Twitter AI Agent - 2026-05-09¶
1. What People Are Talking About¶
1.1 The control plane around the agent is becoming the product 🡕¶
The strongest theme today is that AI-agent differentiation is moving away from raw model choice and toward the layer that wraps the model. Roughly a dozen high-signal posts describe the real moat as harnesses, skill libraries, observability dashboards, trace formats, and review queues that make agents easier to steer, audit, and reuse.
@AMerchantmoh argued that developers are over-rotating on model switching and multi-agent setups when the real need is “proper constraint topology,” context engineering, prompt engineering, and verification. @asmah2107 made almost the same point in a calmer register, saying a mediocre model with validation, memory, and strict tool access will beat a smarter model without guardrails.
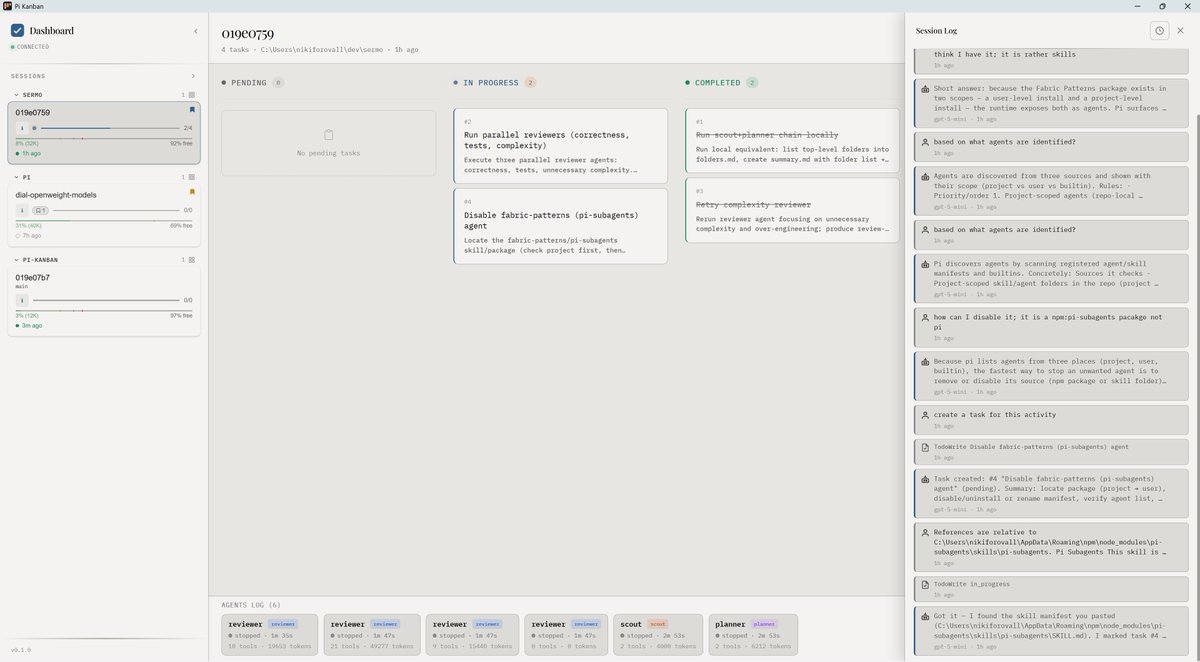
@nikiforovall showed what that looks like in product form with pi-kanban, a workspace for the pi coding agent that surfaces sessions, todos, subagents, and pinned context in one dashboard. The linked blog post says the tool watches agent session files in real time, while the public repo describes it as a web dashboard for sessions, todos, and observability rather than another agent runtime.
@MelkeyDev introduced agent-tail.nvim as a Neovim review queue for Claude Code edits, and the public repo says it captures per-event diffs without git, a daemon, or a watcher. @tom_doerr pointed to the awesome-claude-skills repo, while @Voxyz_ai shared a GitHub Trending screenshot with ruflo at the top. These are all different answers to the same problem: teams want reusable skills, review surfaces, and orchestration layers around the agent, not just a better base model.
Discussion insight: @manthanguptaa summarized research from EntireHQ saying nearly half of agent tool calls are search-related, and that better ranked retrieval matters more than raw grep speed. The practical debate is shifting from “which model?” to “how is context assembled, ranked, traced, and reviewed?”
