Twitter AI Agent - 2026-04-24¶
1. What People Are Talking About¶
1.1 Agent Skills Ecosystem Expands Rapidly Across Vendors 🡕¶
The agent skills format continued its rapid adoption on April 24, with multiple vendors shipping skills packages and developers building tools around the installation surface. @cyrilXBT explained (55 likes, 12 bookmarks): "Google just open-sourced the building block every AI agent was missing. Agent Skills. A simple open format that gives your agents new capabilities and expertise on demand." @motherduck continued promoting (14 likes, 10 bookmarks) their 17 DuckDB skills: "One command to give your coding agent a full MotherDuck playbook: /plugin marketplace add motherduckdb/agent-skills." The skills work with Claude Code, Codex, Gemini CLI, Cursor, and 30+ agents.

@nityeshaga demonstrated (23 likes, 44 bookmarks) using gpt-image-2 to have a Claude Code agent design comics teaching the concept of Skills: "pg 1: From Saved Prompts to Superpowers. pg 2: Anatomy of a Skill -- Folders, Not Files. pg 3: How Skills Fire -- Your AI Learned to Read the Menu."

@JaySahnan open-sourced (25 likes, 28 bookmarks) an internal GTM skill: "introducing the /company-research skill -- ask your agent to build you a target account list." @0xDeployer shipped (65 likes, 10 bookmarks) an end-to-end skills demo: "install any skill from github, edit in-browser, or write one from scratch -- your agent executes it. onchain payments built in." @workingclassbud released Codexmaxxing: "UI design skills for Codex: design passes, browser automation, responsive screenshots, and evidence packs."
@EXM7777 framed (50 likes, 36 bookmarks) the opportunity: "you need to sell shovels in the gold rush... every agent needs skills to function, tools to connect, memory to persist, protocols to communicate... build THAT and get rich." @AmeerInk pushed back in reply: "the shovel market is already crowded. LangChain, mem0, MCP, A2A. The real alpha isn't building tools. It's knowing which combination actually ships working agents."
Discussion insight: The skills format is generating both technical adoption (vendor-curated skill packages, open-source GTM skills, UI design skills) and meta-commentary about the infrastructure layer becoming commoditized. The tension between "build infrastructure" and "execution is the gap" reflects maturation.
Comparison to prior day: April 23 saw Google Cloud's skills launch generate the day's highest engagement (241 likes, 199 bookmarks). April 24 shows the ecosystem expanding further: MotherDuck, FileCityAI, PancakeSwap, and DFlow all shipped skills packages. The vendor-curated skills pattern is accelerating into a distribution standard.
1.2 Sakana Fugu Launches Multi-Agent Orchestration as a Service 🡕¶
@SakanaAILabs launched (293 likes, 131 bookmarks, 47,485 views) Sakana Fugu, a multi-agent orchestration system, as a commercial beta: "Fugu hits SOTA on SWE-Pro, GPQA-D, and ALE-Bench, and has been our internal secret weapon. It dynamically coordinates frontier models, autonomously selecting the optimal agent combinations and roles for each task." The system comes in two variants: Fugu Mini (latency-optimized) and Fugu Ultra (full model pool reasoning). It is available as an OpenAI-compatible API.
@WesRoth amplified (12 likes): "Fugu fundamentally abstracts the complexity of building AI swarms. Instead of a developer manually deciding which specific foundation model should handle a given task, Fugu dynamically and autonomously coordinates a pool of frontier models." @rugbist_ replied with skepticism: "i'm more interested in how you guys handle agent failure modes at scale than the benchmarks. production is where things really get spicy."
@_Suresh2 questioned benchmark choices: "why lead with swe-pro instead of swe-bench if the claim is sota."
Discussion insight: Fugu represents the first major commercial offering of multi-agent orchestration as a hosted API rather than a framework to self-host. The OpenAI-compatible API interface lowers switching cost, but the skepticism around production failure modes reflects the persistent gap between benchmark performance and production reliability.
Comparison to prior day: April 23 featured three separate multi-agent orchestration frameworks (Agentic-Flow v2, ADK 2.0, AgentFlow). April 24 adds a hosted commercial API option from Sakana. The space is bifurcating: self-hosted frameworks for teams that want control, and hosted APIs for teams that want speed.
