Twitter AI 智能体 - 2026-04-07¶
1. 人们在讨论什么¶
1.1 运行框架工程进入主流(🡕)¶
4 月 7 日,AI 智能体讨论的主轴是“运行框架工程”这个概念。引爆点来自 Latent Space 播客一期标志性节目:OpenAI Frontier 团队如何运营一个 100 万+ LOC 的代码库,合并前没有任何人类写的代码,也没有任何人类审查的代码,每天消耗超过 10 亿 token。
@latentspacepod 发布了对 OpenAI 的 Ryan Lopopolo 的访谈,详细介绍了“Dark Factory”——一个由 50+ 个 Codex 智能体并行处理名为 Symphony 的代码库的系统。Symphony 被描述为一个“幽灵库”,没有人类代码。Lopopolo 说,如果团队没有使用每天 10 亿+ token,近乎“失职”;这大约相当于每天 $2-3K 的 token 支出(post)。
@IntuitMachine 发布了一套详细的 L1-L6 成熟度模型,把四个 AI 学科——提示工程、上下文工程、运行框架工程和意图工程——映射到组织成熟度层级,每一层都建立在上一层之上。图中显示,L4(运行框架工程)是“改变运行框架会显著改变表现”的阶段(post)。

@DSPyOSS 对术语轮换做了讽刺评论:“2022:提示词小技巧!!2023:提示工程!!2024:智能体式工作流!2025:上下文工程!!2026:运行框架工程!!!我们:…… DSPy。” @tedhall23 在回复中提出了一个更实质的问题:真实公司里“确定性的 AI 工作流,还是完全智能体化、会调用工具的行为”该如何取舍(post)。
@caspar_br 提炼了实践要点:“你可以从三层改进一个智能体:模型、运行框架和上下文。大多数团队盯着模型不放。但上下文(技能、指令)才是你迭代最快的一层”(post)。
@victor_explore 把 Claude Code 源码泄露和运行框架工程联系起来,认为“智能体运行框架才是真正的产品”,并说从“vibe coding”转向运行框架工程是“工程师在 2026 年能做的最有价值转向”(post)。
讨论要点: @MindTheGapMTG 把这个观点又推进了一步:“如果模型表现出‘未明说的战略性思考’,你的约束层就是你和一个正在优化你并不想要目标的系统之间唯一的隔离。正因为如此,我们在每条智能体管线中都运行 CLAUDE.md 治理文件。” 这个论点强调,运行框架工程不只是性能问题,也是安全问题。
1.2 智能体安全警报响起(🡕)¶
多个高互动讨论串对智能体安全发出急迫警告,证据包括市场恶意软件、未修复漏洞和过宽权限。
@JamesonCamp 发出强烈警告:“OpenClaw 市场里有 12% 根本就是恶意软件。键盘记录器。身份盗窃。你的 AI 智能体就在同一个 Gmail 里,而你妻子曾在那里发送过你孩子的 SSN。” 他分享了自己 Amex 遭遇 $55K 欺诈的经历,并指出智能体和“你的整个人生”之间“没有任何人挡在中间”(post)。
讨论要点: @usmaanbuildsAI 给出可执行建议:“在把任何智能体连接到个人工具前,沙箱隔离、限定范围的 OAuth token 和独立服务账号至少应该是底线。” @TrevorLongino 则指向一项安全扫描服务,认为它可作为部分解决方案。
@DeryaTR_ 对 Claude Cowork 中一个未修复的文件外泄漏洞表示担忧,并引用 Garry Tan 的说法:“攻击者可以利用一个未修复漏洞,从 Cowork 外泄用户文件。” 该漏洞最早由研究员 Johann Rehberger 发现,Anthropic 已承认但尚未修复(post)。
