Twitter AI 智能体 - 2026-04-08¶
1. 人们在讨论什么¶
1.1 Meta 发布 Muse Spark,内置多智能体编排 🡕¶
Meta Superintelligence Labs 发布了 Muse Spark,这是一个原生多模态推理模型,具备工具使用、视觉思维链和多智能体编排能力。公告获得 152K+ 浏览量,并主导了当天讨论。@alexandr_wang(Scale AI CEO)提供了技术分析,指出 Muse Spark 展示了“预训练、RL 和测试时推理上的可预测扩展规律”,并引入“思维压缩”——用显著更少 token 解决问题的能力。
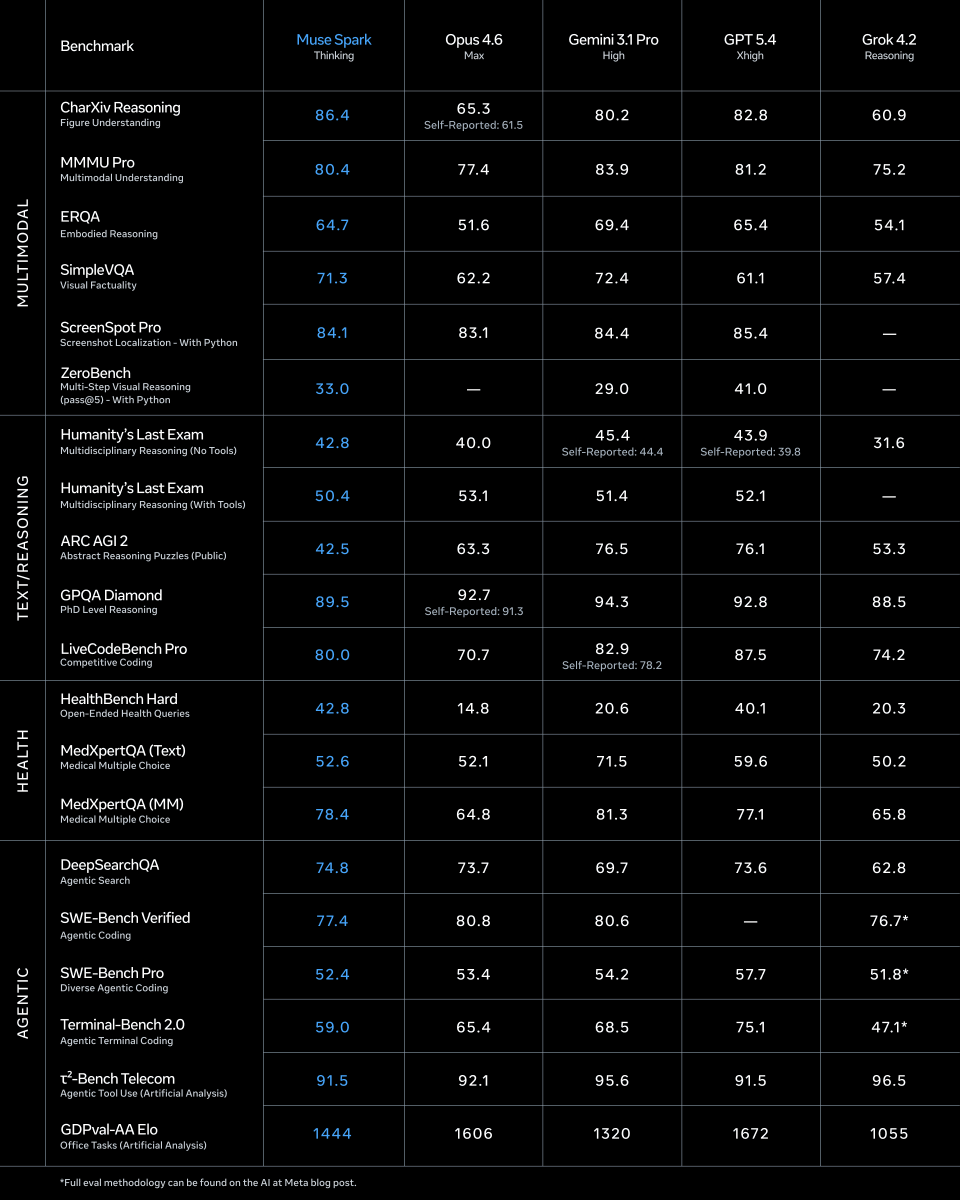
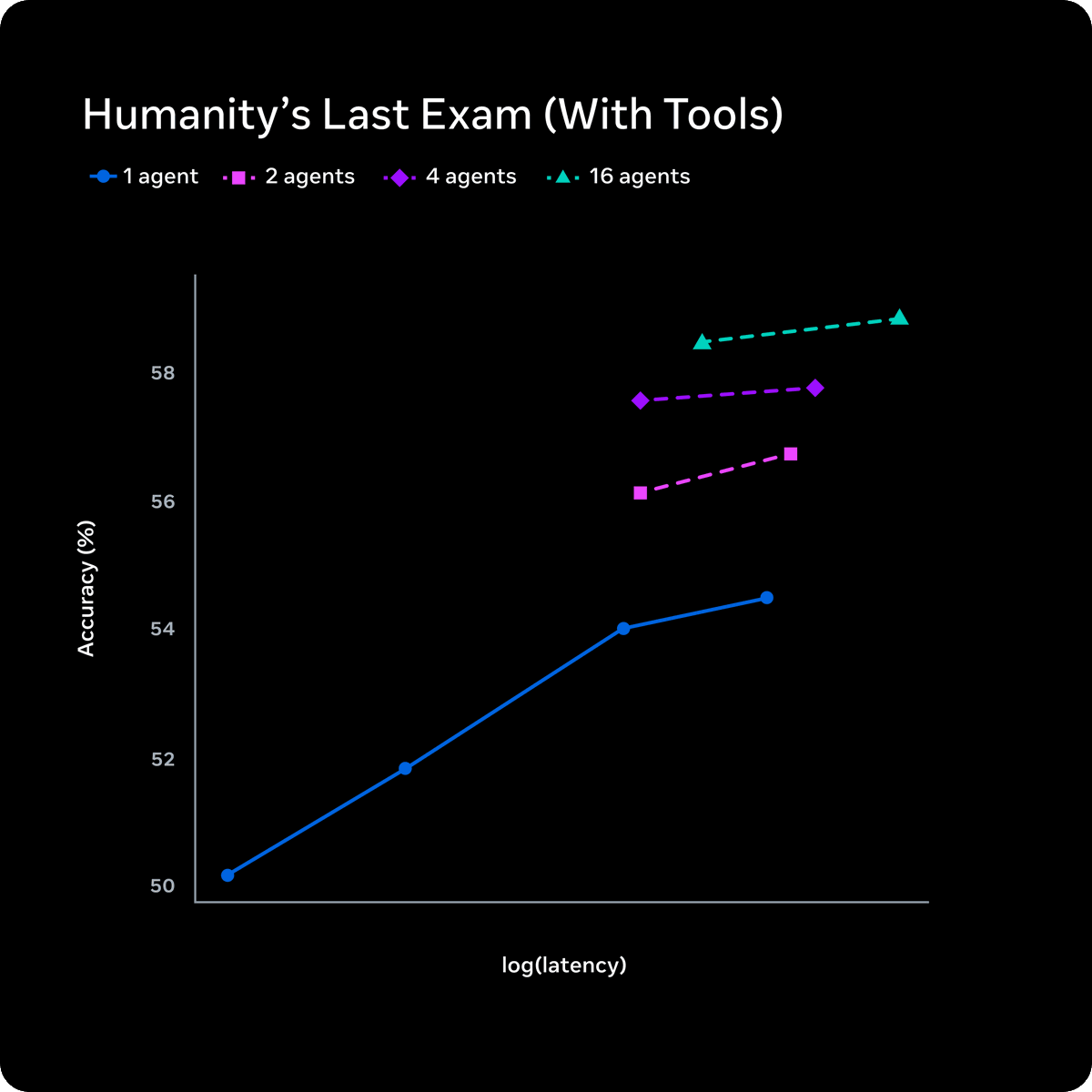
@jhyuxm 分享的基准测试表显示,Muse Spark 在 CharXiv Reasoning(86.4 vs 65.3)、ScreenSpot Pro(84.1 vs 83.1)和 HealthBench Hard(42.8 vs 14.8)上领先 Opus 4.6,但在 ARC AGI 2(42.5 vs 63.3)和 GPQA Diamond(89.5 vs 92.7)上落后。该模型的“Contemplating mode”会编排多个智能体并行推理;@omarsar0 指出,这些智能体“并行运行时并不会显著增加延迟”,并分享了一张图:16 个并行智能体在 Humanity's Last Exam 上达到约 59%,单智能体约为 55%。
