Twitter AI Agent - 2026-05-02¶
1. What People Are Talking About¶
1.1 The Solo AI Agency Dream: 5 Mac Minis, $34k/month 🡕¶
The day's highest-engagement item (74,344 views, 569 bookmarks) was @regent0x_ describing a one-person agency running 5 Mac Minis as specialized AI agents -- each with its own role (architect, coder, reviewer, tester, ops) and strict separation of concerns via dedicated CLAUDE.md files. He claims $34k/month revenue from 4 retainer clients at $115/month total compute cost (5 Claude subscriptions + electricity), with 847 commits across 3 client projects last month.
Each Mini has a clear boundary: the coder never sees deployment secrets, the reviewer cannot push code, ops never touches business logic. They communicate through a shared task queue, not through each other.
Discussion insight: @FabioAlfDee pushed back: "This is a nice post to go viral, but it doesn't really work like that. And most of this is nonsense in my opinion. Source: I work daily with local LLMs both on Mac and GPUs." @BenSammons noted the cost claim excludes the Claude subscriptions at their actual rate.
Comparison to prior day: May 1 focused on the Flue framework and enterprise governance (Agent 365). May 2 shifts to a concrete, visceral demonstration of what a multi-agent system looks like in practice -- physical hardware, clear separation of concerns, claimed revenue numbers. The "solo agency" pattern validates harness engineering principles (isolated contexts, role specialization) in a profit-driven setup.
1.2 Harness Engineering Terminology Solidifies 🡒¶
Multiple posts codified the vocabulary and practices of harness engineering:
@mattpocockuk (TypeScript educator) defined (33 likes, 20 bookmarks) four key terms: Model (stateless parameters), Harness (everything around the model -- tools, system prompt, context window management), Environment (the world the agent acts on), Agent (model + harness + environment). He clarified: "scaffolding is an alias of harness. Or perhaps, the thing that the harness gives the model."
@avrldotdev framed (31 likes) three disciplines replacing prompt engineering: Memory Engineering (what your system remembers), Context Engineering (what the LLM sees currently), and Harness Engineering (how your system behaves).
@DamiDefi published (106 likes, 6,745 views) a comprehensive practitioner guide declaring "every AI framework you're learning right now will be obsolete in 6 months" and listing what compounds: context engineering, tool design, orchestrator-subagent patterns, evals, and "the harness mindset."
@drummatick captured the practitioner fatigue: "AI engineering is so cooked that I read a 2 months old blog on harness and feel it's out of date already."
Comparison to prior day: May 1 saw harness engineering validated empirically (AHE paper, 12% benchmark swing). May 2 shifts from proving the concept to standardizing the language -- multiple educators simultaneously publishing definitional content signals the field is crystallizing its own vocabulary.
1.3 Agent Memory as Infrastructure, Not Feature 🡕¶
Three independent signals converged on memory as the defining challenge for production agents:
@DhravyaShah introduced (28 likes, 26 bookmarks, 5,635 views) SMFS -- a mountable filesystem abstraction with a sync index that optimizes tokens and search latency for agents. The quoted post from Mem0's CTO explains why filesystem memory breaks at scale: loading 100K tokens of memory per query costs $90/month at 10K queries/day, while selective retrieval cuts that to $1.80/month.

@dair_ai shared (14 bookmarks) a new paper "Contextual Agentic Memory is a Memo, Not True Memory" (arXiv:2604.27707, CUHK/Zhejiang) arguing that vector stores, RAG buffers, and scratchpads implement lookup, not memory. The paper draws on Complementary Learning Systems theory from neuroscience, showing that agents built exclusively on retrieval face a provable generalization ceiling.

@eng_khairallah1 posted (53 likes, 50 bookmarks) on Sam Altman's quote "Your whole life should fit in one context window," framing memory as the agent itself rather than a feature of it.
Discussion insight: @lindavivah interviewed Richmond Alake (Director of AI DevEx at Oracle) who distinguished three disciplines: "Context vs Memory vs Harness engineering" -- arguing that memory engineering treats long-term memory as first-class infrastructure, not an afterthought.
Comparison to prior day: May 1 discussed memory primarily through the lens of harness primitives (create_agent's memory support). May 2 elevates memory to an independent infrastructure problem with its own research (Memo paper), cost economics (Mem0), and dedicated tooling (SMFS).
