Twitter AI 智能体 - 2026-05-02¶
1. 人们在讨论什么¶
1.1 单人 AI 代理公司的梦想:5 台 Mac Mini,每月 34k 美元 🡕¶
当天互动最高的内容(74,344 次浏览,569 次收藏)来自 @regent0x_ 描述的一个单人代理公司:用 5 台 Mac Mini 运行专门化 AI 智能体——每台都有自己的角色(架构师、程序员、审查员、测试员、运维),并通过专属 CLAUDE.md 文件严格隔离职责。他声称,每月以 115 美元总计算成本(5 个 Claude 订阅 + 电费),从 4 个 retainer 客户获得 34k 美元收入,上个月在 3 个客户项目中提交了 847 次 commit。
每台 Mini 都有清晰边界:程序员看不到部署密钥,审查员不能推送代码,运维从不触碰业务逻辑。它们通过共享任务队列沟通,而不是互相对话。
讨论要点: @FabioAlfDee 反驳道:“这是一篇适合爆火的帖子,但实际不是这么运作的。我认为其中大多数都是胡扯。来源:我每天都在 Mac 和 GPU 上用本地 LLM 工作。” @BenSammons 指出,成本说法没有按真实价格计入 Claude 订阅。
与前日对比: 5 月 1 日关注 Flue 框架和企业治理(Agent 365)。5 月 2 日转向一个具体、直观的多智能体系统实践演示——实体硬件、清晰职责隔离、声称的收入数字。“单人代理公司”模式在一个利润驱动的设置中验证了运行框架工程原则(隔离上下文、角色专门化)。
1.2 运行框架工程术语定型 🡒¶
多条帖子固化了运行框架工程的词汇和实践:
@mattpocockuk(TypeScript 教育者)定义(33 次点赞,20 次收藏)了 4 个关键术语:Model(无状态参数)、Harness(模型周围的一切——工具、系统提示词、上下文窗口管理)、Environment(智能体作用的世界)、Agent(模型 + 运行框架 + 环境)。他澄清:“scaffolding 是 Harness 的别名。或者说,是运行框架提供给模型的东西。”
@avrldotdev 把(31 次点赞)3 门学科描述为提示工程的替代:记忆工程(系统记住什么)、上下文工程(LLM 当前看到什么)和运行框架工程(系统如何行为)。
@DamiDefi 发布(106 次点赞,6,745 次浏览)了一份全面的实践者指南,宣称“你现在正在学习的每个 AI 框架都会在 6 个月内过时”,并列出会复利积累的能力:上下文工程、工具设计、编排器-子智能体模式、评估,以及“运行框架心智”。
@drummatick 概括了实践者疲劳:“AI 工程已经熟透了,我读一篇 2 个月前关于运行框架的博客,都觉得它已经过时。”
与前日对比: 5 月 1 日,运行框架工程得到了经验证实(AHE 论文、12% 基准波动)。5 月 2 日从证明概念转向标准化语言——多位教育者同时发布定义性内容,说明这个领域开始拥有自己的词汇体系。
1.3 智能体记忆是基础设施,不是功能 🡕¶
三个独立信号共同指向:记忆正在成为生产智能体的决定性挑战。
@DhravyaShah 介绍(28 次点赞,26 次收藏,5,635 次浏览)SMFS——一种可挂载的文件系统抽象,带同步索引,为智能体优化 token 和搜索延迟。Mem0 CTO 的引用帖解释了为什么文件系统记忆无法在生产规模上成立:每次查询加载 100K token 记忆,在每天 10K 次查询下每月成本为 90 美元;选择性检索则把成本降到 1.80 美元/月。