Comparison to prior day: May 8 argued that users still want a simple chat surface while the real leverage hides in context engineering. May 9 makes that hidden layer visible as dashboards, hooks, trace specs, and skill registries.
1.2 Memory and self-improving skills are becoming the real differentiator 🡕¶
The second strong theme is that memory is no longer a nice-to-have. It is becoming the main test people use to decide whether an agent feels usable after the first few days.
@hosseeb said Hermes Agent feels much more adaptive across sessions than OpenClaw, which “felt like it had dementia.” The replies sharpened why that matters: one user said continuity across sessions makes the product feel like a different class of experience, and another said session memory is the thing that decides which agents people keep using past day three.
@banx0isme offered the most concrete self-improvement example in the dataset. Over 14 days, a Hermes-based Polymarket agent rewrote eight skill files in plain English, which the author says cut weekly alerts from about 22 to 17 while raising the number worth reading from about 8 to 13. The important detail is not just that the agent improved, but that the improvement lived in editable skill files instead of a redeploy pipeline.

@om_patel5 showed the UI pressure this creates from another angle with Pokegents, a Pokemon-styled workspace built because managing many Claude and Codex sessions across tmux panes had become frustrating. The post says the builder added persistent agent identities, session cloning, MCP messaging, and a local orchestration server, which is the same pattern as pi-kanban and agent-tail: builders are wrapping agents in continuity and supervision surfaces.
Discussion insight: Across the memory-related threads, the recurring language is not about intelligence gains. It is about less babysitting, fewer false positives, and agents that keep useful state instead of forcing the user to re-explain everything.
Comparison to prior day: May 8 treated persistent memory as an attractive design direction for local agents. May 9 turns it into a direct switching reason, a concrete quality metric, and a source of measurable workflow gains.
1.3 Voice is being treated as the next surface, not a separate agent category 🡕¶
Voice emerged as the clearest new interface theme today. The interesting part is not “AI can talk,” but that builders increasingly treat voice as a thin layer around an agent that already works in chat.
@zarazhangrui built a YouTube realtime copilot browser extension on OpenAI’s realtime 2 API. The agent watches the video with the user, answers what was just said through realtime voice chat, and, according to the post, can separate the YouTube audio stream from the user’s own voice so the video is not treated as a command source.
@aiDotEngineer framed the broader pattern explicitly: 2025 was the year products added chat agents, and voice is the obvious next move because it is faster, more accessible, and reaches surfaces chat does not. The accompanying slide shows an ElevenLabs stack where turn taking, speech-to-text, text-to-speech, and interruption handling wrap an existing agent and its integrations rather than replacing the core logic.

The product wish is already clear in user language. @VraserX said the upgrade they want most is ChatGPT with voice plus “real agent mode” that can browse, control the computer, manage files, and actually complete tasks.
Discussion insight: Replies to the realtime and voice-layer posts focus on latency, auto-pause, interruption quality, and tool use. The demand is not for a nicer chatbot voice; it is for a spoken interface to agents that already know how to act.
Comparison to prior day: May 8 had little voice-specific evidence. May 9 turns voice into a coherent upgrade path for already-working agents rather than a separate novelty category.
1.4 Web3 agent builders are assembling identity, payment, and execution rails in public 🡕¶
The noisiest cluster today is around web3 and crypto agents. Much of it is promotional, but the repeated components are strikingly consistent: agent identity, reputation, sponsorship, machine payments, and guarded execution.
@ABWeb3_ described heyAura as a system for moving from manual DeFi research into automatic execution, with claims of 17K+ monthly users and $500M+ analyzed wallet value. The attached architecture diagram shows onchain, market, opportunity, and real-time-intelligence inputs feeding a context layer, reasoning engine, and execution outputs for yield, airdrops, portfolio actions, and risk control.

@saidinfra listed what it says is already live on SAID: 3,000+ verified agents, stake-and-slash economic security, Merkle-anchored proof of behavior, x402 payments, and cross-chain A2A messaging. @Crypto_Jayone framed the same layer as “Know Your Agent,” with an ERC-8004 stack built from identity registry, reputation registry, and sponsor link. @mpptestkit added the payment side with a roadmap that already includes shipped TypeScript, Python, and Go SDKs plus AUTON beta.
