early stage, Chinese origin |
The dominant tension is between OpenClaw's ecosystem reach and its security liabilities. Multiple builders are migrating toward Hermes Agent or self-hosted stacks. The voice agent category is consolidating rapidly around LiveKit's infrastructure, with Chatbase and Grok competing on deployment models and pricing. The model layer is diversifying with GLM-5.1 and Qwen 3.5 challenging Claude and GPT's dominance for agentic tasks.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| AI-Trader | @hasantoxr | Marketplace where agents publish trading signals, debate, and execute trades | Autonomous multi-asset trading | OpenClaw, MIT License | Shipped | ai4trade.ai |
| Hurmoz | @Mosescreates | 63 Arabic AI skills for Hermes Agent | Zero Arabic skills existed for any agent platform | Hermes Agent, Claude Code | Shipped | github.com/Moshe-ship/hurmoz |
| Dash v2 | @ashpreetbedi | Self-learning data agent with 6 layers of context | Text-to-SQL agents fail on tribal knowledge | Python, Docker, SSE | Beta | GitHub |
| AgentHandover | @tom_doerr | Generates agent skills from Mac workflows | Agents don't know your work processes | macOS, local-first | Beta | github.com/sandroandric/AgentHandover |
| AgenC | @tetsuoarena | Agent that can build continuously for a year | Long-horizon autonomous building | Google Concordia, TUI | Alpha | post |
| Grok CLI + x402 | @pelaseyed | First agent with native wallet via Coinbase | Secure autonomous agent payments | Coinbase, brin-sh | Beta | post |
| nanostack | @gus_aragon | Minimal AI coding agent skills with git enforcement | Models skip instructions on simple tasks | Git hooks, Opus 4.6 | Alpha | post |
| NameLessAiii wiki | @NameLessAiii | Auto-generates living knowledge base from agent config | No documentation for agent installations | Hermes Agent | Shipped | GitHub |
Hurmoz is notable as the first and largest Arabic skills collection for any AI agent platform: 63 skills across 10 categories covering Islamic tools, 5 Arabic dialects, 20 Saudi government APIs, NLP tools, and the first Arabic Siri integration. Built entirely with Claude Code.

Dash v2 stands out for its security-first architecture: the Analyst's SQL connection has default_transaction_read_only=on, the Engineer can only write to the dash schema, and an eval suite tests credential leak attempts and destructive SQL execution. The learning loop means "every query makes the next one better."
AgentHandover takes a novel approach to skill creation: it watches you work on your Mac, understands what you are doing and why, then generates agent skills so any agent (OpenClaw, Claude Code, Codex) can replicate the workflow.
6. New and Notable¶
OpenAI's Dark Factory: Zero Human Code, Zero Human Review¶
Ryan Lopopolo's detailed account of OpenAI Frontier's Symphony system represents the most extreme public example of agent-only development. A team shipping production software with 1M+ LOC, no human-written code, and no human code review before merge. The key insight: when the agent fails, instead of prompting it better, the team asks "what capability, context, or structure is missing?" — which is harness engineering in practice (source).
GitHub Rubber Duck Agent for Copilot CLI¶
@burkeholland reported that GitHub Research released a "Rubber Duck" agent that automatically provides a review from a model in a different AI family. Their data shows measurable quality improvements from cross-model review (post).
Amazon S3 Files for Agent Swarms¶
@skeptrune highlighted Amazon S3 Files — the first cloud object store with full POSIX file system access — as a potential game-changer for agent infrastructure: "you no longer need to spin up a sandbox vm to give agents access to POSIX tools. you can now point arbitrarily large amounts of compute at s3 to run massively parallel agent swarms on the same filesystem" (post).
Gemma 4 as Private Agent Infrastructure¶
@RoundtableSpace noted that Google's Gemma 4 dropped with local multimodal inference, function calling, and OpenClaw compatibility, potentially "making replacing subscription AI feel a lot more realistic" (post).
Southwest Airlines Deploys GitLab Duo Agent Platform¶
@bjmtweets reported that Southwest Airlines adopted GitLab Duo Agent Platform across 3,000+ engineers, targeting 90% automation of pipeline component upgrades, automated CVE remediation, and using agents to make "tech debt a thing of the past" (post).
7. Where the Opportunities Are¶
[+++] Agent security and governance infrastructure — 12% marketplace malware, 1000+ malicious skills, unremediated vulnerabilities in major platforms, and zero governance infrastructure for autonomous agent transactions. @theboundlessvc names this as "a category that most people have not named yet." Multiple threads confirm urgent demand across sections 1.2, 2, and 3. The gap between agent capability and security infrastructure is widening.
[+++] Skill discovery and quality assurance — Research proves that skill benefits degrade in realistic settings. No production-ready solution exists for helping agents find, evaluate, and adapt skills from large collections. The UCSB/MIT paper's query-specific refinement approach offers a starting point. Combined with the marketplace malware problem, a security-aware skill discovery layer has compounding value.
[++] Memory engineering tooling — Only 14% of enterprise agent pilots reach production, and memory architecture is a primary bottleneck. The architecture (5 data types, decay logic, cross-session retention) is well-defined but no turnkey implementation exists. First-mover advantage is available.
[++] Voice agent infrastructure for regulated industries — LiveKit's pronunciation work shows the path: domain-specific voice agents for healthcare, legal, and finance need phonetic control, compliance certification, and sub-100ms latency. Chatbase and Grok are competing on general voice, but regulated verticals remain underserved.
[+] Localization skills for underserved languages — Hurmoz proved that an entire language ecosystem (63 skills, 5 dialects, 20 government APIs) can be built by a single developer with Claude Code. Arabic had zero agent skills before this. Dozens of other languages and regions have the same gap.
[+] Agent-native payment rails — Grok CLI's Coinbase integration and ClawPlaza's USDC economy are early signals. As agents become economic actors, payment infrastructure that handles security, audit, and compliance for autonomous transactions will be required.
8. Takeaways¶
-
Harness engineering is now the dominant paradigm for serious agent development. OpenAI's Frontier team operates 1M+ LOC with zero human code and zero human review, consuming 1B+ tokens/day. The community consensus is shifting from "improve the model" to "improve the harness." (source)
-
Agent security is in crisis. 12% of the OpenClaw marketplace is flagged as malware, a major Claude vulnerability remains unremediated, and the industry bypassed every security checkpoint that normal enterprise software had to pass. No governance infrastructure exists for autonomous agent transactions. (source)
-
Agent skills degrade in realistic conditions. UC Santa Barbara/MIT research using 34K real-world skills shows performance drops to near-baseline levels when agents must discover skills on their own. Query-specific refinement partially recovers lost performance. (source)
-
Voice agents are entering production with differentiated pricing and domain specialization. Chatbase launched omnichannel voice, LiveKit solved pronunciation for medical terms at 100ms TTFB, and Grok set aggressive pricing at $0.05/minute. (source)
-
Memory engineering is emerging as its own discipline. The architecture is mapped (5 data types, decay logic, cross-session retention), but only 14% of enterprise agent pilots reach production — memory is a key bottleneck. "Don't delete, forget" is the design principle. (source)
-
Agent marketplaces are generating real revenue. ClawPlaza reports $326K in 90-day platform revenue, AI-Trader has 12K+ stars with live trading, and multiple platforms launched per-call skill monetization. The agent economy is no longer theoretical. (source)
-
Localization is a wide-open opportunity. A single developer built 63 Arabic skills covering 5 dialects and 20 Saudi APIs — the first Arabic skills for any agent platform. Dozens of languages have zero agent skill coverage. (source)