@dair_ai 分享(14 次收藏)了一篇新论文“Contextual Agentic Memory is a Memo, Not True Memory”(arXiv:2604.27707,CUHK/Zhejiang),认为向量库、RAG buffer 和 scratchpad 做的是查找,不是记忆。论文借鉴神经科学中的 Complementary Learning Systems 理论,指出完全基于检索构建的智能体存在可证明的泛化上限。

@eng_khairallah1 发布(53 次点赞,50 次收藏)了关于 Sam Altman 那句“你的一生都应该能装进一个上下文窗口”的帖子,把记忆描述为智能体本身,而不是它的一个功能。
讨论要点: @lindavivah 采访了 Oracle AI DevEx 总监 Richmond Alake,他区分了三门学科:“上下文 vs 记忆 vs 运行框架工程”——并认为记忆工程把长期记忆视为一等基础设施,而不是事后补上的功能。
与前日对比: 5 月 1 日主要通过运行框架原语(create_agent 的记忆支持)讨论记忆。5 月 2 日,社区把记忆提升为一个独立基础设施问题,它有自己的研究(Memo 论文)、成本经济学(Mem0)和专用工具(SMFS)。
1.4 编程智能体基准进入新范式 🡕¶
@omarsar0 分享(30 次点赞,30 次收藏)了一篇新论文,提出要求编程智能体从零复现著名 ML 突破来评估它们。第一个实例是:Claude Opus 4.7 在消费级硬件上用 3 小时构建了一个面向 Connect Four 的 AlphaZero 式自博弈管线,并在先手情况下 8 局赢了 Pascal Pons solver 中的 7 局。其他被测试的前沿智能体没有一个超过 2/8。

讨论要点: @MindTheGapMTG 区分了研究基准和生产基准:“从零复现 AlphaZero 测的是研究自主性。生产需要相反的东西:受约束执行、范围紧。对 solver 7/8 很厉害。一个普通任务重复 10K 次还能有 7/8 可靠性,才是能上线的东西。”
与前日对比: 5 月 1 日还把 Terminal Bench 和 SWE-bench 当作标准评估表面。5 月 2 日引入了完全不同的评估范式——智能体能否端到端重建一个非平凡 ML 系统?——把门槛从 patch 和单元测试抬到自主研究工程。
1.5 语音智能体出现明确市场领先者 🡒¶
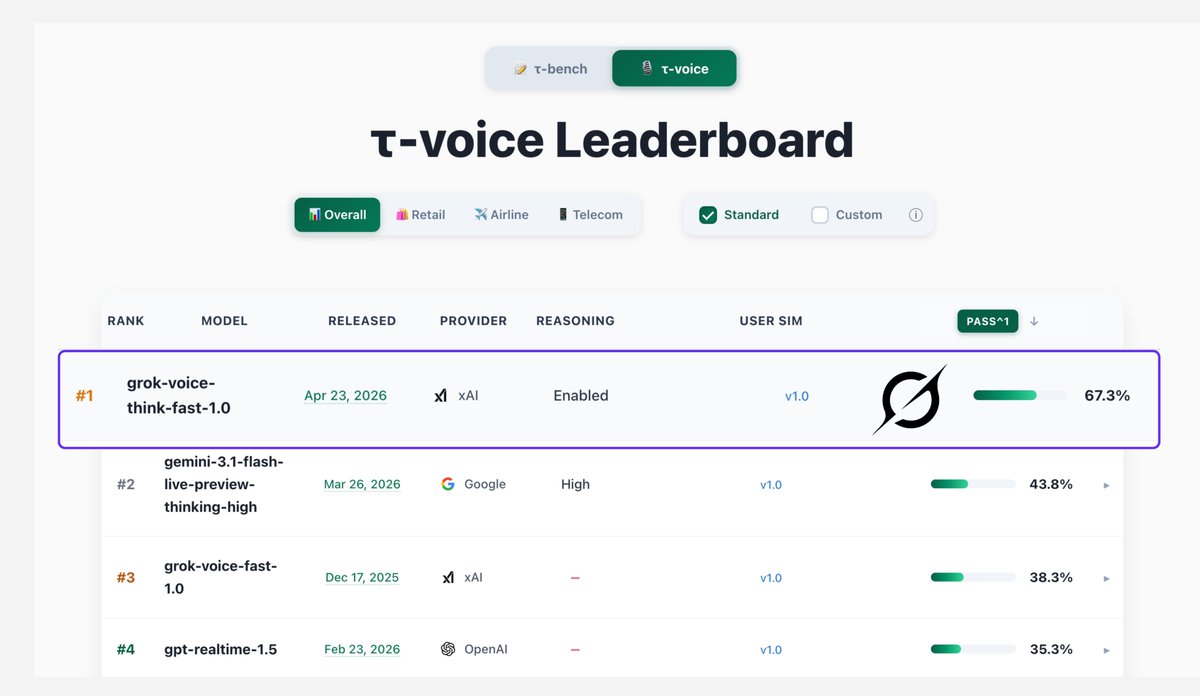
@XFreeze 报告(341 次点赞,2.6M 次浏览),Grok Voice 在 tau-voice Bench 上得分 67.3%,而 Gemini 为 43.8%,GPT Realtime 为 35.3%。该基准排名的是实时推理语音智能体。
@Saboo_Shubham_ 构建(27 次点赞,34 次收藏)了一个开源保险理赔语音 AI 智能体,使用 Gemini 3.1 Flash Live + Google ADK,能填写受理表、提取理赔详情,并实时转给理赔员。
讨论要点: @EloPhanto 提出了关键挑战:“对于理赔智能体,难点不是 demo 式填表——而是交接契约。什么置信阈值转给理赔员、哪些字段会阻止提交,以及智能体如何解释不确定性,都比语音层更重要。”
