Twitter AI Agent - 2026-05-12¶
1. What People Are Talking About¶
1.1 Harness engineering hardens into a named, teachable discipline 🡕¶
The single loudest signal of the day was the continued crystallization of "harness engineering" from a catchy phrase into a structured body of knowledge with articles, mind-maps, course curricula, and practitioner checklists. The pattern was not one viral post; it was a coordinated amplification of @addyosmani's harness engineering article across many accounts, each adding a layer.
@akshay_pachaar published the day's highest-engagement post (97,031 views, 2,664 bookmarks), naming prompt caching vs semantic caching tradeoffs, KV cache management at scale, structured output fallback chains, evals, cost attribution per feature, agent guardrails and loop budgets, LLM observability, model routing, and when to fine-tune as the required curriculum (post link). A reply from @0xNeoArch added prompt-injection defense, model distillation from big-model traces, and "knowing when NOT to use an LLM" as equally essential. Another reply noted "the harness is 95% of the system; prompts are the easy part."
@MindBranches rendered @addyosmani's article as a comprehensive mind-map in 4K light and dark mode, quoting the original post (8,434 views, 110 bookmarks) (post link). Both images are detailed enough to serve as standalone reference material.

@dishantwt_ surfaced a structured course site titled "Learn Harness Engineering" (7,842 views, 252 bookmarks), which covers lecture topics including Why Capable Agents Still Fail, What a Harness Actually Is, Why the Repository Must Become the System of Record, Why One Giant Instruction File Fails, Why Long-Running Tasks Lose Continuity, and Why Feature Lists Are Harness Primitives (post link). The course cites OpenAI's Codex harness engineering guide and Anthropic's docs on effective harnesses for long-running agents as primary references.
Discussion insight: No one pushed back on the harness framing itself. Pushback, where it existed, came from replies demanding concrete implementation examples rather than abstract taxonomies. The space broadly agrees on the frame; the gap is implementation.
Comparison to prior day: May 11 introduced the harness engineering label as a community signal. May 12 moved it into structured educational resources and visualized article summaries. The conversation is now about where to learn it, not what it is.
1.2 Context engineering displaces prompt engineering as the primary optimization target 🡒¶
A parallel cluster of posts argued that the productivity gap between average and expert AI users is no longer intelligence or prompt quality — it is how much persistent context they maintain. The common vocabulary: AGENTS.md, CLAUDE.md, soul.md, brand-context files, taste files.
@NainsiDwiv50980 summarized the shift as "prompt engineering is the new learn-to-type-faster" and contrasted average users (generic role prompts) against power users who store brand voice in .md files, save examples of disliked outputs, and build reusable context folders (908 views, 34 retweets) (post link). @DamiDefi made the same point to 11,237 views: "A perfect prompt inside bad context still produces generic outputs. A simple prompt inside great context can outperform almost anything" (post link).
@oliverwhudson described how his team creates 6,000 ads per month by building context infrastructure rather than better prompts — brand context, domain context, Claude Skills routing logic, a reference file system, Notion MCP integration, and quality gates. Their reporting skill saves two days per creative strategist per month, and reasoning traces log every strategic decision so the system compounds over time (1,529 views, 34 bookmarks) (post link).
@mark_k framed the deeper problem: AI still requires users to constantly translate their intent into machine-friendly instructions, and the big unlock is an interface where people can talk, show, point, interrupt, and correct without reformatting their thoughts (4,554 views, 47 replies) (post link). In replies, he predicted that the future will be dynamic UI generated by the AI itself for the task at hand.
Discussion insight: The most substantive replies extended the context theme into tooling: Obsidian vaults, N8N workflows, CLAUDE.md files, and multi-agent memory stores were all cited as practical implementations. The pattern was consistent — persistent, machine-readable context files compound while ad-hoc prompts plateau.
Comparison to prior day: May 11 covered context engineering as part of the harness checklist. May 12 made it the dominant independent theme, with practitioners sharing specific file-based workflows and productivity measurements.
1.3 Circle Agent Stack launches machine-payable financial rails for agents 🡕¶
Circle launched Circle Agent Stack — financial infrastructure for agents built around Agent Wallets (hold and transact USDC and other tokens across blockchains), Agent Marketplace (discover and pay for x402 services per-request with no API keys), and Circle CLI (deterministic agent-native orchestration integrated with Claude Code, Cursor, Codex, and OpenClaw). The launch drew 60,679 views on the announcement post alone and was amplified by CoinMarketCap (16,217 views), Milk Road, QuickNode as a launch partner, and multiple DeFi commentators.
@circle announced (332 likes, 74 retweets, 30 replies, 60,679 views) that Agent Wallets hold and move USDC, the Agent Marketplace lets agents discover services, and Circle CLI executes repeatable financial actions within defined permissions. The Circle developer docs confirm agents can make gasless USDC nanopayments down to $0.000001 with no subscriptions or API keys, and the CLI integrates directly into any OpenAI-compatible or Claude Code workflow.
