Twitter AI 智能体 - 2026-04-19¶
1. 人们在讨论什么¶
1.1 Hermes Agent 53 天突破 100K GitHub 星标 🡕¶
这是当天的主导故事。@Teknium 宣布 Hermes Agent 达到 100,000 星标,这一里程碑在数据集中被 @minchoi(推文,12 个点赞、15 次收藏)、@TechieUltimatum(推文)和 @0x_kaize(推文)放大。数字是:101,400 星标、14,439 个 fork、500+ 位贡献者。作为对比,Langflow 花了 890+ 天才达到 100K。
@RoundtableSpace 发布了 每周 GitHub Trending 截图(101 个点赞、109 次收藏、50K 次浏览),显示前五个仓库全部是智能体项目:
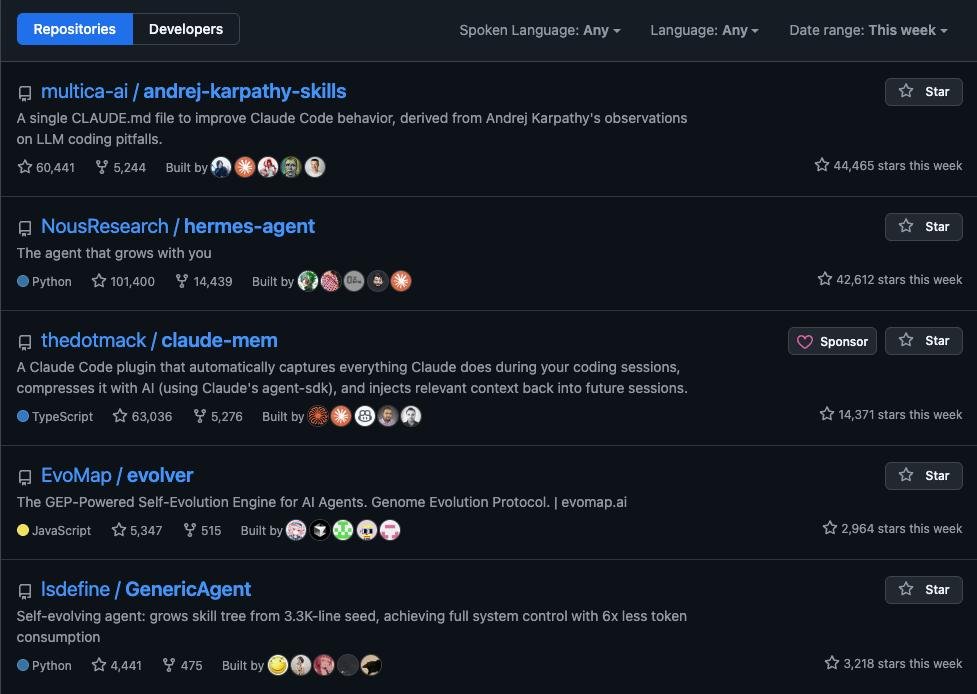
- andrej-karpathy-skills -- 60,441 stars, +44,465 this week
- hermes-agent -- 101,400 stars, +42,612 this week
- claude-mem -- 63,036 stars, +14,371 this week
- evolver -- 5,347 stars, +2,964 this week
- GenericAgent -- 4,441 stars, +3,218 this week
生态正在快速扩张。@JulianGoldieSEO 报道 Max Hermes 是“第一个可一键部署的云端 Hermes 智能体”——无需终端、无需设置,24/7 运行并自我演化。@CardilloSamuel 发布了为 Hermes 微调的 Qwen3.6 35B,提供 safetensors 和 GGUF 格式(63 个点赞)。@tonysimons_ 发布了一条 “我希望早知道的 5 件事”讨论串(19 个点赞、19 次收藏),称它“非常强大……它会从你的互动中学习,并构建自己的技能。”
讨论要点: 100K 里程碑验证了开发者对智能体的价值判断正在转移:自我改进、持久记忆和跨平台部署变得更重要。@omoteurax 的回复抓住了这个动态:“一旦本地持久记忆开始发挥作用,53 天冲到 100k 就说得通了。自我改进会跨会话持续复利,而且不需要向任何提供商发出对外调用。”
与前日对比: 4 月 18 日覆盖了 Hermes 技能生态扩张(与 @dotey 的信息图技能合作)。4 月 19 日是量化里程碑——100K 星标——并出现了云端部署(Max Hermes)、社区模型微调和入门内容,说明它正在从早期采用者进入主流。
1.2 自我改进智能体协议正式化 🡕¶
三条独立讨论汇聚到带安全护栏的自我改进智能体。@omarsar0 分享了一篇 Autogenesis 论文(92 个点赞、125 次收藏、10.3K 次浏览)——当天收藏数最高——称其为“一个用于提出、评估并提交改进的框架,具备可审计的谱系和回滚能力。”

图中展示了版本化智能体组件(提示词、工具、记忆)如何经过上下文管理器,进入提交或回滚关卡。自我改进循环的运行顺序是:反思(读取运行轨迹)> 选择(选择一个编辑目标)> 改进(起草候选方案)> 评估(运行测试或评审)> 提交/回滚(保留或撤回,并保存证据)。报告的 GAIA Test 平均 Pass@1 为 89.04。@Shurtcurt 评论:“底部那句‘带着历史重复,而不是带着失忆重来’分量很重。大多数自我改进智能体设计之所以失败,是因为每一轮改进循环都从冷启动开始。”@damoosmann 反驳说,“这些论文评分用的是某个研究生挑的代理指标;这个循环会一路朝着它优化直到饱和,之后增益就无法迁移了。”
