Twitter AI 智能体 - 2026-04-18¶
1. 人们在讨论什么¶
1.1 运行框架工程从理论走向实践 🡕¶
运行框架工程的讨论从定义之争转向具体落地模式。@_lopopolo 描述了一套 Codex 自动化工作流:自动化流程以 Markdown 文件形式放在 docs/automations 中,提示词只用两句话引用运行手册文件,每个自动化流程都成为可代码审查、归仓库管理、可版本化的资产(55 个点赞、47 次收藏、2,844 次浏览)。@michellelawson 发布了一场 45 分钟深度解析,讲解“Claude Code、Codex、OpenClaw 以及你喜欢的每个 AI 智能体背后的架构”(31 个点赞、34 次收藏)。@ghumare64 贡献了一篇 12 组件运行框架模型的详细分析,认为记忆和上下文管理“被当成两个独立组件,但在生产里它们其实是同一个问题戴了两顶帽子”,并且记忆必须“比你起步时使用的运行框架活得更久”(13 个点赞、23 次收藏、1,573 次浏览)。文中提到 agentmemory 项目在 LongMemEval-S 上使用混合 BM25 + 向量 + 知识图谱检索达到 95.2% R@5。@forefy 记录了具体 智能体运行框架模式,包括 Fork Subagent vs. Swarm Mode,以及 Bridge/Remote Control 模式。
讨论要点: 讨论已经从“运行框架就是产品”成熟为工程细节:Markdown 即运行手册、可移植记忆层和模式目录。收藏数最高的帖子不是哲学立场,而是能复现的模式。记忆可移植性成为最难的未解问题:Claude Code、LangGraph、OpenAI、Anthropic 的 Ralph Loop 等主要运行框架的记忆层做法各不相同,且彼此不互通。
与前日对比: 4 月 17 日,运行框架工程由 @akshay_pachaar 的三阶段框架(从权重到上下文再到运行框架)作为顶层叙事主导。4 月 18 日,讨论下沉到落地细节:Markdown 运行手册、记忆可移植性基准测试和命名架构模式。抽象层级降低,但收藏/点赞比上升,说明受众从泛兴趣转向从业者。
1.2 技能生态增长与供应链安全张力 🡕¶
两股相反力量撞在一起:技能生态快速扩张,以及对技能供应链风险的警觉上升。@NousResearch 宣布与 Jim Liu(@dotey)合作,把流行的信息图和设计技能移植到 Hermes Agent,这是当天最高热度帖子(331 个点赞、198 次收藏、18,501 次浏览)。引用推文提到一个拥有 14k+ GitHub 星标的项目,提供视觉内容技能。@Baconbrix 宣布 Expo Agent 技能成为官方 Claude Code 插件,声称“原生 UI 提升 +46%”(54 个点赞、29 次收藏、2,054 次浏览)。@sharbel 列出了 大多数开发者不知道的 10 个 Claude Code 工具,覆盖技能、持久记忆和编排工具(66 个点赞、46 次收藏)。

与此同时,@shawmakesmagic 认为 不存在可行的技能市场:“下载技能的风险太高,这是史上最容易变成供应链攻击面的东西。专注于做一个你自己会用的智能体,而不是给一个并不存在的市场做产品”(123 个点赞、11 次收藏、4,800 次浏览)。@DanKornas 用一个具体工具回应:@DanKornas 发布了 skill-scanner,一个安全扫描器,结合基于模式的检测(YAML + YARA)、LLM-as-a-judge 和行为数据流分析,用来扫描第三方智能体技能中的提示词注入和数据外泄风险(0 个点赞、5 次收藏)。
讨论要点: 技能生态正在分裂成两派。平台厂商(Nous Research、Expo、MongoDB)通过官方渠道发布精选的第一方技能。与此同时,社区开发者通过 GitHub 仓库分发技能,几乎没有审查。Shaw 的警告和 DanKornas 的扫描器代表了对这一攻击面的第一代回应。