@CoinMarketCap reported (175 likes, 38 retweets, 47 replies, 16,217 views) on the launch. Replies from the CoinMarketCap audience were mixed: @TravelerOfCode called agent wallets the enabling layer for everything downstream, while @somi_ai raised a pointed concern — "on-chain payments don't claw back if an agent gets jailbroken into wiring to a random address." @AgentPays_app added that the hard problem is not the blockchain mechanics but getting fraud detection and spend controls to recognize the agent as a trusted actor rather than a threat.
@MilkRoad noted (10 likes, 4 retweets, 2,873 views) that $77B of USDC is already in circulation (up 28% YoY) and that CRCL closed +16% on announcement day, up ~50% over the prior month. Milk Road quoted @RaoulGMI: "An agent is wildly indifferent whether it's a protocol token or a dollar token, as long as it's faster, efficient, cheaper."
Discussion insight: The replies around Circle consistently focused on the orchestration and policy layer rather than the wallet itself. The consensus worry: agents with wallets need spending controls, rate limits, and jailbreak resistance before they can be trusted for autonomous financial transactions.
Comparison to prior day: May 11 covered the Circle marketplace view with agent services and pricing. May 12 was the formal launch day with developer docs, a demo, and significant media amplification.
1.4 Hermes Agent consolidates as the harness of choice for solo builders 🡒¶
Multiple independent posts praised Hermes Agent as a practical harness for individuals and small teams, with details on real deployments that went beyond the prior day's more abstract endorsements.
@shannholmberg shared (78 likes, 14 retweets, 3,959 views, 51 bookmarks) a summary of why Hermes is the highest-leverage agent framework available: task routing by complexity and cost, persistent memory across sessions without user rebuilding, and integration across the full stack rather than one tool. The attached infographic — "From Zero to Ultimate Hermes Agent Army" — is the most comprehensive visual overview of the Hermes ecosystem published this day.

@gregisenberg shared a full 47-minute course (55 likes, 7 retweets, 2,404 views, 82 bookmarks) on building a managed AI agent business solo. The stack: Hermes Agent for the agent harness, Codex or Claude Code to build and configure, Orgo for cloud VMs (each agent in its own sandbox), Composio for one-click auth across thousands of apps, Agent Mail for per-agent email, and Obsidian as the knowledge base. Model choices: GPT 5.5 for main tasks, GLM 5.1 from ZAI for cheaper tasks. Business model: managed agent services billed at $5k/month, with customers who never need to think about tokens or models. Reply from @gao035: "Agent works in demo. Agent works in production. The difference = error handling infrastructure."
@hasantoxr announced (109 likes, 11,891 views) that SureThing hit SOTA on LongMemEval with 88.0% overall accuracy, 91.0% on knowledge update, and 76.7% on single-session preference — every category that matters — and said he is replacing every memory layer he has ever built into an agent with it.
Discussion insight: The infographic from @shannholmberg reveals the Claude Code vs Hermes vs OpenClaw positioning that the community has informally settled on: Claude Code for daily coding work (Anthropic's driver), Hermes for on-the-go/self-improving/voice-first layer, OpenClaw (350K+ stars) as the alt-agent built on NVIDIA's Nemo Claw. The systems are presented as complementary, not competing.
Comparison to prior day: May 11 focused on Hermes's live execution traces and observability. May 12 moved to adoption patterns, business models built on top of it, and memory benchmarks for its underlying technology.
1.5 Skills get first-party vendor support and a marketplace surface 🡕¶
The skills layer matured from community-contributed lists into vendor-authored, app-store-style catalogs, with the Obsidian CEO personally shipping five official agent skills and a skills marketplace claiming over one million entries going live.
@dr_cintas reported (67 likes, 15 retweets, 3,258 views, 84 bookmarks) that the Obsidian CEO personally wrote five official agent skills for his own app: obsidian-markdown (wikilinks, callouts, embeds, frontmatter), obsidian-bases (database views with filters, formulas, aggregations), json-canvas (visual canvases linked to notes), obsidian-cli (search, create, manage tasks from terminal), and defuddle (clean markdown from any web page). All five are MIT licensed and work with Claude Code, Codex CLI, and OpenCode.
