Twitter AI 智能体 - 2026-04-11¶
1. 人们在讨论什么¶
1.1 Agent Skills 成为标准知识层 🡕¶
Agent skills 格式——为 AI 编程工具编码流程性知识的 markdown 文件——本周越过拐点。多个独立信号确认,它不再只是 Claude 专属的新奇事物,而是正在成为跨平台标准。
@xelebofficial 发布了一条误解澄清讨论串,指出 skills 不是“只是一段长提示词”(skills 会跨任务持久存在,而 prompts 会消失),不要求编程能力(它们是 markdown),并且不仅能用于 Claude,也能用于 GitHub Copilot、Cursor、Gemini CLI 和 Windsurf。最有挑衅性的说法是:“最高价值的 Skills 很少是关于代码。它们关乎你的团队如何写提案、如何组织报告、如何处理客户升级问题。”

@code_rams 宣布 autoskills,一个 CLI 工具(npx autoskills),可以识别项目的技术栈指纹,并从 skills.sh 的精选注册表自动安装匹配的 skill 文件,支持 50+ 技术。@safaa_9411 在回复中提出提示词注入风险:skills 在加载前需要安全审查。
@tom_doerr 分享了 Paul Hudson 的 Swift Agent Skills 仓库——一个面向 Swift 和 Apple 平台开发的精选开源 skills 集合,按框架(SwiftUI、SwiftData、Swift Concurrency 等)组织,并在显眼位置提示安装第三方 skills 前要先审查。

@dshukertjr 发布了官方 Supabase Agent Skills,把最新产品知识和文档打包成 skills——这标志着平台厂商开始把文档作为智能体可消费文件分发,而不是只提供人类可读页面。
@AlphaSignalAI 报道了一个 Google 工程师的开源 Agent Skills repo,编码了覆盖完整开发生命周期的 19 个工程技能和 7 个斜杠命令:先写规格再写代码、先测试再合并、先度量再优化。适用于 Claude Code、Cursor 或任何能读取 markdown 的 agent。
@DipanshuKu55175 整理了 Anthropic 的 13 门免费认证课程,包括 Introduction to Agent Skills 和 MCP Advanced Topics——这是一次实质性的教育推动,说明 Anthropic 正在投资生态增长。
1.2 Harness Engineering 结晶为一门学科 🡕¶
“模型周围的代码比模型本身更重要”这一想法,本周获得了实证支持,也出现了首批书籍篇幅的系统论述。
@elvissun 发布了当天最高分推文(464 个点赞、744 个收藏),描述 Codex 在获得正确 harness 后如何“一次性修好我们的 turbo cache”——一个智能体调试循环将构建时间从 3 分 22 秒降到 34 秒。附图展示了结构化三步方法:给智能体诊断视野(本地和云端工具)、放入假设-测试-结果反馈循环,并让它驱动流程,而工程师在 Telegram 上旁观。

@IntuitMachine 对 Meta-Harness 论文(arXiv:2603.28052v1)做了深度讨论串:自动 harness optimization 比人类专家高 7.7 分,用 token 少 4x,并能泛化到未见过的模型。核心发现是:仅 harness 改动就能让同一个 frozen model 的性能出现 6x 摆动。
@tom_doerr 分享了两本完整 harness engineering 书(托管在 harness-books.agentway.dev):一本 Claude Code 设计指南,一本 Claude Code 与 Codex 理念的比较研究。核心主张是:“Harness engineering 关乎约束结构如何组织执行。”

@RLanceMartin 讨论了 session-harness 解耦,提出一种架构:session 是大脑可以询问的 context 对象,关键洞察是“没有任何 context engineering 是不可逆的”。
