Twitter AI Agent - 2026-04-11¶
1. What People Are Talking About¶
1.1 Agent Skills Become the Standard Knowledge Layer 🡕¶
The agent skills format -- markdown files that encode procedural knowledge for AI coding tools -- crossed a tipping point this week. Multiple independent signals confirm it is no longer a Claude-only curiosity but an emerging cross-platform standard.
@xelebofficial published a misconceptions thread arguing that skills are not "just a long prompt" (skills persist across tasks while prompts vanish), do not require coding ability (they are markdown), and work across GitHub Copilot, Cursor, Gemini CLI, and Windsurf -- not only Claude. The most provocative claim: "The highest-value Skills are rarely about code. They are about how your team writes proposals. How you structure a report. How you handle a client escalation."

@code_rams announced autoskills, a CLI tool (npx autoskills) that fingerprints a project's tech stack and auto-installs matching skill files from a curated registry at skills.sh, supporting 50+ technologies. A reply from @safaa_9411 raised prompt injection risks if skills are not securely reviewed before loading.
@tom_doerr shared Paul Hudson's Swift Agent Skills repository -- a curated collection of open-source skills for Swift and Apple platform development organized by framework (SwiftUI, SwiftData, Swift Concurrency, and more), with a prominent safety warning about reviewing third-party skills before installation.

@dshukertjr launched official Supabase Agent Skills, packaging the latest product knowledge and docs as skills -- marking a shift where platform vendors distribute documentation as agent-consumable files rather than human-readable pages.
@AlphaSignalAI covered a Google engineer's open-source Agent Skills repo encoding 19 engineering skills and 7 slash commands that cover the full dev lifecycle: spec before code, test before merge, measure before optimize. Works with Claude Code, Cursor, or any agent that reads markdown.
@DipanshuKu55175 compiled Anthropic's 13 free certification courses, including Introduction to Agent Skills and MCP Advanced Topics -- a substantial educational push signaling Anthropic's investment in ecosystem growth.
1.2 Harness Engineering Crystallizes as a Discipline 🡕¶
The idea that the code around the model matters more than the model itself gained both empirical backing and its first textbook-length treatments this week.
@elvissun posted the day's top-scoring tweet (464 likes, 744 bookmarks) describing how Codex "one-shotted our turbo cache fix" after being given the right harness -- an agent debugging loop that reduced build time from 3 minutes 22 seconds to 34 seconds. The attached image showed a structured three-step methodology: give the agent diagnostic eyes (local and cloud tools), drop it in a hypothesis-test-result feedback loop, and let it drive while the engineer watches from Telegram.

@IntuitMachine did a deep thread on the Meta-Harness paper (arXiv:2603.28052v1), where automated harness optimization beat human experts by 7.7 points, used 4x fewer tokens, and generalized to unseen models. The key finding: harness changes alone can produce 6x performance swings from the same frozen model.
@tom_doerr shared two full-length books on harness engineering (hosted at harness-books.agentway.dev): a design guide to Claude Code and a comparative study of Claude Code and Codex philosophies. Core claim: "Harness engineering is about how constraint structures organize execution."

@RLanceMartin discussed session-harness decoupling, presenting an architecture where the session is a context object the brain can interrogate, with the key insight that "no context engineering is irreversible."
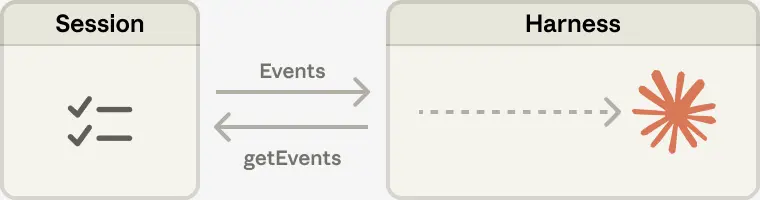
@ottamm_190 shared a survey paper ("Externalization in LLM Agents," arXiv:2604.08224) with 21 authors that provides academic grounding: memory externalizes state, skills externalize procedural expertise, protocols externalize interaction structure, and harness engineering is the unification layer.
@deararchitects offered pushback: harness engineering "sounds like the obvious next step for faster delivery. But it's also another layer of infrastructure that teams now have to own and maintain."
1.3 The Personal AI Voice Agent Wave 🡕¶
@garrytan (YC president) dominated the personal AI conversation with three posts. GBrain v0.8.0 launched with voice-to-brain capabilities shipping 25 production patterns: WebRTC default, context-first prompts, dynamic VAD, radical prompt compression (13K to 4.7K tokens), stuck watchdog, thinking sounds during tool calls, and auth-before-speech. The changelog image revealed production-grade voice infrastructure, not a demo.