质疑很快出现。一条回复指出 Meta “花了 $14 billion,挖走 Alexandr Wang,从零重建整个技术栈。第一个模型落在第四名。” @omarsar0 标记出“一些缺口,尤其是要支持长周期智能体系统和编程工作流。” @TrendSpider 观察到,Meta 股价因这则消息大幅反弹。
1.2 Anthropic 发布 Claude Managed Agents,威胁编排创业公司 🡕¶
Anthropic 发布了公开测试版 Claude Managed Agents,社区反应立刻爆发。@trq212 称其为第一个在简洁性和复杂性之间取得正确平衡的“云端智能体 API”,并详细说明了带自定义包、凭证保险库、文件系统记忆和 GitHub 集成的环境。这条推文获得 921 个点赞和 402 个收藏。
@aakashgupta 宣称 Anthropic “刚刚批量淘汰了所有智能体编排创业公司”,并指向一个生产机群仪表盘:8 个智能体正在运行,已处理 247 个任务,并接入了连接 MCP 的 HubSpot 集成。“Manus 花了六个月做五次运行框架重写。LangChain 花了一年做四套架构。Anthropic 直接发布了托管版本,让你根本不用再自己构建。” @shiri_shh 更直接:“整个 AI 智能体创业板块今天都被烤熟了。”
架构争论也随之升温。@charlespacker 分享了 Anthropic 工程博客摘录,描述“宠物与牛群”的容器问题——当智能体组件共享一个容器时,“运行框架里的 bug、事件流丢包,或者容器离线,看起来都会呈现同一种故障模式。” @alexgshaw 发问:“谁在构建《Agent Sandbox Protocol》?”

