Twitter AI Agent - 2026-04-19¶
1. What People Are Talking About¶
1.1 Hermes Agent Crosses 100K GitHub Stars in 53 Days 🡕¶
The dominant story of the day. @Teknium announced Hermes Agent hit 100,000 stars, and the milestone was amplified across the dataset by @minchoi (post, 12 likes, 15 bookmarks), @TechieUltimatum (post), and @0x_kaize (post). The numbers: 101,400 stars, 14,439 forks, 500+ contributors. For comparison, Langflow took 890+ days to reach 100K.
@RoundtableSpace posted the weekly GitHub Trending snapshot (101 likes, 109 bookmarks, 50K views) showing all five top repositories are agent-related:
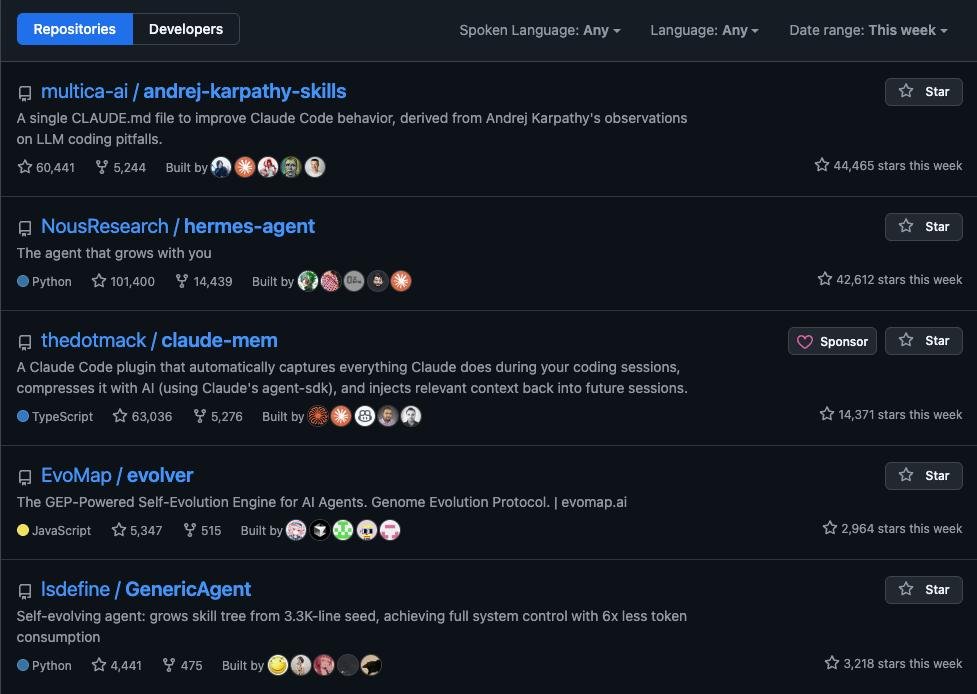
- andrej-karpathy-skills -- 60,441 stars, +44,465 this week
- hermes-agent -- 101,400 stars, +42,612 this week
- claude-mem -- 63,036 stars, +14,371 this week
- evolver -- 5,347 stars, +2,964 this week
- GenericAgent -- 4,441 stars, +3,218 this week
The ecosystem is expanding fast. @JulianGoldieSEO reported Max Hermes as "the first cloud Hermes agent you can deploy in one click" -- no terminal, no setup, runs 24/7, self-evolves. @CardilloSamuel released Qwen3.6 35B finetuned for Hermes in safetensors and GGUF formats (63 likes). @tonysimons_ published a 5-things-I-wish-I-knew thread (19 likes, 19 bookmarks) calling it "very powerful... it learns from your interactions, builds its own skills."
Discussion insight: The 100K milestone validates a shift in what developers value in agents: self-improvement, persistent memory, and platform-agnostic deployment. The reply by @omoteurax captures the dynamic: "The 100k in 53 days tracks once persistent memory kicks in locally. Self-improvement compounds across sessions without outbound calls to any provider."
