Twitter AI Agent - 2026-04-17¶
1. What People Are Talking About¶
1.1 Harness Engineering Debate Intensifies 🡕¶
The harness engineering conversation from April 16 continued accelerating. @akshay_pachaar's three-phase framework (weights to context to harness) remained the top post across the entire dataset on its second day, now at 606 likes, 797 bookmarks, and 76,723 views. The thesis: "the model is no longer the sole location of intelligence. It sits inside a harness that includes persistent memory, reusable skills, standardized protocols (like MCP and A2A), execution sandboxes, approval gates, and observability layers."

@aiDotEngineer promoted a conference talk (41 likes, 46 bookmarks, 15,311 views) featuring @_lopopolo on "Harness Engineering: How to Build Software When Humans Steer, Agents Execute." The discussion thread captured a defining philosophical schism: @SamanvayaY noted this is "the exact opposite of Mario Zechner's nuclear take -- Ryan: 'Code is free. Ban editors. Fire 15-5000 agents.' Mario: 'Read every f*ing line or you lose understanding.'" @Samward replied: "The ceiling on agent scale is the quality of the brakes, not the horsepower."
Then came the counter-narrative. @IceSolst posted a hands-on rebuttal (82 likes, 35 bookmarks): "Building a harness to run scans with an agent. It is absolutely garbage. Completely useless. There's literally 0 benefit to using it over plain Claude Code." @garrytan fired back (12 likes) at a separate essay criticizing agents: "Every single failure example in the essay is a naked LLM interaction! Without skills, without a harness, without deterministic code."
@_lopopolo described his own settled approach (8 likes, 10 bookmarks): "automations live in markdown files in docs/automations. The codex app automation prompt is then 2 sentences."
Discussion insight: The harness debate fractured into three camps: believers who treat harness design as the primary engineering discipline, skeptics who find Claude Code's built-in capabilities sufficient, and pragmatists who use lightweight markdown-based automations. The @Samward comment -- "the quality of the brakes, not the horsepower" -- captured the emerging consensus that harness value is in constraint, not capability.
Comparison to prior day: Yesterday the discourse was largely one-directional -- harness engineering as canonical framework. Today introduced organized pushback (IceSolst's practical failure, the Zechner-lopopolo schism) alongside continued adoption. The concept is no longer just spreading; it is being stress-tested.
1.2 Voice-First Agent Interaction Breaks Through 🡕¶
@thdxr posted the day's second-highest engagement (653 likes, 188 bookmarks, 29,406 views): "the biggest impact on my coding workflow lately hasn't been anything agent related -- it's realizing how good these parakeet local voice models are and then just dictating everything into opencode." He shared a macOS tool for getting started (112 likes on the follow-up reply, 147 bookmarks).
@zazmic_inc explained the mechanism: "Typing forces you to compress and abbreviate and the agent gets a worse prompt because of it, while dictating lets you give the full context including the parts you'd normally cut for laziness."
In parallel, @Teknium added Gemini Voice TTS to Hermes-Agent (112 likes, 49 bookmarks) with a free tier option. @garrytan described testing a voice agent for smart scheduling in Taipei -- a flight attendant immediately asked "what is that and can I have it yet?" @kirodotdev launched a Kiro x ElevenLabs hackathon (51 likes, 34 bookmarks) specifically for voice-powered apps, with $10K in prizes.
Discussion insight: thdxr's framing is significant because it inverts the usual narrative. The productivity gain came not from the agent but from changing the human input modality. @solomonneas offered a counterpoint: "It really slows my workflow. I need to type to slow the thoughts and articulate" -- suggesting voice-first is polarizing by cognitive style.
Comparison to prior day: Yesterday voice appeared in one context (Hermes TTS integration). Today it emerged as a standalone productivity thesis (thdxr), a consumer moment (garrytan's flight attendant), a hackathon category (Kiro x ElevenLabs), and an infrastructure piece (Gemini Voice in Hermes). Voice crossed from feature to theme.
