Twitter AI Agent - 2026-05-23¶
1. What People Are Talking About¶
1.1 Harness engineering moved from a cost complaint to concrete repo infrastructure 🡕¶
The strongest May 23 cluster kept the May 22 harness/context discussion alive, but moved it from “context is expensive” into concrete artifacts people can install, benchmark, and teach. Seven retained items supported it: a high-engagement harness experiment, a diagram separating prompt/context/harness roles, a code-graph product, an AGENTS.md study, a repo-level code graph benchmark, a browser harness demo, and a self-evolving harness paper.
@_vmlops argued (397 likes, 5 replies, 24,034 views, 597 bookmarks) that Anthropic held model and prompt constant but changed the environment around the model: no harness meant $9, 20 minutes, and unusable output, while a full harness meant $200, six hours, and a playable result. The distinctive part was the checklist, not the price tag: instructions before tool use, persistent state, verification gates, scoped work, and a clean session lifecycle.
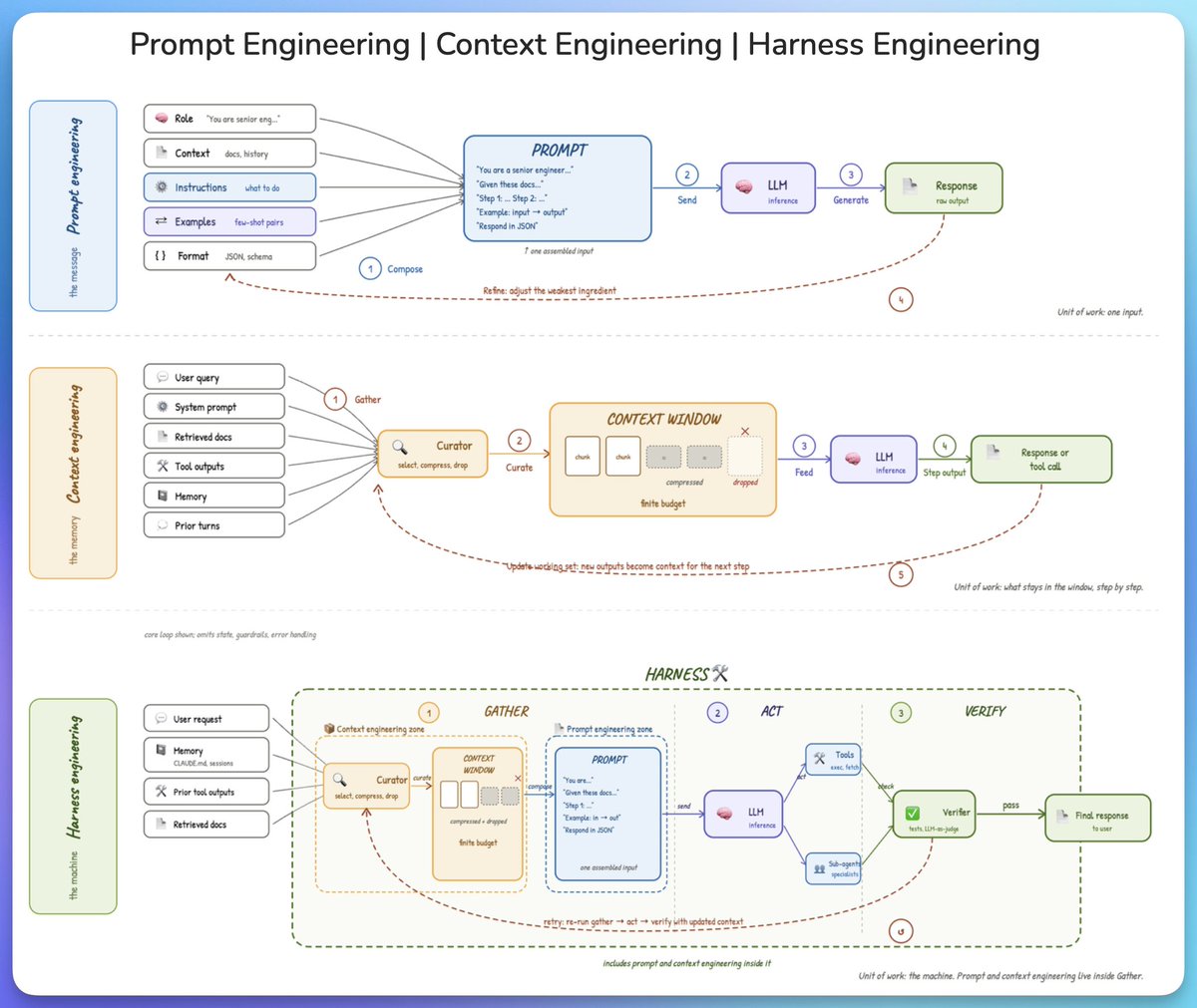
@akshay_pachaar wrote (367 likes, 22 replies, 34,564 views, 564 bookmarks) that prompt engineering is the message, context engineering is the memory, and harness engineering is the machine wrapping gather/act/verify loops. The attached diagram made the distinction visual enough that the replies treated it as shared vocabulary rather than another slogan.
