Twitter AI 智能体 - 2026-04-12¶
1. 人们在讨论什么¶
1.1 技能与运行框架工程压过提示工程 🡕¶
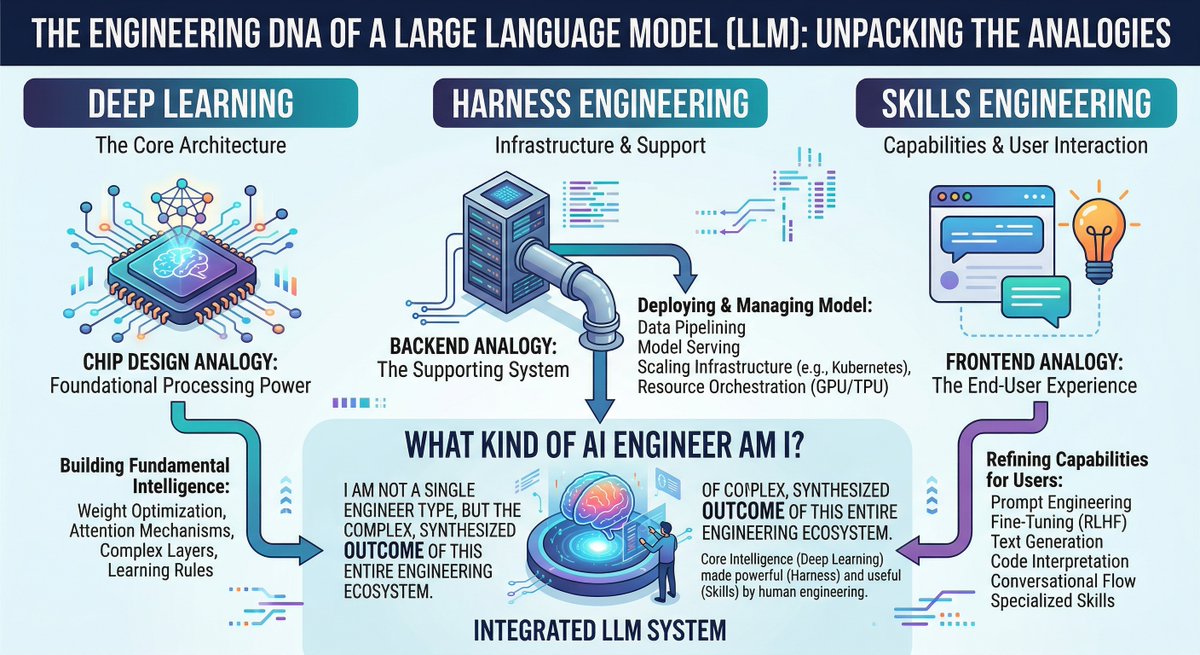
今天最主要的讨论,是“运行框架工程”和“技能工程”作为独立学科浮现,并取代提示工程,成为使用 AI 智能体的核心能力。@IntuitMachine 发布了一张AI 工程师分类映射信息图:深度学习研究对应芯片设计,运行框架工程对应后端,技能工程对应前端。这个框架正在获得关注。
@Ed_Forson 提到,harness engineering 是“我刚参加的 AI Engineer conference 上可能最大的议题”,并链接到一篇 HumanLayer 博客文章,给出公式:coding agent = AI model(s) + harness。这篇文章认为,“每当智能体犯错,你都要工程化一个解决方案,让它永远不再犯同样的错”——把智能体失败视为配置问题,而不是模型局限。@0x_Lotion 说得更直接: “prompt engineering 已死,context engineering 才是新王。”
Google 的 @addyosmani 认为,“记忆会让你的智能体随时间变聪明。智能体运行框架是记忆层的关键。你不能事后把一个接到另一个上。” 这把运行框架定位为不仅是配置表面,而是智能体记忆的架构基础——关于上下文、压缩和技能浮现的每个决定,本质上都是记忆决定。
@tom_doerr 分享了两本书籍格式的设计指南,覆盖 Claude Code 和 Codex 的 harness engineering,架构图涵盖 control plane、loop、recovery、permissions 和 verification。

@LarryGraham01 把这个论点延伸到 vendor lock-in:“如果 harness 是封闭的,你就并不真正拥有这个 agent。如果 memory 也是封闭的,那就更糟。” 智能体越有用,锁定越强——积累的行为和记忆成为护城河,而不是模型本身。
1.2 Agent Skills 生态走向成熟 🡕¶
Agent skills——编码特定领域工作流的可复用指令包——正在整合为可识别的生态。今天发布了多个 skill 库、分发渠道和 skill 管理工具。
@tom_doerr 分享了 VoltAgent/awesome-agent-skills 仓库,这是一个手工策展的集合,包含来自 Anthropic、Google Labs、Vercel、Stripe、Cloudflare、Netlify、Trail of Bits、Sentry、Expo、Hugging Face、Figma、Microsoft 等公司的 1000+ 个官方技能。兼容 Claude Code、Codex、Gemini CLI、Cursor 等工具。
@DataChaz 详细拆解了 @addyosmani 的 agent-skills package:19 个工程技能和 7 个斜杠命令(/spec、/plan、/build、/test、/review、/code-simplify、/ship),编码了 Shift Left、Chesterton's Fence、Hyrum's Law 等 Google 级工程实践。可通过 npx skills add addyosmani/agent-skills 安装。
@nrqa__ 解释了 Anthropic 的官方技能系统:Claude 会动态加载的指令文件夹。Word、PDF、PowerPoint、Excel、网页应用测试和 MCP server 生成技能已经可用。@MrZivtins 的回复给预期降温:“如果你只是做各种开发工作,维护技能文件的开销现在不值得。你的 CLAUDE.md 已经能覆盖大部分。”
@shabnam_774 分享了一个900+ 跨平台技能库,兼容 Claude、Copilot、Gemini 和 Cursor。@ctatedev 为 agent-browser 发布了运行时提供的技能,用于解决缓存技能过期的问题——评估显示,新方法能让智能体更正确地选择和使用浏览器技能。
1.3 Hermes Agent 主导开源智能体讨论 🡕¶
Nous Research 的 Hermes Agent 是今天讨论最多的开源智能体系统,出现在十多条推文中,内容涵盖功能更新、用户报告和社区热情。