@jiqizhixin 报道了清华的 AutoSOTA(9 个点赞、8 次收藏):一个由 8 个专门智能体组成的多智能体系统,可读取研究论文并构建改进版本。它在 LLM、计算机视觉和时间序列领域发现了 105 个新的 SOTA 模型,平均每篇论文 5 小时。
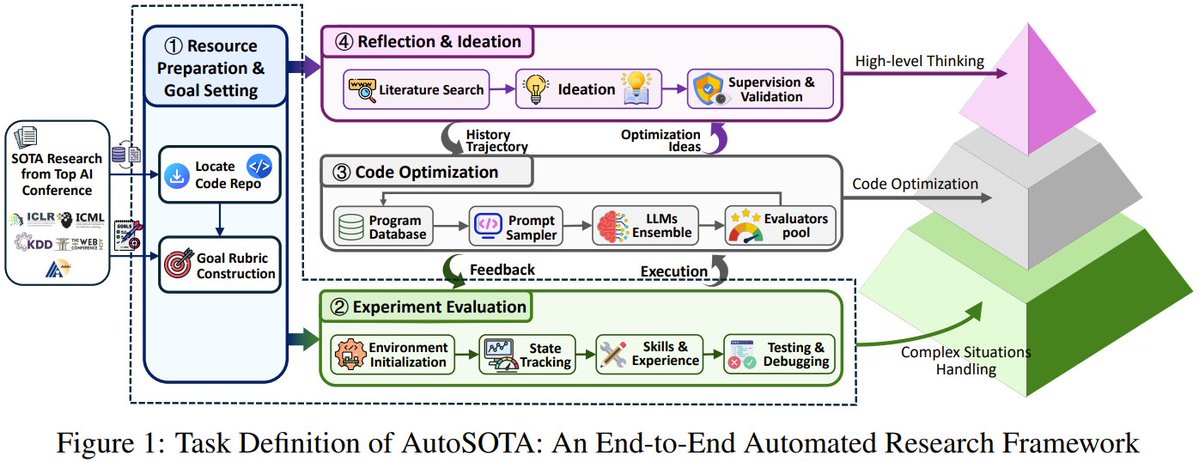
讨论要点: 自我改进智能体在 4 月 19 日从概念走到协议层面。Autogenesis 把类 Git 语义(commit、rollback、lineage)引入智能体自我修改。AutoSOTA 则展示这个概念能产出可衡量的研究结果。代理评测和现实迁移之间的张力仍未解决。
与前日对比: 4 月 18 日,GenericAgent(自我演化、约 3K 行)作为已发布框架出现。4 月 19 日增加了学术协议层(Autogenesis)和自动化研究产出的第一批证据(AutoSOTA 的 105 个新 SOTA 模型)。讨论从“会学习的智能体”成熟为“能带着审计轨迹安全重写自己的智能体”。
1.3 智能体记忆基础设施达到临界规模 🡕¶
智能体记忆出现在多个独立语境中:工具链、平台、研究和从业者抱怨。@tom_doerr 分享了 Cognee(20 个点赞、35 次收藏),这是一个自学习知识引擎,登上 GitHub Trending 当日 #1 仓库,拥有 15K 星标和 462K 下载量。
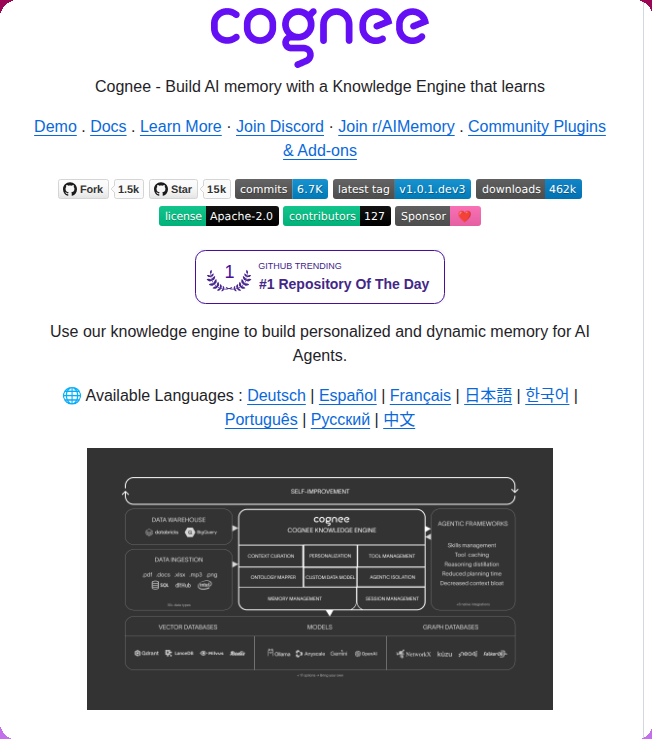
Cognee 提供四个操作——remember、recall、forget、improve——并支持 OpenClaw 和 Claude Code 插件。@Av1dlive 分享了一场 OpenAI 工程师关于智能体记忆的 26 分钟演讲(37 个点赞、63 次收藏、4K 次浏览),完整 58 分钟版本在回复中链接。收藏/点赞比(1.7:1)说明用户很愿意保存起来供以后参考。
@nakadai_mon 报告自己解决了持久记忆(39 个点赞、5 次引用):“和 AI 的对话会随着会话结束一起消失。我四处寻找并试图解决这个问题,让你的智能体拥有持久记忆,而不是变成一个失忆的聊天机器人。”claude-mem 出现在 GitHub Trending #3,拥有 63,036 星标(本周 +14,371),可自动捕获 Claude 会话上下文并重新注入。@aiedge_ 分享了 Claude Code x Obsidian(4 个点赞、16 次收藏):一个基于 Karpathy 的 LLM Wiki 模式的知识库,包含 10 个技能,并在每个会话中热更新缓存。

讨论要点: 记忆已经成为差异化因素。Hermes Agent 的 100K 星标被专门归因于持久记忆(“自我改进会跨会话持续复利”)。工具正在分成两层:平台级记忆(Cognee、用于跨会话持久化的 claude-mem)和应用级记忆(用于知识管理的 claude-obsidian)。OpenAI 演讲说明,即便第一方提供商也把记忆架构当作核心学科。
与前日对比: 4 月 18 日把智能体记忆不可迁移性列为高严重度痛点。4 月 19 日看到市场回应:Cognee 登上 #1 热门、claude-mem 达到 63K 星标,以及 OpenAI 演讲都代表了对记忆层的基础设施投入。问题正在从“智能体记不住事情”转向“哪种记忆架构会胜出”。
1.4 Claude Code Rate Limits 推动开发者转向免费替代方案 🡕¶
@Finstor85 发布了一条 被广泛讨论的抱怨(65 个点赞、15 次收藏、10.9K 次浏览、20 条回复):“Claude 的用量耗尽得非常快。几个 PR、设计改动、一些研究工作就没了。即便上下文工程已经非常结构化,限流来得还是比以前快得多。”讨论串显示,从业者即便优化也会撞墙:@pahaaadi 建议 /compact,但 @Finstor85 回应说“那会降低上下文质量”。