Notion 宣布接入 Claude 智能体,把 Notion 定位为编排层,而 Anthropic 负责运行模型和运行框架。社区成员马上追问是否会支持其他模型。
1.3 Skills 生态爆发(裂缝也显现)🡕¶
智能体技能成为扩展智能体能力的主导范式。@gregisenberg 发布了一篇详细拆解(398 个收藏),认为 agent.md 文件“大多没必要”——一个 1000 行文件每次运行会烧掉 7000 token,而技能在激活前只加载名称和描述(约 50 token)。他的框架是:先手动跑一遍工作流,让智能体写技能,再一起递归修复失败。
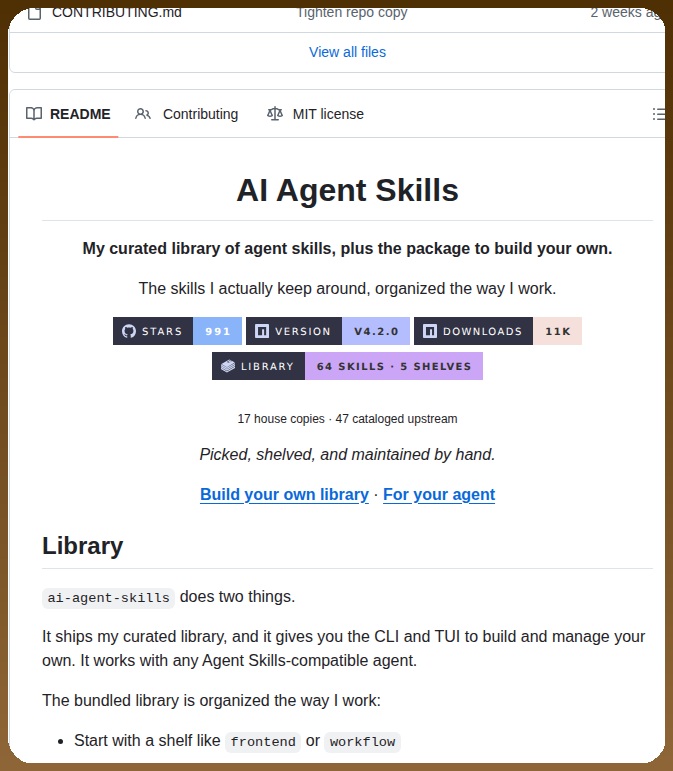
工具层正在快速成熟。@tom_doerr 分享了 AI Agent Skills(991 个星标、64 个技能、11K 下载量)和 Skill Forge,后者是一条可以同时审计并发布技能到五个平台的流水线。Skill Forge 的 README 揭示了一个冷静数据:生态中 88K+ 已发布技能里,社区审计估计约 26% 存在安全漏洞。@FOUNDATIONdvcs 证实:“AI 智能体市场:12% 是恶意软件。”

多个厂商宣布支持技能:MongoDB for Cursor、带 MCP 服务器的 Coinbase Developer Platform、用于 Base 和 Farcaster 链上小应用的 Lazer CLI,以及在一次更新里交付技能 + 云端 + MCP 的 Enter Pro。
1.4 运行框架工程和上下文工程形式化 🡒¶
两个相邻学科正在以正式名称成型。@latentspacepod 发布了 《Extreme Harness Engineering》,介绍 OpenAI 的 Symphony——一个由 Codex 智能体生成 100 万行代码、每天 10 亿 token 的“幽灵库”,做到“0% 人类写代码,合并前 0% 人工审查”。访谈揭示了运行框架工程如何在 OpenAI 内部从 GPT-5 演进到 GPT-5.4。
@IntuitMachine 分享了一套 L1-L6 成熟度模型,将从提示工程(L1)到上下文工程(L2)、运行框架工程(L3-L4),再到自我改进智能体(L6)的进展映射出来,并把“Quality/Vitality Engineering”识别为 L6 阶段尚未命名的行业缺口。

@helloiamleonie(Elastic)在 AI Engineer Europe 举办了一个工作坊,主题是《Agentic Search for Context Engineering》。@DSPyOSS 声称自己预判了每一波:“2024:智能体式工作流!我们:DSPy。2025:上下文工程!我们:DSPy。2026:运行框架工程!!我们:DSPy。”

1.5 智能体基础设施:S3、沙箱和 OS 问题 🡕¶
@skeptrune 认为,Amazon S3 Files 对智能体具有转型意义:“你不再需要启动沙箱 VM,才能让智能体访问 POSIX 工具。现在你可以把任意规模的计算资源指向 S3,在同一个文件系统上运行大规模并行智能体集群。” 这条推文获得 632 个收藏——当天最高收藏率。讨论也降低了预期,指出你仍然需要沙箱来挂载文件系统。