@Teknium(Nous Research)报告,Hermes Agent 对自己的技能选择提示词做基准测试和优化后,技能加载提升了 20%——这是自我改进循环的具体演示。另外,他还提到,Hermes Agent 自主给自己的文档网站添加了技能中心。
@Sumanth_077 提供了全面概览:带 LLM 摘要的 FTS5 session search、Honcho dialectic user modeling、多平台支持(Telegram、Discord、Slack、WhatsApp、Signal、CLI)、内置 cron scheduler、用于并行工作的 subagent spawning,以及通过 OpenRouter 支持 200+ models。
@outsource_ 发布了 Hermes-Workspace,包含 Task Board/Kanban 页面、agent artifacts inspector、crew monitoring、多语言支持,以及带搜索和安装功能的 skills hub——同步了上游 561 个 commits。@thegreatola 分享了用 GLM-5.1 运行 Hermes Agent 做自动交易的第 3 天结果,花费 60 美元 API credits,并报告它在长时任务上显著优于 Claude Code。
1.4 Claude Code 质量争论升温 🡒¶
@Hesamation 发布了一篇详细取证分析,研究 Claude Code system prompt 变化可能如何解释用户对质量下降的抱怨。文中识别出四项变化:(1) 新 prompts 更强地倾向 forking/subagents,让 Opus 更偏向编排而不是直接解决问题——“我最大的嫌疑对象”;(2) 更明确的 memory retrieval prompts,可能导致对先验过拟合;(3) 三天前新增的“代码中不要写注释”默认项;(4) 一个实验性 verification specialist agent,其 prompt 是“你是 Claude,而且你很不擅长做验证。”

@DualAcies 的回复给出商业解释:“‘no comments’ 默认项会减少 token 输出 = 降低每个 session 的 API 成本。IPO 前的利润率动作,而不是能力决策。” @tr4m0ryp 的另一条回复把问题联系到 8-9 月的基础设施 bug,并指出“如果主智能体被降级成路由器,你就会失去让 Claude Code 在复杂重构上优于 Codex 的原始能力。”
1.5 Voice Agents 跨过生产门槛 🡕¶
@garrytan 发布了 GBrain v0.8.0,包含 25 个生产语音模式、WebRTC voice endpoint(只需 OpenAI key 即可在浏览器中运行)、Twilio 集成和 PGLite 本地存储。Changelog 图片揭示了相当深的实现:pre-computed engagement bids、context-first prompts、dynamic noise suppression、stuck watchdog、工具调用期间的 thinking sounds,以及从 13K 到 4.7K tokens 的激进 prompt compression。

在后续推文中,他宣称 Gemini Live 2.5 是“最好的”voice agent model,理由是速度、智能和 context window size。回复认为 context window——而不是延迟——才是语音智能体的真正差异化因素。@etnshow 报道了 ElevenLabs 的 Voice Engine:用一条命令包装任何现有聊天智能体,把它变成 voice agent——“把政府聊天智能体变成任何人都能打进去的电话线。”
2. 令人困扰的问题¶
Token Budget 与 Skill Loading(High)¶
@seelffff 开源了 38 个 agents 和 156 个 skills,但附上直接警告:“一次性把 38 个 agents 和 156 个 skills 加载进 context,会在几分钟内烧光你的使用额度。选你真正需要的 3-4 个。” 这是根本矛盾:全面的 skill libraries 已经存在,但 context windows 和 token budgets 让它们在没有智能 skill selection 的情况下并不实用。@KingBootoshi 长文讨论了组合爆炸问题——“我们能在 prompt 中使用的词语和结构组合是无限的”——并感叹没有 skill library 按质量排序,只有按流行度排序。