1.4 Coding Agent Benchmarks Enter a New Paradigm 🡕¶
@omarsar0 shared (30 likes, 30 bookmarks) a new paper proposing coding agents implement famous ML breakthroughs from scratch as evaluation. The first instance: Claude Opus 4.7 built an AlphaZero-style self-play pipeline for Connect Four on consumer hardware in three hours, beating the Pascal Pons solver 7 of 8 as first-mover. No other frontier agent tested cleared 2 of 8.

Discussion insight: @MindTheGapMTG distinguished research from production benchmarks: "AlphaZero from scratch tests research autonomy. Production needs the opposite: constrained execution, tight scope. 7/8 against a solver is impressive. 7/8 reliability on a mundane task repeated 10K times is what ships."
Comparison to prior day: May 1 referenced Terminal Bench and SWE-bench as the standard evaluation surfaces. May 2 introduces a fundamentally different evaluation paradigm -- can the agent rebuild a non-trivial ML system end-to-end? -- shifting the bar from patches and unit tests to autonomous research engineering.
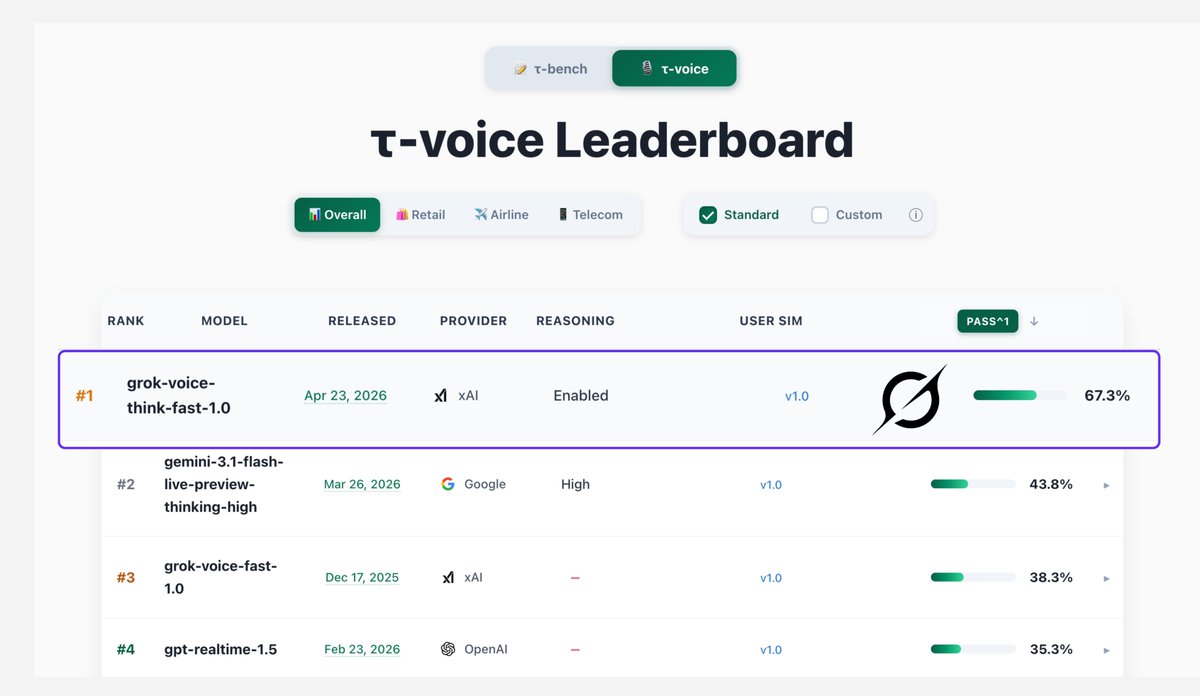
1.5 Voice Agents Show Clear Market Leader 🡒¶
@XFreeze reported (341 likes, 2.6M views) that Grok Voice scores 67.3% on the tau-voice Bench, while Gemini sits at 43.8% and GPT Realtime at 35.3%. The benchmark ranks real-time reasoning voice agents.