Discussion insight: Unlike the coding-agent tooling threads, these replies mostly amplify rather than challenge the claims. That is a signal in itself: the architectural direction is specific, but the public scrutiny around real deployment quality is still relatively thin.
Comparison to prior day: May 8 elevated marketplaces and trust as emerging layers. May 9 decomposes that story into explicit rails: identity, sponsorship, machine payments, isolated execution, and autonomous portfolio actions.
2. What Frustrates People¶
Poor structure creates tool thrash¶
The loudest frustration is that people keep treating model switching, prompt churn, and multi-agent sprawl as substitutes for better system design. @AMerchantmoh says the real fix is constraint topology, context engineering, and verification rather than hopping between LLMs, while @asmah2107 says the harness is the steering wheel and brakes, not an optional add-on. @manthanguptaa adds that retrieval quality, not just search speed, is the real bottleneck in coding agents. Severity: High. The workaround today is to build stronger harnesses and ranked retrieval layers; this looks worth building for directly.
Session continuity still breaks too easily¶
The memory complaint is blunt and repeated. @hosseeb said OpenClaw “felt like it had dementia,” and the replies argue that continuity across sessions is what decides whether an agent survives past the novelty phase. @banx0isme shows the opposite case: a Hermes-based workflow improved because the agent could keep rewriting skill files instead of resetting the learning loop. Severity: High. People cope with persistent-memory agents, skill files, and dashboards such as pi-kanban, but the pain is still active and directly buildable against.
Too many lucrative workflows still begin as tab hell¶
Some of the clearest pain comes from highly repetitive operating loops. @mikefutia described agency SEO as “open 5 Ahrefs tabs, export 5 CSVs, paste into 5 Google Docs,” then built an agent to run the loop inside Claude Code; @ABWeb3_ makes the same complaint in DeFi terms, with users still tracking wallets, watching CT calls, and bridging funds manually. Severity: High for the people doing this work every week. The workaround is custom vertical agents tied to narrow data sources, which makes this another strong direct opportunity.
Trust, authorization, and identity defaults are still weak¶
The security complaints are getting more specific. @HGenng51023 says the blocker to large-scale deployment is authorization, not raw model capability, and the attached SUDP benchmark explicitly compares secret-handling approaches such as MCP Authorization against stronger delegation schemes. In parallel, @saidinfra and @Crypto_Jayone are compensating with verified agents, proofs, sponsor links, and reputation layers. Severity: High. The current coping strategy is to bolt on proofs, identity, and extra validation layers after the fact, which makes this worth building for directly.
3. What People Wish Existed¶
Automatic skill generation and evaluation loops¶
The clearest “someone should build this” post comes from @ZypherHQ, who asks whether an open-source tool should generate stronger prompts, skills, and agent files automatically for specific tasks. The demand looks practical rather than aspirational because @banx0isme shows how much value a manual skill-rewrite loop can already create when it cuts false positives and improves alert quality. Opportunity: direct.
Shared workspaces for supervising many agents at once¶
pi-kanban, agent-tail.nvim, and Pokegents all point to the same missing layer: a durable workspace for sessions, diffs, todos, subagents, and pinned context. @bibryam pushes that further with Agent Trace, an open specification for recording AI contributions in version-controlled codebases. Opportunity: direct.
Voice-first agents that can actually use tools¶
The voice request is not “make the chatbot speak.” @VraserX wants voice plus browsing, computer control, and file management in one flow, while @aiDotEngineer argues teams with working chat agents are already most of the way to that outcome. @zarazhangrui provides the strongest proof-of-concept with a realtime YouTube copilot. Opportunity: direct.