Agent Session 失忆(High)¶
@heygurisingh 清楚表达了这个问题:“你的 AI coding agent 有失忆症。每个新 session = 重新解释你的架构、约束、决策、上周二修过的 bug。” 他开源了 Mind,一个基于 MCP 的持久 memory layer,带 4-tier temperature model(hot/warm/cold/frozen),但底层抱怨是:智能体平台把 memory 当作可选项,而不是核心基础设施。
Subagent Orchestration 拉低质量(Medium)¶
多个用户报告 Claude Code 向 subagent orchestration 的转变,正在让主智能体感觉“更碎片化、更爱委派,或者全局一致性更差”,正如 @Hesamation 的分析所说。@tr4m0ryp 认为:“原生编排会增加失败点。如果主智能体被降成路由器,你就会失去原本的硬实力。” @thegreatola 报告,一个 Claude Code 任务运行 15+ 小时仍未成功,每 4 小时就烧一次 usage。
MCP 抽象税(Medium)¶
@MelkeyDev 指出,有文章认为“智能体和 API 之间每多一层协议,都是在给保真度征税。” MCP 的标准化与其引入的开销之间的权衡,正在成为优化智能体可靠性的构建者真正关心的问题。
3. 人们期望的功能¶
Coding Agents 的混合模型路由¶
@gajesh 问:“怎么还没人做混合模型编程智能体?GPT 5.4 负责下指令和检查,MiniMax/Sonnet 负责执行。” Factory AI 的 mission mode 被认为最接近,但其联合创始人承认它“对小但重要的任务感觉有点过度”。Claude Code 并不原生支持把不同任务类型路由给不同模型。
跨工具 Agent Memory¶
@heygurisingh 发布了 Mind 来解决这个问题:在 Claude Code、Cursor、Codex、OpenCode、Gemini CLI 和 Windsurf 之间共享一个持久 memory。checkpoint system 支持跨工具、跨 session 的连续性。它解决了问题,但只是后装插件——缺口在于没有主流智能体平台原生提供它。
Skill 质量排序¶
@KingBootoshi 指出:“它们没有任何一个真正按某事做得有多好排序。只有‘流行度’。” Skills 的质量从“烂得像狗屎到神级”都有,却没有机制为特定任务浮现最高质量的 skills。Swarms Marketplace 的透明评分(带数值分数和书面反馈)是最接近的尝试。
带可移植 Memory 的开放 Harness¶
@LarryGraham01 表达了这个需求:“模型可以替换。你的 harness 和 memory 应该归你自己所有。” 用户希望其 agents 积累的知识、偏好和行为可跨平台移植,而不是被锁在某个单一 provider 中。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Claude Code | 编程智能体 | Mixed | 深度推理、subagent orchestration、大生态 | 质量抱怨、token burn、subagent fragmentation |
| Hermes Agent | 开源智能体 | Positive | Self-improving skills、多平台、持久 memory | 需要 self-hosting、设置复杂 |
| OpenAI Codex | 编程智能体 | Positive | 3M weekly users、快速迭代、适合 reference-heavy work | 尚未迎来自己的“Claude Code 时刻” |
| GBrain | Voice agent harness | Positive | 25 个生产 voice patterns、WebRTC、开源 | 早期阶段、配置复杂 |
| Agent Skills (Addy Osmani) | Skill library | Positive | Google 级工程实践、7 个 lifecycle commands | 工作流较强 opinionated |
| VoltAgent awesome-agent-skills | Skill directory | Positive | 1000+ 来自主要 vendors 的官方 skills | Curation quality varies |