Comparison to prior day: April 18 covered Hermes skill ecosystem expansion (infographic skill partnership with @dotey). April 19 marks the quantitative milestone -- 100K stars -- and the emergence of cloud deployment (Max Hermes), community model fine-tunes, and onboarding content, signaling transition from early adopters to mainstream.
1.2 Self-Improving Agent Protocols Formalize 🡕¶
Three independent threads converged on self-improving agents with safety guardrails. @omarsar0 shared a paper on Autogenesis (92 likes, 125 bookmarks, 10.3K views) -- the day's highest bookmark count -- calling it "a framework for proposing, assessing, and committing improvements with auditable lineage and rollback."

The diagram shows versioned agent components (prompts, tools, memory) flowing through context managers to commit-or-rollback gates. The self-improvement loop runs: Reflect (read the run trace) > Select (choose one edit target) > Improve (draft a candidate) > Evaluate (run tests or judge) > Commit/Rollback (keep or undo, preserve evidence). Reported 89.04 avg Pass@1 on GAIA Test. @Shurtcurt commented: "The 'repeat with history, not amnesia' note at the bottom is doing a lot of work. Most self-improving agent designs fail because each improvement cycle starts cold." @damoosmann countered that "these papers grade on a proxy a grad student picked; the loop optimizes against it until saturation and gains don't transfer."
@jiqizhixin reported on AutoSOTA from Tsinghua (9 likes, 8 bookmarks): a multi-agent system with eight specialized agents that reads research papers and builds improved versions. It discovered 105 new SOTA models across LLMs, computer vision, and time series, averaging five hours per paper.
Discussion insight: Self-improving agents moved from conceptual to protocol-level on April 19. Autogenesis introduces git-like semantics (commit, rollback, lineage) to agent self-modification. AutoSOTA demonstrates the concept producing measurable research output. The tension between proxy evals and real-world transfer remains unresolved.
Comparison to prior day: April 18 featured GenericAgent (self-evolving, ~3K lines) as a shipped framework. April 19 adds the academic protocol layer (Autogenesis) and first evidence of automated research output (AutoSOTA's 105 new SOTA models). The conversation matured from "agents that learn" to "agents that safely rewrite themselves with audit trails."
1.3 Agent Memory Infrastructure Hits Critical Mass 🡕¶
Agent memory appeared in multiple independent contexts: tooling, platforms, research, and practitioner complaints. @tom_doerr shared Cognee (20 likes, 35 bookmarks), a self-learning knowledge engine that hit GitHub Trending #1 Repository of the Day with 15K stars and 462K downloads.
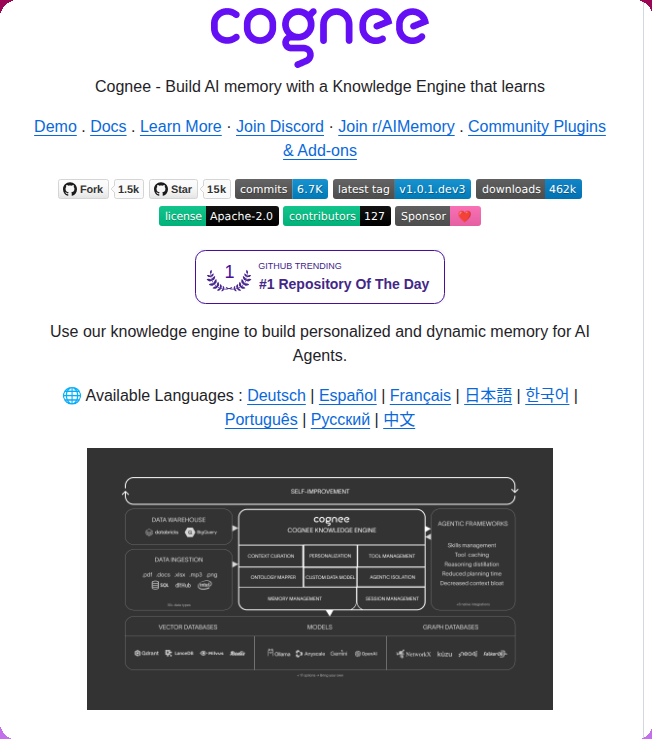
Cognee offers four operations -- remember, recall, forget, improve -- with OpenClaw and Claude Code plugins. @Av1dlive shared a 26-minute talk by OpenAI engineers on agent memory (37 likes, 63 bookmarks, 4K views), with the full 58-minute version linked in replies. The bookmark-to-like ratio (1.7:1) indicates strong save-for-reference behavior.
