Twitter AI Agent - 2026-04-08¶
1. What People Are Talking About¶
1.1 Meta Launches Muse Spark with Native Multi-Agent Orchestration 🡕¶
Meta Superintelligence Labs released Muse Spark, a natively multimodal reasoning model with tool-use, visual chain of thought, and multi-agent orchestration. The announcement drew 152K+ views and dominated the day's conversation. @alexandr_wang (Scale AI CEO) provided technical analysis, noting that Muse Spark demonstrates "predictable scaling across pretraining, RL, and test-time reasoning" and introduces "thought compression" -- the ability to solve problems using significantly fewer tokens.
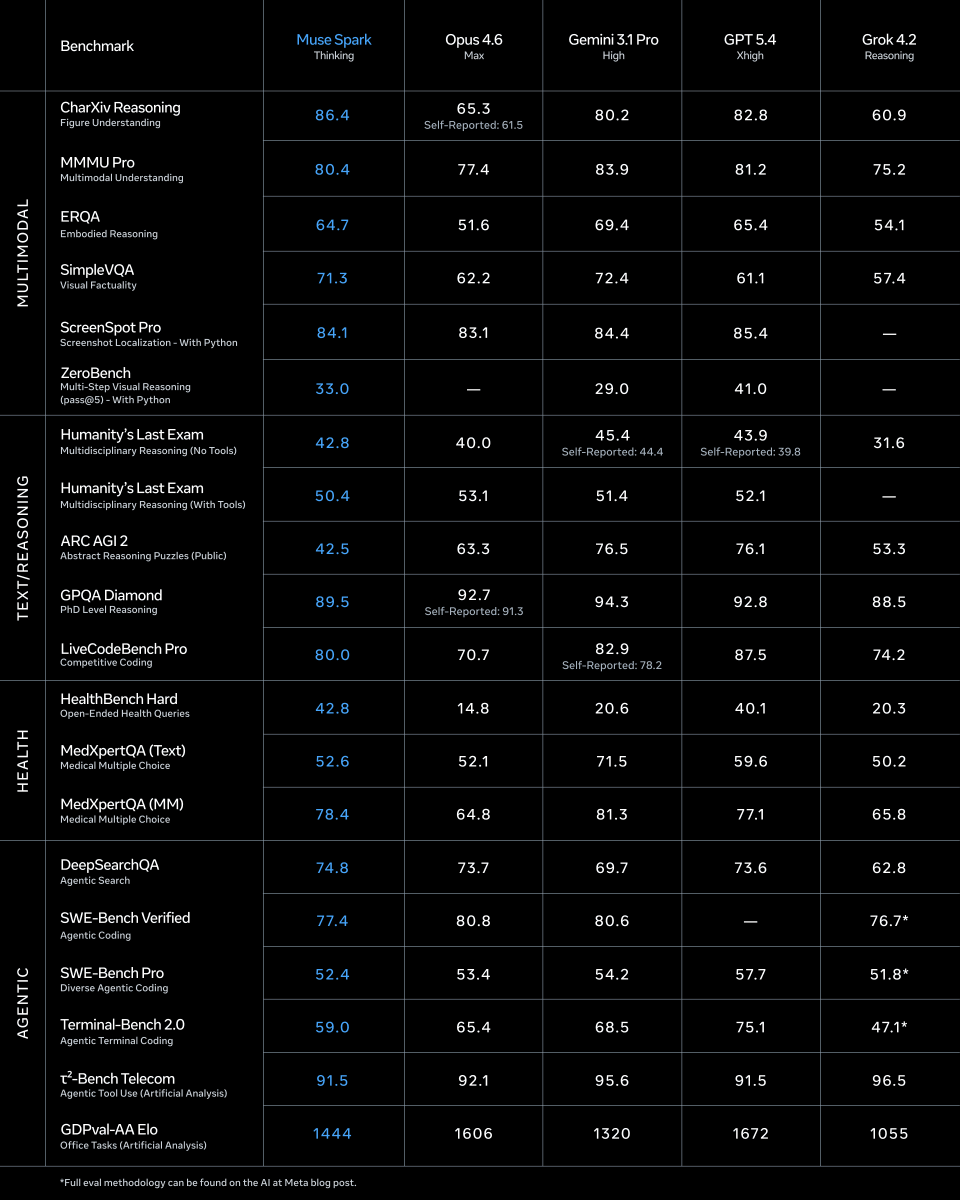
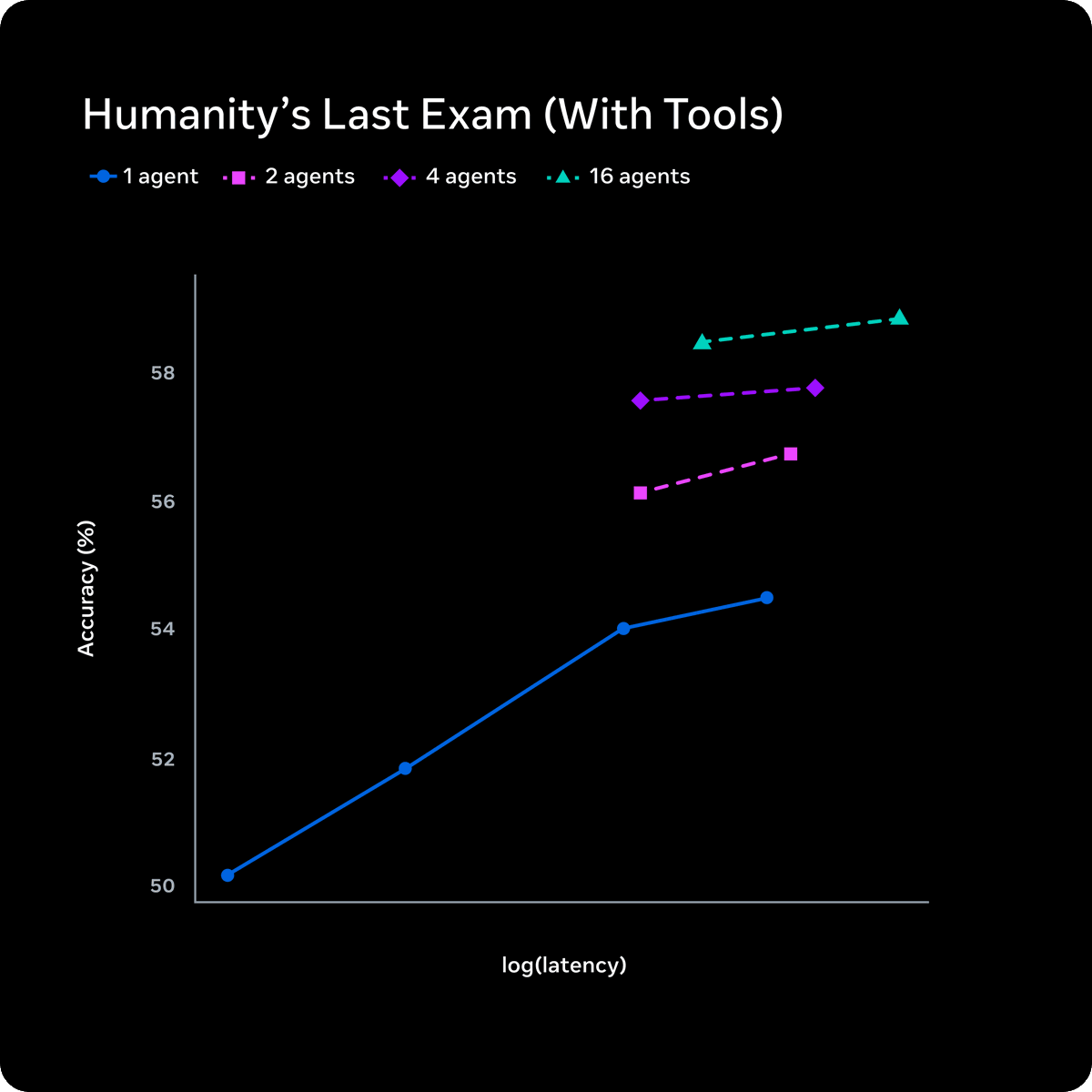
The benchmark table shared by @jhyuxm shows Muse Spark leading Opus 4.6 on CharXiv Reasoning (86.4 vs 65.3), ScreenSpot Pro (84.1 vs 83.1), and HealthBench Hard (42.8 vs 14.8), while trailing on ARC AGI 2 (42.5 vs 63.3) and GPQA Diamond (89.5 vs 92.7). The model's "Contemplating mode" orchestrates multiple agents reasoning in parallel, and @omarsar0 noted that agents are "parallelized without significantly increasing latency," sharing a chart showing 16 parallel agents reaching ~59% on Humanity's Last Exam versus ~55% for a single agent.