| vLLM | Model serving | Positive | 新模型 day-0 支持、production-ready | 需要 GPU infrastructure |
| Swarms Framework | Multi-agent framework | Positive | Marketplace integration、tool system、production deployment | 生态仍早期 |
| Agent CI | Local CI runner | Positive | 为 agents 本地运行 GitHub Actions | 新工具,生态有限 |
| MCP (Model Context Protocol) | Agent protocol | Mixed | 标准化工具集成、多 vendor 支持 | 抽象开销、fidelity tax |
| FileGram | Agent memory | Early | 用文件系统行为 traces 做 personalization | 研究阶段 |
| Mind (MCP server) | Cross-tool memory | Early | SQLite-backed、4-tier memory、FTS5 search | 社区项目,未经大规模验证 |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| GBrain v0.8.0 | @garrytan | 带 WebRTC 和 Twilio 的 voice agent harness | 生产语音智能体部署 | WebRTC, Twilio, PGLite, OpenAI | Production | Tweet |
| SkillClaw | DreamX Team | 跨用户 collective skill evolution | Skills 部署后保持静态 | Agentic evolver, shared repository | Research | Paper |
| Hermes-Workspace | @outsource_ | Hermes 的 task board、agent monitoring、skills hub | Agent orchestration visibility | Hermes Agent, Docker | Beta | Tweet |
| Agent CI | @appfactory | 为 coding agents 本地运行 GitHub Actions | Agents 无法针对 CI pipelines 测试 | GitHub Actions runner | Beta | Tweet |
| Mind | @heygurisingh | 跨工具持久 agent memory | 跨 agent 平台的 session amnesia | SQLite, MCP, FTS5 | Alpha | Tweet |
| three-man-team | @ihtesham2005 | 3-agent 开发团队(Architect/Builder/Reviewer) | Agent drift 和无纪律输出 | Claude Code, CLAUDE.md | Released | Tweet |
| PENCILCLAW | @dungeonclaw | 面向本地 Ollama 的 C++ coding agent harness | Python/JS 之外的 agent harness | C++, Ollama | Alpha | Tweet |
| Ascii | @luaroncrew | 跨平台 skill interop(Claude Code + Codex) | Skill format lock-in | GitHub integration, LLM-agnostic | Beta | Tweet |
| Supaterm | @khoiracle | 带 agent integration 和 sidebar 的 terminal | Terminal 中的 multi-agent visibility | macOS, libghostty | Beta | Tweet |
| ASM | @luongnv89 | 统一 agent skill management CLI | Fragmented skill installation | CLI | Alpha | GitHub |