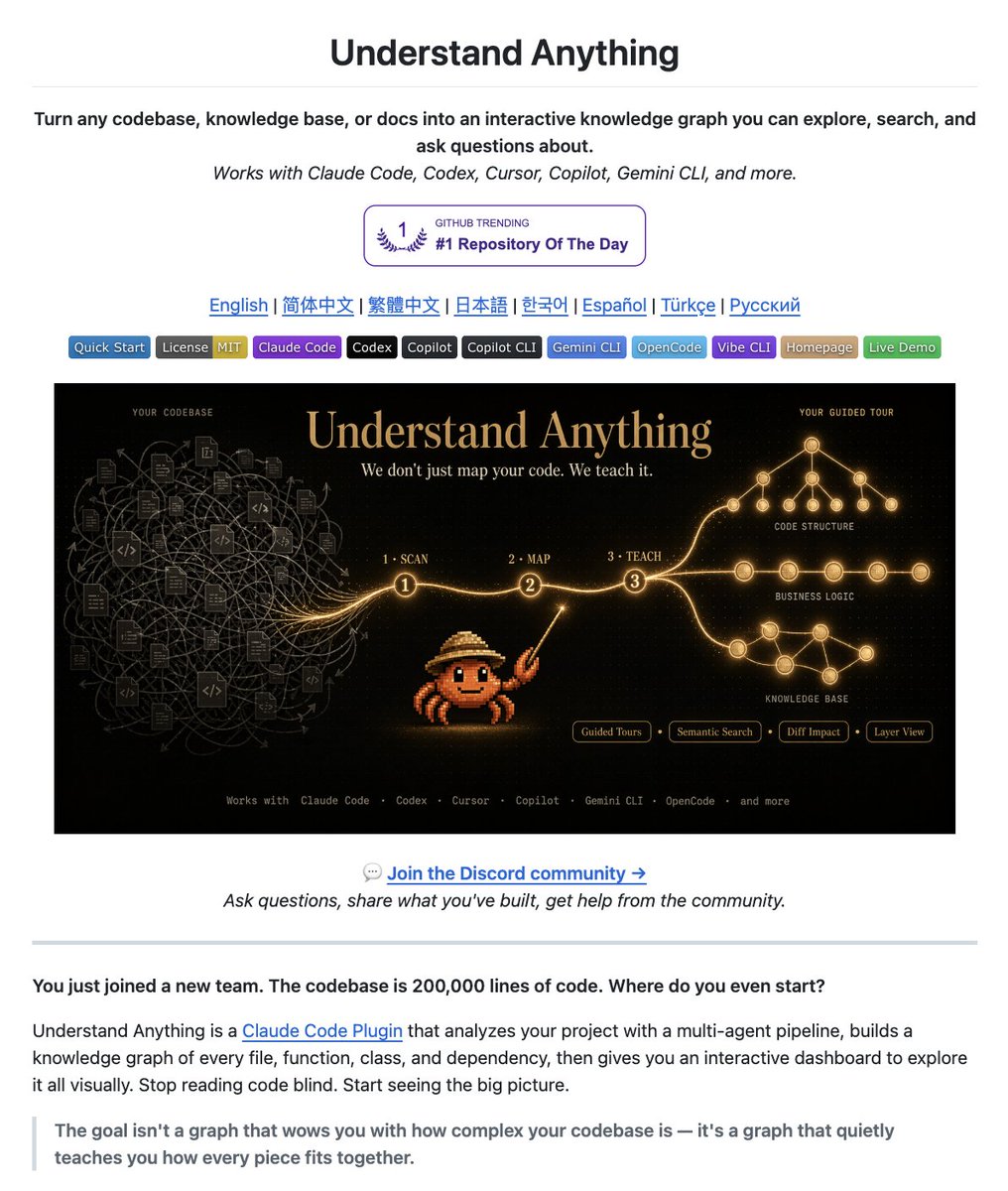
@Saboo_Shubham_ posted (63 likes, 13 replies, 4,975 views, 135 bookmarks) that Understand Anything turns a codebase into an interactive graph an agent can query instead of rereading files. The Understand Anything site says it adds business-domain views, guided tours, fuzzy and semantic search, and quick installs across Claude Code, Codex, OpenCode, Gemini CLI, and more; a reply from @SynabunAI warned that the graph is only as fresh as its last index, so stale edges can leave agents confidently reasoning about deleted code.
@IntuitMachine claimed (5 likes, 2 replies, 266 views, 11 bookmarks) that one root-level AGENTS.md cut median runtime by 28.64% and output tokens by 16.58% across 124 pull requests; the arXiv abstract confirms those deltas across 10 repositories. Separately, @BeauJohnson89 highlighted (106 views) CodeGraph, whose README says a pre-indexed local graph cut cost by 35%, tokens by 59%, time by 49%, and tool calls by 70% across seven codebases, while @TheDawningRoad shared (6 likes, 6 retweets, 37 views) the AHE paper, which frames harness improvement as an observable loop over components, experience, and decisions.
Discussion insight: The most useful pushback was not “use less context,” but “make the context fresher and more attributable.” Replies on the graph post asked for durable task state and warned that stale indexes can be worse than no index at all.
