Twitter AI 智能体 - 2026-04-24¶
1. 人们在讨论什么¶
1.1 Agent Skills 生态在多个供应商间快速扩张 🡕¶
Agent Skills 格式在 4 月 24 日继续快速扩散,多个供应商发布技能包,开发者也围绕安装入口构建工具。@cyrilXBT 解释(55 个点赞、12 次收藏):“Google 刚刚把所有 AI 智能体一直缺少的基础构件开源了:Agent Skills。这是一种简单的开放格式,能按需为你的智能体赋予新能力和专业知识。”@motherduck 继续推广(14 个点赞、10 次收藏)他们的 17 个 DuckDB 技能:“只需一条命令,就能让你的编程智能体拿到完整的 MotherDuck 手册:/plugin marketplace add motherduckdb/agent-skills。” 这些技能包适配 Claude Code、Codex、Gemini CLI、Cursor 和 30+ 个智能体。

@nityeshaga 演示(23 个点赞、44 次收藏)使用 gpt-image-2,让 Claude Code 智能体设计漫画来讲解 Skills 概念:“第 1 页:从保存的提示词到超能力。第 2 页:一个 Skill 的结构——是文件夹,不是文件。第 3 页:Skills 如何触发——你的 AI 学会读菜单了。”

@JaySahnan 开源(25 个点赞、28 次收藏)一个内部 GTM 技能:“推出 /company-research 技能——让你的智能体帮你建立目标客户名单。”@0xDeployer 发布(65 个点赞、10 次收藏)一个端到端技能演示:“你可以从 GitHub 安装任意技能、在浏览器里编辑,或者从零写一个——你的智能体都会执行。还内置了链上支付。”@workingclassbud 发布 Codexmaxxing:“面向 Codex 的 UI 设计技能:设计迭代、浏览器自动化、响应式截图,以及证据包。”
@EXM7777 框定(50 个点赞、36 次收藏)机会:“淘金热里你得卖铲子……每个智能体都需要技能来运转、工具来连接、记忆来持久化、协议来通信……做那个就能发财。”@AmeerInk 在回复中反驳:“卖铲子的市场已经很挤了。LangChain、mem0、MCP、A2A 都在。真正的优势不是造工具,而是知道哪种组合真的能把可用的智能体做出来。”
讨论要点: Skills 格式正在同时带来技术采用(供应商策划的技能包、开源 GTM 技能、UI 设计技能)和关于基础设施层正在商品化的元评论。“做基础设施”与“执行才是缺口”之间的张力体现了生态成熟。
与前日对比: 4 月 23 日,Google Cloud 的 Skills 发布产生当天最高互动(241 个点赞、199 次收藏)。4 月 24 日,生态进一步扩张:MotherDuck、FileCityAI、PancakeSwap 和 DFlow 都发布了技能包。供应商策划的技能模式正在加速成为分发标准。
1.2 Sakana Fugu 发布多智能体编排服务 🡕¶
@SakanaAILabs 发布(293 个点赞、131 次收藏、47,485 次浏览)Sakana Fugu,这是一个多智能体编排系统,并以商业测试版推出:“Fugu 在 SWE-Pro、GPQA-D 和 ALE-Bench 上达到 SOTA,一直是我们的内部秘密武器。它会动态编排前沿模型,为每个任务自主选择最合适的智能体组合和角色。” 该系统有两个变体:Fugu Mini(延迟优化)和 Fugu Ultra(完整模型池推理)。它以兼容 OpenAI 的 API 形式提供。
@WesRoth 放大(12 个点赞):“Fugu 从根本上抽象掉了构建 AI 智能体集群的复杂性。开发者不必再手动决定某个任务该交给哪一种基础模型,Fugu 会动态且自主地协调一组前沿模型。”@rugbist_ 带着怀疑回复:“比起基准,我更想知道你们怎么在大规模下处理智能体的失效模式。真正辣手的地方是在生产环境。”
@_Suresh2 质疑 基准选择:“如果你们要宣称 SOTA,为什么主打 swe-pro,而不是 swe-bench?”
