Twitter AI 智能体 - 2026-05-10¶
1. 人们在讨论什么¶
1.1 测试框架工程正在固化为智能体基础设施的总括术语 🡕¶
最清晰的变化,同时发生在语言和架构层面:人们谈论的已经不再是某一个模型,而是包裹它的测试框架。多条高信号帖子都把检索、记忆、编排、可观测性和执行管线,当成智能体质量的真正来源,而不只是提示词措辞。
@morganlinton 转推 了一条关于“测试框架工程”的讨论串;@ghumare64 认为,Addy Osmani 的综述之所以重要,是因为领先的编程智能体正收敛到同一种模式:真正的护城河是上下文、工具、记忆和编排。@_avichawla 分享 了一份“全栈 AI 工程”路线图,明确把提示工程、RAG、微调、智能体、部署、优化、可观测性和上下文工程放进同一栈里。@hasantoxr 又补上 了一个“测试框架工程”的仓库清单,把 Harness、PostHog、GrowthBook、Chaos Mesh 和 Kubescape 都归进了同一个运营层。
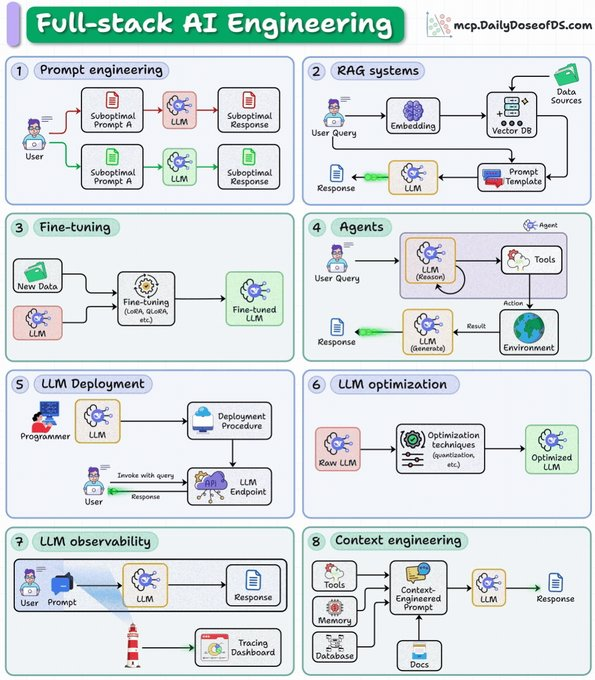
同一主题也延伸到了工作流内部。omarsar0 重点提到 AAFLOW 论文,指出智能体式 RAG 管线通常耗时最多的不是 LLM 调用本身,而是序列化和协同过程;关联的论文称,基于零拷贝 Arrow/Cylon 数据平面,可让管线整体提速最高 4.64 倍,并让嵌入和写入阶段提速 2.8 倍。@aiDotEngineer 则从工具侧 推动 了同样的论点:他把上下文工程描述为“80% 都是智能体式搜索”,并把人们引向一场研讨会,讨论 shell 工具、语义搜索和通用查询执行各自会在什么地方失效。

讨论要点: 回复和相邻帖子说明,大家仍在协商这套词汇,但方向很一致。争论早已不是上下文重不重要,而是团队能不能把检索、批处理和编排做得足够可复现,从而不再把精力过度放在提示词微调上。
与前日对比: 5 月 9 日强调的是围绕智能体的控制层才是真正的产品。到了 5 月 10 日,这种说法被扩展成一门更完整的学科:有命名的技术栈、阅读清单、仓库合集,以及对数据平面性能的明确主张。
1.2 智能体撰写的产品正把构建者推向更薄的栈和更严格的约定 🡕¶
另一个强主题是,团队正在尽量缩小需要智能体管理的表面积。最务实的帖子,不再歌颂越来越重的应用框架,而是偏向更简单的浏览器原语、更明确的配方,以及能让 AI 输出更容易审查和约束的脚手架。
@ctatedev 认为,如果前端完全由智能体来写,构建者可能应该从 index.html、浏览器原语、Web Components 和严格约定出发,而不是先上一个厚重框架。回复也在推同一个方向:有人说自己最近已经放弃 NextJS 和 React;另一位则认为,本地 markdown 文件和内联 CSS/JS 比更复杂的技术栈更容易让智能体管理。@shadcn 表示,他现在的路线图会优先考虑更好的智能体集成,以及更适合智能体使用的 shadcn/skills;回复则在要求 Claude Design 支持和可复用配方,以便在不浪费上下文的前提下组合组件。
这种本能同样体现在脚手架而不是界面上。@tom_doerr 分享 了一套 Claude Code 配置,指向 Claude Bootstrap;其 README 把自己描述为默认启用 TDD stop hooks、默认安全规则和默认智能体团队的系统。这个仓库后来已经演化成了“Maggy”,但核心卖点没变:让 AI 编程工作流更可预测、更易审查,也更容易在工具之间迁移。@mikefutia 则展示 了这种脚手架在垂直工作流中的价值:他把关键词缺口分析、竞品分析、起草和每周报告,都自动化进了面向 DTC SEO 客户的 Claude Code 流程里。