Comparison to prior day: May 22 focused on token budgets, long-context economics, and harness taxonomies. May 23 kept that framing but shifted decisively toward repo-level fixes like code graphs, AGENTS.md, and self-evolving harnesses.
1.2 Skill files turned into a software layer and a security boundary 🡕¶
A second cluster treated SKILL.md, AGENTS.md, and adjacent instruction files as real software artifacts rather than hidden prompt fragments. Five items backed it: a widely shared warning about downloading skills from the internet, an AGENTS.md efficiency study, a tool that manufactures agent instruction files from expert corpora, a new agent-skills curriculum, and an ongoing push to keep these files versioned and explicit instead of implicit.
@AlexFinn warned (289 likes, 46 replies, 9,768 views, 150 bookmarks) not to download agent skills from the internet because public skill directories are becoming a prompt-injection surface. The thread got more useful in replies: @Trish_DIntel replied that even asking an agent to inspect a malicious skill can be unsafe because the payload is already in the context window, and @TulioSousapro argued that the safe version is manual human inspection followed by a separate description to the model.
@DanKornas introduced (7 likes, 252 views, 12 bookmarks) mimeo, a Python tool that turns an expert's public body of work into a ready-to-use SKILL.md or AGENTS.md. The repo says it discovers sources, fetches transcripts and articles, clusters recurring ideas, verifies quotes against original text, and runs a critique pass before outputting the artifact.

