Twitter AI Agent - 2026-04-14¶
1. What People Are Talking About¶
1.1 Harness Engineering Moves from Doctrine to Reference Architecture 🡕¶
Yesterday established the "thin harness, fat skills" doctrine. Today the community began building the reference infrastructure around it. @Vtrivedy10 published a first-principles breakdown of why harnesses exist, working backwards from what models cannot do alone: models are token input/output machines that require augmentation for tool access, memory, planning, and verification loops. The post drew 206 likes and 204 bookmarks -- the highest score in today's dataset.

@codylindley released a harness engineering compatibility matrix at codylindley.github.io, comparing instruction formats (AGENTS.md, CLAUDE.md, GEMINI.md, copilot-instructions.md), custom agent systems, and skill formats across 10+ tools including Copilot, Claude Code, OpenCode, Gemini CLI, Cursor, and Windsurf. With 31 bookmarks on 26 likes -- the highest bookmark-to-like ratio in the dataset -- this signals strong practitioner demand for reference material.
@loiane published a blog post framing harness engineering as a control system with two pillars: feedforward (guidance before the model runs -- instructions, context, examples, schemas) and automated feedback (sensors after execution -- tests, schema validation, business-rule checks). She references Martin Fowler's harness engineering article and maps the concept onto the software delivery lifecycle, arguing the shift is "from in-the-loop to on-the-loop."
@Infoxicador argued that if harness engineering becomes the norm, modularity and tight verification loops are where investment should go -- without them, "tokenmaxxing without reading the code" produces fragile systems. The post drew 30,328 views and 34 bookmarks.

Discussion insight: @KSimback demonstrated using a personal knowledge base to research harness engineering, specifically analyzing what elements constitute a moat versus what will be commoditized. A reply from @SynabunAI surfaced a key insight: "the moat is context that survives sessions. Models are increasingly commoditized. The memory layer is where the lock-in actually is."
Comparison to prior day: Yesterday's conversation established the thin-harness principle. Today it fragmented into implementation specifics: compatibility matrices, control-system frameworks, and explicit moat analysis. The discourse shifted from "what is harness engineering?" to "how do I actually build one?"