与前日对比: 4 月 17 日,对技能市场的怀疑首次成为主题。4 月 18 日,它进一步加强:相较前一天更克制的担忧,Shaw 的帖子获得 123 个点赞;第一个专门的扫描工具(skill-scanner)也作为直接回应出现。
1.3 本地 AI 智能体达到实用门槛 🡕¶
越来越多证据显示,本地模型推理已经跨过智能体式工作的可用阈值。@sudoingX 演示了 Gemma 4 31B Dense Q4 本地运行:在 RTX 5090 移动版(24GB VRAM)上通过 llama.cpp 以 15 tok/s 持续生成,从一句提示词生成完整 GPU 市场 UI,“没有提示工程、没有智能体运行框架、没有工具调用”(126 个点赞、88 次收藏、14,183 次浏览)。后续回复说:“24GB VRAM 和一句提示词就够了。Google 做出来了,这个模型不差,差的是围绕本地模型的叙事。”
@tom_doerr 分享了 GenericAgent,这是一个自演化自治智能体框架,核心代码只有约 3K 行,并登上 GitHub Trending 当日第一仓库(44 个点赞、38 次收藏、2,816 次浏览)。该框架会把执行路径自动固化成可复用技能,并在 30K 上下文窗口下运行。@jahooma 详细说明了 运行免费编程智能体的经济学,解释如何在 8 张 B200 GPU 上服务 GLM 5.1 时优化提示词缓存:“过多并发请求会破坏提示词缓存”,而会话级优化是能否维持业务的关键。

讨论要点: 本地 AI 智能体不再只是业余玩具。24GB 消费级 GPU、量化 30B+ 模型和轻量推理服务器(llama.cpp)结合后,已经产出从业者认为可与云 API 在单轮生成上竞争的结果。瓶颈已经从模型质量转向推理经济性和提示词缓存管理。
与前日对比: 4 月 17 日覆盖了语音优先和 Gemini CLI 等本地模型周边主题,但没有原始本地推理基准测试。4 月 18 日带来了具体硬件配置、token 吞吐量数字,以及一个明确面向本地优先细分方向的框架(GenericAgent)。
1.4 智能体工具过时争论 🡒¶
@samhogan 发布了一条 挑衅性观点,认为“围绕 LLM 构建的大多数工具链,都是为一个基本已经不存在的世界服务的”,并列出 RAG、GraphRAG、多智能体编排、ReAct 框架、提示词管理、LLMOps、评估工具、网关和微调库,称它们“在过去 3 个月全部过时”(99 个点赞、83 次收藏、16,655 次浏览)。回复中,@kylewgrove 说“某些编排工具是为一个从未存在过的世界构建的”。@a_protsyuk 反驳:“RAG 没有过时,只是没那么特殊了——每个模型现在都内置了它,所以独立的‘RAG 流水线’产品死了。但用于真实生产工作流、带重试、状态和人工交接的多智能体……正在增长。”
@official_taches 提供了另一个 视角:从 vibe coding 到结构化框架,再到新的中间地带:“在任何项目搭建之前,我会让 AI 证明核心事情能跑通。一次性、交互式的实验和原型。它快、乱、直接。我把它叫做‘vibe-proofing’”(38 个点赞、3 次收藏、2,496 次浏览)。
讨论要点: 数据集中收藏最高的一条帖子,是对整整一代 AI 工具链已经过时的宣言。更细致的回复揭示了更复杂的现实:独立工具产品在衰退,但底层能力(检索、编排、评估)正被运行框架和模型能力吸收,而不是消失。“Vibe-proofing” 表明从业者既想要 vibe coding 的速度,也想保留结构化框架的质量。
与前日对比: 这是 4 月 18 日的新主题。4 月 17 日关注该用什么工具;4 月 18 日开始质疑整个工具品类是否还有存在必要。
1.5 多智能体编排获得基础设施 🡕¶
多个项目发布了具体编排基础设施。@tom_doerr 分享了 Mission Control,一个自托管 AI 智能体集群编排仪表盘,拥有 4.2k GitHub 星标、32 个仪表盘面板、实时 WebSocket 更新、零外部依赖(SQLite),并支持 OpenClaw、CrewAI、LangGraph 和 AutoGen 的多网关(41 个点赞、66 次收藏、2,927 次浏览)。