Skeptics emerged quickly. One reply noted Meta "spent $14 billion, poached Alexandr Wang, rebuilt the entire stack from scratch. First model lands at fourth place." @omarsar0 flagged "some gaps, especially to enable long-horizon agentic systems and coding workflows." Meta shares rebounded sharply on the news, observed by @TrendSpider.
1.2 Anthropic Ships Claude Managed Agents, Threatens Orchestration Startups 🡕¶
Anthropic launched Claude Managed Agents in public beta, and the reaction was immediate. @trq212 called it "the first 'agent in the cloud' API that has the right mix of simplicity and complexity", detailing environments with custom packages, credential vaults, file system memory, and GitHub integration. The tweet drew 921 likes and 402 bookmarks.
@aakashgupta declared Anthropic "just mass-obsoleted every agent orchestration startup", pointing to a production fleet dashboard showing 8 agents running with 247 completed tasks and MCP-connected HubSpot integrations. "Manus spent six months on five harness rewrites. LangChain spent a year on four architectures. Anthropic just shipped the managed version that eliminates the need to build one at all." @shiri_shh was blunter: "The entire AI agent startup sector just got cooked today."
The architectural debate intensified. @charlespacker shared Anthropic's engineering blog excerpt describing the "pet vs cattle" container problem -- when agent components share one container, "a bug in the harness, a packet drop in the event stream, or a container going offline all presented the same" failure mode. @alexgshaw asked: "Who is building the 'Agent Sandbox Protocol'?"

Notion announced Claude agents integration, positioning Notion as the orchestration layer while Anthropic runs the model and harness. Community members immediately asked whether other models would be supported.
1.3 The Skills Ecosystem Explodes (and Cracks Show) 🡕¶
Agent skills emerged as the dominant paradigm for extending agent capabilities. @gregisenberg posted a detailed breakdown (398 bookmarks) arguing that agent.md files are "mostly unnecessary" -- a 1000-line file burns 7000 tokens per run, while a skill loads only its name and description (~50 tokens) until activated. His framework: run the workflow by hand first, let the agent write the skill, then fix failures recursively together.
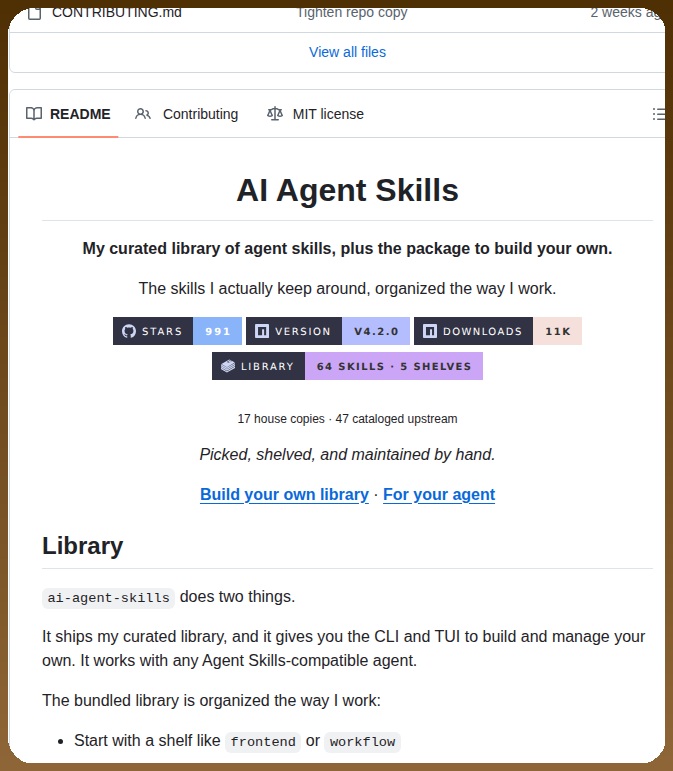
The tooling layer is maturing fast. @tom_doerr shared AI Agent Skills (991 stars, 64 skills, 11K downloads) and Skill Forge, a pipeline that audits and publishes skills to five platforms simultaneously. Skill Forge's README reveals a sobering stat: of 88K+ published skills in the ecosystem, community audits estimate ~26% have security vulnerabilities. @FOUNDATIONdvcs corroborated: "AI agent marketplace: 12% malware."

Multiple vendors announced skills support: MongoDB for Cursor, Coinbase Developer Platform with MCP server, Lazer CLI for onchain mini apps on Base and Farcaster, and Enter Pro shipping skills + cloud + MCP in one update.
