Twitter AI 智能体 - 2026-05-12¶
1. 人们在讨论什么¶
1.1 测试框架工程正在固化成一门有名称、可教授的学科 🡕¶
当天最强的单一信号,是“测试框架工程”继续从一个抓眼球的短语,结晶成一套结构化知识体系:文章、思维导图、课程大纲和从业者检查清单都已出现。这不是某一条爆款帖子的独角戏,而是 @addyosmani 那篇关于测试框架工程的文章,被多个账号协同放大,每个人都补上一层。
@akshay_pachaar 发布了当天互动量最高的帖子(97,031 浏览量、2,664 收藏数),把提示词缓存与语义缓存的取舍、大规模 KV cache 管理、结构化输出兜底链、evals、按功能归因成本、智能体安全护栏与循环预算、LLM 可观测性、模型路由,以及何时该做微调列为必修内容(帖子链接)。来自 @0xNeoArch 的一条回复又补上了提示词注入防御、从大模型轨迹蒸馏模型,以及“知道什么时候根本不该用 LLM”。另一条回复则指出:“运行框架占整个系统的 95%;提示词才是容易的部分。”
@MindBranches 把 @addyosmani 的文章整理成一张完整思维导图,提供 4K 浅色和深色版本,并引用了原帖子(8,434 浏览量、110 收藏数)(帖子链接)。两张图都足够细致,单独拿出来就能当参考资料。

@dishantwt_ 推出了一个结构化课程网站《Learn Harness Engineering》(7,842 浏览量、252 收藏数),涵盖的课程主题包括:为什么能力再强的智能体仍会失败、harness 到底是什么、为什么仓库必须成为事实来源、为什么单一超大指令文件会失效、为什么长时间运行的任务会丢失连续性,以及为什么功能列表本身就是 harness 原语(帖子链接)。这门课程把 OpenAI 的 Codex 测试框架工程指南和 Anthropic 关于长时运行智能体有效 harness 的文档列为主要参考。
讨论要点: 没有人反对测试框架这个框架本身。即便有不同声音,也主要来自回复里要求给出具体落地例子,而不是抽象分类。这个领域整体已经接受了这个框架;缺口在落地。
与前日对比: 5 月 11 日,测试框架工程还是一个社区信号标签。到了 5 月 12 日,它已经进入结构化教育资源和可视化文章摘要阶段。讨论的重点已经变成“去哪里学”,而不再是“它到底是什么”。
1.2 上下文工程取代提示工程,成为主要优化目标 🡒¶
另一组并行出现的帖子认为,普通 AI 用户和高手之间的生产力差距,已经不再是智力或提示词质量——而是他们维护了多少持久上下文。共同词汇是:AGENTS.md、CLAUDE.md、soul.md、品牌上下文文件、审美偏好文件。
@NainsiDwiv50980 把这种转变概括为:“提示工程已经变成新版‘学会更快打字’。”她把普通用户(泛化的角色提示词)与高阶用户区分开来:后者会把品牌语气存进 .md 文件,保存不喜欢的输出示例,并搭建可复用的上下文文件夹(908 浏览量、34 次转发)(帖子链接)。@DamiDefi 也向 11,237 浏览量的受众表达了同样观点:“坏上下文里的完美提示词,产出的仍然是泛泛之作;好上下文里的简单提示词,能胜过几乎一切。”(帖子链接)。
@oliverwhudson 描述了他的团队如何靠建设上下文基础设施、而不是写更好的提示词,每月产出 6,000 条广告——包括品牌上下文、领域上下文、Claude Skills 路由逻辑、参考文件系统、Notion MCP 集成以及质量闸门。他们的报告技能每月能为每位创意策略师节省 2 天,而推理轨迹会记录每一个策略决策,让系统随着时间持续复利(1,529 浏览量、34 收藏数)(帖子链接)。
@mark_k 则指出了更深层的问题:AI 仍要求用户不断把自己的意图翻译成机器友好的指令,而真正的突破,是一种界面,让人们可以直接说、展示、指向、打断和纠正,而不必把思路重新格式化(4,554 浏览量、47 条回复)(帖子链接)。他还在回复里预测,未来会是由 AI 为当前任务动态生成的 UI。
讨论要点: 最有实质内容的回复,把上下文主题延伸到了工具层:Obsidian vault、N8N 工作流、CLAUDE.md 文件和多智能体记忆存储都被举作实际做法。模式很一致——持久、机器可读的上下文文件会不断复利,而临时提示词很快触顶。
与前日对比: 5 月 11 日,上下文工程还只是测试框架清单中的一部分。到了 5 月 12 日,它成了独立且占主导的主题,实践者开始分享具体的文件化工作流和生产力数据。
1.3 Circle Agent Stack 推出面向智能体的可机器支付金融基础设施 🡕¶
