Twitter AI Agent - 2026-04-12¶
1. What People Are Talking About¶
1.1 Skills and Harness Engineering Eclipse Prompt Engineering 🡕¶
The dominant conversation today is the emergence of "harness engineering" and "skills engineering" as distinct disciplines, displacing prompt engineering as the core competency for working with AI agents. @IntuitMachine published an infographic mapping the AI engineer taxonomy: deep learning research corresponds to chip design, harness engineering to backend, and skills engineering to frontend. This framing is gaining traction.
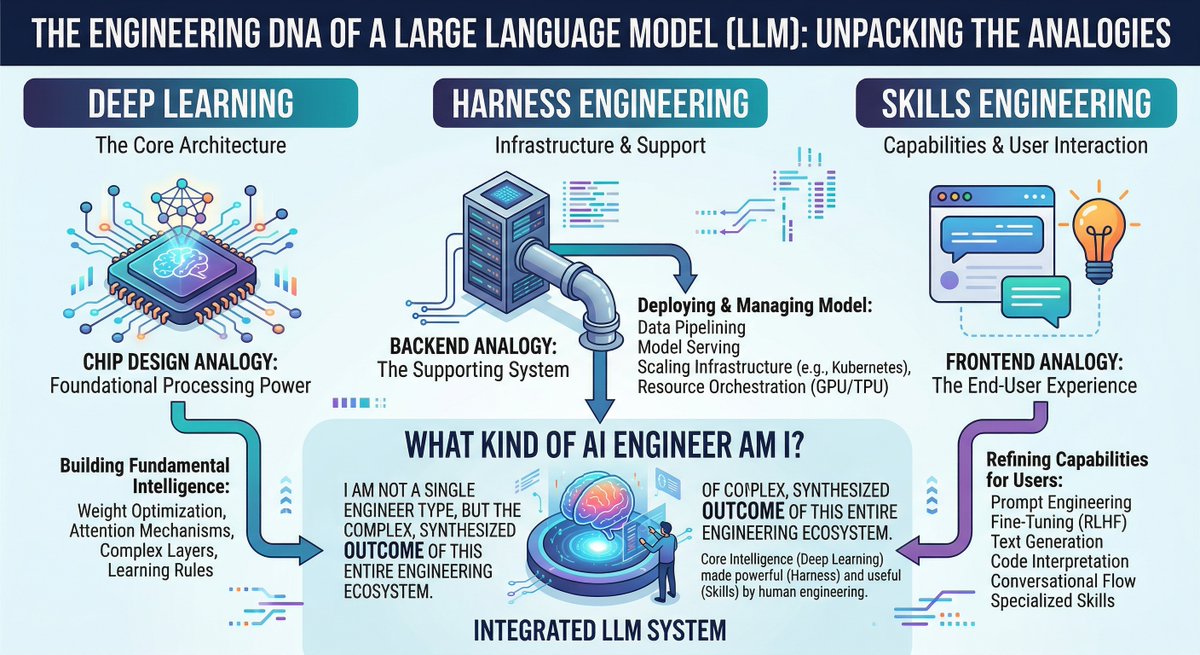
@Ed_Forson reported that harness engineering was "possibly the biggest topic at the AI Engineer conference I just attended," linking to a HumanLayer blog post that defines the formula: coding agent = AI model(s) + harness. The post argues that "every time an agent makes a mistake, you engineer a solution so it never makes that mistake again" -- treating agent failures as configuration problems rather than model limitations. @0x_Lotion put it more bluntly: "prompt engineering = dead. context engineering = long live the new king."
@addyosmani of Google argued that "memory makes your agent smarter over time. The agent harness is key to the memory layer. You can't bolt one onto the other after the fact." This positions the harness not merely as a configuration surface but as the architectural foundation for agent memory -- every decision about context, compaction, and skill surfacing is inherently a memory decision.
@tom_doerr shared two book-format design guides for harness engineering covering Claude Code and Codex, with architecture diagrams spanning control plane, loop, recovery, permissions, and verification.

