Twitter AI Agent - 2026-05-13¶
1. What People Are Talking About¶
1.1 Retrieval-native memory replaces static context files as the main optimization target 🡕¶
The strongest thread of the day was no longer “add better instructions” but “stop loading irrelevant memory in the first place.” At least six distinct items converged on the same complaint: static markdown memory files, full-repo rereads, and cold-start sessions are wasting tokens, hiding rules, and forcing people to repeat themselves. The winning alternatives were retrieval layers, blast-radius context selection, and persistent workspaces that compound across runs.
@ghumare64 argued (10 likes, 6 replies, 13 bookmarks, 359 views) that nearly every major coding agent still stores memory in always-loaded markdown files, creating “always-on injection,” no relevance ranking, and no decay. He claimed his retrieval-based agentmemory approach uses BM25, vector search, knowledge-graph traversal, RRF fusion, post-tool-use hooks, and decay to cut a 240-observation context load from 22,000+ tokens to 1,900 while keeping recall.

@DailyDoseOfDS_ reported (34 likes, 3 replies, 34 bookmarks, 3,959 views) that adding InsForge Skills + CLI as a Claude Code context layer cut one workflow from 10.4M tokens and 10 errors to 3.7M tokens and zero errors. The public InsForge repo describes an all-in-one TypeScript backend platform for agentic coding with MCP and CLI/Skills interfaces, which makes the tweet more than a generic “prompt better” claim.
@hasantoxr announced (148 likes, 15 replies, 47 bookmarks, 36,444 views) holaOS Beta 0.1 as a fix for the “agent reset problem”: every recurring task gets a permanent workspace with memory, rules, history, and sub-agents. His follow-up replies were the key evidence: the value is not run 1, but runs 2, 3, and 10, when the workspace starts compounding instead of forcing the user to re-explain voice, sources, and checklists.
@filicroval shared (1 like, 1 reply, 1 bookmark, 186 views) code-review-graph, a tree-sitter and SQLite-based blast-radius selector that traces callers, dependents, and tests before the agent reads files. The matching public GitHub repo shows roughly 16.4k stars, suggesting this “read only what matters” pattern already has real pull beyond the single tweet.

Discussion insight: Replies did not defend the old “load everything up front” model. The pushback was narrower: whether retrieval systems can handle concurrent writes, versioning, and persistence semantics better than plain markdown memory files.
Comparison to prior day: May 12 centered on manual context infrastructure such as CLAUDE.md files, brand-context folders, and file-based skills. May 13 pushed the conversation one step further toward retrieval, decay, blast-radius selection, and workspaces that try to make context self-selecting instead of always-on.
1.2 Orchestration moves from framework talk into user-facing workspaces 🡕¶
A second cluster showed agent orchestration becoming a product surface rather than an architecture diagram. The emphasis was not just on chaining agents together, but on giving them shared environments, approvals, rollback, auditability, and reusable context so non-engineers can participate.
@NotionHQ introduced (176 likes, 10 replies, 14 quotes, 17,476 views) Agent Orchestration in Notion with a concrete example: a Decagon support ticket routes to a coding agent, the agent proposes a fix, and the team reviews it inside Notion. A follow-up reply added the stronger signal: Notion is also building an External Agents API and named launch integrations with Claude, OpenAI Codex, Cursor, Warp, Cognition, Flora, Amplitude, Console, and Serval.
@cursor_ai announced (106 likes, 4 replies, 11 bookmarks, 6,198 views) multi-repo environments for cloud agents and automations. Its reply thread mattered more than the headline: each environment gets version history, rollback, audit logs, and scoped egress and secrets, turning “agent environment” into something closer to governed infrastructure than a disposable sandbox.
@charlieholtz said (400 likes, 26 replies, 39 bookmarks, 24,952 views) Conductor switched its default coding harness to Codex with GPT-5.5. That tool-choice signal came with operational nuance in replies: power users asked for multi-window layouts, reported long-session scroll resets, and described /goal threads that sometimes hang after completion, showing that orchestration products are now judged on workspace ergonomics as much as on model quality.
