Twitter AI Agent - 2026-04-18¶
1. What People Are Talking About¶
1.1 Harness Engineering Moves From Theory to Practice 🡕¶
The harness engineering conversation shifted from definitional debates to concrete implementation patterns. @_lopopolo described a Codex automation workflow where automations live as markdown files in docs/automations, the prompt is just two sentences referencing the runbook file, and every automation becomes code-reviewed, repo-owned, and versioned (55 likes, 47 bookmarks, 2,844 views). @michellelawson published a 45-minute deep dive covering "the architecture behind Claude Code, Codex, OpenClaw and every AI agent you're in love with" (31 likes, 34 bookmarks). @ghumare64 contributed a detailed analysis of the 12-component harness model, arguing that memory and context management "are treated as two separate components, but in production they're the same problem wearing two hats" and that memory must "outlive the harness you started with" (13 likes, 23 bookmarks, 1,573 views). The agentmemory project was cited as achieving 95.2% R@5 on LongMemEval-S with hybrid BM25 + vector + knowledge-graph retrieval. @forefy documented specific agentic harness patterns including Fork Subagent vs. Swarm Mode and Bridge/Remote Control patterns.
Discussion insight: The conversation matured from "the harness is the product" into engineering specifics: markdown-as-runbook, portable memory layers, and pattern catalogs. The most bookmarked posts were those offering reproducible patterns rather than philosophical positions. Memory portability emerged as the single hardest unsolved problem, with every major harness (Claude Code, LangGraph, OpenAI, Anthropic's Ralph Loop) implementing memory differently and none interoperating.
Comparison to prior day: On April 17, harness engineering was led by @akshay_pachaar's three-phase framework (weights to context to harness) as a top-level framing. On April 18, the conversation moved downstream into implementation details: markdown runbooks, memory portability benchmarks, and named architectural patterns. The abstraction level dropped while the bookmark-to-like ratio increased, suggesting the audience shifted from general interest to practitioners.
1.2 Skill Ecosystem Growth and Supply Chain Security Tension 🡕¶
Two opposing forces collided: rapid skill ecosystem expansion and growing alarm about skill supply chain risk. @NousResearch announced a partnership with Jim Liu (@dotey) to port popular infographic and design skills to Hermes Agent, the day's top post (331 likes, 198 bookmarks, 18,501 views). The quoted tweet references a 14k+ star GitHub project for visual content skills. @Baconbrix announced Expo Agent skills as an official Claude Code plugin, claiming "+46% improvement in native UI" (54 likes, 29 bookmarks, 2,054 views). @sharbel listed 10 Claude Code tools most developers don't know exist, spanning skills, memory persistence, and orchestration tools (66 likes, 46 bookmarks).

Simultaneously, @shawmakesmagic argued there is no viable skill marketplace: "The risk of downloading a skill is too high, it's the easiest supply chain attack surface in history. Focus on making an agent you use, not a product for a market that doesn't exist" (123 likes, 11 bookmarks, 4,800 views). @DanKornas responded with a concrete tool: skill-scanner, a security scanner combining pattern-based detection (YAML + YARA), LLM-as-a-judge, and behavioral dataflow analysis to scan third-party agent skills for prompt injection and data exfiltration risks (0 likes, 5 bookmarks).
Discussion insight: The skill ecosystem is splitting into two camps. Platform vendors (Nous Research, Expo, MongoDB) are shipping curated, first-party skills through official channels. Meanwhile, community builders circulate skills through GitHub repos with minimal vetting. Shaw's warning and DanKornas's scanner represent the first generation of responses to this attack surface.
Comparison to prior day: April 17 introduced skill marketplace skepticism as a new theme. On April 18 it intensified: Shaw's post drew 123 likes versus the prior day's more measured concerns, and the first dedicated scanning tool (skill-scanner) appeared as a direct response.
1.3 Local AI Agents Reach Practical Viability 🡕¶
Evidence mounted that local model inference has crossed a usability threshold for agentic work. @sudoingX demonstrated Gemma 4 31B Dense Q4 running locally on an RTX 5090 mobile (24GB VRAM) at 15 tok/s sustained via llama.cpp, generating a complete GPU marketplace UI from a single prompt with "no prompt engineering, no agentic harness, no tool calls" (126 likes, 88 bookmarks, 14,183 views). The follow-up reply stated: "24gb of vram and a one sentence prompt is all this took. google cooked, the model isn't bad, the narrative around local is."