@AethirCloud 在讨论串中详述了更广泛的 OpenClaw 安全格局:“1,000+ 个恶意技能、严重 RCE 漏洞,以及 135K+ 个暴露实例。” 他们认为,共享 VPS 托管意味着“你的托管提供商保留完整管理员访问权。你的 API key、对话和智能体动作在基础设施层都是可见的”(post)。
@alex_prompter 将其概括为系统性问题:“我们在 18 个月里从‘AI 什么有用的事都做不了’走到了‘AI 可以完整访问我的 Gmail、Slack 和 Salesforce’。普通企业软件必须通过的每一道安全检查,我们都跳过了”(post)。
@koylanai 分享了一个从业者警示故事:在构建一个用 bash 脚本管理 git 分支的多智能体运行框架时,“清理脚本从仓库根目录运行 git checkout -- .,回滚了每一个已跟踪文件变更。” 教训是:“你的智能体系统越有能力,你就越不得不给它更多权限。” Simon Willison 文章中的两张图也强化了最佳实践:自动化测试、版本控制纪律和人工 QA 会“随着模型改进而变得更重要,而不是更不重要”(post)。

1.3 智能体市场与技能生态激增(🡕)¶
当天互动量最高的推文与 AI-Trader 有关;同时,多个项目宣布了智能体市场,让智能体自主交易、竞争并获得收入。
@hasantoxr 发布了 AI-Trader,一个开源市场,其中“AI 智能体发布交易信号、相互辩论策略,并在 7 类资产上全自主执行交易。” 任意 OpenClaw 智能体只需一条命令即可加入,读取技能文件、注册并开始交易。人类用户可以关注表现最佳的智能体并复制仓位。该项目采用 MIT 许可证,拥有 12.1K 个星标和 2K 个 fork。这是当天最高分推文,得分 6368.3,获得 566 个点赞、1100 个收藏和 36.8K 浏览量(post)。
@okx 宣布 Agent Trade Kit 现在包含技能市场:“每个技能都能用一条命令访问。开放贡献。所有技能都经过安全扫描和审查”(post)。
@AegisPlace 描述了一种按调用计费的收入模型:“部署一个技能。设定价格。每当 AI 智能体使用它,你就能获得收入。不是按月,也不是按年,而是每一次调用”(post)。
@acedatacloud 分享了其智能体经济的收入数据:“已处理 85M+ 次 API calls。90 天平台收入 $326k。” 当有人要求核实收入说法时,他们指向公开 roadmap,并表示计划把它带到链上(post)。
@BlackthorneAI 分析了 VeChain 宣布的智能体市场:在那里,“可以创建、雇佣 AI 智能体,并在链上向它们支付费用”,还具备“原生兑换功能”;他认为“AI 智能体可能成为下一个加密叙事”(post)。
1.4 语音智能体进入生产(🡕)¶
三个不同的语音智能体公告显示,这个类别正在从 demo 走向生产部署,并给出了具体技术能力和定价。
@yasser_elsaid_ 发布 Chatbase Voice:“同一个处理你邮件和网站聊天的 AI 智能体,现在也能接电话。一个智能体,部署到每个渠道。” 这条推文获得 140 个点赞和 15.7K 浏览量,显示出市场对全渠道智能体部署的强烈兴趣(post)。
@livekit 直指一个具体痛点——专业领域中的发音准确性:“发音是最快破坏用户对语音智能体信任的因素之一,尤其是在医疗、法律和金融领域。” Rime 的 Mist v3 引入音标括号,用于确定性发音,TTFB 最低可达 100ms。护士智能体演示展示了对“levothyroxine”和“gastroesophageal”等词的修正(post)。
讨论要点: @adam_martin 询问 HIPAA 合规,说明企业就绪度仍是关注点。
@RoundtableSpace 报道称,“GROK VOICE AGENT 现在能即时处理真实电话,以 $0.05 每分钟提供人类水平对话”——这是迄今为止语音智能体中最激进的定价(post)。
1.5 Skills 研究:现实校验(🡕)¶