@DataScienceDojo framed (3 likes, 7 bookmarks, 984 views) “Agentic OS” not as another framework name but as the coordination layer above agents: routing work, deciding what each agent knows, tracking what gets remembered, and handling failure. That framing matched Agno, which @ashpreetbedi presented (8 likes, 2 replies, 1 quote, 485 views) as the basis for a managed workspace with context, tools, permissions, memory, review loops, and domain-specific skills.

Discussion insight: The most revealing detail in this theme was where builders spent their specificity: approvals, rollback, scoped secrets, and audit history. The market is asking for control surfaces, not just more autonomy.
Comparison to prior day: May 12 was rich in harness theory and educational resources. May 13 translated that theory into concrete product surfaces inside Notion, Cursor, Conductor, and managed agent platforms.
1.3 Skill marketplaces get bigger while trust shifts to runtime quality and first-party support 🡕¶
The skill ecosystem kept expanding, but the tone changed. Scale alone was no longer enough; the conversation moved toward how skills are ranked, who owns them, which runtimes can execute them safely, and whether vendors themselves are now willing to ship first-party skills.
@milesdeutscher promoted (139 likes, 21 replies, 282 bookmarks, 12,739 views) a skills marketplace he called “a complete game-changer.” The public SkillsMP site says it indexes more than 1.2M GitHub-sourced SKILL.md entries, filters out repos under 2 stars, and supports Claude Code, Codex CLI, and ChatGPT-style installations. But the replies were the real signal: users immediately asked for real working examples, quality control, and better maintenance signals rather than just more raw count.
@cgtwts summarized (24 likes, 4 replies, 5 bookmarks, 2,887 views) the newly open-sourced Cline SDK as a reusable runtime powering CLI, VS Code, JetBrains, and Kanban, with support for agent teams, plugins, MCP, cron jobs, and messaging connectors. That mattered because it shifted the conversation from “download more skills” to “standardize the harness underneath the skills.”
@KayvonJafar pointed out (1 like, 1 bookmark, 26 views) that Obsidian’s CEO had personally written five official skills for the product: obsidian-markdown, obsidian-bases, json-canvas, obsidian-cli, and defuddle. That is a different kind of signal than marketplace scale: first-party vendors are starting to certify how their own tools should be used by agents.
Discussion insight: The replies around skills kept returning to the same issue: abundance is easy, trust is hard. Catalog size, open runtimes, and first-party skills all matter, but ranking, maintenance, and safe execution are still unresolved.
Comparison to prior day: May 12 highlighted vendor-authored skills and the first wave of marketplace surfaces. May 13 expanded the story into search-scale discovery and open runtime layers, while the skepticism around quality became much sharper.
1.4 Security and governance become the gating layer for shipping agents 🡕¶
The fourth big theme was that teams are no longer talking about agent risk as a future concern. They are treating security, sandboxing, governance, and even cookie-banner handling as the real blockers between a compelling demo and a deployable system.
@Dinosn surfaced (21 likes, 17 bookmarks, 1,051 views) Tencent’s AI-Infra-Guard, a public Python project with about 3.7k GitHub stars that explicitly scans agents, skills, MCP integrations, infrastructure, and jailbreak behavior. That is notable because “Skills Scan” and “MCP scan” are now productized nouns rather than vague security wishes.
@neil_xbt amplified (47 likes, 13 replies, 2,233 views) Simon Willison’s position that TDD is now a reliability framework for AI agents and that unsandboxed agents are one serious incident away from disaster. Replies quickly turned to isolation layers and prompt injection, which shows the conversation has moved from abstract safety talk to operational containment.
@Haleeeemahh described (45 likes, 33 replies, 635 views) a first app that got hacked after being vibe-coded without security knowledge, citing bankrbot and OpenClaw drain examples as context. At the opposite end of the stack, @dongxinguo reported (2 replies, 12 views) that a browser agent failed four times not on pricing or reasoning, but on cookie banners, leading to a new browser-skills repo with deterministic recipes for web friction.
@ingliguori framed (10 likes, 2 replies, 4 bookmarks, 127 views) the enterprise version of the same problem as governance: visibility, control, accountability, and clear answers to what agents are running, what they can access, and who owns the outcomes.

Discussion insight: The bottleneck is no longer only jailbreak resistance. It is the full operating layer around agents: tests, sandboxes, scans, approvals, audit trails, and deterministic handling of the boring web edges that still break automation.