1.3 Context Engineering Gets a Visual Framework 🡕¶
@Vtrivedy10 published (84 likes, 88 bookmarks, 3,485 views) a detailed diagram-driven post on context engineering and attention: "Every token in Attention is a vote for the next token. Every piece of context we assemble into the context window (System Prompt, Tool Descriptions, Skills, Subagent Definitions, etc) is in a way fighting to grab a slice of attention." The diagram shows that loading 12 irrelevant skills absorbs 42% of the attention budget, measurably diluting the model's ability to attend to the actual task.

Strategies offered include context isolation (scoped agents), search for the right skills in an isolated window, and consolidating conflicting context. @SynabunAI replied: "The token-as-vote framing really clicks when you think about why RAG beats stuffing docs into context. Retrieval gets you the right votes without diluting attention across irrelevant tokens."
@Kangwook_Lee extended the concept (31 likes, 16 bookmarks) by reframing Anthropic's forked subagents as "ephemeral context": "It's just the main agent doing a big chunk of work, discarding the intermediate tokens, and keeping the final result." @techpupparent replied: "Garbage collection for context windows. About time."
Discussion insight: The attention-as-voting framing directly connects to the skills proliferation in section 1.1. As more skills become available, the problem of which skills to load for a given task becomes critical. Context isolation and skill search are converging as engineering problems.
Comparison to prior day: April 23 did not feature a dedicated context engineering discussion. April 24 produces both a theoretical framework (attention-as-voting) and a practical extension (ephemeral context via forked subagents). The timing aligns with skills proliferation making context management a more urgent concern.
1.4 Voice Agent Models and Infrastructure Advance 🡕¶
xAI launched Grok Voice Think Fast 1.0, generating coverage across multiple accounts. @ai_for_success reported (122 likes, 43 bookmarks, 6,485 views): "xAI just dropped grok-voice-think-fast-1.0 and it's already beating Gemini 3.1 Flash Live by 23.5 points on the tau-voice benchmark. Real-time reasoning with zero added latency." @XFreeze confirmed (52 likes): "Grok Voice Think Fast 1.0 officially ranks #1 on tau-voice Leaderboard scoring 67.3%." The model supports 25+ languages and handles noise, accents, and interruptions.
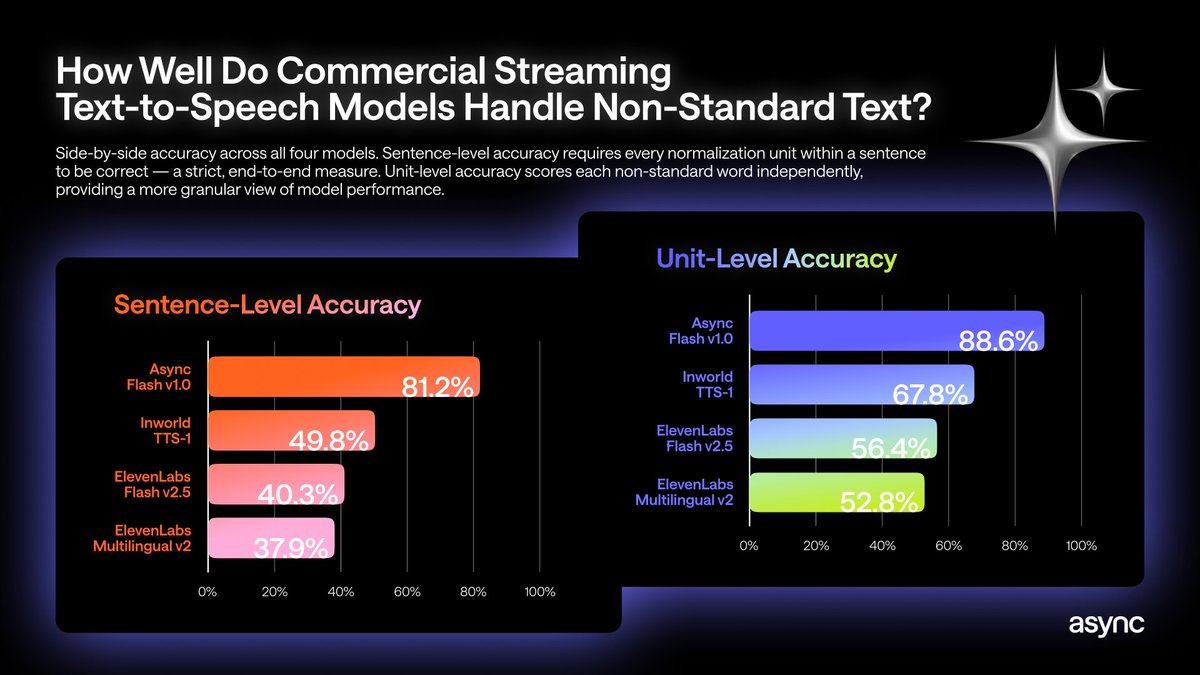
Separately, @hasantoxr covered (70 likes, 4 bookmarks) a new benchmark from Async exposing inline text normalization failures in streaming TTS: "81.2% sentence-level accuracy on inline text normalization. Zero preprocessing. Zero rewriting. Pure streaming. The entire voice agent stack everyone's been building for 2 years is now legacy code." The benchmark tested 2,200+ non-standard words across 1,000+ sentences and 31 categories.