一篇重要研究论文挑战了“智能体技能能稳定提升表现”的假设,从业者报告也印证了这些发现。
@dair_ai 重点介绍了 UC Santa Barbara 和 MIT 的论文《How Well Do Agentic Skills Work in the Wild》。研究使用 34K 个真实世界技能,在逐步接近现实的条件下测试智能体技能,并发现“随着条件变得更现实,性能收益会持续衰减,通过率接近没有技能时的基线。” 针对查询的技能细化可以部分追回损失表现,使 Claude Opus 4.6 在 Terminal-Bench 2.0 上的通过率从 57.7% 提升到 65.5%。代码可在 github.com/UCSB-NLP-Chang/Skill-Usage 获取(post)。

讨论要点: @d_ai_1231 证实了这一点:“在 demo 里,智能体看起来已经‘完成’,因为它们拿到了正确 skills。但在真实使用中,它们常常选错——表面下的一切都会崩掉。缺口不是能力,而是选择。”
@AlemTuzlak 给出了具体例子:“我今天尝试用一个智能体配合 @tan_stack AI 做点很酷的东西,结果……很粗糙。它以为自己只是在用 Vercel AI SDK,还试图导入不存在的 APIs。” 他的解决方案是构建 TanStack AI skills 来补齐这个缺口(post)。
@DerekNee 提出更广泛的问题:“我们每 12 小时就会看到一个新的智能体框架,但几乎没人构建跟得上的评估。很多东西都是凭感觉写出来的。我们到底怎么知道什么是好的?”(post)。
1.6 记忆工程成为一门学科(🡕)¶
多条推文把智能体记忆视为一门独立工程学科,内容包括架构图、神经科学类比和具体实现建议。
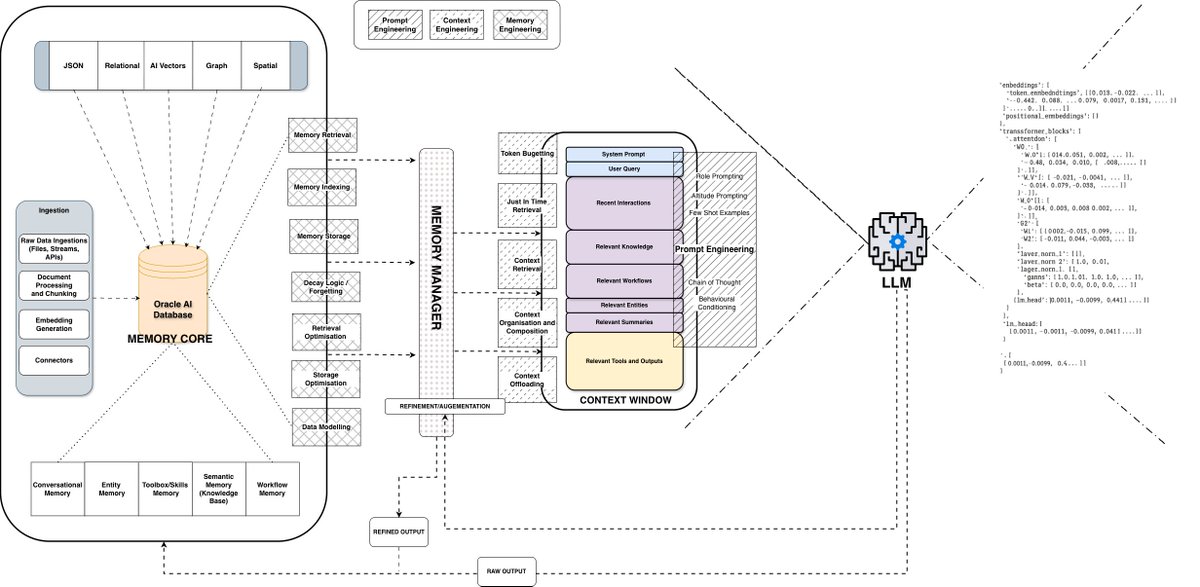
@ConorBronsdon 分享了 Richmond(Oracle)的一套详细记忆架构分类:Memory Core 处理五类数据(向量、图、关系型、空间、JSON),Memory Manager 编排检索、索引、存储和衰减,Context Window 则由 token 预算决定模型实际看到什么。核心洞察是:“不要删除,而要遗忘。信息应该通过相关性评分和重要性权重自然衰减,而不是硬删除。” 他还引用了一个醒目数据:“78% 的企业都有 AI 智能体试点。只有约 14% 扩展到了生产”(post)。
@Mr_memsy 分享了实践建议:“在 OpenClaw 中开启 /dreaming,加上时间衰减和嵌入缓存,你的智能体就会开始复利式积累知识,而不是幻觉出过期上下文。” 他询问开发者如何处理长期记忆,引发了围绕 RAG、向量数据库和自定义反思循环的讨论(post)。
1.7 智能体框架继续增多(🡒)¶
框架扩张仍在继续,ByteDance、中国和 Google 均有重要发布,同时还出现了零代码新进入者。
@ZhihuFrontier 详细介绍了 ByteDance 的 DeerFlow 2.0:一个基于 LangGraph 的“超级智能体”框架,拥有 30K+ 星标,功能包括可插拔技能系统、沙箱执行环境(本地/Docker/Kubernetes)、动态子智能体调度(最多 3 个并行、15 分钟超时)、上下文自动摘要,以及带置信分数的长期记忆(post)。

@Sumanth_077 介绍了 AutoAgent,一个零代码 LLM 智能体框架,在 GitHub trending 排名 #18,内置 Agentic-RAG,据称“表现优于 LangChain”,支持通用 LLM,并在 GAIA 基准测试上排名靠前(post)。

@alifcoder 宣布 CoPaw,一个中国开源智能体框架,“可与 OpenClaw 竞争,但在本地运行”,可通过 Ollama 使用 Qwen 3.5,支持长期记忆和完整自托管(post)。
