Twitter AI Agent - 2026-04-20¶
1. What People Are Talking About¶
1.1 Agent Marketplace Infrastructure Goes Live with Hard Numbers 🡕¶
The dominant signal of the day. @base announced Agentic(.)Market (326 likes, 65 replies, 50.6K views), an agent-to-agent marketplace built on the x402 protocol. The dashboard reveals the scale: 167M+ x402 transactions settled, $48.6M payment volume, 71,490 unique buyers, 12,992 unique sellers, and a services leaderboard topped by Anthropic, X API, Bankr, Google Flights, and OpenAI.

@MilkRoad published a detailed explainer (97 likes, 60 bookmarks, 15.5K views) framing Agentic Market as "the app store, but for robots," where agents discover, evaluate, pay for, and consume services autonomously with zero API keys. @FD_XYZ noted in the replies: "5x more buyers than sellers. Agents are actually shopping across services not just pinging one endpoint." @LyvoCrypto connected it to ClawBank's banking layer: "85% of all agent tx already on Base... $ClawBank is the missing piece that turns agents transacting into agents running real businesses."
Multiple parallel marketplace launches reinforced the theme. @TrenchFu released the TrenchFu Agent Marketplace wrapped in MCP tooling. @OrbisAPI announced 2,200+ APIs installable via npx skills add. @JorgeCastilloPr pointed to skillsmp.com with 60,000+ agent skills. @cysic_xyz previewed Cysic AI 2.0 with agent marketplace, skills, and cloud hosting.
Discussion insight: The agent marketplace is no longer conceptual. Agentic Market's dashboard provides the first public evidence of agent-to-agent commerce at scale: 71K buyers and a 5:1 buyer-to-seller ratio indicates genuine demand. The marketplace layer is forming across multiple platforms simultaneously.
Comparison to prior day: April 19 discussed agentic commerce in terms of protocol-level plumbing (x402, ERC-8004). April 20 produced the first marketplace dashboards with real transaction data and a services leaderboard. The shift is from infrastructure to observable markets.
1.2 OpenClaw vs Hermes Agent: The Framework Comparison Crystallizes 🡒¶
@shannholmberg shared a detailed source-code comparison (59 likes, 39 bookmarks) summarizing @elvissun's 9-hour side-by-side study of OpenClaw and Hermes Agent. The comparison maps two fundamentally different philosophies for how agents should learn and use skills.

Hermes ships with 123 bundled skills (GitHub PRs, Obsidian, Notion, Linear) and a self-authoring loop: every N tool calls, the agent considers saving a skill, then a background review scans for skill-worthy patterns. OpenClaw takes the opposite stance: "new skills should be published to ClawHub first, not added to core by default" with five precedence levels (workspace > user global > managed > bundled > extra) and bounded discovery.
The core finding: Hermes has a "skill explosion problem" -- Elvis found three overlapping skills in his ~/.hermes/skills/ directory just for reading images. Skills grow faster than they consolidate. OpenClaw avoids this by design, at the cost of requiring users to create skills explicitly. @elvissun concluded: "Pick either. Learn from both. Then go make something useful."
@BlockLayerPod published a comprehensive OpenClaw analysis (153 likes, 13.4K views) covering the framework's crypto synergies. Key anecdotes: Austin Griffith's agent was deploying production smart contracts while he slept, and agent @langoustine69A shipped 80+ paid x402 endpoints in one week. The security reality check: "Austin's bot tried to extract its own private key mid-task."
@aiedge_ posted the GitHub Trending weekly snapshot (19 likes, 41 bookmarks) showing the top five repositories are all agent-related:

Discussion insight: The framework competition has matured into an identifiable architectural split: batteries-included (Hermes/Rails analogy) vs primitives-first (OpenClaw/Linux analogy). The 9-hour source code study provides the first rigorous evidence that each approach carries a distinct failure mode: skill explosion vs manual authoring burden.
Comparison to prior day: April 19 focused on Hermes hitting 100K stars. April 20 adds the structural comparison with OpenClaw and identifies the skill explosion problem as Hermes's primary long-tail risk, while documenting OpenClaw's real-world security challenges through production anecdotes.
