Twitter AI 智能体 - 2026-04-17¶
1. 人们在讨论什么¶
1.1 Harness Engineering 争论升温 🡕¶
4 月 16 日的 harness engineering 讨论继续加速。@akshay_pachaar 的 三阶段框架(从 weights 到 context 再到 harness)在第二天仍是整个数据集中热度最高的帖子,已达到 606 个点赞、797 次收藏和 76,723 次浏览。核心论点是:“模型不再是智能唯一所在的位置。它位于一个 harness 之中,里面包含持久记忆、可复用技能、标准化协议(如 MCP 和 A2A)、执行沙箱、审批门,以及可观测性层。”

@aiDotEngineer 推广了一场大会演讲(41 个点赞、46 次收藏、15,311 次浏览),主讲人为 @_lopopolo,题为 “Harness Engineering: How to Build Software When Humans Steer, Agents Execute”。讨论串捕捉到一个关键哲学分歧:@SamanvayaY 指出这“正好和 Mario Zechner 的核爆式观点相反——Ryan:‘代码是免费的。禁用编辑器。开除 15-5000 个 agents。’Mario:‘每一行都要他妈读完,否则你会失去理解。’”@Samward 回复:“智能体规模的上限取决于刹车质量,而不是马力。”
随后反向叙事出现。@IceSolst 发布了一条上手后的反驳(82 个点赞、35 次收藏):“我在构建一个 harness,让 agent 跑扫描。它完全是垃圾。完全没用。相比直接用 Claude Code,收益真的是 0。”@garrytan 回击(12 个点赞)另一篇批评 agents 的文章:“那篇文章里每一个失败例子,都是裸 LLM 交互!没有 skills,没有 harness,没有 deterministic code。”
@_lopopolo 描述了自己已经稳定下来的做法(8 个点赞、10 次收藏):“automations 放在 docs/automations 里的 markdown 文件中。codex app 的 automation prompt 只需要 2 句话。”
讨论要点: Harness 争论分裂成三派:信徒把 harness 设计视为主要工程学科;怀疑者认为 Claude Code 内置能力已经足够;实用派则使用轻量级 markdown automation。@Samward 的评论——“刹车质量,而不是马力”——概括了正在形成的共识:harness 的价值在于约束,而不是能力本身。
与前日对比: 昨天,讨论基本单向扩散——harness engineering 成为 canonical framework。今天则出现了有组织的反驳(IceSolst 的实践失败、Zechner-lopopolo 分歧),同时采用仍在继续。这个概念不只是传播;它正在接受压力测试。
1.2 Voice-First 智能体交互突破 🡕¶
@thdxr 发布了当天互动量第二高的帖子(653 个点赞、188 次收藏、29,406 次浏览):“最近对我编码工作流影响最大的,不是什么 agent 相关的东西——而是意识到这些本地 parakeet 语音模型有多好,然后直接把所有内容 dictating into opencode。”他分享了一个 macOS 入门工具(后续回复获得 112 个点赞、147 次收藏)。
@zazmic_inc 解释了机制:“打字会迫使你压缩和简写,agent 因此得到更差的 prompt;而口述能让你给出完整上下文,包括那些平时因为懒而会删掉的部分。”
与此同时,@Teknium 为 Hermes-Agent 增加了 Gemini Voice TTS(112 个点赞、49 次收藏),并提供 free tier 选项。@garrytan 描述 自己在台北测试一个智能日程 voice agent——一名空乘马上问“那是什么,我现在能用吗?”@kirodotdev 发起 Kiro x ElevenLabs 黑客松(51 个点赞、34 次收藏),专门面向 voice-powered apps,奖金为 10K 美元。
讨论要点: thdxr 的 framing 很重要,因为它反转了常见叙事。生产力提升不是来自智能体本身,而是来自改变人的输入模态。@solomonneas 提供了反向观点:“这真的会拖慢我的工作流。我需要打字来放慢思考并把话说清楚”——说明 voice-first 会因认知风格而分化。