@Voxyz_ai 宣布 GBrain v0.11,由 Garry Tan 发布,声称 Minions 智能体编排“比 OpenClaw 的默认子智能体快 10 倍”,并给出基准测试:在 15 分钟内处理 36 个月的 19,240 条帖子,成本 0 美元;而子智能体方案“40% 运行失败,并消耗 1.08 美元 token”(20 个点赞、10 次收藏、7,423 次浏览)。功能包括 spawn storm 防护(递归深度上限)、幂等任务执行和父任务自动通知。@camsoft2000 称赞 RepoPrompt 的编排工作流,其中“主智能体杀掉一个子智能体,防止它在某个 issue 上反复空转”(29 个点赞、22 次收藏、3,310 次浏览)。@matteocollina 发布了 Regina,这是一个基于 Platformatic Watt 的生产就绪智能体编排层,智能体以 Markdown 定义,每个智能体作为隔离工作线程运行,并拥有自己的 SQLite 虚拟文件系统。
讨论要点: 编排正在从概念框架转为运营仪表盘。Mission Control 收藏数高于点赞数(66 次收藏 vs 41 个点赞),说明开发者有强烈的稍后保存意图。GBrain 的具体基准测试数据(子智能体 40% 失败率、10 倍速度声明)让从业者有数字可以和自己的系统对照。
与前日对比: 4 月 17 日讨论多智能体协作,内容包括 Google 的研究发现和 Av1d 的拆解。4 月 18 日则从研究转向已发布的基础设施:Mission Control、GBrain v0.11、Regina 和 RepoPrompt 编排都是已部署工具,而不是论文。
1.6 智能体安全成为一等关注点 🡕¶
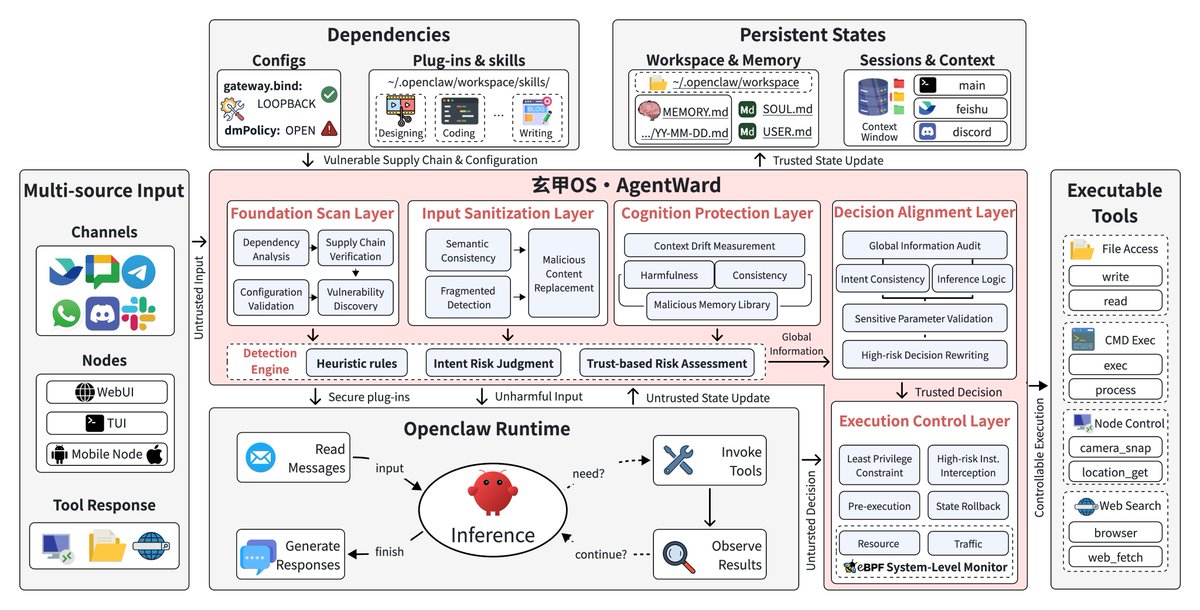
安全担忧从零散警告升级为系统化工具。@jiqizhixin 报道了清华大学的 AgentWard,这是一个全栈安全 OS,把五层协同纵深防御嵌入智能体工作流:Foundation Scan、Input Sanitization、Cognition Protection、Decision Alignment 和 Execution Control(5 个点赞、3 次收藏、509 次浏览)。
@nebusecurity 报告,他们的 使用 GPT-5.4 的 AI 安全智能体 在 7 秒内发现一个漏洞,并转化成“82,337 美元赏金”(16 个点赞、3 次收藏、597 次浏览)。@ChainlCLzxti 标记了一种 新型钓鱼技术:这种技术会分析社交媒体发帖风格,让“AI 智能体模拟官方客服”,生成有说服力的私信(13 个点赞、0 次收藏、4,676 次浏览)。@0xJeff 分享了一个 警示故事:他的 Hermes 智能体产生幻觉,用 Bird CLI “胡说八道,而不是把推文抓给我”,随后他把这次事故写入记忆作为纠偏(18 个点赞、5 次收藏、2,274 次浏览)。
讨论要点: 智能体安全正在分成三层:学术型纵深防御(AgentWard)、商业攻击性安全(Nebu 的 82K 美元赏金)和个人风险缓解(0xJeff 的幻觉事故)。最实用的近端工具是 DanKornas 的 skill-scanner,用于在部署前审查第三方技能。
与前日对比: 4 月 17 日把技能供应链安全作为一种担忧提出。4 月 18 日产出了第一个具体扫描工具(skill-scanner)、一个完整学术安全框架(AgentWard),以及第一起已披露的 AI 智能体发现赏金(82,337 美元)。
1.7 企业编程智能体治理到来 🡕¶