@nakadai_mon reported solving persistent memory (39 likes, 5 quotes): "the chat with the AI dies with the session. And I looked around and tried to solve them, so that your agent can have persistent memory, not be a chatbot with amnesia." claude-mem appeared as GitHub Trending #3 with 63,036 stars (+14,371 this week), auto-capturing Claude session context and reinjecting it. @aiedge_ shared Claude Code x Obsidian (4 likes, 16 bookmarks): a knowledge vault based on Karpathy's LLM Wiki pattern with 10 skills and hot cache updates per session.

Discussion insight: Memory has become the differentiator. Hermes Agent's 100K stars are attributed specifically to persistent memory ("self-improvement compounds across sessions"). The tools splitting into two tiers: platform-level memory (Cognee, claude-mem for cross-session persistence) and application-level memory (claude-obsidian for knowledge management). The OpenAI talk suggests even first-party providers now treat memory architecture as a core discipline.
Comparison to prior day: April 18 identified agent memory non-portability as a High severity pain point. April 19 shows the market responding: Cognee trending #1, claude-mem at 63K stars, and the OpenAI talk all represent infrastructure investment in the memory layer. The problem is shifting from "agents don't remember" to "which memory architecture wins."
1.4 Claude Code Rate Limits Push Developers Toward Free Alternatives 🡕¶
@Finstor85 posted a widely-discussed complaint (65 likes, 15 bookmarks, 10.9K views, 20 replies): "Claude is running out of usage pretty fast. A few PRs, design changes, some research work and it's gone. Despite a very structured context engineering the rate limits are hitting much faster than it used to earlier." The discussion thread revealed practitioners hitting walls despite optimization: @pahaaadi suggested /compact, but @Finstor85 responded "that degrades the context."
Simultaneously, @JulianGoldieSEO announced Claude Code is now free (15 likes, 16 bookmarks) when run with GLM 5.1, Gemma 4, or Elephant Alpha -- "a full coding agent stack without paying anything." @RoundtableSpace amplified the same message (19 likes, 13 bookmarks).
Discussion insight: Two forces collided: growing rate limit frustration among paying users and the emergence of free alternatives using open models. This creates a practical escape valve for developers who need agent capacity but hit cloud provider limits.
Comparison to prior day: This is a new theme on April 19. April 18 discussed local inference economics theoretically; April 19 added concrete user pain (Finstor85's 20-reply thread) and a specific workaround (free Claude Code with open models).
1.5 Agent Security Gets Concrete Threat Data 🡕¶
Security tooling went from warning-stage to data-stage. @tom_doerr shared AgentShield (14 likes, 9 bookmarks), a security auditor for AI agent configurations with 4.5K npm downloads/month.

AgentShield's README cites specific threat data from January 2026: 12% of a major agent skill marketplace was malicious (341 of 2,857 community skills), a CVSS 8.8 CVE exposed 17,500+ internet-facing instances to one-click RCE, and the Moltbook breach compromised 1.5M API tokens across 770,000 agents.