@LarryGraham01 extended the argument to vendor lock-in: "if the harness is closed, you don't really own the agent. And it's even worse when memory is also closed." The more useful an agent becomes, the stronger the lock-in grows -- accumulated behavior and memory become the moat, not the model.
1.2 The Agent Skills Ecosystem Matures 🡕¶
Agent skills -- reusable instruction packages that encode domain-specific workflows -- are consolidating into a recognizable ecosystem. Multiple skill libraries, distribution channels, and skill management tools shipped today.
@tom_doerr shared the VoltAgent/awesome-agent-skills repository, a hand-curated collection of 1000+ official skills from Anthropic, Google Labs, Vercel, Stripe, Cloudflare, Netlify, Trail of Bits, Sentry, Expo, Hugging Face, Figma, Microsoft, and others. Compatible with Claude Code, Codex, Gemini CLI, Cursor, and more.
@DataChaz provided a detailed breakdown of @addyosmani's agent-skills package: 19 engineering skills and 7 slash commands (/spec, /plan, /build, /test, /review, /code-simplify, /ship) encoding Google-tier practices like Shift Left, Chesterton's Fence, and Hyrum's Law. Installable via npx skills add addyosmani/agent-skills.
@nrqa__ explained Anthropic's official skills system: folders of instructions Claude loads dynamically. Skills for Word, PDF, PowerPoint, Excel, web app testing, and MCP server generation are already available. A reply from @MrZivtins tempered expectations: "if you're just doing varied dev work, the overhead of maintaining skill files isn't worth it right now. Your CLAUDE.md already does most of it."
@shabnam_774 shared a library of 900+ cross-platform skills compatible with Claude, Copilot, Gemini, and Cursor. @ctatedev shipped runtime-served skills for agent-browser to solve the staleness problem of cached skills -- evals show agents pick and use browser skills more correctly with the new approach.
1.3 Hermes Agent Dominates Open-Source Agent Conversation 🡕¶
Hermes Agent from Nous Research is the most discussed open-source agent system today, appearing in over a dozen tweets spanning feature updates, user reports, and community enthusiasm.
@Teknium (Nous Research) reported that skill loading improved by 20% after Hermes Agent benchmarked and optimized its own skill-selection prompts -- a concrete demonstration of the self-improvement loop. Separately, he noted that Hermes Agent autonomously added a skills hub to its own documentation site.
@Sumanth_077 provided a comprehensive overview: FTS5 session search with LLM summarization, Honcho dialectic user modeling, multi-platform support (Telegram, Discord, Slack, WhatsApp, Signal, CLI), built-in cron scheduler, subagent spawning for parallel work, and support for 200+ models via OpenRouter.
@outsource_ released Hermes-Workspace with a Task Board/Kanban page, agent artifacts inspector, crew monitoring, multi-language support, and a skills hub with search and install -- syncing 561 upstream commits. @thegreatola shared day-3 results of running Hermes Agent for automated trading with GLM-5.1, spending $60 in API credits, and reported it significantly outperforms Claude Code for long-running tasks.
1.4 Claude Code Quality Debate Intensifies 🡒¶
@Hesamation published a detailed forensic analysis of Claude Code system prompt changes that may explain user complaints about deterioration. Four changes identified: (1) new prompts lean harder into forking/subagents, shifting Opus toward orchestration rather than direct problem-solving -- "my top suspect"; (2) more explicit memory retrieval prompts that could cause overfitting on priors; (3) a "no comments in code" default added three days ago; (4) an experimental verification specialist agent prompted with "You are Claude, and you are bad at verification."

A reply from @DualAcies offered a business interpretation: "the 'no comments' default reduces token output = lower API cost per session. Pre-IPO margin move, not a capability decision." Another from @tr4m0ryp connected the issue to infrastructure bugs from August-September and noted that "if the main agent is reduced to a router, you lose the raw capability that made Claude Code superior to Codex for complex refactoring."
1.5 Voice Agents Cross the Production Threshold 🡕¶
@garrytan shipped GBrain v0.8.0 with 25 production voice patterns, WebRTC voice endpoint (works in browser with just an OpenAI key), Twilio integration, and PGLite local storage. The changelog image reveals substantial depth: pre-computed engagement bids, context-first prompts, dynamic noise suppression, a stuck watchdog, thinking sounds during tool calls, and radical prompt compression from 13K to 4.7K tokens.