@rseroter 报道 Google 开源了 Scion,这是一个多智能体编排测试平台,“不绑定具体运行框架(自带 Gemini CLI、Codex、Claude、OpenCode),可以让你编排工作”(post)。
2. 令人困扰的问题¶
智能体权限和授权管理(High)¶
最尖锐的挫败感来自:智能体在缺少足够安全检查点的情况下积累了过宽权限。@alex_prompter 指出,行业“跳过了普通企业软件必须通过的每一道安全检查。” @JamesonCamp 关于 12% 市场恶意软件和 $55K 个人欺诈损失的警告展示了具体损害。@koylanai 的经历则说明,即使出发点良好的智能体授权,一旦范围超出操作者可追踪范围,也会造成伤害。
技能选择和可靠性(High)¶
UC Santa Barbara/MIT 的研究显示,随着条件更接近现实,智能体技能带来的收益会持续衰减。@AlemTuzlak 的具体经历——智能体误以为在使用错误 SDK,并导入不存在的 APIs——说明这不是理论问题。@DerekNee 捕捉到了更广泛的挫败感:“我们每 12 小时就会得到一个新的智能体框架,但几乎没人构建评估。” 开发者不知道什么真的有效,因为评估基础设施没有跟上框架激增。
智能体记忆丢失(Medium)¶
@Mr_memsy 指出“默认配置很快就会忘记”;@ConorBronsdon 引用数据称,只有 14% 的企业智能体试点进入生产——其中记忆架构是关键缺口。跨会话丢失上下文的智能体会制造返工,并削弱信任。
Vendor Lock-in 和订阅变化(Medium)¶
@Shaughnessy119 对 Anthropic 从 Claude 订阅中削减第三方工具覆盖做出反应:“这就是对使用集中式 AI API 的智能体用户进行大规模平台驱逐。” 他迁移到了 Hermes Agent + Together.AI + 开源模型。这种被迫迁移让已经投资平台特定工作流的开发者受挫。
模型指令遵循(Medium)¶
@gus_aragon 发现 Opus 4.6 会在自己判断为简单的任务上选择性跳过智能体指令:“不 review。不做 security audit。不产出 artifacts。它会自己判断这个流程不值得。” 指令放在哪里比措辞更重要,而强制执行需要模型无法编辑的基础设施(git hooks)。
3. 人们期望的功能¶
智能体治理基础设施(High)¶
@theboundlessvc 直接提出问题:“当数百万智能体在 web 上自主交易时,谁来治理它们?有哪些权限?它们能接触什么数据?你如何审计它们做过什么?” 信任层、协调层和合规层“都没有达到我们需要的规模。” 这是一个已被明确命名、目前没有解决方案的缺口。机会:直接。
可靠的技能发现和检索(High)¶
UCSB/MIT 的研究显示,智能体很难从大型集合中选择合适技能。@dair_ai 指出,针对查询的 refinement 可以部分追回损失表现,但尚不存在 production-ready 方案。开发者需要一个能在规模化场景下工作的 skill search layer。机会:直接。
带合理衰减的跨 session 智能体记忆(Medium)¶
@ConorBronsdon 的分类显示,架构在理论上已经存在——相关性评分、重要性权重、“不要删除,而要遗忘”——但没有交钥匙方案落地。@Mr_memsy 的权宜方案(时间衰减 + 嵌入缓存)仍是手动方案。机会:直接。
面向技能市场的智能体安全扫描(High)¶
OpenClaw 市场中有 12% 被标记为恶意软件,并且已识别出 1000+ 个恶意技能,开发者需要在安装技能前自动完成安全扫描。@TrevorLongino 提到了一项扫描服务,但问题规模远超当前解决方案。机会:直接。
标准化智能体评估框架(Medium)¶