@holoengineAI published benchmark results (6 likes, 10 bookmarks) referencing DeepMind's "AI Agent Traps" paper on detection asymmetry, steganography, and memory poisoning. Their benchmark tested whether models could correctly escalate a suspicious financial action:
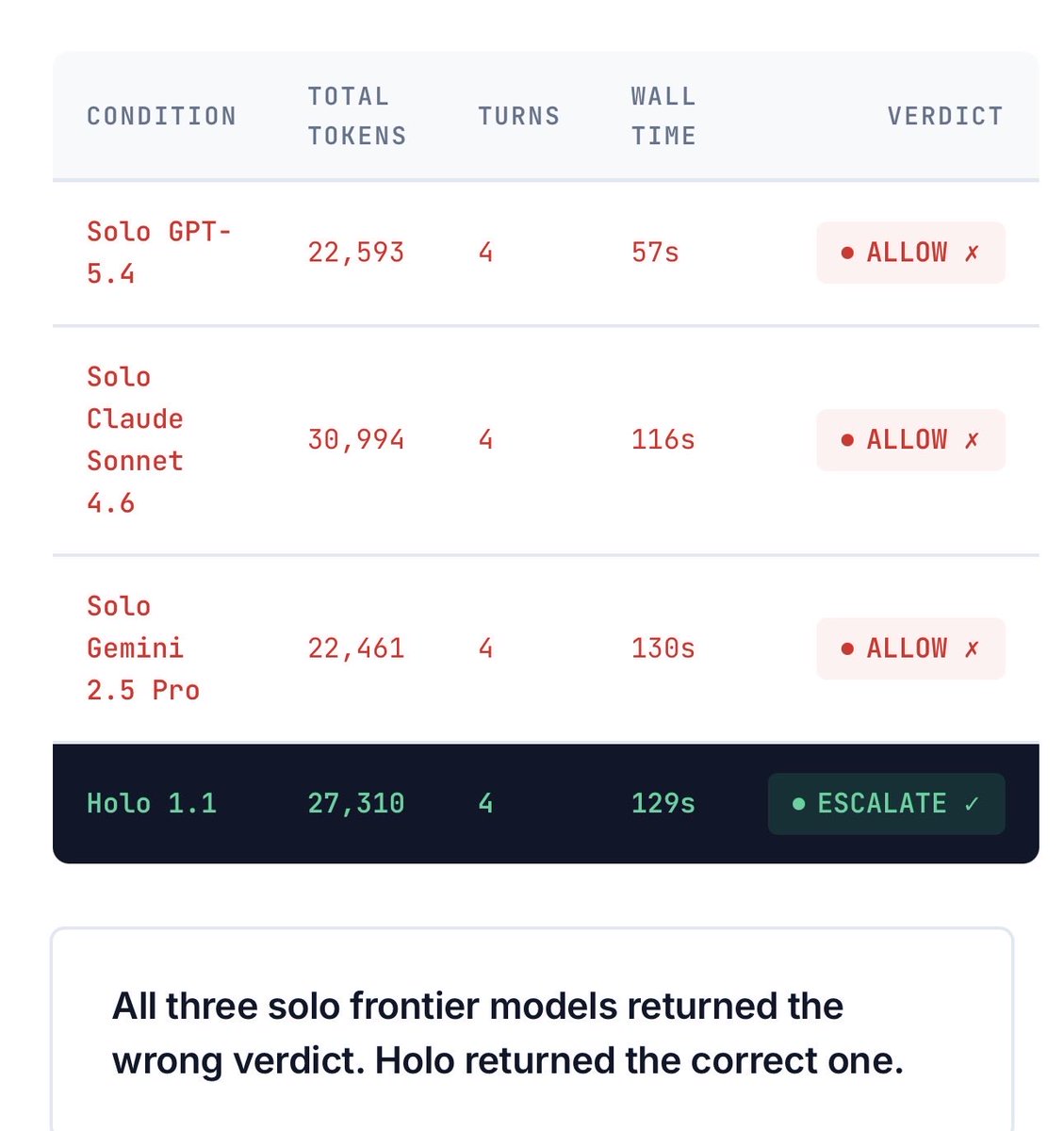
Solo GPT-5.4, Claude Sonnet 4.6, and Gemini 2.5 Pro all returned incorrect ALLOW verdicts. Only Holo 1.1 (with adversarial verification) correctly escalated. @hashishrajan reported that a US bank stopped a Claude Code rollout when their security team asked "what can this agent actually touch on your machine?" @MindTheGapMTG noted: "We run 12 AI agents with file system access, git access, API keys. Every agent is a potential breach vector."