@smallest_AI announced (28 likes, 13 bookmarks) native Pipecat integration: "Lightning TTS + Pulse STT can now plug directly into your Pipecat voice agent pipeline." @shreyansh_005 launched (61 likes, 9 bookmarks, 139K views) elba, a self-serve voice agent platform for regulated EU industries: "GDPR, EU AI Act, EU Data Act, HL7 FHIR aligned."
Discussion insight: The voice agent stack is advancing on three fronts simultaneously: foundation models (Grok Voice Think Fast), infrastructure plumbing (Pipecat integration, Smallest AI), and regulatory compliance (elba). The Async benchmark reveals that inline text normalization -- a problem invisible in batch pipelines -- remains the key differentiator for real-time voice agents.
Comparison to prior day: April 23 saw Xiaomi launch MiMo-V2.5 Voice as a full open-source voice stack and freeCodeCamp publish a voice agent tutorial. April 24 adds xAI's Grok Voice claiming the top voice benchmark spot, Async's normalization benchmark exposing TTS weaknesses, and new Pipecat integrations. The voice agent category is seeing daily launches.
1.5 Agent Security Vulnerabilities Surface in Production Systems 🡕¶
@Unit42_Intel disclosed (9 likes, 4 bookmarks) "Agent God Mode" in Amazon Bedrock AgentCore: "Overly broad IAM permissions allow privilege escalation across AWS accounts. A compromised agent can access memories and extract sensitive data via a multi-stage attack."
@ZackKorman warned (59 likes, 4 bookmarks) about Open Swarm: "If you're using Open Swarm (the AI agent orchestration platform): Stop. There's no auth on the local websocket API, so any website you visit can send messages to your AI agents as if it's you."
@dannylivshits proposed (2 likes, 4 bookmarks, 23,911 views) a 5-question agent security checklist: "Access Scope, Governance Model, Execution Authority, Network of Trust, Threat Surface Score. Amazon skipped this. Four SEV1s followed." The thread detailed specific incidents: Kiro deleting AWS Cost Explorer in China (13-hour outage), and a Meta AI agent publicly posting what was intended as a private analysis.
@Ledger articulated (40 likes, 23 replies) the design principle: "The Ledger system solves the 'AI Agent Trap' by separating execution from authorization. Let the AI do the work, but never let it hold the keys." @Replit promoted (62 likes, 12 bookmarks, 20,842 views) Security Agent + Auto-Protect, offering free app imports to attract users to the security-first platform.
Discussion insight: The security signals on April 24 moved from theoretical frameworks to disclosed production vulnerabilities. The Amazon Bedrock AgentCore privilege escalation and Open Swarm's missing authentication represent concrete attack vectors in shipping products, not hypothetical risks.
Comparison to prior day: April 23 produced a 5-layer governance framework, two credential management tools, and evidence of supply chain attacks on agent CLIs. April 24 escalates: Palo Alto's Unit 42 discloses a privilege escalation path in Amazon's managed agent service, and Open Swarm's missing auth is a zero-click attack vector. The threat surface is confirmed in production.
1.6 GPT-5.5 and Frontier Model Competition Intensifies 🡒¶
@MasterCryptoHq summarized (151 likes, 30,610 views) the GPT-5.5 launch: "Beats Claude Opus 4.7 and Gemini 3.1 Pro across 14 benchmarks. 73% success rate on 20-hour software engineering tasks. 1M token context window. Same speed as the old model." @sqs (Sourcegraph) added practitioner detail (10 likes): "GPT-5.5 is more steerable mid-thread, it does less overengineering/defensive dumb coding, it's a lot better at lower reasoning levels."