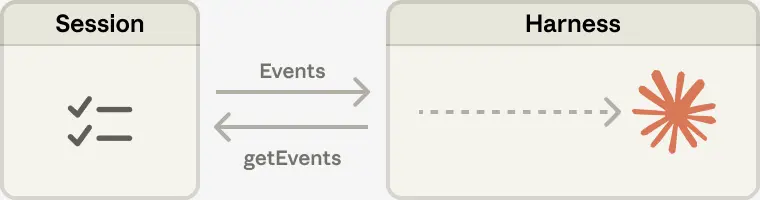
@ottamm_190 分享了一篇综述论文(“Externalization in LLM Agents,” arXiv:2604.08224),21 位作者提供了学术基础:memory 将状态外部化、skills 将流程性专业知识外部化、protocols 将交互结构外部化,而 harness engineering 是统一层。
@deararchitects 提供了反向观点:harness engineering “听起来是更快交付的明显下一步。但它也是团队现在必须拥有和维护的又一层基础设施。”
1.3 个人 AI 语音智能体浪潮 🡕¶
@garrytan(YC 总裁)用三条推文主导了个人 AI 讨论。GBrain v0.8.0 发布了语音到大脑能力,交付 25 个生产模式:WebRTC 默认启用、context-first prompts、dynamic VAD、激进提示词压缩(13K 到 4.7K tokens)、卡住状态看门狗、工具调用期间的思考音效,以及先认证再说话。Changelog 图显示的是生产级语音基础设施,而不是演示。

他还描述了自己在 Kona 泳池边用 iPhone 在 Telegram 上和语音智能体聊天来构建它,并说“我戒酒是为了更好地写代码。” 第三条推文传播了个人 AI 运动,一条回复确认该 setup “能运行所有东西,放在别处每月要花 200 美元。”
@ASUS 发布了一篇官方博客指南,介绍如何用 OpenClaw 把旧笔记本改造成专用 AI 智能体——一个主要硬件厂商正式背书个人 AI 智能体用例。
@cgtwts 展示了用 OpenClaw 本地运行 Gemma的三条命令(安装 Ollama、下载 Gemma、启动 OpenClaw),展示了完整私有 AI 智能体的最低门槛。
1.4 Agent Platform 竞争加剧 🡒¶
OpenClaw 与 Hermes Agent 的竞争成为焦点。@iamlukethedev 详细介绍了 OpenClaw v2026.4.10 release:Active Memory plugin(自动拉取偏好和历史对话)、原生 Codex provider,以及 macOS 本地语音。不过,@markkurajala2 报告 Active Memory 在真实使用中返回空结果,尽管手动 memory 搜索可以查到相关结果——这是一个生产就绪度缺口。
@steipete(OpenClaw 维护者)透露,OpenClaw 中 GPT 的两个实验模式:strict mode 会推动模型继续工作,codex app server 作为 harness——这条回复有 144 个点赞,说明社区对让非 Claude 模型成为可行 orchestrators 很感兴趣。
@bridgemindai 在 NVIDIA DGX Spark 上搭建 Hermes Agent,用于冷邮件外联,耗时不到 20 分钟,并称“OpenClaw 有热度,Hermes 的架构更对。” @cto_junior 称赞 Hermes 的自学习循环,认为它比手动方法更能捕捉经验,并自动启动新 skills。
@KanikaBK 分享了 “The Orange Book”,一本社区编写的 17 章 Hermes Agent 手册,涵盖三层 memory system、skill creation loop,以及与 Claude Code 和 OpenClaw 的比较——社区文档正在填补 Nous Research 留下的缺口。
@Codex_Changelog 宣布 Codex 0.119.0,包括 WebRTC voice default、实质性 MCP 改进(resource reads、elicitations、file uploads)和 remote/app-server workflows。@jlave_dev 的回复批评其节奏:“你们需要加快速度才能和 Claude Code 竞争。复制快捷键居然是最重要的新功能之一,这太离谱了。”
1.5 Context Engineering 进入主流 🡕¶
