Twitter AI Agent - 2026-04-29¶
1. What People Are Talking About¶
1.1 Agentic Harness Engineering Paper Formalizes Self-Improving Harnesses 🡕¶
The day's highest-signal item was a new paper (arXiv:2604.25850v1) introducing Agentic Harness Engineering (AHE), shared by @omarsar0 in a detailed breakdown (500 likes, 1,013 bookmarks, 34,840 views). The framework makes harness evolution observable through three pillars: component observability (file-level edits that are revertible), experience observability (condensed evidence from millions of trajectory tokens), and decision observability (falsifiable predictions checked against task outcomes). Results: pass@1 on Terminal-Bench 2 climbs from 69.7% to 77.0% in ten iterations, beating human-designed Codex-CLI (71.9%) and self-evolving baselines ACE and TF-GRPO. The evolved harness transfers across model families with +5.1 to +10.1 point gains while using 12% fewer tokens.

Martin Fowler linked (139 likes, 170 bookmarks) to his fragments page featuring Birgitta Böckeler's harness engineering video and Chris Parsons' updated AI coding guide, which argues: "The game is not 'how fast can we build' anymore. It is 'how fast can we tell whether this is right'." @jobergum posted (80 likes, 91 bookmarks) the Skill Retrieval Augmented Agents paper from Tsinghua University, proposing dynamic skill retrieval from corpora of 26,262 skills. Their SRA-Bench finding: current agents load skills at similar rates regardless of whether the task actually needs external capabilities -- the bottleneck is knowing when to load, not what to retrieve.

Discussion insight: @RuijieRao offered the most grounded practitioner response: "the hand-tuning part is real. most of my time building agent workflows isn't writing the core logic, it's iterating on the harness config... the bottleneck is that you can't evaluate harness quality without running the full task." @ethankongee extended the frame: self-improving + self-healing + self-secure + self-maintaining = the full vision. @DylSwanepoel identified the core value: "making agent improvement falsifiable instead of vibes-based."
Comparison to prior day: April 28 saw harness engineering reach the conference stage with ODSC talks. April 29 produces the first peer-reviewed framework that automates harness evolution with benchmarked results, moving from "teach it" to "let it improve itself."
1.2 Agent Skills Ecosystem Explodes Across Platforms 🡕¶
The "skills" primitive reached critical mass on April 29 with simultaneous activity across multiple platforms. @bigaiguy reported (12 likes, 11 bookmarks) that Obsidian's creator Kepano dropped obsidian-skills to 27K stars, teaching Claude Code, Codex CLI, and OpenCode to read/write/reason inside vaults. Five skills shipped at launch (obsidian-markdown, obsidian-bases, json-canvas, obsidian-cli, defuddle), installable via npx skills add. @WesRoth noted (11 likes) xAI developing a dedicated "Skills" tab for Grok, with Grok 4.3 supporting skills creation. @github_skydoves published (36 likes, 32 bookmarks) Compose Performance Skills for Jetpack Compose, grounded in primary sources.