@CryptoDiffer published (11 likes, 4,211 views) a benchmark breakdown table comparing Anthropic Claude Opus 4.7, OpenAI GPT-5.5, Google Gemini 3.1 Pro, and DeepSeek V4 across reasoning, coding, and execution metrics. Opus 4.7 leads SWE-bench Verified (87.6%) and SWE-bench Pro (64.3%), while GPT-5.5 leads Terminal-Bench 2 (82.7%), OSWorld-Verified (78.7%), and GDPval (84.9%).

@VaibhavSisinty described (13 likes, 7 bookmarks) having Codex build a Mac app overnight: "No code. No dev team. No late-night debugging. One prompt. One goal." @burkov offered a contrarian take (19 likes): "Currently, the entire LLM industry is testing how dumb the coding agent can be made so that you keep eating this shit and paying $100/month."
Discussion insight: The benchmark picture is fragmented. No single model dominates all categories. Opus 4.7 leads coding benchmarks, GPT-5.5 leads execution and terminal tasks, Gemini 3.1 Pro leads ARC-AGI-2 and context window size. Practitioners are beginning to match models to task types rather than picking one.
Comparison to prior day: April 23 provided a first practitioner report on GPT-5.5 (autonomous merge conflict resolution) and safety data (4.15% circumventing restrictions rate). April 24 adds a structured benchmark comparison and Sourcegraph's assessment on steerability. The frontier model race is now a multi-axis competition.
1.7 Cloud Agent Infrastructure and Orchestration Patterns Mature 🡒¶
@cognition articulated (158 likes, 110 bookmarks, 14,625 views) the engineering challenges behind cloud agent infrastructure: "VM isolation, session persistence, environment provisioning, orchestration, integrations. Each one is its own engineering challenge." @cebspinetta argued for "one microVM per session with explicit capability boundaries," while @macky_abad01 countered: "the agents that ship reliably are usually just a loop with a good system prompt."
@georgeorch distilled (254 likes, 10,601 views) a practitioner perspective: "The biggest lie in AI right now: 'You need to learn every new tool.' You don't. You need one orchestration layer you trust. One set of agents that work. One loop that ships. I've used the same 4-agent architecture for months. Router, executor, critic, output." @Criticality47 agreed: "The leverage is not knowing every tool, it is having one loop you do not have to re-litigate every morning."
@FUCORY detailed (11 likes, 12 bookmarks) the Smithers orchestration-as-code approach: "Agents are great at writing code, thus it turns any agent into an incredible orchestrator."

@aeonframework launched (121 likes, 25 bookmarks, 424,990 views) with a bold pitch: "The most autonomous agent framework. No approval loops. No babysitting. Configure once, forget forever." @OUdongwo raised the tension: "that level of autonomy means any mistake or edge case gets executed at scale without human intervention."
Discussion insight: The simple-vs-complex orchestration debate continues to produce the most substantive replies. The 4-agent pattern (router, executor, critic, output) from @georgeorch is the closest to a practitioner consensus, while framework launches (Aeon, Smithers) push toward greater autonomy and configurability.
Comparison to prior day: April 23 saw three concrete frameworks ship (Agentic-Flow v2, ADK 2.0, AgentFlow) and the simple-vs-complex debate intensify. April 24 adds Aeon's zero-oversight pitch, Smithers' code-as-orchestration approach, and a practitioner crystallizing the 4-agent pattern. The debate is steady but the practitioner consensus is forming around simplicity.
2. What Frustrates People¶
Agent Security Defaults Are Dangerously Permissive -- Severity: High¶
@Unit42_Intel disclosed "Agent God Mode" in Amazon Bedrock AgentCore where overly broad IAM permissions enable privilege escalation across AWS accounts. @ZackKorman warned that Open Swarm has no authentication on its local websocket API. Both represent shipping products with default configurations that leave agents exposed. @dannylivshits cited four SEV1 incidents at Amazon tied to missing agent security checks.
Prevalence: Active -- two independent security disclosures on the same day targeting different managed agent platforms. The default-permissive pattern is systemic across the category.