He also described building his voice agent from a pool in Kona by chatting with it on Telegram on his iPhone, noting that "I gave up drinking to code better." A third post evangelized the personal AI movement, with a reply confirming the setup "runs everything, stuff that'd cost $200 a month elsewhere."
@ASUS published an official blog guide on repurposing old laptops as dedicated AI agents using OpenClaw -- a major hardware vendor legitimizing the personal AI agent use case.
@cgtwts showed running Gemma locally with OpenClaw in three commands (install Ollama, download Gemma, launch OpenClaw), demonstrating the lowest possible barrier to a fully private AI agent.
1.4 Agent Platform Competition Intensifies 🡒¶
The OpenClaw vs. Hermes Agent rivalry took center stage. @iamlukethedev detailed the OpenClaw v2026.4.10 release: Active Memory plugin (auto-pulls preferences and past conversations), native Codex provider, and local speech on macOS. However, @markkurajala2 reported Active Memory returning empty results in real use despite manual memory working -- a production readiness gap.
@steipete (OpenClaw maintainer) revealed two experimental modes for GPT in OpenClaw: strict mode that nudges the model to keep working, and a codex app server as harness -- a 144-like reply signaling high community interest in making non-Claude models viable orchestrators.
@bridgemindai set up Hermes Agent on NVIDIA DGX Spark for cold outreach emails in under 20 minutes, claiming "OpenClaw got the hype. Hermes got the architecture right." @cto_junior praised Hermes's self-learning loop as capturing learnings better than manual approaches and spinning up new skills automatically.
@KanikaBK shared "The Orange Book", a community-written 17-chapter Hermes Agent manual covering the three-layer memory system, skill creation loop, and comparison with Claude Code and OpenClaw -- community documentation filling gaps left by Nous Research.
@Codex_Changelog announced Codex 0.119.0 with WebRTC voice default, substantial MCP improvements (resource reads, elicitations, file uploads), and remote/app-server workflows. A reply from @jlave_dev criticized the pace: "you guys need to pick up the pace to compete with claude code. a copy shortcut being one of the top new features is crazy."
1.5 Context Engineering Enters the Mainstream 🡕¶
@drummatick listed the topics needed to become a top 1% AI engineer -- context engineering, context compactness, agent harness, memory, and subagent spawning appeared alongside traditional LLM skills. The post drew 331 bookmarks, signaling high demand for structured learning paths. A reply added "evals and guardrails" to the list.
@nyk_builderz argued the next AI moat is context governance: "Teams shipping fastest in 2026 all do 3 things: version memory like code, score agent outputs before action, treat prompts as interfaces, not magic." An extended exchange with @l33tdawg compared SAGE (BFT-consensus memory as data plane) with LACP (control plane for Claude Code), concluding they are complementary rather than competing.
@i_amanchadha published a comprehensive context engineering primer at contexteng.aman.ai covering building blocks, retrieval/memory/compression, failure modes (context poisoning, distraction, confusion, clash), and production heuristics.
@aa22396584 crystallized the consensus: "People focus on 'which model is better' when the real skill gap is: how to structure agent memory, design permission boundaries, and build composable SKILL.md files. The tooling is commodity; the architecture is the competitive edge."
