Twitter AI Agent - 2026-05-10¶
1. What People Are Talking About¶
1.1 Harness engineering is hardening into the umbrella term for agent infrastructure 🡕¶
The clearest shift is linguistic and architectural at the same time: people are talking less about a single model and more about the harness around it. Several high-signal posts treated retrieval, memory, orchestration, observability, and execution plumbing as the real source of agent quality rather than prompt phrasing alone.
@morganlinton boosted a thread on "harness engineering," and @ghumare64 argued that Addy Osmani's survey matters because leading coding agents are converging on the same pattern: context, tools, memory, and orchestration as the real moat. @_avichawla shared a "full-stack AI engineering" roadmap that explicitly places prompt engineering, RAG, fine-tuning, agents, deployment, optimization, observability, and context engineering in one stack. @hasantoxr added a repo list for "harness engineering" that grouped Harness, PostHog, GrowthBook, Chaos Mesh, and Kubescape into the same operational layer.
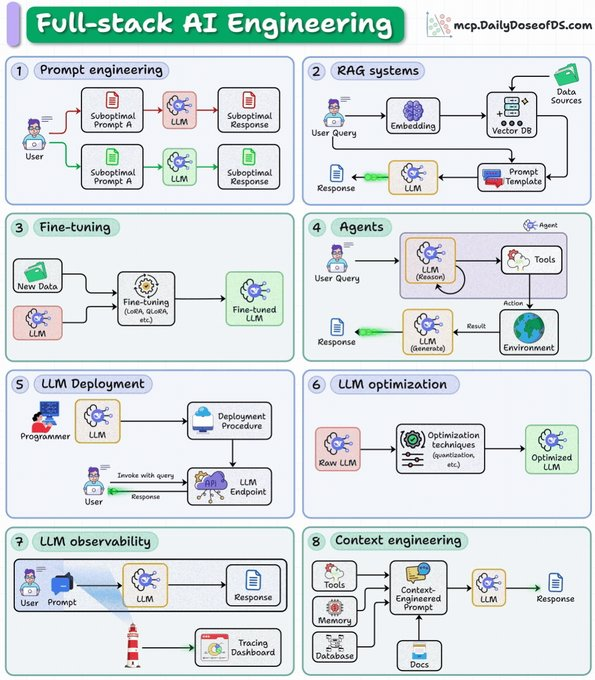
The same theme extended into workflow internals. @omarsar0 highlighted the AAFLOW paper, which says agentic RAG pipelines usually lose time in serialization and coordination rather than in the LLM call itself; the linked paper reports up to 4.64x pipeline speedup and 2.8x gains in embedding and upsert phases from a zero-copy Arrow/Cylon data plane. @aiDotEngineer pushed the same argument from the tool side, framing context engineering as "80% agentic search" and pointing people to a workshop on when shell tools, semantic search, and general-purpose query execution each break.

Discussion insight: Replies and adjacent posts show that people are still negotiating the vocabulary, but the direction is consistent. The debate is no longer whether context matters; it is whether teams can make retrieval, batching, and orchestration reproducible enough to stop over-focusing on prompt tweaks.
Comparison to prior day: May 9 emphasized the control plane around the agent as the real product. May 10 expands that into a broader discipline with named stacks, reading lists, repo bundles, and explicit data-plane performance claims.
1.2 Agent-written products are pushing builders toward thinner stacks and stricter conventions 🡕¶
Another strong theme is that teams are trying to reduce the surface area agents have to manage. Instead of celebrating ever-larger app frameworks, the most practical posts favored simpler browser primitives, stronger recipes, and scaffolding that makes AI output easier to review and constrain.
@ctatedev argued that for fully agent-written frontends, builders may want to start from index.html, browser primitives, Web Components, and strict conventions instead of a heavyweight framework. The replies pushed the same direction: one person said they had recently dropped NextJS and React, while another argued that local markdown files and inline CSS/JS can be easier for agents to manage than more elaborate stacks. @shadcn said his roadmap now prioritizes better agent integration and more agent-friendly shadcn/skills, and replies asked for Claude Design support plus reusable recipes for composing components without wasting context.
