Twitter AI 智能体 - 2026-05-09¶
1. 人们在讨论什么¶
1.1 围绕智能体的控制层正在成为产品 🡕¶
今天最强的主题是,AI 智能体的差异化正在从底层模型选择,转向包裹模型的那一层。大约十几条高信号推文都在说,真正的护城河是测试框架、技能库、可观测性仪表盘、trace 格式和审查队列;这些东西让智能体更容易被引导、审计和复用。
@AMerchantmoh 认为,开发者把太多注意力放在切换模型和多智能体搭建上,而真正需要的是“合适的约束拓扑”、上下文工程、提示工程和验证。@asmah2107 表达 的几乎是同一个观点,只是语气更平和:一个普通模型,如果配上验证、记忆和严格的工具访问控制,也能胜过一个更聪明、却没有安全护栏的模型。
@nikiforovall 展示 了这种思路在产品中的样子:pi-kanban,一个为 pi 编程智能体打造的工作区,把会话、待办事项、子智能体和置顶上下文集中到同一个仪表盘里。关联的博客文章称,这个工具会实时监控智能体会话文件;而公开仓库则把它描述为一个面向会话、待办事项和可观测性的 Web 仪表盘,而不是另一个智能体运行时。
@MelkeyDev 发布 了 agent-tail.nvim:它把 Claude Code 的编辑变成一个 Neovim 审查队列;公开仓库称,它无需 Git、守护进程或文件监听器,就能捕获按事件划分的差异。@tom_doerr 提到了 awesome-claude-skills 这个仓库,而 @Voxyz_ai 分享 了一张 GitHub Trending 截图,其中 ruflo 位居榜首。这些都是对同一个问题的不同回答:团队想要的是围绕智能体的可复用技能、审查界面和编排层,而不只是一个更好的基础模型。
讨论要点:@manthanguptaa 总结 了 EntireHQ 的研究:智能体的工具调用里,几乎一半都与搜索有关;比起单纯提升 grep 速度,更重要的是把检索结果排好序。实际争论的焦点正从“用哪个模型?”转向“上下文是如何被组装、排序、追踪和审查的?”
与前日对比:5 月 8 日的讨论认为,用户仍然想要一个简单的聊天界面,而真正的杠杆藏在上下文工程里。到了 5 月 9 日,这个隐藏层已经以仪表盘、hooks、trace 规范和技能注册表的形式变得可见。
1.2 记忆与自我改进技能正在成为真正的差异化因素 🡕¶
第二个强主题是,记忆已经不再是“有最好、没有也行”的功能。它正变成人们判断一个智能体在用了几天后是否还算好用的主要标准。
@hosseeb 表示,Hermes Agent 跨会话的适应性明显强于 OpenClaw,后者“感觉像得了失忆症”。回复进一步点明了这为什么重要:有用户说,跨会话连续性会让产品像是“完全不同等级的体验”;还有人说,会话记忆才是决定用户在第 3 天之后还会不会继续用某个智能体的关键。
@banx0isme 给出 了数据集中最具体的自我改进案例。在 14 天里,一个基于 Hermes 的 Polymarket 智能体用自然语言重写了 8 个技能文件,作者称,这让每周提醒数量从大约 22 条降到 17 条,同时把“值得一读”的提醒从大约 8 条提高到 13 条。关键不只是智能体变好了,而是这种改进存在于可编辑的技能文件里,而不是部署重发的流水线中。

@om_patel5 从另一个角度展示 了这带来的 UI 压力:他构建了 Pokegents,一个 Pokemon 风格的工作区,因为在 tmux pane 里管理大量 Claude 和 Codex 会话已经变得令人沮丧。推文称,构建者加入了持久的智能体身份、会话克隆、MCP 消息传递和本地编排服务器;这与 pi-kanban 和 agent-tail 是同一种模式:构建者正在用连续性和监督界面把智能体包裹起来。