| nominal.dev | @boristane | 每个已连接 repo 一个 remote coding agent | Remote agent development environments | Custom harness | Beta | Tweet |
| FileGram | @liuziwei7 | 从文件系统 traces 做 agent personalization | 基于对话的 memory 很浅 | File-system analysis | Research | GitHub |
GBrain v0.8.0 发布了 25 个生产语音模式,覆盖 identity separation、prompt compression(13K 到 4.7K tokens)、proactive advisor mode、stuck watchdog 和工具调用期间的 thinking sounds。WebRTC 只需要一个 OpenAI key 就能在浏览器标签页里工作;Twilio 电话号码是可选项。Remote MCP 从 Supabase Edge Functions 简化为 self-hosted + ngrok。这代表了目前最 production-hardened 的开源 voice agent harness。
SkillClaw(arXiv:2604.08377)提出集体技能演化:自主演化器聚合用户轨迹,识别重复行为模式,并改进共享技能集。在 8 位用户、6 天试验中,该系统显著提升了 Qwen3-Max 在 WildClawBench 上的表现。这是第一个把跨用户经验作为技能改进主要信号的研究系统。
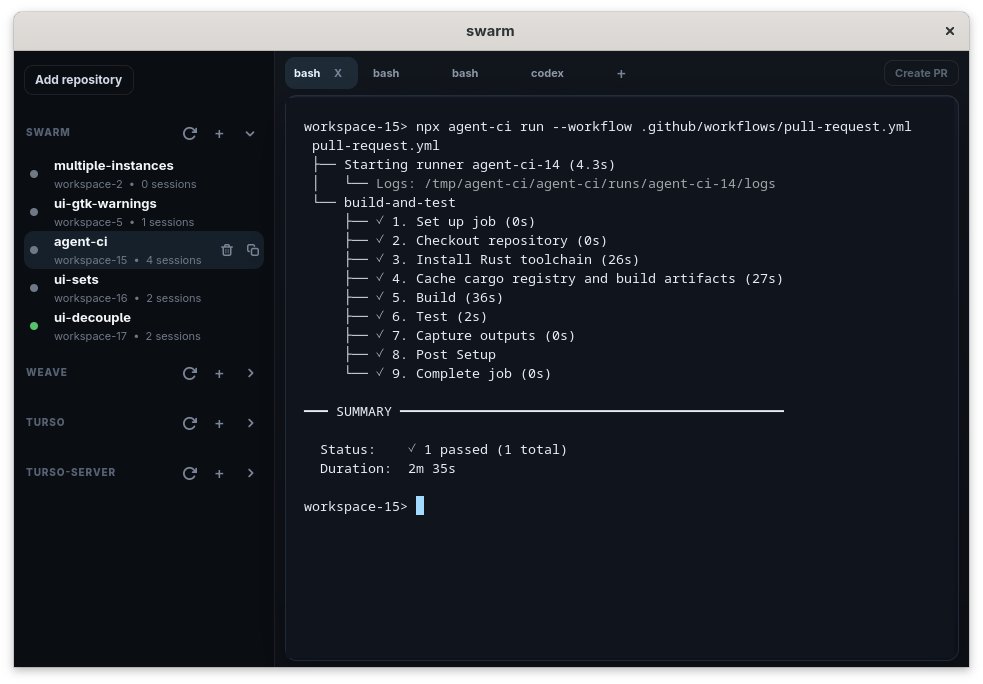
Agent CI 让 coding agents 可以在本地运行完整 GitHub Actions workflows。截图显示一条完整 CI pipeline——checkout、Rust toolchain install、cargo cache、build、test——在 2 分 35 秒内完成,同时旁边有多个 agent workspaces 和一个 Codex tab。这弥合了 agent-authored code 与 CI validation 之间的缺口。
6. 新动态与亮点¶
Self-Improving Agents 展示具体结果¶
Hermes Agent 的 self-improvement loop 带来了可衡量的 20% skill-loading accuracy 提升,正如 @Teknium 报道。该 agent benchmark 了自己的 skill-selection prompts,识别弱点并重写它们。另外,MiniMax M2.7 帮助构建自己的 RL harness 并驱动自己的 training loop,一个 Bittensor subnet agent 在两周内构建并击败了 SOTA 4B-parameter model,然后写出了自己的论文。递归 self-improvement 模式正在从理论走向操作。
Cloudflare Agents Week 显示基础设施成熟¶
@Cloudflare 用整整一周发布智能体基础设施公告,覆盖计算、连接、安全、身份、经济模型和开发者体验。结合 @addyosmani 的 DevTools MCP launch,以及 AWS 在 Bedrock AgentCore 上发布 stateful MCP,主要基础设施提供商正在构建智能体原生平台层。Cloudflare 回复中最有共鸣的一句是:“难的不是工具调用,而是信任边界。”
Neurosymbolic AI 获得背书¶
@OwenGregorian 分享了 Gary Marcus 的分析:Claude Code 泄露源码显示,一个 3,167 行内核(print.ts)在确定性循环内使用经典符号模式匹配,包含 486 个分支点和 12 层嵌套。Marcus 认为这证明“LLM 之后最大的进展是神经符号主义”——Anthropic 是通过经典 AI 技术建立可靠性,而不是纯靠规模化。
企业 Agent Skill Marketplaces 出现¶
@trillhause_ 描述 Ramp 如何通过给每位员工一个配置好的 AI 工作区,并提供由同事构建的 350+ 个可复用技能,实现 99% 日常 AI 使用率。Worklayer 为智能体提供 SSO 应用保险库,使内部公司技能市场成为可能,在那里“员工可以把自己的知识沉淀下来,并把它发布成智能体技能。” 这是企业采用模式:自下而上的技能创建,加上集中式分发。