That same instinct showed up in scaffolding rather than UI. @tom_doerr shared a Claude Code setup that pointed to Claude Bootstrap, whose README describes TDD stop hooks, security-by-default rules, and agent teams by default. The repo has since evolved into "Maggy," but the core pitch is still the same: make AI coding workflows more deterministic, reviewable, and portable across tools. @mikefutia showed what that kind of scaffolding can unlock in a vertical workflow by automating keyword-gap analysis, competitor analysis, drafting, and weekly reporting for DTC SEO clients inside Claude Code.
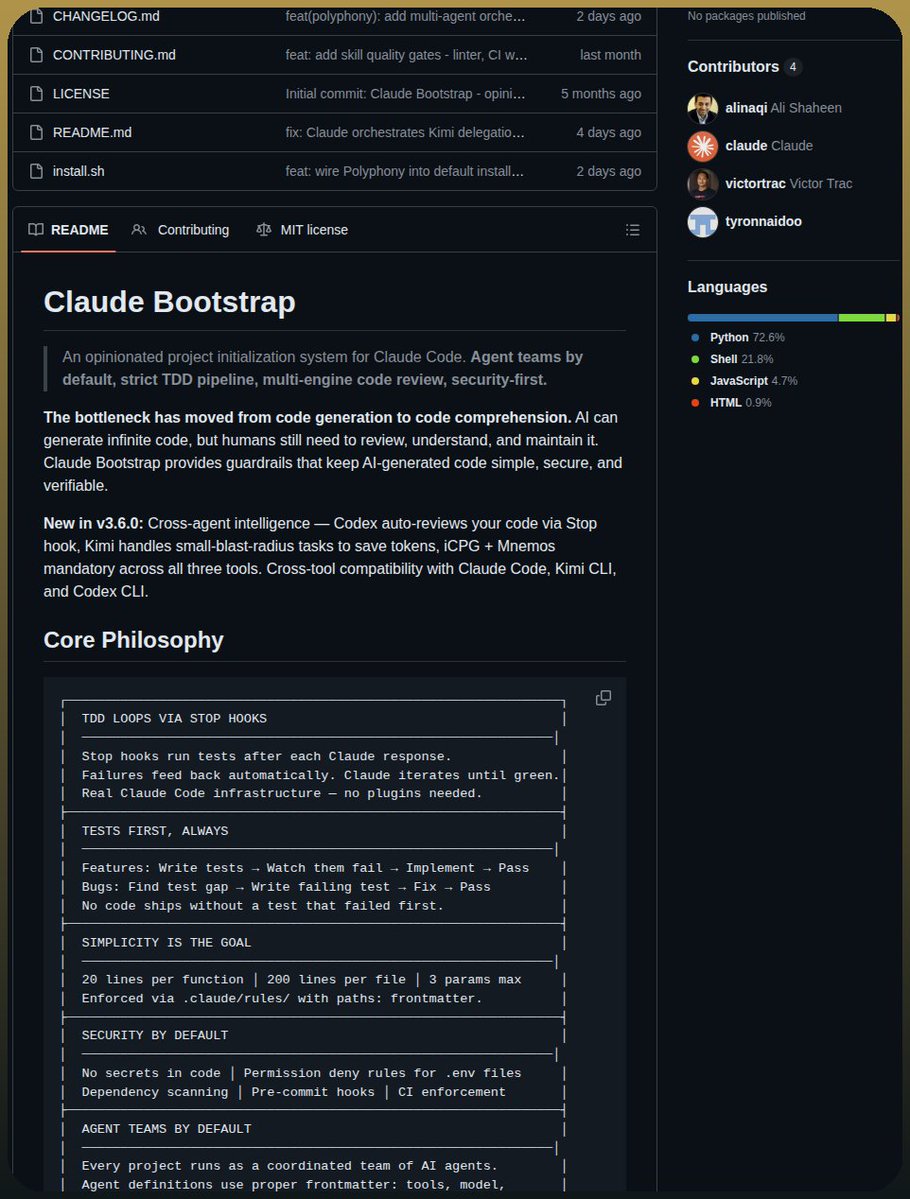
Discussion insight: The replies matter because they are not just cheering the demos. They keep returning to reviewability, custom patterns, and reducing how much context the agent has to juggle at once. "Agent-friendly" increasingly means "thin enough to reason about."