1.2 Skills Self-Improvement Emerges as a Practice 🡕¶
Three independent teams shipped tools for automated skill improvement today, transforming yesterday's manual skill lifecycle into an automated feedback loop. @PiSquared open-sourced skill-optimizer, a tool for evaluating, improving, and adapting agent skills without trial-and-error. @Saboo_Shubham_ built a self-improving multi-agent system using Google Agent Development Kit and Gemini 3 that runs skills against test scenarios, diagnoses failures, and fixes them automatically.

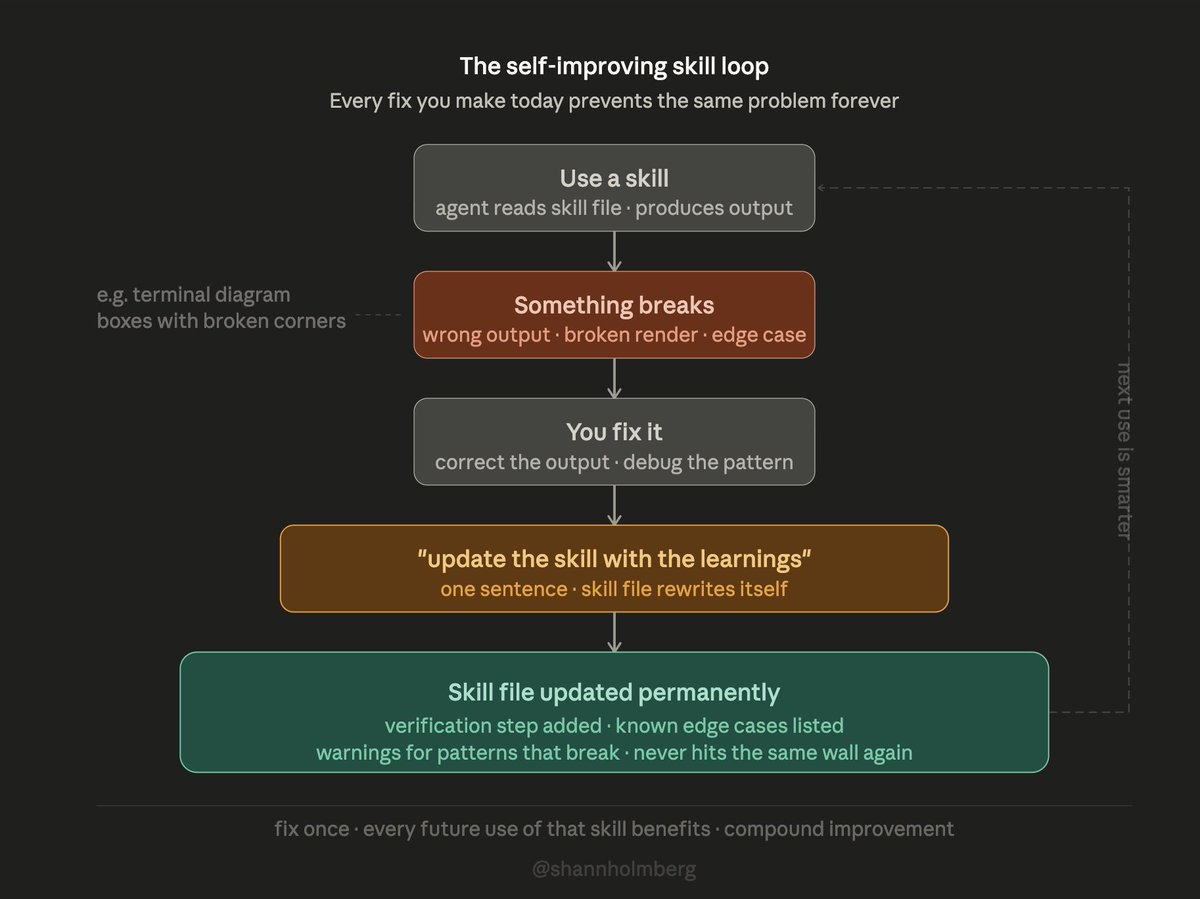
@shannholmberg published a diagram of "the self-improving skill loop": use a skill, something breaks, fix it, tell the agent to "update the skill with the learnings," and the skill file rewrites itself with verification steps and edge-case warnings. The tagline: "fix once -- every future use of that skill benefits."
@koylanai made the case that skills -- the knowledge encoded in markdown procedures -- are the real product, while harnesses are interchangeable infrastructure. The post's 98 bookmarks on 99 likes underscored the point.
Discussion insight: @anatoliygatt, replying to @akshay_pachaar's post about MiniMax M2.7, reported "30% improvement from harness optimisation alone, zero retraining, weights completely frozen" -- a concrete data point that harness/skill optimization can substitute for model retraining.
Comparison to prior day: Yesterday, @avisinghdotdev requested an /update-skills command. Today, three teams independently shipped automated skill improvement. The gap between "skills need to evolve" and "here's how they evolve" closed in 24 hours.
1.3 Multi-Agent Orchestration Goes Mainstream 🡕¶
Multi-agent setups shifted from experimental to recommended practice. @code_rams published a detailed multi-agent guide arguing that "running OpenClaw alone is leaving 80% of its power on the table" and laying out a complementary OpenClaw + Hermes setup. The post scored 1,088 with 192 bookmarks -- the third-highest in the dataset.
@databricks released usage data from 20,000+ organizations showing multi-agent systems growing 327% in under four months, with 78% of companies using two or more agent frameworks simultaneously.
@WesRoth reported that ahead of Google I/O, leaks indicate Google is testing an autonomous multi-agent platform designed as a direct competitor to Anthropic's Claude Cowork. The platform, reportedly named "Agent," targets the Gemini workspace. The post drew 200 likes and 24,403 views.