1.3 HeyGen Skills and Agent-Native Video Continue Expanding 🡕¶
@rileybrown extracted Claude's new design feature as a reusable agent skill (226 likes, 275 bookmarks, 17,313 views) and showed it working inside Codex with web preview. Multiple accounts amplified HeyGen Skills: @JibrilQanqadar declared "Loom is officially on notice" (31 likes, 5,675 views), describing persistent avatar identity across sessions. @manishkumar_dev noted: "Describe your avatar once, and HeyGen Skills builds it, reuses it across every video."
@ashpreetbedi introduced Vibe-Video (48 likes, 50 bookmarks), an open-source multi-agent team built with HeyGen Hyperframes and Opus 4.7 that turns research topics into motion-graphics videos. @AndyMarlowg described a CREAO agent that turns news into comedy using Opus 4.7 for writing and Gemini 3.1 TTS for voice -- "one agent can turn the news into comedy" (62 bookmarks).
Discussion insight: The HeyGen Skills pattern is converging on a specific workflow: describe avatar once, agent remembers it, auto-generates prompt-optimized video. rileybrown's skill extraction from Claude to Codex demonstrates cross-agent skill portability becoming practical.
Comparison to prior day: Yesterday HyperFrames launched and the video category was established. Today the adoption wave hit: practitioners are extracting skills, building on top of them, and declaring incumbent tools "on notice." The video agent category moved from announcement to ecosystem.
1.4 Multi-Agent Orchestration Gains Practical Evidence 🡕¶
@georgeorch dominated the multi-agent conversation with three high-engagement posts. He reversed his prior skepticism (170 likes, 7,053 views): "I used to skip past 'multi-agent' setups, thinking they were overkill. I was wrong. They were right. One agent is a tool. Four agents are a business." He also highlighted the memory problem (202 likes, 10,718 views): "why do you forget everything the moment I need you most?"
@camsoft2000 described (19 likes, 11 bookmarks) RepoPrompt's orchestration managing Codex and Claude Code together: "the main agent killed a subagent to prevent it thrashing on an issue." @DAIEvolutionHub reported teams running 4-8 agents in parallel via git worktrees: "Agent 1 builds, Agent 2 tests, Agent 3 security, Agent 4 refactors, Agent 5 docs."
@petergyang shared a practical pattern (13 likes, 7 bookmarks): "I always ask AI to spin up a separate eval agent to do yes/no checks to grade the first agent's output." @theAIdreamer confirmed: "Writer agent to editor agent that has the style guide loaded as context. The editor rejects drafts 40% of the time."

Discussion insight: The writer-evaluator pattern (build agent + review agent) is emerging as a simple, repeatable multi-agent architecture. petergyang and DimitriGilbert both independently describe the same pattern, suggesting convergence on a minimal viable multi-agent setup.
Comparison to prior day: Yesterday the multi-agent discourse was split between 0xSero's empirical evidence and georgeorch's skepticism. Today georgeorch reversed position, and multiple practitioners independently described working patterns. The debate shifted from "does multi-agent work?" to "what's the simplest multi-agent pattern that works?"
1.5 Coding Agent Governance Enters Enterprise Tooling 🡕¶
@databricks announced Coding Agent Support in Unity AI Gateway (27 likes, 15 bookmarks): centralized governance for coding agents with usage tracking, rate limiting, and inference tables. The architecture routes Cursor, Gemini CLI, and Codex CLI through a single AI Gateway.