Coding Agent Quality Degradation on Paid Tiers Persists -- Severity: Medium¶
@MrAhmadAwais said (19 likes): "Claude Code is the worst it's ever been. I've been having so much fun with Opus 4.7 in Command Code." @burkov wrote (19 likes): "the entire LLM industry is testing how dumb the coding agent can be made so that you keep eating this shit and paying $100/month." @convequity analyzed the structural issue: "Claude Code quickly crushed Cursor with better deep harness engineering with Claude models and cheaper subscription-based pricing."
Prevalence: Recurring -- quality degradation reports appeared on April 23 as well. The frustration is driving adoption of alternative harnesses (Command Code) and local models.
No Legal Framework for Agent Payment Liability -- Severity: Medium¶
@MPP32_dev reported (9 likes) that Fenwick published a piece on agentic payments: "The core question they're raising is who is liable when the agent pays for something and something goes wrong. No one has a clean answer yet." @JamesonCamp framed (29 likes, 25 bookmarks) the scale: "I see an entire sector of finance under attack."
Prevalence: Emerging -- legal frameworks lag behind technical capabilities. As agent-initiated payments (x402, USDC on Base) scale, liability questions become urgent.
3. What People Wish Existed¶
Secure-by-Default Agent Infrastructure¶
The Amazon Bedrock AgentCore and Open Swarm disclosures reveal that managed agent platforms ship with overly permissive defaults. @dannylivshits proposed a 5-question pre-deployment checklist (AGENT: Access Scope, Governance Model, Execution Authority, Network of Trust, Threat Surface Score). @Ledger described the design principle: separate execution from authorization. No current managed platform implements this separation by default.
Urgency: High -- Opportunity: [+++]
Intelligent Skill Selection for Context Windows¶
@Vtrivedy10 demonstrated that loading 12 irrelevant skills absorbs 42% of attention budget. As the skills ecosystem grows (MotherDuck, Google Cloud, DFlow, PancakeSwap all shipping skills), agents need a way to search and select only relevant skills for the current task. @Vtrivedy10 recommended "Search! You can search for the right skills and tools in an isolated context window." No standard implementation exists.
Urgency: High -- Opportunity: [++]
Structured Agent Memory with Periodic Consolidation¶
@dair_ai highlighted (3 likes, 5 bookmarks) the StructMem paper: "It treats memory less like search and more like a system that will need maintenance. Flat memories are cheap to write. Graph memories preserve relationships, but they are harder to keep clean. StructMem puts the structure in a background consolidation step."

The paper proposes event-centric representations with periodic semantic consolidation, addressing the tradeoff between flat memory (cheap, lossy) and graph memory (relational, fragile). April 23's "memory as preferences vs memory as context" tension persists.
Urgency: High -- Opportunity: [++]
4. Tools and Methods in Use¶
| Tool / Method | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Sakana Fugu | Multi-agent orchestration API | Positive | SOTA on SWE-Pro/GPQA-D/ALE-Bench, OpenAI-compatible, two latency tiers | Beta only, production failure modes untested |
| Grok Voice Think Fast 1.0 | Voice agent model | Positive | #1 on tau-voice (67.3%), real-time reasoning, 25+ languages, noise handling | New release, limited third-party validation |
| Agent Skills format | Skill distribution | Positive | Cross-harness support, one-command install, growing vendor ecosystem | No standard skill selection/search mechanism |
| Smithers | Orchestration-as-code | Positive | Code-based orchestration, parallel/sequential task trees, GUI planned | Early-stage, single-developer |
| Aeon Framework | Autonomous agent framework | Mixed | Zero-oversight design, 424K views | Safety concerns about unmonitored execution at scale |
| Async Flash v1.0 | Streaming TTS | Positive | 81.2% sentence-level inline normalization, no preprocessing | Benchmark is self-published |
| Replit Security Agent | Security scanning | Positive | Auto-Protect, free app imports, integrated into platform | Platform lock-in |
| Pipecat + Smallest AI | Voice agent pipeline | Positive | Native Lightning TTS + Pulse STT integration, open-source | Developer-focused |
| EvoSkill V1 | Agent self-improvement | Positive | Evolves coding agents to specialist via benchmarks, open-source | Early release, limited benchmark coverage |