讨论要点: Fugu 代表了第一个主要商业化产品:以托管 API 而不是自托管框架的方式提供多智能体编排。兼容 OpenAI 的 API 接口降低了切换成本,但围绕生产环境失效模式的怀疑反映出基准测试表现与生产可靠性之间仍有缺口。
与前日对比: 4 月 23 日出现了三个独立多智能体编排框架(Agentic-Flow v2、ADK 2.0、AgentFlow)。4 月 24 日,Sakana 增加了托管商业 API 选项。这个空间正在分化:想要控制权的团队使用自托管框架,想要速度的团队使用托管 API。
1.3 上下文工程获得视觉框架 🡕¶
@Vtrivedy10 发布(84 个点赞、88 次收藏、3,485 次浏览)一篇以图解为主的帖子,讨论上下文工程和注意力:“注意力机制中的每个 token,都是在为下一个 token 投票。我们组装进上下文窗口的每一段上下文(系统提示词、工具描述、Skills、子智能体定义等),某种意义上都在争抢一块注意力。” 图中显示,加载 12 个无关技能会吸收 42% 的注意力预算,可测量地稀释模型关注实际任务的能力。

提出的策略包括上下文隔离(限定作用域的智能体)、在隔离窗口中搜索正确技能,以及合并相互冲突的上下文。@SynabunAI 回复:“一旦你用‘token 就是选票’这个框架去理解为什么 RAG 比把文档硬塞进上下文更有效,这件事一下子就讲通了。检索能帮你拿到正确的选票,而不会让注意力被无关 token 稀释。”
@Kangwook_Lee 扩展该概念(31 个点赞、16 次收藏),把 Anthropic 的分叉子智能体重新解释为“短暂上下文”:“本质上就是主智能体先做一大块工作,丢掉中间 token,只保留最终结果。”@techpupparent 回复:“这就是上下文窗口的垃圾回收。早该这样了。”
讨论要点: “注意力即投票”的框架直接连接到第 1.1 节的技能激增。随着可用技能增加,为给定任务加载哪些技能成为关键问题。上下文隔离和技能搜索正在汇聚为工程问题。
与前日对比: 4 月 23 日没有专门的上下文工程讨论。4 月 24 日同时产出理论框架(注意力即投票)和实践扩展(分叉子智能体带来的短暂上下文)。这个时间点与技能激增使上下文管理更迫切相吻合。
1.4 语音智能体模型与基础设施推进 🡕¶
xAI 发布 Grok Voice Think Fast 1.0,在多个账号中获得报道。@ai_for_success 报道(122 个点赞、43 次收藏、6,485 次浏览):“xAI 刚发布 grok-voice-think-fast-1.0,它已经在 tau-voice 基准上比 Gemini 3.1 Flash Live 高出 23.5 分。实时推理,且没有额外延迟。”@XFreeze 确认(52 个点赞):“Grok Voice Think Fast 1.0 以 67.3% 的成绩正式登上 tau-voice 排行榜第 1 名。” 该模型支持 25+ 种语言,并能处理噪声、口音和打断。
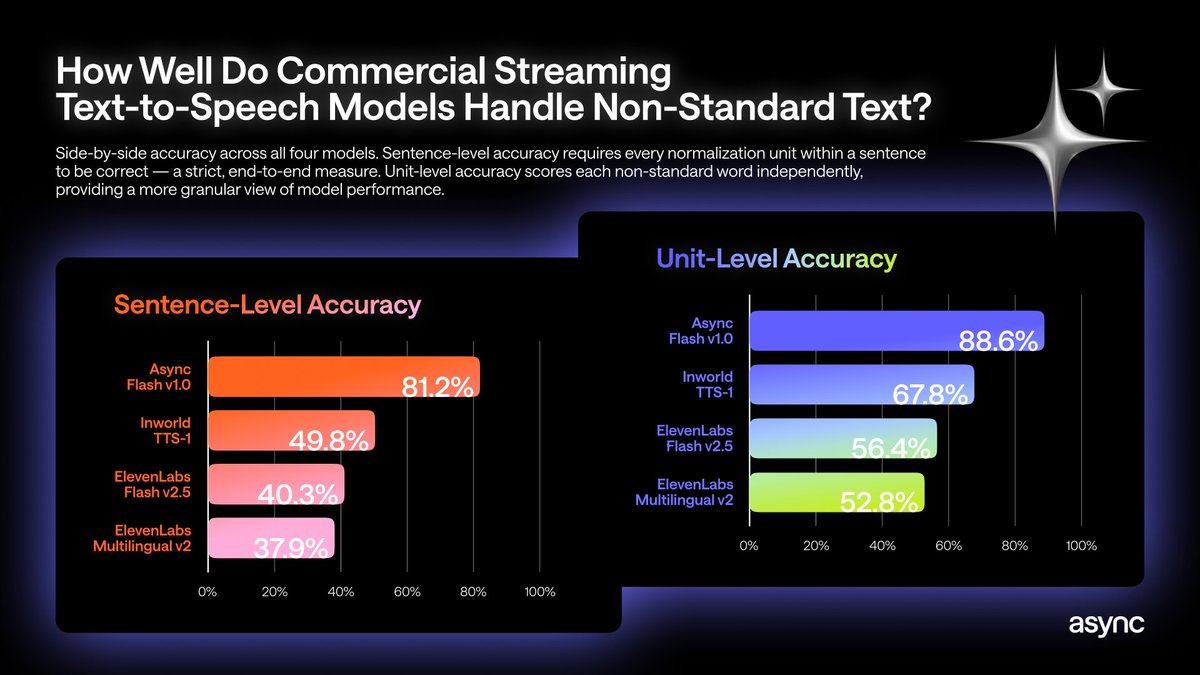
另外,@hasantoxr 介绍(70 个点赞、4 次收藏)Async 的一个新基准测试,暴露流式 TTS 中的内联文本规范化失败:“内联文本规范化的句子级准确率达到 81.2%。零预处理,零改写,纯流式。过去 2 年大家一直在搭的整套语音智能体技术栈,现在都成了遗留代码。” 该基准测试覆盖 31 个类别、1,000+ 个句子和 2,200+ 个非标准词。
@smallest_AI 宣布(28 个点赞、13 次收藏)Pipecat 原生集成:“Lightning TTS + Pulse STT 现在可以直接接入你的 Pipecat 语音智能体管线。”@shreyansh_005 发布(61 个点赞、9 次收藏、139K 次浏览)elba,一个面向受监管欧盟行业的自助式语音智能体平台:“符合 GDPR、EU AI Act、EU Data Act 和 HL7 FHIR。”