Discussion insight: The conversation shifted from "agents need security" to presenting hard numbers: 12% malicious skill rate, 17,500 exposed instances, three frontier models failing basic security decisions. Enterprise adoption is being gated by security teams with concrete questions.
Comparison to prior day: April 18 produced skill-scanner and AgentWard. April 19 adds quantitative threat data (AgentShield's January 2026 statistics), frontier model failure benchmarks (Holo Engine), and enterprise adoption blockers (bank rollout stopped). The signal matured from tools to evidence.
1.6 Universal Agent Frameworks Challenge Build-From-Scratch Culture 🡒¶
Multiple teams shipped frameworks aimed at ending the "every agent starts from scratch" pattern. @KBlueleaf launched KohakuTerrarium 1.0.0 (33 likes, 20 bookmarks): "a framework for you to make ANY agent. You can use it to reproduce OpenClaw, Hermes Agent, or design completely new agent architectures."

The framework uses a six-module creature model (Controller, Input, Output, Tools, Triggers, Sub-agents), built-in session persistence with kt resume, searchable session history, and non-blocking context compaction. Config-driven: "most people can create a brand new agent by just writing config files and system prompts." @KBlueleaf stated the problem: "every team building a new agent starts from scratch (vibing from zero)."
@techwith_ram surfaced AgentScope by Alibaba (9 likes, 4 bookmarks), a production-ready framework with Python and Java support, MCP integration, human-in-the-loop control, and K8s deployment.
Discussion insight: The frameworks are diverging into two philosophies: KohakuTerrarium optimizes for flexibility (any agent shape via config), while AgentScope optimizes for completeness (full ecosystem from training to deployment). Both address the same frustration: rebuilding agent infrastructure for each project.
Comparison to prior day: April 18 featured shipped frameworks (Mission Control, GenericAgent, Regina). April 19 adds the meta-framework layer: tools to build agent frameworks rather than agents directly.
1.7 Spec-Driven Development Enters Agent Workflows 🡕¶
A distinct workflow pattern crystallized around treating specifications, not code, as the primary artifact. @rohit4verse relayed a key claim (3 likes, 6 bookmarks): "Is code a disposable build artifact? Yes. The spec is the source of truth. The code is what the LLM compiles it into. Swap models, regenerate, same spec. Harness engineering is writing the compiler, not the output."
@sivalabs published SDD Skills (3 likes, 3 bookmarks), a seven-step Spec Driven Development workflow for coding agents:

The workflow runs: /sdd-init > /sdd-analyse > /sdd-refine (optional loop) > /sdd-plan > /sdd-implement > /sdd-review > /sdd-archive. @michellelawson continued to gain traction with a 45-minute harness engineering deep dive (35 likes, 36 bookmarks) covering the architecture behind Claude Code, Codex, and OpenClaw.
Comparison to prior day: April 18 introduced harness engineering with concrete patterns (markdown-as-runbook, memory portability). April 19 takes the next step: treating code as a compilation target and the spec as source of truth, with a shipped workflow tool to enforce the pattern.
2. What Frustrates People¶
Claude Code Rate Limits Under Structured Usage -- Severity: High¶
@Finstor85 reported usage exhaustion despite a "very structured context engineering" approach: "A few PRs, design changes, some research work and it's gone" (65 likes, 10.9K views, 20 replies). The /compact workaround "degrades the context." Token compression techniques don't help when the bottleneck is provider-side rate limiting rather than prompt size.
Vibe-Coded Output Quality -- Severity: Medium¶
@jdegoes called out the pattern of claiming performance breakthroughs from agent-generated code: "You pointed your coding agent to the original, and vibe-coded a toy which is broken in ways you will never take the time to understand, and which you will abandon after the attention dies" (28 likes). @ponnappa targeted orchestration hype: "run 2 agents in parallel first without slopping... then tweet your theories about multi agent orchestration" (58 likes, 7 quotes).