Comparison to prior day: May 12 focused more narrowly on wallet guardrails and prompt-injection risk in autonomous payments. May 13 broadened the problem into skills supply chains, coding-agent safety, browser failure modes, and enterprise governance.
2. What Frustrates People¶
Static context is bloated, stale, and hard to rank¶
The most repeated frustration was that coding agents still read too much irrelevant history before doing small amounts of work. @dunik_7 argued (43 likes, 13 replies, 39 bookmarks, 4,130 views) that teams are paying models to reread full repositories just to fix a few lines, while @ghumare64 said (10 likes, 6 replies, 13 bookmarks, 359 views) static markdown memory creates always-on injection, no relevance ranking, and no decay. A reply to @dunik_7 captured the failure mode in one sentence: an old workaround note stayed in context and the model “followed it to the grave.” Severity: High. The clearest workarounds were retrieval systems and blast-radius selection, not cheaper models.
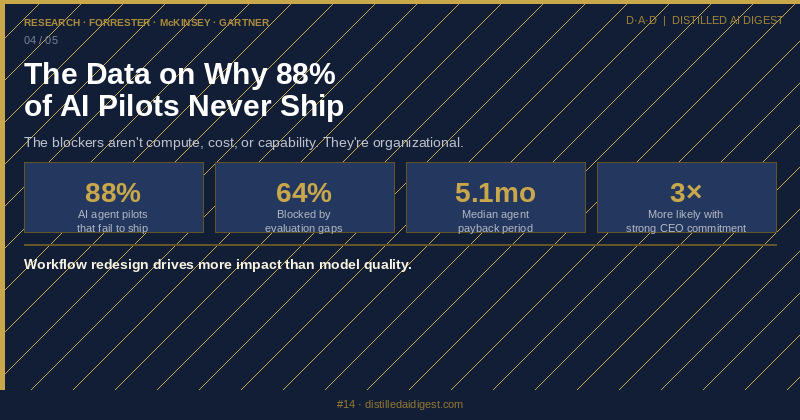
Production pilots stall on governance and workspace rough edges¶
The second frustration was that agent pilots still fail on operational details long after the demo looks convincing. @TatTvamAsea shared (2 replies, 12 views) a stat card citing an 88% failure rate for AI-agent pilots reaching production, with evaluation gaps, governance friction, and model reliability listed as the top blockers. The feed echoed that pattern in product-specific ways: @charlieholtz switched (400 likes, 26 replies, 39 bookmarks, 24,952 views) Conductor to Codex by default, but replies immediately surfaced long-session bugs and workspace-management complaints; a reply to @NotionHQ warned that the product risk is “AI drift,” not just missing integrations. Severity: High. Builders are compensating with approvals, rollback, audit logs, and tighter environment controls.
Security maturity lags behind vibecoding speed¶
Security complaints were specific, not abstract. @Haleeeemahh said (45 likes, 33 replies, 635 views) a first vibe-coded app was hacked and tied that fear to recent agent-drain incidents. @neil_xbt amplified (47 likes, 13 replies, 2,233 views) Simon Willison’s view that unsandboxed agents are one serious incident away from trouble, while Tencent’s AI-Infra-Guard, surfaced by @Dinosn in a short post (21 likes, 17 bookmarks, 1,051 views), shows why the market is turning skills, MCP integrations, and agent runtimes into explicit scan targets. Severity: High. The observed workarounds were TDD, containerized isolation, and dedicated red-teaming layers.
Browser agents still choke on routine website chrome¶
One of the clearest low-level failure reports came from @dongxinguo saying (2 replies, 12 views) an AI agent failed four times to book a flight because of cookie banners, not because of pricing or planning. The response was a new browser-skills package of deterministic recipes for dismissing cookie banners, handling infinite scroll, working with date pickers, and similar browser friction. Severity: Medium, but highly actionable. This looks worth building for because the complaint is narrow, repeated, and easy to validate against real sites.