讨论要点: 语音智能体技术栈同时在三个方向前进:基础模型(Grok Voice Think Fast)、基础设施管线(Pipecat 集成、Smallest AI)和监管合规(elba)。Async 基准测试暴露出内联文本规范化——一个在批处理管线中不可见的问题——仍是实时语音智能体的关键差异点。
与前日对比: 4 月 23 日,Xiaomi 发布 MiMo-V2.5 Voice 作为完整开源语音技术栈,freeCodeCamp 发布语音智能体教程。4 月 24 日加入 xAI Grok Voice 声称占据语音基准榜首、Async 规范化基准测试暴露 TTS 弱点,以及新的 Pipecat 集成。语音智能体类别正在每日发布新东西。
1.5 智能体安全漏洞浮现在生产系统中 🡕¶
@Unit42_Intel 披露(9 个点赞、4 次收藏)Amazon Bedrock AgentCore 中的《Agent God Mode》:“过于宽泛的 IAM 权限会让攻击者能够在 AWS 账户之间提升权限。被攻陷的智能体可以通过多阶段攻击访问记忆并提取敏感数据。”
@ZackKorman 警告(59 个点赞、4 次收藏)Open Swarm:“如果你在用 Open Swarm(这个 AI 智能体编排平台),先停下。它的本地 WebSocket API 没有认证,所以你访问的任何网站都能像你本人一样给你的 AI 智能体发消息。”
@dannylivshits 提出(2 个点赞、4 次收藏、23,911 次浏览)一个 5 问智能体安全检查清单:“访问范围、治理模型、执行权限、信任网络、威胁面评分。Amazon 跳过了这些,随后就出了 4 起 SEV1。” 该讨论串详述具体事件:Kiro 在中国删除 AWS Cost Explorer(13 小时宕机),以及一个 Meta AI 智能体公开发布原本打算作为私有分析的内容。
@Ledger 阐述(40 个点赞、23 个回复)设计原则:“Ledger 系统通过把执行和授权分开,解决了智能体陷阱。让智能体去做事,但永远别把钥匙交给它。”@Replit 推广(62 个点赞、12 次收藏、20,842 次浏览)Security Agent + Auto-Protect,提供免费应用导入来吸引用户进入安全优先的平台。
讨论要点: 4 月 24 日的安全信号从理论框架转向已披露的生产漏洞。Amazon Bedrock AgentCore 的权限提升和 Open Swarm 缺少认证,是已上线产品中的具体攻击向量,而非假想风险。
与前日对比: 4 月 23 日产出了 5 层治理框架、两个凭据管理工具,以及智能体 CLI 遭供应链攻击的证据。4 月 24 日升级:Palo Alto Unit 42 披露 Amazon 托管智能体服务中的权限提升路径,Open Swarm 缺失认证是零点击攻击向量。威胁面已在生产中得到确认。
1.6 GPT-5.5 与前沿模型竞争加剧 🡒¶
@MasterCryptoHq 总结(151 个点赞、30,610 次浏览)GPT-5.5 发布:“它在 14 项基准上击败 Claude Opus 4.7 和 Gemini 3.1 Pro。在 20 小时的软件工程任务上成功率达到 73%。上下文窗口有 1M token。速度和旧模型一样。”@sqs(Sourcegraph)补充实践细节(10 个点赞):“GPT-5.5 在对话中途更容易调教,过度设计和防御性瞎写代码更少,在较低推理强度下也强得多。”