讨论要点:在所有围绕记忆的讨论串里,反复出现的措辞并不是“智能变强了”。大家在意的是更少盯梢、更少误报,以及智能体能保留有用状态,而不是逼着用户把所有事情重新解释一遍。
与前日对比:5 月 8 日还只是把持久记忆视为本地智能体的一个有吸引力的设计方向。到 5 月 9 日,它已经变成直接决定用户切换与否的理由、一个具体的质量指标,以及可量化工作流收益的来源。
1.3 构建者正把语音视为下一层界面,而不是独立的智能体类别 🡕¶
今天最清晰的新界面主题是语音。有意思的点不在于“AI 会说话了”,而在于构建者越来越把语音视为包在一个已经能在聊天里工作的智能体外面的轻薄一层。
@zarazhangrui 做出 了一个基于 OpenAI realtime 2 API 的 YouTube realtime copilot 浏览器扩展。这个智能体会和用户一起看视频,通过实时语音聊天回答刚刚说了什么;按推文描述,它还能把 YouTube 音频流与用户自己的声音分离开,这样视频内容就不会被当作命令来源。
@aiDotEngineer 明确概括 了更大的模式:2025 年是产品加入聊天智能体的一年,而语音显然是下一步,因为它更快、可访问性更强,也能触达聊天触达不到的界面。配图展示了一个 ElevenLabs 技术栈,其中轮次切换、语音转文本、文本转语音和打断处理,都是包在现有智能体及其集成外层的能力,而不是替换核心逻辑。

用户层面的产品诉求也已经非常明确。@VraserX 说,他最想要的升级是带语音的 ChatGPT,再加上“真正的智能体模式”——能浏览网页、控制电脑、管理文件,并且真的把任务做完。
讨论要点:对实时语音层推文的回复,关注点集中在延迟、自动暂停、打断质量和工具使用上。用户要的不是一个声音更好听的聊天机器人,而是一个已经知道如何执行动作的智能体,其上再加一个可说话的界面。
与前日对比:5 月 8 日几乎没有多少关于语音的证据。到了 5 月 9 日,语音已经成了给现有可用智能体升级的一条清晰路径,而不是一个单独的新奇品类。
1.4 Web3 智能体构建者正在公开组装身份、支付与执行轨道 🡕¶
今天最嘈杂的讨论簇集中在 web3 和加密智能体上。其中很多内容带有宣传色彩,但反复出现的组件却高度一致:智能体身份、声誉、赞助、机器支付,以及受保护的执行层。
@ABWeb3_ 将 heyAura 描述为一个把手工 DeFi 研究转成自动执行的系统,并声称其月活用户超过 17K、分析钱包价值超过 $500M。附带的架构图显示,链上、市场、机会和实时情报输入会流入一个上下文层、推理引擎和执行输出层,最终落到收益、空投、投资组合动作和风险控制上。

@saidinfra 列出 了它声称已在 SAID 上线的内容:3,000+ 个已验证智能体、质押惩罚经济安全机制、以 Merkle 锚定的行为证明、x402 支付,以及跨链 A2A 消息传递。@Crypto_Jayone 把 同一层概括为《Know Your Agent》,并提出一个由身份注册表、声誉注册表和赞助链接构成的 ERC-8004 技术栈。@mpptestkit 补上 了支付侧,其路线图已包含已发布的 TypeScript、Python 和 Go SDK,以及 AUTON beta。
讨论要点:不同于围绕编程智能体工具链的讨论串,这里的回复大多是在放大这些说法,而不是质疑它们。这本身就是一个信号:架构方向已经很具体,但围绕真实部署质量的公开审视仍然相对薄弱。
与前日对比:5 月 8 日把市场和信任层抬升为新出现的上层结构。到 5 月 9 日,这个故事已经被拆解成更明确的轨道:身份、赞助、机器支付、隔离执行和自主投资组合操作。
2. 令人困扰的问题¶
糟糕的结构导致工具来回折腾¶