@IntuitMachine used (5 likes, 2 replies, 266 views, 11 bookmarks) the new AGENTS.md paper to argue that better repository instructions beat more prompt tinkering, while @omarsar0 launched (97 likes, 6 replies, 8,484 views, 123 bookmarks) a new DAIR Agentic Engineering lab whose first public module is “Build Your First Agent Skill.” That pairing mattered: people were not just shipping skill files, they were teaching them and measuring them.
Discussion insight: The debate was not whether instruction files matter; it was whether the ingestion path is safe. The day's strongest replies assumed these artifacts are here to stay and focused on how to author, vet, and version them without handing an agent hostile instructions.
Comparison to prior day: May 22 highlighted official vendor skill packs and installable knowledge bundles. May 23 widened the frame to include secure import, automated authoring, and measurable repo-level instruction files.
1.3 Persistent memory and multi-agent control rooms became more visible 🡕¶
The third strong cluster was about making long-lived agent systems visible and operable, not just giving them more memory. Five items supported it: a voice-enabled GBrain release, a typed-memory architecture explainer, a remember/cite/forget framework, a browser-based Hermes war room, and a terminal built around agent notifications.
@garrytan shipped (327 likes, 38 replies, 16,428 views, 260 bookmarks) GBrain v0.40.0 as a voice agent for OpenClaw and Hermes using Gemini Live. The GBrain README describes it as a persistent brain that ingests meetings, emails, tweets, and voice calls, while @neosphere_inc replied that voice-plus-tool use is constrained less by context length than by round-trip latency on each tool call.
@shannholmberg explained (19 likes, 8 replies, 605 views) how she is using GBrain as a memory layer under a Hermes company: markdown in, graph out; Markdown plus Postgres plus pgvector underneath; hybrid keyword, vector, and graph retrieval; and an overnight dedupe cycle that repairs links and updates compiled truth. A reply from @untold_bits added the key caution that human judgment still has to gate auto-ingestion or the system turns into “a massive ball of slop over time.”

@Voxyz_ai wrote (71 likes, 6 replies, 15,911 views, 155 bookmarks) that agent memory needs three distinct jobs — remember, cite, and forget — with layer, source, and expiry checks instead of one undifferentiated store. On the visibility side, @tom_doerr shared (13 likes, 1 reply, 1,947 views, 31 bookmarks) Hermes War Room, whose README describes a browser dashboard over Hermes delegation and kanban systems, while @lawrencecchen built (21 likes, 899 views, 9 bookmarks) cmux, a terminal with pane-level notifications because “you have to know when and where an agent wants to talk to you.”
Discussion insight: The common correction was that better memory alone is not enough. Builders kept adding provenance, expiry, notification, and review surfaces so humans can see what the agent remembers, what it is doing, and when it needs intervention.
Comparison to prior day: May 22 emphasized shared-memory layers and managed runtimes in abstract terms. May 23 turned that into user-facing products: voice fronts, typed-memory architecture posters, war rooms, and notification panes.
2. What Frustrates People¶
Public skill ingestion is still unsafe before inference¶
Severity: High. @AlexFinn warned (289 likes, 46 replies, 9,768 views, 150 bookmarks) that public skill sites are becoming an attack surface for prompt injection. The replies made the failure mode sharper: @Trish_DIntel replied that even letting an agent inspect a malicious skill is unsafe because the payload is already in the context window, while @TulioSousapro argued that the only safe variant is manual human review followed by a separate description to the model. @elsontec asked for a safer workflow entirely. The coping pattern today is “treat skills as untrusted input and rebuild from scratch,” but no strong evidence in the dataset showed a trusted vetting layer or sandbox that solves the problem cleanly. Worth building for because the demand was explicit and the failure happens before the model even starts doing useful work.