1.4 Harness Engineering and Context Engineering Formalize 🡒¶
Two related disciplines are crystallizing under formal names. @latentspacepod published "Extreme Harness Engineering", covering OpenAI's Symphony -- a "ghost library" of Codex agents producing 1M lines of code with 1B tokens/day, "0% human code, 0% human review pre merge." The interview reveals how harness engineering evolved from GPT-5 to GPT-5.4 internally.
@IntuitMachine shared an L1-L6 maturity model mapping the progression from prompt engineering (L1) through context engineering (L2), harness engineering (L3-L4), to self-improving agents (L6), identifying "Quality/Vitality Engineering" as the unnamed industry gap at L6.

@helloiamleonie (Elastic) gave a workshop at AI Engineer Europe on "Agentic Search for Context Engineering." @DSPyOSS claimed to have anticipated every wave: "2024: agentic workflows! us: DSPy. 2025: context engineering! us: DSPy. 2026: harness engineering!! us: DSPy."

1.5 Agent Infrastructure: S3, Sandboxes, and the OS Question 🡕¶
@skeptrune argued that Amazon S3 Files is transformative for agents: "you no longer need to spin up a sandbox vm to give agents access to POSIX tools. you can now point arbitrarily large amounts of compute at s3 to run massively parallel agent swarms on the same filesystem." The tweet drew 632 bookmarks -- the day's highest bookmark rate. Discussion tempered expectations, noting you still need a sandbox to mount the filesystem.
@NathanFlurry described building open-source sandbox infrastructure: "any agent, any LLM, 22 MB of RAM per sandbox, BYOC/on-prem, any file system."
@HSVSphere offered a contrarian vision: "There is no special 'agent sandbox of the future,' the future is an operating system built on a dynamic language, with capabilities and (inherent) scoping for everything." Discussion drew parallels to Plan9 and Ruby, with TypeScript dismissed as "too static."
2. What Frustrates People¶
Agent Security and Trust (Severity: High)¶
The skills ecosystem is growing faster than security infrastructure can keep up. Skill Forge audits found ~26% of 88K+ published skills have security vulnerabilities. @JamesonCamp warned: "12% of OpenClaw's marketplace is literal malware. Keyloggers. Identity theft. Your AI agent is installing packages from strangers." @conor_ai highlighted information leakage: "agents can and will share sensitive info with anyone they're talking to," leading to a "Severance"-inspired "innie/outie" agent architecture at Hyperspell.
Platform Risk and Startup Anxiety (Severity: High)¶
Anthropic's Managed Agents launch triggered existential concern among orchestration startups. @SolSt1ne captured the mood: "spent 6 months building custom agent infra, orchestration, retry logic, rate limiting, 'finally production ready,' Anthropic ships Claude Managed Agents in public beta." @aakashgupta noted that Anthropic had blocked third-party harnesses from using subscription credentials four days prior, then launched the replacement.
Context Window Mismanagement (Severity: Medium)¶
@gregisenberg identified a widespread antipattern: overloading agent.md files with instructions that consume 7000+ tokens on every run, degrading performance. "The closer you get to filling the context window the worse the agent performs, same way you perform worse when someone dumps 10 things on you at once."
Agent Memory Loss (Severity: Medium)¶
@Mr_memsy noted: "Default setups forget fast." Without temporal decay, embedding caches, and governance files, agents "hallucinate stale context" rather than compound knowledge. @bellman_ych described reading "60MB of leaked JS at 3am and by breakfast I am asking 'what is oh-my-claudecode again.'"
3. What People Wish Existed¶
Agent Sandbox Protocol¶
@alexgshaw asked: "Who is building the Agent Sandbox Protocol? A way for users to specify where a 3P agent executes tools." Anthropic's blog describes decoupling the "brain from the hands" via tool calls, but no vendor-neutral standard exists.
Secure Skills Marketplace with Verification¶
Multiple signals converge: 26% of skills have vulnerabilities, 12% malware in some marketplaces. Skill Forge scans for leaked API keys and blocks critical issues, but the ecosystem lacks a trusted, curated marketplace with real usage-based rankings. OKX's Plugin Store promises "search, install, and share Skills in one place, ranked by real usage" -- but verification remains unsolved.
Long-Horizon Agent Reliability¶
The Gym-Anything benchmark shows the best model (GPT-5.4) achieves only 27.5% pass rate on 500+ step tasks. @tetsuoarena is building AgenC with the goal of "an agent that can keep building for a full year without stopping" -- a target that remains aspirational.