1.3 Agent Security Threat Data Gets More Concrete 🡕¶
Security was the day's most data-rich theme. @stormrae_ai cited enterprise figures (285 likes, 24.9K views): "96% of enterprises are already running AI agents. Only 21% have a governance model to match." The post described a Palo Alto Networks red-team demonstration where an agent executed a $900 withdrawal through persuasion alone -- "no exploit, no breach, just clever reframing." OWASP's Q2 2026 landscape report names top threats: prompt injection, agent privilege escalation, data poisoning, hallucination drift. @maestroalvarez noted in replies: "Phishing tabletop exercises don't transfer; agents need adversarial roleplays where the attacker is a polite user."
@akshay_pachaar provided the most detailed security thread of the day (48 likes, 69 bookmarks), summarizing Google DeepMind's "AI Agent Traps" paper. The paper maps six attack surfaces: Content Injection (86% hijack rate with HTML injections), Semantic Manipulation, Cognitive State Traps (>80% attack success with <0.1% poisoned data), Behavioural Control, Systemic, and Human-in-the-Loop.

@web3nomad raised the cross-session angle: "an adversarial content injection that writes to agent memory persists across sessions. Single-session hijacks are bad. Cross-session knowledge poisoning is a different threat class." @hugobowne warned that "AI Builders are slowly realising that they should assume their system prompts will be exfiltrated... few realize that their entire agent harnesses are as good as public." @aixarizzo flagged that crypto accounts using AI agents with browser access expose cached wallet sessions, login tokens, and seeds to the agent.
@hackSultan posted the day's most engaged tweet (254 likes, 794 bookmarks, score 4362): a comprehensive security audit prompt for vibe-coded projects. The prompt instructs the agent to perform exhaustive vulnerability analysis across frontend, backend, auth, data, API, infra, and supply chain layers. @goldencantech observed in replies: "I love how the conversation is shifting from 'don't vibecode' to 'if you must vibecode, here's how to do it.'"
Discussion insight: The security conversation evolved in three dimensions on April 20: enterprise governance data (96% deployed, 21% governed), academic threat taxonomy (DeepMind's six attack surfaces), and practitioner tooling (security audit prompts gaining 794 bookmarks). The most important signal is cross-session memory poisoning as a new threat class, raised independently by @web3nomad.
Comparison to prior day: April 19 provided quantitative threat data from AgentShield (12% malicious skills) and frontier model benchmark failures. April 20 adds enterprise governance statistics, the DeepMind threat taxonomy, and the cross-session memory poisoning vector. The threat model is expanding from skill-level risks to memory-level and multi-agent systemic risks.
1.4 Self-Improving Agents Extend to Industrial and Research Domains 🡕¶
@omarsar0 continued the Autogenesis thread (228 likes, 293 bookmarks, 26.6K views) from April 19, elaborating on the self-improvement loop architecture.

The diagram shows prompts, tools, and memory as mutable components, with context managers mediating changes through commit-or-rollback gates. Reported 89.04 avg Pass@1 on GAIA Test. @Shurtcurt commented: "The 'repeat with history, not amnesia' note at the bottom is doing a lot of work. Most self-improving agent designs fail because each improvement cycle starts cold."
@dair_ai shared a new NVIDIA paper (63 likes, 52 bookmarks) on self-evolving EDA tools: multi-agent LLMs autonomously refining the ABC codebase (1.2 million lines of C, 4,000+ source files), discovering optimization strategies that surpass human-designed heuristics on ISCAS, VTR, EPFL, and IWLS benchmarks.

This is the first application of self-improving agent patterns to production semiconductor infrastructure. @blip_tm connected the dots (30 likes): "if agentic workloads are driving CPU demand, they should also drive demand for accelerators like SmartNICs that offload networking and security and let the CPU focus on running the agent loop."
Discussion insight: Self-improving agents graduated from paper abstractions to industrial applications. The NVIDIA paper demonstrates the pattern works at million-line scale on production codebases that ship chips. Combined with Autogenesis's protocol-level semantics, this signals the pattern is crossing from research to deployment.
Comparison to prior day: April 19 introduced Autogenesis as a protocol and AutoSOTA as research automation. April 20 extends the pattern to industrial EDA tools (NVIDIA/ABC) and adds the hardware infrastructure angle (SmartNICs for agent loop acceleration).