与前日对比: 昨天,voice 只出现在一个场景中(Hermes TTS 集成)。今天,它成为独立的生产力论点(thdxr)、消费者时刻(garrytan 的空乘)、黑客松类别(Kiro x ElevenLabs)和基础设施部件(Gemini Voice in Hermes)。Voice 从功能跨成了主题。
1.3 HeyGen Skills 与 Agent-Native 视频继续扩张 🡕¶
@rileybrown 把 Claude 的新设计功能提取成可复用 agent skill(226 个点赞、275 次收藏、17,313 次浏览),并展示它在 Codex 中配合 web preview 工作。多个账号放大了 HeyGen Skills:@JibrilQanqadar 宣称 “Loom is officially on notice”(31 个点赞、5,675 次浏览),描述跨 sessions 的持久 avatar identity。@manishkumar_dev 指出:“只需描述一次你的 avatar,HeyGen Skills 就会构建它,并在每个视频中复用。”
@ashpreetbedi 介绍 Vibe-Video(48 个点赞、50 次收藏),这是一个用 HeyGen Hyperframes 和 Opus 4.7 构建的开源多智能体团队,可把研究主题变成 motion-graphics videos。@AndyMarlowg 描述 了一个 CREAO agent,使用 Opus 4.7 写作、Gemini 3.1 TTS 配音,把新闻变成喜剧——“一个 agent 就能把新闻变成喜剧”(62 次收藏)。
讨论要点: HeyGen Skills 模式正在收敛到一个具体工作流:描述一次 avatar,agent 记住它,自动生成面向 prompt 优化的视频。rileybrown 把 skill 从 Claude 提取到 Codex,说明跨智能体 skill portability 正在变得实用。
与前日对比: 昨天,HyperFrames 发布并确立了视频品类。今天,采用浪潮到来:从业者在提取 skills、基于它们构建新东西,并宣称 incumbent tools “on notice”。视频智能体品类从公告进入生态阶段。
1.4 多智能体编排获得实践证据 🡕¶
@georgeorch 用三条高互动帖子主导了多智能体讨论。他 逆转了此前的怀疑(170 个点赞、7,053 次浏览):“我过去会跳过 ‘multi-agent’ setups,觉得它们过度设计。我错了。他们是对的。一个 agent 是工具。四个 agents 是一门生意。”他还 强调了记忆问题(202 个点赞、10,718 次浏览):“为什么你总是在我最需要你的时候忘掉一切?”
@camsoft2000 描述(19 个点赞、11 次收藏)RepoPrompt 的 orchestration 如何同时管理 Codex 和 Claude Code:“main agent 杀掉了一个 subagent,防止它在一个 issue 上 thrashing。”@DAIEvolutionHub 报告 团队通过 git worktrees 并行运行 4-8 个 agents:“Agent 1 构建,Agent 2 测试,Agent 3 安全,Agent 4 重构,Agent 5 写文档。”
@petergyang 分享了一个实用模式(13 个点赞、7 次收藏):“我总是要求 AI 拉起一个独立 eval agent,做 yes/no checks 来给第一个 agent 的输出打分。”@theAIdreamer 确认:“Writer agent 接到 editor agent,后者把 style guide 作为 context。editor 会拒绝 40% 的 drafts。”

讨论要点: writer-evaluator 模式(构建 agent + 审查 agent)正在成为一种简单、可重复的多智能体架构。petergyang 和 DimitriGilbert 都独立描述了同一模式,说明最小可行 multi-agent setup 正在收敛。
与前日对比: 昨天,多智能体讨论在 0xSero 的实证证据和 georgeorch 的怀疑之间分裂。今天 georgeorch 转向,而多个从业者独立描述了可行模式。争论从“multi-agent 是否有效?”转向“最简单有效的 multi-agent 模式是什么?”