In a follow-up, he declared Gemini Live 2.5 "the best" voice agent model, citing speed, intelligence, and context window size. Replies identified context window -- not latency -- as the real differentiator for voice agents. @etnshow covered ElevenLabs' Voice Engine: wrap any existing chat agent to make it a voice agent with one command -- "turn a gov chat agent into a phone line anyone can ring."
2. What Frustrates People¶
Token Budget vs Skill Loading (Severity: High)¶
@seelffff open-sourced 38 agents with 156 skills but included a blunt warning: "loading 38 agents and 156 skills into your context at once will burn your usage limits in minutes. Pick the 3-4 you actually need." This is the fundamental tension: comprehensive skill libraries exist, but context windows and token budgets make using them impractical without intelligent skill selection. @KingBootoshi wrote at length about the combinatorial problem -- "the combination of words and structure we can use in a prompt is INFINITE" -- and lamented that no skill library sorts by quality, only popularity.
Agent Session Amnesia (Severity: High)¶
@heygurisingh articulated the problem: "Your AI coding agent has amnesia. Every new session = re-explaining your architecture, your constraints, your decisions, the bug you fixed last Tuesday." He open-sourced Mind, an MCP-backed persistent memory layer with 4-tier temperature model (hot/warm/cold/frozen), but the underlying complaint is that agent platforms treat memory as optional rather than core infrastructure.
Subagent Orchestration Degrading Quality (Severity: Medium)¶
Multiple users report that Claude Code's shift toward subagent orchestration is making the primary agent feel "more fragmented, more delegation-happy, or less globally coherent," as @Hesamation's analysis put it. @tr4m0ryp argued: "native orchestration adds failure points. If the main agent is reduced to a router, you lose the raw capability." @thegreatola reported that a Claude Code task ran for 15+ hours without success, burning usage every 4 hours.
MCP Abstraction Tax (Severity: Medium)¶
@MelkeyDev highlighted an article arguing that "every protocol layer between an agent and an API is a tax on fidelity." The trade-off between MCP's standardization and the overhead it introduces is becoming a real concern for builders optimizing agent reliability.
3. What People Wish Existed¶
Hybrid Model Routing for Coding Agents¶
@gajesh asked: "how has no one built a hybrid model coding agent? GPT 5.4 instructs and checks the work. MiniMax/Sonnet executes it." Factory AI's mission mode was cited as the closest approximation, but its co-founder acknowledged it "feels like overkill for small yet important tasks." Claude Code does not natively support routing different task types to different models.
Cross-Tool Agent Memory¶
@heygurisingh shipped Mind to address exactly this: one persistent memory shared across Claude Code, Cursor, Codex, OpenCode, Gemini CLI, and Windsurf. The checkpoint system enables cross-tool, cross-session continuity. This solves the problem but as an aftermarket add-on -- the gap is that no major agent platform provides this natively.
Skill Quality Ranking¶
@KingBootoshi noted: "none of them actually sort by how good it does something. Just 'popularity'." Skills range from "dog-shit to godtier" and there is no mechanism for surfacing the highest-quality skills for a given task. The Swarms Marketplace's transparent scoring with numerical scores and written feedback is the closest attempt.