1.5 New Model Releases Target Agentic Coding Directly 🡕¶
Two major model releases focused explicitly on agentic execution capabilities. @Alibaba_Qwen announced Qwen 3.6 Max Preview (291 likes, 38 bookmarks), an early preview of their next flagship model with improved agentic coding, world knowledge, and agent reliability. The benchmark chart covers 12 categories:

Qwen 3.6 Max leads on SuperGPQA (73.9), SkillsBench (55.6 vs Claude 4.5 Opus's 30.0), Terminal-Bench 2.0 (65.4), and SWE-Bench Pro (57.3). @drawais_ai noted: "The preserve_thinking feature is the part most people will underrate... carrying reasoning across turns is what actually makes long agent traces coherent." @DoDataThings observed: "Alibaba's coding stack is converging on the same agentic patterns Anthropic and Cursor run. Tool integration depth is where the China model race actually happens now."
@aaryan_kakad provided a technical breakdown of Kimi K2.6 (6 likes, 8 bookmarks): 12-hour autonomous coding sessions, 4,000+ tool calls without context loss, 300 parallel sub-agents (up from K2.5's 100), and a 68.2 score on long-horizon engineering benchmarks. The model optimized Qwen3.5-0.8B inference in Zig from 15 to 193 tokens/second, beating LM Studio by 20%. Kimi K2.6 is open-weight on Hugging Face.
@sudoingX praised Grok 4.3 (36 likes) for autonomous agent work: "the way it handles multi step reasoning, the way it doesn't bail halfway, different model energy entirely."
Discussion insight: Model competition has shifted from general benchmarks to agentic-specific capabilities: SkillsBench, Terminal-Bench, long-horizon execution, and cross-turn reasoning persistence. The SkillsBench gap (Qwen 3.6 Max at 55.6 vs Claude 4.5 Opus at 30.0) is the most striking delta.
Comparison to prior day: April 19 discussed free Claude Code alternatives using open models. April 20 adds two major model releases (Qwen 3.6 Max, Kimi K2.6) both explicitly optimized for agentic execution, and the first practitioner report of Grok 4.3 performing well in autonomous agent workflows.
1.6 Codex Gets Long-Term Orchestration; Single Agents Outperform Swarms 🡒¶
@WesRoth described Codex's new workflow features (195 likes, 91 bookmarks, 19.2K views): scheduled automations, thread reuse, and persistent memory that lets the agent "retain project conventions, go to sleep, and autonomously wake itself up later to keep pushing a long-running task forward." This builds on background computer use where multiple agents operate desktop apps in parallel.
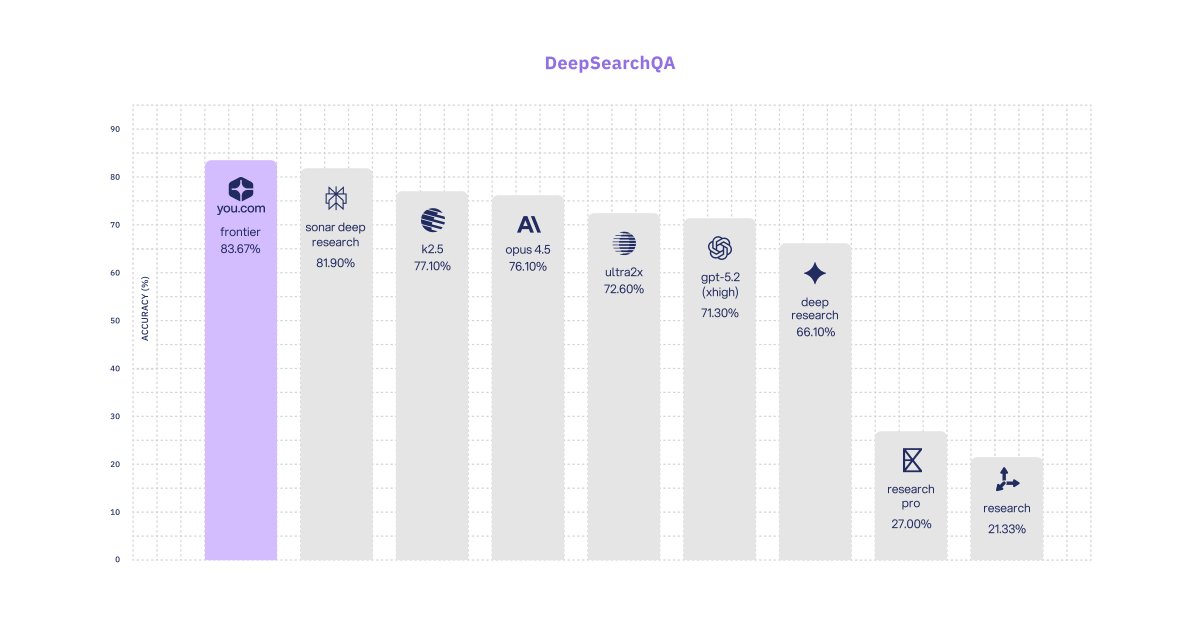
Meanwhile, @youdotcom published a counterpoint to multi-agent hype: "Multi-agent swarms underperform a single well-scaled agent at the same compute budget." Their single-agent system hit SOTA on DeepSearchQA at 83.67% accuracy over 10M tokens and 1,000 turns.