最强烈的不满在于,人们一直把切换模型、不断改提示词和多智能体蔓延,当成更好系统设计的替代品。@AMerchantmoh 说,真正的修复方向是约束拓扑、上下文工程和验证,而不是在不同 LLM 之间来回跳;@asmah2107 则说,测试框架是方向盘和刹车,而不是可选附件。@manthanguptaa 还补充说,真正的编程智能体瓶颈是检索质量,而不只是搜索速度。严重程度:高。当前的权宜方案是构建更强的测试框架和排序检索层;这看起来非常值得直接围绕它做产品。
会话连续性仍然太容易断裂¶
围绕记忆的抱怨既直接又反复出现。@hosseeb 说 OpenClaw“感觉像得了失忆症”,而回复则认为,跨会话连续性才是决定一个智能体能否熬过新鲜感阶段的关键。@banx0isme 展示了相反的情况:一个基于 Hermes 的工作流之所以能持续变好,是因为智能体可以不断重写技能文件,而不是每次都把学习循环重置。严重程度:高。人们现在靠持久记忆智能体、技能文件和像 pi-kanban 这样的仪表盘来应对,但这个痛点依然活跃,而且完全可以直接针对它构建产品。
太多高价值工作流仍然从标签页地狱开始¶
一些最清晰的痛点来自高度重复的操作循环。@mikefutia 把代理机构的 SEO 描述为“打开 5 个 Ahrefs 标签页,导出 5 个 CSV,再粘贴到 5 个 Google Docs 里”,随后构建了一个能在 Claude Code 里跑完整个循环的智能体;@ABWeb3_ 在 DeFi 领域抱怨的是同一类问题:用户仍然要手动追踪钱包、盯着 CT 上的喊单、手动跨链转资金。严重程度:对于每周都要做这类工作的人来说非常高。现在的绕行方案是把定制垂直智能体绑到狭窄的数据源上,这也让它成为另一个很强的直接机会。
信任、授权与身份的默认设置仍然偏弱¶
安全层面的抱怨正在变得更具体。@HGenng51023 说,大规模部署的阻碍不是原始模型能力,而是授权;配图中的 SUDP 基准测试明确比较了不同机密信息处理方式,包括 MCP Authorization 与更强的委托方案。与此同时,@saidinfra 和 @Crypto_Jayone 则用已验证智能体、证明、赞助链接和声誉层来补这个缺口。严重程度:高。当前的应对方式,是在事后再外挂证明、身份和额外验证层;这让它很值得直接围绕它做产品。
3. 人们期望的功能¶
自动生成技能与评估循环¶
最明确的“应该有人来做这个”的推文来自 @ZypherHQ:他们在问,是否应该有一个开源工具,能针对特定任务自动生成更强的提示词、技能和智能体文件。这个需求看起来很务实,而不只是愿景,因为 @banx0isme 已经展示了,手动重写技能的循环只要能减少误报、提高提醒质量,就能创造多大的价值。机会:直接。
用于同时监督多个智能体的共享工作区¶
pi-kanban、agent-tail.nvim 和 Pokegents 都指向同一个缺失层:一个持久工作区,用来承载会话、差异记录、待办事项、子智能体和置顶上下文。@bibryam 用 Agent Trace 把这个方向又往前推了一步:它是一个用于在版本控制代码库中记录 AI 贡献的开放规范。机会:直接。
真正能使用工具的语音优先智能体¶
用户对语音的要求并不是“让聊天机器人开口说话”。@VraserX 想要的是语音加浏览、电脑控制和文件管理,全部在同一个流程里;而 @aiDotEngineer 认为,已经有可用聊天智能体的团队,其实离这个结果只差一步。@zarazhangrui 则用一个 realtime YouTube copilot 给出了最有说服力的概念验证。机会:直接。
身份、赞助和机器支付轨道¶
web3 智能体这一簇讨论,本质上就是一张“缺失基础设施”清单。@saidinfra 在谈已验证智能体、证明、x402 支付和跨链 A2A 消息传递;@Crypto_Jayone 把缺失的部分定义为 KYA 身份;@mpptestkit 则亲自去构建支付开发者层。这看起来更像一个竞争激烈的赛道,而不是一片空白市场,但需求是明确的。机会:竞争型。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Hermes Agent | 开源智能体运行时 | (+) | 跨会话连续性强、技能可自我改进、工具覆盖面广 | 今天公开证据仍主要来自用户证词,而不是硬性的运营指标 |