1.5 编程智能体治理进入企业工具 🡕¶
@databricks 宣布 Unity AI Gateway 支持 Coding Agents(27 个点赞、15 次收藏):为 coding agents 提供集中治理,包含用量跟踪、限流和 inference tables。该架构让 Cursor、Gemini CLI 和 Codex CLI 通过单一 AI Gateway 路由。

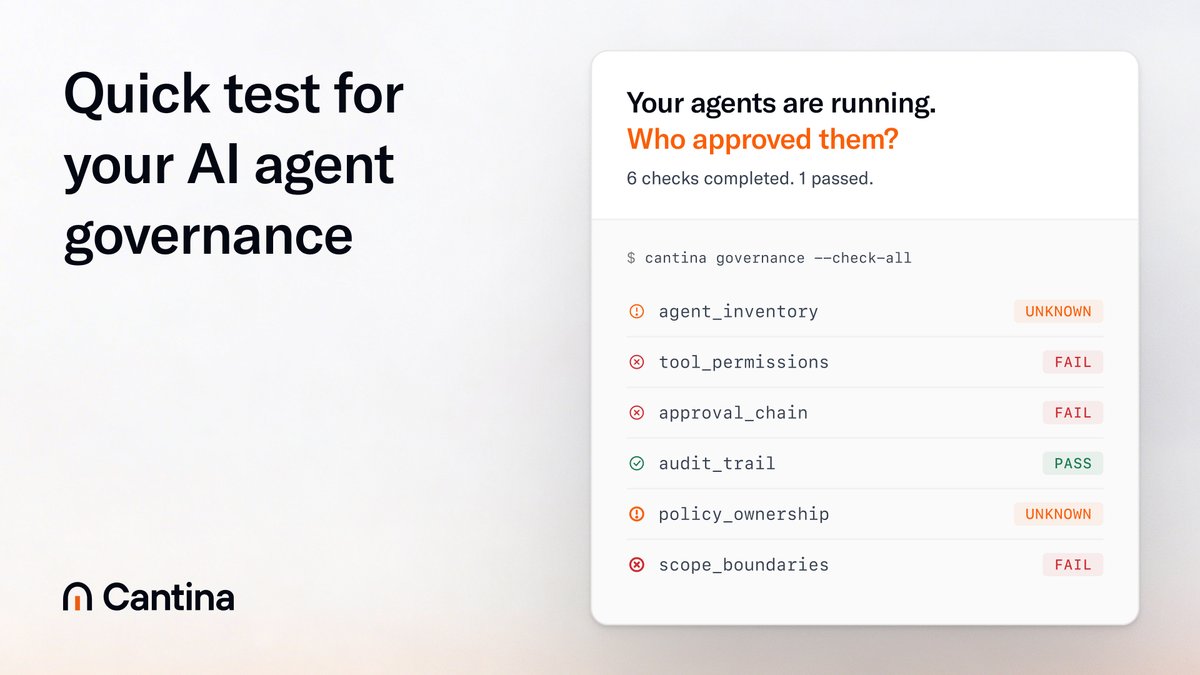
@cantinasecurity 继续推进(10 个点赞)自己的 agent governance framework,并追问:“你的团队能回答谁拥有 agent policy、agents 能调用哪些工具,以及它们行动时记录什么吗?”配套 CLI 工具显示 6 项检查中有 3 项失败、2 项未知、1 项通过。
@matthewhall_com 报告,Cloudflare 发布了 isitagentready.com——一个扫描器,用五个类别检查任意网站的 AI-agent readiness:discoverability、content accessibility、bot access control、protocol discovery(MCP、Agent Skills、WebMCP、OAuth)和 commerce(x402)。
讨论要点: 三个独立治理工具在同一天发布:Databricks 针对 coding agent sprawl,Cantina 针对安全态势,Cloudflare 针对 Web readiness。这说明治理正在从概念走向产品。
与前日对比: 昨天,governance 主要还是抽象讨论(cantinasecurity 的指南、Chromia 的 phishing incident)。今天,它变成了 Databricks、Cloudflare 等大厂可交付的软件。“我们需要治理”到“这里有治理工具”之间的距离被缩短了。
1.6 技能市场怀疑开始出现 🡒¶
@shawmakesmagic(ElizaOS creator)强烈反对(78 个点赞、8 次收藏)技能市场叙事:“没有 skill marketplace。当 Hermes 成功做成某件事时,它会创建一个 skill。下载 skill 的风险太高,这是史上最容易变成供应链攻击面的东西。专注于做一个你自己会用的 agent,而不是给一个并不存在的市场做产品。”
与此同时,Graft 继续协调式推广——@web3_gord、@ArumBeadlesX、@aisarcore 都发布了几乎相同的 Graft 描述,称其为“a marketplace for AI agent skills”,并附上同一个 contract address,进一步强化了 Shaw 对人造需求的怀疑。
@betomoedano 采取了另一种做法(70 个点赞、97 次收藏),众包真实的 skill 使用情况:“你构建或见过的最佳 Agent Skills 是哪些?”回复串浮现出一些具体工具:@swmansion 的 react-native-best-practices,以及 @callstackio 的 agent-device 和 agent-react-devtools。
讨论要点: Shaw 的批评划出了一条清晰边界:自生成 skills(Hermes 从成功动作中自动创建)对比下载 skills(marketplace model)。安全论点很具体——skills 会在 agent 的上下文里执行代码,因此直接构成供应链风险。
与前日对比: 昨天,有五个 skill marketplaces 发布或扩展。今天,可信 builder 发出了第一条有分量的反对意见。Graft 的协调式推广(多条几乎相同的帖子,带相同 contract address)反而为 Shaw 关于人造需求的观点提供了意外证据。
1.7 Opus 4.7 vs 4.6:量化行为差异 🡕¶
@dimitrioskonst 发布了 Claude Opus 4.7 与 4.6 的头对头比较(5 个点赞、3 次收藏、2,099 次浏览),任务是真实 monorepo。结果差异很大:在 5 个任务中,4.6 进行了 222 次 tool calls,并修改了 26 个文件;4.7 进行了 58 次 tool calls,只修改了 3 个文件。Opus 4.6 启动了 6 个 explore subagents;4.7 没有启动任何一个。某个任务中,“4.6 修改了 billing logic 来处理一个它从未验证过是否存在的 race condition。4.7 拒绝动它。”
