Twitter AI 智能体 - 2026-05-13¶
1. 人们在讨论什么¶
1.1 检索原生记忆取代静态上下文文件,成为主要优化目标 🡕¶
当天最强的讨论线索,已经不是“加更好的指令”,而是“先别把无关记忆加载进来”。至少有 6 个彼此独立的讨论项都指向同一个抱怨:静态 Markdown 记忆文件、全仓库重读和冷启动会话正在浪费 token、隐藏规则,并迫使人们反复重复自己。胜出的替代方案是检索层、按影响范围选取上下文,以及能在多次运行中持续累积的持久工作区。
@ghumare64 指出(10 个点赞、6 条回复、13 次收藏、359 次浏览),几乎所有主流编程智能体仍把记忆存放在总是加载的 Markdown 文件里,造成“常驻注入”、没有按关联度排序,也没有衰减机制。他声称,自己基于检索的 agentmemory 方法结合了 BM25、向量检索、知识图谱遍历、RRF 融合、工具使用后钩子和衰减机制,能把 240 条观察的上下文加载量从 22,000 多个 token 降到 1,900,同时保留召回率。

@DailyDoseOfDS_ 表示(34 个点赞、3 条回复、34 次收藏、3,959 次浏览),给 Claude Code 加上 InsForge Skills + CLI 作为上下文层后,某个工作流从 1,040 万 token 和 10 个错误降到了 370 万 token 和 0 个错误。公开的 InsForge 仓库把自己描述为一个面向智能体式编程的 TypeScript 全栈后端平台,支持 MCP 以及 CLI/Skills 接口,这让这条推文不只是泛泛的“把提示词写好点”的说法。
@hasantoxr 宣布(148 个点赞、15 条回复、47 次收藏、36,444 次浏览)holaOS Beta 0.1 用来解决“智能体重置问题”:每个重复任务都配有一个永久工作区,里面包含记忆、规则、历史和子智能体。他后续回复给出的关键信号是:价值不在第 1 次运行,而在第 2、3、10 次运行——这时工作区开始持续累积,而不是逼用户重新解释语气、来源和清单。
@filicroval 分享(1 个点赞、1 条回复、1 次收藏、186 次浏览)了 code-review-graph,这是一个基于 tree-sitter 和 SQLite 的影响范围选择器,会在智能体读取文件之前先追踪调用方、依赖项和测试。配套的公开 GitHub 仓库显示大约有 16.4k stars,说明这种“只读真正重要内容”的模式,已经不只是单条推文里的想法。

讨论要点: 回复并没有为旧的“先把一切都加载进来”模型辩护。争论更集中在:检索系统能否比普通 Markdown 记忆文件更好地处理并发写入、版本管理和持久化语义。
与前日对比: 5 月 12 日的重点还是手动上下文基础设施,比如 CLAUDE.md 文件、品牌上下文文件夹和基于文件的 Skills。5 月 13 日则把讨论往前推进了一步,转向检索、衰减、影响范围选择,以及试图让上下文自动筛选而不是常驻加载的工作区。
1.2 编排从框架讨论走向面向用户的工作区 🡕¶
第二个讨论簇显示,智能体编排正在成为产品表面,而不只是架构图上的一层。重点不再只是把多个智能体串起来,而是给它们共享环境、审批、回滚、可审计性和可复用上下文,让非工程师也能参与。
@NotionHQ 介绍了(176 个点赞、10 条回复、14 次引用、17,476 次浏览)Notion 里的智能体编排,并给出一个具体例子:一张 Decagon 支持工单会路由到一个编程智能体,智能体提出修复方案,团队再在 Notion 里审阅。后续回复补充了更强的信号:Notion 也在构建 External Agents API,并列出了 Claude、OpenAI Codex、Cursor、Warp、Cognition、Flora、Amplitude、Console 和 Serval 等首发集成。