@NathanFlurry 描述了正在构建的开源沙箱基础设施:“任意智能体、任意 LLM,每个沙箱 22 MB RAM,BYOC/本地部署,任意文件系统。”
@HSVSphere 给出了一个反向愿景:“未来没有特殊的‘智能体沙箱’,未来是一个构建在动态语言之上的操作系统,对一切都有能力和(内在的)作用域。” 讨论将其类比到 Plan9 和 Ruby,并把 TypeScript 斥为“太静态”。
2. 令人困扰的问题¶
智能体安全和信任(严重性:高)¶
技能生态的增长速度已经超过安全基础设施。Skill Forge 审计发现,88K+ 已发布技能中约 26% 存在安全漏洞。@JamesonCamp 警告:“OpenClaw 市场中 12% 根本就是恶意软件。键盘记录器。身份盗窃。你的 AI 智能体正在安装陌生人发布的包。” @conor_ai 强调信息泄露:“智能体可以、也会把敏感信息分享给任何正在和它们对话的人”,这促成 Hyperspell 采用受“Severance”启发的“innie/outie”智能体架构。
平台风险和创业公司焦虑(严重性:高)¶
Anthropic 发布 Managed Agents 引发了编排创业公司的生存焦虑。@SolSt1ne 捕捉到这种情绪:“花 6 个月构建自定义智能体基础设施、编排、重试逻辑、限流,‘终于可投入生产’,然后 Anthropic 发布 Claude Managed Agents 公开测试版。” @aakashgupta 指出,Anthropic 四天前刚阻止第三方运行框架使用订阅凭证,随后就发布了替代品。
上下文窗口管理不当(严重性:中)¶
@gregisenberg 指出一个常见反模式:把 agent.md 文件塞满指令,导致每次运行都消耗 7000+ token,拖累表现。“你越接近填满上下文窗口,智能体表现就越差,就像别人一次性往你脑子里倒 10 件事时,你也会表现变差。”
智能体记忆丢失(严重性:中)¶
@Mr_memsy 指出:“默认配置很快就会忘记。” 如果没有时间衰减、嵌入缓存和治理文件,智能体会“幻觉出过期上下文”,而不是复利式积累知识。@bellman_ych 描述了自己“凌晨 3 点读了 60MB 泄露 JS,到早餐时却在问‘oh-my-claudecode 又是什么来着’。”
3. 人们期望的功能¶
Agent Sandbox Protocol¶
@alexgshaw 发问:“谁在构建《Agent Sandbox Protocol》?一种让用户指定第三方智能体在哪里执行工具的方式。” Anthropic 的博客描述了用工具调用把“大脑”和“手”解耦,但还没有厂商中立标准。
带验证的安全技能市场¶
多个信号汇合:26% 的技能有漏洞,一些市场中 12% 是恶意软件。Skill Forge 会扫描泄露的 API 密钥并阻断严重问题,但生态缺少一个可信、经过筛选、按真实使用情况排名的市场。OKX 的 Plugin Store 承诺“在一个地方搜索、安装和分享技能,并按真实使用情况排名”——但验证问题仍未解决。
长周期智能体可靠性¶
Gym-Anything 基准测试显示,最佳模型(GPT-5.4)在 500+ 步任务上的通过率只有 27.5%。@tetsuoarena 正在构建 AgenC,目标是“一个可以连续构建整整一年而不停下来的智能体”——但这个目标仍然偏愿景。
智能体原生身份与访问管理¶