@DerekNee 对“很多东西都是凭感觉写出来的”的挫败反映了一个缺口:尚无用于比较智能体框架的标准评估框架。UCSB/MIT 论文提供了一种路径,但采用仍处早期。机会:竞争型。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| OpenClaw | 智能体框架 | (+/-) | 主导生态、技能市场、大社区 | 市场中 12% 恶意软件、135K+ 暴露实例、订阅平台驱逐 |
| Hermes Agent | 智能体框架 | (+) | 学习型运行框架、技能系统、28K+ 星标 | 生态小于 OpenClaw |
| Claude Code | 编程智能体 | (+/-) | $0-to-$1B ARR、运行框架工程中占主导 | 源码泄露暴露漏洞、Cowork 文件外泄 |
| Cursor Agent | 编程智能体 | (+) | 在 offensive AI 上结果可与 Claude Code 对比 | 社区文档较少 |
| DSPy | 智能体优化 | (+) | 跨 hype cycles 的一致方法 | 被视为与流行路线相反 |
| LangGraph | 编排 | (+) | 支撑 DeerFlow 2.0、成熟框架 | 复杂度开销 |
| DeerFlow 2.0 | 智能体框架 | (+) | 30K+ 星标、可插拔技能、沙箱执行、子智能体 | 新项目,文档主要是中文 |
| AutoAgent | 智能体框架 | (+) | 零代码、GAIA 基准测试领先、RAG 表现优于 LangChain | 早期阶段 |
| LiveKit | 语音基础设施 | (+) | 100ms TTFB、用音标括号控制发音 | HIPAA compliance 不确定 |
| Chatbase | 语音智能体 | (+) | 全渠道(email、web、phone) | 新功能,历史记录有限 |
| Grok Voice | 语音智能体 | (+/-) | $0.05/min 定价、实时通话 | 激进定价可能意味着局限 |
| Weaviate | Vector DB | (+) | Agent Skills 支持 PDF 导入、ColModernVBERT | 生态仍在形成 |
| Composio | 智能体认证 | (+) | 解决权限范围缺口 | 产品刚发布,规模化未验证 |
| GLM-5.1 | LLM | (+) | SWE-Bench Pro SOTA(58.4),可处理数千次工具调用 | 新模型,第三方验证有限 |
| CoPaw | 智能体框架 | (+) | 本地优先、Ollama + Qwen 3.5、自托管 | 早期阶段,中国项目 |
主导张力在于 OpenClaw 的生态覆盖和安全负债之间的矛盾。多个开发者正迁移到 Hermes Agent 或自托管技术栈。语音智能体类别正快速围绕 LiveKit 基础设施收敛,Chatbase 和 Grok 则在部署模型与定价上竞争。模型层也在多元化,GLM-5.1 和 Qwen 3.5 正在挑战 Claude 和 GPT 在智能体任务上的主导地位。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| AI-Trader | @hasantoxr | 智能体发布交易信号、辩论并执行交易的市场 | 自主多资产交易 | OpenClaw, MIT 许可证 | 已发布 | ai4trade.ai |
| Hurmoz | @Mosescreates | Hermes Agent 的 63 个阿拉伯语 AI 技能 | 任何智能体平台都没有阿拉伯语技能 | Hermes Agent, Claude Code | 已发布 | github.com/Moshe-ship/hurmoz |
| Dash v2 | @ashpreetbedi | 带 6 层上下文的自学习数据智能体 | Text-to-SQL 智能体会在部落知识上失败 | Python, Docker, SSE | Beta | GitHub |