Identity, sponsorship, and machine-payment rails¶
The web3 agent cluster is effectively a list of missing infrastructure. @saidinfra is talking about verified agents, proofs, x402 payments, and cross-chain A2A messaging; @Crypto_Jayone frames the missing piece as KYA identity; @mpptestkit is building the payment developer layer itself. This looks competitive rather than greenfield, but the need is explicit. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Hermes Agent | Open-source agent runtime | (+) | Strong continuity across sessions, self-improving skills, broad tool coverage | Public evidence today is still mostly user testimony rather than hard operational metrics |
| OpenClaw | Open-source coding agent | (+/-) | Large ecosystem and integrations | Repeated complaints about weaker memory continuity and more babysitting |
| Claude Code | Coding agent substrate | (+) | Strong enough to support vertical agents, skill packs, and review tooling on top | Users increasingly need third-party dashboards, hooks, and skill systems to manage complexity |
| pi-kanban | Observability workspace | (+) | Sessions, todos, subagents, and pinned context in one place | Read-only and tied to the pi coding agent workflow |
| agent-tail.nvim | Review / audit plugin | (+) | Per-event diffs, no git dependency, lightweight Neovim workflow | Experimental, Claude-only, and session-scoped |
| awesome-claude-skills | Skill library | (+) | Reusable verified skills across debugging, testing, architecture, docs, and security | Curated pack rather than automatic skill generation or safety enforcement |
| Agent Trace | Trace / attribution spec | (+) | Makes AI contributions auditable across storage, IDE, analytics, and logging | Still a proposal-level spec rather than an adopted standard |
| Voice Engine SDK / voice wrappers | Voice agent layer | (+) | Adds speech, turn taking, and interruption handling without rewriting the agent core | Latency, auto-pause, and tool-use UX remain unresolved |
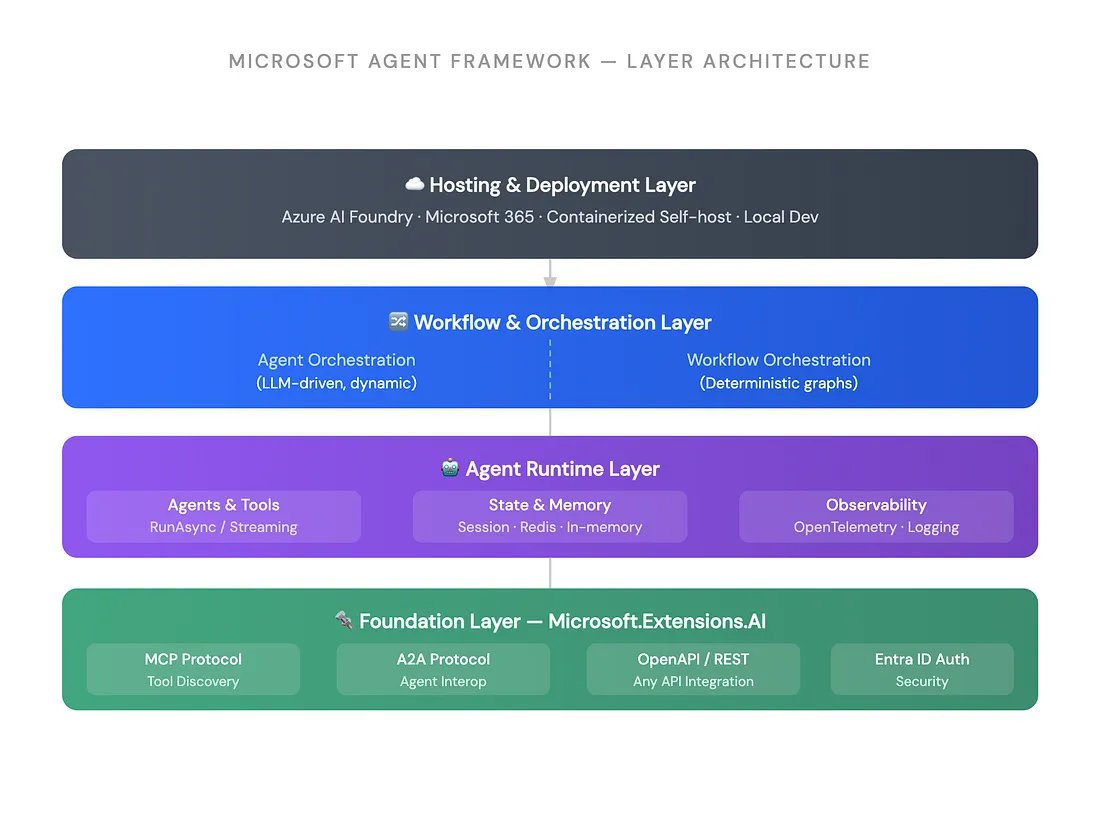
| Microsoft Agent Framework | Enterprise agent framework | (+) | Clear reference architecture with orchestration, runtime, MCP, A2A, and telemetry layers | Evidence today is architectural rather than deployment-heavy |
| OpenHarness | Open-source harness framework | (+) | MCP, multi-agent coordination, persistent memory, validation-oriented design | Very early project with little traction evidence so far |
| SAID / KYA identity rails | Identity / trust infrastructure | (+/-) | Verified agents, proofs, sponsor links, reputation, payment hooks | Still fragmented and heavily promotional in today’s evidence |
| MPP TestKit | Machine payments | (+) | Shipped SDKs and a roadmap aimed squarely at agent integrations | Early-stage roadmap, unclear real-world adoption outside builder circles |
| heyAura | Autonomous DeFi agent | (+/-) | Moves from recommendation to execution with multi-chain context inputs | Public evidence is product-forward and light on adversarial scrutiny |