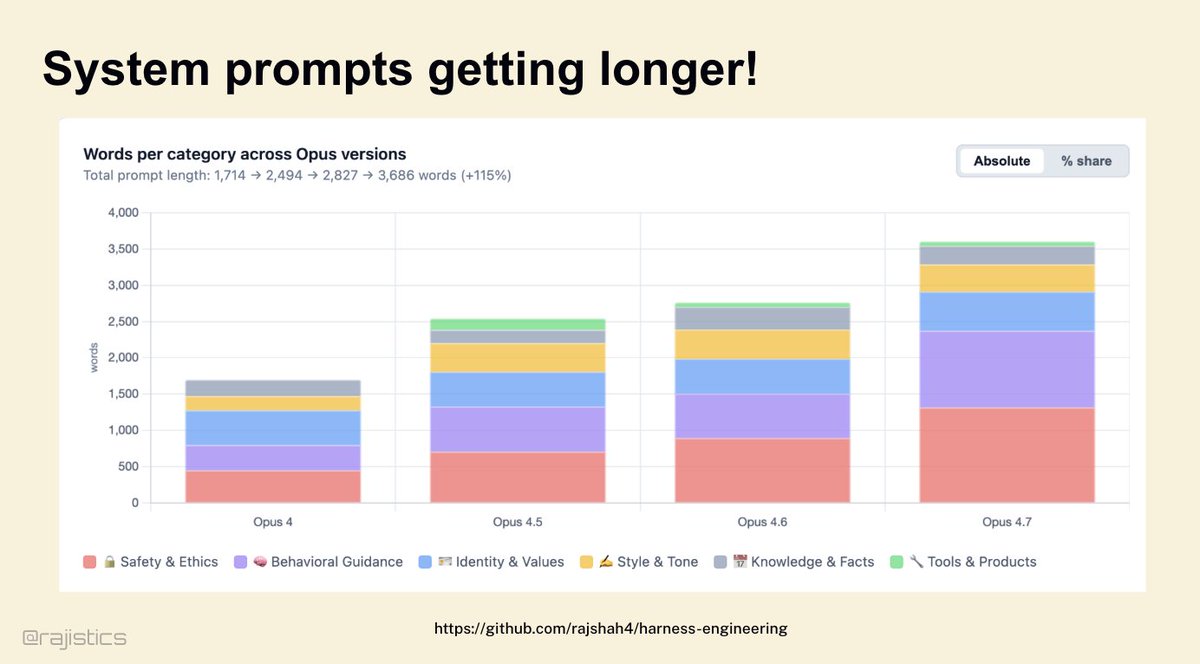
@code (VS Code) announced (39 likes, 20 bookmarks) Agent Plugins for installing skills, commands, MCP servers, and hooks. @rajistics shared slides from his ODSC harness engineering talk showing system prompts growing 115% across Opus versions (1,714 to 3,686 words).
Discussion insight: @_jphwang admitted the gap practitioners feel: "I didn't actually know (a) how much they boosted performance, and (b) how to write good ones." This points to skills being widely adopted but poorly understood.
Comparison to prior day: April 28 saw Google launch its official Agent Skills repository. April 29 shows the pattern proliferating: Obsidian, xAI/Grok, VS Code, and domain-specific repos all converging on skills as the standard extension mechanism.
1.3 Cursor SDK and /multitask Ship Agent-as-Infrastructure 🡕¶
Cursor made two significant moves. @cursor_ai introduced the Cursor SDK allowing developers to build agents with the same runtime, harness, and models that power Cursor -- runnable from CI/CD pipelines, automations, or embedded in products. @alphabatcher framed it (11 likes): "CI fails > agent wakes up > checks the repo > patches the bug > opens the PR > shows up in Cursor if a human needs to take over. At some point the IDE stops being the place the agent lives and becomes the place you inspect the agents."
Separately, @kevinkern reported (33 likes, 12 bookmarks) that Cursor shipped /multitask: "instead of one agent doing everything in one long context, the main agent can split work into smaller async subagents... you can use different models for different tasks within Cursor's harness. I've been running Opus 4.7 as the main orchestrator and GPT-5.5 high for implementation tasks."
Discussion insight: @infix_fun flagged a limitation: "I just wish it would work consistently. It doesn't try to parallelize as much as I'd like." The cross-model orchestration pattern (premium model orchestrates, cheaper model implements) is emerging as the practical default.
Comparison to prior day: April 28's jcode launched grey-zone parallel agent sessions. April 29's Cursor SDK offers the legitimate version: officially supported agent runtime embeddable in CI/CD, plus IDE-native orchestration via /multitask.
1.4 Context Engineering and Agent Orchestration Converge on Shared Primitives 🡒¶
@Av1dlive highlighted (110 likes, 230 bookmarks) a video playbook on "context engineering, tool design, orchestrator-subagent, evals, the harness mindset," framing it as the path to being a 100x agentic engineer. @yoheinakajima endorsed (82 likes, 162 bookmarks) an article on simplifying agent orchestration to its core, noting it "converges on an architecture very similar to babyagi 2, which stored functions (agent tools) in a db with input/output/dependencies/keys."