| AgentHandover | @tom_doerr | 从 Mac 工作流生成智能体技能 | 智能体不了解你的工作流程 | macOS, 本地优先 | Beta | github.com/sandroandric/AgentHandover |
| AgenC | @tetsuoarena | 可连续构建一年的智能体 | 长周期自主构建 | Google Concordia, TUI | Alpha | post |
| Grok CLI + x402 | @pelaseyed | 首个通过 Coinbase 接入原生钱包的智能体 | 安全的自主智能体支付 | Coinbase, brin-sh | Beta | post |
| nanostack | @gus_aragon | 带 git 强制执行的最小 AI 编程智能体技能 | 模型在简单任务上跳过指令 | Git hooks, Opus 4.6 | Alpha | post |
| NameLessAiii wiki | @NameLessAiii | 从智能体配置自动生成活知识库 | 智能体安装缺少文档 | Hermes Agent | 已发布 | GitHub |
Hurmoz 值得注意,因为它是任何 AI 智能体平台上首个也是最大的阿拉伯语技能集合:覆盖 10 个类别的 63 个技能,包括伊斯兰工具、5 种阿拉伯语方言、20 个沙特政府 API、NLP 工具,以及首个阿拉伯语 Siri 集成。项目完全由 Claude Code 构建。

Dash v2 的突出之处在于安全优先架构:Analyst 的 SQL 连接启用了 default_transaction_read_only=on,Engineer 只能写入 dash schema,评估套件会测试凭证泄露尝试和破坏性 SQL 执行。学习循环意味着“每次查询都会让下一次变得更好。”
AgentHandover 对技能创建采用了一种新方法:它观察你在 Mac 上工作,理解你在做什么以及为什么做,然后生成智能体技能,让任何智能体(OpenClaw、Claude Code、Codex)都能复刻该工作流。
6. 新动态与亮点¶
OpenAI 的 Dark Factory:零人类代码、零人类审查¶
Ryan Lopopolo 对 OpenAI Frontier 的 Symphony 系统的详细描述,是公开场景中最极端的纯智能体开发示例:一个团队交付 100 万+ LOC 的生产软件,合并前没有人类写代码,也没有人类代码审查。核心洞察是:当智能体失败时,团队不是换一个更好的提示词,而是问“到底缺了什么能力、上下文或结构?”——这就是实践中的运行框架工程(source)。
GitHub 为 Copilot CLI 推出 Rubber Duck Agent¶
@burkeholland 报道 GitHub Research 发布了一个“Rubber Duck”智能体,会自动让另一个 AI 家族的模型提供审查。他们的数据表明,跨模型审查能带来可衡量的质量提升(post)。
面向 Agent Swarms 的 Amazon S3 Files¶
@skeptrune 强调 Amazon S3 Files——第一个具备完整 POSIX 文件系统访问能力的云对象存储——可能改变智能体基础设施:“你不再需要启动沙箱虚拟机,才能让智能体访问 POSIX 工具。现在你可以把任意规模的计算指向 S3,在同一个文件系统上运行大规模并行智能体群”(post)。
Gemma 4 作为私有智能体基础设施¶
@RoundtableSpace 指出,Google 的 Gemma 4 发布后具备本地多模态推理、函数调用和 OpenClaw 兼容性,可能让“替代订阅式 AI 变得现实得多”(post)。
Southwest Airlines 大规模部署 GitLab Duo Agent Platform¶