与此同时,@JulianGoldieSEO 宣布 Claude Code 现在免费(15 个点赞、16 次收藏),只要搭配 GLM 5.1、Gemma 4 或 Elephant Alpha 运行——“这就是一整套完整的编程智能体栈,而且不用花一分钱。”@RoundtableSpace 放大 了同一信息(19 个点赞、13 次收藏)。
讨论要点: 两股力量撞在一起:付费用户的限流挫败感上升,以及基于开源模型的免费替代方案出现。这为需要智能体容量、但被云供应商限额卡住的开发者提供了现实逃生口。
与前日对比: 这是 4 月 19 日的新主题。4 月 18 日以理论方式讨论了本地推理经济性;4 月 19 日增加了具体用户痛点(Finstor85 的 20 条回复讨论)和一个具体绕行方案(用开放模型免费跑 Claude Code)。
1.5 智能体安全获得具体威胁数据 🡕¶
安全工具从警示阶段进入数据阶段。@tom_doerr 分享了 AgentShield(14 个点赞、9 次收藏),这是一个 AI 智能体配置安全审计器,每月有 4.5K npm 下载量。

AgentShield 的 README 引用了 2026 年 1 月的具体威胁数据:某大型智能体技能市场中 12% 是恶意内容(2,857 个社区技能中有 341 个),一个 CVSS 8.8 的 CVE 让 17,500+ 个暴露在互联网的实例面临一键 RCE,Moltbook 事件则导致 770,000 个智能体的 1.5M API tokens 被泄露。
@holoengineAI 发布了 基准测试结果(6 个点赞、10 次收藏),引用 DeepMind 的《AI Agent Traps》论文,主题包括检测不对称、隐写术和记忆投毒。他们的基准测试考察模型是否能正确升级一个可疑金融动作:
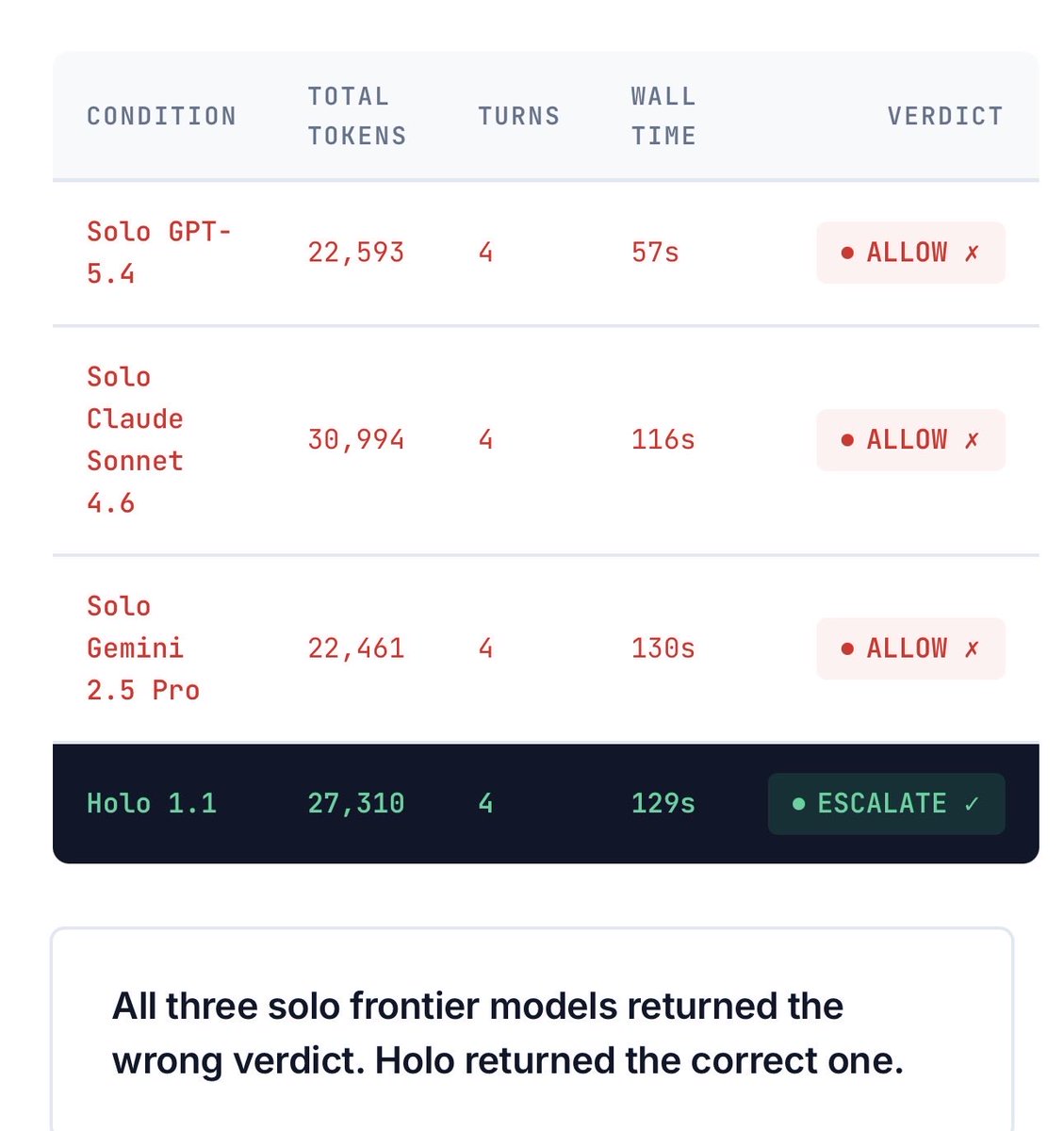
单独使用 GPT-5.4、Claude Sonnet 4.6 和 Gemini 2.5 Pro 都返回了错误的 ALLOW 判定。只有带对抗式验证的 Holo 1.1 正确升级。@hashishrajan 报道,一家 美国银行暂停了 Claude Code 推出,因为安全团队问“这个智能体到底能碰你机器上的哪些东西?”@MindTheGapMTG 指出:“我们运行着 12 个 AI 智能体,它们拥有文件系统访问权限、git 访问权限和 API keys。每个智能体都是潜在的入侵向量。”
讨论要点: 讨论从“智能体需要安全保障”转向提供硬数字:12% 恶意技能比例、17,500 个暴露实例、三个前沿模型在基本安全决策上失败。企业采用正在被安全团队用具体问题卡住。
与前日对比: 4 月 18 日产出了 skill-scanner 和 AgentWard。4 月 19 日增加了量化威胁数据(AgentShield 的 2026 年 1 月统计)、前沿模型失败基准测试(Holo Engine)和企业采用阻碍(银行停止推出)。信号从工具成熟到证据。
1.6 通用智能体框架挑战从零构建文化 🡒¶
多个团队发布了旨在结束“每个智能体都从零开始”模式的框架。@KBlueleaf 发布了 KohakuTerrarium 1.0.0(33 个点赞、20 次收藏):“这是一个让你构建任意智能体的框架。你可以用它复现 OpenClaw、Hermes Agent,或者设计全新的智能体架构。”

该框架采用六模块生物模型(Controller、Input、Output、Tools、Triggers、Sub-agents),内置会话持久化,支持 kt resume、可搜索会话历史,以及非阻塞上下文压缩。它是配置驱动的:“大多数人只要写配置文件和系统提示词,就能创建一个全新的智能体。”@KBlueleaf 说明了问题:“每个构建新智能体的团队都得从零开始摸索。”