@CryptoDiffer 发布(11 个点赞、4,211 次浏览)一张基准拆解表,比较 Anthropic Claude Opus 4.7、OpenAI GPT-5.5、Google Gemini 3.1 Pro 和 DeepSeek V4 在推理、编程和执行指标上的表现。Opus 4.7 领先 SWE-bench Verified(87.6%)和 SWE-bench Pro(64.3%),GPT-5.5 领先 Terminal-Bench 2(82.7%)、OSWorld-Verified(78.7%)和 GDPval(84.9%)。

@VaibhavSisinty 描述(13 个点赞、7 次收藏)让 Codex 一夜之间构建一个 Mac 应用:“没有代码,没有开发团队,没有深夜调试。一个提示词,一个目标。”@burkov 给出反向观点(19 个点赞):“现在整个 LLM 行业都在测试,能把编程智能体做得多蠢,你还会继续买账并每月付 100 美元。”
讨论要点: 基准测试图景是碎片化的。没有单一模型主导所有类别。Opus 4.7 领先编程基准,GPT-5.5 领先执行和终端任务,Gemini 3.1 Pro 领先 ARC-AGI-2 和上下文窗口大小。从业者开始按任务类型匹配模型,而不是只选一个。
与前日对比: 4 月 23 日提供了第一条 GPT-5.5 实践者报告(自主解决合并冲突)和安全数据(绕过限制率 4.15%)。4 月 24 日增加了结构化基准比较和 Sourcegraph 对可控性的评估。前沿模型竞赛现在是多轴竞争。
1.7 云端智能体基础设施与编排模式走向成熟 🡒¶
@cognition 阐述(158 个点赞、110 次收藏、14,625 次浏览)云端智能体基础设施背后的工程挑战:“VM 隔离、会话持久化、环境配置、编排、集成。每一项都是独立的工程挑战。”@cebspinetta 主张“每个会话一个 microVM,并明确划定能力边界”,而 @macky_abad01 反驳:“真正能稳定上线的智能体,通常就只是一个配了好系统提示词的循环。”
@georgeorch 提炼(254 个点赞、10,601 次浏览)一个实践者视角:“AI 领域现在最大的谎言是:‘你得学会每一个新工具。’其实不用。你需要的是一层你信得过的编排层、一组真正能工作的智能体、一个能把东西发出去的闭环。我这几个月一直用同一套 4 智能体架构:路由、执行、审校、输出。”@Criticality47 同意:“真正的杠杆不在于你知道每个工具,而在于你有一个不必每天早上重新争论一遍的固定闭环。”
@FUCORY 详述(11 个点赞、12 次收藏)Smithers 的编排即代码方法:“智能体很擅长写代码,因此它能把任何智能体都变成很强的编排器。”

@aeonframework 发布(121 个点赞、25 次收藏、424,990 次浏览)并给出大胆宣传口号:“这是最自主的智能体框架。没有审批环节,不用人盯着。配置一次,之后就放着跑。”@OUdongwo 提出其中张力:“这种级别的自主性意味着,任何错误或边界情况都会在没有人工干预的情况下被大规模执行。”
讨论要点: 简单 vs 复杂编排的争论继续产出最有实质内容的回复。来自 @georgeorch 的 4 智能体模式(路由、执行、审校、输出)最接近实践者共识,而框架发布(Aeon、Smithers)则推动更高自主性和可配置性。
与前日对比: 4 月 23 日有三个具体框架发布(Agentic-Flow v2、ADK 2.0、AgentFlow),简单 vs 复杂争论加剧。4 月 24 日加入 Aeon 的零监督口号、Smithers 的代码即编排方法,以及一位实践者将 4 智能体模式结晶化。争论保持稳定,但从业者共识正在围绕简单性收敛。
2. 令人困扰的问题¶
智能体安全默认配置危险地宽松 -- 严重程度:高¶