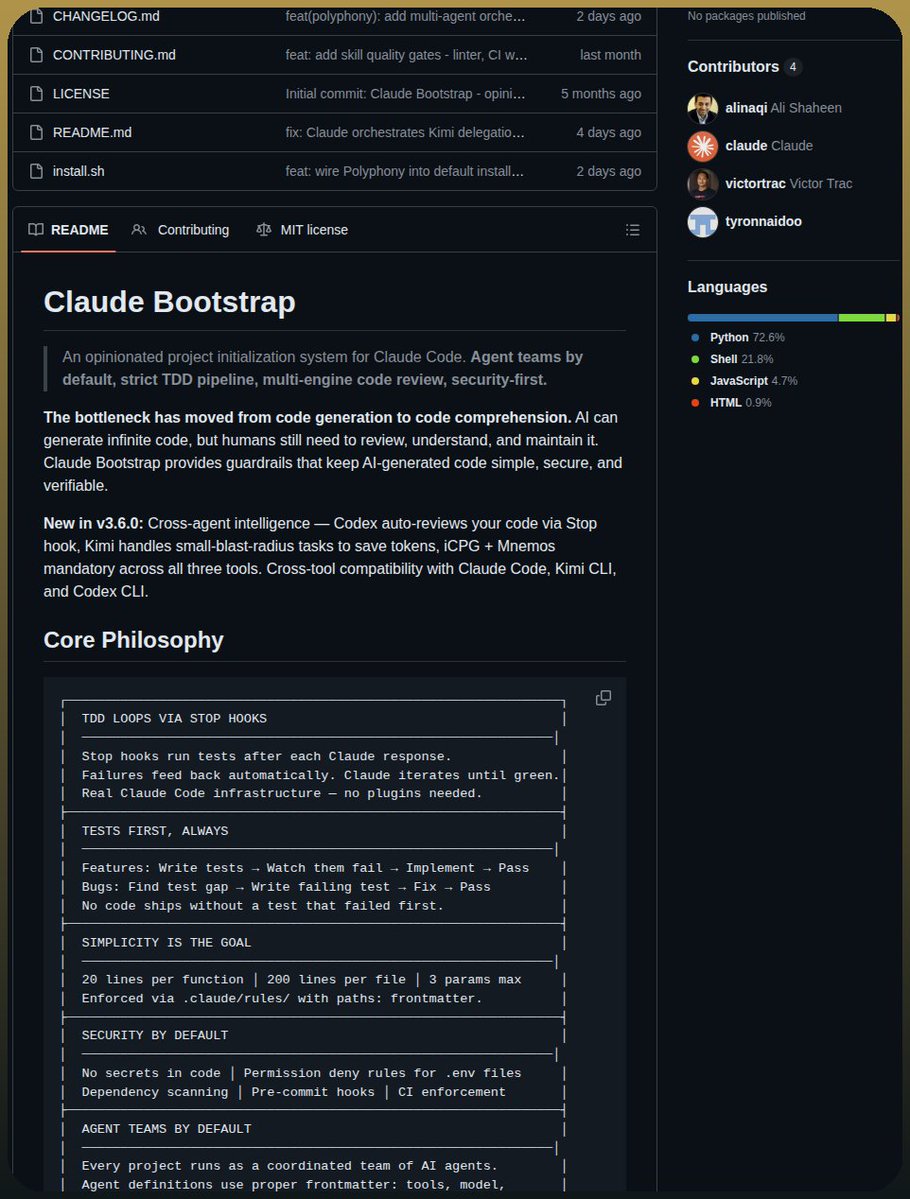
讨论要点: 回复之所以重要,是因为大家并不只是给演示鼓掌。人们反复回到审查性、自定义模式,以及如何减少智能体必须同时处理的上下文量。所谓“对智能体友好”,越来越意味着“栈要薄到足够推理得过来”。
与前日对比: 5 月 9 日更关注编程智能体周围的仪表盘、审查队列和编排界面。5 月 10 日则把这些抽象落成了更直接的栈建议:更薄的前端、可复用的组件配方,以及更严格、偏 TDD 的脚手架。
1.3 记忆、技能与技能分发正在从提示词技巧变成可复用资产 🡕¶
第三个主题是,有用的智能体行为正被外化到持久文件、配置档案和目录层里。构建者越来越像是在说,真正的工作成果不只是智能体给出的那次回答,而是它为下一次运行留下的技能、记忆或共享上下文。
@garrytan 把这种模式称作“代码即记忆”:第一次运行负责研究并写出脚本,后续运行只需要执行它。@kevincodex 表示,一次过夜的 OpenClaude 会话催生了一个新的“智能体记忆文件系统”概念;他把这看作一个信号:这个时代需要的是新原语,而不是更多提示词调优。@owenbjennings 则预告,Mongoose 会基于 Goose OSS 做云端多智能体编排,并从网页、日历、Slack、邮件和文档中共享上下文,让一个持久存在的“AI 员工团队”能持续掌握跨界面发生的事情。
围绕技能的分发层也在变厚。@exploraX_ 推广 了一个拥有“70k+”智能体技能的开源技能市场;@kevinkern 表示,他做了一个只提取你真正需要的那一小段技能的工具;@RoundtableSpace 则指向 Awesome Opencode 仓库,把它当作 Opencode 的插件、主题、智能体和资源总目录。就连涉及 Hermes 的帖子也符合这个模式:@IMJustinBrooke 说,每个 Hermes 配置档案都可以带自己的规则、训练和技能;@Teknium 则表示,Hermes 已经把 Anthropic 的 banker skills 移植进了可选技能集里。
讨论要点: 反复出现的价值主张,不是“我的智能体更聪明”,而是“我的智能体记得住、能复用旧流程,而且能在不重建整个工作流的前提下加载刚好需要的能力”。围绕 Mongoose 和 Opencode 目录的回复,都在强调上下文连续性和发现能力。
与前日对比: 5 月 9 日已经把记忆视为一种差异化因素。到了 5 月 10 日,这种差异化从单一产品特性,扩展成了一整套生态模式:记忆文件、配置档案、技能市场、目录仓库,以及选择性技能检索。
1.4 治理与智能体安全正成为明确的产品层 🡕¶
安全和治理离讨论中心更近了。最强的帖子,不再只是泛泛提醒风险,而是指向了可大规模部署智能体所需的具体界面、基准测试和预算控制。
@googlecloud 宣布,Gemini Enterprise 引入了 Agent Gateway,作为网络策略、数据访问和提示词注入安全护栏的统一管理点。关联的 Google Cloud 博客文章 还提到,Gemini Enterprise 正在加入一个自带可复用技能、长时运行智能体、收件箱式管理、可观测性和治理能力的智能体平台。@Dinosn 链接了 Agent Security Bench;其仓库描述称,它会在 10 种场景里对 LLM 智能体的攻击与防御做基准测试,包括直接提示词注入、观察提示词注入、plan-of-thought 后门和记忆投毒。@Crypto_Jayone 则推动 了同一问题的 Web3 版本:为自主机器建立《Know Your Agent》身份基础设施。