| OpenClaw | 开源编程智能体 | (+/-) | 生态和集成规模大 | 围绕记忆连续性较弱、需要更多人工盯梢的抱怨反复出现 |
| Claude Code | 编程智能体底座 | (+) | 足够强大,能在其上承载垂直智能体、技能包和审查工具 | 用户越来越需要第三方仪表盘、hooks 和技能系统来管理复杂性 |
| pi-kanban | 可观测性工作区 | (+) | 会话、待办事项、子智能体和置顶上下文集中在一处 | 只读,并且绑定在 pi 编程智能体的工作流上 |
| agent-tail.nvim | 审查 / 审计插件 | (+) | 按事件显示差异,不依赖 Git,适合轻量 Neovim 工作流 | 仍属实验性、仅支持 Claude,且作用域限于单个会话 |
| awesome-claude-skills | 技能库 | (+) | 可复用、已验证的技能覆盖调试、测试、架构、文档和安全 | 更像人工策展技能包,而不是自动技能生成或安全强制执行 |
| Agent Trace | 追踪 / 归因规范 | (+) | 让 AI 贡献能在存储、IDE、分析和日志中被审计 | 目前仍是提案级规范,还不是已被采用的标准 |
| Voice Engine SDK / voice wrappers | 语音智能体层 | (+) | 无需重写智能体核心,就能加入语音、轮次切换和打断处理 | 延迟、自动暂停和工具使用体验仍未解决 |
| Microsoft Agent Framework | 企业级智能体框架 | (+) | 参考架构清晰,涵盖编排、运行时、MCP、A2A 和遥测层 | 今天的证据更多是架构层面的,而不是大量部署案例 |
| OpenHarness | 开源测试框架 | (+) | 支持 MCP、多智能体协同、持久记忆和面向验证的设计 | 项目很早期,目前几乎没有牵引力证据 |
| SAID / KYA identity rails | 身份 / 信任基础设施 | (+/-) | 提供已验证智能体、证明、赞助链接、声誉和支付 hooks | 在今天的证据里仍然比较碎片化,而且宣传味很重 |
| MPP TestKit | 机器支付 | (+) | 已发布 SDK,并有一条明确面向智能体集成的路线图 | 仍处早期,构建者圈子之外的真实采用情况不清楚 |
| heyAura | 自主 DeFi 智能体 | (+/-) | 从推荐推进到执行,并能利用多链上下文输入 | 公开证据更偏产品展示,缺少对抗性审视 |
总结:满意度最高的地方,是工具能切实降低监督开销;这也是为什么今天 Hermes 式连续性比原始模型能力得到更多称赞。最清晰的迁移路径,是从裸智能体走向包裹层和界面层:Claude Code 上叠加了技能库和审查工具,OpenClaw 用户被直接拿来和 Hermes 对比,而聊天智能体也在被包进语音层,而不是推倒重建。竞争格局也在分化:编程智能体工具聚集在技能、追踪、审查和可观测性上,而加密智能体工具则聚集在身份、支付和受保护执行上。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| YouTube realtime copilot | @zarazhangrui | 陪用户一起看 YouTube 视频,并通过实时语音聊天回答问题 | 视频学习仍然高度依赖暂停、搜索和回退 | 浏览器扩展、OpenAI Realtime 2 API | Alpha | 推文 |