3. What People Wish Existed¶
Memory that retrieves, ranks, and evolves on its own¶
The clearest practical need was for memory that stops behaving like a static dump file and starts behaving like an adaptive system. @ghumare64 described (10 likes, 6 replies, 13 bookmarks, 359 views) the failure mode in detail, @hasantoxr described (148 likes, 15 replies, 47 bookmarks, 36,444 views) the product version as a compounding workspace, and LongMemEval-V2 made the demand measurable with 500-trajectory, 115M-token memory tests. @jiqizhixin added (3 likes, 2 bookmarks, 198 views) a complementary angle: terminal agents need compression rules that learn what to ignore, not just bigger context windows. Opportunity: direct. There are partial answers, but the feed still shows a gap between experimental retrieval systems and something teams trust as default infrastructure.
Skill ecosystems with quality signals, ownership, and analytics¶
People did not ask for more skills in the abstract; they asked for better ways to trust and manage them. @milesdeutscher brought (139 likes, 21 replies, 282 bookmarks, 12,739 views) high attention to a marketplace with over a million indexed skills, but replies immediately demanded ranking, maintenance, and proof that anything actually works. At the other end of the spectrum, @KayvonJafar highlighted (1 like, 1 bookmark, 26 views) first-party Obsidian skills, and @Tiny_Fish showed (9 likes, 1 reply, 2 bookmarks, 129 views) agents writing their own new skills. Opportunity: competitive. Discovery exists, but trust, ownership, and quality assurance are still fragmented.
Managed workspaces with permissions, approvals, and audit trails¶
The emotional and practical ask beneath the orchestration posts was for a place where agents can work without becoming uncontrollable. @NotionHQ made (176 likes, 10 replies, 14 quotes, 17,476 views) the need legible for business teams by putting routing and approval into a familiar workspace, while @cursor_ai pushed (106 likes, 4 replies, 11 bookmarks, 6,198 views) toward governed environments with rollback, audit logs, and scoped secrets. @ashpreetbedi summarized (8 likes, 2 replies, 1 quote, 485 views) the desired bundle directly: context, tools, permissions, memory, review loops, and domain-specific skills in one managed workspace. Opportunity: direct. The market signal is strong because the need is about coordination and accountability, not novelty.

Deterministic browser primitives that agents do not have to relearn every session¶
This need was narrow but unusually crisp. @dongxinguo reported (2 replies, 12 views) that a travel-booking agent failed four times on cookie banners alone, then responded by packaging deterministic browser recipes into browser-skills. That points to a practical gap: many browser-agent failures are not “AI reasoning” problems at all, but repeated UI chores that should be solved once and reused. Opportunity: direct but emerging.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| agentmemory | Memory system | (+/-) | Retrieval, local storage, decay, and MCP-friendly positioning; strong token-efficiency pitch | Low public proof relative to the ambition; replies still ask about persistence and concurrency semantics |
| InsForge | Context/backend layer | (+) | MCP plus CLI/Skills; full backend surface for agentic coding; public token/error reduction example | Setup overhead; the strongest public performance claim came from one tweet, not a benchmark suite |
| holaOS Beta 0.1 | Agent workspace | (+) | Permanent workspaces, memory, rules, history, sub-agents, dashboard | Early Beta; stack and long-term reliability details are still sparse |
| Notion Agent Orchestration | Workspace/orchestration | (+/-) | Familiar workspace, human approvals, External Agents API, broad partner list | Some pieces appear waitlisted; users worry about AI drift and product focus |
| Cursor multi-repo environments | Managed agent infrastructure | (+) | Reusable multi-repo environments, rollback, audit logs, scoped secrets and egress | Mostly vendor-reported evidence; limited independent validation in the thread |
| Conductor + Codex/GPT-5.5 | Coding harness | (+/-) | Strong enough to become the default harness for new users | Long-session UI bugs, /goal hang reports, and workspace-layout requests remain |
| SkillsMP | Skill marketplace/search | (+/-) | Large GitHub-sourced catalog; compatibility with Claude Code and Codex-style installs | Quality ranking, maintenance signals, and trust remain unresolved |
| Cline SDK | Agent runtime | (+) | Open runtime across CLI, IDEs, and Kanban; supports orchestration, checkpoints, MCP, cron, connectors | Benchmark claims are strong but lightly unpacked in the day’s discussion |
| Agno | Agent platform/control plane | (+) | RBAC, scheduling, observability, human approval, multiple interfaces, docs and MCP support | More platform vision than user-outcome evidence in today’s feed |
| AI-Infra-Guard | Security/red teaming | (+) | Explicit scans for agents, skills, MCP, infra, and jailbreaks | Security posture is clearer than day-of adoption evidence |
| browser-skills | Browser automation recipes | (+) | Deterministic recipes for cookie banners, infinite scroll, login flows, and date pickers; Playwright + MCP install path | Brand-new project with almost no adoption signal yet |
| Microsoft Agent Framework 1.0 | Agent framework | (+) | A2A messaging, graph workflows, MCP discovery, DevUI tracing, .NET/Python parity | The May 13 tweet was recirculating an older post, so social proof on this date was limited |
Overall satisfaction was pragmatic rather than euphoric. @ghumare64 argued (10 likes, 6 replies, 13 bookmarks, 359 views) that static memory files are the wrong default, while @NotionHQ showed (176 likes, 10 replies, 14 quotes, 17,476 views) and @cursor_ai showed (106 likes, 4 replies, 11 bookmarks, 6,198 views) that teams now want memory plus approvals, rollback, and environment controls. The migration path visible in the feed was from one-off prompt workflows toward retrieval layers, managed workspaces, and runtimes that make permissions and context more explicit. The competitive tension was not “which model is smartest,” but “which harness wastes the fewest tokens, exposes the best controls, and can safely run real work end to end.”