2. What Frustrates People¶
Vault and Permission Scoping in Managed Agents (High)¶
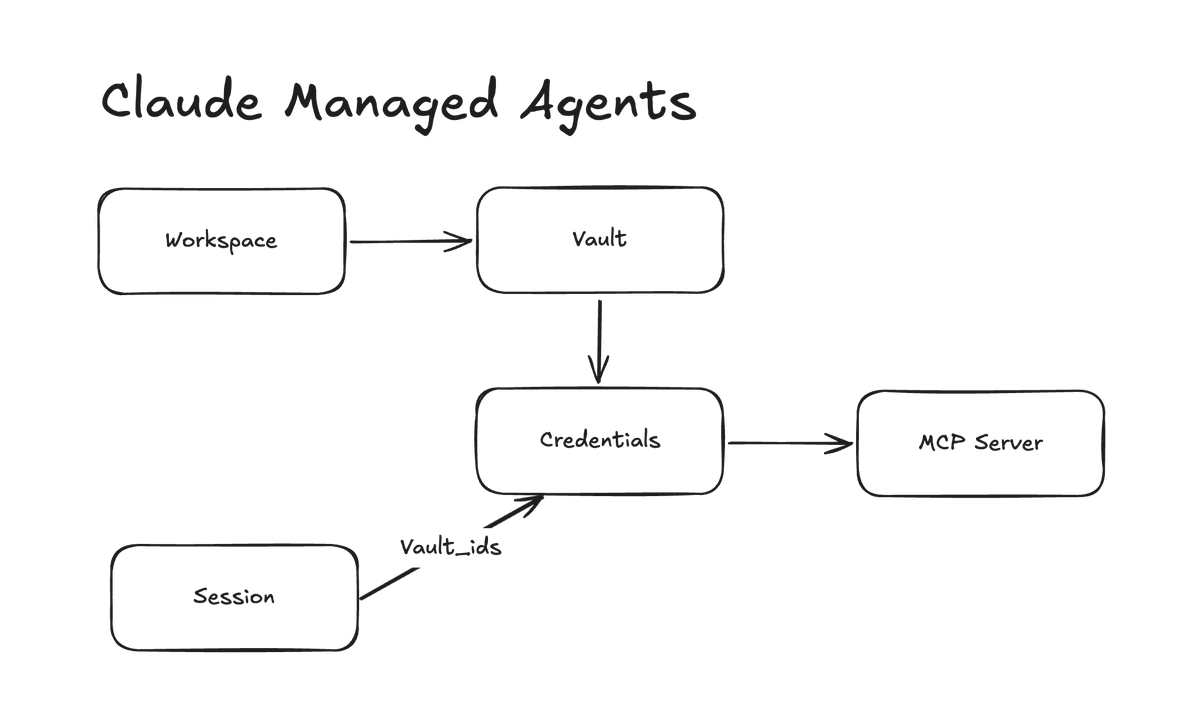
@dani_avila7 discovered that Claude Managed Agents vaults are workspace-scoped, meaning anyone with workspace access can reference vaults and use stored OAuth credentials in their own sessions. The architectural diagram makes the issue clear: sessions attach vault_ids, but access control exists only at the workspace level. Requested fixes include per-agent vault permissions, credential audit logs, and native scheduled agents.
Active Memory Not Working in Production (Medium)¶
@markkurajala2 reported that OpenClaw's new Active Memory plugin "keeps returning empty for us in real use, even though manual memory searches do return relevant results." Another user reported being stuck debugging in terminal after updating. The headline feature of a major release not working reliably in production is a recurring pattern.
Agent Tooling Pace vs. Competition (Medium)¶
@jlave_dev criticized Codex: "you guys need to pick up the pace to compete with claude code. a copy shortcut being one of the top new features is crazy." The frustration reflects a broader sentiment that OpenAI's agent tooling lags behind Anthropic's in developer experience.
Misaligned Infrastructure Metrics (Low)¶
@braelyn_ai pointed out that sandbox vendors compete on initialization time ("0.02s faster") while the agent using the sandbox takes 15 minutes. The real bottleneck is agent execution time, not infrastructure startup -- vendors optimize for benchmarks rather than user-experienced performance.
Agent Exploit Demos Mislead About General Capability (Low)¶
@dbreunig argued that finding exploits is a search problem (find one crack in a wall), while building software is a construction problem (handle edge cases, maintain coherence). Agent exploit demos have built-in verification loops that make them ideal marketing but poor indicators of broader capability. Unanswered question: how much did Anthropic spend per exploit?
3. What People Wish Existed¶
Granular Agent Permission Systems¶
Multiple practitioners described the need for per-agent (not per-workspace) credential scoping, runtime permission enforcement that prevents drift between declared and actual agent capabilities, and credential audit trails showing who used what and when. @dani_avila7 and @0xAgix both raised versions of this need independently.
A Unified Learning Path for Agent Engineering¶
@drummatick acknowledged "there's almost no single resource to capture all" the skills needed for top-tier AI engineering, promising to write one. @KanikaBK noted that Nous Research "dropped the tool and basically left you to figure it out alone." The community is creating its own documentation -- Orange Book, harness books, context engineering primer -- but no canonical curriculum exists.
Agent-Native Scheduling and Cron¶
@dani_avila7 specifically called out the lack of native scheduled agents in Claude Managed Agents, noting that "cron job workarounds shouldn't be needed." @Viewforge built a multi-device scheduler to fill this gap, suggesting the demand is strong enough to motivate independent tooling.