与前日对比: 5 月 1 日出现了 ElevenLabs 语音 skills。5 月 2 日同时展示了基准格局(Grok 领先)和实际语音智能体部署(保险理赔),讨论则暴露出语音界面只是基本能力,业务逻辑层才是真正挑战。
1.6 多智能体金融走向主流 🡕¶
@gusik4ever 发布(33 次点赞,20 次收藏)了本周增长最快的 GitHub 金融 repo:
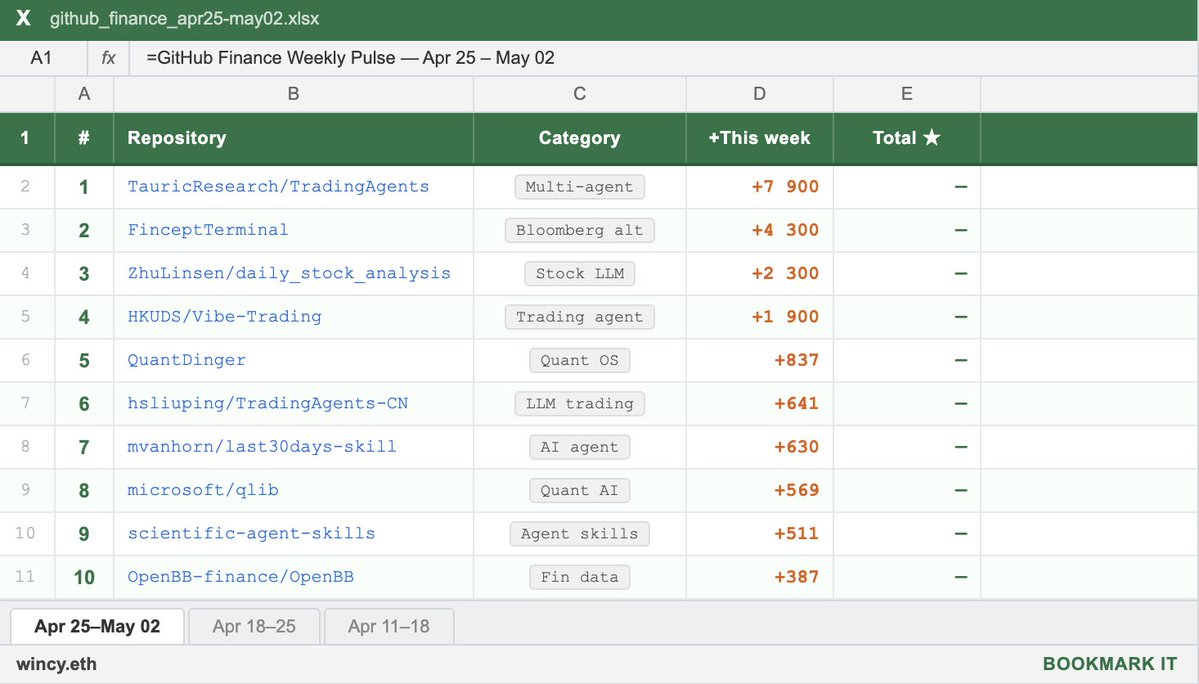
TradingAgents(+7,900 星标)位居第一,这是 UCLA/MIT 的多智能体 LLM 交易框架,包含基本面分析师、情绪分析师、技术分析师和风控经理角色,并支持 DeepSeek V4 thinking-mode。FinceptTerminal(+4,300 星标)提供开源 Bloomberg 替代品,包含 37 个 Buffett/Munger/Lynch/Graham 风格的 AI 智能体。
与前日对比: 5 月 1 日提到 TradingAgents 为 +1.5K stars,并有批评者质疑“智能体编排是否能带来 edge”。5 月 2 日,star 增长加速到 5 倍(+7.9K),说明这种怀疑并未压低兴趣。
2. 令人困扰的问题¶
运行框架知识衰减得比学习速度更快 -- 严重程度:高¶
@drummatick 表达(19 次点赞):“AI 工程已经熟透了,我读一篇 2 个月前关于运行框架的博客,都觉得它已经过时。” @DamiDefi 量化了这种衰减:“智能体领域每个季度都会变化。你优化过的基准已经被刷穿。你掌握的框架已经成了遗产。” 运行框架知识生产和实践者吸收之间的差距正在扩大。多位教育者同日发布定义性内容,说明这个领域的词汇现在才开始稳定。
智能体 trace 会泄露一切 -- 严重程度:High¶
@MaziyarPanahi 记录(40 次点赞,32 次收藏):“智能体执行轨迹会泄露一切。邮件、API keys、患者 ID、支持工单、事故日志。” 智能体执行轨迹正在成为可共享产物(用于评估、bug report、支持交接),但其中包含敏感数据。他的 openmed v1.3.0 会在分享前本地 mask/fake 字段。@ewhauser 指出了缺口:医疗公司要采用这些模型,需要“expert determination method”认证。
编排仍然需要自己构建 -- 严重程度:Medium¶
@RhysSullivan 发布(67 次点赞,92 次收藏)了一份详细的“理想智能体工作流”规格,引用 Symphony、Diffity、Warden、Linear 和 Graphite——这些都是独立工具,没有一个产品能整合起来。@ianlapham 建议:“为你的项目构建一个专用运行框架就好。” 前一天 @davidfowl 的挫败感(“我们现在都在做这件事吗?”)仍在延续——Flue 已经存在,但还早期,实践者仍默认采用定制设置。
3. 人们期望的功能¶
真正会学习的智能体记忆¶
“Contextual Agentic Memory”论文(source)认为,当前记忆系统(向量库、RAG、scratchpad)做的是查找,不是真正记忆。它们在新任务上面临“可证明的泛化上限”。实践者想要的是:能把抽象规则应用到从未见过的输入上、从而产生泛化的记忆,而不只是检索相似案例。来自 @DhravyaShah 的 SMFS 是一种尝试,优化成本/延迟问题;来自 @Unibase_AI 的 Membase 则瞄准协作/共享状态问题。