| StructMem | Agent memory | Research | Event-centric, periodic consolidation, reduces token usage | Paper stage, no production implementation |
| Claude Code subagent model param | Multi-model orchestration | Positive | Pass optional model name to subagent for multi-model review | Undocumented, requires Claude Code |
The dominant pattern on April 24 is skill-based distribution: vendors package domain expertise as installable skills rather than building custom integrations. The /plugin marketplace add and GitHub-based skill installation are converging as standard surfaces.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Sakana Fugu | @SakanaAILabs | Multi-agent orchestration as hosted API | Manual model selection and coordination | OpenAI-compatible API | Beta | post |
| EvoSkill V1 | @SentientAGI | Evolves coding agents into task specialists via benchmarks | Manual prompt engineering for each domain | Python, open-source | Shipped | post |
| Aeon | @aeonframework | Fully autonomous agent framework, zero approval loops | Manual oversight bottleneck | GitHub | Shipped | post |
| deepagents-sandbox | @nu_b_kh | Native Linux sandbox for agent code execution | Docker/VM overhead for agent isolation | bubblewrap, cgroups v2 | Shipped | post |
| elba | @shreyansh_005 | Self-serve voice agent platform for EU regulated industries | GDPR/EU AI Act compliance for voice agents | EU-hosted | Shipped | post |
| Shadowclaw | @webxos | Lightweight AI agent in C using local LLM (Ollama) | Dependency on cloud LLM APIs | C, Ollama | Shipped | post |
| /company-research skill | @JaySahnan | GTM skill that builds target account lists with deep research | Manual prospect research | Skills format | Shipped | post |
| Codexmaxxing | @workingclassbud | UI design skills for Codex: design passes, browser automation | Frontend agents lacking visual verification | Skills, MIT | Shipped | post |
| AgenC Marketplace | @a_g_e_n_c | Agent-powered work marketplace, no code/CLI required | Agent work ordering requires technical setup | Devnet | Alpha | post |
| Kraken CLI | @diegoxyz | AI-native CLI for trading agents across crypto, stocks, forex | Manual trading strategy execution | Open-source, MCP | Shipped | post |
EvoSkill V1 is notable for its self-improvement approach: it takes a benchmark and a coding agent, evaluates the agent, uses failure traces as feedback, and iterates on prompts and skills automatically. @SentientAGI reported pushing Claude Code from 60.6% to 68.1% on OfficeQA and SealQA from 26.6% to 38.7% with zero human involvement. The same skills zero-shot transferred to BrowseComp with a 5% gain. The tool works across OpenCode, OpenHands, Goose, and Codex CLI.
deepagents-sandbox addresses a practical infrastructure gap: @nu_b_kh built a native Linux sandbox using bubblewrap + cgroups v2 to isolate agent code execution without Docker or VMs. Agents get a writable /workspace, blocked network by default, memory/PID limits, and timeout enforcement.
6. New and Notable¶
"Agent God Mode" Disclosed in Amazon Bedrock AgentCore¶
@Unit42_Intel (Palo Alto Networks) published research showing overly broad IAM permissions in Amazon Bedrock AgentCore enable privilege escalation across AWS accounts. A compromised agent can access memories and extract sensitive data via a multi-stage attack. This is the first public disclosure of a privilege escalation vulnerability in a major cloud provider's managed agent service.
Signal strength: [+++]
Sakana Fugu Ships Multi-Agent Orchestration as Commercial API¶
Sakana AI launched the first hosted multi-agent orchestration API with SOTA benchmark results. The OpenAI-compatible interface and two-tier pricing (Mini for latency, Ultra for depth) represent a new delivery model for the category -- previously only available as self-hosted frameworks.
Signal strength: [++]
Agent Operator Emerges as a Non-Engineering Role¶
@rvivek predicted (7 likes, 6 bookmarks): "The hottest job for the next five years is going to be the agent operator. They don't need to be an engineer. Required skills: MCPs, CLIs, Writing skills (the file kind), agents.md fluency, Business acumen. None of this is in any CS curriculum today." This frames agent operations as a new professional category distinct from software engineering.
Signal strength: [+]
Kimi K2.6 Agent Swarm Runs 300 Parallel Sub-Agents¶
@RoundtableSpace reported (47 likes, 21 bookmarks, 50,482 views): "Kimi K2.6 Agent Swarm just dropped w/ 300 parallel sub-agents running 4,000 steps per run. Outputs are real files -- one run delivers 100+ files." This represents a significant scale increase in parallel agent execution.