Summary: Satisfaction is highest where the tool reduces supervision overhead, which is why Hermes-style continuity gets more praise than raw model capability today. The clearest migration pattern is from bare agents toward wrappers and surfaces: Claude Code gets skill libraries and review tooling layered on top, OpenClaw users are compared directly against Hermes, and chat agents are being wrapped in voice instead of rebuilt. Competitive dynamics are also fragmenting: coding-agent tooling clusters around skills, tracing, review, and observability, while crypto-agent tooling clusters around identity, payments, and guarded execution.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| YouTube realtime copilot | @zarazhangrui | Watches a YouTube video with the user and answers questions through realtime voice chat | Video learning is still pause-search-rewind heavy | Browser extension, OpenAI Realtime 2 API | Alpha | post |
| Claude Code SEO agent | @mikefutia | Runs keyword-gap analysis, competitor analysis, content drafting, and weekly rank tracking inside Claude Code | Agencies repeat the same Ahrefs, CSV, and docs workflow every week | Claude Code, Google Search Console, Apify | Alpha | post |
| pi-kanban | @nikiforovall | Read-only dashboard for sessions, todos, subagents, and pinned context around the pi coding agent | Terminal-only agent work is hard to monitor, resume, and supervise | JavaScript, pi coding agent, file-watching web dashboard | Beta | blog, repo, post |
| agent-tail.nvim | @MelkeyDev | Neovim session review queue that shows per-event diffs for Claude Code edits | Developers need a low-friction way to audit agent changes without extra ceremony | Lua, Neovim, Claude Code hook integration | Alpha | repo, post |
| OpenHarness | @abhishek__AI | Open-source Claude Code-style agent framework with memory and validation layers | Teams want autonomous agent infrastructure without depending on a closed product | Python, MCP, multi-agent coordination, persistent memory | Alpha | repo, post |
| awesome-claude-skills | @tom_doerr / karanb192 | Public collection of verified Claude skills across debugging, testing, docs, and architecture | Users keep reinventing prompt and skill files | Markdown skills for Claude Code, Claude.ai, and API usage | Shipped | repo, post |
| MPP TestKit | @mpptestkit | SDK stack and protocol roadmap for machine payments and agent integrations | Agents need payment primitives, lifecycle callbacks, and integration tooling | TypeScript, Python, Go SDKs, AUTON beta | Beta | post |
| heyAura | @heyaura | Autonomous DeFi execution agent that reasons over wallet, market, and opportunity context | Manual DeFi research and execution is still dashboard-heavy and reactive | Multi-chain data ingestion, context layer, AI reasoning, execution engine | Shipped | quoted post, supporting post |
Most of the builder energy today falls into two buckets. One bucket wraps coding agents with control planes, review surfaces, skill packs, and validation layers: pi-kanban, agent-tail.nvim, OpenHarness, and awesome-claude-skills all exist because base agents are useful enough that supervision and reuse are becoming their own product categories.