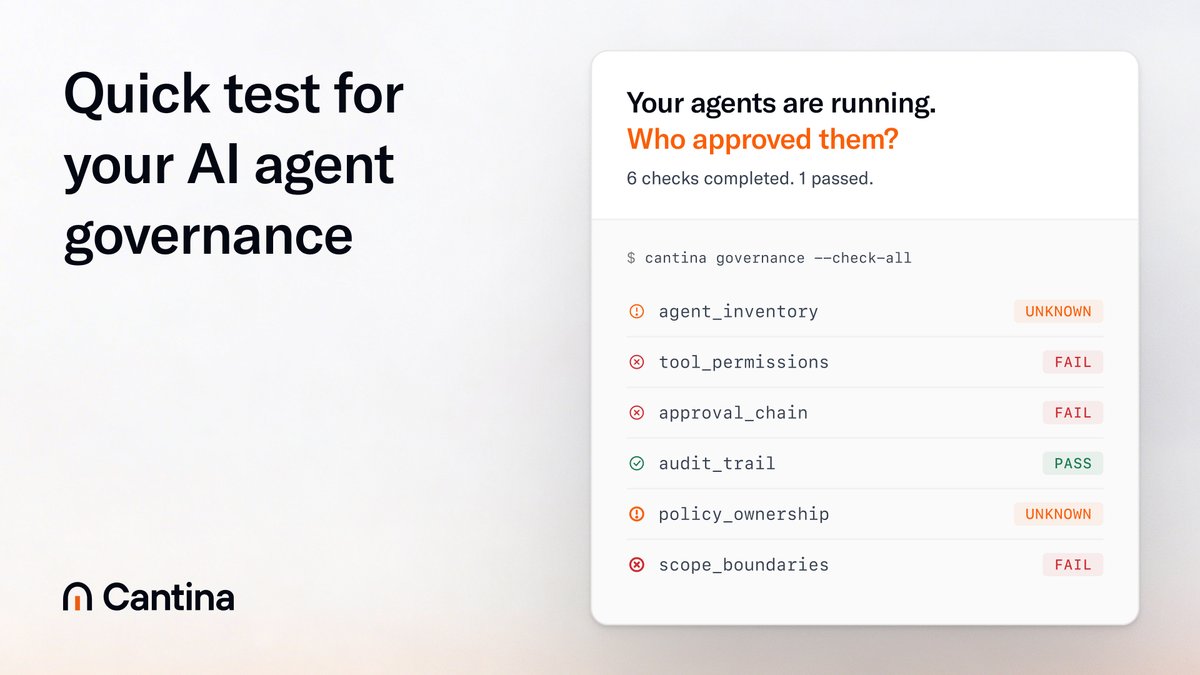
@cantinasecurity continued pushing (10 likes) its agent governance framework, asking: "Can your team answer who owns agent policy, which tools agents can call, and what gets logged when they act?" The accompanying CLI tool showed 6 checks with 3 failures, 2 unknown, and 1 pass.
@matthewhall_com reported that Cloudflare launched isitagentready.com -- a scanner that checks any website's AI-agent readiness across five categories: discoverability, content accessibility, bot access control, protocol discovery (MCP, Agent Skills, WebMCP, OAuth), and commerce (x402).
Discussion insight: Three independent governance tools shipped in a single day: Databricks for coding agent sprawl, Cantina for security posture, Cloudflare for web readiness. This signals governance moving from concept to product.
Comparison to prior day: Yesterday governance was discussed abstractly (cantinasecurity's guide, Chromia's phishing incident). Today it became shippable software from major vendors (Databricks, Cloudflare). The gap between "we need governance" and "here's a governance tool" closed.
1.6 Skill Marketplace Skepticism Emerges 🡒¶
@shawmakesmagic (ElizaOS creator) pushed back sharply (78 likes, 8 bookmarks) against the skill marketplace narrative: "There is no skill marketplace. When Hermes does something successfully, it makes a skill. The risk of downloading a skill is too high, it's the easiest supply chain attack surface in history. Focus on making an agent you use, not a product for a market that doesn't exist."
Meanwhile, Graft continued its coordinated promotional push -- @web3_gord, @ArumBeadlesX, @aisarcore all posted near-identical descriptions of Graft as "a marketplace for AI agent skills" with the same contract address, reinforcing Shaw's skepticism about artificial demand.
@betomoedano took a different approach (70 likes, 97 bookmarks) by crowdsourcing actual skill usage: "What are the best Agent Skills you've built or come across?" The reply thread surfaced concrete tools: react-native-best-practices by @swmansion, agent-device and agent-react-devtools by @callstackio.
Discussion insight: Shaw's critique draws a clear line: self-generated skills (Hermes auto-creates from successful actions) versus downloaded skills (marketplace model). The security argument is specific -- skills execute code, making them a direct supply chain risk.
Comparison to prior day: Yesterday five skill marketplaces launched or expanded. Today the first significant counter-argument arrived from a credible builder. The Graft coordinated campaign (multiple near-identical posts with the same contract address) provided unintentional evidence for Shaw's point about manufactured demand.