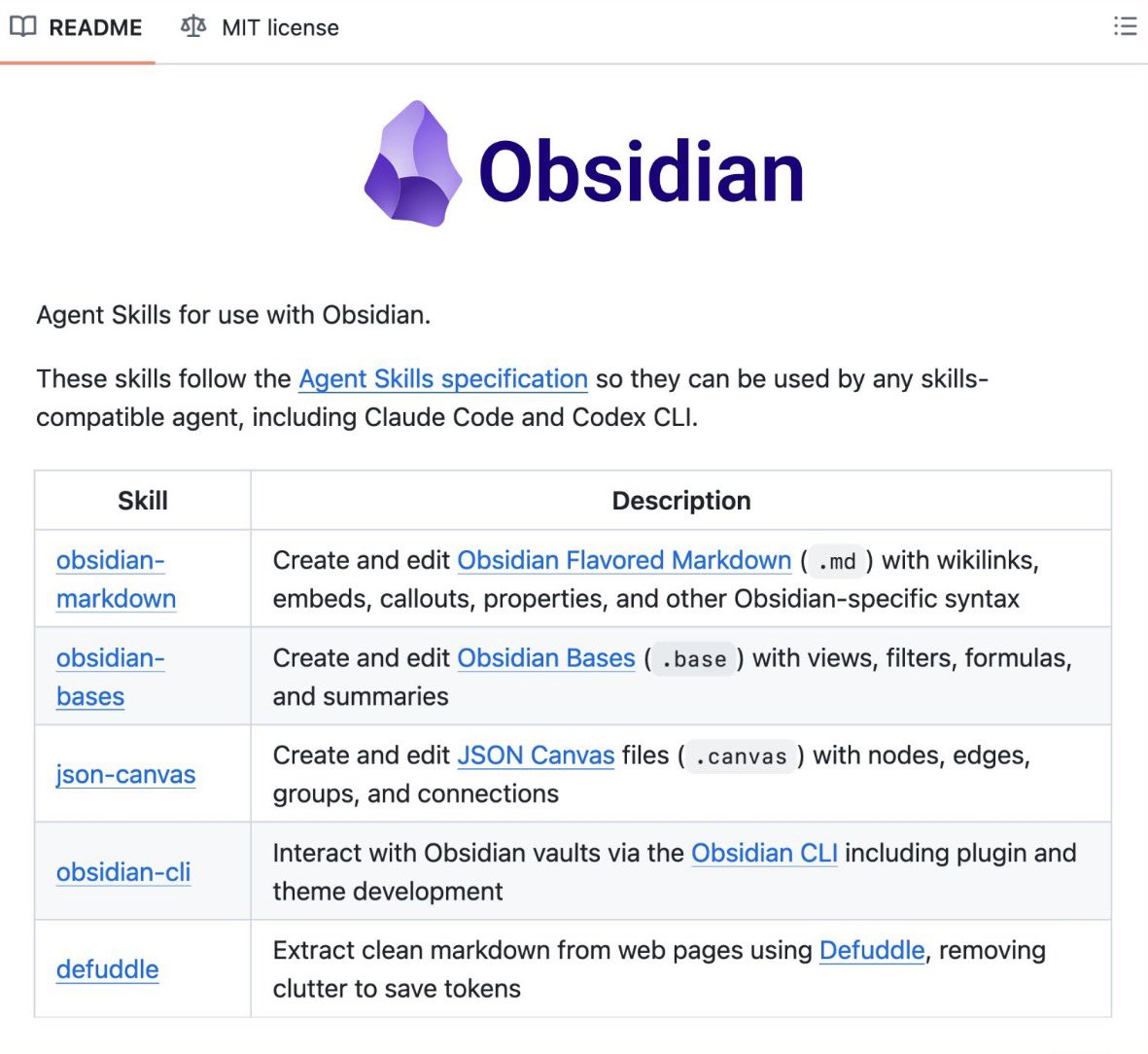
Reply from @StartupPrac_In: "defuddle cleaning markdown from any web page is the quietly useful one. agents pulling web content into obsidian has been a mess of formatting noise. that single skill removes a daily friction point."
@milesdeutscher promoted (57 likes, 90 bookmarks, 4,167 views) skillsmp.com as having over a million ready-to-use agent skills and plug-ins. Replies pushed back: @LordDr8ke demanded real working examples rather than screen-recorded demos.
@termix_ai announced (27 likes, 5 retweets, 5,171 views) that TermiX Agent Skills are now live on OpenClaw ClawHub, enabling skills discovery and coordination across autonomous agent workflows.
Discussion insight: The gap between the promise (a million skills, composable economy) and the reality (skeptical replies demanding real examples) was the sharpest tension of this theme. Vendor-authored skills from the Obsidian CEO are more credible than marketplace claims because they carry first-party validation.
Comparison to prior day: May 11 covered the notion-skills tool for syncing skills from Notion and AutoSkill's experience-driven extraction. May 12 added vendor-authored official skills and a marketplace surface — supply-side infrastructure is now shipping from multiple directions.
1.6 Multi-agent systems post quantitative wins over single-model baselines 🡕¶
Two benchmark results were shared on May 12 that provide hard numbers on the multi-agent advantage: DeepMind's Co-Mathematician topping the FrontierMath leaderboard, and Artificial Analysis publishing the first voice-agent agentic performance benchmark.
@hsu_steve summarized (38 likes, 5 retweets, 2,812 views) Google DeepMind's AI Co-Mathematician: Gemini 3.1 Pro alone achieved 19% on FrontierMath Tier 4; the multi-agent framework (literature search + code execution + iterative verification loops) added +28.9 percentage points to reach 47.9%, surpassing GPT-5.5 Pro (XHigh) at 39.6% and Claude 4.7 Opus at 22.9%. The system was given up to 48 hours of asynchronous compute per problem while OpenAI models were benchmarked on standard web harnesses.