紧迫性:High -- 机会:基础设施
集成式智能体开发工作流¶
@RhysSullivan(92 次收藏)详细描述了完整愿望:能把项目拆成 Linear 工单的技能,展示运行中任务和 diff 的编排器,本地 PR 审查器负责细化,强制执行反模式约束,在编排器、Linear 和 GitHub 之间建立反向链接,并通过 Graphite 做 stacked diffs。核心要求是:“你可以停止盯着智能体运行。” 现有产品没有一个能端到端交付这些能力。
紧迫性:High -- 机会:产品
PII 安全的智能体 trace 共享¶
@MaziyarPanahi(32 次收藏)为医疗领域发布了 openmed,但需求是普遍的:智能体执行轨迹正在成为调试、评估和协作的主要产物,却包含凭据和 PII。@TommyFalkowski 提议:“一个本地 key value store,这样你可以在导回时 unfake 条目。” 完整方案需要导出时 mask/fake,导入时 unfake,并获得受监管行业认证。
紧迫性:Medium -- 机会:工具
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Flue | 智能体运行框架 | (+) | 首个运行框架;运行时无关;虚拟和容器沙箱;TypeScript | 实验性;API 可能变化 |
| LangChain create_agent / Deep Agents | 智能体框架 | (+) | 可扩展原语;subagents、skills、memory、hooks;开源 | 生产使用需要大量扩展 |
| AWS Strands Agent SDK v1.0 | Agent SDK | (+) | Zod schemas;streaming;MCP;内置 OpenTelemetry;通过配置切换 provider | 仅 TypeScript;新 |
| Google ADK + Gemini Enterprise | 智能体平台 | (+) | 长运行智能体;Inbox 指挥中心;LLM-as-a-judge anomaly detection | GCP 专用 |
| GBrain | 个人智能体大脑 | (+) | 自连线图;17K+ 页面;混合搜索;P@5 49%;34 个技能;评估系统 | 单用户设计;需要智能体平台 |
| Hermes Agent v0.12 | 编程/通用智能体 | (+) | Curator 每 7 天自动修剪/评分技能;通过 agent_control PR 支持多智能体 | 社区驱动;Hermes 生态 |
| OpenMed v1.3.0 | 智能体 trace 隐私 | (+) | 共享 trace 前本地 mask/fake PII;已有医疗使用确认 | 企业采用需要认证 |
| AutoSkills | 技能安装器 | (+) | 一条命令;检测技术栈;从 skills.sh 安装匹配技能 | 早期;依赖 skills.sh 目录 |
| SMFS | 智能体记忆 | (+) | 可挂载抽象;同步索引;优化 token 和搜索延迟 | 新;尚未在规模上证明 |