1.7 Opus 4.7 vs 4.6: Quantified Behavior Differences 🡕¶
@dimitrioskonst published a head-to-head comparison (5 likes, 3 bookmarks, 2,099 views) of Claude Opus 4.7 vs 4.6 on real monorepo tasks. The results were dramatic: across 5 tasks, 4.6 made 222 tool calls and touched 26 files; 4.7 made 58 tool calls and touched 3 files. Opus 4.6 spawned 6 explore subagents; 4.7 spawned zero. On one task, "4.6 edited billing logic for a race condition it never verified existed. 4.7 refused to touch it."
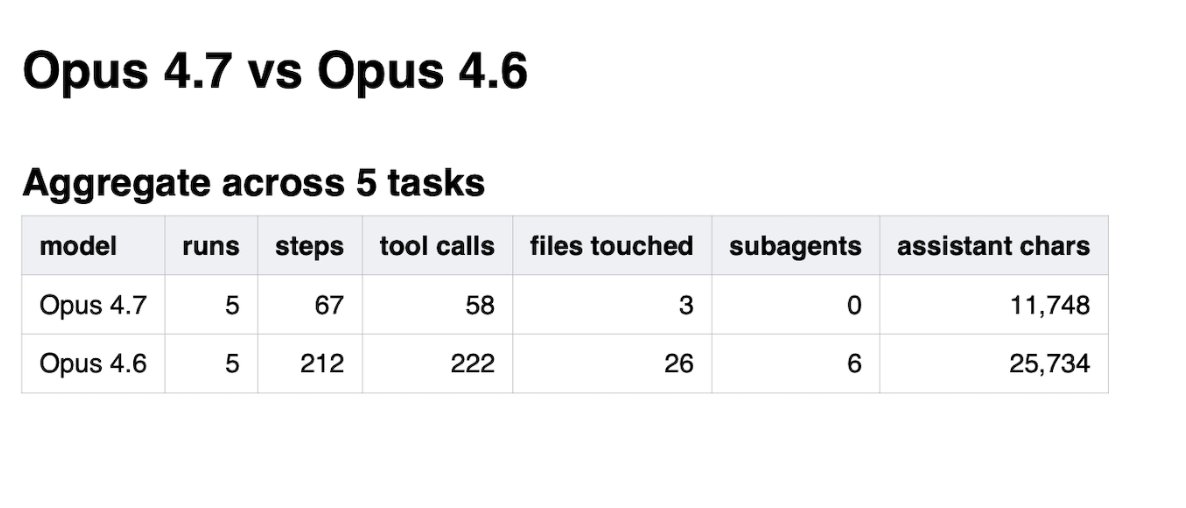
Discussion insight: The data suggests 4.7 represents a fundamental shift in agent behavior -- not just better output but dramatically different operational profile. Fewer actions, fewer files, zero subagents. This has direct implications for harness design: a model that self-constrains changes what the harness needs to do.
Comparison to prior day: No equivalent comparison existed yesterday. This is new quantified evidence on how model updates change agent behavior at the harness level.
1.8 Research Papers Advance Multi-Agent Coordination 🡒¶
Two research papers addressed multi-agent coordination failures from different angles. @jiqizhixin highlighted AgentConductor (9 likes, 4 bookmarks) from Shanghai Jiao Tong University and Meituan: an RL-based system that dynamically reconfigures communication pathways between agents. It achieved 14.6% accuracy improvement in competition-level code generation while cutting token costs by 68%.

@rryssf_ covered PAC-BENCH from Yonsei University -- the first benchmark for multi-agent collaboration under privacy constraints. Key findings: GPT-5.1 paired with itself achieved only 56% joint success; LLaMA paired with itself achieved 6%. Three failure modes emerged: early privacy violations (75% within first 3 turns), over-conservative abstraction (35% of failures), and privacy-induced hallucination (41% of failures). Most striking: which agent initiates the conversation matters more than which model it uses.
@jiqizhixin also shared MindDR (10 likes, 3 bookmarks): a multi-agent deep research framework from Li Auto where a 30B parameter model outperformed comparable open-source systems using a Planning-DeepSearch-Report agent trio.