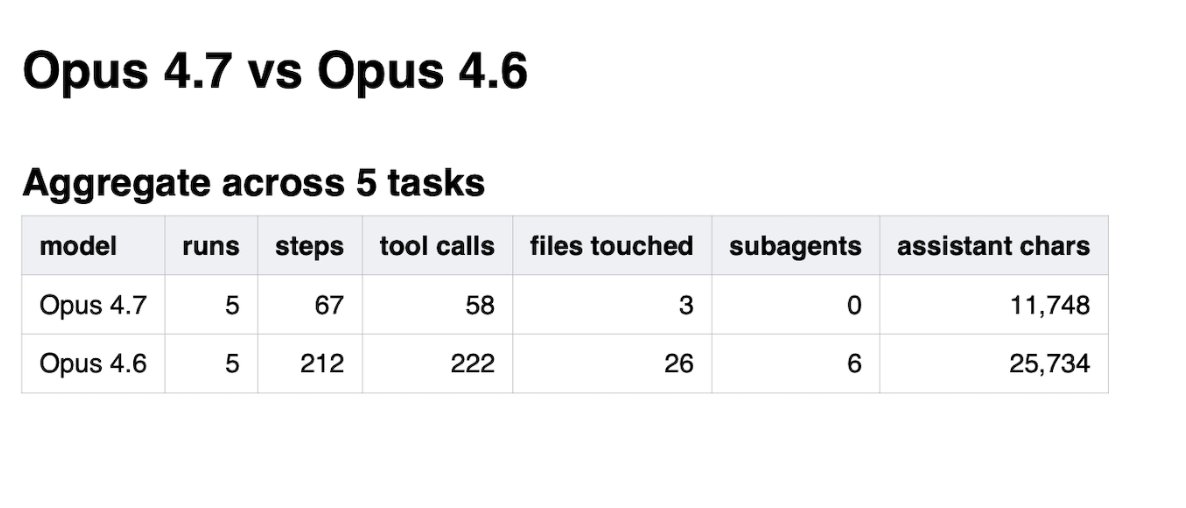
讨论要点: 数据表明 4.7 代表了一种智能体行为的根本变化——不只是输出更好,而是操作画像完全不同。动作更少、文件更少、零 subagents。这对 harness design 有直接影响:一个会自我约束的模型,会改变 harness 需要承担的职责。
与前日对比: 昨天没有类似比较。这是关于模型更新如何在 harness level 改变 agent behavior 的新量化证据。
1.8 研究论文推动多智能体协调 🡒¶
两篇研究论文从不同角度处理多智能体协调失败。@jiqizhixin 介绍 AgentConductor(9 个点赞、4 次收藏),来自上海交通大学和美团:这是一个基于 RL 的系统,可动态重配置 agents 之间的通信路径。在竞赛级代码生成中,它将准确率提高 14.6%,同时把 token 成本降低 68%。

@rryssf_ 报道 PAC-BENCH,来自 Yonsei University——第一个针对隐私约束下 multi-agent collaboration 的 benchmark。关键发现包括:GPT-5.1 与自身配对时 joint success 只有 56%;LLaMA 与自身配对只有 6%。出现了三类失败模式:早期 privacy violations(75% 发生在前 3 轮内)、过度保守抽象(35% 的失败)和 privacy-induced hallucination(41% 的失败)。最惊人的是:哪个 agent 发起对话,比它使用哪个模型更重要。
@jiqizhixin 还 分享 MindDR(10 个点赞、3 次收藏):这是理想汽车的 multi-agent deep research framework,一个 30B 参数模型通过 Planning-DeepSearch-Report 三智能体组合,超过了同类开源系统。

讨论要点: PAC-BENCH 揭示,privacy-aware multi-agent collaboration 基本还没有解决。发起者角色比模型质量更重要,这一发现对企业部署有直接影响,因为不同组织或部门的 agents 必须协作时,信息边界不能被打穿。
与前日对比: 昨天有 ACE 论文(上下文作为动态 playbooks)和 GAM(just-in-time memory)。今天新增了 AgentConductor(动态拓扑)、PAC-BENCH(隐私约束协作)和 MindDR(小模型 deep research)。研究 pipeline 正在加速。
1.9 智能体可观测性工具增多 🡕¶
多个可观测性工具发布。@aijoey 宣布 hermes-hudui 达到 1,000 个 GitHub stars(10 个点赞)——这是一个 Hermes agents 监控 dashboard,包含 14 个 tabs、live chat、实时 memory 和 cost tracking。

@badlogicgames 称赞(26 个点赞、14 次收藏)了 HuggingFace 上的一个 coding agent traces viewer。@mattpocockuk 描述了自己最好的想法(9 个点赞):“一个 coding agent observability platform——安装一个插件,把所有 session data 上传到 dashboard,让你能比较一段时间内的趋势。”@tarunsachdeva 发布 Traces for Teams(19 个点赞),用于在团队内部分享 coding agent sessions,并为 startups 和 open source 提供 free plan。
讨论要点: Agent observability 正在分裂成三层:per-session traces(HuggingFace viewer)、per-agent dashboards(hermes-hudui)和 team-level analytics(Traces for Teams)。还没有一个工具覆盖全部三层。
与前日对比: 昨天可观测性只是顺带提到。今天,三个产品和一个产品想法都汇聚到同一需求上。hermes-hudui 的 star 增长速度(1 周从 0 到 1,000)说明需求很强。
2. 令人困扰的问题¶
自定义 Harness 开销 vs. 内置能力 -- Severity: High¶