成本控制也属于同一主题。@MichaelThiessen 引用转发 了 @levie 的长帖,后者认为,随着智能体接手越来越多长时任务、公司又必须看清钱花到了哪里,token 预算将成为重要的组织级议题。换句话说,智能体治理不只是安全策略,也包括预算、可审计性,以及对数字劳动力的集中控制。
讨论要点: 共同主线是可追踪性。不管受众是企业 IT,还是加密智能体构建者,诉求都一样:身份、策略、可观测性和控制能力,必须存在于平台层,而不能在最后一刻再包一层壳。
与前日对比: 5 月 9 日主要通过加密智能体帖子露出了信任和身份轨道。5 月 10 日则把它扩展成企业网关、正式攻击基准测试和 token 预算管理。
2. 令人困扰的问题¶
编排和数据管线仍然比模型调用本身更耗时间¶
最稳定的技术挫败感是:智能体管线仍然被 LLM 周围的一切卡住。omarsar0 直接指出,智能体式 RAG 管线真正的减速点,是序列化开销、分布式服务协同,以及预处理 / embedding 交接;关联的 AAFLOW 论文 也把提升归因于数据流,而不是模型加速。DataScienceDojo 把“上下文管线”本身描述成关键架构;@aiDotEngineer 则把上下文工程定义为大部分都是搜索和工具选择。严重程度:高。当前的应对方式,是把资源投向批处理、检索、审查闭环和运行时工程,而不是假设模型升级就能自动救回整个工作流。
智能体编写的应用仍在和厚重前端栈与脆弱网页界面搏斗¶
@ctatedev 把这种抱怨说得最直接:当构建者避开厚重框架、改用浏览器原语加清晰约定时,智能体编写的前端会更好用。回复也在印证这一点:有人说已经放弃 NextJS 和 React,转向更薄的配置。数据采集侧,aaliya_va 则说,大多数爬虫都会在反 bot 系统或简单布局变化面前失效,并把 Scrapling 当作避免反复重写选择器的办法。严重程度:高。人们当前的应对方式,是简化应用架构并采用更自适应的抓取层;这让它成为一个显而易见的构建面。
治理、攻击测试和支出可见性仍落后于智能体能力¶
安全层面的挫败感已经不再抽象。googlecloud 明确在卖 Agent Gateway 和 Model Armor,主打对提示词注入和失控访问的防护;这只有在企业已经感到暴露时才说得通。Dinosn 之所以贴出 ASB,就是因为人们需要对智能体攻击面做更正式的覆盖,包括记忆投毒和观察层攻击。而 @MichaelThiessen 放大 @levie 关于 token 预算的说法,则说明长时运行智能体正在制造新的支出可见性问题。严重程度:高。当前的应对方式,是事后再给智能体外面加网关、基准测试和预算控制;但这看起来仍然不完整。
重复性的运营闭环依然显而易见,却还没被充分自动化¶
这种挫败感既现实又朴素。mikefutia 把标准 SEO 代理机构的流程描述成 5 个 Ahrefs 标签页、5 次 CSV 导出、5 份 Google Docs、写手说明,以及下个月再来一遍,然后他用 Claude Code 智能体把这一切压缩进一个系统里。这里的痛点,不是大家想象不到自动化,而是很多行业里还存在太多明显、摩擦很高的重复闭环,等着有人把它们打包成工作流。严重程度:中到高。这个方向看起来非常值得直接构建。
3. 人们期望的功能¶
轻量、以智能体为先的应用约定¶