@cursor_ai 宣布(106 个点赞、4 条回复、11 次收藏、6,198 次浏览)为云端智能体和自动化提供多仓库环境。真正重要的是回复串:每个环境都带版本历史、回滚、审计日志,以及受限的出站访问和密钥,等于是把“智能体环境”变成了更接近受管基础设施的东西,而不是一次性的沙箱。
@charlieholtz 表示(400 个点赞、26 条回复、39 次收藏、24,952 次浏览)Conductor 已把默认的编码运行框架切到 Codex with GPT-5.5。这个工具选择信号在回复里带上了运营层面的细节:重度用户想要多窗口布局,报告长会话滚动重置,并描述了有时在跑完后仍然挂住的 /goal 线程,说明编排类产品现在不只是看模型质量,也看工作区的易用性。
@DataScienceDojo 把(3 个点赞、7 次收藏、984 次浏览)“Agentic OS”框定为不是另一个框架名,而是位于智能体之上的协调层:负责路由工作、决定每个智能体知道什么、追踪什么被记住,以及处理失败。这种说法与 Agno 的定位相呼应,后者被 @ashpreetbedi 介绍为(8 个点赞、2 条回复、1 次引用、485 次浏览)构建受管工作区的基础,包含上下文、工具、权限、记忆、审查循环和领域专属 Skills。

讨论要点: 这个主题里最能说明问题的细节,是构建者把精力放在了哪些具体项上:审批、回滚、受限密钥和审计历史。市场要的是控制面,而不只是更大的自主性。
与前日对比: 5 月 12 日更多是在讨论运行框架理论和教育资源。5 月 13 日则把这些理论落到了 Notion、Cursor、Conductor 以及受管智能体平台里的具体产品表面。
1.3 Skills 市场持续扩张,但信任正转向运行时质量和官方支持 🡕¶
Skills 生态还在扩张,但语气变了。规模本身已经不够了;讨论开始转向 Skills 如何排序、谁拥有它们、哪些运行时能安全执行它们,以及厂商自己是否愿意发布第一方 Skills。
@milesdeutscher 推广了(139 个点赞、21 条回复、282 次收藏、12,739 次浏览)一个他称为“彻底改变游戏规则”的技能市场。公开的 SkillsMP 网站称自己索引了超过 120 万条来自 GitHub 的 SKILL.md 条目,过滤掉 stars 少于 2 的仓库,并支持 Claude Code、Codex CLI 和 ChatGPT 风格的安装。但真正的信号来自回复:用户立刻开始追问真实可运行的示例、质量控制和更好的维护信号,而不只是更大的数量。
@cgtwts 总结了(24 个点赞、4 条回复、5 次收藏、2,887 次浏览)刚开源的 Cline SDK,称其是一个可复用运行时,为 CLI、VS Code、JetBrains 和看板提供支持,并支持智能体团队、插件、MCP、cron 作业和消息连接器。这之所以重要,是因为讨论焦点从“下载更多 Skills”转向了“把 Skills 底下的运行框架标准化”。
@KayvonJafar 指出(1 个点赞、1 次收藏、26 次浏览),Obsidian 的 CEO 亲自为这个产品写了 5 个官方 Skills:obsidian-markdown、obsidian-bases、json-canvas、obsidian-cli 和 defuddle。这和市场规模是另一种不同的信号:第一方厂商开始认证智能体应当如何使用自己的工具。