@conor_ai 的 innie/outie 模式 是一种权宜方案。现在还没有标准,能根据智能体与谁交互来限定它能访问哪些数据。@ashpreetbedi 用 Dash 的数据库级 RBAC 为数据智能体解决了这个问题,但这种方法是领域特定的。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Claude Managed Agents | 智能体平台 | 积极 | 生产机群管理、MCP 集成、凭证保险库、沙箱抽象 | 公开测试 API 访问受限、存在厂商锁定风险 |
| Claude Skills / agent.md | 智能体配置 | 褒贬不一 | 技能只加载 50 个 token,而 agent.md 要 7000 个;支持递归改进 | 已发布技能生态中 26% 存在漏洞 |
| OpenClaw | 开源智能体框架 | 积极 | 本地/隐私优先、WhatsApp/Telegram 集成、/dreaming 记忆 | 市场中 12% 是恶意软件、由社区维护 |
| LangGraph | 编排 | 积极 | 有状态生产工作流、检查点 | 简单用例中复杂度偏高 |
| CrewAI | 多智能体团队 | 积极 | 快速搭建面向营销、研究、运营的角色型团队 | 不太适合生产规模 |
| DSPy | 智能体编程 | 忠实拥趸 | 跨范式变化的一致框架 | “预判每一波”的说法受到质疑 |
| Skill Forge | 技能 CI/CD | 积极 | 发布到 5 个平台、安全扫描、结构验证 | 解决的是生态质量问题的症状 |
| Gym-Anything | 智能体评估 | 有前景 | 200+ 真实软件、10K+ 任务、80-90% 成本降低 | 最佳智能体在长周期任务上仍失败 72.5% |
| Dirpack | 上下文工程 | 积极 | 确定性上下文打包、Claude Code 插件、缓存 | 早期阶段 |
| Rime Mist v3 | 语音智能体 TTS | 积极 | 用音标括号保证发音可确定、100ms TTFB | 英语之外的语言支持不清楚 |
| Prefab (FastMCP 3.2) | 生成式 UI | 早期 | Python 中提供 100+ shadcn 组件,无需 JavaScript | 刚发布 |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Dash v2 | @ashpreetbedi | 带 6 层上下文的自学习数据团队 | Text-to-SQL 智能体缺少团队隐性知识就会失败 | Python, PostgreSQL, JWT RBAC | 开源,预发布 | Tweet |
| Skill Forge | motiful | 审计、验证并将智能体技能发布到 5 个平台 | 26% 的技能存在安全漏洞 | Python, CLI | v9.0, MIT | GitHub |
| Gym-Anything / CUA-World | @wellecks, @PranjalAggarw16 (CMU) | 把任意软件变成智能体训练环境 | 智能体基准测试只覆盖消费级应用上的短任务 | Python, VM 编排 | 论文 + 代码已发布 | Site |