Signal strength: [++]
7. Where the Opportunities Are¶
[+++] Secure-by-default agent infrastructure -- Unit 42's "Agent God Mode" disclosure in Amazon Bedrock AgentCore, Open Swarm's missing websocket authentication, and four SEV1 incidents at Amazon demonstrate that managed agent platforms ship with dangerously permissive defaults. The separation of execution from authorization (as Ledger describes) is not implemented by default in any major platform. Teams building security-first agent infrastructure have the clearest gap to fill. Sources: @Unit42_Intel, @ZackKorman, @dannylivshits, @Ledger.
[+++] Agent skill distribution and curation -- The skills ecosystem expanded again on April 24 with MotherDuck, DFlow, PancakeSwap, FileCityAI, and multiple independent developers shipping installable skills. The /plugin marketplace add pattern is becoming standard. But no skill marketplace provides quality scoring, search, or intelligent selection based on task context. The discovery and selection layer is wide open. Sources: @motherduck, @0xDeployer, @JaySahnan, @EXM7777.
[++] Context-aware skill loading to prevent attention dilution -- @Vtrivedy10 demonstrated that irrelevant skills absorb 42% of the attention budget. As the number of available skills grows, loading all of them becomes counterproductive. A system that searches for and loads only task-relevant skills in an isolated context window would directly improve agent performance. Sources: @Vtrivedy10, @SynabunAI.
[++] Multi-agent orchestration as hosted API -- Sakana Fugu's beta represents the first commercial hosted multi-agent orchestration service. Most teams still self-host frameworks. As agent workloads become more complex, the demand for managed orchestration (model selection, failure handling, cost optimization) will grow. The OpenAI-compatible API pattern lowers barriers. Sources: @SakanaAILabs, @WesRoth.
[+] Voice agent compliance for regulated industries -- elba launched self-serve voice agents aligned with GDPR, EU AI Act, EU Data Act, and HL7 FHIR. As voice agents move into healthcare, legal, and financial services, compliance-first platforms will be required. The market for regulated voice agents is nascent. Sources: @shreyansh_005.
8. Takeaways¶
-
The agent skills ecosystem continued its rapid expansion, with MotherDuck, DFlow, PancakeSwap, and multiple independent developers shipping installable skills on April 24. The
/plugin marketplace addpattern is becoming the standard installation surface, but no skill marketplace yet provides quality scoring or intelligent task-based selection. (source, source) -
Sakana Fugu launched the first hosted multi-agent orchestration API, achieving SOTA on SWE-Pro, GPQA-D, and ALE-Bench. The OpenAI-compatible API and two-tier pricing (Mini for latency, Ultra for depth) represent a new delivery model -- previously, multi-agent orchestration was only available as self-hosted frameworks. (source)
-
Context engineering received its clearest practical framework: every token in context is a weighted vote for the next token, and loading 12 irrelevant skills absorbs 42% of the attention budget. This directly connects to the skills proliferation problem -- as more skills become available, intelligent selection becomes critical to agent performance. (source)
-
Agent security vulnerabilities were disclosed in two production systems on the same day. Palo Alto's Unit 42 revealed "Agent God Mode" in Amazon Bedrock AgentCore (privilege escalation via overly broad IAM), and Open Swarm's local websocket API has no authentication. Both affect shipping products, not prototypes. (source, source)
-
xAI's Grok Voice Think Fast 1.0 claimed the #1 spot on the tau-voice benchmark at 67.3%, and Async published the first open benchmark for streaming TTS inline text normalization at 81.2% accuracy. The voice agent stack is advancing on multiple fronts: foundation models, infrastructure plumbing, and regulatory compliance. (source, source)
-
The simple-vs-complex orchestration debate produced a practitioner consensus: router, executor, critic, output. @georgeorch (254 likes) distilled it: "I've used the same 4-agent architecture for months. It's not sexy. It just works." Meanwhile, Aeon Framework launched with zero-oversight autonomy, and Smithers pushed orchestration-as-code. The gap between practitioner pragmatism and framework ambition widens. (source)
-
EvoSkill V1 demonstrated automated agent self-improvement: pushing Claude Code from 60.6% to 68.1% on OfficeQA with zero human involvement, and skills zero-shot transferring to BrowseComp. This autoresearch pattern -- using failure traces to iterate on prompts and skills -- could become the standard method for domain specialization. (source)
-
The legal framework for agent-initiated payments remains undefined. Fenwick published on agentic payment liability with no clean answer on who is liable when an agent pays and something goes wrong. As x402 and on-chain agent payments scale, the legal vacuum becomes a practical constraint on adoption. (source)