@IceSolst 花时间构建了一个自定义 harness,最后认为它相比直接用带 skills 的 Claude Code “literally 0 benefit”。@HankYeomans 回复:“claude code 本身也是一个 harness——你试过把它的 harness 用到别的东西上吗?”这次交流暴露出概念混乱:从业者在本来已经是 harness 的工具之上继续构建 harness,导致层级冗余。还没有清晰指南说明什么时候自定义 harness 有价值,什么时候内置 agent harness 已经足够。
多智能体记忆丢失 -- Severity: High¶
@georgeorch 捕捉到了广泛挫败感(202 个点赞、10,718 次浏览):“我觉得 agents 丢上下文这件事太有意思了,为什么你总是在我最需要你的时候忘掉一切?”@timourxyz 指出一个系统性缺口:“agent land 里似乎缺少的一件事是 memory benchmarks。我会用几个个人测试去试每个在这里有足够 traction 的 memory system,但我想看到不同 frameworks 和 agents 在一系列 established tests 上表现如何。”目前没有标准 memory benchmark。
技能供应链安全 -- Severity: Medium¶
@shawmakesmagic 称 skill downloads 是“史上最容易变成供应链攻击面的东西”。Skills 会在 agent 的上下文中执行代码。@cybernewslive 报道 MCP 中存在一个设计缺陷,“会让攻击者在任何安装恶意工具的人的电脑上运行命令”。可执行 skills 与 MCP 漏洞结合,会形成复合风险面,而且还没有缓解标准。
3. 人们期望的功能¶
智能体记忆基准¶
@timourxyz 希望看到 标准化 memory benchmarks。@georgeorch 表达了面向用户的症状(202 个点赞):agents 总在最糟糕的时候遗忘。@burkov 分享了 GAM 论文,提出 just-in-time memory,但还没有 benchmark 能评估这些方法是否真的跨 frameworks 有效。需求是一个标准化 evaluation suite——而不是又一个 memory system。
编程智能体可观测性平台¶
@mattpocockuk 描述 了缺失产品:“安装一个插件,把所有 session data 上传到 dashboard,让你能比较一段时间内的趋势。”@alexhillman 描述 把 session transcripts 存起来,并解析出 user messages、agent messages、tool calls 和 touched files 等 metadata columns。多个团队正在构建自用方案(hermes-hudui、Traces for Teams、HuggingFace viewer),但还没有 cross-agent observability standard。
隐私感知的多智能体协调¶
Yonsei University 的 PAC-BENCH 论文 量化了这个缺口:即便 GPT-5.1 与自身配对,在需要共享私密信息的任务中也只有 56% 的成功率。@abundand 确认:“这已经杀死了我尝试交付的每一个 multi-agent build。”不同部门或组织的 agents 需要协作的企业部署,还没有一种能保住隐私边界的协调机制。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Claude Code | Coding agent | (+) | 内置 harness、skills、可提取为 skills 的设计功能 | IceSolst 认为在它之上构建自定义 harness 是冗余的 |
| Codex (OpenAI) | General agent | (+) | Computer use、browser、plugins、automations、multi-terminal | “agent runtime” 定位仍然新 |
| Hermes Agent | Multi-agent framework | (+) | Gemini Voice TTS、Umbrel self-hosting、持久记忆、自动创建 skills | 设置复杂,多个 competing skill sources |
| Warp | Terminal UI | (+) | 富文本输入、用于 context 的 @-menu、语音输入、用于移动端的 /remote control | 仅限 terminal |