Circle 推出了 Circle Agent Stack——一套面向智能体的金融基础设施,围绕 Agent Wallets(可在多条区块链上持有并转移 USDC 和其他 token)、Agent Marketplace(无需 API 密钥,智能体即可按请求发现并支付 x402 服务)以及 Circle CLI(可重复、确定性的原生智能体编排,已集成 Claude Code、Cursor、Codex 和 OpenClaw)构建。仅公告帖就获得 60,679 浏览量,CoinMarketCap(16,217 浏览量)、Milk Road、作为首发合作伙伴的 QuickNode,以及多位 DeFi 评论员都跟着放大了声量。
@circle 宣布(332 点赞、74 次转发、30 条回复、60,679 浏览量),Agent Wallets 负责持有和转移 USDC,Agent Marketplace 让智能体发现服务,Circle CLI 则在既定权限内执行可重复的金融动作。Circle 的开发者文档确认,智能体可以在无需订阅或 API 密钥的情况下发起低至 $0.000001 的免 gas USDC 纳支付,而且 CLI 能直接接入任何兼容 OpenAI 或 Claude Code 的工作流。
@CoinMarketCap 报道(175 点赞、38 次转发、47 条回复、16,217 浏览量)了这次发布。CoinMarketCap 受众的回复看法不一:@TravelerOfCode 认为,智能体钱包是后续一切能力的使能层;而 @somi_ai 则尖锐地提醒:“如果智能体被越狱后把钱打到一个随机地址,链上支付可不会撤回。”@AgentPays_app 还补充说,真正的难点不在区块链机制,而在于让欺诈检测和支出控制把智能体识别为可信执行者,而不是威胁。
@MilkRoad 提到(10 点赞、4 次转发、2,873 浏览量),USDC 流通量已达 $77B(同比增长 28%),CRCL 在公告当天收涨 16%,较前一个月累计上涨约 50%。Milk Road 引述 @RaoulGMI:“智能体根本不在乎那是协议 token 还是美元 token,只要更快、更高效、更便宜就行。”
讨论要点: 围绕 Circle 的回复,焦点始终不在钱包本身,而在编排和策略层。共识性的担忧是:带钱包的智能体必须先有支出控制、限流和抗越狱能力,才能让人相信它适合自主处理金融交易。
与前日对比: 5 月 11 日覆盖的是 Circle 市场视角——智能体服务和定价。5 月 12 日则是正式发布日,开发者文档、demo 和媒体放大传播都齐了。
1.4 Hermes Agent 正巩固为个人开发者首选的运行框架 🡒¶
多条相互独立的帖子都称赞 Hermes Agent 是个人和小团队可落地的运行框架,并给出了真实部署细节,不再像前一天那样只是抽象背书。
@shannholmberg 分享(78 点赞、14 次转发、3,959 浏览量、51 收藏数)了一份总结,解释为什么 Hermes 是当前杠杆最高的智能体框架:按复杂度和成本做任务路由、跨会话持久记忆而无需用户手动重建,以及覆盖全栈而非单一工具的集成。附带的信息图《From Zero to Ultimate Hermes Agent Army》是当天发布的 Hermes 生态最完整的可视化总览。

@gregisenberg 分享了一门完整的 47 分钟课程(55 点赞、7 次转发、2,404 浏览量、82 收藏数),讲如何独自搭建托管式 AI 智能体业务。技术栈包括:作为智能体运行框架的 Hermes Agent、用于构建与配置的 Codex 或 Claude Code、用于云 VM 的 Orgo(每个智能体都在自己的沙箱里)、负责跨数千应用一键鉴权的 Composio、为每个智能体提供邮箱的 Agent Mail,以及作为知识库的 Obsidian。模型选择是:主任务用 GPT 5.5,更便宜的任务用 ZAI 的 GLM 5.1。商业模式是每月 $5k 的托管式智能体服务,客户完全不需要关心 token 或模型。@gao035 回复说:“能在 demo 里跑通的智能体,和能在生产里跑通的智能体,差别就在错误处理基础设施。”
@hasantoxr 宣布(109 点赞、11,891 浏览量),SureThing 在 LongMemEval 上拿到 SOTA:总体准确率 88.0%,知识更新 91.0%,单会话偏好 76.7%——每一项都是关键指标——并表示他会把自己过去给智能体做过的每一层记忆,都替换成它。
讨论要点: @shannholmberg 的信息图揭示了社区非正式达成的 Claude Code vs Hermes vs OpenClaw 定位:Claude Code 负责日常编码工作(Anthropic 的主力)、Hermes 负责移动场景 / 自我改进 / 语音优先层,OpenClaw(350K+ GitHub stars)则是基于 NVIDIA Nemo Claw 的替代系智能体。社区更把这些系统看成互补关系,而不是竞争关系。