| Grok Voice | 语音智能体 | (+) | tau-voice Bench 67.3%;大幅领先竞争者 | 仅限 xAI 平台 |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| GBrain | @garrytan | 带自连线知识图谱和 34 个技能的个人 AI 大脑 | 个人智能体缺少结构化记忆 | OpenClaw/Hermes, PGLite, graph DB | Shipped (v0.25) | post, GitHub |
| Voice Insurance Claims Agent | @Saboo_Shubham_ | 面向保险受理、转给理赔员的语音 AI | 手工理赔处理 | Gemini 3.1 Flash Live, Google ADK | Shipped (OSS) | post |
| Bug Hunter v3 | @VivekIntel | 采用 Hunter/Skeptic/Referee pipeline 的对抗式代码审查 | AI 安全扫描误报 | Multi-agent, CVSS, CWE/STRIDE | Shipped | post |
| Watchtower | @VivekIntel | 带 Planner/Worker/Analyst 和 20+ 工具的 AI 渗透测试 | 人工渗透测试 | Multi-agent, SQLite, PDF reports | Shipped | post |
| SMFS | @DhravyaShah | 带同步索引的可挂载文件系统抽象,用于智能体记忆 | 文件系统记忆在规模上失效 | Custom FS, indexer | Alpha | post |
| open-slide | @1weiho | 为智能体构建的幻灯片框架——从提示词到精美 deck | 手工制作幻灯片 | CLI, agent-native | Shipped | post |
| Pi-Daytona Extension | @richardanaya | 用 Daytona 沙箱访问替换 Pi Coding Agent 文件工具 | 智能体文件系统访问不安全 | Pi agent, Daytona | Shipped | post |
| Hermes agent_control | @DODOREACH | 基于 ACP 的多智能体编排,用于持久 Hermes profiles | 一次性 subagents 无法持久化 | Hermes Agent, ACP | PR open | post |
| Diff Viewer | @jeetnirnejak | 用于审查编程智能体改动的组件,带动画 | 审查智能体输出缺少打磨 | Figma, Motion | Demo | post |

6. 新动态与亮点¶
GBrain:YC 总裁发布带基准图谱的个人智能体大脑¶
@garrytan(YC President/CEO)开源(44 次点赞,39 次收藏)了 GBrain——他的个人智能体大脑,支撑 17,888 页、4,383 人、723 家公司的自连线知识图谱。它用 12 天构建,包含 34 个技能,能自主运行 21 个 cron job,摄取会议、邮件、推文和语音通话。基准结果为 P@5 49.1%、R@5 97.9%——比禁用图谱和 BM25+vector 基线高 31+ 个点。这个智能体会在夜间维护并丰富知识图谱。