| HeyGen Skills | Video production | (+) | 持久 avatar、MCP + CLI auto-detect、prompt engineering | 单一 vendor dependency |
| RepoPrompt | Agent orchestration | (+) | 通过 MCP 管理多个 agent CLIs、动态 tool availability | 采用范围较窄 |
| cmux | Terminal | (+) | 基于 Ghostty、vertical tabs、notification rings、14K GitHub stars | 仅限 macOS |
| Parakeet | Local voice STT | (+) | 本地推理、低延迟、可配合任何 coding agent | 需要 macOS 设置,工作流适配分化 |
| LangGraph | Multi-agent framework | (+) | Cisco 企业验证、LangSmith 集成 | Framework lock-in |
| Databricks Unity AI Gateway | Agent governance | (+) | 跨 Cursor/Gemini/Codex 的集中用量跟踪与限流 | 仅面向企业,早期阶段 |
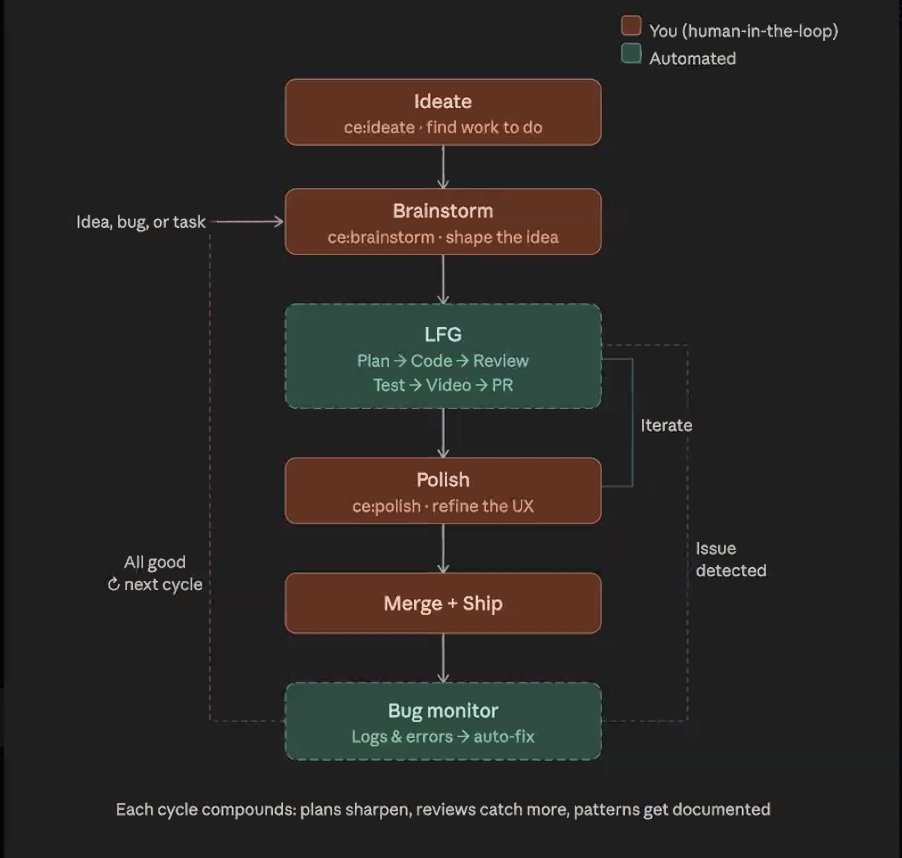
“compound engineering” 模式(@ridegoodwaves,引用 @kieranklaassen 和 @danshipper)把一种工作流正式化:先在写代码前构思,让 agents 处理中间部分,PR 后再 polish,把计划保存在 repo 中,作为 agents 和 postmortems 的上下文。@DAIEvolutionHub 描述了 git worktrees 模式,让 4-8 个并行 agents 各自在自己的 branch 中工作。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Vibe-Video | @ashpreetbedi | 将研究转成 motion-graphics videos 的多智能体团队 | 视频制作需要手动 timeline editing | HeyGen Hyperframes, Opus 4.7 | Open-source | Tweet |
| OpenFang | @openfangg | 基于 Rust 的 agent OS,137K LOC,可离线运行在 Raspberry Pi 上 | Agent frameworks 只是 Python wrappers,不是真正 OS | Rust, 14 crates, MIT | v0.5.10, open-source | GitHub |
| hermes-hudui | @aijoey | Hermes agents 监控 dashboard:14 个 tabs、live chat、memory + cost tracking | 运行中的 Hermes agents 缺少可观测性 | - | v0.5.0, 1K stars | Tweet |
| Traces for Teams | @tarunsachdeva | 面向团队共享 coding agent sessions 的 viewer | 无法跨团队分享和比较 agent sessions | - | Launched, free tier | Tweet |
| pro-workflow | @DanKornas | 面向 Claude Code + Cursor 的自纠错记忆、可复用 skills、agent teamwork | Agents 缺少 self-correction loops | npm, 1K stars | v1.3.0 | Tweet |
| ClawGUI | Zhejiang University | 完整 GUI agent pipeline:训练、评估、部署到真机 | GUI agents 缺少端到端 train-to-deployment pipeline | ClawGUI-RL, ClawGUI-Eval, ClawGUI-Agent | Open-source | Tweet |
| Reah for Agents | @charleswayn | 面向 AI agents 的金融账户,带 scoped permissions 和 approval flows | Agents 需要在护栏内获得真实金融能力 | Ledger-level traceability | Live for individuals | Tweet |