与前日对比: 5 月 11 日聚焦的是 Hermes 的实时执行轨迹和可观测性。5 月 12 日则转向采用模式、基于它构建的商业模式,以及支撑它的记忆基准。
1.5 Skills 获得第一方厂商支持,并出现市场化入口 🡕¶
技能层已经从社区贡献的清单,走向厂商亲自编写、类似应用商店的目录:Obsidian CEO 亲自发布了 5 个官方智能体技能,同时一个宣称收录超过 100 万条目的技能市场也已上线。
@dr_cintas 报道(67 点赞、15 次转发、3,258 浏览量、84 收藏数),Obsidian CEO 亲自为自己的应用写了 5 个官方智能体技能:obsidian-markdown(wikilinks、callouts、embeds、frontmatter)、obsidian-bases(支持 filters、formulas、aggregations 的数据库视图)、json-canvas(与笔记相连的可视化画布)、obsidian-cli(从终端搜索、创建和管理任务),以及 defuddle(把任何网页清理成 markdown)。这 5 个技能都采用 MIT 许可,并可与 Claude Code、Codex CLI 和 OpenCode 配合使用。
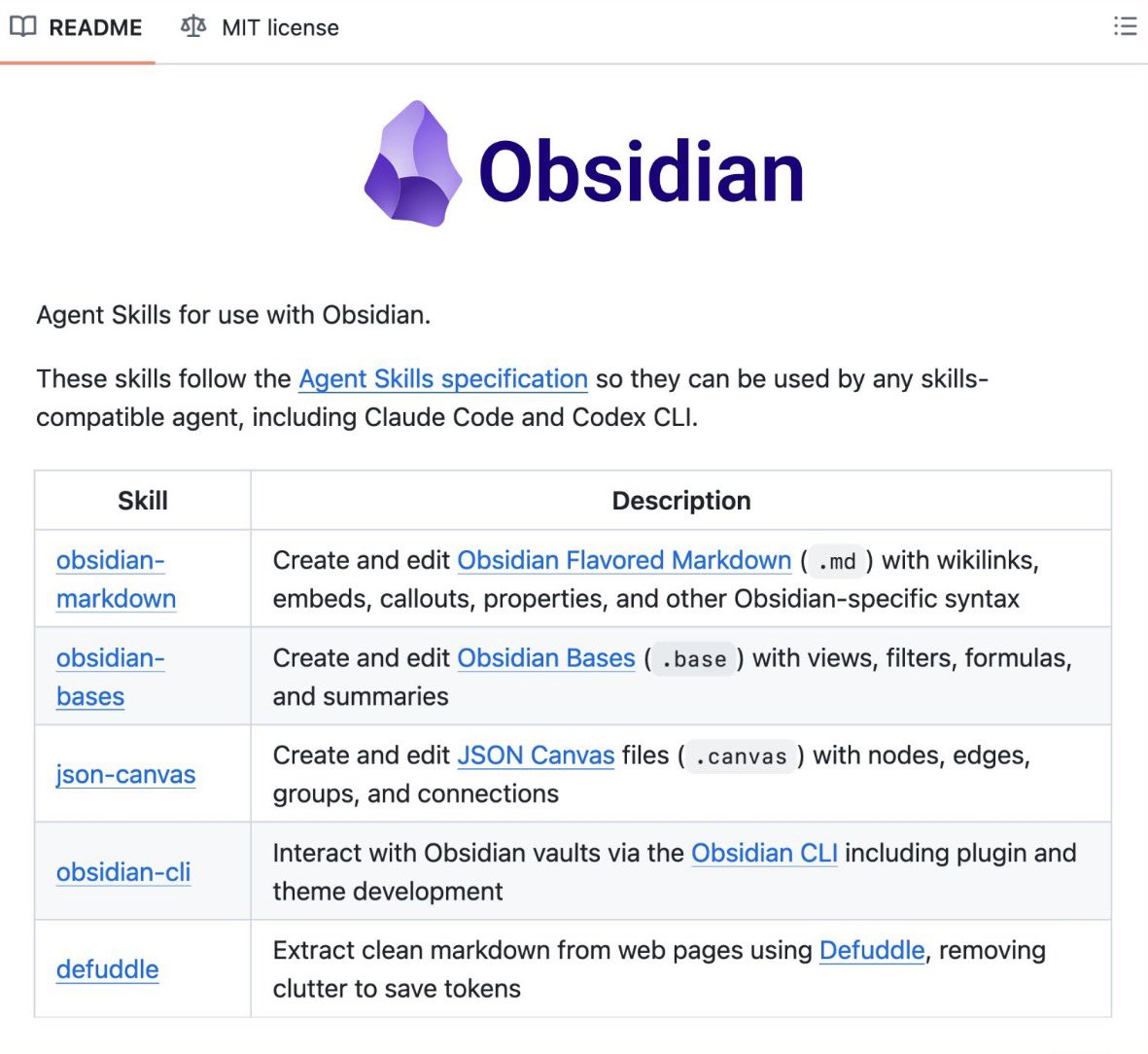
来自 @StartupPrac_In 的回复说:“defuddle 才是那个低调但特别有用的。智能体把网页内容拉进 Obsidian 时,一直是一团格式噪音;这一个技能就去掉了一个日常摩擦点。”
@milesdeutscher 宣传(57 点赞、90 收藏数、4,167 浏览量)skillsmp.com 拥有超过 100 万个即用型智能体技能与插件。回复里有人提出异议:@LordDr8ke 要求看到真正能跑的例子,而不是录屏 demo。
@termix_ai 宣布(27 点赞、5 次转发、5,171 浏览量),TermiX Agent Skills 已在 OpenClaw ClawHub 上线,可在自主智能体工作流之间支持技能发现与协同。
讨论要点: “一百万个技能、可组合经济”这样的承诺,与回复里“拿出真实案例”的怀疑之间,构成了这一主题最尖锐的张力。相比 marketplace 的宏大口号,Obsidian CEO 亲自编写的厂商官方技能更可信,因为它们带有第一方验证。
与前日对比: 5 月 11 日覆盖的是 notion-skills 这种从 Notion 同步技能的工具,以及 AutoSkill 这种从经验中提取技能的方法。5 月 12 日则补上了厂商亲自编写的官方技能和 marketplace 入口——供给侧基础设施正从多个方向一起上线。
1.6 多智能体系统在量化结果上胜过单模型基线 🡕¶
5 月 12 日分享的两项基准结果,为多智能体优势给出了硬数字:DeepMind 的 Co-Mathematician 登顶 FrontierMath 排行榜,Artificial Analysis 也发布了首个语音智能体的智能体式性能基准。
@hsu_steve 总结(38 点赞、5 次转发、2,812 浏览量)了 Google DeepMind 的 AI Co-Mathematician:单独使用 Gemini 3.1 Pro 时,在 FrontierMath Tier 4 上得分 19%;加入多智能体框架(文献检索 + 代码执行 + 迭代验证循环)后,成绩提升 28.9 个百分点,达到 47.9%,超过 GPT-5.5 Pro(XHigh)的 39.6% 和 Claude 4.7 Opus 的 22.9%。该系统每道题最多可使用 48 小时异步算力,而 OpenAI 模型则是在标准网页测试框架上跑出来的成绩。


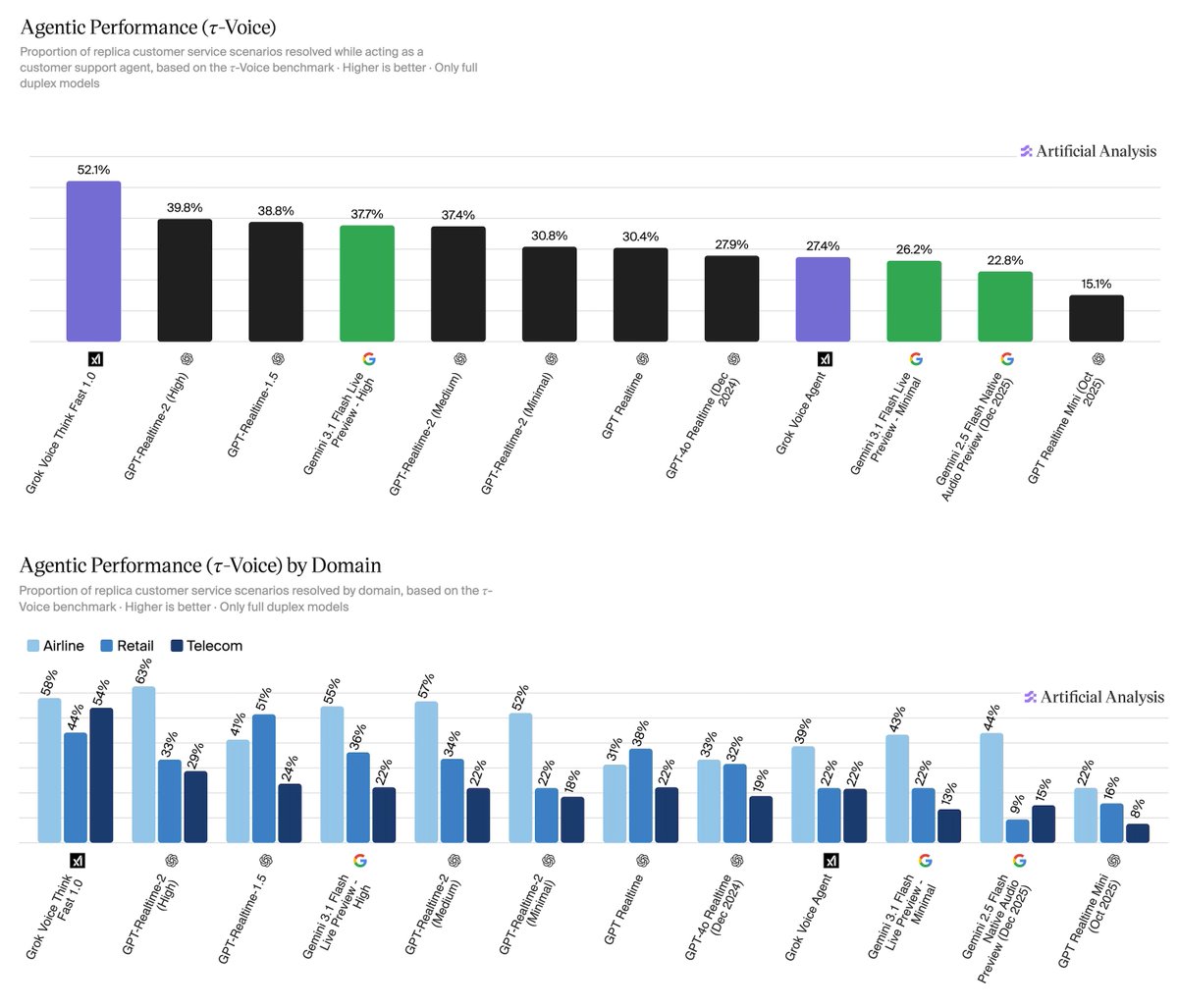
@ArtificialAnlys 宣布(100 点赞、7 次转发、5,221 浏览量、16 收藏数)发布了使用 tau-Voice 的语音智能体基准,它在逼真的客服场景中测试语音到语音模型。关键结果是:即便是最强模型——Grok Voice Think Fast 1.0,得分 52.1%——也只能端到端解决大约一半场景。GPT-Realtime-2(High)得分 39.8%,Gemini 3.1 Flash Live Preview High 得分 37.7%,其余模型全部低于 40%。该基准覆盖航空、零售和电信 278 个场景,并纳入多样口音、背景噪声,以及按真实条件建模的丢包。