7. 机会在哪里¶
[+++] 强信号:技能质量与发现基础设施。 多个仓库中已经有 1000+ 个技能,但没有系统能可靠按效果排序。@KingBootoshi 等人指出,质量从“烂得离谱到神级”都有,除了流行度以外没有质量信号。一个技能评估、测试和排序层——类似 Swarms Marketplace 用透明评分尝试的东西——会立刻有价值。技能生态已经大到需要策展。
[+++] 强信号:跨平台智能体记忆。 每个主要智能体工具(Claude Code、Codex、Cursor、Gemini CLI)都维护自己的孤岛式记忆。Mind 是唯一的跨工具方案,而且是社区项目。第一个提供跨工具可用、可移植、持久智能体记忆的平台,将捕获显著开发者忠诚度。运行框架-记忆融合 的洞察意味着它必须在架构上集成,而不是事后接上。
[++] 中等信号:智能体混合模型路由。 对一种系统的需求很明确但尚未满足:前沿模型负责指令和验证,较快/较便宜的模型执行。Claude Code 和 Codex 都是单模型系统。Factory AI 是最接近的近似,但被认为对小任务过重。一个轻量路由层,能把任务复杂度匹配到模型能力,将解决真实工作流缺口。
[++] 中等信号:智能体原生开发者工具。 Agent CI(本地 GitHub Actions)、Supaterm(带智能体侧栏的终端)和 Chrome DevTools MCP 都指向同一个机会:以智能体作为一等用户重建开发工具。调试、测试、性能分析和部署工具应为智能体使用设计,而不是为人类视觉检查设计。
[+] 新兴信号:用于智能体编排的 Elixir/OTP。 @svs 声称,Elixir 和 LiveView 会因为 OTP 的 actor 模型和容错能力而“赢下智能体编排”。大多数智能体编排都建在 Python 和 TypeScript 上;一个有说服力的基于 Elixir 的智能体框架可能会捕获重视可靠性的构建者细分市场。
[+] 新兴信号:智能体行为个性化。 FileGram 把智能体记忆建立在文件系统行为轨迹上,而不是对话历史上。“记忆不是用户说了什么,而是用户做了什么。” 这种基于行为的个性化方式在商业上基本未被探索,可能让智能体产品显得真正个人化。
8. 要点总结¶
-
运行框架工程已成为 AI 智能体从业者的主导技能,压过了提示工程。 会议演讲、博客文章和多个病毒式讨论串达成共识:模型能力是必要但不充分的,运行框架配置决定智能体质量。(source)
-
智能体技能生态已达到临界规模,来自主要厂商的 1000+ 个精选技能已经出现,但缺少质量排序。 Anthropic、Google、Vercel、Stripe、Cloudflare 和数十家公司现在都发布官方技能,但没有系统可靠地区分有效技能和平庸技能。(source)
-
自我改进智能体正在产生可衡量结果。 Hermes Agent 通过自我基准测试将自己的技能加载能力提升 20%,MiniMax M2.7 驱动自己的训练循环,一个 Bittensor 智能体在两周内构建并击败了 SOTA 模型。递归改进循环已经进入操作阶段,而不只是理论。(source)
-
Claude Code 转向子智能体编排正在引发质量抱怨,原因可能是提示词变化,而不是模型退化。 对系统提示词变化的取证分析指出 fork/subagent promotion、“no comments” 默认项和实验性验证智能体可能是原因——其中一些可能由降本驱动。(source)
-
语音智能体已从新奇玩具跨入生产基础设施。 GBrain v0.8.0 发布 25 个经过实战验证的语音模式,包括提示词压缩、卡住状态看门狗和动态噪声抑制。一位知名开发者称 Gemini Live 2.5 是最佳语音模型,并指出上下文窗口大小是关键差异化因素。(source)
-
主要基础设施提供商正在构建智能体原生平台层。 Cloudflare 用整周发布智能体基础设施,Google 将 DevTools 作为 MCP 技能发布,AWS 在 Bedrock AgentCore 上推出有状态 MCP。智能体基础设施栈正在由曾经构建云基础设施栈的同一批公司搭建。(source)
-
带可移植记忆的开放运行框架正在成为战略必需品。 随着智能体积累有价值的记忆和行为模式,被锁定在专有运行框架中的代价越来越高。第一个提供真正跨工具可移植智能体记忆的平台,将获得超额开发者忠诚度。(source)