@Saboo_Shubham_ built (27 likes, 34 bookmarks) an open-source voice AI agent for insurance claims using Gemini 3.1 Flash Live + Google ADK that fills intake forms, extracts claim details, and routes to an adjuster in real-time.
Discussion insight: @EloPhanto raised the key challenge: "For claims agents, the hard part isn't the demo form fill -- it's the handoff contract. What confidence threshold routes to an adjuster, what fields block submission, and how the agent explains uncertainty matter more than the voice layer."
Comparison to prior day: May 1 featured ElevenLabs voice skills. May 2 shows both the benchmark landscape (Grok dominance) and practical voice agent deployment (insurance claims), with the discussion exposing that the voice interface is table stakes while the business logic layer is the real challenge.
1.6 Multi-Agent Finance Goes Mainstream 🡕¶
@gusik4ever published (33 likes, 20 bookmarks) the fastest-growing GitHub repos in finance for the week:
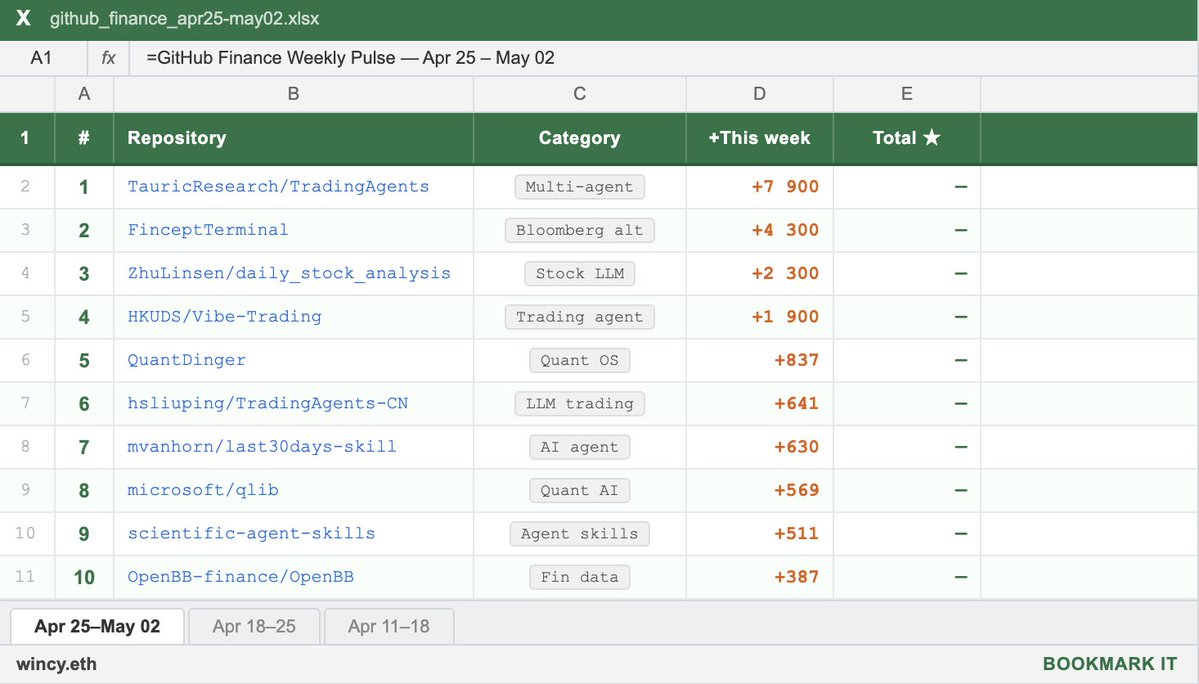
TradingAgents (+7,900 stars) leads with a multi-agent LLM trading framework from UCLA/MIT featuring fundamental analyst, sentiment analyst, technicals, and risk manager roles with DeepSeek V4 thinking-mode support. FinceptTerminal (+4,300 stars) offers an open-source Bloomberg alternative with 37 AI agents in Buffett/Munger/Lynch/Graham style.
Comparison to prior day: May 1 noted TradingAgents at +1.5K stars and critics questioning whether "agent orchestration buys edge." May 2 shows 5x acceleration in star growth (+7.9K), suggesting the skepticism has not dampened interest.