讨论要点: Co-Mathematician 的结果在时间线里几乎没有引来实质性怀疑——有人注意到基准方法(异步算力 vs 标准运行框架)的差异,但没人真正反对。语音基准也没有引发争议;它的价值在于把当前天花板量化出来。
与前日对比: 5 月 11 日覆盖的是 TradingAgents(多智能体交易公司,73.7K GitHub stars)这一构建者信号。5 月 12 日则补上了两项经同行评审的基准结果,确认多智能体优势已经在研究领域和生产领域(语音)都跑出了数据。
2. 令人困扰的问题¶
测试框架复杂度仍是主要成本中心¶
这种最主要的挫败感——也与前几天一致——在于:模型能力的提升,并没有减轻测试框架上的工程负担。@akshay_pachaar 点名列出 10 项必备能力,并把每一项都说成一门独立学科;一条回复又补了 3 项。多种表达归结到同一个实际含义:如今用智能体做构建,所需深度已经和搭建生产级 ML 系统一样,包括缓存策略、可观测性、兜底链和成本归因——这些都不会因为模型更强就消失。严重程度:高。除了一项项把这些能力补齐之外,今天没有观察到其他权宜方案。
从 demo 到生产的落差,其实是错误处理基础设施¶
@gao035(在回复 @gregisenberg 时,帖子链接)说:“没人谈的那道鸿沟:智能体在 demo 里能跑 ✅。智能体在生产里能跑 ❌。差别 = 错误处理基础设施。”这条回复虽然简短,却把一个系统性抱怨浓缩得很到位。严重程度:高。@gregisenberg 给出的应对方式,是为网关崩溃设置 watchdog、失败时自动恢复,以及在 cron 任务出问题时让智能体发邮件通知你。
长会话场景下的上下文管理一旦规模化仍会失效¶
@aiDotEngineer 转发的一场关于分层记忆的演讲提到,Arize AI 的 Sally-Ann Delucia 构建过一个智能体,它必须分析自己生成的 trace 数据,而随着会话变长,朴素截断和直白摘要都失败了。真正能撑住的做法,是保留头尾上下文,配合可检索记忆存储,以及在上下文过大时启用子智能体。严重程度:在长时程部署中为高。现成方案仍然没有;实践者都在自建策略。
带钱包的智能体的提示词注入问题仍无解¶
@somi_ai 给出了 这个风险最清晰的表述:“如果智能体被越狱后把钱打到一个随机地址,链上支付可不会撤回。”@AgentPays_app 也附和说,欺诈检测需要把智能体理解成可信执行者,而不是威胁信号。这一风险专属于具备自主支付能力的智能体。严重程度:高。回复里没有提到任何缓解方案;Circle 描述了安全护栏,但尚未公开演示它们如何抵御注入场景。
AI 界面仍然要求用户把意图翻译成机器指令¶
@mark_k(4,554 浏览量、47 条回复)说:“AI 现在还是太像在和终端说话了。”回复证明这是一种广泛挫败感。@Mikey100200 说,修一张照片时,人们仍得用精确文字描述改动,而不是直接圈出目标区域。严重程度:中。已有部分缓解方案(Grok Imagine、HyperFrames Inspector、Google 的实验性鼠标指针 demo),但都还没有进入主流。
3. 人们期望的功能¶
无需在会话之间反复重建的持久上下文基础设施¶
@NainsiDwiv50980 和 @DamiDefi 都在隐含地要求一种工具:能自动构建并维护上下文基础设施——把品牌语气、过往输出、风格违规、受众偏好存进每次会话都会加载的持久文件。当前的权宜做法仍然是手工:.md 文件、Obsidian vault、N8N 流程和 AGENTS.md 配置。人们真正想要的是一套系统,能在用户不亲自管理的情况下自动组装并更新这些上下文。机会:直接——上下文基础设施工具市场活跃,但需求仍未被满足。
为技能作者提供真实变现能力的智能体应用商店¶
@dotey(3,208 浏览量、4 收藏数)把论点说得很直白:MCP 负责连接,技能负责知识,但最后一公里——用户编辑和垂直工作流——还没解决。类比对象是 VSCode 扩展和 Chrome 插件:让社区贡献,并为高质量的垂直技能收费,因为当前的技能模式根本没有变现路径。@dotey 提到,他的 baoyu-skills 仓库已经接近 20,000 GitHub stars,却从中赚到 $0。技能是透明的、复制成本低;如果有一个同时具备支付和 IP 保护的插件市场,激励就会变。机会:直接,但存在竞争——skillsmp.com、ClawHub 和 Codex 早期 marketplace 都只是部分尝试。
真正能解决客户问题、而不只是接电话的语音智能体¶
@ArtificialAnlys 发布的 tau-Voice 基准表明,即便最好的语音智能体,也只能解决 52.1% 的客服场景。回复里虽然没有出现实践者抱怨,但数据缺口本身已经说明问题:行业需要的是能覆盖长尾边界情况(口音、噪声、多轮策略遵循)、并且不用在一半电话上转人工的语音智能体。机会:竞争型——所有主要 AI 实验室都在积极冲这个基准。