Open Harness with Portable Memory¶
@LarryGraham01 articulated the need: "models can be swapped. Your harness and memory should be yours." Users want the accumulated knowledge, preferences, and behavior of their agents to be portable across platforms -- not locked into any single provider.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude Code | Coding agent | Mixed | Deep reasoning, subagent orchestration, large ecosystem | Quality complaints, token burn, subagent fragmentation |
| Hermes Agent | Open-source agent | Positive | Self-improving skills, multi-platform, persistent memory | Requires self-hosting, complex setup |
| OpenAI Codex | Coding agent | Positive | 3M weekly users, fast iteration, strong for reference-heavy work | Hasn't had its "Claude Code moment" yet |
| GBrain | Voice agent harness | Positive | 25 production voice patterns, WebRTC, open source | Early-stage, complex configuration |
| Agent Skills (Addy Osmani) | Skill library | Positive | Google-tier engineering practices, 7 lifecycle commands | Opinionated workflow may not fit all teams |
| VoltAgent awesome-agent-skills | Skill directory | Positive | 1000+ official skills from major vendors | Curation quality varies |
| vLLM | Model serving | Positive | Day-0 support for new models, production-ready | Requires GPU infrastructure |
| Swarms Framework | Multi-agent framework | Positive | Marketplace integration, tool system, production deployment | Ecosystem still early |
| Agent CI | Local CI runner | Positive | Run GitHub Actions locally for agents | New, limited ecosystem |
| MCP (Model Context Protocol) | Agent protocol | Mixed | Standardized tool integration, multi-vendor support | Abstraction overhead, fidelity tax |
| FileGram | Agent memory | Early | File-system behavioral traces for personalization | Research-stage |
| Mind (MCP server) | Cross-tool memory | Early | SQLite-backed, 4-tier memory, FTS5 search | Community project, not battle-tested |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| GBrain v0.8.0 | @garrytan | Voice agent harness with WebRTC and Twilio | Production voice agent deployment | WebRTC, Twilio, PGLite, OpenAI | Production | Tweet |
| SkillClaw | DreamX Team | Collective skill evolution across users | Skills remain static after deployment | Agentic evolver, shared repository | Research | Paper |
| Hermes-Workspace | @outsource_ | Task board, agent monitoring, skills hub for Hermes | Agent orchestration visibility | Hermes Agent, Docker | Beta | Tweet |
| Agent CI | @appfactory | Run GitHub Actions locally for coding agents | Agents can't test against CI pipelines | GitHub Actions runner | Beta | Tweet |
| Mind | @heygurisingh | Cross-tool persistent agent memory | Session amnesia across agent platforms | SQLite, MCP, FTS5 | Alpha | Tweet |
| three-man-team | @ihtesham2005 | 3-agent dev team (Architect/Builder/Reviewer) | Agent drift and undisciplined output | Claude Code, CLAUDE.md | Released | Tweet |
| PENCILCLAW | @dungeonclaw | C++ coding agent harness for local Ollama | Agent harness outside Python/JS | C++, Ollama | Alpha | Tweet |
| Ascii | @luaroncrew | Cross-platform skill interop (Claude Code + Codex) | Skill format lock-in | GitHub integration, LLM-agnostic | Beta | Tweet |
| Supaterm | @khoiracle | Terminal with agent integration and sidebar | Multi-agent visibility in terminal | macOS, libghostty | Beta | Tweet |
| ASM | @luongnv89 | Unified CLI for agent skill management | Fragmented skill installation | CLI | Alpha | GitHub |
| nominal.dev | @boristane | Remote coding agent per connected repo | Remote agent development environments | Custom harness | Beta | Tweet |
| FileGram | @liuziwei7 | Agent personalization from file-system traces | Memory based on conversation is shallow | File-system analysis | Research | GitHub |
GBrain v0.8.0 shipped 25 production voice patterns covering identity separation, prompt compression (13K to 4.7K tokens), proactive advisor mode, stuck watchdog, and thinking sounds during tool calls. WebRTC works in a browser tab with just an OpenAI key; Twilio phone number is optional. Remote MCP was simplified from Supabase Edge Functions to self-hosted + ngrok. This represents the most production-hardened open-source voice agent harness available.
SkillClaw (arXiv:2604.08377) proposes collective skill evolution where an autonomous evolver aggregates user trajectories, identifies recurring behavioral patterns, and refines the shared skill set. In an 8-user, 6-day trial, the system significantly improved Qwen3-Max performance on WildClawBench. This is the first research system to treat cross-user experience as the primary signal for skill improvement.