@databricks 宣布 Unity AI Gateway 支持 Coding Agents,用集中治理处理“编程智能体蔓延”的风险,覆盖编程智能体、LLM 交互和 MCP 集成,包括限流、预算和统一可观测性(35 个点赞、15 次收藏、2,143 次浏览)。

@LangChain 发布了一个 案例研究,Cisco 团队用 LangSmith + LangGraph 构建了一个多智能体协作框架,“表现得像真实世界的软件团队”(21 个点赞、12 次收藏、3,377 次浏览)。
@Docker 确认 Docker Agent 支持 Claude Opus 4.7,这是一个用于构建和运行自定义智能体团队的框架(13 个点赞、1 次收藏、2,243 次浏览)。
讨论要点: 企业工具厂商正在把编程智能体治理当作新的产品类别。Databricks 的“智能体蔓延”叙事类似早期云资源蔓延和 SaaS 工具蔓延,暗示一种治理优先的销售打法。Cisco 案例研究提供了第一张公开的企业架构图,展示 LangGraph 在生产中的使用。
与前日对比: 4 月 17 日以 Databricks 为起点,将编程智能体治理作为新兴主题提出。4 月 18 日新增 Cisco 的生产架构和 Docker 的模型支持,将企业信号从一家厂商扩展到三家。
2. 令人困扰的问题¶
技能供应链信任 -- 严重程度:高¶
@shawmakesmagic 在一条 被广泛分享的帖子 中称技能是“史上最容易变成供应链攻击面的东西”(123 个点赞、4,800 次浏览)。@DanKornas 在 宣布 skill-scanner 的帖子 中警告:“第三方智能体技能需要像 shell 脚本一样被怀疑。”任何主流智能体平台都还没有标准审查流程。
智能体记忆不可移植 -- 严重程度:高¶
@ghumare64 记录了 锁定问题:“Claude Code:三层记忆层级。LangGraph:按命名空间组织的 JSON Stores。OpenAI:由 SQLite 或 Redis 支撑的会话。每个都解决了记忆问题。没有一个能互相沟通。切换运行框架,你积累的上下文就没了。”@fxnction 呼应道:“每一个智能体——无论跑在 OpenClaw、Hermes,还是自定义技术栈上——都困在自己的沙箱里。”
多智能体失败率 -- 严重程度:中等¶
@Av1dlive 引用 Google 研究,称“独立智能体的失败率是单智能体的 17 倍”(15 个点赞、14 次收藏)。@Voxyz_ai 报告 GBrain v0.11 基准测试,其中 子智能体方案“40% 运行失败”。@ybouane 建议:“如果你只用一个智能体,并让它在更长时间里做活,因为有缓存,你整体 token 花费会少很多。”
生产中的智能体幻觉 -- 严重程度:中等¶
@0xJeff 分享了一起 事故:他的 Hermes 智能体“产生幻觉,开始用 Bird CLI 胡乱输出,而不是直接帮我抓推文”。修复方式是把这次事故写入记忆。@Plar_ai 回复:“现在想象一下它接了支付工具。同样的幻觉,只不过这次不是发胡话,而是在下单。”
3. 人们期望的功能¶
可移植的智能体记忆标准¶
@ghumare64 在 引用 agentmemory 的帖子 中呼吁记忆必须“比你起步时使用的运行框架活得更久,因为你起步时的运行框架,不会是你最终使用的运行框架。今天 Claude Code,明天 Codex,下个月又会有新东西”(13 个点赞、23 次收藏)。agentmemory 项目声称拥有跨 Claude Code、Cursor、Gemini CLI 和 OpenCode 的 12 个钩子,但它仍是单一项目,而不是标准。
机会:一个跨运行框架的记忆协议将允许用户切换运行框架而不丢上下文。当前碎片化把用户锁进了第一个选择。
自动化技能审查流水线¶
@shawmakesmagic 宣称 没有信任就不存在可行技能市场。@DanKornas 构建了 skill-scanner 作为第一步,但它只覆盖检测,不覆盖持续监控、声誉评分或沙箱执行。
机会:一个完整技能审查流水线(静态分析 + 运行时沙箱隔离 + 社区声誉)将让平台想要、从业者目前不信任的市场成为可能。