@drummatick 列出了成为前 1% AI 工程师所需的主题——context engineering、context compactness、agent harness、memory 和 subagent spawning 与传统 LLM skills 并列。这条推文获得 331 个收藏,说明对结构化学习路径的需求很高。一条回复补充了“evals and guardrails”。
@nyk_builderz 认为 下一个 AI 护城河是 context governance:“2026 年交付最快的团队都做三件事:像代码一样给 memory 做版本管理、在行动前给 agent outputs 打分、把 prompts 当作 interfaces,而不是 magic。” 他与 @l33tdawg 的扩展交流把 SAGE(BFT-consensus memory as data plane)与 LACP(Claude Code control plane)做对比,结论是二者互补而非竞争。
@i_amanchadha 在 contexteng.aman.ai 发布了完整 context engineering 入门指南,涵盖构建模块、retrieval/memory/compression、失效模式(context poisoning、distraction、confusion、clash)和生产启发式。
@aa22396584 凝练出共识:“人们关注‘哪个模型更好’,但真正的 skill gap 是:如何组织 agent memory、设计 permission boundaries,以及构建 composable SKILL.md files。工具会商品化,架构才是竞争优势。”
2. 令人困扰的问题¶
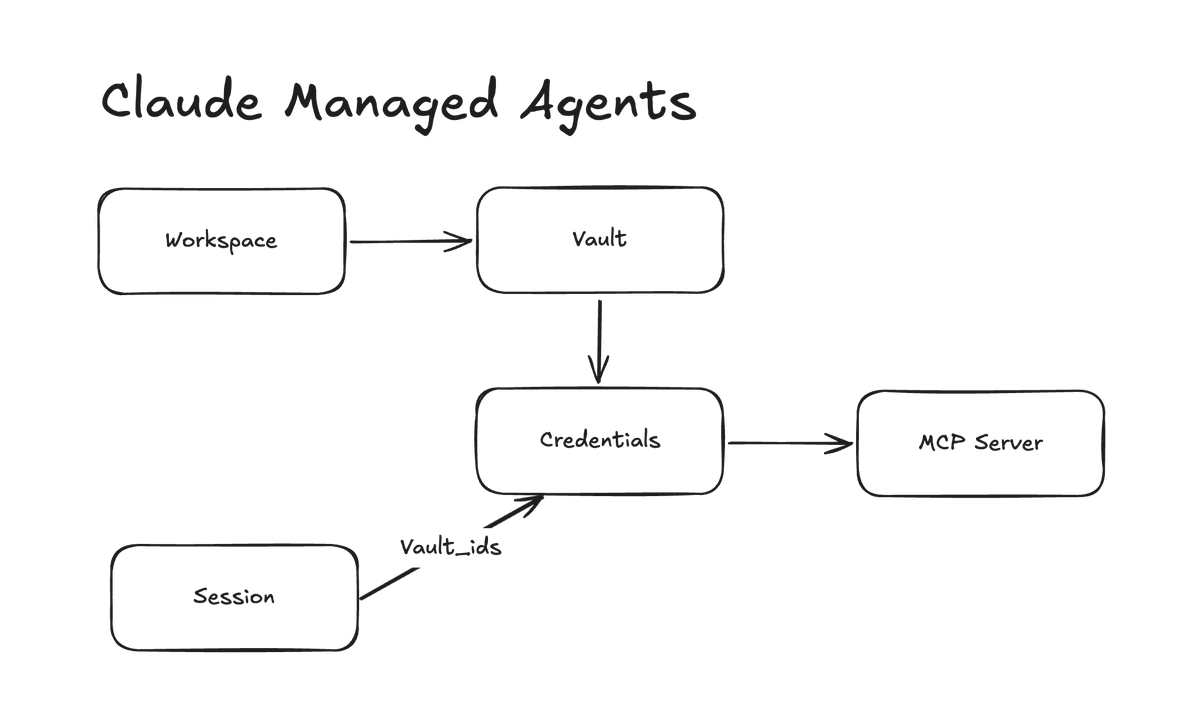
Managed Agents 中的 Vault 和 Permission Scoping(High)¶
@dani_avila7 发现 Claude Managed Agents vaults 是 workspace-scoped,意味着任何有 workspace access 的人都可以引用 vaults,并在自己的 sessions 中使用已存储的 OAuth credentials。架构图让问题很清楚:sessions 会 attach vault_ids,但 access control 只存在于 workspace level。请求的修复包括按 agent 划分的 vault permissions、credential audit logs 和原生定时 agents。
Active Memory 在生产中失效(Medium)¶
@markkurajala2 报告,OpenClaw 新的 Active Memory plugin “在真实使用中一直返回空结果,尽管手动 memory 搜索能返回相关结果。” 另一名用户报告更新后被卡在 terminal 中调试。一个重大 release 的头号功能无法在生产中稳定工作,已经成为反复出现的模式。
Agent Tooling 速度落后竞争(Medium)¶
@jlave_dev 批评 Codex:“你们需要加快速度才能和 Claude Code 竞争。复制快捷键居然是最重要的新功能之一,这太离谱了。” 这种挫败感反映了更广泛的情绪:OpenAI 的 agent tooling 在 developer experience 上落后于 Anthropic。
基础设施指标错位(Low)¶
@braelyn_ai 指出,sandbox vendors 在 initialization time 上竞争(“快 0.02s”),而使用 sandbox 的 agent 会运行 15 分钟。真正瓶颈是 agent execution time,而不是 infrastructure startup——厂商优化的是 benchmarks,不是用户实际感知性能。
智能体 Exploit Demos 误导泛化能力(Low)¶
@dbreunig 认为,发现漏洞利用是搜索问题(在墙上找到一道裂缝),而构建软件是建造问题(处理边界情况,维持一致性)。智能体漏洞利用演示有内置验证循环,非常适合营销,但不能很好说明更广泛能力。未回答的问题是:Anthropic 为每个漏洞利用花了多少钱?