The other bucket is vertical execution. The SEO agent and heyAura both start from a workflow with too many tabs, exports, and manual decisions, then compress it into a narrower agent loop with real operating data. The YouTube realtime copilot sits between those buckets: it is a concrete build, but it also points to a broader interface shift toward spoken, contextual agents.
6. New and Notable¶
Authorization is being treated as an agent-systems bottleneck¶
@HGenng51023 posted one of the most substantive low-volume signals in the dataset: a four-image thread around SUDP, a secret-use delegation protocol for agentic systems. The images include a paper screenshot, a formal requester-authorizer-custodian flow, a security-model comparison, and a benchmark table that scores SUDP Pro at 8/8 while showing much weaker results for several other approaches. That matters because it reframes the scaling problem as authorization and secret handling, not just model quality.

Microsoft’s four-layer agent stack is a useful public reference model¶
@adnan_hashmi shared a Microsoft Agent Framework diagram that lays out hosting and deployment, orchestration, runtime, and foundation layers in one picture. The image is notable because it places MCP, A2A, OpenAPI/REST, Entra ID, Redis-backed session memory, and OpenTelemetry in the same stack, which makes it the clearest enterprise reference architecture in today’s dataset.
Agent Trace suggests version control is preparing for AI provenance¶
@bibryam proposed Agent Trace as “an open specification for recording AI contributions alongside human authorship in version-controlled codebases.” The attached diagram routes agent traces into storage, IDE or CLI views, analytics, and audit logging, which is notable because it treats attribution as infrastructure instead of an afterthought.
7. Where the Opportunities Are¶
[+++] Coding-agent control planes and review surfaces — pi-kanban, agent-tail.nvim, Pokegents, Agent Trace, and the broader harness-engineering discussion all point to the same gap: once agents become useful, teams need supervision, replay, traceability, and reusable workspace state around them. This is the strongest opportunity because the pain is explicit and multiple builders are independently converging on the same layer.
[+++] Trust, authorization, and payment rails for autonomous agents — SUDP, SAID, KYA, and MPP TestKit all attack different parts of the same missing stack: secret delegation, verified identity, sponsor and reputation links, and machine payments. The evidence spans research, architecture diagrams, and product roadmaps, which makes this more than a single-thread narrative.
[++] Automated skill generation and self-improvement tooling — ZypherHQ’s request for auto-generated skill files, banx0isme’s measurable skill-rewrite loop, OpenHarness, and awesome-claude-skills all suggest a market for tools that create, test, rank, and maintain skills automatically. The need is direct, but the market may get crowded quickly.
[++] Voice wrappers for already-working chat agents — The YouTube realtime copilot, ElevenLabs voice-layer framing, and direct user demand for voice plus real agent mode all suggest that many teams will not rebuild their agents from scratch. They will add voice as an interface layer. That makes integration and latency tooling more attractive than greenfield “voice agents” alone.
[+] Vertical agents that replace recurring operator loops — The SEO agent and heyAura show a repeatable pattern: take a profitable but tedious workflow with too many tabs and decisions, then compress it into a narrow agent loop. The upside is clear, but today’s evidence is still builder-led and sometimes promotional, so this looks emerging rather than fully validated.
8. Takeaways¶
- The differentiator is moving from the model to the control layer around the model. Constraint topology, harness engineering, dashboards, review queues, and skill registries dominate the strongest posts today, which is a materially more operational discussion than simple model comparison. (constraint topology, pi-kanban)
- Memory continuity is the clearest user-visible quality test for agents right now. Hermes-vs-OpenClaw discussion centers on whether the system adapts across sessions, and the banx0isme thread shows that editable skill memory can produce measurable workflow gains. (Hermes vs OpenClaw, self-rewriting skills)
- Voice is being treated as an interface upgrade for agents that already work, not as a separate stack. The realtime YouTube copilot and the ElevenLabs voice-layer framing both assume the agent logic already exists and that the next step is wrapping it in speech, turn taking, and live context. (realtime copilot, voice layer)
- The crypto-agent stack is standardizing around identity, payments, and guarded execution, but most public evidence is still architectural. SAID, KYA, MPP TestKit, and SUDP all describe real stack components, yet the conversation still contains more diagrams and roadmaps than long-term operational proof. (SAID, KYA, MPP TestKit, SUDP)