讨论要点: 关于 Skills 的回复反复回到同一个问题:数量充足很容易,信任却很难。目录规模、开放运行时和第一方 Skills 都重要,但排序、维护和安全执行仍未解决。
与前日对比: 5 月 12 日突出的是厂商编写的 Skills 和市场表面的第一波形态。5 月 13 日则把故事扩展到搜索规模的发现能力和开放运行时层,同时对质量的怀疑也变得尖锐得多。
1.4 安全与治理成为智能体上线的门槛层 🡕¶
第四个大主题是:团队已经不再把智能体风险看作未来问题,而是把安全、沙箱隔离、治理,甚至 cookie 横幅处理,都视为把一个吸引人的 demo 变成可部署系统之间的真正阻碍。
@Dinosn 转发了(21 个点赞、17 次收藏、1,051 次浏览)腾讯的 AI-Infra-Guard,这是一个公开的 Python 项目,GitHub stars 约 3.7k,明确会扫描智能体、Skills、MCP 集成、基础设施和越狱行为。这很值得注意,因为“Skills 扫描”和“MCP 扫描”现在已经变成了产品化名词,而不再只是模糊的安全愿望。
@neil_xbt 强调了(47 个点赞、13 条回复、2,233 次浏览)Simon Willison 的观点:TDD 现在是 AI 智能体的可靠性框架,而无沙箱隔离的智能体距离严重事故只差一步。回复很快转向隔离层和提示注入,说明讨论已经从抽象的安全话题转到了运行层面的收容。
@Haleeeemahh 描述了(45 个点赞、33 条回复、635 次浏览)有人第一次用氛围编程做了一个应用,黑客很快就攻破了它,并把 bankrbot 和 OpenClaw 的资金被盗案例作为背景。站在技术栈的另一端,@dongxinguo 报告说(2 条回复、12 次浏览)一个浏览器智能体在 cookie 横幅上连续失败了 4 次,而不是在定价或推理上失败,于是催生了新的 browser-skills 仓库,用确定性流程处理网页摩擦。
@ingliguori 把(10 个点赞、2 条回复、4 次收藏、127 次浏览)同样的问题在企业场景中框定为治理:可见性、控制、责任归属,以及明确回答智能体正在运行什么、能访问什么、结果由谁负责。

讨论要点: 瓶颈已经不只是防越狱能力,而是围绕智能体的整个运行层:测试、沙箱、扫描、审批、审计轨迹,以及那些仍会打断自动化的普通网页边角问题的确定性处理。
与前日对比: 5 月 12 日更集中在钱包护栏和自治支付中的提示注入风险。5 月 13 日则把问题扩展到 Skills 供应链、编程智能体安全、浏览器故障模式和企业治理。
2. 令人困扰的问题¶
静态上下文过于臃肿、陈旧,而且难以排序¶
最反复出现的挫败感是:编程智能体在做少量工作前,还是会先读进太多无关历史。@dunik_7 指出(43 个点赞、13 条回复、39 次收藏、4,130 次浏览),团队正在付费让模型重读整个仓库,只为修几行代码;而 @ghumare64 说(10 个点赞、6 条回复、13 次收藏、359 次浏览),静态 Markdown 记忆会造成常驻注入、没有按关联度排序,也没有衰减。一条对 @dunik_7 的回复用一句话概括了这个失败模式:一条旧的绕行说明留在上下文里,模型“跟着它一路走到黑”。严重程度:高。最清晰的绕行方案是检索系统和影响范围选择,而不是更便宜的模型。
生产试点在治理和工作区边角问题上卡住¶
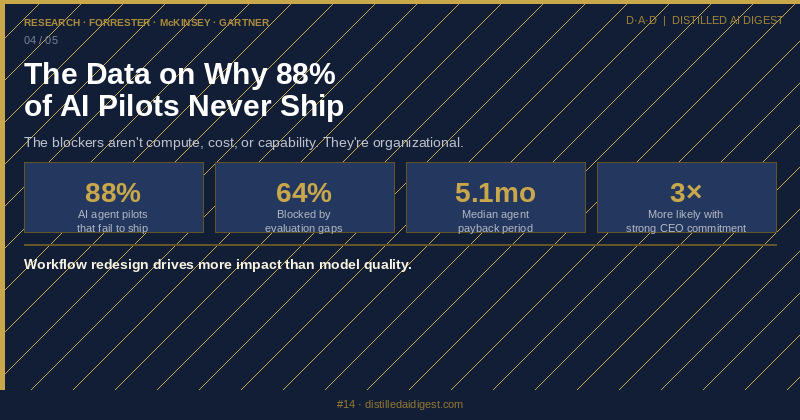