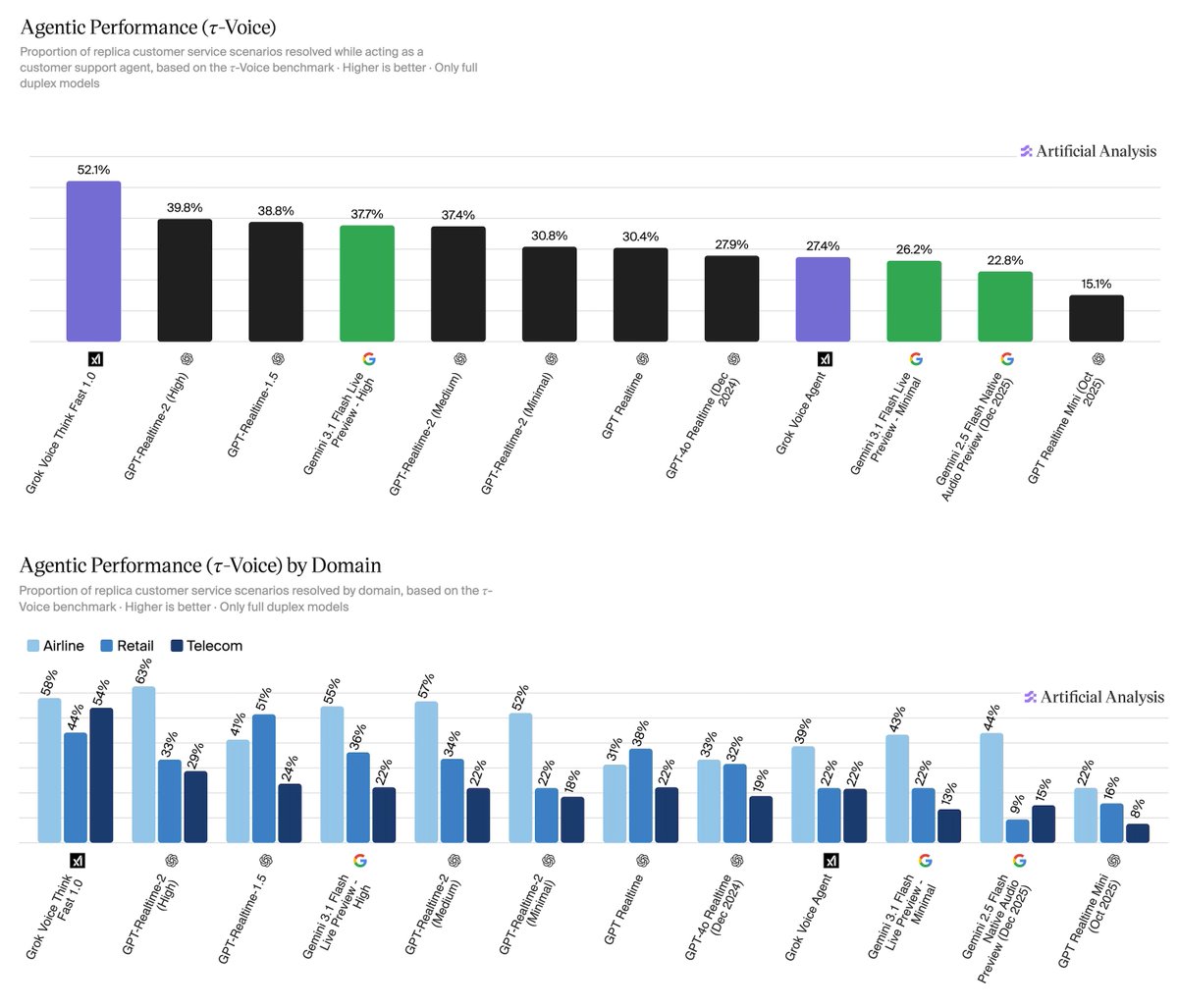
@ArtificialAnlys announced (100 likes, 7 retweets, 5,221 views, 16 bookmarks) a voice agent agentic benchmark using tau-Voice, which tests speech-to-speech models on realistic customer service scenarios. Key result: even the strongest model — Grok Voice Think Fast 1.0 at 52.1% — resolves only about half of scenarios end-to-end. GPT-Realtime-2 (High) scored 39.8%, Gemini 3.1 Flash Live Preview High scored 37.7%, with all others below 40%. The benchmark covers 278 scenarios across airline, retail, and telecom domains, using diverse accents, background noise, and packet loss modeled on real conditions.
Discussion insight: The Co-Mathematician result drew no significant skeptical replies in the feed — the benchmark methodology (asynchronous compute vs standard harness) was noted but not contested. The voice benchmark attracted no controversy; its value was the hard ceiling it documents.