能赢得企业信任的智能体治理与信誉基础设施¶
@Conste11ation(45 点赞、739 浏览量)说:“多智能体系统不可能靠尽力而为式编排赢得企业信任。它们需要的是按设计就能生成可审计记录的确定性底座。智能体经济缺的,正是这层可溯源基础设施。”@Altcoinist 对 Virtuals.io 的分析,则从加密方向指出了同一个缺口:面向智能体的不可篡改链上履历,能让大规模自主网络建立信任。机会:对注重安全的企业买家来说很直接;对链上信誉系统来说则更偏愿景。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Hermes Agent | 智能体运行框架 | (+) | 持久记忆、自我改进循环、按任务复杂度做模型路由、覆盖全栈;140K GitHub stars | 直到最近都只有 CLI;不是 Claude Code 的替代品;多智能体协同仍有些不稳定 |
| Claude Code | 编程智能体 | (+) | 日常桌面工作主力;借助 AGENTS.md 的上下文工程很强;Managed Agents 更新带来 Dreaming / Outcomes / Webhooks | 权限边界可被链式网页内容漏洞绕过(@DarkNavyOrg 演示) |
| OpenClaw | 智能体运行框架 | (+/-) | 350K+ stars;有 NVIDIA Nemo Claw 背书;生态强 | 与原作者(Clawnch)发生高关注度分裂;信任分散 |
| LangGraph | 智能体框架 | (+) | 有状态管道、循环、分支;生产级;控制力强 | 学习曲线更陡;抽象层较高 |
| CrewAI | 智能体框架 | (+) | 多智能体团队、基于角色的任务、代码易读、交付快 | 按实践者反馈,生产成熟度不如 LangGraph |
| PydanticAI | 智能体框架 | (+) | 结构化输出、类型安全、原生 Python 体验、验证优先 | 不太适合长时程任务 |
| Google ADK | 智能体框架 | (+) | 5 种可组合智能体类型(LlmAgent、SequentialAgent、ParallelAgent、LoopAgent、CustomAgent) | 较新;公开的实战验证还不多 |
| MCP | 智能体协议 | (+) | 让不同框架里的智能体连上真实世界工具;采用广泛 | 不解决技能作者的变现问题 |
| Circle CLI / Agent Stack | 金融基础设施 | (+) | 原生 USDC 支付、无需 API 密钥、支持低至 $0.000001 的纳支付,可配合 Claude Code / Cursor / Codex | 钱包提示词注入仍无解;机构级韧性尚未验证 |
| Voiceflow + Twilio | 语音智能体构建器 | (+/-) | 不到 1 小时即可从提示词到真实通话的无代码流程 | “无代码”仍需 500 词结构化系统提示词;两次失败规则仍会把一半难例转给人工 |
| Obsidian + CLAUDE.md / AGENTS.md | 上下文基础设施 | (+) | 持久品牌语气、可复用上下文、多会话连续性;免费 | 需要手动维护;不会根据会话结果自动更新上下文 |
| N8N | 工作流自动化 | (+) | 每日 inbox 简报、cron 触发的智能体任务;可自托管 | 上手有摩擦;不是原生面向智能体的工具 |
| Orgo | 智能体云 VM | (+) | 每个智能体独立沙箱;无需管理服务器 | 不如主流云厂商成熟 |
| Composio | 应用鉴权层 | (+) | 为智能体提供跨数千应用的一键鉴权 | 依赖风险;定价未讨论 |
| SureThing | 记忆层 | (+) | LongMemEval 上 SOTA:总体 88.0%,知识更新 91.0% | 较新;信息流里暂无独立复现 |
| Cisco DefenseClaw | 智能体安全治理 | (+) | 检查每次 prompt / completion / tool call;覆盖 9 个智能体;可按 connector 执行拦截 / 批准 / 审计;Apache-2.0 | 覆盖范围受支持 connector 限制;尚未展示针对提示词注入利用链的防御 |
| Grok Voice Think Fast 1.0 | 语音到语音模型 | (+) | tau-Voice 上最佳,任务完成率 52.1% | 仍会在 48% 的客服场景中失败;平均通话时长第二长(5.6 分钟) |