| AI Agent Skills | @tom_doerr | 精选技能库,带 CLI/TUI 用于构建和管理技能 | 技能分散,缺少标准管理方式 | CLI/TUI, MIT | v4.2.0, 991 星标 | Tweet |
| Sandbox Search | @arlanr | 为智能体提供扎实仓库信息的代码库搜索 | 智能体缺少来自代码库的扎实上下文 | 搜索基础设施 | 已发布 | Tweet |
| FinalRun Agent | final-run | 用自然语言 YAML 规格驱动 AI 移动应用测试 | 手动移动测试缓慢且脆弱 | Node.js, Gemini/GPT/Claude, Apache 2.0 | 已发布到 npm | GitHub |
| NTM Orchestration | @doodlestein | 使用 80 种推理模式分类法的智能体集群 | 代码审查工具只会从单一分析视角看问题 | Claude Code + Codex 集群 | 概念/原型 | Tweet |
| Prefab | @jlowin (Prefect) | Python 中面向 MCP 应用的生成式 UI 框架 | 构建智能体 UI 需要 JavaScript | Python, React/shadcn, FastMCP 3.2 | 已发布 | Site |
| AgenC | @tetsuoarena | 带反注入加固的长运行自主智能体 | 智能体无法持续处理长周期工作 | Google Concordia, TUI | 开发中 | Tweet |
| Dirpack | @raw_works | 带 Claude Code 插件的确定性上下文打包 | 上下文组装不确定 | CLI, 插件系统 | 已发布 | Tweet |
| SkillX | @zxlzr | 从智能体轨迹自动构建技能知识库 | 手动编写技能无法扩展 | 研究论文 | 论文阶段 | Tweet |
Dash v2 的突出点是安全模型:Analyst 的 SQL 连接使用 default_transaction_read_only=on,Engineer 只写入 dash schema,评测套件会明确尝试泄露凭证、执行破坏性 SQL,并跨越 schema 边界。学习循环同时存储人工整理的知识(已验证查询、人类维护的业务规则)和自动发现的知识(错误模式、易踩坑,由智能体维护)。
Gym-Anything 解决了智能体评估中的根本缺口。当前基准测试测的是消费级应用上的短任务,但真实工作发生在专门的专业软件中——放射科工具、ERP 系统、地震学监测工具。CUA-World 让智能体构建智能体环境,相比标准部署降低 80-90% 成本,同时覆盖美国 22 个 SOC 职业组中的 200+ 个应用。

NTM 的推理编排 会给 Claude Code + Codex 集群中的每个智能体分配一种来自 80 种模式分类法的不同推理模式,该分类法跨 12 个类别和 7 条认识论轴——演绎逻辑、对抗性攻击、反事实分析、贝叶斯更新——然后用带来源追踪的共识来交叉校验结论。

6. 新动态与亮点¶
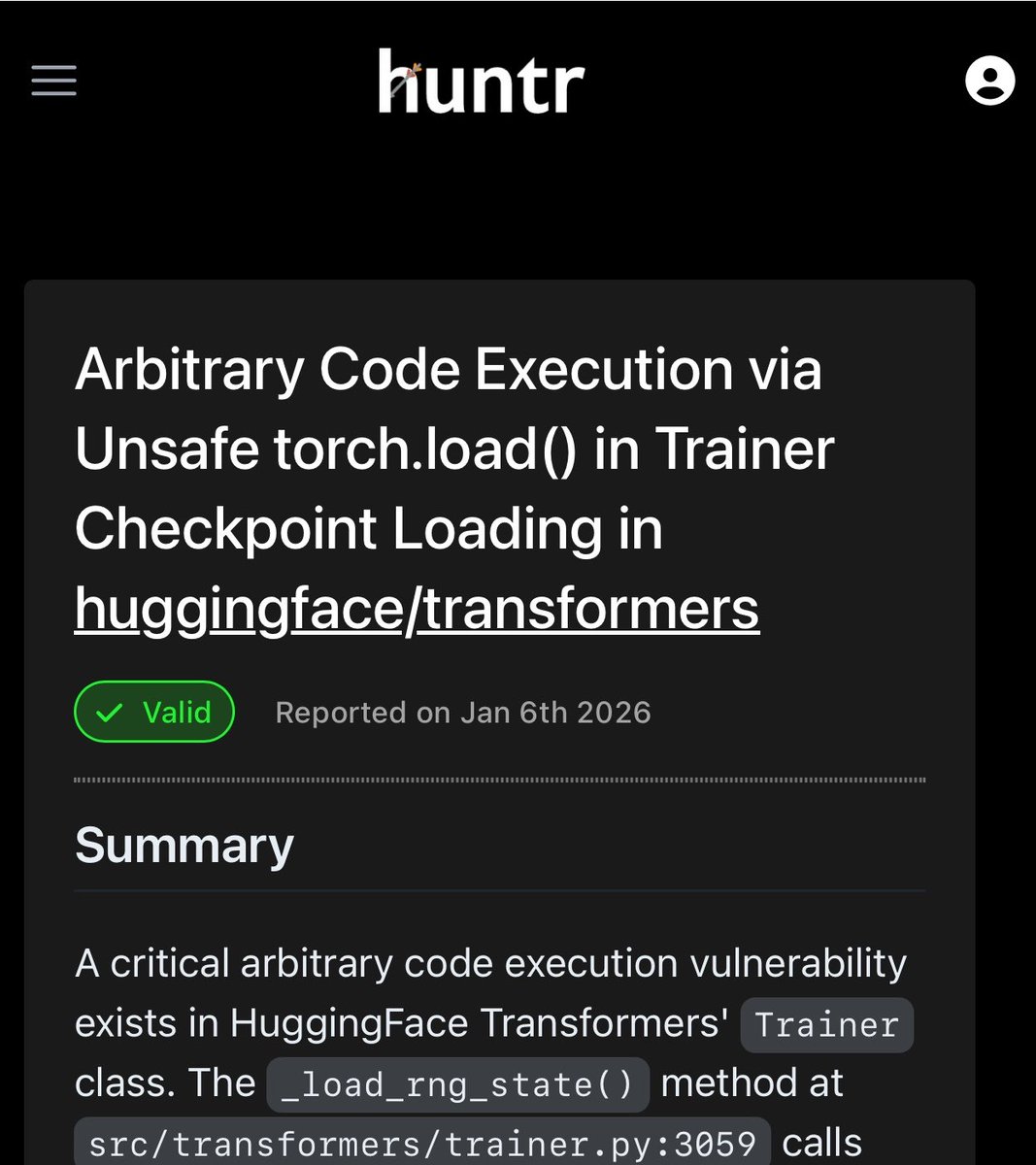
AI 智能体发现真实漏洞¶