3. 人们期望的功能¶
细粒度智能体权限系统¶
多位从业者描述了对按智能体(而不是按工作区)限定凭证范围、运行时权限强制执行(防止声明能力和实际能力之间漂移),以及显示谁在何时使用了什么的凭证审计轨迹的需求。@dani_avila7 和 @0xAgix 都独立提出了类似需求。
统一的 Agent Engineering 学习路径¶
@drummatick 承认,要成为顶级 AI engineer 所需的 skills “几乎没有一个单一资源能完整覆盖”,并承诺自己写一个。@KanikaBK 指出 Nous Research “丢下工具,基本让你自己摸索”。社区正在自行创建文档——Orange Book、harness books、context engineering primer——但仍没有 canonical curriculum。
智能体原生调度和 Cron¶
@dani_avila7 特别指出 Claude Managed Agents 缺少原生定时智能体,并说“不应该需要 cron job 这种绕路方案。” @Viewforge 构建了一个多设备调度器来填补这个缺口,说明需求强到足以推动独立工具。
Cross-Framework Skill Portability Guarantees¶
虽然 @xelebofficial 声称 skills 可跨多个平台工作,但 @felipedeleon_ 指出需要“一个原生 runtime solution,在需要时检查 skill 并移植它”。Skills 是 markdown,但运行时行为各异。尚无互操作性测试标准。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| OpenClaw | 智能体平台 | Mixed | Active Memory、本地 speech、广泛 model support、50K+ stars | 生产 memory bugs、update breakage |
| Hermes Agent | 智能体平台 | Positive | Self-improving skill loop、3-layer memory、Orange Book community docs | Skill browsing 仅 console;official docs 稀疏 |
| Codex (OpenAI) | 编程智能体 | Mixed | WebRTC voice、MCP improvements、session resume | 速度被批评落后 Claude Code,被视为追赶中 |
| Claude Code | 编程智能体 | Positive | Managed agents、vault system、强 harness design | Vault scoping 过宽、无 native scheduling |
| GBrain | Personal AI | Positive | 25 voice patterns、WebRTC、prompt compression(13K 到 4.7K tokens) | 需要 OpenClaw/Hermes,早期阶段 |
| Daytona | Sandbox | Positive | 通过 OpenRouter CLI 一条命令 spawn agent | -- |
| autoskills | Skill installer | Early | 自动检测 50+ tech stacks、--dry-run flag | 来自 untrusted skills 的 prompt injection risk |
| Agent Lightning | RL optimization | Early | Framework-agnostic、drop-in agl.emit()、MIT license | v0.3.0,规模化未验证 |
| Gemma 4 31B | Open model | Positive | 用 ADK 做 autonomous agent work,open weights | 小于 frontier models |
| Privy Agent CLI | Wallet infra | Early | Spin up、fund、manage agent wallets | Experimental surfaces |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| GBrain | @garrytan | 带 WebRTC、Twilio 和 memory 的 personal AI voice agent | Packaged AI limitations | OpenClaw/Hermes, WebRTC, PGLite | v0.8.0 | GitHub |
| Vibe-Trading | @ihtesham2005 | 64 skills、29 swarm presets 的开源 trading agent | Quant tools 碎片化 | Python, FastAPI, React, DAG multi-agent | v0.1.4 | Tweet |
| SearchClaw | @ruc_ytz | 带 quality gates 和 harness engineering 的 research agent | LLM research answers 不可靠 | FastAPI, litellm, Playwright | Released | GitHub |
| Charon | @suncostlabs | 管理 remote Claude、Codex、pi、Hermes instances 的 orchestrator | Multi-agent coordination | Custom orchestration | Pre-release | Tweet |