Comparison to prior day: May 11 covered TradingAgents (multi-agent trading firm, 73.7K GitHub stars) as a builder signal. May 12 added two peer-reviewed benchmark results confirming the multi-agent advantage in a research domain and a production domain (voice).
2. What Frustrates People¶
Harness complexity remains the primary cost center¶
The dominant frustration — consistent with prior days — is that improvements in model capability do not reduce the engineering burden on the harness. @akshay_pachaar named ten required competencies and framed each as an independent discipline. A reply added three more. The practical implication, stated in multiple forms, is that building with agents now requires the same depth as building a production ML system, including caching strategies, observability, fallback chains, and cost attribution — none of which disappear with a better model. Severity: High. No observed workaround other than accumulating these skills individually.
Demo-to-production gap is error handling infrastructure¶
@gao035 (in replies to @gregisenberg, post link): "The gap nobody talks about: Agent works in demo ✅. Agent works in production ❌. The difference = error handling infrastructure." This was a brief but pointed reply that condensed a systemic complaint. Severity: High. The workaround cited by @gregisenberg is watchdogs for gateway crashes, auto-restore on failure, and agents that email you when cron jobs break.
Context management still fails at scale in long sessions¶
The hierarchical memory talk surfaced by @aiDotEngineer reported that Sally-Ann Delucia at Arize AI built an agent that had to analyze the very trace data it generated, and that both naive truncation and obvious summarization failed as the session grew. What held was head/tail preservation with a retrievable memory store and sub-agents for oversized context. Severity: High in long-horizon deployments. There is no off-the-shelf solution; practitioners are building custom strategies.
Prompt injection into agents with wallets is unsolved¶
@somi_ai raised the clearest statement of this risk: "on-chain payments don't claw back if an agent gets jailbroken into wiring to a random address." @AgentPays_app echoed that fraud detection needs to understand the agent as a trusted actor, not a threat signal. The risk is specific to agents with autonomous payment capability. Severity: High. No mitigating solution was cited in replies; Circle's guardrails are described but not publicly demonstrated against injection scenarios.
AI interfaces still require translating intent into machine instructions¶
@mark_k (4,554 views, 47 replies): "AI still feels too much like talking to a terminal." Replies confirmed this is a broad frustration. @Mikey100200 said editing a photo requires describing the change in precise words instead of circling the target area. Severity: Medium. Partial mitigations exist (Grok Imagine, HyperFrames Inspector, Google's experimental mouse-pointer demo) but none are mainstream.
3. What People Wish Existed¶
Persistent context infrastructure that does not require rebuilding between sessions¶
@NainsiDwiv50980 and @DamiDefi both asked, implicitly, for tooling that builds and maintains context infrastructure automatically — storing brand voice, past outputs, style violations, and audience preferences in persistent files that load every session. The current workaround is manual: .md files, Obsidian vaults, N8N pipelines, and AGENTS.md configs. What people want is a system that assembles and updates this context without the user managing it. Opportunity: direct — the market for context infrastructure tooling is active and unmet.
An agent app store with real monetization primitives for skill authors¶
@dotey (3,208 views, 4 bookmarks) made the argument explicitly: MCP handles connections, Skills handle knowledge, but the last mile — user editing and vertical workflows — is unsolved. The analogy is VSCode extensions and Chrome plug-ins: let the community contribute and charge for high-quality vertical skills, because the current skills model offers no monetization path. @dotey noted that his baoyu-skills repository has nearly 20,000 GitHub stars and has earned $0 from it. Skills are transparent and cheap to copy; a plug-in market with payment and IP protection would change that incentive. Opportunity: direct but contested — skillsmp.com, ClawHub, and Codex's early marketplace are all partial attempts.
Voice agents that actually resolve customer issues, not just handle calls¶
The tau-Voice benchmark published by @ArtificialAnlys established that even the best voice agent resolves only 52.1% of customer service scenarios. The benchmark was not accompanied by practitioner complaints in replies, but the data gap is implicit: the industry needs voice agents that handle the full tail of edge cases (accents, noise, multi-turn policy compliance) without human escalation on half of calls. Opportunity: competitive — all major AI labs are actively targeting this benchmark.