围绕 @ctatedev 的前端讨论、@shadcn 那条帖子下对智能体集成的请求,以及 Claude Bootstrap 这类脚手架,都指向同一个缺失标准:一个更轻的默认应用栈,专门为了智能体写作与审查而设计。这是现实需求,而不是臆想,因为人们已经在主动放弃更重的框架,或者自己发明本地约定。机会:直接。
可复用的记忆与技能打包,以及精确检索¶
Mongoose、Hermes profiles、“代码即记忆”、那个 70k 技能市场,以及 Kevin Kern 只提取所需技能片段的工具,都把需求说得很明确。人们想让工作流越跑越值钱,而不是每次重来;但他们也想要选择性检索,而不是一团巨大、无差别的提示词文本。部分答案已经存在于 Awesome Opencode 和各个产品自己的技能系统里,但整体模式仍未定型。机会:直接。
面向智能体身份、策略与支出的托管治理¶
Agent Gateway、ASB、KYA 和 token 预算讨论,分别从不同角度描述了同一个缺失层。团队想要的是拥有清晰身份、权限边界、提示词注入防御、预算可见性和审计轨迹的智能体。这件事之所以紧迫,是因为长时运行智能体已经被当作可持续数小时甚至数天的企业工作流工具来推。机会:直接。
更快、可复现性更强的智能体式工作流数据平面¶
AAFLOW 之所以突出,在于它攻击的是一个具体的系统问题,而不是又一层提示词抽象。帖子和论文都在暗示,构建者想要的,是能让检索 / 推理 / 记忆管线更高效通信、更可复现的智能体运行时,而不是逼每个团队都手搓一遍编排层。这个方向看起来更偏竞争型,而不是完全空白市场,但需求明确而且技术性很强。机会:竞争型。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| 测试框架工程 / 上下文工程 | 方法 | (+) | 给团队一套词汇来描述检索、记忆、编排、可观测性和执行,而不是只盯着提示词 | 仍然过于宽泛,不同帖子、课程和仓库清单里的含义并不一致 |
| AAFLOW | 智能体运行时 / 数据平面 | (+) | 用 Apache Arrow 和 Cylon 降低序列化开销;论文报告称,管线整体最高提速 4.64 倍,embedding 和 upsert 阶段提速 2.8 倍 | 仍属研究阶段,数据集中几乎没有部署证据 |
| shadcn/skills + Claude Bootstrap | 智能体开发脚手架 | (+) | 推动可复用、对智能体友好的配方、TDD stop hooks、安全默认项和协同多智能体工作流 | 仍然绑定在特定工具生态上,也还处于早期社区约定阶段 |
| Hermes Agent | 智能体运行时 | (+/-) | 多 profile、可选 skillset,以及围绕可复用技能和记忆的可见势头 | 这里的大部分证据仍来自社区证词和生态讨论,而非中立的生产指标 |
| Awesome Opencode / 技能市场 | 技能目录 / 分发 | (+) | 能加速发现插件、主题、智能体和可复用能力,减少从零重建 | 目录规模或 star 数并不能保证质量、适配性或长期维护 |
| Scrapling | 网页提取 / MCP 工具链 | (+) | 自适应 selector、抗 bot 能力、并发抓取和 MCP 集成,有望在模型调用前提供更干净的上下文 | 基准测试和抗 bot 说法很吸引人,但今天的证据里真实世界验证仍然很薄 |
| Gemini Enterprise 中的 Agent Gateway | 治理 / 安全 | (+) | 为企业智能体集中管理网络策略、数据访问、安全护栏和模型筛查 | 这是 Google Cloud 的托管产品,而不是可移植标准;最适合企业买家 |