Discussion insight: PAC-BENCH reveals that privacy-aware multi-agent collaboration is essentially unsolved. The finding that initiator role matters more than model quality has direct implications for enterprise deployments where agents from different organizations must collaborate.
Comparison to prior day: Yesterday had the ACE paper (contexts as dynamic playbooks) and GAM (just-in-time memory). Today added AgentConductor (dynamic topology), PAC-BENCH (privacy-constrained collaboration), and MindDR (small-model deep research). The research pipeline is accelerating.
1.9 Agent Observability Tooling Proliferates 🡕¶
Multiple observability tools shipped. @aijoey announced hermes-hudui crossed 1,000 GitHub stars (10 likes) -- a monitoring dashboard for Hermes agents with 14 tabs, live chat, real-time memory and cost tracking.

@badlogicgames praised (26 likes, 14 bookmarks) a coding agent traces viewer on HuggingFace. @mattpocockuk described his best idea (9 likes): "a coding agent observability platform -- install a plugin which uploads all your session data to a dashboard so you can compare trends over time." @tarunsachdeva launched Traces for Teams (19 likes) for sharing coding agent sessions within teams, with a free plan for startups and open source.
Discussion insight: Agent observability is fragmenting into three layers: per-session traces (HuggingFace viewer), per-agent dashboards (hermes-hudui), and team-level analytics (Traces for Teams). No single tool covers all three.
Comparison to prior day: Yesterday observability was mentioned in passing. Today three products and one product idea all converged on the same need. The speed of hermes-hudui's star growth (0 to 1,000 in one week) signals strong demand.
2. What Frustrates People¶
Custom Harness Overhead vs. Built-In Capabilities -- Severity: High¶
@IceSolst spent time building a custom harness and concluded it added "literally 0 benefit" over plain Claude Code with skills. @HankYeomans replied: "claude code is also a harness -- have you tried using its harness with something else?" The exchange reveals a conceptual confusion: practitioners are building harnesses on top of tools that already are harnesses, creating redundant layers. No clear guide exists for when a custom harness adds value versus when the built-in agent harness is sufficient.
Multi-Agent Memory Loss -- Severity: High¶
@georgeorch captured widespread frustration (202 likes, 10,718 views): "I find how agents lose context so fascinating, like why do you forget everything the moment I need you most?" @timourxyz identified a systemic gap: "One thing seemingly missing in agent land are memory benchmarks. I try every memory system that gets enough traction here with a few personal tests, but I want to see how different frameworks and agents perform on a series of established tests." No standard memory benchmark exists.
Skill Supply Chain Security -- Severity: Medium¶
@shawmakesmagic called skill downloads "the easiest supply chain attack surface in history." Skills execute code in the agent's context. @cybernewslive reported a design flaw in MCP "that lets attackers run commands on the computers of anyone who installs a malicious tool." The combination of executable skills and MCP vulnerabilities creates a compounding risk surface with no mitigation standard.
3. What People Wish Existed¶
Agent Memory Benchmarks¶
@timourxyz asked for standardized memory benchmarks. @georgeorch expressed the user-facing symptom (202 likes): agents that forget at the worst moments. @burkov shared the GAM paper proposing just-in-time memory, but no benchmark evaluates whether these approaches actually work across frameworks. The demand is for a standardized evaluation suite -- not another memory system.
Coding Agent Observability Platform¶
@mattpocockuk described the missing product: "Install a plugin which uploads all your session data to a dashboard so you can compare trends over time." @alexhillman described storing session transcripts with parsed metadata columns for user messages, agent messages, tool calls, and files touched. Multiple teams are building custom solutions (hermes-hudui, Traces for Teams, HuggingFace viewer), but no cross-agent observability standard exists.