Agent governance and reputation infrastructure that earns enterprise trust¶
@Conste11ation (45 likes, 739 views): "Multi-agent systems will not earn enterprise trust on best-effort orchestration. They need deterministic substrates that generate auditable records by design. That provenance layer is what the agent economy is still missing." @Altcoinist's Virtuals.io analysis pointed at the same gap from the crypto side: immutable, onchain track records for agents enable trust in large-scale autonomous networks. Opportunity: direct for security-conscious enterprise buyers; aspirational for onchain reputation systems.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Hermes Agent | Agent harness | (+) | Persistent memory, self-improving loop, model routing by task complexity, works across the full stack; 140K GitHub stars | CLI-only until recent desktop app; not a replacement for Claude Code; some instability in multi-agent coordination |
| Claude Code | Coding agent | (+) | Daily driver for desk work; strong context engineering with AGENTS.md; Managed Agents update adds Dreaming/Outcomes/Webhooks | Permission boundaries can be bypassed via chained web-content vulnerabilities (@DarkNavyOrg demo) |
| OpenClaw | Agent harness | (+/-) | 350K+ stars; backed by NVIDIA Nemo Claw; strong ecosystem | Had a high-profile fallout with original creator (Clawnch); fragmented trust |
| LangGraph | Agent framework | (+) | Stateful pipelines, loops, branching, production-grade, full control | Steeper learning curve; high abstraction |
| CrewAI | Agent framework | (+) | Multi-agent teams, role-based tasks, readable code, fast to ship | Less production-hardened than LangGraph per practitioners |
| PydanticAI | Agent framework | (+) | Structured outputs, type-safe, native Python feel, validation-first | Less suited for long-horizon tasks |
| Google ADK | Agent framework | (+) | Five composable agent types (LlmAgent, SequentialAgent, ParallelAgent, LoopAgent, CustomAgent) | Newer; less field testing reported |
| MCP | Agent protocol | (+) | Connects agents to real-world tools across frameworks; broad adoption | Does not solve monetization for skill authors |
| Circle CLI / Agent Stack | Financial infra | (+) | Native USDC payments, no API keys, nanopayments to $0.000001, works with Claude Code/Cursor/Codex | Prompt injection into wallets is unsolved; institutional-scale resilience unproven |
| Voiceflow + Twilio | Voice agent builder | (+/-) | No-code pipeline from prompt to live call in under an hour | "No code" still requires 500-word structured system prompt; two-strike rule still escalates half of hard cases |
| Obsidian + CLAUDE.md / AGENTS.md | Context infrastructure | (+) | Persistent brand voice, reusable context, multi-session continuity; free | Manual maintenance; no automatic context update from session outcomes |
| N8N | Workflow automation | (+) | Daily inbox briefs, cron-triggered agent tasks; self-hosted | Setup friction; not agent-native |
| Orgo | Cloud VMs for agents | (+) | Each agent in its own sandbox; no server management | Less established than major cloud providers |
| Composio | App auth layer | (+) | One-click authentication across thousands of apps for agents | Dependency risk; pricing not discussed |
| SureThing | Memory layer | (+) | SOTA on LongMemEval: 88.0% overall, 91.0% knowledge update | New; no independent replication in feed |
| Cisco DefenseClaw | Agent security governance | (+) | Inspects every prompt/completion/tool call; covers 9 agents; block/approve/audit per connector; Apache-2.0 | Coverage limited to supported connectors; no prompt injection exploit defense demonstrated |
| Grok Voice Think Fast 1.0 | Speech-to-speech model | (+) | Best on tau-Voice at 52.1% task completion | Still fails on 48% of customer service scenarios; second-longest average call time (5.6 min) |
Sentiment overall is cautiously positive. The most consistent migration pattern is away from one-off prompt workflows toward persistent context-file architectures and harness-aware tooling. Multiple practitioners independently described moving away from "session-start context rebuilding" toward files that pre-load everything relevant. The dominant competitive dynamic is Hermes vs Claude Code: community consensus is that they are complementary rather than competing, with Claude Code handling deep coding sessions and Hermes handling everything else.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| TradingAgents | TauricResearch | Multi-agent trading firm with fundamental analyst, sentiment analyst, technical analyst, trader, and risk manager agents that debate and vote on trades | Single-agent trading bots lack role specialization and adversarial debate | Python, LLMs, Apache-2.0 | Shipped | GitHub · arXiv |
| Purr-Fect Agent | Pieverse | Open-source TypeScript agent harness; 60 seconds from clone to running agent with TEE-based wallet, 142 onchain skills, 5 surfaces (REPL, ACP editor, HTTP gateway, API, cron) | Agent harness with built-in onchain wallet and multi-chain skill library | TypeScript, OpenAI-compat, Anthropic, BNB Chain ecosystems | Shipped | Announced via @pieverse_io |
| Circle Agent Stack | Circle | Agent Wallets + Agent Marketplace + Circle CLI + nanopayments ($0.000001 USDC, gasless) | No native financial infrastructure for agent-to-agent commerce | USDC, x402, Circle Gateway, Claude Code / Cursor / Codex integration | Shipped | docs |