@tom_doerr shared GenericAgent, a self-evolving autonomous agent framework with just ~3K lines of core code that hit GitHub Trending #1 Repository of the Day (44 likes, 38 bookmarks, 2,816 views). The framework auto-crystallizes execution paths into reusable skills and operates under a 30K context window. @jahooma detailed the economics of running a free coding agent, explaining prompt cache optimization on 8 B200 GPUs serving GLM 5.1, where "too many concurrent requests break prompt caching" and session-level optimization is key to staying in business.

Discussion insight: Local AI agents are no longer a hobby curiosity. The combination of 24GB consumer GPUs, quantized 30B+ models, and lightweight inference servers (llama.cpp) is producing results that practitioners describe as competitive with cloud APIs for single-turn generation. The bottleneck has shifted from model quality to inference economics and prompt cache management.
Comparison to prior day: April 17 covered voice-first and Gemini CLI as local-adjacent themes but did not feature raw local inference benchmarks. April 18 brought specific hardware configs, token throughput numbers, and a framework (GenericAgent) that explicitly targets the local-first niche.
1.4 Agent Tooling Obsolescence Debate 🡒¶
@samhogan posted a provocative claim that "most of tooling around llms was built for a world that largely doesn't exist anymore" listing RAG, GraphRAG, Multi Agent Orchestration, ReAct frameworks, prompt management, LLMOps, eval tools, gateways, and finetuning libs as "all obsoleted in the last 3 months" (99 likes, 83 bookmarks, 16,655 views). In replies, @kylewgrove said "some of the orchestration tools were built for a world that never existed." @a_protsyuk countered: "RAG isn't obsolete, it's just less special - every model has it baked in now so the standalone 'RAG pipeline' product is dead. But multi-agent for real production workflows with retries, state, and human handoff... that's growing."
@official_taches offered a related perspective on the evolution from vibe coding to structured frameworks to a new middle ground: "Before any project setup, I make the AI prove the core things work. Throwaway and interactive experiments and mockups. It's fast, messy, and immediate. I call it 'vibe-proofing'" (38 likes, 3 bookmarks, 2,496 views).
Discussion insight: The highest-bookmarked post in the dataset was a declaration that an entire generation of AI tooling is obsolete. The nuanced replies reveal a more complex reality: standalone tooling products are dying, but the underlying capabilities (retrieval, orchestration, evaluation) are being absorbed into harnesses and model capabilities rather than disappearing. "Vibe-proofing" suggests practitioners want the speed of vibe coding with the quality of structured frameworks.
Comparison to prior day: This is a new theme on April 18. April 17 focused on what tools to use; April 18 questions whether entire categories of tools should exist at all.
1.5 Multi-Agent Orchestration Gets Infrastructure 🡕¶
Multiple projects shipped concrete orchestration infrastructure. @tom_doerr shared Mission Control, a self-hosted AI agent fleet orchestration dashboard with 4.2k GitHub stars, 32 dashboard panels, real-time WebSocket updates, zero external dependencies (SQLite), and multi-gateway support for OpenClaw, CrewAI, LangGraph, and AutoGen (41 likes, 66 bookmarks, 2,927 views).

@Voxyz_ai announced GBrain v0.11 by Garry Tan, claiming Minions agent orchestration is "10x faster than openclaw's default subagents" with benchmarks: 19,240 posts across 36 months processed in 15 minutes for $0 versus the sub-agent approach that "failed on 40% of runs and cost $1.08 in tokens" (20 likes, 10 bookmarks, 7,423 views). Features include spawn storm defense (recursion depth caps), idempotent task execution, and parent auto-notification. @camsoft2000 praised RepoPrompt's orchestration workflow where "the main agent killed a subagent to prevent it thrashing on an issue" (29 likes, 22 bookmarks, 3,310 views). @matteocollina released Regina, a production-ready agent orchestration layer on Platformatic Watt where agents are defined in Markdown, each running as an isolated worker thread with its own SQLite virtual filesystem.
Discussion insight: Orchestration is shifting from conceptual frameworks to operational dashboards. The bookmark-heavy engagement on Mission Control (66 bookmarks vs 41 likes) signals strong save-for-later intent from builders. GBrain's concrete benchmark data (40% failure rate for sub-agents, 10x speed claim) gives practitioners numbers to evaluate against their own systems.