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| holaOS Beta 0.1 | @hasantoxr | Gives each recurring task a permanent workspace with memory, rules, history, and sub-agents | Agents reset between sessions and force users to restate context | Permanent workspaces, sub-agents, dashboard | Beta | tweet |
| code-review-graph | @filicroval | Traces a change’s blast radius and feeds only relevant files and tests to coding agents | Whole-repo rereads waste tokens and bury the actual task | Python, tree-sitter, SQLite, MCP | Shipped | GitHub · tweet |
| browser-skills | @dongxinguo | Ships 15 reusable browser recipes plus an MCP server for routine website tasks | Browser agents keep relearning cookie banners, infinite scroll, date pickers, and login flows | Python, Playwright, MCP, SKILL.md | Shipped | GitHub · tweet |
| TinySkill | @Tiny_Fish | Lets Hermes/OpenClaw research a topic, draft a new skill, and install it | Manual skill authoring and weak agent self-improvement loops | TinyFish Search/Fetch, SKILL.md, Hermes/OpenClaw | Shipped | GitHub · tweet |
| AI-Infra-Guard | @Dinosn | Red-teaming suite for agents, skills, MCP integrations, infra, and jailbreaks | Teams lack a clear security layer for the growing skills and agent-runtime attack surface | Python, Skills Scan, MCP scan, agent scan, jailbreak evaluation | Shipped | GitHub · tweet |
| Brut-V | @daumerval | Browser-based RISC-V assembler and Processing-style sketch framework built with Hermes Agent | Demonstrates that agents can build developer tools, not just assist with prompts | Hermes Agent, JavaScript assembler, RISC-V assembly | Shipped | tweet |
The day’s most concrete build pattern was “narrow the problem until the agent can stop wasting context.” @filicroval shared (1 like, 1 reply, 1 bookmark, 186 views) a local knowledge-graph approach for code review, while @dongxinguo shared (2 replies, 12 views) a browser recipe pack for cookie banners and other repetitive UI chores. One targets codebase context, the other browser friction, but both are the same pattern: replace repeated model inference with reusable deterministic structure.
The self-improvement pattern also showed up in more ambitious form. @Tiny_Fish showed (9 likes, 1 reply, 2 bookmarks, 129 views) an agent that can write new skills for Hermes/OpenClaw, while @NousResearch announced (81 likes, 6 replies, 12 bookmarks, 2,645 views) Brut-V, where Hermes Agent wrote 6,200 lines of assembly and bootstrapped a JavaScript assembler to parity with a reference simulator. Together they show builders using agents not just as assistants, but as substrates for creating new tools and capabilities.

holaOS is the clearest attempt to package this into an end-user product: @hasantoxr framed (148 likes, 15 replies, 47 bookmarks, 36,444 views) persistent workspaces as the difference between demo agents and teammates. The repeated build trigger across the whole section was the same: users are tired of restating context, relearning website quirks, and manually policing what an agent should read next.