@techwith_ram 介绍了阿里巴巴的 AgentScope(9 个点赞、4 次收藏),这是一个可用于生产的框架,支持 Python 和 Java、MCP 集成、人在回路控制和 K8s 部署。
讨论要点: 这些框架分化出两种哲学:KohakuTerrarium 优化灵活性(通过配置支持任意智能体形态),AgentScope 优化完整性(从训练到部署的完整生态)。两者都回应同一个挫败点:每个项目都要重建智能体基础设施。
与前日对比: 4 月 18 日出现了已发布框架(Mission Control、GenericAgent、Regina)。4 月 19 日新增元框架层:构建智能体框架的工具,而不只是直接构建智能体。
1.7 规格驱动开发进入智能体工作流 🡕¶
围绕“规范而不是代码才是主要产物”的工作流模式变得清晰。@rohit4verse 转述了一个 关键观点(3 个点赞、6 次收藏):“代码是不是一次性的构建产物?是。规范才是真正的事实来源。代码只是 LLM 把它编译出来的结果。换个模型、重新生成,规范还是同一个。运行框架工程写的是编译器,而不是输出结果。”
@sivalabs 发布了 SDD Skills(3 个点赞、3 次收藏),一个面向编程智能体的七步规格驱动开发工作流:

流程为:/sdd-init > /sdd-analyse > /sdd-refine(可选循环)> /sdd-plan > /sdd-implement > /sdd-review > /sdd-archive。@michellelawson 的 45 分钟运行框架工程深度解析 继续获得热度(35 个点赞、36 次收藏),内容覆盖 Claude Code、Codex 和 OpenClaw 背后的架构。
与前日对比: 4 月 18 日用具体模式引入运行框架工程(把 Markdown 当 runbook、记忆可迁移)。4 月 19 日再进一步:把代码当作编译目标,把规范当作事实来源,并用一个已发布的工作流工具来强制执行该模式。
2. 令人困扰的问题¶
结构化使用下 Claude Code 限流 -- Severity: High¶
@Finstor85 报告,即便采用“高度结构化的上下文工程”方法,也会 耗尽用量:“几个 PR、设计改动、一些研究工作就没了”(65 个点赞、10.9K 次浏览、20 条回复)。/compact 权宜方案“会降低上下文质量”。当瓶颈是供应商侧限流而不是提示词长度时,token 压缩技术帮不上忙。
Vibe-Coded 输出质量 -- Severity: Medium¶
@jdegoes 点名批评 那种宣称智能体生成代码带来性能突破的模式:“你把编程智能体对准原始版本,然后凭感觉拼出一个小玩具。它坏掉的地方,你永远不会花时间去理解;等热度过去,你也会把它扔掉。”(28 个点赞)。@ponnappa 针对编排炒作发问:“先别写出一堆烂东西,先把 2 个智能体并行跑通,再来发你那些多智能体编排理论。”(58 个点赞、7 次引用)。
智能体演示与生产差距 -- Severity: Medium¶
@FelixCraftAI 观察到:“大多数 AI 智能体演示,都是为了创始人那 20 分钟的路演而搭的。关键安全性、可靠执行和上下文保留——在演示时都不重要。但到了第 40 天,当客户在等,而智能体已经忘了那次对话时,这些问题就全都重要了。”(13 个点赞)。
企业安全阻断采用 -- Severity: High¶
@hashishrajan 描述一家 美国银行暂停 Claude Code 推出,原因是安全团队问这个智能体能访问什么。@MindTheGapMTG 记录 自己运行“12 个带文件系统访问权限、git 访问权限和 API keys 的 AI 智能体”,并意识到每个智能体都是入侵向量。