Agent-Native Identity and Access Management¶
@conor_ai's innie/outie pattern is a workaround. No standard exists for scoping what data agents can access based on who they interact with. @ashpreetbedi solved this for data agents with Dash's database-level RBAC, but this approach is domain-specific.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude Managed Agents | Agent Platform | Positive | Production fleet management, MCP integrations, credential vaults, sandbox abstraction | Private beta API access limited, vendor lock-in risk |
| Claude Skills / agent.md | Agent Configuration | Mixed | Skills load 50 tokens vs 7000 for agent.md; recursive improvement | 26% vulnerability rate in published skills ecosystem |
| OpenClaw | Open-Source Agent Framework | Positive | Local/privacy-first, WhatsApp/Telegram integration, /dreaming memory | 12% malware in marketplace, community-maintained |
| LangGraph | Orchestration | Positive | Stateful production workflows, checkpointing | Complexity for simple use cases |
| CrewAI | Multi-Agent Teams | Positive | Quick role-based team setup for marketing, research, ops | Less suited for production scale |
| DSPy | Agent Programming | Loyal following | Consistent framework across paradigm shifts | Claims of anticipating every wave met with skepticism |
| Skill Forge | Skill CI/CD | Positive | Publishes to 5 platforms, security scanning, structure validation | Addresses symptoms of ecosystem quality problem |
| Gym-Anything | Agent Evaluation | Promising | 200+ real software, 10K+ tasks, 80-90% cost reduction | Best agents still fail 72.5% of long-horizon tasks |
| Dirpack | Context Engineering | Positive | Deterministic context packing, Claude Code plugin, caching | Early stage |
| Rime Mist v3 | Voice Agent TTS | Positive | Phonetic brackets for deterministic pronunciation, 100ms TTFB | Language support unclear beyond English |
| Prefab (FastMCP 3.2) | Generative UI | Early | 100+ shadcn components in Python, no JavaScript needed | Just launched |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Dash v2 | @ashpreetbedi | Self-learning data team with 6 context layers | Text-to-SQL agents fail without tribal knowledge | Python, PostgreSQL, JWT RBAC | Open source, pre-release | Tweet |
| Skill Forge | motiful | Audits, validates, publishes agent skills to 5 platforms | 26% of skills have security vulnerabilities | Python, CLI | v9.0, MIT | GitHub |
| Gym-Anything / CUA-World | @wellecks, @PranjalAggarw16 (CMU) | Turns any software into agent training environment | Agent benchmarks limited to short tasks on consumer apps | Python, VM orchestration | Paper + code released | Site |
| AI Agent Skills | @tom_doerr | Curated skill library with CLI/TUI for building and managing | Skills scattered, no standard management | CLI/TUI, MIT | v4.2.0, 991 stars | Tweet |
| Sandbox Search | @arlanr | Codebase search that gives agents grounded repo information | Agents lack grounded context from codebases | Search infrastructure | Launched | Tweet |
| FinalRun Agent | final-run | AI-driven mobile app testing via natural language YAML specs | Manual mobile testing is slow and fragile | Node.js, Gemini/GPT/Claude, Apache 2.0 | Released on npm | GitHub |
| NTM Orchestration | @doodlestein | Swarm agents using 80-mode reasoning taxonomy | Code review tools look through single analytical lens | Claude Code + Codex swarm | Concept/prototype | Tweet |
| Prefab | @jlowin (Prefect) | Generative UI framework for MCP apps in Python | Building agent UIs requires JavaScript | Python, React/shadcn, FastMCP 3.2 | Launched | Site |
| AgenC | @tetsuoarena | Long-running autonomous agent with anti-injection hardening | Agents can't sustain work over long horizons | Google Concordia, TUI | Active development | Tweet |
| Dirpack | @raw_works | Deterministic context packing with Claude Code plugin | Context assembly is non-deterministic | CLI, plugin system | Released | Tweet |
| SkillX | @zxlzr | Automatically constructs skill knowledge bases from agent trajectories | Manual skill authoring doesn't scale | Research paper | Paper stage | Tweet |
Dash v2 stands out for its security model: the Analyst's SQL connection uses default_transaction_read_only=on, the Engineer writes only to a dash schema, and an eval suite explicitly tries to leak credentials, execute destructive SQL, and cross schema boundaries. The learning loop stores both curated knowledge (validated queries, business rules maintained by humans) and discovered knowledge (error patterns, gotchas maintained by the agent).