| Agent Security Bench (ASB) | 安全基准测试 | (+) | 在 10 种智能体场景里形式化了攻击与防御,包括提示词注入和记忆投毒 | 它有助于评估,但本身并不解决运行时安全或策略执行 |
| KYA identity rails | 智能体身份 / 信任基础设施 | (+/-) | 让机器身份、赞助关系和声誉变得显式 | 今天公开证据更多停留在叙事层,而不是广泛部署质量 |
总结: 最强的正面情绪,都落在那些能让智能体更容易被引导、被观察和被复用的方法或工具上。迁移路径正在从以提示词为中心,转向以基础设施为中心:搜索、记忆、轻量界面层、技能加载、网关和基准测试。竞争格局也开始分成两条线:面向智能体构建者的开源工具,以及面向企业的托管治理层。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Claude Code SEO 智能体 | @mikefutia | 为 DTC SEO 工作自动化关键词缺口分析、竞品分析、品牌语气内容生成和每周排名闭环 | 代理机构每周仍在重复执行标签页繁多的 SEO 操作 | Claude Code、Google Search Console、Apify | Alpha | post |
| Mongoose | @owenbjennings | 从网页、日历、Slack、邮件和文档共享上下文的云端多智能体编排 | 助手通常会丢失跨界面的上下文,无法像持久团队一样工作 | Goose OSS、共享上下文编排、记忆复利 | Alpha | post |
| Maggy / Claude Bootstrap | alinaqi | 把 Claude Code 配置变成带安全护栏的自主工程工作流,包含 stop hooks、智能体团队和跨工具同步 | AI 生成代码需要更强的审查、TDD 和安全默认项 | Python、shell、JavaScript、stop hooks、智能体定义、跨工具配置 | Beta | repo, post |
| Gemini Enterprise Agent Gateway | @googlecloud | 为企业智能体加入集中式网关、Model Armor、skills、收件箱管理和可观测性 | 长时运行智能体需要受管理的策略、可追踪性和安全工具访问 | Gemini Enterprise Agent Platform、Agent Gateway、Model Armor | Beta | blog, post |
| AAFLOW | Sarker et al. | 用零拷贝数据平面驱动检索、推理和记忆工作流的分布式运行时 | 智能体式 RAG 系统把大量时间浪费在序列化和协同开销上 | Apache Arrow、Cylon、异步批处理 | Alpha | paper, post |
| Agent Security Bench | AGI Research | 为 LLM 智能体在多种场景中的攻击与防御做基准测试 | 构建者缺少对提示词注入、记忆投毒等攻击的系统性评估 | 基于 AIOS 的攻击 / 评估框架 | Beta | repo, post |
今天数据集里的构建者,大致聚成三种模式。一类是在为智能体开发本身搭控制平面和脚手架,比如 Claude Bootstrap、Mongoose,以及和 Awesome Opencode 相邻的目录层。另一类是在做垂直运营者,比如 Mike Futia 的 SEO 智能体,价值来自把一个行业里重复、摩擦高的闭环压成一个系统。第三类则在做治理和系统基础设施——网关、安全基准测试和分布式运行时——因为部署痛点已经具体到不能忽视了。