Comparison to prior day: April 17 covered multi-agent coordination with Google's research findings and Av1d's breakdown. April 18 moved from research to shipped infrastructure: Mission Control, GBrain v0.11, Regina, and RepoPrompt orchestration all represent deployed tools rather than papers.
1.6 Agent Security Becomes a First-Class Concern 🡕¶
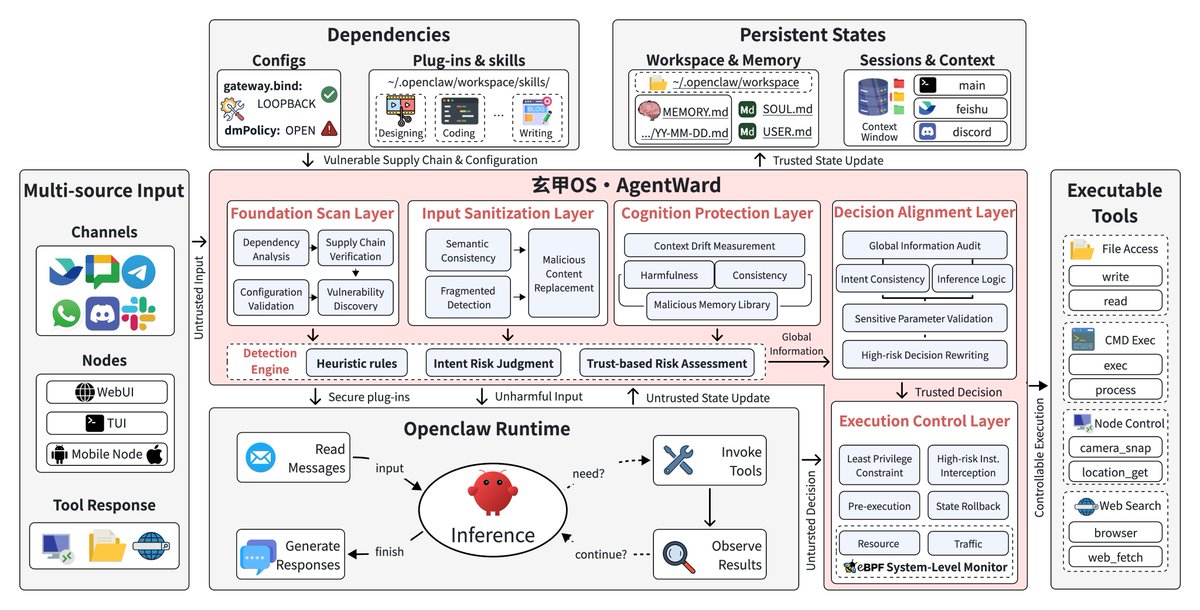
Security concerns graduated from scattered warnings to systematic tooling. @jiqizhixin reported on AgentWard by Tsinghua University, a full-stack security OS building five coordinated defense-in-depth layers into the agent workflow: Foundation Scan, Input Sanitization, Cognition Protection, Decision Alignment, and Execution Control (5 likes, 3 bookmarks, 509 views).
@nebusecurity reported their AI security agent using GPT-5.4 found a bug in 7 seconds and converted it into an "$82,337 bounty" (16 likes, 3 bookmarks, 597 views). @ChainlCLzxti flagged a new phishing technique where "AI agents simulate official customer service" by analyzing social media posting style to generate persuasive private messages (13 likes, 0 bookmarks, 4,676 views). @0xJeff shared a cautionary tale about his Hermes agent hallucinating and using Bird CLI to "spout nonsense instead of just fetching me the tweets" and subsequently embedding the mishap into memory as a corrective (18 likes, 5 bookmarks, 2,274 views).
Discussion insight: Agent security is splitting into three tiers: academic defense-in-depth (AgentWard), commercial offensive security (Nebu's $82K bounty), and individual harm mitigation (0xJeff's hallucination incident). The most practical near-term tool is DanKornas's skill-scanner for vetting third-party skills before deployment.
Comparison to prior day: April 17 introduced skill supply chain security as a concern. April 18 produced the first concrete scanner tool (skill-scanner), a full academic security framework (AgentWard), and the first reported AI-agent-discovered bounty ($82,337).
1.7 Enterprise Coding Agent Governance Arrives 🡕¶
@databricks announced Coding Agent Support in Unity AI Gateway to address "the risk of coding agent sprawl" with centralized governance across coding agents, LLM interactions, and MCP integrations, including rate limits, budgets, and unified observability (35 likes, 15 bookmarks, 2,143 views).