@_colemurray 披露,他的 AI 安全智能体“waclaude”发现了 CVE-2026-1839——HuggingFace Transformers 库中由不安全 torch.load() 引发的任意代码执行。该漏洞是 PyTorch checkpoint 加载中的一行代码。这是智能体执行有效安全研究的具体证明,不只是生成报告。像 PHALANX 和 METATRON 这样的面向安全的智能体运行框架(完全离线、本地 LLM)正在成为独立类别。
复古电话在 London AI Engineer 接入语音智能体¶
@ktoya_me 把 ElevenLabs 语音智能体接到一部复古转盘电话,放在 London AI Engineer 大会的红色英国电话亭里展示。这部电话是用 Claude 逆向工程出来的,并接入 ElevenLabs Agent。装置获得 64 个点赞和 5K+ 浏览量——它让参会者可以实际触摸和交互,成为语音智能体技术的实体演示。

Southwest Airlines 大规模部署 GitLab Duo Agent Platform¶
@bjmtweets 报道,Southwest Airlines 正在 3,000+ 名工程师中采用 GitLab Duo Agent Platform,目标是提升 30% 生产力。这是已公开披露的最大规模企业 AI 智能体部署之一,并给出了具体规模和 ROI 数据。
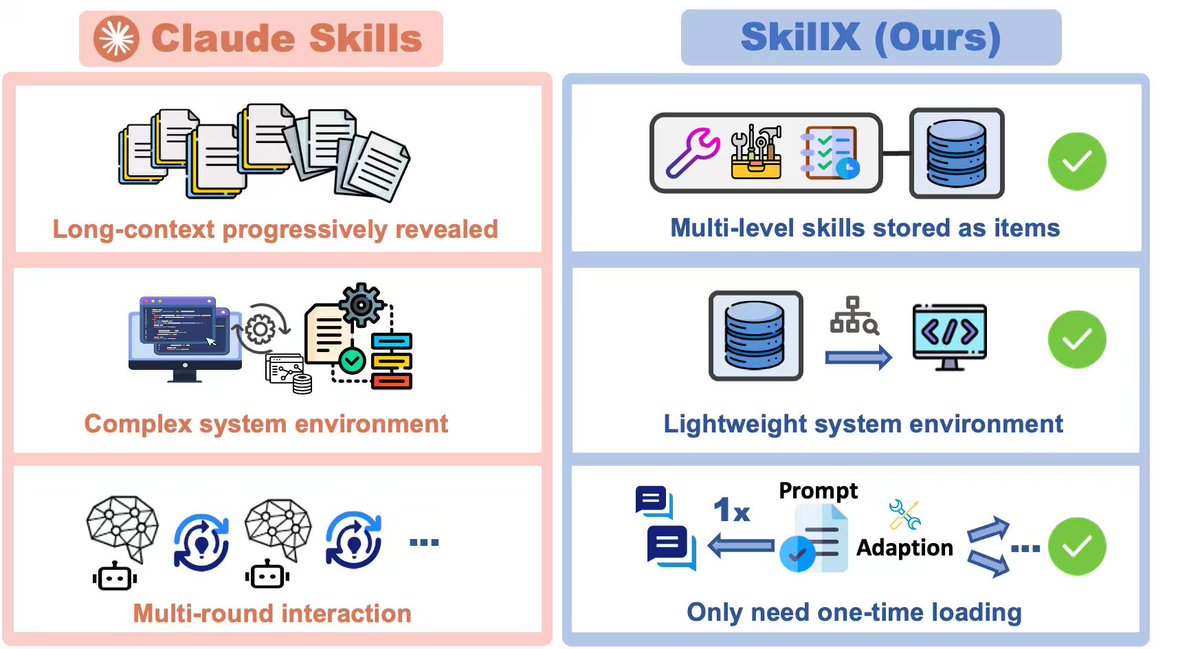
SkillX:从智能体轨迹自动构建技能¶
@zxlzr 分享了 SkillX,一个把智能体轨迹自动转换成可复用、可索引技能的研究系统。不同于需要长上下文渐进式揭示的 Claude Skills,SkillX 将多层级技能存为条目,一次加载,系统要求更轻。
自愈智能体¶
@witcheer 记录了一个智能体“通过自我反思循环诊断并修补了自己在 GPT/Codex 工具调用中的 5 种失败模式。” 这种递归自修复模式也出现在 @gregisenberg 的描述中:“问智能体它到底为什么失败。它会具体告诉你哪里出了问题。在同一段对话里一起修复。然后让它更新技能文件,确保这种失败模式永远不再发生。”
7. 机会在哪里¶
[+++] 强信号:智能体技能质量和安全基础设施。 88K+ 技能已发布,26% 存在漏洞,一些市场中 12% 是恶意软件。Skill Forge 解决的是单个仓库层面的问题,但生态层面还没有一个带自动扫描、基于使用排名和依赖分析的可信注册表。发布规模与安全安装之间的缺口,正在以任何单一工具都追不上的速度扩大。
[+++] 强信号:面向企业的托管智能体基础设施。 Anthropic 通过发布 Managed Agents 证明了需求。但企业需要厂商中立选项、多模型支持和合规认证。46% 的企业把集成列为主要智能体挑战。Notion 的集成模式——SaaS 作为编排层,模型提供商作为执行引擎——可能成为几十个垂直应用的模板。
[++] 中等信号:长周期智能体评估和训练。 Gym-Anything 显示,最佳模型在现实的 500+ 步任务上失败率仍为 72.5%。能够以 80-90% 成本降低扩展到数千副本的智能体训练基础设施,会打开专门的评估即服务提供商市场。面向医疗、金融和工程软件的领域基准测试仍然大开。
[++] 中等信号:智能体记忆和知识复利。 当前智能体默认会遗忘。正在出现的方案——时间衰减、嵌入缓存、/dreaming 模式、BRAID 治理文件——都碎片化且绑定框架。一个跨平台智能体记忆层,如果能处理持久化、关联度衰减和多会话知识复利,将解决多个开发者提到的痛点。