Gym-Anything addresses a fundamental gap in agent evaluation. Current benchmarks test short tasks over consumer apps, but real work happens in specialized professional software -- radiology tools, ERP systems, seismology monitors. Using agents to build agent environments, CUA-World achieves 80-90% cost reduction from standard deployment while covering 200+ applications across all 22 U.S. SOC occupation groups.

NTM's reasoning orchestration assigns each agent in a Claude Code + Codex swarm a distinct reasoning mode from an 80-mode taxonomy spanning 12 categories and 7 epistemological axes -- deductive logic, adversarial attack, counterfactual analysis, Bayesian updating -- then triangulates findings with provenance-tracked consensus.

6. New and Notable¶
AI Agents Finding Real Vulnerabilities¶
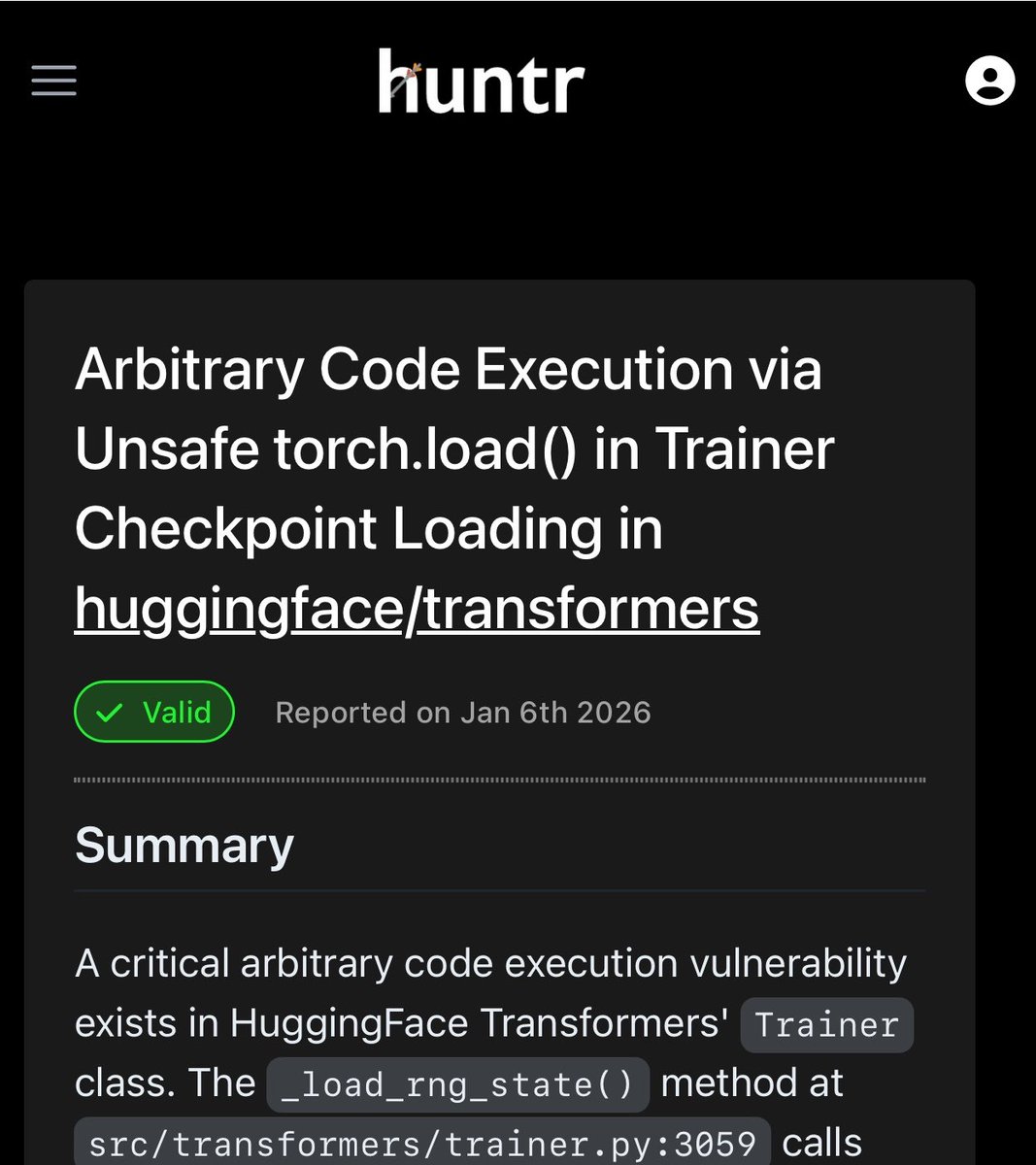
@_colemurray disclosed that his AI security agent "waclaude" found CVE-2026-1839 -- arbitrary code execution via unsafe torch.load() in HuggingFace's Transformers library. The vulnerability was a one-liner in PyTorch checkpoint loading. This is a concrete demonstration of agents performing useful security research, not just generating reports. Security-focused agent harnesses like PHALANX and METATRON (fully offline, local LLM) are emerging as a distinct category.