面向 SRE 工作流的智能体可观测性¶
@TheNJDevOpsGuy 描述了一个 SRE 智能体架构,需要“一个合适的提示词/系统消息、把智能体变成 SRE 和可观测性专家的智能体技能、一个好的 LLM,以及目标对象”(12 个点赞、13 次收藏)。通用编程智能体和 SRE 专用工具链之间仍有很大差距。

机会:带有 Prometheus、PagerDuty、Kubernetes 和云服务商预置集成的 SRE 专用智能体技能,会打开一个高价值垂直缺口。
4. 使用中的工具与方法¶
| 工具 / 方法 | 类别 | 提及次数 | 代表帖子 |
|---|---|---|---|
| Hermes Agent | 智能体平台 | 10+ | @NousResearch |
| Claude Code | 编程智能体 | 30+ | @sharbel |
| OpenClaw | 智能体框架 | 10+ | @CrypSaf |
| LangGraph + LangSmith | 编排 | 3 | @LangChain |
| llama.cpp | 本地推理 | 2 | @sudoingX |
| Opus 4.7 | 模型 | 5+ | @nickvasiles |
| Gemma 4 31B Dense | 本地模型 | 2 | @sudoingX |
| Codex | 编程智能体 | 5+ | @_lopopolo |
| MCP (Model Context Protocol) | 集成 | 5+ | @NamedFarouk |
| Docker Agent | 智能体运行时 | 1 | @Docker |
| Databricks Unity AI Gateway | 治理 | 1 | @databricks |
| skill-scanner | 安全 | 1 | @DanKornas |
Claude Code 和 Hermes Agent 继续主导工具提及。显著变化是治理和安全工具链(Databricks AI Gateway、skill-scanner)与执行平台一起进入讨论。Opus 4.7 已成为高能力智能体工作的默认模型参照,大家认为成本“高”,但还没有到劝退程度。
5. 人们在构建什么¶
| 项目 | 构建者 | 阶段 | 描述 |
|---|---|---|---|
| Mission Control | @tom_doerr / builderz-labs | Alpha | 自托管智能体集群编排仪表盘,4.2k 星标,SQLite,多网关 |
| GenericAgent | @tom_doerr / lsdefine | Shipped | 自演化智能体框架,约 3K 行,GitHub Trending #1 |
| GBrain v0.11 | @garrytan | Shipped | 带 spawn storm 防护和幂等任务的 Minions 编排 |
| GStack | @garrytan | Shipped | 26 个带明确观点的编程智能体技能,MIT 许可证 |
| Browser Harness | @gregpr07 | Shipped | 通过 direct CDP 做自修复浏览器自动化,无框架 |
| skill-scanner | @DanKornas | Shipped | 智能体技能安全扫描器(YAML+YARA、LLM-as-a-judge、dataflow) |
| AgentWard | Tsinghua University | Alpha | 带五层防御的全栈智能体安全 OS |
| ClawGUI | Zhejiang University | Alpha | GUI 智能体流水线:训练、评估、部署到真机。2B 模型击败 Qwen3-VL-32B |
| ok-skills | @tom_doerr / mxyhi | Shipped | 面向 Codex、Claude Code、Cursor、OpenClaw 的 58 个可复用 AI 编程智能体技能 |