2. What Frustrates People¶
Harness Knowledge Decays Faster Than It Can Be Learned -- Severity: High¶
@drummatick expressed (19 likes): "AI engineering is so cooked that I read a 2 months old blog on harness and feel it's out of date already." @DamiDefi quantified the decay: "The agent field changes every quarter. The benchmark you optimized for got gamed. The framework you mastered is already legacy." The gap between harness knowledge production and practitioner absorption is widening. Multiple educators published definitional content on the same day, suggesting the field's vocabulary is only now stabilizing.
Agent Trace Privacy Leaks Everything -- Severity: High¶
@MaziyarPanahi documented (40 likes, 32 bookmarks): "Agent traces leak everything. Emails. API keys. patient IDs. support tickets. incident logs." Agent traces are becoming shareable artifacts (for evals, bug reports, support handoffs), but contain sensitive data. His openmed v1.3.0 masks/fakes fields locally before sharing. @ewhauser noted the gap: these models need "expert determination method" certification for health companies to adopt them.
Orchestration Still Requires Building Your Own -- Severity: Medium¶
@RhysSullivan published (67 likes, 92 bookmarks) a detailed "dream agent workflow" spec referencing Symphony, Diffity, Warden, Linear, and Graphite -- all separate tools that no single product integrates. @ianlapham recommended: "Just build one purpose built harness for your project." The prior day's frustration from @davidfowl ("Are we all doing this now?") persists -- Flue exists but is early, and practitioners still default to bespoke setups.
3. What People Wish Existed¶
Agent Memory That Actually Learns¶
The "Contextual Agentic Memory" paper (source) argues current memory systems (vector stores, RAG, scratchpads) implement lookup, not true memory. They face a "provable generalization ceiling" on novel tasks. What practitioners want: memory that generalizes by applying abstract rules to inputs never seen before, not just retrieval of similar cases. SMFS from @DhravyaShah is one attempt, optimizing for the cost/latency problem while Membase from @Unibase_AI targets the coordination/shared-state problem.
Urgency: High -- Opportunity: infrastructure
Integrated Agent Development Workflow¶
@RhysSullivan (92 bookmarks) detailed the full wish: skills that decompose projects into linear tickets, an orchestrator showing running tasks and diffs, a local PR reviewer for refinement, anti-pattern enforcement, backlinks between orchestrator/Linear/GitHub, stacked diffs via Graphite. The key requirement: "you can stop babysitting the agent runs." No existing product delivers this end-to-end.
Urgency: High -- Opportunity: product
PII-Safe Agent Trace Sharing¶
@MaziyarPanahi (32 bookmarks) ships openmed for healthcare, but the need is universal: agent traces are becoming primary artifacts for debugging, evals, and collaboration, yet they contain credentials and PII. @TommyFalkowski proposed: "a local key value store so you can unfake the entries on the way back." The full solution requires mask/fake on export and unfake on reimport, certified for regulated industries.
Urgency: Medium -- Opportunity: tooling
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Flue | Agent harness framework | (+) | First harness framework; runtime-agnostic; virtual and container sandboxes; TypeScript | Experimental; APIs may change |
| LangChain create_agent / Deep Agents | Agent framework | (+) | Extensible primitive; subagents, skills, memory, hooks; open source | Production requires significant extension |
| AWS Strands Agent SDK v1.0 | Agent SDK | (+) | Zod schemas; streaming; MCP; OpenTelemetry built-in; swap providers via config | TypeScript only; new |
| Google ADK + Gemini Enterprise | Agent platform | (+) | Long-running agents; Inbox command center; anomaly detection with LLM-as-a-judge | GCP-specific |
| GBrain | Personal agent brain | (+) | Self-wiring graph; 17K+ pages; hybrid search; P@5 49%; 34 skills; eval system | Single-user design; requires agent platform |
| Hermes Agent v0.12 | Coding/general agent | (+) | Curator auto-prunes/grades skills every 7 days; multi-agent via agent_control PR | Community-driven; Hermes ecosystem |
| OpenMed v1.3.0 | Agent trace privacy | (+) | Masks/fakes PII locally before trace sharing; healthcare usage confirmed | Needs certification for enterprise adoption |