@mizzysworld described splitting a single Hermes agent into specialist profiles with "separate memory, separate sessions, shared doctrine." @kevinchan showed his first major output using a Hermes multi-agent framework: an orchestrator and research agent created the PRD, then passed it to a coder agent for implementation.

Discussion insight: @hassanlaasri, replying to WesRoth, predicted: "Over time, chat, coding, and workspace management will increasingly converge into one conversational interface."
Comparison to prior day: Yesterday's multi-agent discussion was conceptual. Today it backed up with Databricks data (327% growth, 20K organizations), practical guides (OpenClaw + Hermes), and competitive moves (Google Agent platform). The narrative shifted from "should we use multi-agent?" to "which multi-agent setup?"
1.4 Agent Security: The "Lethal Trifecta" 🡕¶
@iancr recounted standing on a stage last October warning that "an agentic future where we give agents our logins, credit cards, and identities is a security nightmare." Six months later, he called the prediction validated. In a self-reply thread, he defined the "lethal trifecta": agents need access to value (money, email, credentials, browser, files), but no verification infrastructure exists to ensure they use it safely. The post drew 41 retweets -- unusually high amplification for a security warning.
@omarsar0 shared "Multi-User Large Language Model Agents" (arXiv:2604.08567) from Stanford, KAUST, and MIT -- the first systematic study of multi-user LLM agent interaction. The paper found that frontier LLMs fail to maintain stable prioritization under conflicting user objectives and exhibit increasing privacy violations over multi-turn interactions.

@a_g_e_n_c shipped a devnet task system update treating marketplace tasks as untrusted input: "A task can describe work, rewards, constraints, and deliverables. But the task text itself has no authority." The task hash serves as a cryptographic work contract.
Discussion insight: @FoltzAI, replying to @rryssf_, asked "how long until a context curator is the norm?" -- framing security and context quality as two sides of the same trust problem.
Comparison to prior day: Yesterday documented active attacks on LLM API routers ("Your Agent Is Mine" paper). Today moved from attack documentation to architectural response: the "lethal trifecta" framing, multi-user privacy research, and cryptographic task validation.
1.5 Context Noise Reframed as the Core Problem 🡒¶
@rryssf_ posted that "every major AI agent framework is solving the wrong problem. They're expanding context windows. But the problem isn't capacity -- it's that 90% of what agents read is structural noise." The post drew 6 quote-tweets and 66 bookmarks, indicating it sparked substantive debate.

@dair_ai shared "Artifacts as Memory Beyond the Agent Boundary" (arXiv:2604.08756), which formalizes how the environment itself can serve as an agent's memory. The Artifact Reduction Theorem proves that certain environmental observations reduce the information agents need to store internally -- agents can use their environment as external memory rather than copying everything into context.

@talraviv observed: "We solved file sharing 19 years ago, and we still haven't solved shared AI context." The goal, in the words of Zapier's VP of Product, is "context engineering as a team sport."
Comparison to prior day: Yesterday's context engineering discussion focused on taxonomy (6 components) and cross-tool memory. Today reframed the problem: the bottleneck is not context window size but signal-to-noise ratio within context.
1.6 Chinese AI Solves Open Mathematical Problem 🡕¶
@commiepommie reported that Peking University's dual-agent framework solved a decade-old open problem in commutative algebra with no human intervention. The system used two collaborating agents to generate and verify proofs autonomously.

Comparison to prior day: No direct precedent in prior day. This represents a step change in AI mathematical reasoning capability using multi-agent architecture.
2. What Frustrates People¶
Platform Dependency Risk (Severity: High)¶
@heynavtoor reported that Anthropic killed their Claude Max subscription ($200/month) without warning while running OpenClaw 24/7: "One email from Anthropic and it all stopped working. No warning period. No migration window. Just done." The screenshot showed the Anthropic termination email.
This follows yesterday's pattern where subscription-dependent workflows create single points of failure. The gap between "always-on agent infrastructure" and "pay-per-month API access that can be revoked" remains a structural problem.