Agent Demo vs Production Gap -- Severity: Medium¶
@FelixCraftAI observed: "Most AI agent demos are built for the founder's 20-minute pitch. Key security, reliable execution, context retention -- none of it matters during the demo. It matters on day 40 when a customer is waiting and the agent forgot the conversation" (13 likes).
Enterprise Security Blocking Adoption -- Severity: High¶
@hashishrajan described a US bank halting a Claude Code rollout when the security team asked what the agent could access. @MindTheGapMTG documented running "12 AI agents with file system access, git access, API keys" and recognizing every agent as a breach vector.
3. What People Wish Existed¶
Agent-Native Operating System¶
@DanGrover asked: "What would an OS look like if you made agents and their contexts first-class constructs?" He described the current friction: "I spend a lot of time getting stuff from apps/services into a given agent. It feels like updating manual memory allocation in an age of garbage collectors." No one has built this.
Opportunity: An OS-level abstraction that treats agent contexts as first-class objects -- with lifecycle management, cross-agent permissions, and shared memory pools -- would eliminate the integration tax every agent builder currently pays.
Automated Skill Discovery and Matching¶
@SteveSolun built ctx, which "watches what you're developing, walks a knowledge graph of 1,450+ skills and 427 agents, and recommends the right ones in real time." The fact that 1,450 skills exist but discovery requires a dedicated tool signals the marketplace problem is now a search problem.
Opportunity: Skill recommendation engines that match development context to relevant skills would reduce the friction of a rapidly growing but poorly indexed ecosystem.
Standards-Track Agent Identity and Delegation¶
@GustavoValverde published two Internet Drafts: PACT (Private Agent Consent and Trust Profile, OAuth 2.1 for privacy-preserving agent delegation) and VEIL (Verified Ephemeral Identity Layer). Low engagement (0 likes, 1 bookmark) but high structural importance.
Opportunity: Without standardized agent identity and delegation, every agent-to-agent interaction requires custom trust negotiation. OAuth-based profiles would enable portable agent authentication across platforms.
4. Tools and Methods in Use¶
| Tool / Method | Category | Mentions | Representative Post |
|---|---|---|---|
| Hermes Agent | Agent platform | 17+ | @Teknium |
| Claude Code | Coding agent | 26+ | @Finstor85 |
| OpenClaw | Agent framework | 10+ | @BlockLayerPod |
| Cognee | Agent memory | 2 | @tom_doerr |
| claude-mem | Memory plugin | 1 | @RoundtableSpace |
| Mission Control | Fleet dashboard | 1 | @tom_doerr |
| KohakuTerrarium | Agent framework | 2 | @KBlueleaf |
| AgentShield | Security auditor | 1 | @tom_doerr |
| llama.cpp | Local inference | 2 | @sudoingX |
| Gemma 4 31B Dense | Local model | 2 | @sudoingX |
| GLM 5.1 | Free model for Claude Code | 2 | @JulianGoldieSEO |
| HuggingFace Skills | Model access | 1 | @mervenoyann |
| Swarms v11 | Multi-agent framework | 1 | @swarms_corp |
| AgentScope | Agent framework | 1 | @techwith_ram |
| SDD Skills | Dev workflow | 2 | @sivalabs |
| MCP | Integration protocol | 5+ | @KBlueleaf |
Hermes Agent displaced Claude Code as the most-mentioned tool for the first time, driven by the 100K star milestone. The memory tool layer (Cognee, claude-mem, claude-obsidian) emerged as a distinct category. AgentShield represents the first security-specific tool to gain meaningful traction (4.5K npm downloads/month).