| isitagentready.com | Cloudflare | 跨 5 个类别扫描网站的 AI-agent readiness | 没有标准方式检查网站是否可被 agents 发现 | MCP, Agent Skills, OAuth, x402, WebMCP | Live | Tweet |
| Tidewave | @josevalim | Elixir 的 agent tooling:UI variants、vision mode、code reviews、browser agent | Elixir 生态缺少 agent tooling | Elixir | Shipping weekly | Tweet |
值得注意的是:@ihtesham2005 报告,ClawGUI 的 2B 参数模型在 GUI agent tasks 上超过了 Qwen3-VL-32B——参数量小 16x,结果却更好。这延续了小型专用模型在受限领域超过通用大模型的趋势。
6. 新动态与亮点¶
Cloudflare 发布 AI Agent Readiness Scanner¶
@matthewhall_com 报告 Cloudflare 发布了 isitagentready.com,它会跨五个类别扫描任意网站:discoverability(robots.txt、sitemap)、content accessibility(markdown negotiation)、bot access control、protocol discovery(MCP、Agent Skills、WebMCP、OAuth)和 commerce(x402、UCP、ACP)。这是第一家大型基础设施厂商把“agent readiness”定义为网站可测属性。
SIGIR 2026 论文提出智能体 Marketplace Evaluation¶
@TEKnologyy 宣布(9 个点赞)“Evaluation of Agents under Simulated AI Marketplace Dynamics” 被 SIGIR 2026 接收。该 论文 提出一种基于模拟的范式,把信息访问系统作为 marketplace participants 评估,衡量 retention 和 market share,而不只看 accuracy。这正式化了 skill marketplaces 已经在创造的竞争动态。
Opus 4.7 大幅降低智能体 Footprint¶
@dimitrioskonst 的 benchmark data 显示,在相同任务上,Opus 4.7 相比 4.6 减少了 3.8x 的 tool calls,触碰文件数减少 8.7x,并且没有启动 subagents。一个 billing logic 任务中,4.7 拒绝为未验证的 race condition 修改代码,而 4.6 毫不犹豫地改了。这代表模型行为的质变,也将改变 harness 的设计方式。
MongoDB 发布带 Agent Skills 的 Claude Marketplace Plugin¶
@MongoDB 宣布(14 个点赞、6 次收藏)在 Claude Marketplace 上发布 plugin,包含用于 MongoDB workflows 的 Agent Skills,以及用于 context-aware guidance 的 MCP Server。数据库厂商现在也把 agent skills 当作开发者工具的分发渠道。
7. 机会在哪里¶
[+++] 跨全栈的智能体可观测性。 hermes-hudui 一周达到 1K stars。mattpocockuk 描述了缺失平台。Traces for Teams 发布。badlogicgames 称赞 HuggingFace trace viewer。但还没有一个工具同时覆盖 per-session traces、per-agent dashboards 和 team-level analytics。第一个能适配 Claude Code、Codex、Hermes 和 Cursor 的跨智能体可观测性平台,将抓住整个新兴市场。(source)
[+++] Voice-First 智能体界面。 thdxr 的帖子(653 个点赞、188 次收藏)证明 voice-to-agent 是一个巨大解锁点。Gemini TTS 进入 Hermes。Kiro 和 ElevenLabs 发起 voice hackathon。garrytan 在台北遇到消费者时刻。但 stack 仍然碎片化:Parakeet 做 STT,Gemini 做 TTS,没有集成式 voice-native agent shell。第一个内置专为 agent prompting 优化的语音听写的 terminal 或 IDE,将获得输入模态优势。(source)