Retro Phone Meets Voice Agent at London AI Engineer¶
@ktoya_me connected an ElevenLabs voice agent to a retro rotary phone inside a red British telephone box, exhibited at the London AI Engineer conference. The phone was reverse-engineered with Claude and integrated with an ElevenLabs Agent. The installation drew 64 likes and 5K+ views -- a tangible demonstration of voice agent technology that attendees could physically interact with.

Southwest Airlines Deploys GitLab Duo Agent Platform at Scale¶
@bjmtweets reported Southwest Airlines is adopting GitLab Duo Agent Platform across its 3,000+ engineers, targeting 30% productivity gains. This is among the largest disclosed enterprise AI agent deployments with specific scale and ROI figures.
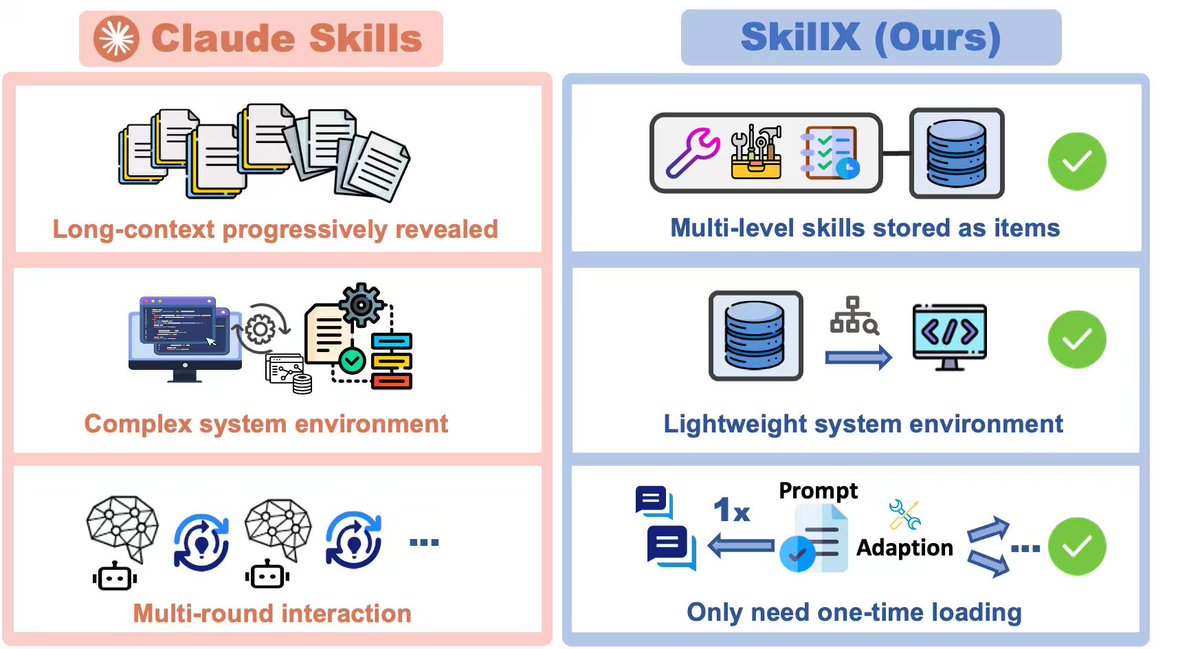
SkillX: Automated Skill Construction from Agent Trajectories¶
@zxlzr shared SkillX, a research system that automatically converts agent trajectories into reusable, indexed skills. Unlike Claude Skills which require long-context progressive revelation, SkillX stores multi-level skills as items with one-time loading and lightweight system requirements.
Self-Healing Agents¶
@witcheer documented an agent that "diagnosed and patched 5 of its own failure modes in GPT/Codex tool calling through self-reflection loops." This recursive self-repair pattern is also described by @gregisenberg: "ask the agent exactly why it failed. It will tell you specifically what went wrong. Fix it together in that same conversation. Then tell it to update the skill file so that failure mode never happens again."