@Unit42_Intel 披露 Amazon Bedrock AgentCore 中的《Agent God Mode》,其中过于宽泛的 IAM 权限会让攻击者在 AWS 账户之间提升权限。@ZackKorman 警告 Open Swarm 的本地 WebSocket API 没有认证。两者都代表已上线产品的默认配置让智能体暴露在风险中。@dannylivshits 引用 Amazon 因缺少智能体安全检查引发的四起 SEV1 事件。
普遍程度:活跃 -- 同一天出现两个独立安全披露,针对不同托管智能体平台。默认宽松模式在整个类别中是系统性问题。
付费档位上的编程智能体质量下滑仍在持续 -- 严重程度:中¶
@MrAhmadAwais 说(19 个点赞):“Claude Code 现在是它有史以来最差的时候。我最近在 Command Code 里用 Opus 4.7 用得可开心了。”@burkov 写道(19 个点赞):“整个 LLM 行业现在都在测试,能把编程智能体做得多蠢,你还会继续买账并每月付 100 美元。”@convequity 分析 结构性问题:“Claude Code 靠着更强的 Claude 模型深度运行框架工程,以及更便宜的订阅制定价,很快就把 Cursor 压过去了。”
普遍程度:反复出现 -- 4 月 23 日也出现了质量下滑报告。这种挫败感正在推动替代运行框架(Command Code)和本地模型的采用。
智能体支付责任缺少法律框架 -- 严重程度:中¶
@MPP32_dev 报告(9 个点赞)Fenwick 发布了一篇关于智能体支付的文章:“他们提出的核心问题是:当智能体替人付款、结果出了问题时,责任到底算谁的。现在没人有一个明确答案。”@JamesonCamp 框定(29 个点赞、25 次收藏)其规模:“我看到整个金融行业都在遭受冲击。”
普遍程度:刚出现 -- 法律框架滞后于技术能力。随着智能体发起的支付(x402、Base 上的 USDC)扩张,责任问题变得紧迫。
3. 人们期望的功能¶
默认安全的智能体基础设施¶
Amazon Bedrock AgentCore 和 Open Swarm 的披露显示,托管智能体平台默认配置过于宽松。@dannylivshits 提出了部署前 5 问检查清单(AGENT:访问范围、治理模型、执行权限、信任网络、威胁面评分)。@Ledger 描述了设计原则:将执行与授权分离。当前没有托管平台把这种分离作为默认能力。
紧迫性:高 -- 机会:[+++]
面向上下文窗口的智能技能选择¶
@Vtrivedy10 展示,加载 12 个无关技能会吸收 42% 的注意力预算。随着 Skills 生态增长(MotherDuck、Google Cloud、DFlow、PancakeSwap 都发布技能),智能体需要一种方法,只为当前任务搜索并选择匹配的技能。@Vtrivedy10 建议“搜!你可以在一个隔离的上下文窗口里搜索合适的技能和工具。” 当前还没有标准做法。
紧迫性:高 -- 机会:[++]
带定期整合的结构化智能体记忆¶
@dair_ai 重点介绍(3 个点赞、5 次收藏)StructMem 论文:“它不把记忆当成搜索,而更像一个需要维护的系统。平铺记忆写入成本低;图谱记忆能保留关系,但更难保持干净。StructMem 把结构化放到后台整合这一步里。”

该论文提出以事件为中心的表示和定期语义整合,解决平铺记忆(便宜但有损)与图谱记忆(能保留关系但脆弱)之间的取舍。4 月 23 日关于“记忆是偏好 vs 记忆是上下文”的张力仍在。
紧迫性:高 -- 机会:[++]
4. 使用中的工具与方法¶
| 工具 / 方法 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Sakana Fugu | 多智能体编排 API | 正面 | SWE-Pro/GPQA-D/ALE-Bench 上 SOTA、兼容 OpenAI、两个延迟档位 | 仅测试版、生产失效模式未经验证 |