3. 人们期望的功能¶
智能体原生操作系统¶
@DanGrover 问道:“如果把智能体及其上下文都当作一等构造,一个 OS 会是什么样?” 他描述了当前摩擦:“我花很多时间把应用/服务里的内容搬进某个智能体。这感觉就像在垃圾回收器时代还得手动处理内存分配。”还没人真正构建这个。
机会:一个 OS 级抽象,把智能体上下文当作一等对象——带生命周期管理、跨智能体权限和共享记忆池——将消除每个智能体构建者当前都要支付的集成成本。
自动化技能发现与匹配¶
@SteveSolun 构建了 ctx,它会“观察你正在开发的内容,遍历包含 1,450+ 个技能和 427 个智能体的知识图谱,并实时推荐合适的对象”。1,450 个技能已经存在,但发现还需要专门工具,这说明市场问题已经变成搜索问题。
机会:能把开发上下文匹配到合适技能的技能推荐引擎,将降低快速增长但索引不良生态的使用摩擦。
标准路线上的智能体身份与委托¶
@GustavoValverde 发布了 两份互联网草案:PACT(《Private Agent Consent and Trust Profile》,用于隐私保护型智能体委托的 OAuth 2.1)和 VEIL(《Verified Ephemeral Identity Layer》)。互动很低(0 个点赞、1 次收藏),但结构重要性很高。
机会:没有标准化智能体身份和委托,每次智能体间交互都需要自定义信任协商。基于 OAuth 的 profiles 将使跨平台可移植智能体认证成为可能。
4. 使用中的工具与方法¶
| 工具 / 方法 | 类别 | 提及次数 | 代表帖子 |
|---|---|---|---|
| Hermes Agent | Agent platform | 17+ | @Teknium |
| Claude Code | Coding agent | 26+ | @Finstor85 |
| OpenClaw | Agent framework | 10+ | @BlockLayerPod |
| Cognee | Agent memory | 2 | @tom_doerr |
| claude-mem | Memory plugin | 1 | @RoundtableSpace |
| Mission Control | Fleet dashboard | 1 | @tom_doerr |
| KohakuTerrarium | Agent framework | 2 | @KBlueleaf |
| AgentShield | Security auditor | 1 | @tom_doerr |
| llama.cpp | Local inference | 2 | @sudoingX |
| Gemma 4 31B Dense | Local model | 2 | @sudoingX |
| GLM 5.1 | Free model for Claude Code | 2 | @JulianGoldieSEO |
| HuggingFace Skills | Model access | 1 | @mervenoyann |
| Swarms v11 | Multi-agent framework | 1 | @swarms_corp |
| AgentScope | Agent framework | 1 | @techwith_ram |
| SDD Skills | Dev workflow | 2 | @sivalabs |
| MCP | Integration protocol | 5+ | @KBlueleaf |
Hermes Agent 首次取代 Claude Code 成为提及最多的工具,主要由 100K 星标里程碑驱动。记忆工具层(Cognee、claude-mem、claude-obsidian)成为独立类别。AgentShield 是第一个获得明显热度的安全专用工具(每月 4.5K npm 下载量)。