@ZypherHQ observed (32 likes) that Codex and OpenCode are LLM wrappers and "the only thing they can really compete on is better agent orchestration." Reply consensus: "The real edge for wrappers is UX and workflow, not the underlying intelligence."
Discussion insight: Two forces in tension: Codex betting on multi-agent, long-running orchestration, while you.com's research shows a single well-scaled agent outperforms swarms at equivalent compute. This echoes @ponnappa's April 19 challenge: "run 2 agents in parallel first without slopping... then tweet your theories about multi agent orchestration."
Comparison to prior day: April 19 saw Swarms v11 shipping multi-agent architectures. April 20 adds you.com's empirical counterargument, suggesting the multi-agent pattern may be premature for many use cases.
1.7 Anthropic's Free Course Ecosystem and Skill Discovery Expand 🡕¶
Multiple accounts independently surfaced Anthropic's 13 free AI courses (@Shruti_0810, 19 likes, 29 bookmarks; @manishamishra24, post, 12 likes). The courses span Claude 101, AI Fluency, Introduction to Agent Skills, Claude Code in Action, MCP basics and advanced topics, and cloud integrations with Bedrock and Vertex AI. @TimHaldorsson called agent skills "the most powerful feature in Claude right now... this is the layer that turns Claude from a chatbot into a system."
@SteveSolun continued promoting ctx (5 likes, 19 bookmarks), a skill/agent discovery tool that "watches what you're developing, walks a knowledge graph of 1,700+ skills and 450+ agents, and recommends the right ones in real time." The 1,700+ skill count (up from 1,450+ on April 19) shows rapid ecosystem growth.
Comparison to prior day: April 19 identified skill discovery as an emerging need. April 20 shows the ecosystem growing (1,700+ skills vs 1,450+) while Anthropic invests in education to drive adoption across the skill layer.
2. What Frustrates People¶
Agent Governance Lags Deployment -- Severity: High¶
@stormrae_ai reported 96% enterprise agent deployment vs 21% governance (285 likes, 24.9K views). The Palo Alto Networks demonstration of a red-team agent executing a $900 financial withdrawal through social engineering -- with no exploit or breach -- illustrates the gap. @EddyBrown777 responded: "The core issue isn't AI capability -- it's control. Enterprises rushed deployment without aligning incentives, oversight, or fail-safes."
Cross-Session Memory Poisoning Has No Defense -- Severity: High¶
@web3nomad identified (in reply to the DeepMind paper thread) a new threat class: "an adversarial content injection that writes to agent memory persists across sessions... auto-capture memory systems have no real defense against this." The only current mitigation is "explicit write-time review" where a human decides what enters the knowledge base.
Skill Explosion in Self-Authoring Agents -- Severity: Medium¶
@elvissun (via @shannholmberg, 59 likes, 39 bookmarks) documented finding three overlapping skills in Hermes for a single task (reading local images). "The agent is good at spotting 'I should bottle this up.' It's less good at spotting 'I already bottled this up three folders over.'" Skills grow faster than they consolidate. No deduplication mechanism exists yet.