Comparison to prior day: May 9 focused more on dashboards, review queues, and orchestration surfaces around coding agents. May 10 turns that into direct stack advice: thinner frontends, reusable component recipes, and stricter TDD-oriented scaffolding.
1.3 Memory, skills, and skill distribution are becoming reusable assets instead of prompt craft 🡕¶
The third theme is that useful agent behavior is being externalized into persistent files, profiles, and catalog layers. Builders increasingly talk as if the work product is not just the answer an agent gives, but the skill, memory, or shared context it leaves behind for the next run.
@garrytan described the pattern as "code as memory": the first run researches and writes the script, while future runs just execute it. @kevincodex said an overnight OpenClaude session produced a new "agent memory file system" concept, which he framed as evidence that the era needs new primitives rather than more prompt tuning. @owenbjennings teased Mongoose as cloud multi-agent orchestration on top of Goose OSS, with shared context from web, calendar, Slack, email, and docs so a persistent "AI staff" can keep track of what is going on across surfaces.
The distribution layer around skills is also getting thicker. @exploraX_ promoted an open-source marketplace with "70k+" agentic skills, @kevinkern said he built a tool to extract only the one skill fragment you need, and @RoundtableSpace pointed to the Awesome Opencode repository as a centralized list of plugins, themes, agents, and resources for Opencode. Even Hermes-related posts fit the pattern: @IMJustinBrooke said Hermes profiles can each carry their own rules, training, and skills, while @Teknium said Hermes had already ported Anthropic's banker skills into its optional skillsets.
Discussion insight: The recurring value proposition is not "my agent is smarter." It is "my agent remembers, can reuse a prior routine, and can load exactly the right capability without rebuilding the whole workflow." Replies around Mongoose and the Opencode catalog both emphasize context continuity and discovery.
Comparison to prior day: May 9 already treated memory as a differentiator. May 10 expands that from one product feature into an ecosystem pattern spanning memory files, profiles, marketplaces, catalog repos, and selective skill retrieval.
1.4 Governance and agent security are becoming explicit product layers 🡕¶
Security and governance moved closer to the center of the conversation. Instead of vague warnings about risk, the strongest posts pointed to concrete interfaces, benchmarks, and budget controls for deploying agents at scale.
@googlecloud announced Agent Gateway in Gemini Enterprise as a central management point for network policies, data access, and prompt-injection guardrails. The linked Google Cloud blog post says Gemini Enterprise is adding an agent platform with reusable skills, long-running agents, inbox-style management, observability, and governance features built in from day one. @Dinosn linked Agent Security Bench, whose repo describes benchmarking attacks and defenses for LLM agents across 10 scenarios including direct prompt injection, observation prompt injection, plan-of-thought backdoors, and memory poisoning. @Crypto_Jayone pushed a Web3 version of the same problem with "Know Your Agent" identity infrastructure for autonomous machines.

Cost control is part of the same theme. @MichaelThiessen quote-tweeted a longer post from @levie arguing that token budgeting will become a major organizational concern as agents take on longer-running work and companies need visibility into where the spend is going. The implication is that agent governance is not just security policy; it is also budgeting, auditability, and central control over digital labor.
Discussion insight: The common thread is traceability. Whether the audience is enterprise IT or crypto-agent builders, the ask is the same: identity, policy, observability, and controls need to exist at the platform layer, not as a last-minute wrapper.