Privacy-Aware Multi-Agent Coordination¶
The PAC-BENCH paper from Yonsei University quantified the gap: even GPT-5.1 paired with itself achieves only 56% success on tasks requiring private information sharing. @abundand confirmed: "this has killed every multi-agent build I've tried to ship." Enterprise deployments where agents from different departments or organizations must collaborate have no coordination mechanism that preserves privacy.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude Code | Coding agent | (+) | Built-in harness, skills, design features extractable as skills | IceSolst found custom harness redundant on top of it |
| Codex (OpenAI) | General agent | (+) | Computer use, browser, plugins, automations, multi-terminal | Positioning as "agent runtime" still new |
| Hermes Agent | Multi-agent framework | (+) | Gemini Voice TTS, Umbrel self-hosting, persistent memory, auto-skill creation | Complex setup, multiple competing skill sources |
| Warp | Terminal UI | (+) | Rich text input, @-menu for context, voice input, /remote control for mobile | Terminal-only |
| HeyGen Skills | Video production | (+) | Persistent avatar, MCP + CLI auto-detect, prompt engineering | Single vendor dependency |
| RepoPrompt | Agent orchestration | (+) | Manages multiple agent CLIs via MCP, dynamic tool availability | Niche adoption |
| cmux | Terminal | (+) | Ghostty-based, vertical tabs, notification rings, 14K GitHub stars | macOS only |
| Parakeet | Local voice STT | (+) | Local inference, low latency, works with any coding agent | Requires macOS setup, polarizing workflow fit |
| LangGraph | Multi-agent framework | (+) | Cisco enterprise validation, LangSmith integration | Framework lock-in |
| Databricks Unity AI Gateway | Agent governance | (+) | Centralized usage tracking, rate limiting across Cursor/Gemini/Codex | Enterprise-only, early stage |
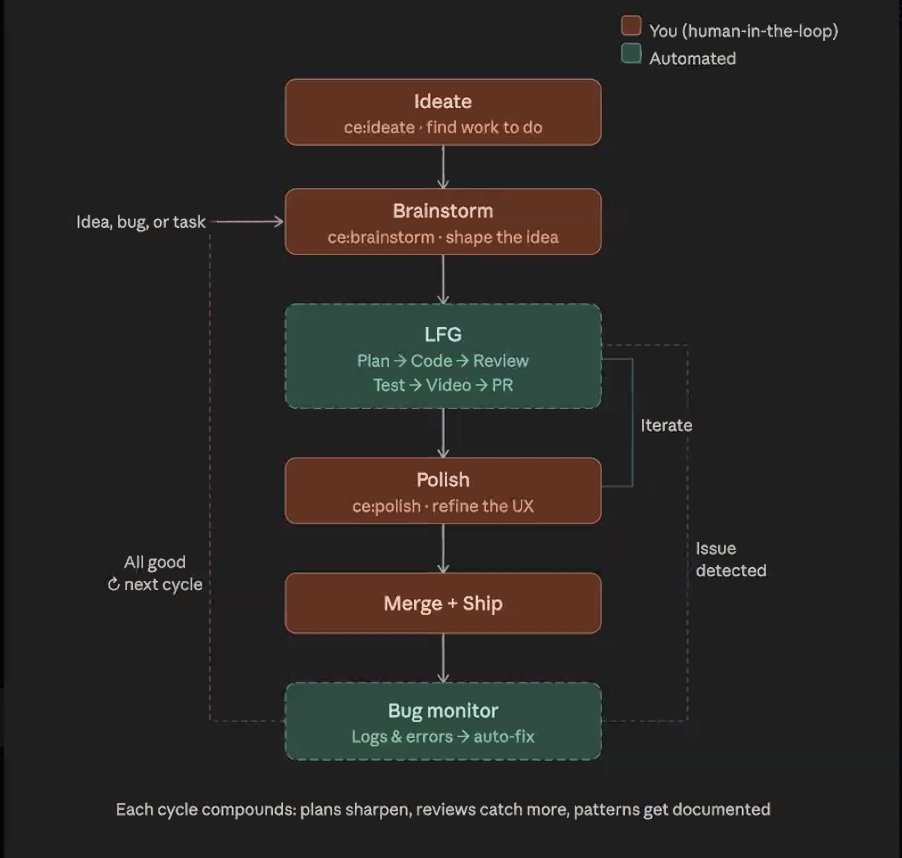
The "compound engineering" pattern (@ridegoodwaves, citing @kieranklaassen and @danshipper) formalized a workflow: ideate before code, let agents handle the middle, polish after the PR, save plans in the repo as context for agents and postmortems. @DAIEvolutionHub described the git worktrees pattern enabling 4-8 parallel agents, each in its own branch.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Vibe-Video | @ashpreetbedi | Multi-agent team turning research into motion-graphics videos | Video production requires manual timeline editing | HeyGen Hyperframes, Opus 4.7 | Open-source | Tweet |
| OpenFang | @openfangg | Rust-based agent OS, 137K LOC, runs offline on Raspberry Pi | Agent frameworks are Python wrappers, not true OS | Rust, 14 crates, MIT | v0.5.10, open-source | GitHub |
| hermes-hudui | @aijoey | Monitoring dashboard for Hermes agents: 14 tabs, live chat, memory + cost tracking | No observability into running Hermes agents | - | v0.5.0, 1K stars | Tweet |
| Traces for Teams | @tarunsachdeva | Shared coding agent session viewer for teams | No way to share and compare agent sessions across a team | - | Launched, free tier | Tweet |