| Claude Code SEO agent | @mikefutia | 在 Claude Code 里处理关键词差距分析、竞品分析、内容起草和每周排名跟踪 | 代理机构每周都在重复同样的 Ahrefs、CSV 和文档工作流 | Claude Code、Google Search Console、Apify | Alpha | 推文 |
| pi-kanban | @nikiforovall | 围绕 pi 编程智能体提供只读仪表盘,展示会话、待办事项、子智能体和置顶上下文 | 纯终端里的智能体工作很难监控、恢复和监督 | JavaScript、pi 编程智能体、文件监听式 Web 仪表盘 | Beta | 博客, 仓库, 推文 |
| agent-tail.nvim | @MelkeyDev | 面向 Claude Code 编辑的 Neovim 会话审查队列,可按事件展示 diff | 开发者需要一种低摩擦方式来审计智能体变更,而不想引入额外仪式成本 | Lua、Neovim、Claude Code hook 集成 | Alpha | 仓库, 推文 |
| OpenHarness | @abhishek__AI | 类似 Claude Code 的开源智能体框架,带记忆层和验证层 | 团队想要自主智能体基础设施,而不想依赖封闭产品 | Python、MCP、多智能体协同、持久记忆 | Alpha | 仓库, 推文 |
| awesome-claude-skills | @tom_doerr / karanb192 | 面向调试、测试、文档和架构的公开 Claude 已验证技能集合 | 用户不断重复发明提示词和技能文件 | 面向 Claude Code、Claude.ai 和 API 用法的 Markdown 技能 | 已发布 | 仓库, 推文 |
| MPP TestKit | @mpptestkit | 面向机器支付和智能体集成的 SDK 栈与协议路线图 | 智能体需要支付原语、生命周期回调和集成工具链 | TypeScript、Python、Go SDK、AUTON beta | Beta | 推文 |
| heyAura | @heyaura | 一个能基于钱包、市场和机会上下文自主推理的 DeFi 执行智能体 | 手工 DeFi 研究和执行仍然依赖大量仪表盘,而且偏被动 | 多链数据摄取、上下文层、AI 推理、执行引擎 | 已发布 | 引用推文, 补充推文 |
今天构建者的精力大致落在两个桶里。一个桶,是给编程智能体包上控制层、审查界面、技能包和验证层:pi-kanban、agent-tail.nvim、OpenHarness 和 awesome-claude-skills 之所以存在,都是因为基础智能体已经足够有用,以至于监督和复用正在成为独立的产品类别。
另一个桶,是垂直执行。SEO 智能体和 heyAura 都是从一个拥有太多标签页、导出步骤和手工决策的工作流出发,再把它压缩进一个更窄的智能体循环里。YouTube realtime copilot 处在这两个桶之间:它是一个具体构建,但同时也指向一个更大的界面迁移——朝向可说话、带上下文的智能体。
6. 新动态与亮点¶
授权正在成为智能体系统的瓶颈¶
@HGenng51023 发布 了数据集中最有实质内容、但传播量不高的信号之一:一个围绕 SUDP 的四图讨论串。SUDP 是面向智能体系统的秘密使用委托协议。图片中包括论文截图、正式的请求方-授权方-托管方流程、安全模型对比,以及一张基准测试表:SUDP Pro 得分 8/8,而其他几种方法的结果明显更弱。这很重要,因为它把扩展问题重新定义为授权和机密信息处理,而不只是模型质量。

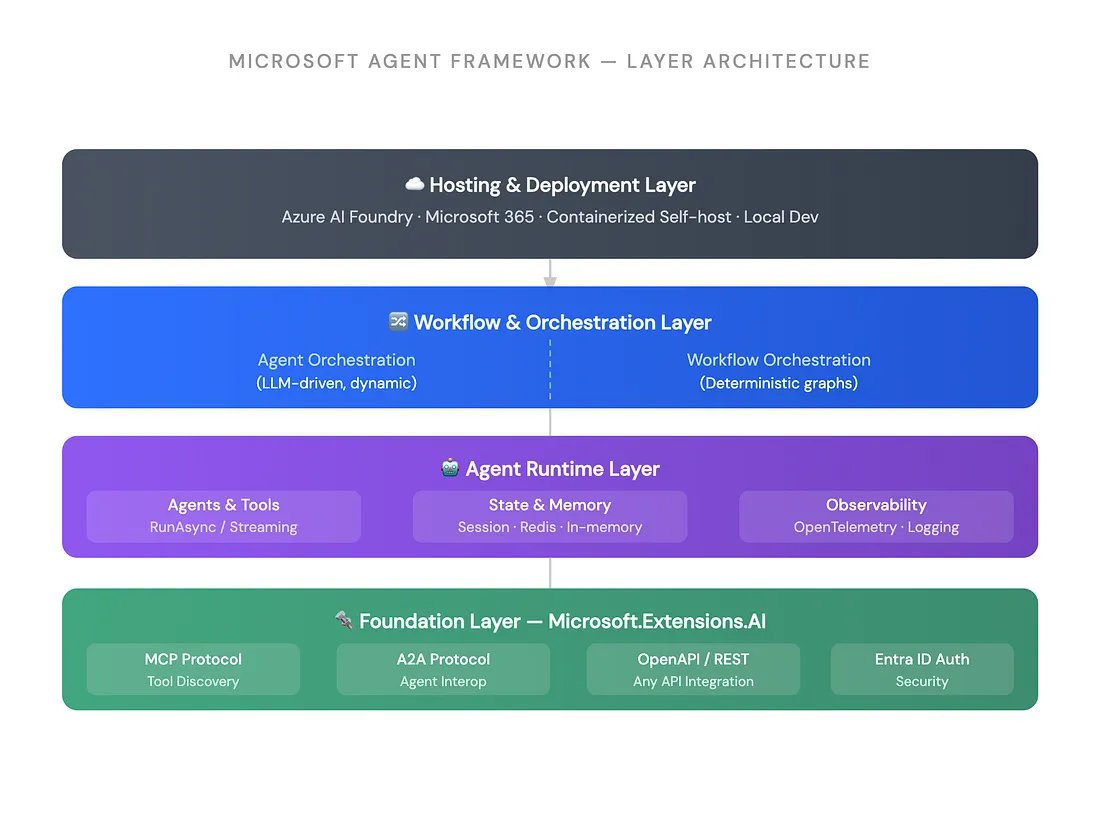
Microsoft 的四层智能体栈是一个有用的公开参考模型¶