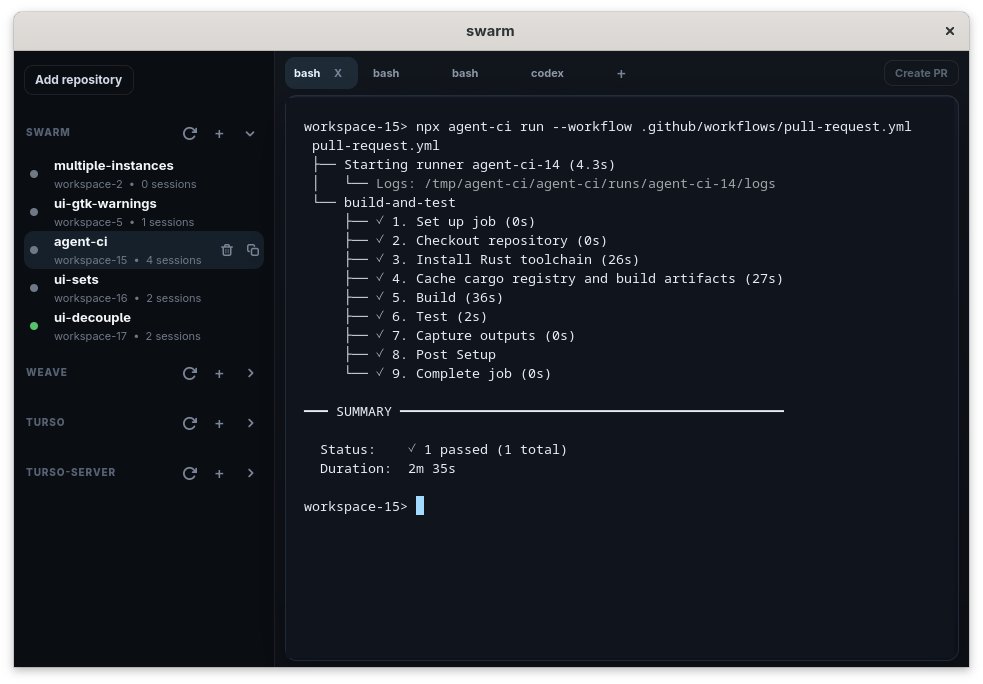
Agent CI enables coding agents to run full GitHub Actions workflows locally. The screenshot shows a complete CI pipeline -- checkout, Rust toolchain install, cargo cache, build, test -- completing in 2 minutes 35 seconds alongside multiple agent workspaces with a Codex tab. This closes the gap between agent-authored code and CI validation.
6. New and Notable¶
Self-Improving Agents Show Concrete Results¶
Hermes Agent's self-improvement loop produced a measurable 20% improvement in skill-loading accuracy, as reported by @Teknium. The agent benchmarked its own skill-selection prompts, identified weaknesses, and rewrote them. Separately, MiniMax M2.7 helped build its own RL harness and drive its own training loop, and a Bittensor subnet agent built and beat a SOTA 4B-parameter model in two weeks, then wrote its own paper. The recursive self-improvement pattern is moving from theoretical to operational.
Cloudflare Agents Week Signals Infrastructure Maturity¶
@Cloudflare dedicated an entire week to agent infrastructure announcements spanning compute, connectivity, security, identity, economics, and developer experience. Combined with @addyosmani's DevTools MCP launch and AWS shipping stateful MCP on Bedrock AgentCore, the major infrastructure providers are now building agent-native platform layers. The reply to Cloudflare that resonated most: "the hard part isn't tool-calling, it's trust boundaries."
Neurosymbolic AI Gets Vindication¶
@OwenGregorian shared Gary Marcus's analysis of Claude Code's leaked source code, revealing a 3,167-line kernel (print.ts) using classical symbolic pattern matching with 486 branch points and 12 levels of nesting inside a deterministic loop. Marcus argues this proves "the biggest advance since the LLM is neurosymbolic" -- Anthropic built reliability through classical AI techniques, not pure scaling.
Enterprise Agent Skill Marketplaces Emerge¶
@trillhause_ described how Ramp enables 99% daily AI usage by giving every employee a configured AI workspace with 350+ reusable skills built by colleagues. Worklayer provides the SSO app vault for agents, enabling internal company skill marketplaces where "employees can codify their knowledge and publish them as agent skills." This is the enterprise adoption pattern: bottom-up skill creation with centralized distribution.