整体评价偏谨慎乐观。最一致的迁移模式,是从一次性提示词工作流转向持久上下文文件架构,以及与运行框架配套的工具链。多位实践者分别描述了同一变化:不再“每次会话开始都重建上下文”,而是改用能预加载一切必要信息的文件。当前最主要的竞争动态是 Hermes vs Claude Code:社区共识认为两者是互补关系,而非直接竞争,Claude Code 处理深入的编码会话,Hermes 处理其他大多数事情。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| TradingAgents | TauricResearch | 由基本面分析师、情绪分析师、技术分析师、交易员和风控经理智能体组成的多智能体交易公司,会围绕交易辩论并投票 | 单智能体交易机器人缺少角色专业化和对抗式辩论 | Python、LLMs、Apache-2.0 | 已发布 | GitHub · arXiv |
| Purr-Fect Agent | Pieverse | 开源 TypeScript 智能体运行框架;从 clone 到跑通智能体只要 60 秒,带基于 TEE 的钱包、142 个链上技能、5 个入口(REPL、ACP editor、HTTP gateway、API、cron) | 内置链上钱包和多链技能库的智能体运行框架 | TypeScript、OpenAI-compat、Anthropic、BNB Chain 生态 | 已发布 | 由 @pieverse_io 宣布 |
| Circle Agent Stack | Circle | Agent Wallets + Agent Marketplace + Circle CLI + 纳支付($0.000001 USDC、免 gas) | 智能体间商业交易缺少原生金融基础设施 | USDC、x402、Circle Gateway、Claude Code / Cursor / Codex 集成 | 已发布 | 文档 |
| Rail Protocol | RailProtocolOrg | 用 Rust 和 Anchor 编写的链上程序,提供钱包注册表、交易台账、策略执行和多智能体支付路由 | 多智能体系统缺少可审计的支付路由层 | Rust、Anchor、Solana | 已发布(内部已做安全审计) | GitHub |
| Browser Harness (Browser Use) | Browser Use team | 仅 592 行的 Python 浏览器自动化,直接使用 CDP;缺工具时智能体会自己编写并持久化(自愈);11.6K stars | 浏览器自动化框架会抬高抽象天花板;工具无法复利 | Python、Chrome CDP、MIT 许可 | 已发布 | 由 @thisdudelikesAI 发掘 |
| AI Co-Mathematician | DeepMind | 面向数学家的多智能体工作台:文献检索、计算探索、定理证明、迭代验证循环;FrontierMath Tier 4 达到 47.9% | 单模型在高难数学上进入平台期;人机协作需要结构化迭代 | Gemini 3.1 Pro + 多智能体框架 | 已发布(研究) | arXiv:2605.06651 |
| ClawdOS | Clawnch | 把智能体作为长期运行 daemon(clawdaemons)来运行的 Agent OS,具备独立窗口、沙箱文件系统、链上 Base 钱包和可选 Farcaster 身份 | 当前智能体框架是无状态聊天窗口;智能体需要像进程一样工作 | Python、PyPI(pip install clawdaemons)、Hermes Agent、Deer Flow、Base wallet | Alpha | GitHub |
| Managed AI agent business | Greg Isenberg / Nick Vasiles (Orgo) | 面向单人运营者的完整 playbook:Hermes + Codex + Orgo VMs + Composio + Agent Mail + Obsidian,为 SMB 客户提供每位客户 $5k/月 的服务 | 智能体是为开发者打造的;没有基础设施,企业主根本搭不起来 | Hermes、Codex、Orgo、Composio、Agent Mail、GPT 5.5、GLM 5.1 | RFC / Playbook | 视频 |
TradingAgents 是当天被提到的开源项目里,结构上最有意思的一个:5 个智能体各司其职、彼此争论、辩论并投票,这种角色专业化降低了单智能体系统自我评分的偏差,而且这个模式可以泛化到任何“对抗式审查能提高决策质量”的领域。73.7K GitHub stars(已从仓库页确认)说明,这套架构的吸引力早已超出金融场景。