| Escroue | @Escapation | Trustless agent-to-agent task marketplace | Agent payment settlement | OpenServ SDK, on-chain | Hackathon winner | escroue.com |
| Harness Books | @tom_doerr / AgentWay | 两本 harness engineering design guides | 缺少 written harness engineering theory | Markdown, hosted at agentway.dev | Published | GitHub |
| autoskills | @code_rams | 自动检测 stack 并安装匹配 agent skills | 手动 skill installation overhead | npx CLI, skills.sh registry | Released | Tweet |
| Agent Experience Protocol | @itsashonaroll | Security-first agent coordination standard | 缺少 agent interoperability standard | Protocol spec | Early | Tweet |
Vibe-Trading 是今天出现的开源项目中架构野心最大的一个。它使用基于 DAG 的多智能体系统,专门智能体会实时协作、辩论和交接,覆盖技术分析(Ichimoku、Elliott Wave、SMC)、量化工具(Black-Scholes、Greeks、MVO)、另类数据(social sentiment、macro regime detection)和 crypto(perp funding basis、liquidation heatmaps)。该项目来自 HKU Data Intelligence Lab,发布仅 10 天。
SearchClaw 来自 RUC-NLPIR,将 harness engineering principles 应用于 web research:quality gate hooks 会拒绝缺少足够 citations 的答案,research plan tool 会把复杂 queries 分解成可跟踪 sub-tasks,两阶段 context compaction 让 sessions 保持在 context limits 内。这是 harness engineering 从理论走向应用的具体案例。
6. 新动态与亮点¶
Meta-Harness:模型周围的模型¶
Meta-Harness 论文(arXiv:2603.28052v1)证明,AI agent 可以自动优化 frozen model 周围的 harness code,并以 7.7 分优势超过人类 harness engineers,同时 token 用量少 4x。该 agent 拥有 prior code、最高 10M tokens 的 execution traces 和 failure logs 的 filesystem access。它不是在 gaming benchmarks,而是发现了 structured programs——classification 中的 draft-verification、math retrieval 中的 lexical routing、coding 中的 adaptive context。含义是:harness search 可能是 model scaling 之后的下一个 frontier。
Famou-Agent 2.0 重夺 MLE-Bench SOTA¶
Baidu AI Cloud 的 Famou-Agent 2.0 在 ML engineering tasks 的 MLE-Bench 上重新夺回第一名,升级包括 evolution strategies、long-horizon memory 和 infrastructure。它已经部署到制造、金融、交通等行业的数千家企业。
VAGEN:教 VLM Agents 构建 World Models¶
Stanford 的 VAGEN framework 使用 reinforcement learning 教 vision-language model agents 构建并维护 internal world models。通过鼓励 agents 估计 current state 并预测 future transitions,一个 3B parameter model 使用 PPO with bi-level advantage estimation,在多类视觉任务上达到 SOTA。

Agent Lightning:适用于任何 Agent Framework 的 RL¶
@pvergadia 宣布 Microsoft open-sourced Agent Lightning,这是一个 framework-agnostic RL tool,用于提升 agents。插入 agl.emit(),或使用 auto-tracer 把每个 prompt、tool call 和 reward 捕捉为 structured events。支持 LangChain、AutoGen、CrewAI、OpenAI SDK 和 plain Python。它把手动调 prompt 替换成 continuous learning loop。

外部化理论获得综述论文¶
一篇 21 位作者合著的综述论文(arXiv:2604.08224)用认知外部化来框定智能体基础设施:记忆把跨时间状态外部化,技能把流程性专业知识外部化,协议把交互结构外部化,而运行框架工程则作为统一层。它梳理了从权重到上下文再到运行框架的历史进展。
7. 机会在哪里¶