Comparison to prior day: May 9 mostly surfaced trust and identity rails through crypto-agent posts. May 10 broadens that into enterprise gateways, formal attack benchmarks, and token-budget management.
2. What Frustrates People¶
Orchestration and data plumbing still eat more time than the model call¶
The most consistent technical frustration is that agent pipelines remain bottlenecked by everything around the LLM. @omarsar0 pointed directly to serialization overhead, distributed-service coordination, and preprocessing/embedding handoffs as the real slowdown in agentic RAG pipelines, and the linked AAFLOW paper reports its gains from data flow rather than model acceleration. @DataScienceDojo described the "context pipeline" itself as the important architecture, while @aiDotEngineer framed context engineering as mostly search and tool selection. Severity: High. The workaround today is to invest in batching, retrieval, reviewer loops, and runtime engineering rather than assume model upgrades alone will rescue the workflow.
Agent-written apps still fight heavyweight frontend stacks and brittle web surfaces¶
@ctatedev made the complaint most directly by suggesting that agent-written frontends work better when builders avoid heavyweight frameworks and stick to browser primitives plus clear conventions. The replies reinforced that with reports of dropping NextJS and React for thinner setups. On the data-ingestion side, @aaliya_va said most scrapers break on anti-bot systems or simple layout changes, and pointed to Scrapling as a way to avoid constant selector rewrites. Severity: High. People are coping by simplifying app architecture and adopting adaptive scraping layers, which makes this an obvious build surface.
Governance, attack testing, and spend visibility still lag agent capability¶
The security frustration is no longer abstract. @googlecloud is explicitly selling Agent Gateway and Model Armor as protection against prompt injection and uncontrolled access, which only makes sense if enterprises already feel exposed. @Dinosn linked ASB precisely because people need more formal attack coverage for agents, including memory poisoning and observation-level attacks. And @MichaelThiessen amplified @levie on token budgeting because long-running agents are creating a new visibility problem for spend allocation. Severity: High. Current coping behavior is to add gateways, benchmarks, and budget controls around agents after the fact; that still looks incomplete.
Repetitive operating loops remain obvious but under-automated¶
The frustration is practical as much as technical. @mikefutia described the standard SEO agency loop as five Ahrefs tabs, five CSV exports, five Google Docs, writer briefs, and another monthly repeat cycle, then built a Claude Code agent to collapse that into one system. The pain here is not that people cannot imagine the automation. It is that many industries still have obvious high-friction loops waiting for someone to package the workflow. Severity: Medium to High. This looks worth building for directly.
3. What People Wish Existed¶
Thin, agent-first application conventions¶
The frontend thread around @ctatedev, the agent-integration requests under @shadcn, and the Claude Bootstrap scaffolding push all point to the same missing standard: a lighter default application stack designed for agent authorship and review. This is a practical need, not a speculative one, because people are already abandoning heavier frameworks or inventing their own local conventions. Opportunity: direct.
Reusable memory and skill packaging with precise retrieval¶
The demand is explicit across Mongoose, Hermes profiles, code-as-memory, the 70k-skill marketplace, and Kevin Kern's tool for extracting just the needed skill fragment. People want workflows to compound instead of resetting every run, but they also want selective retrieval rather than huge undifferentiated prompt blobs. Partial answers exist in Awesome Opencode and product-specific skill systems, but the general pattern is still unsettled. Opportunity: direct.
Managed governance for agent identity, policy, and spend¶
Agent Gateway, ASB, KYA, and the token-budget conversation all describe the same missing layer from different angles. Teams want agents with clear identity, permission boundaries, prompt-injection defenses, budget visibility, and audit trails. That is urgent because long-running agents are already being positioned for enterprise workflows that last hours or days. Opportunity: direct.