@adnan_hashmi 分享 了一张 Microsoft Agent Framework 图,把托管与部署、编排、运行时和基础能力四层放进同一张图里。它之所以值得注意,是因为图里把 MCP、A2A、OpenAPI/REST、Entra ID、基于 Redis 的会话记忆,以及 OpenTelemetry 放进了同一个栈里,这让它成为今天数据集中最清晰的企业级参考架构。
Agent Trace 暗示版本控制正在为 AI 来源追踪做准备¶
@bibryam 提出 了 Agent Trace,称它是“一个开放规范,用于在版本控制代码库中,把 AI 贡献与人类作者信息一起记录下来”。配图把 agent trace 路由到存储、IDE 或 CLI 视图、分析以及审计日志,这之所以值得注意,是因为它把归因当成基础设施,而不是事后补丁。
7. 机会在哪里¶
[+++] 编程智能体控制层与审查界面 —— pi-kanban、agent-tail.nvim、Pokegents、Agent Trace,以及更广泛的测试框架工程讨论,都指向同一个缺口:一旦智能体开始变得有用,团队就需要围绕它们建立监督、回放、可追踪性和可复用的工作区状态。这是当前最强的机会,因为痛点明确,而且多个构建者正在独立收敛到同一层。
[+++] 自主智能体的信任、授权与支付轨道 —— SUDP、SAID、KYA 和 MPP TestKit 分别在补同一套缺失栈的不同部分:机密委托、已验证身份、赞助与声誉链接,以及机器支付。证据横跨研究、架构图和产品路线图,因此这不只是单个讨论串带出的叙事。
[++] 自动技能生成与自我改进工具链 —— ZypherHQ 对自动生成技能文件的需求、banx0isme 可量化的技能重写循环、OpenHarness,以及 awesome-claude-skills,都在暗示一个市场:自动创建、测试、排序并维护技能的工具。需求很直接,但市场可能也会很快拥挤起来。
[++] 面向已可用聊天智能体的语音包裹层 —— YouTube realtime copilot、ElevenLabs 的语音层叙事,以及用户对“语音 + 真正智能体模式”的直接需求,都说明很多团队不会从头重建智能体,而是把语音作为一层界面加上去。因此,比起纯粹从零开始做“语音智能体”,集成能力和延迟工具更有吸引力。
[+] 替代重复操作循环的垂直智能体 —— SEO 智能体和 heyAura 展示了一个可复用模式:找出一个利润可观、但充满标签页和手工决策的繁琐工作流,再把它压缩成一个狭窄的智能体循环。上行空间很明确,但今天的证据仍主要由构建者主导,有时也带宣传色彩,因此它更像正在浮现的机会,而不是已经被充分验证的市场。
8. 要点总结¶
- 差异化焦点正从模型转向模型外的控制层。约束拓扑、测试框架工程、仪表盘、审查队列和技能注册表,占据了今天最强势的讨论;这比单纯比较模型能力,已经明显更偏运营和落地。(约束拓扑, pi-kanban)
- 记忆连续性是当前用户最能直接感知的智能体质量测试。围绕 Hermes 与 OpenClaw 的讨论,核心就在于系统能否跨会话持续适应;而 banx0isme 的讨论串则表明,可编辑的 skill 记忆确实能带来可量化的工作流收益。(Hermes vs OpenClaw, 自我重写技能)
- 构建者正把语音当成对“已经能工作”的智能体的一次界面升级,而不是另一套独立技术栈。无论是 realtime YouTube copilot,还是 ElevenLabs 的语音层叙事,都默认智能体逻辑已经存在,下一步只是把语音、轮次切换和实时上下文包在外面。(realtime copilot, 语音层)
- 加密智能体栈正在围绕身份、支付和受保护执行走向标准化,但大多数公开证据仍停留在架构层。SAID、KYA、MPP TestKit 和 SUDP 都描述了真实的栈组件,但当前讨论里,图表和路线图仍然多于长期运营证明。(SAID, KYA, MPP TestKit, SUDP)