@akoratana described (90 likes, 135 bookmarks) a "context graph" -- a company world model emerging from work exhaust rather than manual documentation. Key claim: PlayerZero went from 54% to 95+% simulation accuracy in six months purely from accumulated context. @DeepLearningAI covered (25 likes, 11 bookmarks) a workshop on memory engineering and context engineering, with the line: "An AI Agent without memory is just autocomplete with ambition."
Discussion insight: @wanner_tyler posed the synthesis: "imagine if beautiful, simple, robust, reliable durable deterministic workflow tools already existed with simple function level workflow semantics and you simply gave agents governed levers to run that system." The convergence point is that orchestration, context, and memory are collapsing into a single discipline.
Comparison to prior day: April 28 focused on memory architecture reverse-engineering (Hermes five-layer system). April 29 moves to the higher abstraction: orchestration and context as unified engineering disciplines.
1.5 Agent-to-Agent Commerce Gets First Real-Money Evidence 🡕¶
@omooretweets shared (70 likes, 64 bookmarks, 9,949 views) Anthropic's internal "Project Deal" experiment: Claude interviewed 69 employees about items to buy/sell, set up a classified marketplace, and agents negotiated deals autonomously. Result: 186 matches, $4,000+ in real transactions, physical goods exchanged from snowboards to ping-pong balls. Participants stated willingness to pay for a similar service.

@ryanmcnutty33 identified the infrastructure gap: "I think we will need a radio for agents to have it work. I'm thinking some new infra that would act like a broadcast for other agents to see each other that isn't just a centralized lookup. Discovery is going to be such a big problem." @pjmfinn extended the application: "This should be the direction for LinkedIn as well. Have an agent intermediary that validates incoming and helps you with outgoing."
Discussion insight: The shift from "agents negotiating theoretical trades" to "agents negotiating real physical goods with real money among real employees" is a significant evidence upgrade. The stated bottleneck -- agent discovery infrastructure -- mirrors the skills retrieval problem from a different angle.
Comparison to prior day: April 28 first reported this experiment via @DeFi_Pop. April 29 surfaces the primary source (Anthropic blog) with concrete details and practitioner responses focused on infrastructure gaps.
1.6 Pika Agents Continue the "RIP Prompt Box" Thesis 🡒¶
Pika Agent's launch continued generating coverage. @dr_cintas demonstrated (38 likes, 39 bookmarks, 5,063 views) teaching an agent a full creative ads skill and executing in one shot. @svpino analyzed (13 likes, 16 bookmarks) the approach: "The bet here is on improving the interface between humans and agents." Multiple posts echoed Pika's framing: personality-driven conversation replaces prompt engineering for creative workflows.
@Th3RealSocrates maintained the competitive analysis from April 28: "the personality layer is the moat here. model selection will commoditize in 6 months but 'my Pika agent' keeps users sticky."
Comparison to prior day: April 28 introduced the Pika Agent launch. April 29 adds practitioner demonstrations and sustained endorsement but no new technical claims.
1.7 OneManCompany Organizational MAS Framework Gains Traction 🡕¶
@TheTuringPost published (6 likes, 6 bookmarks) a detailed breakdown of Huawei Noah's Ark Lab's OneManCompany framework. Key innovations: Skills become Talents (full agent packages with role, tools, prompts, configs); Container = runtime (Claude Code, LangGraph, scripts); Talent Market for dynamic recruitment; E2R (Explore-Execute-Review) tree search; and an HR lifecycle with performance reviews, PIP, offboarding, and replacement. Result: 84.67% on PRDBench, +15 over baselines.
@Jiaru_Zou introduced (34 likes, 28 bookmarks, 5,360 views) RecursiveMAS, a complementary approach: latent-space recursion for multi-agent collaboration achieving +8.3% average accuracy, 1.2-2.4x inference speedup, and 34.6-75.6% token reduction across 9 benchmarks.
Comparison to prior day: April 28 introduced OMC at 68 bookmarks. April 29 adds detailed technical breakdowns and a complementary recursive approach, cementing organizational metaphors as the leading multi-agent architecture pattern.