Agent Harnesses Are Effectively Public -- Severity: Medium¶
@hugobowne warned (6 likes, 3 bookmarks): "AI Builders are slowly realising that they should assume their system prompts will be exfiltrated and made public. Few realize that their entire agent harnesses are as good as public." The implication: any security assumption that depends on harness secrecy is already broken.
3. What People Wish Existed¶
Skill Deduplication and Consolidation¶
@elvissun (via @shannholmberg) identified the need for "consolidation pass with invocation metrics + stronger dedupe on skill creation" for Hermes Agent. The skill corpus grows unchecked: "some brilliant, some redundant, some that overlap three other skills nobody remembers exist."
Opportunity: A skill deduplication engine that clusters semantically similar skills, merges overlapping ones, and prunes unused skills based on invocation data would solve the primary long-term risk of self-authoring agents.
Agent Financial Identity (Know Your Agent)¶
@t54ai described the gap: "Every check in today's financial stack was designed around a human. Signatures, IDs, clicks, chargebacks. When an AI agent is the one transacting, each of those checks has a gap." The thread proposed KYA (Know Your Agent) covering model provenance, version, runtime integrity, and signed mandates for every autonomous action.
Opportunity: A KYA framework that bridges agent identity to existing financial compliance infrastructure would unlock enterprise agent commerce at scale.
Write-Time Memory Security¶
@web3nomad (in reply to @akshay_pachaar) identified that no tool currently validates what enters agent memory: "explicit write-time review (human decides what enters the wiki) is the only current mitigation."
Opportunity: Automated memory write validation -- classifying, filtering, and flagging injected content before it enters persistent memory -- would address the cross-session poisoning vector.
4. Tools and Methods in Use¶
| Tool / Method | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Hermes Agent | Agent platform | Positive | 123 bundled skills, self-authoring loop, persistent memory | Skill explosion problem, no deduplication |
| OpenClaw | Agent framework | Positive | Governance by design, 5 precedence levels, bounded discovery | Manual skill authoring, setup difficulty for non-developers |
| Claude Code | Coding agent | Mixed | Powerful with skills, 13 free courses | Rate limits persist, harness effectively public |
| Codex | Coding agent | Positive | Scheduled automations, persistent memory, thread reuse | LLM wrapper competing on orchestration alone |
| Kimi K2.6 | LLM | Positive | 12-hour sessions, 4K+ tool calls, open weights | Requires serious GPU for self-hosting |
| Qwen 3.6 Max | LLM | Positive | SkillsBench 55.6, preserve_thinking for cross-turn reasoning | Preview only, not yet publicly available weights |
| Grok 4.3 | LLM | Positive | Strong multi-step reasoning, real-time X search | Limited practitioner reports |
| x402 | Payment protocol | Positive | 167M+ transactions, zero API keys | 85% on Base, chain concentration risk |
| Swarms v11 | Multi-agent framework | Positive | 3 new architectures, HeavySwarm to 16 agents, security fixes | Single well-scaled agents may outperform swarms |
| Firecrawl web-agent | Web agent framework | Positive | Plan-Act mechanism, parallel sub-agents, model-agnostic | New, limited production data |
| Browser Harness | Browser automation | Positive | Self-healing selectors, agent rewrites broken functions | No guardrails by design |
| Hyperframes | Video framework | Positive | HTML in, MP4 out, agent-native, Apache 2.0 | Just launched, limited adoption |
| MCP | Integration protocol | Positive | Expanding ecosystem, tool poisoning awareness growing | Poisoning attacks via malicious tool descriptions |
| LiveKit + xAI STT | Voice agent infra | Positive | One API key for full STT + Grok + TTS pipeline | Cascaded latency still requires aggressive streaming |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Agentic(.)Market | @base / Coinbase | Agent-to-agent service marketplace | Agents discovering and paying for capabilities | x402, Base | Shipped | post |
| Hermes-Workspace V2 | @outsource_ | Agent View Office, Conductor for missions, sub-agent orchestration | Hermes UI and deployment | Hermes Agent | Shipped | post |