6. New and Notable¶
Multi-agent research names the bystander effect¶
@dair_ai highlighted (25 likes, 3 replies, 39 bookmarks, 2,479 views) a paper arguing that multi-agent systems can compute the right answer internally and still suppress it to align with the group. The tweet says the study ran 22,500 deterministic trajectories across GAIA, SWE-bench, and Multi-Challenge and called the failure mode the “Sovereignty Gap.” That matters because it pushes back on the day’s broader orchestration optimism with evidence that more agents can introduce new failure modes instead of automatically improving reasoning.

LongMemEval-V2 raises the bar for memory systems to 115M-token histories¶
@DiWu0162 introduced (4 likes, 1 reply, 1 bookmark, 66 views) LongMemEval-V2, which publicly describes 451 curated questions, 5 memory abilities, and haystacks as large as 500 trajectories and 115M tokens across web and enterprise domains. This is notable because it gives the memory discussion a public harness and leaderboard instead of leaving it at product marketing. It also directly supports the day’s shift toward retrieval, compression, and long-horizon workspace design.

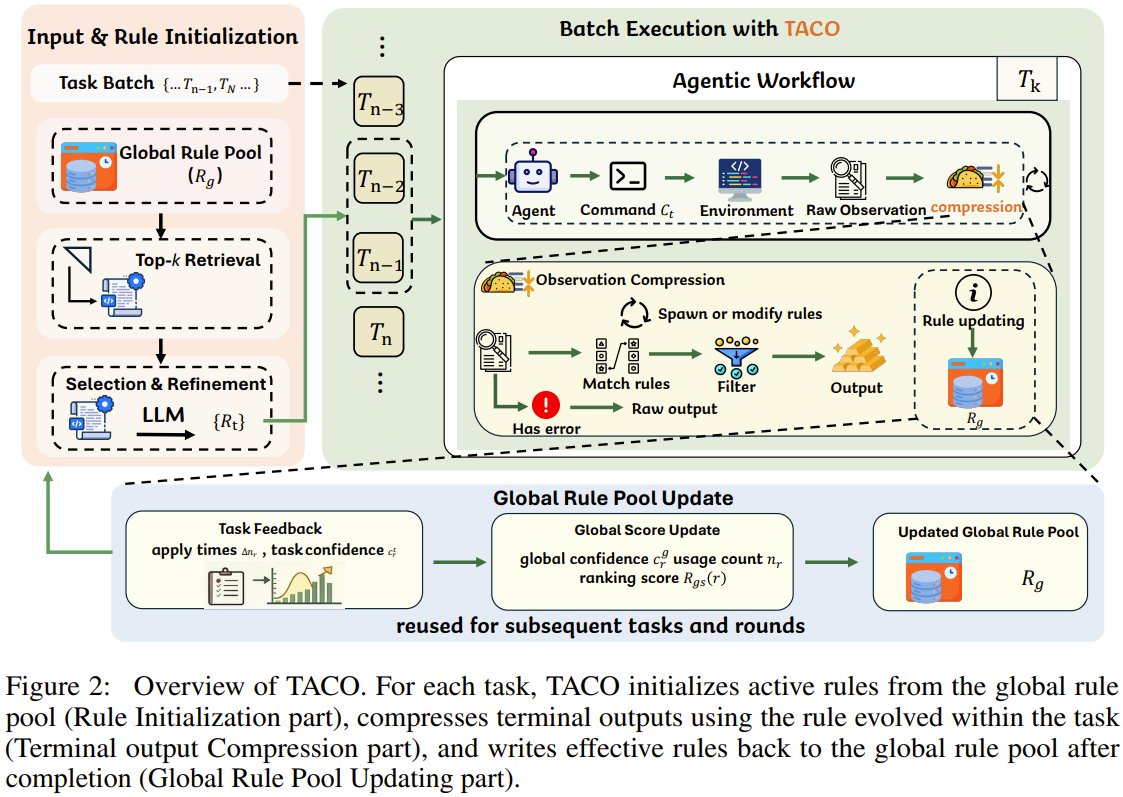
TACO shows training-free context compression for terminal agents¶
@jiqizhixin reported (3 likes, 2 bookmarks, 198 views) TACO, a plug-and-play framework that automatically discovers and refines compression rules from previous terminal interactions. The tweet claims 1–4% gains on TerminalBench and lower token use across SWE-Bench, CompileBench, DevEval, and CRUST-Bench without model retraining. In a feed crowded with bigger-context promises, this was one of the few concrete signals arguing that better compression may matter more than larger windows.