第二个挫败感是:即便 demo 看起来已经很像样,智能体试点还是会在运维细节上失败。@TatTvamAsea 分享了(2 条回复、12 次浏览)一张统计卡,称 AI 智能体试点冲击生产环境时失败率高达 88%,其中评估缺口、治理摩擦和模型可靠性被列为主要阻碍。信息流里不同产品也在重复这一模式:@charlieholtz 把(400 个点赞、26 条回复、39 次收藏、24,952 次浏览)Conductor 的默认设置切到 Codex,但回复立刻暴露出长会话 bug 和工作区管理抱怨;而对 @NotionHQ 的一条回复则警告,产品风险是“AI 偏移”,而不只是缺少集成。严重程度:高。构建者正在用审批、回滚、审计日志和更紧的环境控制来补洞。
安全成熟度落后于 vibe coding 的速度¶
安全方面的抱怨很具体,不是抽象的。@Haleeeemahh 说(45 个点赞、33 条回复、635 次浏览)有人第一次用氛围编程做了一个应用,结果被黑,并把这种担忧与近期的智能体资金被盗事件联系起来。@neil_xbt 转发了(47 个点赞、13 条回复、2,233 次浏览)Simon Willison 的观点:没有沙箱隔离的智能体几乎就是一场近在眼前的事故风险;而 Tencent’s AI-Infra-Guard 由 @Dinosn 在一条短帖中提到(21 个点赞、17 次收藏、1,051 次浏览),说明为什么市场正在把技能、MCP 集成和智能体运行时变成明确的扫描目标。严重程度:高。观察到的绕行方案是 TDD、容器化隔离和专门的红队层。
浏览器智能体仍会卡在网站常见的界面边角上¶
最清楚的一条底层失败报告来自 @dongxinguo 的说法(2 条回复、12 次浏览):一个 AI 智能体因为 cookie 横幅而连续 4 次订机票失败,问题不在定价或规划。随之而来的是一个新的 browser-skills 包,里面装的是处理 cookie 横幅、无限滚动、日期选择器以及类似浏览器摩擦的确定性流程。严重程度:中等,但可直接落地。这个方向值得做,因为问题范围很窄、反复出现,而且很容易拿真实网站验证。
3. 人们期望的功能¶
能自动检索、排序并随时间演进的记忆¶
最清晰的实际需求,是记忆不要再像静态转储文件,而要像一个自适应系统。@ghumare64 详细描述了(10 个点赞、6 条回复、13 次收藏、359 次浏览)这个失败模式,@hasantoxr 把(148 个点赞、15 条回复、47 次收藏、36,444 次浏览)产品形态描述为会持续累积的工作区,而 LongMemEval-V2 用 500 条轨迹、1.15 亿 token 的记忆测试把这种需求变得可度量。@jiqizhixin 补充了(3 个点赞、2 次收藏、198 次浏览)一个补充角度:终端智能体需要的是能学会忽略什么的压缩规则,而不只是更大的上下文窗口。机会:直接。虽然已有一些部分答案,但信息流里仍然能看到实验性检索系统和团队敢当默认基础设施的系统之间存在鸿沟。
带有质量信号、所有权和分析能力的 Skills 生态¶
人们并不是抽象地要求更多 Skills,而是要求更好地信任和管理它们。@milesdeutscher 把注意力带到了(139 个点赞、21 条回复、282 次收藏、12,739 次浏览)一个索引了超过一百万个 Skills 的市场,但回复立刻要求排序、维护,以及能证明任何东西真的能用。另一端则是 @KayvonJafar 强调的(1 个点赞、1 次收藏、26 次浏览)Obsidian 第一方 Skills,以及 @Tiny_Fish 展示的(9 个点赞、1 条回复、2 次收藏、129 次浏览)让智能体自己编写新 Skills。机会:有竞争性。发现机制已经有了,但信任、所有权和质量保证仍然碎片化。
具备权限、审批和审计轨迹的受管工作区¶