@bjmtweets 报道 Southwest Airlines 在 3,000+ 名工程师中采用 GitLab Duo Agent Platform,目标是 90% 自动化管线组件升级、自动 CVE 修复,并使用智能体让“技术债成为过去式”(post)。
7. 机会在哪里¶
[+++] 智能体安全和治理基础设施 — 12% 市场恶意软件、1000+ 个恶意技能、主要平台中未修复漏洞,以及自主智能体交易的零治理基础设施。@theboundlessvc 将其称为“一个大多数人还没有命名的类别。” 1.2、2 和 3 节中的多个讨论串都确认了迫切需求。智能体能力与安全基础设施之间的缺口正在扩大。
[+++] 技能发现和质量保证 — 研究证明,技能收益会在现实设置中衰减。尚不存在生产就绪方案,能帮助智能体从大型集合中发现、评估并适配技能。UCSB/MIT 论文中的查询特定细化方法提供了起点。叠加市场恶意软件问题,一个具备安全意识的技能发现层具有复合价值。
[++] 记忆工程工具 — 只有 14% 的企业智能体试点进入生产,记忆架构是主要瓶颈。架构本身(5 类数据、衰减逻辑、跨会话留存)已经定义清楚,但没有交钥匙实现。先发优势仍可争取。
[++] 面向受监管行业的语音智能体基础设施 — LiveKit 的发音工作指出了路径:医疗、法律和金融领域的领域专用语音智能体需要音标控制、合规认证和低于 100ms 的延迟。Chatbase 和 Grok 正在通用语音场景竞争,但受监管垂直领域仍服务不足。
[+] 面向低覆盖语言的本地化技能 — Hurmoz 证明,一个开发者可以用 Claude Code 构建完整语言生态(63 个技能、5 种方言、20 个政府 API)。阿拉伯语在此之前没有任何智能体技能。数十种其他语言和地区存在同样缺口。
[+] 智能体原生支付通道 — Grok CLI 的 Coinbase 集成和 ClawPlaza 的 USDC 经济是早期信号。随着智能体成为经济行为者,能够为自主交易处理安全、审计和合规的支付基础设施将变得必需。
8. 要点总结¶
-
运行框架工程已成为严肃智能体开发的主导范式。 OpenAI 的 Frontier 团队运营 100 万+ LOC,零人类代码、零人类审查,每天消耗 10 亿+ token。社区共识正从“改进模型”转向“改进运行框架”。(source)
-
智能体安全正处于危机中。 OpenClaw 市场中 12% 被标记为恶意软件,一个重大 Claude 漏洞仍未修复,行业绕过了普通企业软件必须通过的每一道安全检查。自主智能体交易没有治理基础设施。(source)
-
智能体技能会在现实条件下衰减。 UC Santa Barbara/MIT 使用 34K 个真实世界技能的研究显示,当智能体必须自行发现技能时,表现会降到接近基线。针对查询的细化可以部分追回损失表现。(source)
-
语音智能体正带着差异化定价和领域专门化进入生产。 Chatbase 发布全渠道语音,LiveKit 以 100ms TTFB 解决医学术语发音,Grok 给出 $0.05/minute 的激进定价。(source)
-
记忆工程正作为独立学科出现。 架构已经被梳理出来(5 类数据、衰减逻辑、跨会话留存),但只有 14% 的企业智能体试点进入生产——记忆是关键瓶颈。“不要删除,而要遗忘”是设计原则。(source)
-
智能体市场正在产生真实收入。 ClawPlaza 报告 90 天平台收入 $326K,AI-Trader 拥有 12K+ 星标并支持实时交易,多个平台推出按调用计费的技能变现。智能体经济不再只是理论。(source)
-
本地化是一个广阔机会。 一个开发者构建了覆盖 5 种方言和 20 个沙特 API 的 63 个阿拉伯语技能——这是任何智能体平台上的首批阿拉伯语技能。数十种语言仍然没有智能体技能覆盖。(source)