| Grok Voice Think Fast 1.0 | 语音智能体模型 | 正面 | tau-voice 第 1(67.3%)、实时推理、25+ 种语言、噪声处理 | 新发布、第三方验证有限 |
| Agent Skills format | 技能分发 | 正面 | 支持多个运行框架、一条命令安装、供应商生态增长 | 缺少标准技能选择/搜索机制 |
| Smithers | 编排即代码 | 正面 | 基于代码的编排、并行/顺序任务树、计划推出 GUI | 早期、单人开发 |
| Aeon Framework | 自主智能体框架 | 褒贬不一 | 零监督设计、424K 浏览量 | 担心无人监控的大规模执行带来安全风险 |
| Async Flash v1.0 | 流式 TTS | 正面 | 81.2% 句子级内联规范化、无需预处理 | 基准测试由厂商自行发布 |
| Replit Security Agent | 安全扫描 | 正面 | Auto-Protect、免费导入应用、集成进平台 | 平台锁定 |
| Pipecat + Smallest AI | 语音智能体管线 | 正面 | Lightning TTS + Pulse STT 原生集成、开源 | 面向开发者 |
| EvoSkill V1 | 智能体自我改进 | 正面 | 通过基准测试把编程智能体演化为专家、开源 | 早期发布、基准覆盖有限 |
| StructMem | 智能体记忆 | 研究 | 以事件为中心、定期整合、降低 token 用量 | 论文阶段、暂无生产落地 |
| Claude Code 子智能体模型参数 | 多模型编排 | 正面 | 可向子智能体传入可选模型名,用于多模型评审 | 未文档化、需要 Claude Code |
4 月 24 日的主导模式是基于技能的分发:供应商把领域专业知识打包为可安装技能,而不是构建自定义集成。/plugin marketplace add 和基于 GitHub 的技能安装正在汇合为标准入口。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 成熟度 | 链接 |
|---|---|---|---|---|---|---|
| Sakana Fugu | @SakanaAILabs | 托管 API 形式的多智能体编排 | 手动模型选择与协调 | 兼容 OpenAI 的 API | Beta | post |
| EvoSkill V1 | @SentientAGI | 通过基准测试把编程智能体演化为任务专家 | 每个领域都要手写提示词 | Python、开源 | 已发布 | post |
| Aeon | @aeonframework | 全自主智能体框架,零审批环节 | 人工监督瓶颈 | GitHub | 已发布 | post |
| deepagents-sandbox | @nu_b_kh | 面向智能体代码执行的原生 Linux 沙箱 | 智能体隔离中的 Docker/VM 开销 | bubblewrap、cgroups v2 | 已发布 | post |
| elba | @shreyansh_005 | 面向受监管欧盟行业的自助式语音智能体平台 | 语音智能体的 GDPR/EU AI Act 合规 | 欧盟托管 | 已发布 | post |
| Shadowclaw | @webxos | 使用本地 LLM(Ollama)的 C 语言轻量 AI 智能体 | 依赖云端 LLM API | C、Ollama | 已发布 | post |
| /company-research skill | @JaySahnan | 用深度研究构建目标客户名单的 GTM 技能 | 手动潜客研究 | Skills 格式 | 已发布 | post |