@LangChain published a case study where Cisco's team built a LangSmith + LangGraph powered framework for multi-agent coordination that "behaves like a real-world software team" (21 likes, 12 bookmarks, 3,377 views).
@Docker confirmed Claude Opus 4.7 support in Docker Agent, a framework for building and running custom agent teams (13 likes, 1 bookmark, 2,243 views).
Discussion insight: Enterprise tooling vendors are treating coding agent governance as a new product category. Databricks's framing of "agent sprawl" mirrors the early days of cloud sprawl and SaaS sprawl, suggesting a governance-first sales motion. The Cisco case study provides the first public enterprise architecture diagram showing LangGraph in production.
Comparison to prior day: April 17 introduced coding agent governance as a nascent theme with Databricks. April 18 added Cisco's production architecture and Docker's model support, broadening the enterprise signal from one vendor to three.
2. What Frustrates People¶
Skill Supply Chain Trust -- Severity: High¶
@shawmakesmagic called skills "the easiest supply chain attack surface in history" in a widely-shared post (123 likes, 4,800 views). @DanKornas warned that "third-party agent skills need the same skepticism as shell scripts" in a post announcing skill-scanner. No standard vetting process exists across any major agent platform.
Agent Memory Non-Portability -- Severity: High¶
@ghumare64 documented the lock-in problem: "Claude Code: three-tier memory hierarchy. LangGraph: namespace-organized JSON Stores. OpenAI: Sessions backed by SQLite or Redis. Each one solves memory. None of them talk to each other. Switch harnesses and your accumulated context is gone." @fxnction echoed: "Every single agent out there -- whether it's running on OpenClaw, Hermes, or a custom stack -- is trapped in its own sandbox."
Multi-Agent Failure Rates -- Severity: Medium¶
@Av1dlive cited Google research showing "independent agents fail 17x more than single agents" (15 likes, 14 bookmarks). @Voxyz_ai reported GBrain v0.11 benchmarks where the sub-agent approach "failed on 40% of runs". @ybouane advised: "If you just use one agent and let it do the work over a longer period you will spend a lot less tokens overall because of caching."
Agent Hallucination in Production -- Severity: Medium¶
@0xJeff shared an incident where his Hermes agent "hallucinated and started using Bird CLI to spout nonsense instead of just fetching me the tweets." The fix was embedding the mishap into memory. @Plar_ai replied: "Now imagine it had a payment tool attached. Same hallucination, except now it's placing orders instead of posting nonsense."
3. What People Wish Existed¶
Portable Agent Memory Standard¶
@ghumare64 called for memory that "outlives the harness you started with, because the harness you start with is not the harness you end with. Claude Code today, Codex tomorrow, whatever ships next month after that" in a post citing agentmemory as a potential solution (13 likes, 23 bookmarks). The agentmemory project claims 12 hooks across Claude Code, Cursor, Gemini CLI, and OpenCode but remains a single-project effort rather than a standard.
Opportunity: A cross-harness memory protocol would unlock harness switching without context loss. Current fragmentation locks users into their first choice.
Automated Skill Vetting Pipeline¶
@shawmakesmagic declared no skill marketplace is viable without trust. @DanKornas built skill-scanner as a first step, but it covers detection only, not continuous monitoring, reputation scoring, or sandboxed execution.
Opportunity: A comprehensive skill vetting pipeline (static analysis + runtime sandboxing + community reputation) would enable the marketplace that platforms want but practitioners currently distrust.
Agent Observability for SRE Workflows¶
@TheNJDevOpsGuy described an SRE Agent architecture requiring "a proper prompt/system message, agent skills designed to turn your agent into an SRE and observability expert, a good LLM, and targets" (12 likes, 13 bookmarks). The gap between general-purpose coding agents and SRE-specific tooling remains wide.

Opportunity: SRE-specific agent skills with pre-built integrations for Prometheus, PagerDuty, Kubernetes, and cloud providers would unlock a high-value vertical.