| pro-workflow | @DanKornas | Self-correcting memory, reusable skills, agent teamwork for Claude Code + Cursor | Agents lack self-correction loops | npm, 1K stars | v1.3.0 | Tweet |
| ClawGUI | Zhejiang University | Complete GUI agent pipeline: train, evaluate, deploy to real phones | GUI agents lack end-to-end training-to-deployment pipeline | ClawGUI-RL, ClawGUI-Eval, ClawGUI-Agent | Open-source | Tweet |
| Reah for Agents | @charleswayn | Financial accounts for AI agents with scoped permissions, approval flows | Agents need real financial power within guardrails | Ledger-level traceability | Live for individuals | Tweet |
| isitagentready.com | Cloudflare | Scans websites for AI-agent readiness across 5 categories | No standard way to check if a site is discoverable by agents | MCP, Agent Skills, OAuth, x402, WebMCP | Live | Tweet |
| Tidewave | @josevalim | Agent tooling for Elixir: UI variants, vision mode, code reviews, browser agent | Elixir ecosystem lacks agent tooling | Elixir | Shipping weekly | Tweet |
Notable: @ihtesham2005 reported that ClawGUI's 2B parameter model outperformed Qwen3-VL-32B on GUI agent tasks -- 16x smaller with better results. This continues the trend of small, specialized models beating general-purpose large ones in constrained domains.
6. New and Notable¶
Cloudflare Ships AI Agent Readiness Scanner¶
@matthewhall_com reported Cloudflare's launch of isitagentready.com, which scans any website across five categories: discoverability (robots.txt, sitemap), content accessibility (markdown negotiation), bot access control, protocol discovery (MCP, Agent Skills, WebMCP, OAuth), and commerce (x402, UCP, ACP). This is the first major infrastructure vendor to define "agent readiness" as a measurable property of web properties.
SIGIR 2026 Paper Introduces Marketplace Evaluation for Agents¶
@TEKnologyy announced (9 likes) acceptance of "Evaluation of Agents under Simulated AI Marketplace Dynamics" at SIGIR 2026. The paper introduces a simulation-based paradigm that evaluates information access systems as marketplace participants, measuring retention and market share rather than only accuracy. This formalizes the competitive dynamics that skill marketplaces are already creating.
Opus 4.7 Drastically Reduces Agent Footprint¶
@dimitrioskonst's benchmark data showed Opus 4.7 making 3.8x fewer tool calls, touching 8.7x fewer files, and spawning zero subagents compared to 4.6 on identical tasks. On a billing logic task, 4.7 refused to edit code for an unverified race condition that 4.6 modified without hesitation. This represents a qualitative shift in model behavior that will change how harnesses are designed.
MongoDB Ships Claude Marketplace Plugin with Agent Skills¶
@MongoDB announced (14 likes, 6 bookmarks) its plugin on the Claude Marketplace with Agent Skills for MongoDB workflows and an MCP Server for context-aware guidance. Database vendors are now shipping agent skills as a distribution channel for developer tooling.