2. What Frustrates People¶
Coding Agents Do Not Codify Feedback for Reuse -- Severity: High¶
@RhysSullivan articulated (34 likes, 1,787 views) the gap: "coding agents don't push you enough towards reusability of feedback. Just gave notes to my agent about how it doing optimistic updates wrong, but there's not really a 'step 2' that's encouraged of codifying that knowledge for the future." @skeptrune confirmed the problem: "claude code has started saying 'added a memory for this', but I tend to believe it doing that is just a path towards context rot." @_jack_hogan added: "using tons of memories feels wrong (and is unreliable), unsure how to do this optimally." The only clear workaround came from @NathanOyler: "I codify the knowledge in skills... I also use cronjobs to improve skills."
Harness Sovereignty vs Platform Lock-in -- Severity: Medium¶
@Vtrivedy10 argued (12 likes) that harnesses "deeply affect agent performance" and outsourcing them means "praying that labs or closed harnesses do this for you and align with your goals." @jobergum stated it bluntly: "Don't outsource your agent harness." @itunpredictable catalogued (53 likes, 3,337 views) the conflicting pitches flooding practitioners: "We're starting an agent harness company. We're pivoting into an open source IDE for coding agents. It's a context engine for your internal brain." The signal: developers want harness ownership but the ecosystem fragmentation makes choosing costly.
Cursor /multitask Parallelization Is Inconsistent -- Severity: Low¶
@infix_fun reported: "It doesn't try to parallelize as much as I'd like. In fact I had a session where it kept dispatching to the same agent." Early-stage orchestration UX where the capability exists but reliability is uneven.
3. What People Wish Existed¶
Feedback-to-Skill Pipeline as Default Agent Behavior¶
@RhysSullivan and multiple replies confirm: when you correct an agent, the correction should automatically become a reusable skill or rule, not a fragile memory entry. The current options (memories that rot, manual skill creation) require human effort that defeats the productivity purpose. Need: a framework-level "feedback capture > skill synthesis > validation" pipeline.
Urgency: High -- Opportunity: direct
Agent Discovery Infrastructure for Commerce¶
@ryanmcnutty33 identified in response to Anthropic's marketplace experiment: "some new infra that would act like a broadcast for other agents to see each other that isn't just a centralized lookup." As agents begin transacting, they need decentralized discovery mechanisms -- the equivalent of DNS for agent services.
Urgency: Medium -- Opportunity: infrastructure
Skill Quality Verification at Scale¶
The SR-Agents paper revealed agents load skills regardless of need. As skill corpora grow (26,262+ in the benchmark), the missing layer is automatic quality scoring and relevance gating -- knowing not just which skill exists but whether loading it will actually help the current task.
Urgency: Medium -- Opportunity: research-to-product
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude Code | Coding agent | Positive | Fowler endorses; ODSC talks reference it; skills ecosystem growing | Subscription constraints for multi-agent; memory codification gap |
| Cursor SDK | Agent runtime | Positive | Same runtime/harness as IDE; CI/CD embeddable; /multitask orchestration | Parallelization inconsistent; brand new |
| Hermes Agent | Agent framework | Positive | Swarm patches shipping; multi-user support | Complexity for beginners |
| Obsidian Skills | Skills package | Positive | 27K stars; 5 skills at launch; MIT; works with Claude Code/Codex/OpenCode | Vault-specific; new ecosystem |
| Agent Skills spec | Standard | Positive | Adopted by Google, Obsidian, Sleek, HeyGen, VS Code, xAI | No quality verification layer |
| Codex CLI | Coding agent | Mixed | Fowler recommendation; AHE paper uses as baseline (71.9%) | Beaten by AHE evolved harness (77.0%) |
| RecursiveMAS | Research framework | Positive | +8.3% accuracy; 2.4x speedup; 75.6% token reduction | Research stage; no production tooling |
| LiveKit | Voice agent infra | Positive | Structured data collection; Tasks/TaskGroups SDK; JSON output | Voice-domain specific |
| Gemini Agent Platform | Enterprise | Positive | Agent Identity/Registry/Gateway; multi-harness support | Enterprise-focused; newer entrant |
The dominant pattern is convergence on skills as the extension primitive, with every major platform (Google, Anthropic ecosystem, xAI, VS Code, Cursor) either shipping or announcing skills support within a single week.