ClawdOS 的定位在概念上明显不同——它把智能体当成 OS 进程,而不是聊天会话——也是当天唯一一个明确回应“当前所有智能体框架都只能服务单用户、单窗口”限制的项目。运行多个具名智能体 daemon,每个都有独立钱包和文件系统,这种模式更像服务器进程,而不像聊天机器人。
6. 新动态与亮点¶
DeepMind Co-Mathematician 以 47.9% 登顶 FrontierMath Tier 4¶
Google DeepMind 发布了 arXiv:2605.06651,《AI Co-Mathematician: Accelerating Mathematicians with Agentic AI》。这个多智能体系统——基于 Gemini 3.1 Pro,并加入文献检索和代码执行层——在 FrontierMath Tier 4 上拿到 47.9%,显著高于 GPT-5.5 Pro 的 39.6% 和 Claude 4.7 Opus 的 22.9%。基础模型单独只有 19%;多智能体框架贡献了完整的 +28.9 个百分点增益。该系统每道题最多使用 48 小时异步算力;OpenAI 模型则是在标准网页测试框架上跑分,因此这组比较并非完全可比。即便如此,这仍是迄今最清晰的公开证据,说明多智能体框架在高难推理任务上,能带来超出任何单模型配置的实质能力提升。由 @hsu_steve 发掘。
Google 把鼠标指针变成智能体界面¶
@GoogleDeepMind 发布了实验性 demo,把已有 50 年历史的鼠标指针重新想象成 AI 界面——用户只需指向屏幕元素,再说一句自然简写(“修这个”“把那个移过去”),就能直接在屏幕上驱动 Gemini,无需打开提示框。@minchoi 把它形容为:“提示框正在死去。”这些 demo 仍处实验阶段,看起来还没进入任何已发布产品,但它们是目前最具体的公开信号,说明大型 AI 实验室确实在积极攻克 @mark_k 指出的翻译成本问题。
Cisco DefenseClaw 扩展至覆盖 9 个编程智能体¶
@AISecHub 报道称,Cisco DefenseClaw(Apache-2.0、Cisco 官方项目)现在已经支持 9 个编程智能体:Claude Code、OpenAI Codex、Cursor、Windsurf、Gemini CLI、GitHub Copilot、Hermes、OpenClaw 和 Zeptoclaw。该产品会检查每一次 prompt、completion 和 tool call,再按 connector 执行拦截、批准或审计。一下子扩展到 9 个智能体,说明 Cisco 把智能体安全治理视为横向基础设施层,而不是某个单一智能体的附属功能。巧合的是,就在同一天,@DarkNavyOrg 演示了一条针对 Claude Code 的可运行利用链:它把网页内容探索和其他漏洞串在一起,从而绕过权限检查。
Anthropic Managed Agents 新增 Dreaming、多智能体编排、Outcomes 和 Webhooks¶
@Alina_with_Ai 和 @JulianGoldieSEO 都提到了 Claude Managed Agents 的一次升级,加入 4 个新功能:可把任务委派给专用子智能体的多智能体编排;基于 rubric 的自我改进与评估循环 Outcomes;让智能体从过往会话学习并更新记忆的 Dreaming;以及无需轮询即可接收事件更新的 Webhooks。据称,有一位客户借助 Dreaming 功能把完成率提高了 6 倍。来自 @Vanarchain 的回复补上了关键限定:“Memory + coordination 只有在它始终建立在可靠执行之上时才有意义,而不是只让输出随着时间推移变得更好。”
7. 机会在哪里¶
[+++] 持久上下文基础设施工具 — 当天最反复、最一致的信号是:普通与高手 AI 用户之间的差距,不在模型质量或提示词技巧,而在上下文基础设施。市面上没有主流产品能自动构建并维护品牌语气文件、风格违规库、受众上下文和会话连续性。文中提到的每位实践者,都是靠 .md 文件和 Obsidian vault 手工做这些事。谁能做出一款工具,把用户的持久智能体上下文自动组装、更新并做版本控制,谁就能同时服务单人操作者和团队。证据见 1.2、2.1、3.1 和 4 节。
[+++] 智能体安全治理层 — Cisco DefenseClaw 扩展到 9 个智能体的同一天,Claude Code 也出现了一条可运行的利用链演示。目前还没有产品能以可扩展方式,在多个智能体运行时之间同时拦截、限流和审计动作,并且经过真实注入场景验证。问题扩张的速度快于解决方案。企业买方的需求也很具体(可审计记录、按 connector 执行策略),但目前仍没有产品真正完整覆盖。证据见 1.6、2.4、3.4、5 和 6 节。