4. Tools and Methods in Use¶
| Tool / Method | Category | Mentions | Representative Post |
|---|---|---|---|
| Hermes Agent | Agent platform | 10+ | @NousResearch |
| Claude Code | Coding agent | 30+ | @sharbel |
| OpenClaw | Agent framework | 10+ | @CrypSaf |
| LangGraph + LangSmith | Orchestration | 3 | @LangChain |
| llama.cpp | Local inference | 2 | @sudoingX |
| Opus 4.7 | Model | 5+ | @nickvasiles |
| Gemma 4 31B Dense | Local model | 2 | @sudoingX |
| Codex | Coding agent | 5+ | @_lopopolo |
| MCP (Model Context Protocol) | Integration | 5+ | @NamedFarouk |
| Docker Agent | Agent runtime | 1 | @Docker |
| Databricks Unity AI Gateway | Governance | 1 | @databricks |
| skill-scanner | Security | 1 | @DanKornas |
Claude Code and Hermes Agent continue to dominate tool mentions. The notable shift is toward governance and security tooling (Databricks AI Gateway, skill-scanner) entering the conversation alongside execution platforms. Opus 4.7 has become the default model reference for high-capability agent work, with cost noted as "high" but not disqualifying.
5. What People Are Building¶
| Project | Builder | Stage | Description |
|---|---|---|---|
| Mission Control | @tom_doerr / builderz-labs | Alpha | Self-hosted agent fleet orchestration dashboard, 4.2k stars, SQLite, multi-gateway |
| GenericAgent | @tom_doerr / lsdefine | Shipped | Self-evolving agent framework, ~3K lines, GitHub Trending #1 |
| GBrain v0.11 | @garrytan | Shipped | Minions orchestration with spawn storm defense and idempotent tasks |
| GStack | @garrytan | Shipped | 26 opinionated coding agent skills, MIT license |
| Browser Harness | @gregpr07 | Shipped | Self-healing browser automation via direct CDP, no framework |
| skill-scanner | @DanKornas | Shipped | Security scanner for agent skills (YAML+YARA, LLM-as-a-judge, dataflow) |
| AgentWard | Tsinghua University | Alpha | Full-stack agent security OS with five defense layers |
| ClawGUI | Zhejiang University | Alpha | GUI agent pipeline: train, evaluate, deploy to real phones. 2B model beat Qwen3-VL-32B |
| ok-skills | @tom_doerr / mxyhi | Shipped | 58 reusable AI coding agent skills for Codex, Claude Code, Cursor, OpenClaw |
| Regina | @matteocollina | Shipped | Agent orchestration on Platformatic Watt, markdown-defined, SQLite VFS per agent |
| DeepTutor | HKUDS | Shipped | AI agent for personalized learning with persistent memory and quiz generation |
| Open Claude | Community | Alpha | Open-source Claude Code alternative with BYO API key |
| Expo Agent Plugin | @Baconbrix | Shipped | Official Claude Code plugin for React Native/Expo development |
| MCP for Arc docs | @NamedFarouk | Shipped | MCP server pulling 85 doc sections into any AI coding tool, Cloudflare Workers |
Mission Control stands out for scope: 32 panels covering tasks, agents, skills, logs, tokens, memory, security, cron, alerts, webhooks, and pipelines with zero external dependencies. The repo shows 577 tests (282 unit + 295 E2E), multi-gateway adapters, and a built-in Aegis review system that blocks task completion without sign-off.
GenericAgent takes the opposite approach: ~3K lines of core code with 9 atomic tools and a ~100-line Agent Loop that grants any LLM system-level control. Its self-evolution mechanism automatically crystallizes execution paths into skills, operating under a 30K context window versus the 200K-1M other agents consume.
ClawGUI represents the academic frontier: a 2B parameter model outperforming Qwen3-VL-32B (16x larger) on GUI agent tasks by training on real Android/iOS devices rather than emulators, then deploying to phones through Telegram, Slack, and Discord.
6. New and Notable¶
Hermes Agent Infographic Skill Partnership¶
@NousResearch announced a partnership with Jim Liu to port his 14k-star infographic generation skills to Hermes Agent native tooling. This is the first major third-party skill integration for Hermes and signals the platform's push toward visual content generation alongside code. Available via /baoyu-infographic <topic>.
GenericAgent Hits GitHub Trending #1¶
GenericAgent by lsdefine reached #1 on GitHub Trending with a self-evolving agent approach: every completed task is automatically crystallized into a reusable skill. The framework's ~3K line core and 30K context window make it viable for local deployment. The README states: "Everything in this repository, from installing Git and running git init to every commit message, was completed autonomously by GenericAgent."