[++] 企业编程智能体治理。 Databricks 为 coding agents 发布 Unity AI Gateway。Cantina 发布 governance CLI。Cloudflare 发布 isitagentready.com。三家厂商同时进入,验证了这个品类。缺口是:没有统一 governance layer 能同时覆盖 web readiness、tool permissions、spend controls 和所有主流 coding agents 的 session audit。(source)
[++] 何时不该构建 Harness 的设计模式。 IceSolst 失败的 harness(82 个点赞)和 garrytan 的反驳,把核心问题具体化:什么时候自定义 harness 有价值,什么时候 agent 内置 harness 已足够?一个决策框架或诊断工具(“你的用例需要自定义 harness 吗?”)能解决正在浪费从业者时间的困惑。(source)
[+] 隐私感知多智能体协议。 PAC-BENCH 显示,即便 GPT-5.1 在隐私约束下也只有 56% 成功率。企业跨部门或跨组织 multi-agent deployments,被缺少保住信息边界的协调机制卡住。第一个解决这个问题的协议将拿下受监管行业。(source)
[+] 智能体记忆基准。 timourxyz 直接提出了需求。georgeorch 获得 202 个点赞的帖子量化了用户挫败感。每个 memory framework 都声称有所改进,但没有标准化评估。第一个发布的跨框架 memory benchmark suite 会成为行业参考。(source)
8. 要点总结¶
-
Harness engineering 正在接受压力测试。 IceSolst 的“zero benefit”经历(82 个点赞)和 lopopolo-Zechner 的哲学分歧,挑战了前一天 harness-engineering-as-salvation 的叙事。garrytan 的反驳和 lopopolo 的轻量级 markdown automation 做法说明答案更细:harnesses 在规模化时有价值,但个人使用时,内置 agent harness 往往已经足够。(source)
-
语音输入是从业者发现的最大智能体生产力解锁点。 thdxr 的观察(653 个点赞、188 次收藏)认为,推动最大工作流提升的是 dictation,而不是 agent 改进,这反转了常见叙事。本地 Parakeet STT models 与 agent workflows 结合,移除了一个很多人之前没意识到的瓶颈。(source)
-
多智能体模式正在收敛到 writer-evaluator 作为最小可行架构。 georgeorch 逆转了怀疑(170 个点赞)。petergyang 和 DimitriGilbert 独立描述了同一个 build-then-review 模式。框架转变是:multi-agent 不再是“更多 agents”,而是最简单有效的委派。(source)
-
编程智能体治理在一天内变成可交付软件。 Databricks Unity AI Gateway、Cantina 的 governance CLI 和 Cloudflare 的 isitagentready.com 都发布了生产工具。企业把关问题从“我们需要治理”变成“我们采用哪个治理工具”。(source)
-
Opus 4.7 对 agent harness design 来说代表行为范式转变。 dimitrioskonst 的数据显示,相同任务下 tool calls 减少 3.8x,且没有启动 subagents。一个会自我约束的模型会改变 harness 需要提供的东西——从“约束 agent”转向“agent 自我约束”。(source)
-
技能市场怀疑来自可信来源。 Shaw(ElizaOS creator)把下载 skills 称为“史上最容易变成供应链攻击面的东西”。结合一个可让远程命令执行的 MCP 设计缺陷报道,agent skill ecosystems 的安全面正在比缓解工具更快扩大。(source)
-
隐私约束下的多智能体协作基本还没解决。 PAC-BENCH 中 GPT-5.1 与自身配对也只有 56% 成功率,并且发现发起者角色比模型质量更重要,这为跨信任边界的企业 multi-agent deployments 设定了硬上限。(source)