[++] 面向专业领域工作的多智能体编排 — TradingAgents 的架构(角色专业化 + 对抗式辩论 + 投票)可以自然泛化到任何“对抗式审查能提高质量”的行业:法律文档审查、临床决策支持、代码安全审计、金融分析。TradingAgents 拥有 73.7K GitHub stars 和一篇 arXiv 论文。DeepMind Co-Mathematician 则把同一模式延伸到数学研究,并仅靠多智能体层就带来 +28.9 个百分点提升。框架是开源的,结果也经同行评审,但还没有主导性产品把这套架构打包给非技术行业买家。证据见 1.6、5 和 6 节。
[++] 超过 50% 阈值的语音智能体可靠性 — tau-Voice 基准表明,目前没有任何语音智能体能在端到端上解决超过 52.1% 的客服场景。呼叫中心和预约服务已经在部署语音智能体,但 50% 的天花板意味着一半电话不是转人工,就是失败。最佳表现(52.1%)与“足够支持无人值守运行”(80%+)之间的差距,是噪声鲁棒性、多轮策略遵循和优雅升级逻辑上的实打实工程机会。证据见 1.6、3.3 和 4 节。
[+] 技能作者的变现基础能力 — @dotey 点出了具体问题:技能是透明的、容易复制,而且无论质量或采用度如何,目前都给作者带来 $0 收入。应用商店类比(VSCode 扩展、Chrome 插件)大家都很理解。缺的,是一个内建支付、IP 保护和质量信号的可信市场。Circle Agent Stack 的纳支付基础设施在技术上已经能支持按次计费的技能付费;缺的只是上层市场。证据见 1.5 和 3.2 节。
[+] 守护进程化的智能体运行时(agent OS 模型) — ClawdOS 的定位方式——把智能体视为长期运行的 OS 进程,而不是无状态聊天会话——解决的是一个真实问题:当前运行框架会重置状态、丢失连续性,也无法在共享底座上协调多个同时运行的智能体工作负载。如果智能体真要承担持续的后台任务(邮件分拣、cron 任务、财务监控、代码审查),daemon 模型就是正确抽象。这个项目还在 Alpha,但定位明确且有差异化。证据见 1.4 和 5 节。
8. 要点总结¶
-
测试框架工程如今已经是一套结构化、可教授的知识体系。 @addyosmani 的文章、《Learn Harness Engineering》课程,以及 @MindBranches 的思维导图,共同构成了这门学科第一套连贯课程体系。社区已经越过“什么是测试框架工程”,进入“去哪里学它”。 (akshay_pachaar, dishantwt_)
-
面向智能体的机器可支付金融轨道已经上线。 Circle Agent Stack 在这一天发布了 Agent Wallets、Agent Marketplace,以及免 gas 的 USDC 纳支付($0.000001)。而仍未解决的问题——提示词注入导致未授权转账——在上线数小时内就被点名,目前也没有公开缓解方案。 (circle, somi_ai via CoinMarketCap)
-
多智能体框架在高难场景里的价值,已经超过单纯升级模型。 DeepMind 的 Co-Mathematician 仅通过在单一基础模型上叠加多智能体框架,就在 FrontierMath Tier 4 上提升了 28.9 个百分点。被测的最强单模型配置 GPT-5.5 Pro,也没有超过 39.6%。 (hsu_steve)
-
语音智能体在任务完成率约 50% 处撞上了硬天花板。 tau-Voice 是首个在真实条件下评估语音到语音模型的公开智能体基准。最好的模型端到端只解决了 52.1% 的客服场景;其他模型全部低于 40%。这不是猜测中的市场缺口,而是已经量化出来的缺口。 (ArtificialAnlys)
-
区分高表现智能体操作者的,现在是持久上下文基础设施,而不是提示词质量。 多位拿出生产结果的实践者都描述了同一件事:真正的杠杆来自品牌语气文件、风格库和持久上下文文件夹,而不是反复打磨提示词。这个模式同时出现在单人创作者(每月 6,000 条广告)、企业团队和开源构建者中。 (NainsiDwiv50980, oliverwhudson)
-
智能体安全治理正在变成企业基础设施。 Cisco DefenseClaw 扩展到 9 个智能体的同一天,Claude Code 的一条可运行利用链也被公开演示。攻防共演正在加速。任何会使用浏览器工具或网页内容的智能体部署,都暴露在当前运行框架尚未阻断的链式漏洞路径之下。 (AISecHub, DarkNavyOrg)