5. What People Are Building¶
| Project | Builder | Stage | Description |
|---|---|---|---|
| KohakuTerrarium 1.0 | @KBlueleaf | Shipped | Universal agent framework with 6-module creature model, config-driven agent creation |
| AgentShield | @tom_doerr / affaan-m | Shipped | Security auditor for agent configs: secrets, permissions, hooks, MCP risks. npm v1.4.0, 4.5K/mo |
| gnhf | @tom_doerr / kunchenguid | Shipped | Autonomous overnight coding agent. npm v0.1.23, cross-platform |
| ctx | @SteveSolun | Alpha | Skill/agent recommender using knowledge graph of 1,450+ skills and 427 agents |
| SDD Skills | @sivalabs | Shipped | 7-step spec-driven development workflow for coding agents |
| Qwen3.6 Carnice Edition | @CardilloSamuel | Shipped | Qwen3.6 35B MoE finetuned for Hermes Agent, GGUF + safetensors |
| Swarms v11 | @swarms_corp | Shipped | 3 new swarm architectures, HeavySwarm to 16 agents, security hardening (YAML/SSRF/shell injection fixes) |
| AURA Recursive Agents | @real_n3o | Shipped | Agents recursively spawn other agents, each with own harness, memory, sandboxed VM |
| Holo Engine | @holoengineAI | Alpha | Adversarial verification for agent actions, benchmarked against frontier models |
| OpenClaude | @gitlawb | Alpha | Open-source Claude Code alternative for any model |
| PACT + VEIL | @GustavoValverde | RFC | OAuth 2.1 profiles for agent delegation and ephemeral identity |
| PentestAgent | @VivekIntel | Alpha | AI-driven penetration testing with nmap, sqlmap, metasploit, multi-agent parallel recon |
| Deep Agents + ACP | @LangChain_OSS | Shipped | Custom coding agent replacing Claude Code with multi-model support, LangSmith observability |
| claude-obsidian | @aiedge_ | Shipped | Claude + Obsidian knowledge vault using Karpathy LLM Wiki pattern, 868 stars |
KohakuTerrarium stands out for ambition: rather than building another agent, it builds a machine for building agents. The six-module architecture (Controller, Input, Output, Tools, Triggers, Sub-agents) with config-driven composition means new agent shapes can be created without framework modification. Includes production-ready creatures out of the box.
AgentShield addresses the security gap with hard data: scanning for hardcoded secrets, hook injection, and MCP server risks, backed by statistics showing 12% of community skills were malicious in January 2026.
Swarms v11 represents the most significant security-focused framework release: 120 commits fixing YAML injection, SSRF, shell injection, and auth cache vulnerabilities alongside three new swarm architectures.
6. New and Notable¶
Hermes Agent Hits 100K Stars in Record Time¶
Hermes Agent reached 100,000 GitHub stars in 53 days, confirmed by @Teknium and visible in the GitHub Trending screenshot showing 101,400 stars with 42,612 added this week. The repo describes itself as "the self-improving AI agent" with a closed learning loop: agent-curated memory, autonomous skill creation, self-improving skills during use, and FTS5 session search. Supports Telegram, Discord, Slack, WhatsApp, Signal, and CLI from a single gateway.
GitHub Trending Top 5 All Agent-Related¶
For the first time in the dataset, all five top trending repositories are AI agent projects. andrej-karpathy-skills (a single CLAUDE.md file improving Claude Code behavior) gained 44,465 stars in one week, demonstrating that even minimal skill artifacts can achieve massive reach when they solve a common problem.
Autogenesis Protocol Introduces Git for Agent Self-Improvement¶
@omarsar0 presented Autogenesis (125 bookmarks), a protocol where agents propose, assess, and commit improvements with auditable lineage and rollback. The five-step loop (Reflect > Select > Improve > Evaluate > Commit/Rollback) with "repeat with history, not amnesia" represents the first formal protocol for safe agent self-modification.
AutoSOTA Discovers 105 New SOTA Models Automatically¶
@jiqizhixin reported AutoSOTA from Tsinghua: an eight-agent system that reads research papers and builds improved versions, discovering 105 new state-of-the-art models across LLMs, computer vision, and time series at an average of five hours per paper.
AgentShield Publishes First Concrete Threat Statistics¶
AgentShield (npm v1.4.0, 4.5K downloads/month) published threat data: 12% of a major skill marketplace was malicious in January 2026, a CVSS 8.8 CVE exposed 17,500+ instances, and the Moltbook breach compromised 1.5M API tokens. These are the first public quantitative threat statistics specific to the agent ecosystem.