| Codexmaxxing | @workingclassbud | Codex 的 UI 设计技能:设计迭代、浏览器自动化 | 前端智能体缺少视觉验证 | Skills、MIT | 已发布 | post |
| AgenC Marketplace | @a_g_e_n_c | 智能体驱动的工作市场,不需要代码/CLI | 下单智能体工作需要技术配置 | Devnet | Alpha | post |
| Kraken CLI | @diegoxyz | 面向加密货币、股票、外汇交易智能体的 AI 原生 CLI | 手动执行交易策略 | 开源、MCP | 已发布 | post |
EvoSkill V1 的自我改进方法值得关注:它输入一个基准测试和编程智能体,评估智能体,使用失败轨迹作为反馈,并自动迭代提示词和技能。@SentientAGI 报告,在无人参与下把 Claude Code 在 OfficeQA 上从 60.6% 推到 68.1%,SealQA 从 26.6% 推到 38.7%。同一套技能零样本迁移到 BrowseComp,带来 5% 提升。该工具适配 OpenCode、OpenHands、Goose 和 Codex CLI。
deepagents-sandbox 解决一个实际基础设施缺口:@nu_b_kh 使用 bubblewrap + cgroups v2 构建原生 Linux 沙箱,不用 Docker 或 VM 即可隔离智能体代码执行。智能体获得可写 /workspace、默认阻断网络、内存/PID 限制和超时强制。
6. 新动态与亮点¶
Amazon Bedrock AgentCore 披露《Agent God Mode》¶
@Unit42_Intel(Palo Alto Networks)发布 研究,显示 Amazon Bedrock AgentCore 中过于宽泛的 IAM 权限可导致跨 AWS 账户权限提升。被攻陷的智能体可通过多阶段攻击访问记忆并提取敏感数据。这是主要云提供商的托管智能体服务中首个公开披露的权限提升漏洞。
信号强度:[+++]
Sakana Fugu 以商业 API 形式发布多智能体编排¶
Sakana AI 发布首个托管式多智能体编排 API,并给出 SOTA 基准测试结果。兼容 OpenAI 的接口和两档定价(Mini 侧重延迟、Ultra 侧重深度)代表该类别的新交付模式——此前只有自托管框架。
信号强度:[++]
智能体操作员成为非工程岗位¶
@rvivek 预测(7 个点赞、6 次收藏):“未来 5 年最热门的工作会是智能体操作员。他们不需要是工程师。需要的技能包括:MCP、CLI、写作能力(是写文件那种)、agents.md 素养,以及商业判断。这些东西今天任何 CS 课程都没教。” 这把智能体操作框定为一个不同于软件工程的新职业类别。
信号强度:[+]
Kimi K2.6 Agent Swarm 运行 300 个并行子智能体¶
@RoundtableSpace 报道(47 个点赞、21 次收藏、50,482 次浏览):“Kimi K2.6 Agent Swarm 刚发布,300 个并行子智能体,每次运行 4,000 步。输出都是真文件——一次运行就能交付 100+ 个文件。” 这代表并行智能体执行规模的显著提升。
信号强度:[++]
7. 机会在哪里¶
[+++] 默认安全的智能体基础设施 -- Unit 42 在 Amazon Bedrock AgentCore 中披露的《Agent God Mode》、Open Swarm 缺失 WebSocket 认证,以及 Amazon 的四起 SEV1 事件表明,托管智能体平台的默认配置危险地宽松。Ledger 描述的执行与授权分离还没有成为任何主要平台的默认能力。构建安全优先智能体基础设施的团队最有明确缺口可填。来源:@Unit42_Intel, @ZackKorman, @dannylivshits, @Ledger.