| AutoSkills | Skill installer | (+) | One-command; detects stack; installs matching skills from skills.sh | Early; depends on skills.sh catalog |
| SMFS | Agent memory | (+) | Mountable abstraction; sync index; optimizes tokens and search latency | New; unproven at scale |
| Grok Voice | Voice agent | (+) | 67.3% on tau-voice Bench; massive lead over competitors | xAI platform only |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| GBrain | @garrytan | Personal AI brain with self-wiring knowledge graph, 34 skills | Personal agents lack structured memory | OpenClaw/Hermes, PGLite, graph DB | Shipped (v0.25) | post, GitHub |
| Voice Insurance Claims Agent | @Saboo_Shubham_ | Voice AI for insurance intake, routing to adjusters | Manual claims processing | Gemini 3.1 Flash Live, Google ADK | Shipped (OSS) | post |
| Bug Hunter v3 | @VivekIntel | Adversarial code review with Hunter/Skeptic/Referee pipeline | False positives in AI security scanning | Multi-agent, CVSS, CWE/STRIDE | Shipped | post |
| Watchtower | @VivekIntel | AI pentesting with Planner/Worker/Analyst and 20+ tools | Manual penetration testing | Multi-agent, SQLite, PDF reports | Shipped | post |
| SMFS | @DhravyaShah | Mountable filesystem abstraction with sync index for agent memory | Filesystem memory breaks at scale | Custom FS, indexer | Alpha | post |
| open-slide | @1weiho | Slide framework built for agents -- prompt to polished deck | Manual slide creation | CLI, agent-native | Shipped | post |
| Pi-Daytona Extension | @richardanaya | Replaces Pi Coding Agent file tools with Daytona sandbox access | Unsafe file system access in agents | Pi agent, Daytona | Shipped | post |
| Hermes agent_control | @DODOREACH | ACP-based multi-agent orchestration for persistent Hermes profiles | Disposable subagents cannot persist | Hermes Agent, ACP | PR open | post |
| Diff Viewer | @jeetnirnejak | Component to review coding agent changes, animated | Reviewing agent output lacks polish | Figma, Motion | Demo | post |

6. New and Notable¶
GBrain: YC President Ships Personal Agent Brain With Benchmarked Graph¶
@garrytan (YC President/CEO) open-sourced (44 likes, 39 bookmarks) GBrain -- his personal agent brain powering 17,888 pages, 4,383 people, 723 companies in a self-wiring knowledge graph. Built in 12 days with 34 skills, it runs 21 cron jobs autonomously, ingesting meetings, emails, tweets, and voice calls. Benchmarked at P@5 49.1%, R@5 97.9% -- beating graph-disabled and BM25+vector baselines by 31+ points. The agent literally maintains and enriches the knowledge graph overnight.
Signal strength: [+++]
Coding Agent AlphaZero Benchmark Establishes New Evaluation Paradigm¶
A new paper (arXiv:2604.25067, UChicago) proposes evaluating coding agents by asking them to autonomously rebuild famous ML breakthroughs. Claude Opus 4.7 implemented AlphaZero self-play for Connect Four on consumer hardware in three hours, winning 7/8 against the Pascal Pons solver. No other frontier agent cleared 2/8. This shifts evaluation from "can it patch code?" to "can it build a non-trivial ML system end-to-end?"
Signal strength: [++]
"Memory is a Memo" Paper Challenges Agent Memory Foundations¶
A paper from CUHK/Zhejiang (arXiv:2604.27707) argues that all current agent memory systems (vector stores, RAG, scratchpads) implement lookup, not true memory. Drawing on Complementary Learning Systems theory, it shows that retrieval-only agents face a provable generalization ceiling and are structurally vulnerable to persistent memory poisoning. The paper calls for pairing fast hippocampal storage with slow neocortical weight consolidation.
Signal strength: [++]
AWS Ships Full Agent Harness SDK v1.0¶
@awsdevelopers shipped (38 likes, 15 bookmarks) version 1.0 of their TypeScript agent SDK with Zod schemas, streaming, MCP support, multi-agent orchestration, session persistence, and OpenTelemetry baked in. Providers (Bedrock, OpenAI, Anthropic, Gemini) swap via one config change.

Signal strength: [+]
Google Ships Agent Anomaly Detection¶
@GoogleCloudTech announced (61 likes, 15 bookmarks) Agent Anomaly Detection in Gemini Enterprise Agent Platform, using statistical models and an LLM-as-a-judge framework to flag unusual reasoning in real time. This represents the shift from "model safety" to "agent governance" -- monitoring runtime behavior rather than just training-time alignment.