信号强度:[+++]
编程智能体 AlphaZero 基准确立新评估范式¶
一篇新论文(arXiv:2604.25067,UChicago)提出要求编程智能体自主重建著名 ML 突破来评估它们。Claude Opus 4.7 在消费级硬件上用 3 小时复现了 Connect Four 的 AlphaZero 自博弈,8 局赢 Pascal Pons solver 7 局。其他前沿智能体没有一个超过 2/8。这把评估从“能否 patch 代码?”转向“能否端到端构建非平凡 ML 系统?”
信号强度:[++]
“Memory is a Memo”论文挑战智能体记忆基础¶
来自 CUHK/Zhejiang 的一篇论文(arXiv:2604.27707)认为,当前所有智能体记忆系统(向量库、RAG、scratchpad)做的都是查找,不是真正记忆。它借鉴 Complementary Learning Systems 理论,指出检索式智能体存在可证明的泛化上限,并在结构上容易遭受持久记忆投毒。论文呼吁把快速 hippocampal storage 与缓慢 neocortical weight consolidation 配对。
信号强度:[++]
AWS 发布完整 Agent Harness SDK v1.0¶
@awsdevelopers 发布(38 次点赞,15 次收藏)了他们的 TypeScript 智能体 SDK 1.0 版本,内置 Zod schemas、流式处理、MCP 支持、多智能体编排、会话持久化和 OpenTelemetry。提供商(Bedrock、OpenAI、Anthropic、Gemini)可通过一次配置变更切换。

信号强度:[+]
Google 发布 Agent Anomaly Detection¶
@GoogleCloudTech 宣布(61 次点赞,15 次收藏)Gemini Enterprise Agent Platform 中的 Agent Anomaly Detection,使用统计模型和 LLM-as-a-judge 框架实时标记异常推理。这代表从“模型安全”转向“智能体治理”——监控运行时行为,而不只是训练时对齐。
信号强度:[+]
7. 机会在哪里¶
[+++] 个人智能体大脑基础设施 -- @garrytan 展示了价值(17K 页面、21 个 cron job、量化检索质量),但他的设置需要相当高的技术能力。这个模式——智能体摄取所有个人数据,构建知识图谱,夜间运行维护,并用图谱增强检索回答问题——可复现,但还没有为非技术用户产品化。前一天 @thegreatola 的“5-15 美元/月个人智能体”模式是预算版;GBrain 是高级版。两者之间的空白就是产品机会。
[+++] 智能体执行轨迹隐私与 PII 管理 -- 智能体执行轨迹正在成为主要协作产物(评估、调试、交接),却会泄露凭据和 PII。@MaziyarPanahi 为医疗领域发布 openmed;通用方案(导出时 mask,导入时 unfake,并获得受监管行业认证)尚不存在。随着执行轨迹变得可共享,每个智能体平台都需要这一层。