| Rail Protocol | RailProtocolOrg | Onchain program for wallet registry, transaction ledger, policy enforcement, and multi-agent payment routing written in Rust with Anchor | No auditable payment routing layer for multi-agent systems | Rust, Anchor, Solana | Shipped (internally security audited) | GitHub |
| Browser Harness (Browser Use) | Browser Use team | Python browser automation in 592 lines using direct CDP; agent writes its own tools when missing and persists them (self-healing); 11.6K stars | Browser automation frameworks add abstraction ceilings; tools don't compound | Python, Chrome CDP, MIT license | Shipped | Surfaced via @thisdudelikesAI |
| AI Co-Mathematician | DeepMind | Multi-agent workbench for mathematicians: literature search, computational exploration, theorem proving, iterative verification loops; 47.9% on FrontierMath Tier 4 | Single models plateau on hard math; human-AI collaboration needs structured iteration | Gemini 3.1 Pro + multi-agent framework | Shipped (research) | arXiv:2605.06651 |
| ClawdOS | Clawnch | Agent OS where agents run as long-running daemons (clawdaemons) with their own window, sandboxed filesystem, onchain Base wallet, and optional Farcaster identity | Current agent frameworks are stateless chat windows; agents need to behave like processes | Python, PyPI (pip install clawdaemons), Hermes Agent, Deer Flow, Base wallet | Alpha | GitHub |
| Managed AI agent business | Greg Isenberg / Nick Vasiles (Orgo) | Full playbook for solo operators: Hermes + Codex + Orgo VMs + Composio + Agent Mail + Obsidian, servicing SMB customers at $5k/month per client | Agents built for developers; business owners cannot set them up without infrastructure | Hermes, Codex, Orgo, Composio, Agent Mail, GPT 5.5, GLM 5.1 | RFC / Playbook | Video |
TradingAgents is the most structurally interesting open-source project cited on this date: role specialization across five agents that argue, debate, and vote reduces the self-grading bias of a single-agent system, and the pattern generalizes to any domain where adversarial review improves decision quality. The 73.7K GitHub stars (confirmed from the repository page) indicate the architecture has already resonated far beyond the finance use case.
ClawdOS takes a conceptually distinct position — treating agents as OS processes rather than chat sessions — and is the only project on this date that explicitly addresses the single-user/single-window limitation of all current agent frameworks. Running multiple named agent daemons with independent wallets and filesystems is closer to a server process model than a chatbot model.
6. New and Notable¶
DeepMind Co-Mathematician tops FrontierMath Tier 4 at 47.9%¶
Google DeepMind published arXiv:2605.06651, "AI Co-Mathematician: Accelerating Mathematicians with Agentic AI." The multi-agent system — built on Gemini 3.1 Pro with literature search and code execution layers — scored 47.9% on FrontierMath Tier 4, beating GPT-5.5 Pro at 39.6% and Claude 4.7 Opus at 22.9% by a significant margin. The base model alone scored 19%; the multi-agent framework contributed the full +28.9 percentage point gain. The system was given up to 48 hours of asynchronous compute per problem; OpenAI models were benchmarked on standard web harnesses, which makes the comparison partially apples-to-oranges. Still, the result is the clearest published evidence to date that multi-agent frameworks add substantial capability beyond what any single model configuration provides on hard reasoning tasks. Surfaced by @hsu_steve.
Google turns the mouse pointer into an agent interface¶
@GoogleDeepMind released experimental demos reimagining the 50-year-old mouse pointer as an AI interface — users point at screen elements and speak natural shorthand ("fix this," "move that") to direct Gemini directly on screen, without opening a prompt box. @minchoi described it as "the prompt box is dying." The demos are experimental and do not appear to be in any shipped product, but they represent the most concrete published signal that a major AI lab is actively targeting the translation-cost problem @mark_k identified.
Cisco DefenseClaw expands to cover 9 coding agents¶
@AISecHub reported that Cisco DefenseClaw (Apache-2.0, official Cisco project) now supports nine coding agents: Claude Code, OpenAI Codex, Cursor, Windsurf, Gemini CLI, GitHub Copilot, Hermes, OpenClaw, and Zeptoclaw. The product inspects every prompt, completion, and tool call that each agent makes, then blocks, approves, or audits per connector. The expansion to nine agents simultaneously signals that Cisco sees agent security governance as a horizontal infrastructure layer rather than a per-agent feature. This was published on the same day that @DarkNavyOrg demonstrated a working exploit chain against Claude Code that bypasses permission checks by combining web-content exploration with other vulnerabilities.
Anthropic Managed Agents gains Dreaming, multi-agent orchestration, Outcomes, and Webhooks¶
@Alina_with_Ai and @JulianGoldieSEO both covered a Claude Managed Agents upgrade with four new features: multi-agent orchestration for delegating tasks to specialized sub-agents; Outcomes, a rubric-based self-improvement and evaluation loop; Dreaming, where agents learn from past sessions and update memory; and Webhooks, for receiving event updates without polling. One customer reportedly improved completion rates by 6x with the Dreaming feature. A reply from @Vanarchain added the key caveat: "Memory + coordination only matters if it stays grounded in reliable execution, not just better outputs over time."