Faster, more reproducible data planes for agentic workflows¶
AAFLOW stands out because it attacks a concrete systems problem instead of another prompting abstraction. The post and paper both suggest builders want agent runtimes that make retrieval/reasoning/memory pipelines communication-efficient and reproducible without forcing every team to hand-roll the orchestration layer themselves. This looks more competitive than greenfield, but the need is concrete and technical. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Harness engineering / context engineering | Method | (+) | Gives teams a vocabulary for retrieval, memory, orchestration, observability, and execution instead of over-indexing on prompts | Still broad and interpreted differently across posts, courses, and repo lists |
| AAFLOW | Agent runtime / data plane | (+) | Uses Apache Arrow and Cylon to cut serialization overhead; paper reports up to 4.64x pipeline speedup and 2.8x gains in embedding and upsert phases | Research-stage result with limited deployment evidence in the dataset |
| shadcn/skills + Claude Bootstrap | Agent development scaffolding | (+) | Pushes reusable agent-friendly recipes, TDD stop hooks, security defaults, and coordinated multi-agent workflows | Still tied to specific tooling ecosystems and early community conventions |
| Hermes Agent | Agent runtime | (+/-) | Multiple profiles, optional skillsets, and visible momentum around reusable skills and memory | Most evidence here is community testimony and ecosystem chatter rather than neutral production metrics |
| Awesome Opencode / skill marketplaces | Skill catalog / distribution | (+) | Speeds discovery of plugins, themes, agents, and reusable capabilities; reduces rebuilding from scratch | Catalog size or stars do not guarantee quality, fit, or long-term maintenance |
| Scrapling | Web extraction / MCP tooling | (+) | Adaptive selectors, anti-bot posture, concurrent crawling, and MCP integration promise cleaner context before model calls | Benchmarks and anti-bot claims are attractive, but broad real-world validation is thin in today's evidence |
| Agent Gateway in Gemini Enterprise | Governance / security | (+) | Centralizes network policies, data access, guardrails, and model screening for enterprise agents | Managed Google Cloud product rather than a portable standard; strongest fit is enterprise buyers |
| Agent Security Bench (ASB) | Security benchmark | (+) | Formalizes attacks and defenses across 10 agent scenarios, including prompt injection and memory poisoning | Useful for evaluation, but it does not itself solve runtime security or policy enforcement |
| KYA identity rails | Agent identity / trust infrastructure | (+/-) | Makes machine identity, sponsor linkage, and reputation explicit for autonomous agents | Public evidence today is stronger on framing than on widespread deployment quality |
Summary: The strongest positive sentiment attaches to methods or tools that make agents easier to steer, observe, and reuse. The migration pattern is away from prompt-centric thinking and toward infrastructure-centric thinking: search, memory, thin UI layers, skill loading, gateways, and benchmarks. Competitive dynamics are splitting into two tracks: open tooling for agent builders, and managed governance layers for enterprises.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Claude Code SEO agent | @mikefutia | Automates keyword-gap analysis, competitor analysis, brand-voice content generation, and weekly ranking loops for DTC SEO work | Agencies still run repetitive tab-heavy SEO operations every week | Claude Code, Google Search Console, Apify | Alpha | post |
| Mongoose | @owenbjennings | Cloud multi-agent orchestration with shared context from web, calendar, Slack, email, and docs | Assistants usually lose cross-surface context and cannot act like persistent staff | Goose OSS, shared-context orchestration, memory compounding | Alpha | post |
| Maggy / Claude Bootstrap | alinaqi | Turns Claude Code setup into a guarded autonomous engineering workflow with stop hooks, agent teams, and cross-tool sync | AI-generated code needs stronger review, TDD, and security defaults | Python, shell, JavaScript, stop hooks, agent definitions, cross-tool config | Beta | repo, post |
| Gemini Enterprise Agent Gateway | @googlecloud | Adds centralized gateway, Model Armor, skills, inbox management, and observability to enterprise agents | Long-running agents need managed policy, traceability, and secure tool access | Gemini Enterprise Agent Platform, Agent Gateway, Model Armor | Beta | blog, post |
| AAFLOW | Sarker et al. | Distributed runtime for retrieval, reasoning, and memory workflows with a zero-copy data plane | Agentic RAG systems lose time in serialization and coordination overhead | Apache Arrow, Cylon, asynchronous batching | Alpha | paper, post |
| Agent Security Bench | AGI Research | Benchmarks attacks and defenses for LLM agents across multiple scenarios | Builders lack systematic evaluation for prompt injection, memory poisoning, and related attacks | AIOS-based attack/evaluation framework | Beta | repo, post |
The builders in today's dataset cluster into three patterns. One group is building control planes and scaffolding for agent development itself, such as Claude Bootstrap, Mongoose, and Awesome Opencode-adjacent catalogs. Another group is building vertical operators like Mike Futia's SEO agent, where the win comes from collapsing a repetitive industry loop. The third group is building governance and systems infrastructure - gateways, security benches, and distributed runtimes - because deployment pain has become too concrete to ignore.