[++] 集成式智能体开发工作流 -- @RhysSullivan(92 次收藏)列出了完整愿望清单:工单拆解、编排器可视化、本地审查、反模式约束、stacked diffs。没有产品能端到端交付。Symphony、Diffity、Warden、Linear 和 Graphite 都独立存在,但需要手工粘合。第一个把这些整合成单一智能体开发流程的产品,会抓住想“停止盯着智能体运行”的开发者。
[++] 超越检索的真正智能体记忆 -- “Memo, Not True Memory”论文和 SMFS/Membase 发布确认,当前基于检索的记忆会遇到上限。机会在于能泛化的记忆基础设施(权重巩固、从经验中学习),而不只是回忆。这仍处于研究阶段,但来自多个独立团队的需求信号很清楚。
[+] 智能体安全工具(对抗式验证) -- Bug Hunter 的 Hunter/Skeptic/Referee 模式和 Watchtower 的 Planner/Worker/Analyst 都展示了安全领域的多智能体方法。共同洞察是:单个智能体无法可靠地自我验证。对抗式多智能体安全扫描正在成为一个新类别,并已有实践者需求。
8. 要点总结¶
-
一个单人代理公司用 5 台 Mac Mini 运行专门化 AI 智能体,声称以每月 115 美元计算成本获得 34k 美元/月收入,生成了当天最高互动(74K 浏览、569 次收藏),展示了运行框架工程的经济潜力。 该设置通过专属 CLAUDE.md 文件严格分离角色——架构师、程序员、审查员、测试员、运维——并通过共享任务队列沟通。(source)
-
运行框架工程词汇在一天内标准化,Matt Pocock 定义了 Model/Harness/Environment/Agent,多位教育者同时发布定义性内容,说明这个领域已经进入“命名事物”阶段。 这紧随 5 月 1 日的经验验证,表明这门学科已准备好进入正式文档和课程体系。(source)
-
一篇新论文认为,当前所有智能体记忆(向量库、RAG、scratchpad)做的都是查找而非记忆,存在可证明的泛化上限;与此同时,SMFS、Membase、GBrain 三个独立项目发布了相互竞争的记忆基础设施。 研究批判与产品发布共同收敛,表明记忆工程正在从一般智能体工作中分离出来,成为独立基础设施类别。(source, source)
-
Claude Opus 4.7 在消费级硬件上用 3 小时从零构建 AlphaZero 自博弈管线,并在 8 局中赢 Pascal Pons solver 7 局,确立了一种新基准范式:用端到端 ML 系统构建来评估编程智能体,而不是只看 patch。 其他前沿智能体没有一个超过 2/8,显示研究自主性层面存在显著能力差距。(source)
-
Garry Tan(YC President)开源 GBrain:他的个人智能体大脑包含 17,888 页和自连线知识图谱,P@5 达到 49.1%,比禁用图谱的基线高 31+ 个点,证明个人智能体基础设施已经在量化指标上优于扁平检索。 21 个 cron job 会自主运行,摄取并维护图谱。(source)
-
AWS 发布内置 OpenTelemetry 的 Strands Agent SDK v1.0,Grok Voice 在 tau-voice Bench 上以 67.3% 领先 Gemini 的 43.8%,Google 推出 Agent Anomaly Detection,这些共同说明智能体基础设施已进入“无聊管道”阶段,可观测性、治理和基准测试比模型能力更重要。 (source, source, source)