[++] 中等信号:语音智能体垂直解决方案。 LiveKit 的 Rime Mist v3 集成 通过音标括号展示了受监管行业需要的细粒度能力。@yourealazyfvck 指出,语音智能体能以“同样价格”售出,但复杂度远低于多工具自动化。发音、合规和领域术语仍未在规模化场景下解决。
[+] 新兴信号:Agent Sandbox Protocol 标准化。 目前没有厂商中立协议来指定智能体在哪里执行工具。Anthropic 解耦大脑和手;AWS 提供 S3 Files;开源项目提供 22MB 沙箱。一个标准组织或事实协议如果能定义智能体执行环境,将降低碎片化。
[+] 新兴信号:从轨迹自动生成技能。 SkillX 展示了智能体能把自己的成功运行转换成可复用技能。结合 @gregisenberg 的递归技能构建工作流,这指向能自我制造能力的自我改进智能体系统——目前仍处研究阶段,但生产应用清晰。
8. 要点总结¶
-
Meta 带着原生多智能体编排重新进入前沿模型竞赛。 Muse Spark 的 Contemplating mode 可以在不成比例增加延迟的情况下跨智能体并行推理,“思维压缩”降低 token 消耗。基准测试表显示它有竞争力但并不占优;长周期智能体式编程仍是缺口。(source)
-
Anthropic 的 Managed Agents 是一次威胁编排中间层的平台动作。 Anthropic 通过交付生产基础设施,包括机群管理、凭证保险库和 MCP 集成,把创业公司多年的路线图压缩成一次发布。四天内先封锁第三方认证,再发布替代品,显示出有意的生态整合。(source)
-
智能体技能是新的软件包生态,而且已经出现安全危机。 88K+ 已发布技能,26% 存在漏洞,一些市场中 12% 是恶意软件。Skill Forge 和类似工具只能处理症状;生态缺少等同于 npm audit + 认证发布者的规模化机制。(source)
-
上下文工程和运行框架工程正在形式化为工程学科。 L1-L6 成熟度模型把从提示词技巧到自我改进智能体的进展映射出来。OpenAI 的 Symphony 展示了终局:100 万 LOC、每天 10 亿 token、零人类代码或审查。这个终局和多数团队当前实践之间差距巨大。(source)
-
真实智能体基准测试揭示了残酷限制。 Gym-Anything 的 CUA-World-Long 让智能体面对专业软件中的 500+ 步任务,最佳模型通过率只有 27.5%。演示级智能体表现和真实专业工作流上的生产可靠性之间的差距,仍是这个领域的核心挑战。(source)
-
用技能取代 agent.md 文件正成为共识性最佳实践。 每次对话都加载完整指令文件会浪费 token 并降低表现。按需激活的技能,加上递归改进工作流,会产出更可靠的智能体。实践建议是:从手动工作流开始,让智能体写技能,再围绕失败迭代。(source)
-
AI 智能体正在发现真实安全漏洞。 一个 AI 安全智能体在 HuggingFace Transformers 中发现 CVE-2026-1839——真实的任意代码执行漏洞。面向安全的智能体运行框架(PHALANX、METATRON)正在成为一个专门类别,完全离线、使用本地 LLM。智能体驱动的安全研究正从理论走向生产力。(source)