关于编排的推文底下真正的情绪和实际诉求,是想要一个让智能体能干活、但不会失控的地方。@NotionHQ 通过(176 个点赞、10 条回复、14 次引用、17,476 次浏览)把路由和审批放进熟悉的工作区,让业务团队能看懂并使用;@cursor_ai 则推动了(106 个点赞、4 条回复、11 次收藏、6,198 次浏览)带回滚、审计日志和受限密钥的受管环境。@ashpreetbedi 直接总结了(8 个点赞、2 条回复、1 次引用、485 次浏览)期望中的整套能力:上下文、工具、权限、记忆、审查循环和领域专属技能全都放进一个受管工作区。机会:直接。这个市场信号很强,因为需求关乎协调和责任,而不是新鲜感。

无需每个会话都重学的确定性浏览器原语¶
这个需求范围很窄,但异常清晰。@dongxinguo 报告说(2 条回复、12 次浏览),一个旅行预订智能体光是在 cookie 横幅上就失败了 4 次,随后他把确定性的浏览器流程打包进 browser-skills。这指向一个很实际的缺口:很多浏览器智能体失败根本不是“AI 推理”问题,而是那些重复的 UI 杂活,应该一次解决、反复复用。机会:直接,但仍处于早期。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| agentmemory | 记忆系统 | (+/-) | 检索、本地存储、衰减,以及对 MCP 友好的定位;主打 token 效率 | 相比其雄心,公开证据仍然有限;回复仍在追问持久化和并发语义 |
| InsForge | 上下文/后端层 | (+) | MCP 加 CLI/Skills;面向智能体式编程的完整后端表面;有公开的 token/错误减少案例 | 上手成本较高;最强的公开性能说法来自一条推文,而不是基准测试套件 |
| holaOS Beta 0.1 | 智能体工作区 | (+) | 永久工作区、记忆、规则、历史、子智能体、仪表盘 | 仍处于 Beta;技术栈和长期可靠性的细节还很少 |
| Notion Agent Orchestration | 工作区/编排 | (+/-) | 熟悉的工作区、人类审批、External Agents API、广泛的合作伙伴名单 | 部分功能似乎还在候补名单上;用户担心 AI 偏移和产品重心 |
| Cursor 多仓库环境 | 受管智能体基础设施 | (+) | 可复用的多仓库环境、回滚、审计日志、受限密钥和出站访问 | 主要是厂商自述证据;线程里独立验证有限 |
| Conductor + Codex/GPT-5.5 | 编程运行框架 | (+/-) | 足够强,能成为新用户的默认运行框架 | 长会话 UI bug、/goal 挂起报告和工作区布局需求仍然存在 |
| SkillsMP | Skills 市场/搜索 | (+/-) | 规模很大的 GitHub 来源目录;兼容 Claude Code 和 Codex 风格安装 | 排序、维护信号和信任仍未解决 |
| Cline SDK | 智能体运行时 | (+) | 覆盖 CLI、IDE 和看板的开放运行时;支持编排、检查点、MCP、cron、连接器 | 基准测试说法很强,但当天讨论里展开得不多 |
| Agno | 智能体平台/控制平面 | (+) | RBAC、调度、可观测性、人类审批、多接口、文档和 MCP 支持 | 更像平台愿景,而不是今天信息流里的用户结果证据 |
| AI-Infra-Guard | 安全/红队 | (+) | 明确扫描智能体、Skills、MCP、基础设施和越狱 | 安全姿态比当天采用证据更清晰 |
| browser-skills | 浏览器自动化流程 | (+) | 面向 cookie 横幅、无限滚动、登录流程和日期选择器的确定性流程;支持 Playwright + MCP 的安装路径 | 刚发布,几乎没有采用信号 |