7. Where the Opportunities Are¶
[+++] Persistent context infrastructure tooling — The most consistent and repeated signal of the day: the gap between average and expert AI users is context infrastructure, not model quality or prompt skill. There is no mainstream product that builds and maintains brand voice files, style violation libraries, audience context, and session continuity automatically. Every practitioner mentioned is doing this by hand with .md files and Obsidian vaults. A tool that assembles, updates, and version-controls a user's persistent agent context would serve both solo operators and teams. Evidence spans sections 1.2, 2.1, 3.1, and 4.
[+++] Agent security governance layer — The same day that Cisco DefenseClaw expanded coverage to nine agents, a working exploit against Claude Code was demonstrated. No existing product blocks, rate-limits, or audits agent actions at scale across multiple agent runtimes simultaneously in a way that has been tested against real injection scenarios. The problem is growing faster than the solutions. Enterprise buyers have a specific need (auditable records, policy enforcement per connector) that no product fully addresses yet. Evidence in sections 1.6, 2.4, 3.4, 5, and 6.
[++] Multi-agent orchestration for domain-specific professional work — The TradingAgents architecture (role specialization + adversarial debate + vote) generalizes cleanly to any domain where adversarial review improves quality: legal document review, clinical decision support, code security audits, financial analysis. TradingAgents has 73.7K GitHub stars and an arXiv paper. The DeepMind Co-Mathematician extends the same pattern to mathematical research with a +28.9 percentage point gain from the multi-agent layer alone. The framework is open-source, the results are peer-reviewed, and no dominant product has packaged the architecture for non-technical domain buyers. Evidence in sections 1.6, 5, and 6.
[++] Voice agent reliability above the 50% threshold — The tau-Voice benchmark established that no current voice agent resolves more than 52.1% of customer service scenarios end-to-end. Call centers and appointment-booking services are already deploying voice agents, but the 50% ceiling means half of calls either escalate or fail. The gap between best performance (52.1%) and "good enough for unattended operation" (80%+) represents a meaningful engineering opportunity in noise robustness, multi-turn policy compliance, and graceful escalation logic. Evidence in sections 1.6, 3.3, and 4.
[+] Agent monetization primitives for skill authors — @dotey named the specific problem: skills are transparent, cheap to copy, and currently return $0 to authors regardless of quality or adoption. The app-store analogy (VSCode extensions, Chrome plug-ins) is well understood. The gap is a trustworthy marketplace with payment, IP protection, and quality signaling built in. Circle Agent Stack's nanopayment infrastructure is technically capable of powering per-use skill billing; what is missing is the marketplace layer above it. Evidence in sections 1.5 and 3.2.
[+] Daemonized agent runtime (agent OS model) — ClawdOS's framing — agents as long-running OS processes rather than stateless chat sessions — solves a real problem: current harnesses reset state, lose continuity, and cannot coordinate multiple simultaneous agent workloads from a shared substrate. If agents are going to perform ongoing background tasks (email triage, cron jobs, financial monitoring, code review), a daemon model is the correct abstraction. The project is in Alpha but the positioning is differentiated. Evidence in sections 1.4 and 5.
8. Takeaways¶
-
The harness engineering curriculum is now a structured, teachable body of knowledge. The addyosmani article, the Learn Harness Engineering course, and the @MindBranches mind-map collectively represent the first coherent curriculum for the discipline. The community is past "what is harness engineering" and into "where do I learn it." (akshay_pachaar, dishantwt_)
-
Machine-payable financial rails for agents are now live. Circle Agent Stack shipped Agent Wallets, Agent Marketplace, and gasless USDC nanopayments ($0.000001) on this date. The unsolved problem — prompt injection enabling unauthorized transfers — was identified within hours of launch and has no published mitigation. (circle, somi_ai via CoinMarketCap)
-
Multi-agent frameworks add more value than model upgrades at the hard end. DeepMind's Co-Mathematician achieved a +28.9 percentage point improvement on FrontierMath Tier 4 purely from adding a multi-agent framework on top of a single base model. GPT-5.5 Pro, the strongest single-model configuration tested, did not exceed 39.6%. (hsu_steve)
-
Voice agents are hitting a hard reliability ceiling at ~50% task completion. The tau-Voice benchmark is the first published agentic benchmark for speech-to-speech models in realistic conditions. The best model resolves 52.1% of customer service scenarios end-to-end; all others are below 40%. This is a quantified market gap, not a speculative one. (ArtificialAnlys)
-
Persistent context infrastructure, not prompt quality, now differentiates high-performing agent operators. Multiple independent practitioners with production results described building brand voice files, style libraries, and persistent context folders as the core leverage activity — not prompt iteration. The pattern is consistent across solo creators (6,000 ads/month), enterprise teams, and open-source builders. (NainsiDwiv50980, oliverwhudson)
-
Agent security governance is becoming enterprise infrastructure. Cisco DefenseClaw expanded to nine agents on the same day a working exploit was demonstrated against Claude Code. The attack-defense co-evolution is accelerating. Any agent deployment that uses browser tools or web content is exposed to chained vulnerability paths that current harnesses do not block. (AISecHub, DarkNavyOrg)