5. 人们在构建什么¶
| 项目 | 构建者 | 阶段 | 描述 |
|---|---|---|---|
| KohakuTerrarium 1.0 | @KBlueleaf | Shipped | 带 6-module creature model 的通用 agent framework,通过 config-driven agent creation |
| AgentShield | @tom_doerr / affaan-m | Shipped | Agent configs 安全审计:secrets、permissions、hooks、MCP risks。npm v1.4.0,4.5K/mo |
| gnhf | @tom_doerr / kunchenguid | Shipped | Autonomous overnight coding agent。npm v0.1.23,cross-platform |
| ctx | @SteveSolun | Alpha | 使用 1,450+ skills 和 427 agents 的 knowledge graph 做 skill/agent recommender |
| SDD Skills | @sivalabs | Shipped | 面向 coding agents 的 7-step spec-driven development workflow |
| Qwen3.6 Carnice Edition | @CardilloSamuel | Shipped | 为 Hermes Agent 微调的 Qwen3.6 35B MoE,GGUF + safetensors |
| Swarms v11 | @swarms_corp | Shipped | 3 个新 swarm architectures、HeavySwarm 到 16 agents、安全加固(YAML/SSRF/shell injection fixes) |
| AURA Recursive Agents | @real_n3o | Shipped | Agents 递归 spawn 其他 agents,每个都有自己的 harness、memory、sandboxed VM |
| Holo Engine | @holoengineAI | Alpha | 面向 agent actions 的 adversarial verification,已对 frontier models 做 benchmark |
| OpenClaude | @gitlawb | Alpha | 适配任意模型的 open-source Claude Code alternative |
| PACT + VEIL | @GustavoValverde | RFC | 用于 agent delegation 和 ephemeral identity 的 OAuth 2.1 profiles |
| PentestAgent | @VivekIntel | Alpha | AI-driven penetration testing,带 nmap、sqlmap、metasploit、multi-agent parallel recon |
| Deep Agents + ACP | @LangChain_OSS | Shipped | 取代 Claude Code 的 custom coding agent,支持 multi-model 和 LangSmith observability |
| claude-obsidian | @aiedge_ | Shipped | Claude + Obsidian knowledge vault,使用 Karpathy LLM Wiki pattern,868 stars |