| Microsoft Agent Framework 1.0 | 智能体框架 | (+) | A2A 消息传递、图式工作流、MCP 发现、DevUI 追踪、.NET/Python 对齐 | 5 月 13 日那条推文是在转发更早的文章,因此当天的社交证明有限 |
总体满意度更偏务实,而不是狂热。@ghumare64 指出(10 个点赞、6 条回复、13 次收藏、359 次浏览),静态记忆文件并不是正确默认值;而 @NotionHQ 展示了(176 个点赞、10 条回复、14 次引用、17,476 次浏览)以及 @cursor_ai 展示了(106 个点赞、4 条回复、11 次收藏、6,198 次浏览),团队现在要的是记忆加审批、回滚和环境控制。信息流里可见的迁移路径,是从一次性的提示词工作流,走向检索层、受管工作区,以及能让权限和上下文更明确的运行时。竞争的核心不是“哪个模型最聪明”,而是“哪个运行框架浪费的 token 最少、控制最好,而且能安全地端到端跑真实工作”。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| holaOS Beta 0.1 | @hasantoxr | 为每个重复任务提供带记忆、规则、历史和子智能体的永久工作区 | 智能体在会话之间重置,迫使用户重新说明上下文 | 永久工作区、子智能体、仪表盘 | Beta | 推文 |
| code-review-graph | @filicroval | 追踪变更的影响范围,只把必要文件和测试喂给编程智能体 | 全仓库重读浪费 token,也掩盖了真正任务 | Python、tree-sitter、SQLite、MCP | 已发布 | GitHub · 推文 |
| browser-skills | @dongxinguo | 提供 15 个可复用的浏览器流程和一个用于常见网站任务的 MCP 服务器 | 浏览器智能体总是在重新学习 cookie 横幅、无限滚动、日期选择器和登录流程 | Python、Playwright、MCP、SKILL.md | 已发布 | GitHub · 推文 |
| TinySkill | @Tiny_Fish | 让 Hermes/OpenClaw 研究一个主题、起草一个新 Skill 并安装它 | 手工编写 Skills 太麻烦,而且智能体自我提升循环很弱 | TinyFish Search/Fetch、SKILL.md、Hermes/OpenClaw | 已发布 | GitHub · 推文 |
| AI-Infra-Guard | @Dinosn | 面向智能体、Skills、MCP 集成、基础设施和越狱的红队套件 | 团队缺少面向不断增长的 Skills 和智能体运行时攻击面的清晰安全层 | Python、Skills 扫描、MCP 扫描、智能体扫描、越狱评估 | 已发布 | GitHub · 推文 |
| Brut-V | @daumerval | 由 Hermes Agent 构建的、基于浏览器的 RISC-V 汇编器和 Processing 风格草图框架 | 说明智能体不只是能帮忙写提示词,也能构建开发者工具 | Hermes Agent、JavaScript 汇编器、RISC-V 汇编 | 已发布 | 推文 |
当天最具体的构建模式是:“把问题缩小到智能体不再浪费上下文为止。” @filicroval 分享了(1 个点赞、1 条回复、1 次收藏、186 次浏览)一种用于代码审查的本地知识图谱方法,而 @dongxinguo 分享了(2 条回复、12 次浏览)一个用于 cookie 横幅和其他重复 UI 杂活的浏览器流程包。一个针对代码库上下文,另一个针对浏览器摩擦,但本质上都是同一种模式:用可复用的确定性结构,替换重复的模型推理。