7. Where the Opportunities Are¶
[+++] Agent Observability Across the Full Stack. hermes-hudui hit 1K stars in a week. mattpocockuk described the missing platform. Traces for Teams launched. badlogicgames praised a HuggingFace trace viewer. But no single tool spans per-session traces, per-agent dashboards, and team-level analytics. The first cross-agent observability platform that works with Claude Code, Codex, Hermes, and Cursor captures the entire emerging market. (source)
[+++] Voice-First Agent Interfaces. thdxr's post (653 likes, 188 bookmarks) proved voice-to-agent is a massive unlock. Gemini TTS shipped in Hermes. Kiro and ElevenLabs launched a voice hackathon. garrytan had a consumer moment in Taipei. But the stack is fragmented: Parakeet for STT, Gemini for TTS, no integrated voice-native agent shell. The first terminal or IDE that ships with built-in voice dictation optimized for agent prompting captures the input-modality advantage. (source)
[++] Enterprise Coding Agent Governance. Databricks shipped Unity AI Gateway for coding agents. Cantina shipped a governance CLI. Cloudflare shipped isitagentready.com. Three vendors entered simultaneously, validating the category. The gap: no unified governance layer spans web readiness, tool permissions, spend controls, and session audit across all major coding agents. (source)
[++] Harness Design Patterns for When Not to Harness. IceSolst's failed harness (82 likes) and garrytan's rebuttal crystallize the core question: when does a custom harness add value, and when is the agent's built-in harness sufficient? A decision framework or diagnostic tool ("does your use case need a custom harness?") would resolve the confusion that is burning practitioner time. (source)
[+] Privacy-Aware Multi-Agent Protocols. PAC-BENCH showed even GPT-5.1 achieves only 56% success under privacy constraints. Enterprise multi-agent deployments across departments or organizations are blocked by the absence of coordination mechanisms that preserve information boundaries. The first protocol that solves this captures regulated industries. (source)
[+] Agent Memory Benchmarks. timourxyz asked for them directly. georgeorch's 202-like post quantified the user frustration. Every memory framework claims improvement, but no standardized evaluation exists. The first published benchmark suite that tests memory across frameworks becomes the industry reference. (source)
8. Takeaways¶
-
Harness engineering is being stress-tested. IceSolst's "zero benefit" experience (82 likes) and the lopopolo-Zechner philosophical schism challenged the harness-engineering-as-salvation narrative from the day prior. garrytan's rebuttal and lopopolo's lightweight markdown automation approach suggest the answer is nuanced: harnesses add value at scale, but the built-in agent harness is often sufficient for individual use. (source)
-
Voice input is the biggest agent productivity unlock practitioners have found. thdxr's observation (653 likes, 188 bookmarks) that dictation, not agent improvements, drove the biggest workflow gain inverts the usual narrative. The combination of local Parakeet STT models with agent workflows removes a bottleneck most people did not realize they had. (source)
-
Multi-agent patterns are converging on writer-evaluator as the minimal viable architecture. georgeorch reversed his skepticism (170 likes). petergyang and DimitriGilbert independently described the same build-then-review pattern. The framework shift: multi-agent is no longer about "more agents" but about the simplest effective delegation. (source)
-
Coding agent governance became shippable software in a single day. Databricks Unity AI Gateway, Cantina's governance CLI, and Cloudflare's isitagentready.com all shipped production tooling. The enterprise gatekeeping question moved from "we need governance" to "which governance tool do we adopt." (source)
-
Opus 4.7 represents a behavioral paradigm shift for agent harness design. dimitrioskonst's data showed 3.8x fewer tool calls and zero subagent spawning compared to 4.6 on identical tasks. A model that self-constrains changes what the harness needs to provide -- the shift from "restrain the agent" to "the agent restrains itself." (source)
-
Skill marketplace skepticism arrived from a credible source. Shaw (ElizaOS creator) called downloaded skills "the easiest supply chain attack surface in history." Combined with a reported MCP design flaw enabling remote command execution, the security surface of agent skill ecosystems is widening faster than the mitigation tooling. (source)
-
Privacy-constrained multi-agent collaboration is essentially unsolved. PAC-BENCH's 56% success rate for GPT-5.1 paired with itself, and the discovery that initiator role matters more than model quality, establishes a hard ceiling on enterprise multi-agent deployments across trust boundaries. (source)