Context Noise, Not Context Size (Severity: High)¶
@rryssf_ argued that agent frameworks are solving the wrong problem by expanding context windows when 90% of content is structural noise. Multiple replies validated this frustration. @FoltzAI asked why frontier labs haven't added context curation as a built-in feature. The frameworks are optimizing for capacity when practitioners need signal quality.
IP Tension in Agent Frameworks (Severity: Medium)¶
@uniquesingh__ surfaced an accusation from @EvoMapAI that the Hermes team mirrored their "Evolver" agent framework -- "same loop, same structure, same reasoning chain." The post drew 81 likes and 53 replies. As agent frameworks proliferate, IP disputes over architectural patterns are becoming more common.
Agent Orchestration Skepticism (Severity: Medium)¶
@alexhillman called agent orchestration tools claiming to offer "an AI company in a box" as "productivity cosplay." The criticism targets the gap between demo-ready agent orchestration and production-ready agent management.
3. What People Wish Existed¶
Shared Agent Context for Teams¶
@talraviv identified that 19 years after solving file sharing, shared AI context remains unsolved. Zapier's VP of Product described the goal as "context engineering as a team sport" -- how do you share knowledge, prompts, and agent configuration across a team so every agent session builds on prior work?
Context Curation Layer¶
@FoltzAI, replying to @rryssf_'s post about structural noise, asked: "How long until a context curator is the norm? Why can't frontier labs just add this as a feature tomorrow?" No satisfactory answer emerged. The gap between raw context windows and curated, signal-rich context remains unfilled.
Agent Subscription Portability¶
@heynavtoor's experience of losing a Claude Max subscription overnight highlights the need for portable agent infrastructure that doesn't depend on a single provider's subscription terms. No solution exists beyond running local models.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude Code | Coding agent | Mixed | Deep reasoning, large skill ecosystem, subagent support | Platform dependency risk, subscription revocation |
| OpenClaw | Open-source agent | Positive | 6.5M MAU, 143K GitHub stars, complementary with Hermes | Loses 80% power without multi-agent setup per @code_rams |
| Hermes Agent | Multi-agent framework | Positive | Memory, research, orchestration, specialist profiles | IP dispute with EvoMapAI, complex setup |
| Runtime (runtm.com) | Agent infrastructure | Positive | Harnesses, sandboxes, observability, multi-agent, self-hostable | New launch, unproven at scale |
| GBrain | Personal agent brain | Positive | PGLite (no server), dream cycle, entity sweep, integrations | Requires frontier models (Opus 4.6 / GPT-5.4) |
| Google ADK | Agent development kit | Positive | Gemini 3 integration, self-improving skills | Google ecosystem lock-in |
| skill-optimizer | Skill QA tool | Positive | Open-source, automated skill evaluation and improvement | New, community project |
| Letta Code | Agent framework | Positive | Recall subagent as fork of main context, endorsed by Dex Horthy | Niche adoption |
| LiveKit Agent Console | Voice agent debugging | Positive | Realtime pipeline visibility, latency tracking, tool call inspection | Voice-agent specific |
| Pipecat | Voice agent framework | Positive | Real-time voice agent construction | Tutorial-stage content |
| Fire-PDF | PDF parser | Positive | Rust-based, 5x faster markdown conversion | New release |
Runtime, launched by @ycombinator and built by @gustrigos, is the most notable new tool -- it productizes harness engineering with sandboxed environments, policy controls (spend limits, file protections), and session-level observability across Claude Code, Codex, Gemini CLI, and OpenCode. Self-hostable with MIT/Apache/AGPL licensing. GBrain, published by @garrytan, introduces a "dream cycle" -- nightly memory consolidation where the agent performs entity sweeps, citation fixes, and knowledge compounding.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Runtime | @gustrigos | Harnesses, sandboxes, and observability for coding agents | Teams building agent infrastructure from scratch | Multi-agent, self-hostable | Launched (YC) | Tweet, Site |