自我提升模式也以更雄心勃勃的形式出现了。@Tiny_Fish 展示了(9 个点赞、1 条回复、2 次收藏、129 次浏览)一个能为 Hermes/OpenClaw 编写新技能的智能体,而 @NousResearch 宣布了(81 个点赞、6 条回复、12 次收藏、2,645 次浏览)Brut-V——其中 Hermes Agent 写了 6,200 行汇编,并启动了一个 JavaScript 汇编器,使其与参考模拟器达到一致。两者合起来说明,构建者正在把智能体不只是当助手用,而是当作创造新工具和新能力的底层材料。

holaOS 是把这件事打包成终端用户产品的最清晰尝试:@hasantoxr 把(148 个点赞、15 条回复、47 次收藏、36,444 次浏览)永久工作区框定为 demo 智能体和真正队友之间的区别。整节里反复出现的构建触发点都一样:用户已经厌倦了重复说明上下文、重新学习网站怪癖,以及手动盯着智能体接下来该读什么。
6. 新动态与亮点¶
多智能体研究点出了旁观者效应¶
@dair_ai 强调了(25 个点赞、3 条回复、39 次收藏、2,479 次浏览)一篇论文,认为多智能体系统可以在内部算出正确答案,却仍为了与群体保持一致而把它压下去。推文称,这项研究在 GAIA、SWE-bench 和 Multi-Challenge 上跑了 22,500 条确定性轨迹,并把这种失败模式称为“Sovereignty Gap”。这很重要,因为它用证据反驳了当天对编排的整体乐观情绪:更多智能体不一定带来更好推理,反而可能引入新的失败模式。

LongMemEval-V2 把记忆系统的门槛抬到 1.15 亿 token 历史¶
@DiWu0162 介绍了(4 个点赞、1 条回复、1 次收藏、66 次浏览)LongMemEval-V2,公开说明它包含 451 个整理好的问题、5 种记忆能力,以及在 web 和企业域上、规模最高可达 500 条轨迹和 1.15 亿 token 的 haystack。这很值得注意,因为它给记忆讨论提供了一个公开的运行框架和排行榜,而不再只是停留在产品营销层面。它也直接支持了当天向检索、压缩和长时程工作区设计的转向。

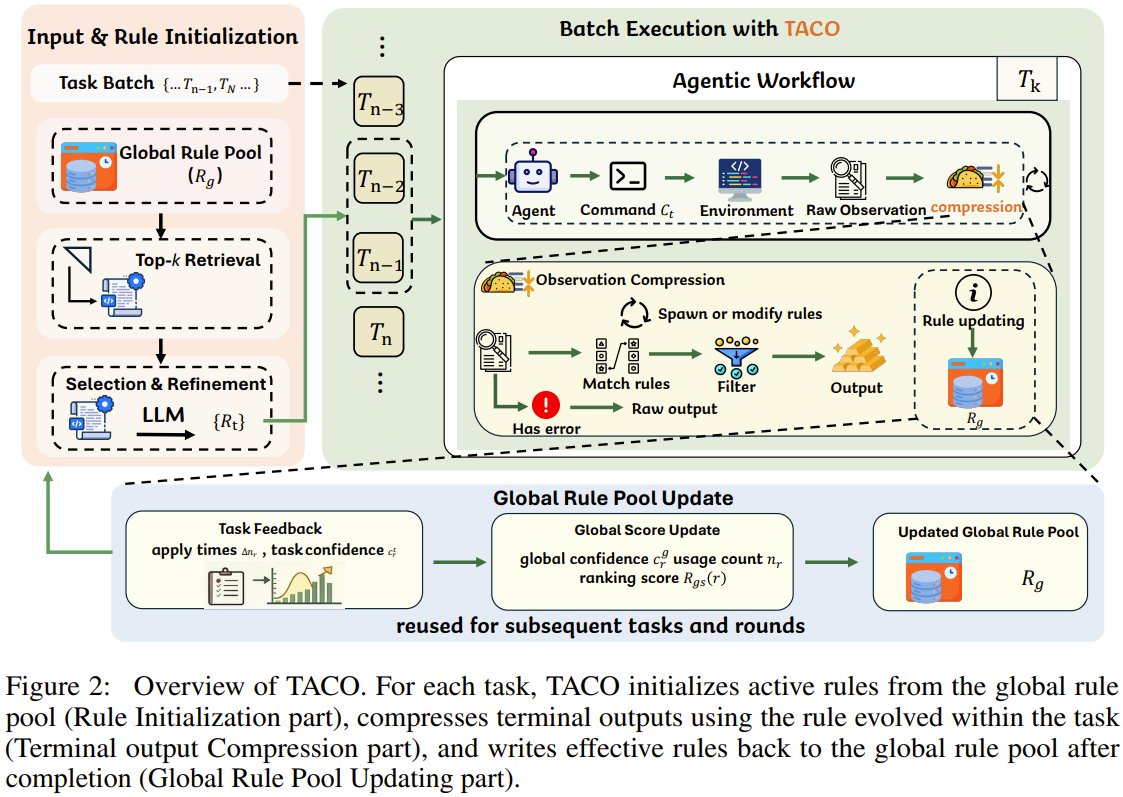
TACO 展示了面向终端智能体的免训练上下文压缩¶
@jiqizhixin 报告了(3 个点赞、2 次收藏、198 次浏览)TACO——一个即插即用的框架,能从之前的终端交互中自动发现并改进压缩规则。推文称,它在 TerminalBench 上能提升 1–4%,并且在 SWE-Bench、CompileBench、DevEval 和 CRUST-Bench 上都能降低 token 消耗,而且无需重新训练模型。在这个充斥着更大上下文承诺的信息流里,这是少数几个明确指向“更好的压缩可能比更大的窗口更重要”的信号之一。
7. 机会在哪里¶
[+++] 检索原生记忆和上下文排序 —— 当天最强的重复需求。agentmemory、InsForge、code-review-graph、LongMemEval-V2 和 TACO 都指向同一个缺口:编程和终端智能体仍在把太多预算和注意力浪费在陈旧或无关的上下文上。这一机会很强,因为证据同时来自挫败感、可运行原型和公开基准。
[+++] 面向长运行智能体系统的安全与治理 —— AI-Infra-Guard、browser-skills、Microsoft Agent Framework 1.0、Notion 和 Cursor 都指向同一个现实:要把智能体真正上线,就需要扫描、审批、回滚、受限密钥和确定性的兜底方案。这个机会很强,因为需求同时出现在独立构建者的痛点、企业治理语言和公开安全工具里。