Cross-Framework Skill Portability Guarantees¶
While @xelebofficial claims skills work across multiple platforms, @felipedeleon_ noted the need for "a native runtime solution that checks the skill and when needed ports it" between frameworks. Skills are markdown, but runtime behavior varies. No interoperability testing standard exists yet.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| OpenClaw | Agent platform | Mixed | Active Memory, local speech, broad model support, 50K+ stars | Memory bugs in production, update breakage |
| Hermes Agent | Agent platform | Positive | Self-improving skill loop, 3-layer memory, Orange Book community docs | Console-only for skill browsing, sparse official docs |
| Codex (OpenAI) | Coding agent | Mixed | WebRTC voice, MCP improvements, session resume | Pace criticized vs Claude Code, seen as catching up |
| Claude Code | Coding agent | Positive | Managed agents, vault system, strong harness design | Vault scoping too broad, no native scheduling |
| GBrain | Personal AI | Positive | 25 voice patterns, WebRTC, prompt compression (13K to 4.7K tokens) | Requires OpenClaw/Hermes, early-stage |
| Daytona | Sandbox | Positive | One-command agent spawn via OpenRouter CLI | -- |
| autoskills | Skill installer | Early | Auto-detects 50+ tech stacks, --dry-run flag | Prompt injection risk from untrusted skills |
| Agent Lightning | RL optimization | Early | Framework-agnostic, drop-in agl.emit(), MIT license | v0.3.0, unproven at scale |
| Gemma 4 31B | Open model | Positive | Autonomous agent work with ADK, open weights | Smaller than frontier models |
| Privy Agent CLI | Wallet infra | Early | Spin up, fund, manage agent wallets | Experimental surfaces |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| GBrain | @garrytan | Personal AI voice agent with WebRTC, Twilio, memory | Packaged AI limitations | OpenClaw/Hermes, WebRTC, PGLite | v0.8.0 | GitHub |
| Vibe-Trading | @ihtesham2005 | Open-source trading agent with 64 skills, 29 swarm presets | Fragmented quant tools | Python, FastAPI, React, DAG multi-agent | v0.1.4 | Tweet |
| SearchClaw | @ruc_ytz | Research agent with quality gates and harness engineering | Unreliable LLM research answers | FastAPI, litellm, Playwright | Released | GitHub |
| Charon | @suncostlabs | Orchestrator managing remote Claude, Codex, pi, Hermes instances | Multi-agent coordination | Custom orchestration | Pre-release | Tweet |
| Escroue | @Escapation | Trustless agent-to-agent task marketplace | Agent payment settlement | OpenServ SDK, on-chain | Hackathon winner | escroue.com |
| Harness Books | @tom_doerr / AgentWay | Two design guides for harness engineering | No written harness engineering theory | Markdown, hosted at agentway.dev | Published | GitHub |
| autoskills | @code_rams | Auto-detect stack and install matching agent skills | Manual skill installation overhead | npx CLI, skills.sh registry | Released | Tweet |
| Agent Experience Protocol | @itsashonaroll | Standardized security-first protocol for agent coordination | No interoperability standard for agents | Protocol spec | Early | Tweet |
Vibe-Trading is the most architecturally ambitious open-source project surfaced today. It uses a DAG-based multi-agent system where specialized agents collaborate, debate, and hand off between each other in real-time, covering technical analysis (Ichimoku, Elliott Wave, SMC), quant tools (Black-Scholes, Greeks, MVO), alt data (social sentiment, macro regime detection), and crypto (perp funding basis, liquidation heatmaps). Released just 10 days ago from HKU's Data Intelligence Lab.
SearchClaw from RUC-NLPIR applies harness engineering principles to web research: quality gate hooks reject answers lacking sufficient citations, a research plan tool decomposes complex queries into trackable sub-tasks, and two-phase context compaction keeps sessions within context limits. A concrete example of harness engineering moving from theory to application.
6. New and Notable¶
Meta-Harness: The Model Around the Model¶
The Meta-Harness paper (arXiv:2603.28052v1) demonstrated that an AI agent can automatically optimize the harness code around a frozen model and beat human harness engineers by 7.7 points while using 4x fewer tokens. The agent was given filesystem access to prior code, execution traces up to 10M tokens, and failure logs. Rather than gaming benchmarks, it discovered structured programs -- draft-verification for classification, lexical routing for math retrieval, adaptive context for coding. The implication: harness search may be the next frontier after model scaling.
Famou-Agent 2.0 Reclaims MLE-Bench SOTA¶
Baidu AI Cloud's Famou-Agent 2.0 retook the number-one position on MLE-Bench for ML engineering tasks, with upgrades in evolution strategies, long-horizon memory, and infrastructure. Already deployed by thousands of enterprises across manufacturing, finance, and transportation.