| Fuel | @ashleyhindle | Opinionated development workflow harness | Unstructured agent workflows | Custom harness | Day one | Tweet |
| GBrain | @garrytan | Personal agent knowledge base with memory consolidation | Agents lack persistent personal context | PGLite, OpenClaw/Hermes, Bun | Released | Tweet, GitHub |
| skill-optimizer | @PiSquared | Automated skill evaluation, improvement, and adaptation | Manual skill maintenance | Open-source | Released | Tweet |
| Harness Compatibility Matrix | @codylindley | Cross-tool comparison of instruction formats and skill systems | No standard reference for harness configurations | Static site | Released | Tweet, Site |
| LiveKit Agent Console | @livekit | Realtime debugging surface for voice agents | No visibility into voice agent pipeline | LiveKit platform | Shipped | Tweet |
| AgenC Devnet Task System | @a_g_e_n_c | Cryptographic task validation for agent marketplaces | Marketplace tasks treated as trusted input | Custom runtime | Devnet | Tweet |
| ClickNClaw | @ClickNClawLabs | Native Windows multi-agent orchestration desktop app | Agent tools trapped in browser tabs and web wrappers | Windows native, Gemini CLI | Working demo | Tweet |
| Self-improving Skills (ADK) | @Saboo_Shubham_ | Multi-agent system that tests, diagnoses, and fixes agent skills | Manual skill debugging and iteration | Google ADK, Gemini 3 | Demo | Tweet |
Runtime stands out as the first product to explicitly package harness engineering for teams. It provides sandboxed environments auto-provisioned per repo, policy controls (spend limits, file protections, per-user rules), and native integrations with Slack, Linear, GitHub, and Jira -- allowing PMs and designers to trigger agent sessions without git knowledge.
GBrain introduces the concept of a "dream cycle" -- a nightly cron job where the agent performs entity sweeps, citation fixes, and memory consolidation across a personal knowledge base. The brain compounds over time as the agent processes meetings, emails, tweets, and voice calls into searchable, linked knowledge.
6. New and Notable¶
Databricks: Multi-Agent Adoption Up 327% Across 20,000 Organizations¶
@databricks published the first large-scale adoption data for multi-agent systems. Key findings from 20,000+ global organizations: multi-agent systems grew 327% in under four months, and 78% of companies are using two or more agent frameworks simultaneously. This is the hardest usage data on multi-agent adoption reported in the dataset.

Harness Engineering Compatibility Matrix¶
@codylindley published a comprehensive compatibility matrix comparing instruction formats, agent systems, and skill formats across Copilot, Claude Code, OpenCode, Gemini CLI, Cursor, Windsurf, and more. The matrix covers scoping mechanisms (repo-root vs. subdirectory vs. glob-pattern), activation modes, and cross-tool compatibility. The first attempt to standardize the fragmented harness configuration landscape.
ClickHouse CEO on Agent-Driven Data Infrastructure Shift¶
@ceo_clickhouse quoted analysis arguing that "the AI bear case for Snowflake revolves around differences in human vs. agent preferences for accessing data." As agents increasingly query data infrastructure directly, the products optimized for human dashboards and SQL workbench interactions may be disadvantaged against those optimized for programmatic, high-throughput agent access patterns. The post reached 38,337 views.
Multi-User Agent Privacy Failures Documented¶
The "Multi-User Large Language Model Agents" paper (arXiv:2604.08567) from Stanford, KAUST, University of Toronto, and MIT established that frontier LLMs serving multiple users simultaneously exhibit increasing privacy violations over multi-turn interactions and fail to maintain stable prioritization when user objectives conflict. This is the first systematic study of the multi-principal agent problem.