[+++] 智能体技能分发与策展 -- 4 月 24 日,MotherDuck、DFlow、PancakeSwap、FileCityAI 和多个独立开发者发布可安装技能,技能生态再次扩张。/plugin marketplace add 模式正在成为标准。但还没有技能市场提供质量评分、搜索,或基于任务上下文的智能选择。发现与选择层完全开放。来源:@motherduck, @0xDeployer, @JaySahnan, @EXM7777.
[++] 感知上下文的技能加载,防止注意力稀释 -- @Vtrivedy10 展示无关技能会吸收 42% 的注意力预算。随着可用技能数量增长,全部加载会适得其反。一个在隔离上下文窗口中只搜索并加载匹配任务的技能的系统,将直接提升智能体表现。来源:@Vtrivedy10, @SynabunAI.
[++] 托管 API 形式的多智能体编排 -- Sakana Fugu beta 代表首个商业化托管多智能体编排服务。大多数团队仍然自托管框架。随着智能体工作负载变得更复杂,对托管编排(模型选择、失效处理、成本优化)的需求会增长。兼容 OpenAI 的 API 模式降低了门槛。来源:@SakanaAILabs, @WesRoth.
[+] 面向受监管行业的语音智能体合规 -- elba 发布自助式语音智能体,对齐 GDPR、EU AI Act、EU Data Act 和 HL7 FHIR。随着语音智能体进入医疗、法律和金融服务,将需要合规优先的平台。受监管语音智能体市场仍处于萌芽期。来源:@shreyansh_005.
8. 要点总结¶
-
Agent Skills 生态继续快速扩张,MotherDuck、DFlow、PancakeSwap 和多个独立开发者在 4 月 24 日发布可安装技能。
/plugin marketplace add模式正在成为标准安装入口,但还没有技能市场提供质量评分或基于任务的智能选择。(source, source) -
Sakana Fugu 发布首个托管式多智能体编排 API,在 SWE-Pro、GPQA-D 和 ALE-Bench 上达到 SOTA。 兼容 OpenAI 的 API 和两档定价(Mini 侧重延迟、Ultra 侧重深度)代表一种新交付模式——此前多智能体编排只以自托管框架形式存在。(source)
-
上下文工程获得最清晰的实践框架:上下文中每个 token 都是下一个 token 的加权投票,加载 12 个无关技能会吸收 42% 的注意力预算。 这直接连接到技能激增问题——随着可用技能增多,智能选择对智能体表现变得关键。(source)
-
同一天有两个生产系统披露智能体安全漏洞。 Palo Alto Unit 42 披露 Amazon Bedrock AgentCore 中的《Agent God Mode》(过于宽泛的 IAM 导致权限提升),Open Swarm 的本地 WebSocket API 没有认证。两者影响已上线产品,而不是原型。(source, source)
-
xAI 的 Grok Voice Think Fast 1.0 声称以 67.3% 占据 tau-voice 基准第 1,Async 发布第一个流式 TTS 内联文本规范化开放基准,准确率为 81.2%。 语音智能体技术栈正在基础模型、基础设施管线和监管合规多个方向同时推进。(source, source)
-
简单 vs 复杂编排的争论产出了实践者共识:路由、执行、审校、输出。 @georgeorch(254 个点赞)提炼:“我这几个月一直用同一套 4 智能体架构。它不花哨,但就是管用。” 同时,Aeon Framework 发布零监督自主性,Smithers 推出编排即代码。实践者务实思路与框架雄心之间的差距扩大。(source)
-
EvoSkill V1 展示自动化智能体自我改进:在无人参与下,将 Claude Code 在 OfficeQA 上从 60.6% 提升到 68.1%,并让技能零样本迁移到 BrowseComp。 这种自动研究模式——使用失败轨迹迭代提示词和技能——可能成为领域专精的标准方法。(source)
-
智能体发起支付的法律框架仍未定义。 Fenwick 发布关于智能体支付责任的文章:当智能体付款且出错时由谁负责,目前没有清晰答案。随着 x402 和链上智能体支付扩张,法律真空会成为采用的实际约束。(source)