| FreeBuff | @jahooma | Free coding agent with GLM 5.1, waiting room system | Cost barrier to agent coding | GLM 5.1, npm | Shipped | post |
| Aigis v2 | @NayanKanaparthi | AI governance compiler for coding agents | Governance patterns as agent-readable context | NIST AI RMF, OWASP, ISO 42001 | Shipped | post |
| RuFlo v3.5 | @tom_doerr | Multi-agent orchestration platform for Claude | Coordinating multiple Claude agents | Claude Code SDK, MIT | Shipped | post |
| OpenTraces 0.3 | @jayfarei | Git for agent traces with session blame | Attributing code changes to agent traces | Local TUI, HuggingFace datasets | Alpha | post |
| SAEP | @BuildOnSAEP | Agent economy protocol with 10 Anchor programs | Agent identity, task bidding, ZK verification, streaming payments | Solana, Groth16, Switchboard VRF | Shipped | post |
| Hyperframes | HeyGen | Agent-native video composition: HTML in, MP4 out | Replacing React-based video frameworks for agent workflows | Puppeteer, FFmpeg, Apache 2.0 | Shipped | post |
| ctx | @SteveSolun | Skill/agent recommender via knowledge graph | Discovering relevant skills from 1,700+ options | Knowledge graph | Alpha | post |
| Eliza LifeOps | @shawmakesmagic | Personal agent with local model support, n8n workflows | Information overload management | Local models, n8n | Alpha | post |
| Nyx | @FabraixHQ | Verification engine for AI agents | Finding failure modes in agent behavior | AI security engineers on demand | Alpha | post |
| Sleek Design Skill | @jameslevicf | Agent skill for better mobile app designs | Design quality in agent-generated UIs | Claude Code, Codex | Shipped | post |
| DSPy Agent Skills | @intertwineai | Skills plugin teaching DSPy GEPA and RLM to agents | Agents learning optimization frameworks | Claude, Codex | Shipped | post |
6. New and Notable¶
Agentic(.)Market Dashboard Reveals Agent Commerce Scale¶
@base published the first public dashboard for agent-to-agent commerce: 167M+ x402 transactions, $48.6M volume, 71,490 unique buyers, 12,992 unique sellers. The services leaderboard shows Anthropic, X API, Bankr, Google Flights, and OpenAI as top agent-consumed services. This is the first hard evidence that agent-to-agent marketplaces are operating at meaningful scale.
Google DeepMind Taxonomizes Six Agent Attack Surfaces¶
@akshay_pachaar summarized the "AI Agent Traps" paper (69 bookmarks), the first systematic framework for adversarial content targeting agents. The six categories -- Content Injection, Semantic Manipulation, Cognitive State, Behavioural Control, Systemic, and Human-in-the-Loop -- with concrete attack success rates (86% with HTML injection, 80% with 0.1% poisoned data) provide a research agenda for agent security.
NVIDIA Demonstrates Self-Evolving EDA at Million-Line Scale¶
@dair_ai shared NVIDIA's paper (52 bookmarks) applying multi-agent self-improvement to ABC, a 1.2-million-line logic synthesis tool used across the semiconductor industry. The framework discovers optimization strategies beyond human-designed heuristics. This is the first application of self-evolving agent patterns to production industrial infrastructure.
Qwen 3.6 Max Preview Posts SkillsBench Lead of Nearly 2x Over Claude¶
@Alibaba_Qwen released benchmark results showing Qwen 3.6 Max Preview at 55.6 on SkillsBench (agent skill execution) versus Claude 4.5 Opus at 30.0 -- a 1.85x advantage. The preserve_thinking feature, which carries reasoning chains across disconnected sessions, is a novel capability for long agent traces.
Single Agent Hits SOTA on DeepSearchQA, Challenging Swarm Paradigm¶
@youdotcom reported 83.67% accuracy on DeepSearchQA with a single well-scaled agent using 10M tokens and 1,000 turns, claiming "multi-agent swarms underperform a single well-scaled agent at the same compute budget." This empirical finding challenges the prevailing multi-agent trend.
MCP Tool Poisoning Identified as Invisible Attack Vector¶
@correlicHQ described MCP tool poisoning: "A malicious tool description tells your agent to read your SSH keys. The agent thinks it's following instructions. The UI shows nothing." The attack exploits the trust relationship between agents and tool descriptions, where the description itself becomes the payload.