KohakuTerrarium 的野心最突出:它不是再构建一个智能体,而是构建一台用来构建智能体的机器。六模块架构(Controller、Input、Output、Tools、Triggers、Sub-agents)配合配置驱动组合,意味着无需修改框架就能创建新的智能体形态。开箱即包含生产可用的生物体。
AgentShield 用硬数据回应安全缺口:扫描硬编码密钥、钩子注入和 MCP 服务器风险,并以 2026 年 1 月 12% 社区技能为恶意内容的统计作为支撑。
Swarms v11 是最重要的安全导向框架版本:120 个 commits 修复 YAML 注入、SSRF、shell 注入和认证缓存漏洞,同时加入三种新群体架构。
6. 新动态与亮点¶
Hermes Agent 以创纪录速度达到 100K 星标¶
Hermes Agent 在 53 天内达到 100,000 GitHub 星标,由 @Teknium 确认,并可在 GitHub Trending 截图 中看到:101,400 星标,本周新增 42,612。该仓库自称“会自我改进的 AI 智能体”,具有闭环学习:智能体策划的记忆、自主技能创建、使用中的自我改进技能,以及 FTS5 会话搜索。它通过单一网关支持 Telegram、Discord、Slack、WhatsApp、Signal 和 CLI。
GitHub Trending 前 5 全部是智能体项目¶
这是数据集中第一次,前五个热门仓库 全部是 AI 智能体项目。andrej-karpathy-skills(一个改进 Claude Code 行为的单一 CLAUDE.md 文件)一周获得 44,465 星标,证明即便是最小技能产物,只要解决共同问题,也能获得巨大传播。
Autogenesis 协议为智能体自我改进引入 Git¶
@omarsar0 展示了 Autogenesis(125 次收藏),这是一个让智能体提出、评估并提交改进的协议,带可审计谱系和回滚。五步循环(Reflect > Select > Improve > Evaluate > Commit/Rollback)以及“带着历史重复,而不是带着失忆重来”,代表第一个安全智能体自我修改的正式协议。
AutoSOTA 自动发现 105 个新 SOTA 模型¶
@jiqizhixin 报道了清华的 AutoSOTA:一个八智能体系统,读取研究论文并构建改进版本,在 LLM、计算机视觉和时间序列中发现 105 个新的最先进模型,平均每篇论文 5 小时。
AgentShield 发布首批具体威胁统计¶
AgentShield(npm v1.4.0,每月 4.5K 下载量)发布了威胁数据:2026 年 1 月某大型技能市场中 12% 为恶意内容,一个 CVSS 8.8 CVE 暴露 17,500+ 个实例,Moltbook 事件泄露 1.5M API tokens。这是首批公开的、专门针对智能体生态的量化威胁统计。
前沿模型在智能体安全基准测试上失败¶
@holoengineAI 对单独使用的 GPT-5.4、Claude Sonnet 4.6 和 Gemini 2.5 Pro 做了基准测试,在一项金融决策任务上三者都返回错误 ALLOW 判定。只有带对抗式验证循环的 Holo 1.1 正确升级。
7. 机会在哪里¶
[+++] 智能体记忆基础设施 -- 记忆是竞争差异化因素。Cognee 登上 GitHub Trending #1,claude-mem 有 63K 星标,Hermes Agent 的 100K 里程碑也归因于持久记忆。解决跨运行框架记忆可移植性、结构化知识检索和会话连续性的工具有巨大吸引力。来源:@tom_doerr, @nakadai_mon, @aiedge_.