| Regina | @matteocollina | Shipped | Platformatic Watt 上的智能体编排,Markdown 定义,每个智能体拥有 SQLite VFS |
| DeepTutor | HKUDS | Shipped | 带持久记忆和测验生成的个性化学习 AI 智能体 |
| Open Claude | Community | Alpha | 开源 Claude Code 替代品,自备 API key |
| Expo Agent Plugin | @Baconbrix | Shipped | 面向 React Native/Expo 开发的官方 Claude Code 插件 |
| MCP for Arc docs | @NamedFarouk | Shipped | MCP server,把 85 个文档章节拉进任意 AI 编程工具,Cloudflare Workers |
Mission Control 的范围最突出:32 个面板覆盖任务、智能体、技能、日志、token、记忆、安全、cron、警报、webhook 和流水线,且零外部依赖。仓库显示有 577 个测试(282 个单元测试 + 295 个 E2E 测试)、多网关适配器,以及内置 Aegis 审查系统,可在没有签署确认时阻止任务结束。
GenericAgent 采取相反路径:约 3K 行核心代码、9 个原子工具、约 100 行 Agent Loop,让任意 LLM 获得系统级控制。它的自演化机制会自动把执行路径固化成技能,在 30K 上下文窗口下运行,而其他智能体往往消耗 200K-1M。
ClawGUI 代表学术前沿:一个 2B 参数模型,在 GUI 智能体任务上超过 Qwen3-VL-32B(大 16 倍),原因是它在真实 Android/iOS 设备上训练,而不是模拟器,随后通过 Telegram、Slack 和 Discord 部署到手机。
6. 新动态与亮点¶
Hermes Agent 信息图技能合作¶
@NousResearch 宣布与 Jim Liu 合作,把他的 14k 星标信息图生成技能移植到 Hermes Agent 原生工具链。这是 Hermes 的第一个重要第三方技能集成,也显示该平台在代码之外推进视觉内容生成。可通过 /baoyu-infographic <topic> 使用。
GenericAgent 登顶 GitHub Trending #1¶
lsdefine 的 GenericAgent 以自演化智能体路线登上 GitHub Trending #1:每个跑完的任务都会自动固化成可复用技能。框架的约 3K 行核心代码和 30K 上下文窗口让它适合本地部署。README 写道:“这个仓库里的所有东西,从安装 Git、运行 git init 到每条提交信息,都是 GenericAgent 自主做完的。”

AI 安全智能体在 7 秒内发现 82K 美元赏金¶
@nebusecurity 报告,他们 使用 GPT-5.4 的 AI 安全智能体 在 7 秒内跑完整利用链,并转化为 82,337 美元漏洞赏金。完整复盘要等补丁部署后发布。
Garry Tan 发布 GStack 和 GBrain v0.11¶
Y Combinator CEO @garrytan 发布了 GStack,这是一组 26 个技能,可把编程智能体变成虚拟工程团队(CEO、UX 设计师、工程师、QA、发布工程师),并发布了带 Minions 编排的 GBrain v0.11。GStack 的 README 声称相比他 2013 年的编码速度有 810 倍生产率提升。
Databricks 发布 Coding Agent Governance¶
@databricks 发布 Unity AI Gateway 支持 Coding Agents,这是第一个明确针对编程智能体蔓延的企业治理层,提供跨 Cursor、Gemini CLI 和 Codex CLI 的集中限流、预算和可观测性。