5. What People Are Building¶
| Project | Who | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Agentic Harness Engineering | Fudan/Peking Univ | Self-improving harness via observability-driven evolution | Manual harness tuning; unverifiable improvements | Terminal-Bench 2, SWE-bench | Research | post |
| Cursor SDK | @cursor_ai | Embeddable agent runtime for CI/CD and products | IDE-locked agents; no programmatic access | Cursor runtime, multi-model | Shipped | post |
| obsidian-skills | Kepano | Claude Code/Codex skills for Obsidian vaults | Agents can't reason inside note systems | Agent Skills spec, npx | Shipped | post |
| Lazar | @jasonkneen | Self-evolving agent with single execute tool + skills only | Tool bloat; agent capability drift | Go, recursive self-calls | Alpha | post |
| RecursiveMAS | @Jiaru_Zou | Latent-space recursive MAS collaboration | Token waste and slow inference in multi-agent | Lightweight Connector, inner-outer loop | Research | post |
| Pentest Agent Suite | @VivekIntel | Autonomous bug bounty framework (48 agents) | Manual recon-to-report workflow | Claude, Codex, FAISS, SQLite | Shipped | post |
| Compose Performance Skills | @github_skydoves | Agent skills for Jetpack Compose performance | Generic agents lack domain expertise | Agent Skills spec | Shipped | post, repo |
| VoiceBox (local TTS/dictation) | @exploraX_ | Free local voice clone + dictation with MCP server | ElevenLabs/WisprFlow subscription cost | Chatterbox, MCP, 7 TTS engines | Shipped | post |
| X Spaces Agent | @trythreews | Agent joins live X Spaces, listens, responds with voice | Agents can't participate in live audio | Puppeteer, Groq/Anthropic/OpenAI | Alpha | post |
| Harness Engineering exercises | @rajistics | ODSC talk with published slides + exercises | No teaching materials quantifying harness growth | GitHub | Shipped | post, repo |
@jasonkneen's Lazar is notable for its extreme minimalism: one tool (execute), recursive self-calls, and skills as the only extension mechanism. It creates/discovers/evolves skills autonomously, making it a pure test of whether skills alone are sufficient for general-purpose agent behavior.
6. New and Notable¶
Agentic Harness Engineering Paper Introduces Observable Self-Improvement¶
The AHE paper (1,013 bookmarks) is the first peer-reviewed work demonstrating automated harness evolution with falsifiable predictions. The 77.0% pass@1 on Terminal-Bench 2 exceeds both human-designed harnesses and prior self-evolving approaches, while transferring across model families. Code: github.com/china-qijizhifeng/agentic-harness-engineering.
Signal strength: [+++]
Cursor SDK Makes IDE Agent Runtime Embeddable¶
Cursor SDK lets developers run the same agent runtime from CI/CD pipelines, automations, or products. Combined with /multitask (cross-model orchestration), this transforms Cursor from an IDE into an agent infrastructure provider. The "CI fails > agent patches > opens PR" workflow described by @alphabatcher is now officially supported.
Signal strength: [+++]
Martin Fowler Endorses Verification-First Harness Engineering¶
Fowler's fragments page (170 bookmarks) carries the thesis: "The game is not 'how fast can we build' anymore. It is 'how fast can we tell whether this is right'." His endorsement of Birgitta Böckeler's harness engineering article (plus a new video discussion) signals the concept has crossed from practitioner Twitter into the software architecture establishment.
Signal strength: [++]
Anthropic's Project Deal: 186 Real-Money Agent-to-Agent Trades¶
Anthropic's internal marketplace experiment (64 bookmarks) produced 186 deals across 69 employees with $4,000+ in real physical goods transacted entirely by agents. This is the strongest evidence to date that agent-to-agent commerce works with real stakes. The stated participant enthusiasm ("willingness to pay for similar service") suggests consumer demand.