7. Where the Opportunities Are¶
[+++] Strong: Agent Skills Quality and Security Infrastructure. 88K+ skills published, 26% with vulnerabilities, 12% malware in some marketplaces. Skill Forge addresses individual repos, but no trusted registry with automated scanning, usage-based ranking, and dependency analysis exists at ecosystem scale. The gap between what is published and what is safe to install is growing faster than any single tool can close.
[+++] Strong: Managed Agent Infrastructure for Enterprises. Anthropic proved demand by shipping Managed Agents. But enterprises need vendor-neutral options, multi-model support, and compliance certifications. 46% of enterprises cite integration as their primary agent challenge. Notion's integration model -- SaaS as orchestration layer, model provider as execution engine -- may become the template for dozens of vertical applications.
[++] Moderate: Long-Horizon Agent Evaluation and Training. Gym-Anything shows the best models fail 72.5% of realistic 500+ step tasks. Agent training infrastructure that scales to thousands of replicas with 80-90% cost reduction opens a market for specialized evaluation-as-a-service providers. Domain-specific benchmarks for healthcare, finance, and engineering software remain wide open.
[++] Moderate: Agent Memory and Knowledge Compounding. Current agents default to forgetting. The solutions emerging -- temporal decay, embedding caches, /dreaming modes, BRAID governance files -- are fragmented and framework-specific. A cross-platform agent memory layer that handles persistence, relevance decay, and multi-session compounding would address a pain point cited by multiple builders.
[++] Moderate: Voice Agent Vertical Solutions. LiveKit's Rime Mist v3 integration with phonetic brackets demonstrates the specificity required for regulated industries. @yourealazyfvck notes voice agents sell "for the same price" as multi-tool automation but with far less complexity. Pronunciation, compliance, and domain terminology remain unsolved at scale.
[+] Emerging: Agent Sandbox Protocol Standardization. No vendor-neutral protocol exists for specifying where agents execute tools. Anthropic decouples brain from hands; AWS offers S3 Files; open-source projects offer 22MB sandboxes. A standards body or de facto protocol for agent execution environments would reduce fragmentation.
[+] Emerging: Automated Skill Generation from Trajectories. SkillX demonstrates that agents can convert their own successful runs into reusable skills. Combined with @gregisenberg's recursive skill-building workflow, this points toward self-improving agent systems that manufacture their own capabilities -- currently research-stage but with clear production applications.
8. Takeaways¶
-
Meta re-enters the frontier model race with native multi-agent orchestration. Muse Spark's Contemplating mode parallelizes reasoning across agents without proportional latency increases, and "thought compression" reduces token consumption. The benchmark table shows competitive but not dominant results; long-horizon agentic coding remains a gap. (source)
-
Anthropic's Managed Agents is a platform play that threatens the orchestration middleware layer. By shipping production infrastructure with fleet management, credential vaults, and MCP integrations, Anthropic compressed years of startup roadmaps into a single launch. The four-day sequence -- blocking third-party auth, then launching the replacement -- signals intentional ecosystem consolidation. (source)
-
Agent skills are the new package ecosystem, and they have a security crisis. 88K+ published skills, 26% with vulnerabilities, 12% malware in some marketplaces. Skill Forge and similar tools treat symptoms; the ecosystem lacks the equivalent of npm audit + verified publishers operating at scale. (source)
-
Context engineering and harness engineering are formalizing as engineering disciplines. An L1-L6 maturity model maps the progression from prompt tricks to self-improving agents. OpenAI's Symphony demonstrates the endgame: 1M LOC, 1B tokens/day, zero human code or review. The distance between that endgame and most teams' current practice is enormous. (source)
-
Realistic agent benchmarks reveal harsh limitations. Gym-Anything's CUA-World-Long puts agents against 500+ step tasks across professional software, and the best model achieves 27.5% pass rate. The gap between demo-quality agent performance and production reliability on real professional workflows remains the field's central challenge. (source)
-
Skills over agent.md files is becoming consensus best practice. Loading full instruction files into every conversation wastes tokens and degrades performance. Skills that activate on demand, combined with recursive improvement workflows, produce more reliable agents. The practical advice: start with manual workflows, let the agent write the skill, iterate on failures. (source)
-
AI agents are finding real security vulnerabilities. An AI security agent discovered CVE-2026-1839 in HuggingFace Transformers -- a genuine arbitrary code execution bug. Security-focused agent harnesses (PHALANX, METATRON) are emerging as a specialized category, running fully offline with local LLMs. Agent-driven security research is transitioning from theoretical to productive. (source)