7. Where the Opportunities Are¶
[+++] Skill Lifecycle Automation. Three independent teams shipped skill self-improvement tools today (@PiSquared, @Saboo_Shubham_, @shannholmberg's conceptual loop). Yesterday this was an unmet need. Today it has three competing implementations but no standard approach. The gap between "skills that exist" and "skills that compound in quality over time" is where the next platform advantage forms. Databricks data showing 78% multi-framework adoption means skills that work across tools have outsized value. (source)
[+++] Agent Infrastructure for Teams. Runtime (YC-backed) launched today, but the market for team-level agent infrastructure -- harnesses, sandboxes, observability, governance -- is wide open. @talraviv identified shared AI context as the unsolved problem. @ashleyhindle launched Fuel. The pattern is consistent: individual agent use works; team agent use requires infrastructure that does not yet exist at maturity. (source)
[++] Context Curation over Context Expansion. @rryssf_'s framing -- 90% of agent context is structural noise -- resonated with 66 bookmarks and 6 quote-tweets. The "Artifacts as Memory" paper (arXiv:2604.08756) provides theoretical grounding for environmental memory that reduces internal context requirements. A tool that curates context (removing noise, prioritizing signal) rather than expanding it would address a documented practitioner pain point. (source)
[++] Agent Security Verification. The "lethal trifecta" (@iancr), multi-user privacy failures (arXiv:2604.08567), and AgenC's cryptographic task validation all point to the same gap: agents need access to value, but no verification infrastructure exists. The multi-user paper demonstrates the problem is not just theoretical -- frontier models actively violate privacy constraints under multi-principal conditions. (source)
[+] Personal Agent Memory Systems. GBrain's "dream cycle" concept -- nightly memory consolidation, entity sweeps, knowledge compounding -- represents a new category of agent infrastructure. @KSimback's research showed "the moat is context that survives sessions." The gap between session-scoped agent memory and persistent, compounding personal knowledge remains wide. (source)
[+] Platform-Independent Agent Access. @heynavtoor's Claude Max termination demonstrates the fragility of subscription-dependent agent workflows. As agents become always-on infrastructure, the mismatch between "revocable subscription" and "mission-critical runtime" creates demand for platform-independent agent access layers. (source)
8. Takeaways¶
-
Harness engineering moved from doctrine to reference architecture in one day. A compatibility matrix comparing 10+ tools, a control-system framework (feedforward + feedback), and explicit moat analysis now exist as community-built resources. The discourse shifted from "what is it?" to "how do I implement it?" (source)
-
Skill self-improvement is no longer a wish -- three independent teams shipped implementations. PiSquared open-sourced skill-optimizer, Saboo built self-improving skills with Google ADK, and shannholmberg diagrammed the compound-improvement loop. The 30% performance gain from harness optimization alone (zero retraining) validates that skill quality matters more than model selection. (source)
-
Multi-agent adoption has hard data: 327% growth across 20,000 organizations, with 78% using two or more frameworks. Databricks provided the first large-scale evidence that multi-agent systems are not experimental -- they are the default pattern. Google's leaked "Agent" platform for Gemini confirms that major vendors see multi-agent workspaces as a competitive battleground. (source)
-
Agent security research is outpacing agent security infrastructure. The Stanford/MIT multi-user paper documented privacy violations that worsen over multi-turn interactions. The "lethal trifecta" framing captured the structural problem: agents need value access, no verification exists. AgenC's cryptographic task validation is the only implementation-level response observed today. (source)
-
The moat in agentic AI is shifting from model access to persistent context. Multiple signals converge: GBrain's "dream cycle" for knowledge compounding, KSimback's moat analysis identifying context-that-survives-sessions as the lock-in, and the Artifacts-as-Memory paper theorizing environmental memory as a substitute for internal context. Models are commoditizing; what persists between sessions is not. (source)
-
Platform dependency is now a documented risk for production agent workflows. Anthropic terminated a Claude Max subscription used for always-on OpenClaw with no warning or migration window. As agents become mission-critical infrastructure, subscription-revocable access creates a structural vulnerability that the market has not yet addressed. (source)
-
Context quality, not context quantity, is the emerging bottleneck. The argument that 90% of agent context is structural noise resonated across the community. The Artifacts-as-Memory paper provides a theoretical alternative: let agents use their environment as memory rather than copying everything into context windows. The context engineering field is pivoting from "how big?" to "how clean?" (source)