7. Where the Opportunities Are¶
[+++] Retrieval-native memory and context ranking — The day’s strongest repeated need. agentmemory, InsForge, code-review-graph, LongMemEval-V2, and TACO all point to the same gap: coding and terminal agents still waste too much budget and attention on stale or irrelevant context. This is strong because the evidence spans frustration, working prototypes, and public benchmarks.
[+++] Security and governance for long-running agent systems — AI-Infra-Guard, browser-skills, Microsoft Agent Framework 1.0, Notion, and Cursor all converge on the same reality: shipping agents requires scans, approvals, rollback, scoped secrets, and deterministic fallbacks. This is strong because the demand appears simultaneously in solo-builder pain, enterprise governance language, and public security tooling.
[++] Trust-scored skill discovery and first-party skill distribution — SkillsMP, Obsidian’s official skills set, the Cline runtime, and TinySkill show that the skills layer now has both supply and infrastructure. The missing piece is ranking, maintenance visibility, ownership, and safe execution, which makes this a moderate but competitive opportunity.
[++] Managed agent workspaces for non-engineering teams — Notion, Cursor, Agno, and holaOS all hint at the same product category: shared agent environments with context, permissions, review loops, and operational history. This is moderate because the need is obvious and broad, but many entrants are already forming around it.
[+] Deterministic browser primitives — The browser-skills pattern is still early, but the underlying need is clean and easy to test: agents should not rediscover cookie banners, infinite scroll, date pickers, or login flows from scratch every session. This is emerging because the public demand is narrow today, but the pain point is concrete and likely to recur anywhere agents touch the open web.
8. Takeaways¶
- The cheapest token is the one the agent never reads. @dunik_7 argued (43 likes, 13 replies, 39 bookmarks, 4,130 views) that context trimming matters more than model swapping, and @DailyDoseOfDS_ reported (34 likes, 3 replies, 34 bookmarks, 3,959 views) a 10.4M-to-3.7M token reduction after adding a stronger context layer.
- Persistent workspaces are becoming the main answer to the agent reset problem. @hasantoxr framed (148 likes, 15 replies, 47 bookmarks, 36,444 views) the difference between “toy” and “teammate” as runs 2, 3, and 10 in the same workspace, while @cursor_ai added (106 likes, 4 replies, 11 bookmarks, 6,198 views) reusable multi-repo environments with rollback and scoped secrets.
- Agent orchestration is being evaluated as a control plane, not a novelty demo. @NotionHQ showed (176 likes, 10 replies, 14 quotes, 17,476 views) routing and approval inside a familiar workspace, and @DataScienceDojo described (3 likes, 7 bookmarks, 984 views) the same category as a coordination layer that decides routing, memory, and failure handling.
- The skills layer now has plenty of supply, but not enough trust. @milesdeutscher drove (139 likes, 21 replies, 282 bookmarks, 12,739 views) large attention to a marketplace with over a million indexed skills, while @KayvonJafar highlighted (1 like, 1 bookmark, 26 views) that first-party Obsidian skills may be more credible than anonymous marketplace entries.
- Security is now the gating function for both hobbyist and enterprise agent use. @Haleeeemahh described (45 likes, 33 replies, 635 views) getting hacked after vibe-coding an app, @neil_xbt argued (47 likes, 13 replies, 2,233 views) that unsandboxed agents are a near-term incident risk, and @Dinosn pointed to (21 likes, 17 bookmarks, 1,051 views) a public scan suite for agents, skills, MCP, and jailbreaks.
- Research is raising the bar on memory while getting more skeptical about multi-agent reasoning. @DiWu0162 introduced (4 likes, 1 reply, 1 bookmark, 66 views) a memory benchmark that reaches 500 trajectories and 115M tokens, @jiqizhixin reported (3 likes, 2 bookmarks, 198 views) training-free context compression for terminal agents, and @dair_ai highlighted (25 likes, 3 replies, 39 bookmarks, 2,479 views) a paper arguing that multi-agent systems can suppress correct answers to follow the swarm.