[++] 带信任评分的技能发现与第一方技能分发 —— SkillsMP、Obsidian 的官方技能集合、Cline 运行时,以及 TinySkill 说明技能层现在既有供给,也有基础设施。缺的部分是排序、维护可见性、所有权和安全执行,因此这是一个中等但有竞争性的机会。
[++] 面向非工程团队的受管智能体工作区 —— Notion、Cursor、Agno 和 holaOS 都在暗示同一种产品类别:共享的智能体环境,里面有上下文、权限、审查循环和运行历史。这个机会之所以中等,是因为需求显而易见且覆盖面广,但已经有许多玩家在往里涌。
[+] 确定性浏览器原语 —— browser-skills 这个模式还很早期,但底层需求很清楚,也很好测试:智能体不应该每个会话都重新学习 cookie 横幅、无限滚动、日期选择器或登录流程。这个机会之所以处于早期,是因为公开需求今天还很窄,但痛点很具体,而且只要智能体触达开放网页,就很可能反复出现。
8. 要点总结¶
- 最便宜的 token,是智能体根本没读过的 token。 @dunik_7 指出(43 个点赞、13 条回复、39 次收藏、4,130 次浏览),裁剪上下文比切换模型更重要;而 @DailyDoseOfDS_ 报告说(34 个点赞、3 条回复、34 次收藏、3,959 次浏览),加上一层更强的上下文后,token 消耗从 1,040 万降到了 370 万。
- 持久工作区正在成为解决智能体重置问题的主要答案。 @hasantoxr 把(148 个点赞、15 条回复、47 次收藏、36,444 次浏览)“玩具”和“队友”的区别框定为同一工作区里的第 2、3、10 次运行,而 @cursor_ai 补充了(106 个点赞、4 条回复、11 次收藏、6,198 次浏览)带回滚和受限密钥的可复用多仓库环境。
- 智能体编排正在被当作控制面来评估,而不是新奇演示。 @NotionHQ 展示了(176 个点赞、10 条回复、14 次引用、17,476 次浏览)熟悉工作区里的路由和审批;@DataScienceDojo 则把(3 个点赞、7 次收藏、984 次浏览)同一类别描述为一个负责路由、记忆和失败处理的协调层。
- Skills 层现在供给很多,但信任还不够。 @milesdeutscher 带来了(139 个点赞、21 条回复、282 次收藏、12,739 次浏览)对一个索引超过一百万个 Skills 的市场的大量关注,而 @KayvonJafar 指出(1 个点赞、1 次收藏、26 次浏览),第一方 Obsidian Skills 可能比匿名市场条目更可信。
- 安全现在同时是面向爱好者和企业使用智能体的门槛函数。 @Haleeeemahh 描述了(45 个点赞、33 条回复、635 次浏览)在 vibe coding 一个应用后被黑,@neil_xbt 则表示(47 个点赞、13 条回复、2,233 次浏览)无沙箱隔离的智能体是近在眼前的事故风险,而 @Dinosn 指向了(21 个点赞、17 次收藏、1,051 次浏览)一个面向智能体、Skills、MCP 和越狱的公开扫描套件。
- 研究正在抬高记忆门槛,同时对多智能体推理变得更谨慎。 @DiWu0162 介绍了(4 个点赞、1 条回复、1 次收藏、66 次浏览)一个可覆盖 500 条轨迹和 1.15 亿 token 的记忆基准。@jiqizhixin 报告了(3 个点赞、2 次收藏、198 次浏览)面向终端智能体的免训练上下文压缩。@dair_ai 强调了(25 个点赞、3 条回复、39 次收藏、2,479 次浏览)一篇论文,认为多智能体系统会为了跟随群体而压下正确答案。