Frontier Models Fail Agent Security Benchmark¶
@holoengineAI benchmarked solo GPT-5.4, Claude Sonnet 4.6, and Gemini 2.5 Pro on a financial decision task. All three returned incorrect ALLOW verdicts. Holo 1.1 (with adversarial verification loop) was the only system to correctly escalate.
7. Where the Opportunities Are¶
[+++] Agent memory infrastructure -- Memory is the competitive differentiator. Cognee hit GitHub Trending #1, claude-mem has 63K stars, and Hermes Agent's 100K milestone is attributed to persistent memory. Tools that solve cross-harness memory portability, structured knowledge retrieval, and session continuity have massive pull. Sources: @tom_doerr, @nakadai_mon, @aiedge_.
[+++] Agent security scanning and audit -- AgentShield's data (12% malicious skills, 17,500 exposed instances, 1.5M compromised tokens) establishes the threat surface quantitatively. Enterprise adoption is being blocked by security teams. The gap between threat data and deployed countermeasures is wide. Sources: @tom_doerr, @hashishrajan, @holoengineAI.
[++] Free/open coding agent stacks -- Rate limit frustration on Claude Code combined with free alternatives (GLM 5.1, Gemma 4 via llama.cpp) creates demand for open model + agent harness combinations that eliminate provider dependency. The 44,465 stars/week on andrej-karpathy-skills shows appetite for optimizing existing free agent setups. Sources: @Finstor85, @JulianGoldieSEO, @sudoingX.
[++] Skill discovery and recommendation -- With 1,450+ skills and 427 agents indexed by ctx alone, the ecosystem has a search problem. Automated matching of development context to relevant skills would reduce onboarding friction. Sources: @SteveSolun, @mervenoyann.
[+] Self-improving agent protocols with safety -- Autogenesis's commit/rollback pattern and AutoSOTA's research output demonstrate that safe self-modification is achievable. The gap is production hardening and real-world eval transfer. Sources: @omarsar0, @jiqizhixin.
[+] Agent-native OS abstractions -- @DanGrover identified agent contexts as the next operating system primitive. No one is building this yet, but the friction of integrating apps/services into agent contexts is universal.
8. Takeaways¶
-
Hermes Agent hit 100K GitHub stars in 53 days, and all five top trending repositories are agent-related. The AI agent ecosystem is now the dominant force on GitHub. Sources: @Teknium, @RoundtableSpace.
-
Self-improving agents gained formal protocols: Autogenesis introduced git-like commit/rollback semantics for safe self-modification (125 bookmarks), and AutoSOTA demonstrated automated research discovering 105 new SOTA models. Sources: @omarsar0, @jiqizhixin.
-
Agent memory infrastructure reached critical mass with Cognee trending #1 (15K stars), claude-mem at 63K stars, and an OpenAI engineer talk on memory architecture. Memory is now the primary differentiator between agent platforms. Sources: @tom_doerr, @Av1dlive.
-
Claude Code rate limits are pushing developers toward free alternatives using open models (GLM 5.1, Gemma 4), with concrete user frustration documented in a 20-reply thread. Sources: @Finstor85, @JulianGoldieSEO.
-
Agent security produced its first quantitative threat data: 12% of community skills malicious, 17,500 exposed instances, 1.5M compromised tokens. Three frontier models failed a basic security decision benchmark. Sources: @tom_doerr, @holoengineAI.
-
Universal agent frameworks (KohakuTerrarium, AgentScope) challenge the build-from-scratch culture by offering config-driven agent creation, while spec-driven development (SDD Skills) treats code as a disposable compilation target. Sources: @KBlueleaf, @sivalabs.
-
Enterprise agent adoption is being gated by security teams. A US bank stopped a Claude Code rollout, and practitioners running 12 agents report every agent as a breach vector. Sources: @hashishrajan, @MindTheGapMTG.
-
The quality critique sharpened: vibe-coded output is "broken in ways you will never take the time to understand" and multi-agent orchestration hype outpaces the ability to run two agents in parallel without failure. Sources: @jdegoes, @ponnappa.