VAGEN: Teaching VLM Agents to Build World Models¶
Stanford's VAGEN framework uses reinforcement learning to teach vision-language model agents to build and maintain internal world models. By encouraging agents to estimate current state and predict future transitions, a 3B parameter model achieves SOTA across diverse visual tasks using PPO with bi-level advantage estimation.

Agent Lightning: RL for Any Agent Framework¶
@pvergadia announced that Microsoft open-sourced Agent Lightning, a framework-agnostic RL tool for agent improvement. Drop in agl.emit() or use the auto-tracer to capture every prompt, tool call, and reward as structured events. Supports LangChain, AutoGen, CrewAI, OpenAI SDK, and plain Python. Replaces manual prompt tweaking with a continuous learning loop.

Externalization Theory Gets Its Survey Paper¶
A 21-author survey paper (arXiv:2604.08224) frames agent infrastructure through cognitive externalization: memory externalizes state across time, skills externalize procedural expertise, protocols externalize interaction structure, and harness engineering serves as the unification layer. Traces a historical progression from weights to context to harness.
7. Where the Opportunities Are¶
[+++] Strong: Agent Skills Tooling and Distribution Skills are becoming the standard unit of knowledge packaging for AI agents, but the ecosystem lacks curation, security review, and cross-platform testing. The prompt injection risk raised by @safaa_9411 and the safety warnings on Swift Agent Skills both point to a gap: no trusted registry with verified, security-audited skills exists yet. Whoever builds the "npm for agent skills" with proper vetting captures the distribution layer.
[+++] Strong: Harness Engineering as a Service The Meta-Harness paper showed that automated harness optimization beats human experts. Most teams still hand-tune their agent scaffolding. A service that profiles agent harnesses, identifies bottlenecks, and suggests or auto-applies improvements would address a pain point confirmed by the 744 bookmarks on @elvissun's post about debugging harness methodology.
[++] Moderate: Agent Permission and Credential Governance @dani_avila7's vault scoping discovery and @nyk_builderz's "context governance as moat" thesis both point to the same gap: agents handling real credentials need fine-grained, auditable permission systems. Current implementations are workspace-scoped at best. Enterprise adoption depends on solving this.
[++] Moderate: Personal AI Voice Infrastructure Garry Tan's GBrain, OpenClaw's local speech, and ASUS's laptop-repurposing guide all converge on personal voice-first AI agents. The infrastructure is functional but rough. Packaging that compresses the setup from "read changelog and debug" to "install and talk" would unlock a consumer market.
[+] Emerging: Agent-to-Agent Marketplaces and Protocols Escroue (hackathon winner), Agent Experience Protocol, Privy Agent CLI, and multiple marketplace announcements suggest early demand for agents that can discover, negotiate with, and pay other agents. The infrastructure is fragmented and mostly crypto-native. A framework-agnostic coordination layer is the missing piece.
[+] Emerging: Multi-Device Agent Orchestration @Viewforge's cross-device scheduler and @suncostlabs's Charon orchestrator show demand for running agent fleets across machines. No dominant tool exists for scheduling, monitoring, and coordinating agents across heterogeneous devices.
8. Takeaways¶
-
Agent skills are the new standard for packaging AI knowledge. Supabase, Google engineers, Paul Hudson, and Anthropic all shipped skills this week, and autoskills automates their installation for 50+ tech stacks. (Supabase skills launch)
-
Harness engineering now has textbooks, survey papers, and empirical proof. The Meta-Harness paper showed 7.7-point gains over human experts from automated harness search alone, while two books and a 21-author survey provide the theoretical foundation. (Meta-Harness thread)
-
The code around the model produces larger performance swings than the model itself. A single harness change can produce 6x performance variation from a frozen model; the architecture -- not the model -- is the competitive edge. (elvissun harness methodology)
-
Personal AI voice agents crossed from demo to daily driver. Garry Tan's GBrain v0.8.0 ships 25 production voice patterns with radical prompt compression, while ASUS published official guides for repurposing hardware as personal AI. (GBrain v0.8.0)
-
Agent platform competition is exposing production readiness gaps. OpenClaw's Active Memory returns empty in real use; Codex's pace is criticized as lagging Claude Code; Hermes's self-learning loop gets praised but requires community-written documentation to be usable. (OpenClaw bug report)
-
Security and governance are the binding constraints on agent adoption. Workspace-scoped credential vaults, unvetted skill installation, and missing audit logs are concrete blockers cited by practitioners this week. (Vault scoping issue)
-
Context engineering has its own curriculum, primers, and failure taxonomy. From poisoning to distraction to compression artifacts, practitioners now treat context as a finite resource with known failure modes rather than a magic input field. (Context engineering primer)