7. 机会在哪里¶
[+++] 智能体记忆可移植层 -- 每个主要运行框架的记忆层做法都不同,而且彼此不互通。一个带混合检索(BM25 + 向量 + 知识图谱)的跨运行框架记忆协议,将解决排名第一的锁定投诉。@ghumare64 记录了这个问题;agentmemory 通过 12 个跨工具钩子显示了早期热度。
[+++] 技能安全与审查基础设施 -- Skill-scanner 已经存在,但只覆盖静态检测。市场需要持续监控、声誉评分和沙箱执行,才能释放平台想构建的技能市场。@shawmakesmagic 和 @DanKornas 定义了问题,也给出第一个局部解法。
[++] 企业编程智能体治理 -- Databricks 是第一个进入市场者,但问题是普遍的。每家公司运行多个编程智能体时,都需要用量跟踪、限流、成本分摊和审计轨迹。这是一个企业 SaaS 机会,类似早期云管理平台。
[++] 面向智能体的本地推理优化 -- @jahooma 显示,提示词缓存管理是自托管编程智能体的关键瓶颈。能优化会话级缓存利用率、管理并发用户调度、平衡 GPU 饱和度的工具,将直接降低推理成本。
[+] SRE 专用智能体技能 -- @TheNJDevOpsGuy 给出了四组件 SRE 智能体架构。面向事故检测、根因分析和自动修复的预置技能包,若能覆盖 Kubernetes、云服务商和监控栈,将填补一个高价值垂直缺口。
[+] 智能体集群仪表盘 -- Mission Control 在 41 个点赞上获得 66 次收藏,显示开发者对智能体集群运行可见性的强需求。市场还早(Alpha 软件),且在 OpenClaw、CrewAI、LangGraph 和自定义技术栈之间碎片化。
8. 要点总结¶
-
运行框架工程从哲学转向工程模式:Markdown 即运行手册、记忆可移植性基准测试和命名架构模式取代了高层叙事。来源: @_lopopolo, @ghumare64, @forefy.
-
技能供应链安全成为当天最高风险张力,Shaw 称技能是“史上最容易变成供应链攻击面的东西”,DanKornas 发布了第一个专用扫描器。来源: @shawmakesmagic, @DanKornas.
-
本地 AI 跨过实用门槛:Gemma 4 31B 在消费级硬件上以 15 tok/s 从单句提示词生成生产级 UI。来源: @sudoingX.
-
多智能体编排获得真实基础设施:Mission Control(4.2k 星标、32 个面板)、GBrain v0.11(带基准测试的 10 倍更快编排)和 Regina(Markdown 定义智能体,配 SQLite VFS)。来源: @tom_doerr, @Voxyz_ai, @matteocollina.
-
企业治理进入编程智能体领域,Databricks Unity AI Gateway 与 Cisco 的生产 LangGraph 部署,说明它正在从开发者实验转向组织控制。来源: @databricks, @LangChain.
-
智能体安全产出了第一批具体成果:AgentWard(清华的 5 层防御 OS)、skill-scanner(提示词注入检测)和一个 GPT-5.4 智能体在 7 秒内发现 82K 美元赏金。来源: @jiqizhixin, @DanKornas, @nebusecurity.
-
GenericAgent 的 #1 GitHub Trending 位置和约 3K 行架构说明,相比重量级编排,人们更需要极简、自演化框架。来源: @tom_doerr.
-
技能生态分裂为两种分发模式:精选第一方插件(Expo、MongoDB、Nous Research 合作)和几乎无审查的社区 GitHub 仓库。两种模式都还没有在规模化层面解决信任问题。来源: @Baconbrix, @NousResearch, @shawmakesmagic.