Signal strength: [++]
xAI Joins Skills Ecosystem with Grok Skills Tab¶
@WesRoth reported xAI developing a Skills tab for Grok (currently hidden), with Grok 4.3 supporting skills creation. This makes xAI the fourth major platform (after Google, Anthropic ecosystem, OpenAI) to adopt skills as an extension primitive, approaching universal convergence.
Signal strength: [+]
7. Where the Opportunities Are¶
[+++] Feedback-to-skill pipeline -- The gap between "I corrected my agent" and "the agent permanently learned this" is the most consistently cited frustration across multiple independent practitioners. @RhysSullivan, @skeptrune, and @_jack_hogan all confirm that current approaches (memories, manual skill writing) are inadequate. The opportunity is an automated system that captures corrections, synthesizes them into validated skills, and prunes stale ones. The only working pattern cited is @NathanOyler's manual "cronjobs to improve skills" -- ripe for productization.
[+++] Open harness with observable evolution -- The AHE paper proves harnesses can self-improve measurably. @Vtrivedy10 and @jobergum argue developers should own their harness. The opportunity is an open-source harness base that includes AHE-style observability: every edit tracked, every prediction falsifiable, performance gains measurable without full task reruns. The first harness that ships this as a product feature captures the practitioners who currently tune by hand.
[++] Agent discovery and commerce infrastructure -- Anthropic proved agents can transact. @ryanmcnutty33 identified the missing layer: broadcast/discovery infrastructure so agents can find each other without centralized lookup. As skills marketplaces grow (Swarms, Cursor, Google), the interoperability layer for agent-to-agent service discovery becomes critical infrastructure.
[++] Skill quality and relevance gating -- The SR-Agents paper (@jobergum) revealed agents load skills indiscriminately. With 26,262+ skills in corpora and growing, the opportunity is a retrieval layer that scores skill relevance before loading -- preventing context waste and wrong-skill application. This is the "search quality" problem for the skills ecosystem.
[+] Cross-model orchestration tooling -- @kevinkern demonstrated Opus 4.7 orchestrating GPT-5.5 for implementation. Cursor's /multitask enables this but inconsistently. The opportunity is reliable cross-model orchestration where premium models plan and cheaper models execute, with automatic model selection based on subtask complexity.
8. Takeaways¶
-
The Agentic Harness Engineering paper (1,013 bookmarks) proved that harness self-improvement is measurable and transferable: pass@1 climbs from 69.7% to 77.0% in ten iterations, beating both human-designed and self-evolving baselines while using 12% fewer tokens. This moves harness engineering from "teach humans to tune" to "let the harness tune itself with observable contracts." (source)
-
The agent skills ecosystem reached convergence: Obsidian (27K stars), xAI/Grok, VS Code Agent Plugins, Cursor SDK, Google, and multiple domain-specific repos all ship or announce skills in a single day, establishing the Agent Skills spec as the de facto standard for agent extension. (source, source, source)
-
Cursor SDK transforms the IDE from workspace to agent infrastructure provider: embeddable runtime for CI/CD, /multitask for cross-model orchestration (Opus 4.7 planning, GPT-5.5 implementing), and the explicit thesis that "the IDE becomes the place you inspect the agents." (source, source)
-
Anthropic's Project Deal produced the strongest evidence yet for agent-to-agent commerce: 186 real deals, $4,000+ transacted, physical goods exchanged, with participants willing to pay for the service -- shifting the conversation from "can agents trade?" to "what discovery infrastructure do they need?" (source)
-
The feedback-to-skill gap emerged as the day's most consistent practitioner frustration: agents accept corrections but don't codify them into reusable skills, leaving developers in a loop of re-correcting the same errors across sessions. Current workarounds (memories, manual skills, cronjobs) are uniformly described as inadequate. (source)
-
Martin Fowler's endorsement of verification-first harness engineering -- "the game is not 'how fast can we build' but 'how fast can we tell whether this is right'" -- signals the concept's acceptance by the software architecture establishment, completing its arc from Twitter thread to Fowler recommendation. (source)