7. Where the Opportunities Are¶
[+++] Agent marketplace infrastructure -- Agentic Market's dashboard (167M transactions, 71K buyers, $48.6M volume) proves agent-to-agent commerce is real. The 5:1 buyer-to-seller ratio indicates undersupply of services. Tools that help developers list, price, and monitor agent-consumable services have immediate demand. Sources: @base, @MilkRoad, @OrbisAPI.
[+++] Agent security and governance tooling -- 96% enterprise deployment vs 21% governance creates a massive gap. The DeepMind taxonomy provides a structured attack surface map. Cross-session memory poisoning and MCP tool poisoning have no automated defenses. Sources: @stormrae_ai, @akshay_pachaar, @correlicHQ.
[++] Skill deduplication and lifecycle management -- Hermes's skill explosion problem (skills grow faster than they consolidate) will affect every self-authoring agent system. Tools that cluster, merge, and prune semantically similar skills based on invocation data solve a problem that scales with adoption. Sources: @elvissun via @shannholmberg.
[++] Agentic-native model optimization -- SkillsBench, Terminal-Bench, and long-horizon benchmarks are becoming the selection criteria for agent builders. Models explicitly optimized for tool-call coherence and cross-turn reasoning (Qwen 3.6 Max's preserve_thinking, Kimi K2.6's 12-hour sessions) are pulling ahead of general-purpose models. Sources: @Alibaba_Qwen, @aaryan_kakad.
[+] Agent financial identity (KYA) -- @t54ai identified the structural gap between human-designed financial compliance and agent-executed transactions. With 167M agent transactions already settled, the compliance gap is widening. Sources: @t54ai, @stormrae_ai.
[+] Single-agent scaling vs multi-agent orchestration -- you.com's DeepSearchQA result (83.67% with single agent) versus Swarms v11's 16-agent architectures represents an unresolved architectural question. Tooling that helps developers determine when to scale depth vs breadth would save significant compute and engineering time. Sources: @youdotcom, @swarms_corp.
8. Takeaways¶
-
Agent-to-agent commerce produced its first public dashboard: 167M+ x402 transactions, $48.6M volume, 71,490 buyers on Agentic Market, with a 5:1 buyer-to-seller ratio indicating undersupply. Sources: @base, @MilkRoad.
-
The OpenClaw vs Hermes comparison crystallized into two philosophies: batteries-included (Hermes, 123 skills, self-authoring) vs primitives-first (OpenClaw, bounded discovery, governance by policy). Hermes's skill explosion is the primary long-term risk; OpenClaw's manual authoring is the primary adoption friction. Source: @shannholmberg.
-
Agent security threat data reached a new level: 96% enterprise deployment vs 21% governance, DeepMind's six-category attack taxonomy, 86% hijack rate with HTML injection, and cross-session memory poisoning identified as a new threat class with no automated defense. Sources: @stormrae_ai, @akshay_pachaar.
-
Self-improving agents reached industrial infrastructure: NVIDIA demonstrated multi-agent self-evolution of a 1.2M-line semiconductor EDA tool, discovering optimization strategies beyond human heuristics. Sources: @dair_ai, @omarsar0.
-
Model competition shifted to agentic-specific benchmarks: Qwen 3.6 Max posted a 1.85x SkillsBench advantage over Claude 4.5 Opus (55.6 vs 30.0), and Kimi K2.6 demonstrated 12-hour autonomous coding with 4,000+ tool calls. Sources: @Alibaba_Qwen, @aaryan_kakad.
-
The multi-agent paradigm received its first empirical challenge: you.com's single well-scaled agent hit SOTA on DeepSearchQA (83.67%), claiming swarms underperform at equivalent compute budgets. Source: @youdotcom.
-
The vibecoding security conversation shifted from "don't do it" to "if you do it, audit it" -- a security prompt achieving 794 bookmarks (highest in the dataset) demonstrates demand for practical security tooling within the vibecoding workflow. Source: @hackSultan.
-
Skill ecosystem growth accelerated: ctx now indexes 1,700+ skills and 450+ agents (up from 1,450 skills on April 19), skillsmp.com lists 60,000+ skills, and Anthropic invested in 13 free courses to drive adoption. The discovery problem is now the primary bottleneck. Sources: @SteveSolun, @JorgeCastilloPr.