[+++] 智能体安全扫描与审计 -- AgentShield 的数据(12% 恶意技能、17,500 个暴露实例、1.5M 泄露 tokens)量化了威胁面。企业采用正在被安全团队阻断。威胁数据与已部署对策之间差距很大。来源:@tom_doerr, @hashishrajan, @holoengineAI.
[++] 免费/开放编程智能体栈 -- Claude Code 的限流挫败感,加上免费替代方案(GLM 5.1、通过 llama.cpp 的 Gemma 4),为消除提供商依赖的开放模型 + 智能体运行框架组合创造需求。andrej-karpathy-skills 每周 +44,465 星标,说明人们渴望优化现有免费智能体方案。来源:@Finstor85, @JulianGoldieSEO, @sudoingX.
[++] 技能发现与推荐 -- 仅 ctx 就索引了 1,450+ 个技能和 427 个智能体,生态已经有搜索问题。根据开发上下文自动匹配合适技能,将降低入门摩擦。来源:@SteveSolun, @mervenoyann.
[+] 带安全性的自我改进智能体协议 -- Autogenesis 的提交/回滚模式和 AutoSOTA 的研究产出表明,安全自我修改是可行的。缺口在生产加固和现实评测迁移。来源:@omarsar0, @jiqizhixin.
[+] 智能体原生 OS 抽象 -- @DanGrover 指出智能体上下文是下一个操作系统原语。还没有人在构建这个,但把应用/服务集成进智能体上下文的摩擦是普遍的。
8. 要点总结¶
-
Hermes Agent 在 53 天内达到 100K GitHub 星标,且前五个热门仓库全部是智能体项目。AI 智能体生态现在是 GitHub 上的主导力量。来源:@Teknium, @RoundtableSpace.
-
自我改进智能体获得正式协议:Autogenesis 引入用于安全自我修改的类 Git 提交/回滚语义(125 次收藏),AutoSOTA 展示自动化研究发现 105 个新 SOTA 模型。来源:@omarsar0, @jiqizhixin.
-
智能体记忆基础设施达到临界规模:Cognee 登上 #1 热门(15K 星标)、claude-mem 达到 63K 星标,以及一场 OpenAI 工程师关于记忆架构的演讲。记忆现在是智能体平台之间的主要差异化因素。来源:@tom_doerr, @Av1dlive.
-
Claude Code 限流正把开发者推向使用开源模型(GLM 5.1、Gemma 4)的免费替代方案,并在一个 20 条回复的讨论中记录了具体用户挫败。来源:@Finstor85, @JulianGoldieSEO.
-
智能体安全产出首批量化威胁数据:12% 社区技能为恶意内容、17,500 个暴露实例、1.5M 泄露 tokens。三个前沿模型在基本安全决策基准测试上失败。来源:@tom_doerr, @holoengineAI.
-
通用智能体框架(KohakuTerrarium、AgentScope)通过配置驱动的智能体创建挑战从零构建文化;而规格驱动开发(SDD Skills)把代码当作一次性编译目标。来源:@KBlueleaf, @sivalabs.
-
企业智能体采用正在被安全团队卡住。一家美国银行暂停 Claude Code 推出,从业者运行 12 个智能体时也报告每个智能体都是入侵向量。来源:@hashishrajan, @MindTheGapMTG.
-
质量批评更尖锐:凭感觉编出来的输出“坏在你永远不会花时间理解的地方”,多智能体编排炒作超过了“能不制造垃圾地并行跑两个智能体”的能力。来源:@jdegoes, @ponnappa.