AI Security Agent Discovers $82K Bounty in 7 Seconds¶
@nebusecurity reported their AI security agent using GPT-5.4 completed a full exploit in 7 seconds that converted into an $82,337 bug bounty. A full write-up is pending patch deployment.
Garry Tan Ships GStack and GBrain v0.11¶
Y Combinator CEO @garrytan released GStack, a 26-skill set turning coding agents into virtual engineering teams (CEO, UX designer, engineer, QA, release engineer), and shipped GBrain v0.11 with Minions orchestration. GStack's README claims an 810x productivity increase over his 2013 coding pace.
Databricks Ships Coding Agent Governance¶
@databricks launched Coding Agent Support in Unity AI Gateway, the first enterprise governance layer explicitly targeting coding agent sprawl with centralized rate limits, budgets, and observability across Cursor, Gemini CLI, and Codex CLI.
7. Where the Opportunities Are¶
[+++] Agent memory portability layer -- Every major harness implements memory differently and none interoperate. A cross-harness memory protocol with hybrid retrieval (BM25 + vector + knowledge graph) would address the #1 lock-in complaint. @ghumare64 documented the problem; agentmemory shows early traction with 12 cross-tool hooks.
[+++] Skill security and vetting infrastructure -- Skill-scanner exists but covers static detection only. The market needs continuous monitoring, reputation scoring, and sandboxed execution to unlock the skill marketplace that platforms are trying to build. @shawmakesmagic and @DanKornas defined both the problem and the first partial solution.
[++] Enterprise coding agent governance -- Databricks is first to market but the problem is universal. Every company running multiple coding agents needs usage tracking, rate limiting, cost allocation, and audit trails. This is an enterprise SaaS opportunity analogous to early cloud management platforms.
[++] Local inference optimization for agents -- @jahooma showed prompt cache management is the critical bottleneck for self-hosted coding agents. Tools that optimize session-level cache utilization, manage concurrent user scheduling, and balance GPU saturation would directly reduce inference costs.
[+] SRE-specific agent skills -- @TheNJDevOpsGuy laid out the four-component SRE agent architecture. Pre-built skill packs for incident detection, root cause analysis, and auto-remediation targeting Kubernetes, cloud providers, and monitoring stacks would fill a high-value vertical gap.
[+] Agent fleet dashboards -- Mission Control's 66 bookmarks on 41 likes shows strong builder demand for operational visibility into agent fleets. The market is early (Alpha software) and fragmented across OpenClaw, CrewAI, LangGraph, and custom stacks.
8. Takeaways¶
-
Harness engineering moved from philosophy to engineering patterns: markdown-as-runbook, memory portability benchmarks, and named architectural patterns replaced high-level framing. Sources: @_lopopolo, @ghumare64, @forefy.
-
Skill supply chain security emerged as the day's highest-stakes tension, with Shaw declaring skills "the easiest supply chain attack surface in history" and DanKornas shipping the first dedicated scanner. Source: @shawmakesmagic, @DanKornas.
-
Local AI crossed a practical viability threshold, with Gemma 4 31B generating production-quality UI from single prompts at 15 tok/s on consumer hardware. Source: @sudoingX.
-
Multi-agent orchestration got real infrastructure: Mission Control (4.2k stars, 32 panels), GBrain v0.11 (10x faster orchestration with benchmarks), and Regina (markdown-defined agents with SQLite VFS). Sources: @tom_doerr, @Voxyz_ai, @matteocollina.
-
Enterprise governance entered the coding agent space with Databricks Unity AI Gateway and Cisco's production LangGraph deployment, signaling the transition from developer experimentation to organizational control. Sources: @databricks, @LangChain.
-
Agent security produced its first concrete artifacts: AgentWard (5-layer defense OS from Tsinghua), skill-scanner (prompt injection detection), and a GPT-5.4 agent discovering an $82K bounty in 7 seconds. Sources: @jiqizhixin, @DanKornas, @nebusecurity.
-
GenericAgent's #1 GitHub Trending position and ~3K line architecture suggest appetite for minimal, self-evolving frameworks over heavyweight orchestration. Source: @tom_doerr.
-
The skill ecosystem split into two distribution models: curated first-party plugins (Expo, MongoDB, Nous Research partnerships) versus community GitHub repos with minimal vetting. Neither model has solved trust at scale. Sources: @Baconbrix, @NousResearch, @shawmakesmagic.