Signal strength: [+]
7. Where the Opportunities Are¶
[+++] Personal agent brain infrastructure -- @garrytan demonstrates the value (17K pages, 21 cron jobs, quantified retrieval quality) but his setup requires significant technical skill. The pattern -- agent ingests all personal data, builds knowledge graph, runs maintenance overnight, answers queries with graph-boosted retrieval -- is reproducible but not yet productized for non-technical users. Prior day's "$5-15/month personal agent" pattern from @thegreatola is the budget version; GBrain is the premium version. The gap between them is the product opportunity.
[+++] Agent trace privacy and PII management -- Agent traces are becoming primary collaboration artifacts (evals, debugging, handoffs) but leak credentials and PII. @MaziyarPanahi ships openmed for healthcare; the universal solution (mask on export, unfake on reimport, certified for regulated industries) does not exist. Every agent platform will need this as traces become shareable.
[++] Integrated agent development workflow -- @RhysSullivan (92 bookmarks) detailed the full wish list: ticket decomposition, orchestrator visibility, local review, anti-pattern enforcement, stacked diffs. No product delivers this end-to-end. Symphony, Diffity, Warden, Linear, and Graphite exist independently but require manual glue. The first product that integrates these into a single agent development flow captures the developer who wants to "stop babysitting agent runs."
[++] True agent memory beyond retrieval -- The "Memo, Not True Memory" paper and SMFS/Membase launches confirm that current retrieval-based memory hits a ceiling. The opportunity is memory infrastructure that generalizes (weight consolidation, learning from experience) rather than just recalls. This is research-stage but the demand signal is clear from multiple independent teams.
[+] Agent security tooling (adversarial validation) -- Bug Hunter's Hunter/Skeptic/Referee pattern and Watchtower's Planner/Worker/Analyst both demonstrate multi-agent approaches to security. The common insight: a single agent cannot reliably self-validate. Adversarial multi-agent security scanning is an emerging category with demonstrated practitioner demand.
8. Takeaways¶
-
A one-person agency running 5 Mac Minis as specialized AI agents claims $34k/month at $115/month compute, generating the day's highest engagement (74K views, 569 bookmarks) and demonstrating harness engineering's economic potential. The setup uses strict role separation via dedicated CLAUDE.md files -- architect, coder, reviewer, tester, ops -- communicating through a shared task queue. (source)
-
Harness engineering vocabulary standardizes in a single day, with Matt Pocock defining Model/Harness/Environment/Agent and multiple educators publishing concurrent definitional content, signaling the field has reached the "naming things" stage. This follows May 1's empirical validation and suggests the discipline is ready for formal documentation and curriculum. (source)
-
A new paper argues all current agent memory (vector stores, RAG, scratchpads) implements lookup not memory, with a provable generalization ceiling, while three independent projects (SMFS, Membase, GBrain) ship competing memory infrastructure. The convergence from research critique and product launches indicates memory engineering is separating from general agent work into its own infrastructure category. (source, source)
-
Claude Opus 4.7 builds an AlphaZero self-play pipeline from scratch in 3 hours on consumer hardware and beats the Pascal Pons solver 7/8, establishing a new benchmark paradigm that evaluates coding agents on end-to-end ML system implementation rather than patches. No other frontier agent cleared 2/8, suggesting a significant capability gap at the research autonomy level. (source)
-
Garry Tan (YC President) open-sources GBrain, his personal agent brain with 17,888 pages and a self-wiring knowledge graph benchmarked at P@5 49.1%, beating graph-disabled baselines by 31+ points, demonstrating that personal agent infrastructure is now quantifiably superior to flat retrieval. 21 cron jobs run autonomously to ingest and maintain the graph. (source)
-
AWS ships Strands Agent SDK v1.0 with OpenTelemetry built in, Grok Voice leads tau-voice Bench at 67.3% vs Gemini's 43.8%, and Google launches Agent Anomaly Detection, collectively showing that agent infrastructure has entered the "boring plumbing" phase where observability, governance, and benchmarking matter more than model capabilities. (source, source, source)