[+++] 强信号:Agent Skills Tooling and Distribution Skills 正在成为 AI agents 的标准知识包装单元,但生态缺少策展、安全审查和跨平台测试。@safaa_9411 提出的提示词注入风险和 Swift Agent Skills 上的安全警告都指向同一个缺口:目前还没有一个具备 verified、security-audited skills 的可信 registry。谁能用合适的审核机制建出“agent skills 的 npm”,谁就能抓住分发层。
[+++] 强信号:Harness Engineering as a Service Meta-Harness 论文显示,automated harness optimization 超过了人类专家。多数团队仍在手动调 agent scaffolding。一个能 profile agent harnesses、识别瓶颈,并建议或自动应用改进的服务,将解决 @elvissun 关于 debugging harness methodology 的帖子获得 744 个收藏所证明的痛点。
[++] 中等信号:Agent Permission and Credential Governance @dani_avila7 的 vault scoping 发现和 @nyk_builderz 的“context governance as moat”论点,都指向同一个缺口:处理真实 credentials 的 agents 需要细粒度、可审计的 permission systems。当前实现最多只是 workspace-scoped。企业采用取决于这个问题的解决。
[++] 中等信号:Personal AI Voice Infrastructure Garry Tan 的 GBrain、OpenClaw 的本地语音和 ASUS 的笔记本改造指南都指向以语音优先的个人 AI 智能体。基础设施可以用,但仍粗糙。把 setup 从“读 changelog 然后 debug”压缩到“安装后开聊”的 packaging,可以打开 consumer market。
[+] 新兴信号:Agent-to-Agent Marketplaces and Protocols Escroue(hackathon winner)、Agent Experience Protocol、Privy Agent CLI 和多个 marketplace announcements 表明,agents 发现、协商并支付其他 agents 的需求已经出现。基础设施碎片化,且多为 crypto-native。缺失的是 framework-agnostic coordination layer。
[+] 新兴信号:Multi-Device Agent Orchestration @Viewforge 的 cross-device scheduler 和 @suncostlabs 的 Charon orchestrator 显示,跨机器运行 agent fleets 有真实需求。尚无主导工具负责在 heterogeneous devices 上 scheduling、monitoring 和 coordinating agents。
8. 要点总结¶
-
Agent skills 是新的 AI 知识包装标准。 Supabase、Google engineers、Paul Hudson 和 Anthropic 本周都发布了 skills,autoskills 还为 50+ tech stacks 自动安装它们。(Supabase skills launch)
-
Harness engineering 现在已有 textbooks、survey papers 和 empirical proof。 Meta-Harness 论文显示,单靠 automated harness search 就能比人类专家高 7.7 分;两本书和一篇 21-author survey 则提供了理论基础。(Meta-Harness thread)
-
模型周围的代码带来的性能波动,比模型本身更大。 一个 harness change 可以让 frozen model 出现 6x 性能差异;架构——不是模型——才是竞争优势。(elvissun harness methodology)
-
个人 AI 语音智能体从 demo 进入 daily driver。 Garry Tan 的 GBrain v0.8.0 交付 25 个 production voice patterns,包括 prompt compression、stuck watchdogs 和 dynamic noise suppression;ASUS 则发布了官方指南,用旧硬件改造 personal AI。(GBrain v0.8.0)
-
Agent platform 竞争正在暴露 production readiness gaps。 OpenClaw 的 Active Memory 在真实使用中返回空结果;Codex 的节奏被批评落后 Claude Code;Hermes 的 self-learning loop 获赞,但需要社区写文档才可用。(OpenClaw bug report)
-
安全和治理是 agent adoption 的约束条件。 Workspace-scoped credential vaults、未经审查的 skill installation 和缺失 audit logs,都是本周从业者指出的具体 blockers。(Vault scoping issue)
-
Context engineering 已经有自己的 curriculum、primers 和 failure taxonomy。 从 poisoning 到 distraction 再到 compression artifacts,从业者现在把 context 当作有限资源,且有已知 failure modes,而不是一个神奇输入框。(Context engineering primer)