7. Where the Opportunities Are¶
[+++] Strong: Skill Quality and Discovery Infrastructure. Over 1000 skills exist across multiple repositories, but no system reliably ranks them by effectiveness. @KingBootoshi and others note the range from "dog-shit to godtier" with no quality signal beyond popularity. A skill evaluation, testing, and ranking layer -- something like what the Swarms Marketplace attempts with transparent scoring -- would be immediately valuable. The skill ecosystem is big enough to need curation.
[+++] Strong: Cross-Platform Agent Memory. Every major agent tool (Claude Code, Codex, Cursor, Gemini CLI) maintains its own siloed memory. Mind is the only cross-tool solution, and it is a community project. The first platform to offer portable, persistent agent memory that works across tools will capture significant developer loyalty. The harness-memory fusion insight means this must be architecturally integrated, not bolted on.
[++] Moderate: Hybrid Model Routing for Agents. The demand for a system where a frontier model instructs and verifies while a faster/cheaper model executes is clear but unmet. Claude Code and Codex are single-model systems. Factory AI is the nearest approximation but is perceived as overkill for small tasks. A lightweight routing layer that matches task complexity to model capability would address a real workflow gap.
[++] Moderate: Agent-Native Developer Tooling. Agent CI (local GitHub Actions), Supaterm (terminal with agent sidebar), and Chrome DevTools MCP all point to the same opportunity: rebuilding developer tools with agents as first-class users. Debugging, testing, profiling, and deployment tools designed for agent consumption rather than human visual inspection.
[+] Emerging: Elixir/OTP for Agent Orchestration. @svs claimed Elixir and LiveView will "win the agent orchestration" due to OTP's actor model and fault tolerance. The majority of agent orchestration is built in Python and TypeScript; a compelling Elixir-based agent framework could capture a niche of reliability-focused builders.
[+] Emerging: Agent Behavioral Personalization. FileGram grounds agent memory in file-system behavioral traces rather than conversation history. "Memory isn't what users say. It's what they do." This behavioral approach to personalization is largely unexplored commercially and could differentiate agent products that feel genuinely personal.
8. Takeaways¶
-
Harness engineering has become the dominant skill for AI agent practitioners, eclipsing prompt engineering. Conference talks, blog posts, and multiple viral threads agree: model capability is necessary but insufficient -- the harness configuration determines agent quality. (source)
-
The agent skills ecosystem has reached critical mass, with 1000+ curated skills from major vendors, but lacks quality ranking. Anthropic, Google, Vercel, Stripe, Cloudflare, and dozens of other companies now publish official skills, yet no system reliably distinguishes effective skills from mediocre ones. (source)
-
Self-improving agents are producing measurable results. Hermes Agent improved its own skill-loading by 20% through self-benchmarking, MiniMax M2.7 drove its own training loop, and a Bittensor agent built and beat a SOTA model in two weeks. The recursive improvement loop is operational, not theoretical. (source)
-
Claude Code's shift toward subagent orchestration is generating quality complaints that may be driven by prompt changes rather than model degradation. Forensic analysis of system prompt changes identified fork/subagent promotion, a "no comments" default, and an experimental verification agent as potential causes -- some possibly motivated by cost reduction. (source)
-
Voice agents crossed from novelty to production infrastructure. GBrain v0.8.0 ships 25 battle-tested voice patterns including prompt compression, stuck watchdogs, and dynamic noise suppression. Gemini Live 2.5 was declared the best voice model by a prominent builder, with context window size identified as the key differentiator. (source)
-
Major infrastructure providers are now building agent-native platform layers. Cloudflare dedicated an entire week to agent infrastructure, Google shipped DevTools as MCP skills, and AWS launched stateful MCP on Bedrock AgentCore. The agent infrastructure stack is being built by the same companies that built the cloud infrastructure stack. (source)
-
Open harnesses with portable memory are emerging as the strategic imperative. As agents accumulate valuable memory and behavior patterns, lock-in to proprietary harnesses becomes increasingly costly. The first platform to offer genuinely portable agent memory across tools will capture outsized developer loyalty. (source)