6. New and Notable¶
Harness engineering is becoming a shared frame rather than a niche phrase¶
Multiple independent posts treated "harness engineering" or "context engineering" as the center of agent quality, and they backed that framing with repo lists, roadmaps, workshops, and quote-tweets rather than one isolated hot take. That is notable because it suggests the category is stabilizing into common language for builders. (morganlinton, ghumare64, avichawla)
Enterprise agent management is being productized quickly¶
Google Cloud's Agent Gateway announcement is notable because it packages long-running agents, reusable skills, inbox management, governance, and Model Armor into a single enterprise narrative. That is a stronger signal than a standalone model launch because it treats agents as an operational system that must be traced, managed, and secured across business workflows. (blog, post)
Skill discovery is turning into its own tooling layer¶
The skill marketplace post, Kevin Kern's selective-skill tool, and the Awesome Opencode repo all point to the same new category: products that help agents find, load, and reuse capabilities instead of forcing users to rebuild them from scratch. The number itself - "70k+" skills - matters less than the fact that distribution and curation have become visible product surfaces. (marketplace post, selective tool, Awesome Opencode)
7. Where the Opportunities Are¶
[+++] Agent control planes for context, memory, and execution — The harness engineering cluster, Mongoose, Claude Bootstrap, and the code-as-memory discussion all point to the same need: better products for assembling context, coordinating agents, and preserving reusable routines across runs.
[++] Agent-first application and extraction tooling — ctatedev's thin-frontend argument, shadcn's agent integration roadmap, and Scrapling's adaptive scraping pitch all show that today's frameworks and web surfaces still create unnecessary friction for agents.
[++] Governance, security, and spend management for autonomous work — Agent Gateway, ASB, KYA, and Levie's token-budget framing all show that safety, policy, and cost controls are becoming first-class deployment requirements.
[+] Skill discovery and selective capability loading — Skill marketplaces, catalogs, and selective-skill tools suggest a growing market for packaging and routing reusable capability blocks without flooding agents with irrelevant context.
8. Takeaways¶
- The center of gravity shifted from prompts to infrastructure. The biggest May 10 posts were about harness engineering, context pipelines, agentic search, and data-plane bottlenecks rather than raw model comparisons. (morganlinton, omarsar0, aiDotEngineer)
- Builders are simplifying stacks while externalizing reusable knowledge. Thin frontend conventions, TDD scaffolding, code-as-memory, skill marketplaces, and profile-based agents all point toward the same operating model: make the environment easier for agents to navigate, then persist the good parts for reuse. (ctatedev, tom_doerr, garrytan, RoundtableSpace)
- Governance is becoming part of the product, not a postscript. Google's Agent Gateway, ASB, KYA, and token-budget discussions all show that identity, policy, attack testing, and spend visibility are now central to how agent platforms are evaluated. (googlecloud, ASB, Crypto_Jayone, MichaelThiessen)