6. 新动态与亮点¶
测试框架工程正在成为共同语境,而不再是小众说法¶
多条彼此独立的帖子,都把“测试框架工程”或“上下文工程”视作智能体质量的核心,而且它们不是孤零零的一句 hot take,而是配上了仓库清单、路线图、workshop 和引用转发。这一点之所以重要,是因为它说明这个类别正在稳定成构建者的共同语言。(morganlinton, ghumare64, avichawla)
企业级智能体管理正在迅速产品化¶
Google Cloud 宣布 Agent Gateway 之所以重要,是因为它把长时运行智能体、可复用技能、收件箱管理、治理和 Model Armor 打包进了同一个企业叙事里。相比单独发一个模型,这个信号更强,因为它把智能体当成一个必须在业务工作流里被追踪、被管理、被保护的运营系统。(blog, post)
技能发现正在长成独立的工具层¶
技能市场那条帖子、Kevin Kern 的选择性技能工具,以及 Awesome Opencode 仓库,都指向同一个新类别:帮助智能体发现、加载和复用能力的产品,而不是逼用户每次都从零重建。“70k+” 这个数字本身没那么重要,真正重要的是,分发与策展已经开始成为可见的产品表层。(marketplace post, selective tool, Awesome Opencode)
7. 机会在哪里¶
[+++] 面向上下文、记忆与执行的智能体控制平面 —— 测试框架工程讨论簇、Mongoose、Claude Bootstrap,以及“代码即记忆”的讨论,都指向同一个需求:更好的产品来组装上下文、协调智能体,并在多次运行之间保留可复用流程。
[++] 以智能体为先的应用与提取工具链 —— ctatedev 倡导薄前端,shadcn 在推进智能体集成路线图,Scrapling 则主打自适应抓取;这些信号都说明,今天的框架和网页界面仍在给智能体制造不必要的摩擦。
[++] 面向自主化工作的治理、安全与支出管理 —— Agent Gateway、ASB、KYA 和 Levie 关于 token 预算的框定,都表明安全、策略和成本控制正在成为一流的部署要求。
[+] 技能发现与选择性能力加载 —— 技能市场、目录和选择性技能工具,都说明市场正在冒出来:把可复用能力块打包并路由给智能体,而不是让无关上下文把它们淹没。
8. 要点总结¶
- 重心已经从提示词转向基础设施。 5 月 10 日最重要的帖子,都在谈测试框架工程、上下文管线、智能体式搜索和数据平面瓶颈,而不是原始模型对比 (morganlinton, omarsar0, aiDotEngineer)。
- 构建者一边简化技术栈,一边把可复用知识外化。 更薄的前端约定、TDD 脚手架、“代码即记忆”、技能市场和基于 profile 的智能体,都在把工作模式推向同一个方向:先让环境更容易被智能体理解,再把好用的部分持久化下来反复利用 (ctatedev, tom_doerr, garrytan, RoundtableSpace)。
- 治理正在成为产品的一部分,而不是附注。 Google 的 Agent Gateway、ASB、KYA 以及围绕 token 预算的讨论,都说明身份、策略、攻击测试和支出可见性,已经成了评估智能体平台的核心标准 (googlecloud, ASB, Crypto_Jayone, MichaelThiessen)。