Repo context still goes stale or gets re-read expensively¶
Severity: High. @Saboo_Shubham_ posted (63 likes, 13 replies, 4,975 views, 135 bookmarks) a graph-based context tool precisely because agents still reread codebases instead of carrying forward structure, and @SynabunAI replied that stale edges can leave an agent confidently reasoning about code deleted three PRs ago. @Bushmaster18523 added that what people really lose across compaction and handoffs is durable task state: decisions, checkpoints, dead ends, and evidence. On the measurement side, @IntuitMachine cited the AGENTS.md paper, which found 28.64% lower median runtime and 16.58% lower output-token usage across 124 pull requests, while the CodeGraph README advertises lower cost, lower tokens, lower time, and fewer tool calls from pre-indexing. The workaround is to add repo instructions, keep an index warm, or distill traces after the fact, but each fix creates another layer that must stay current. Worth building for because multiple independent artifacts on the same day all existed to fix the same silent waste.
Memory layers become junk drawers without provenance and expiry¶
Severity: High. @Voxyz_ai wrote (71 likes, 6 replies, 15,911 views, 155 bookmarks) that piling more memory onto Hermes or OpenClaw produced a junk drawer until memory was split into remember, cite, and forget with layer, source, and expiry checks. @abdiisan replied that Hermes' built-in memory was hit-or-miss across long sessions until Mnemosyne replaced it with hybrid vector plus text search, and @shannholmberg showed a more structured alternative with typed links, hybrid retrieval, and overnight dedupe. A reply from @untold_bits summarized the remaining problem: auto-ingestion is fast, but without a human quality gate it can turn into “a massive ball of slop over time.” Worth building for because builders are still solving this with custom plugins, schema packs, and cleanup jobs instead of a stable default.
Orchestration overhead still repels a meaningful slice of developers¶
Severity: Medium. @ThePrimeagen posted (963 likes, 68 replies, 32,835 views) that there is “so much peace in deep thought instead of some insane frenetic agent orchestration fever dream,” and the replies were full of people saying they still enjoy slow, manual building more than agent-heavy workflows. That frustration did not only come from skeptics: @simonlast advised (304 likes, 14 replies, 28,727 views, 171 bookmarks) improving the testing harness while explicitly warning that “usually, simpler is better,” and @_avichawla wrote (51 likes, 9 replies, 5,980 views, 79 bookmarks) that one agent with good tools usually beats a multi-agent stack. The coping pattern is to push deterministic control logic into runtime code, keep human-in-the-loop as a design pattern, and avoid adding agents where a cheaper rule would do. Worth building for as a design constraint: products that add orchestration overhead without adding legibility will keep losing users back to simpler loops.
3. What People Wish Existed¶
Safe skill vetting before an agent ever sees the file¶
This was an urgent, practical need rather than a vague wish. @elsontec asked how to follow the popular “analyze then rebuild” advice while staying protected against prompt injection, and @JoeJ45665 asked whether any vetted marketplace exists at all. The replies from @Trish_DIntel and @TulioSousapro made the gap explicit: the problem has to be solved before inference, because once the model reads the hostile instructions the damage may already be done. Today the only partial answer in the dataset is manual human review plus rebuilding from scratch, which does not scale. Opportunity: direct.
Faster, auditable authoring of AGENTS.md and SKILL.md¶
People were not only using instruction files; they were asking for a better way to create them. @DanKornas said writing a good AGENTS.md should not take weeks of source digging, and mimeo exists precisely to discover sources, distill them, verify quotes, and emit the final artifact. @omarsar0 started a new curriculum with agent skills as lesson one, while the AGENTS.md paper suggests the payoff is measurable once those files exist. That makes this both a practical and competitive need: people want auditable defaults, but current authoring still looks manual or model-dependent. Opportunity: direct and competitive.
Fresh repo maps with durable task state¶
The need was not just “better retrieval.” @Saboo_Shubham_ showed one answer in code graphs, but @SynabunAI warned that stale edges poison the result, and @Bushmaster18523 asked for durable task state that survives compaction, tool switches, and handoffs. The CodeGraph README and AGENTS.md paper both point to partial answers, but neither removes the freshness problem by itself. This is a practical need with clear ROI and an already forming market. Opportunity: direct and competitive.
Human control rooms for fleets of agents¶
The day’s builders kept asking for visibility, not just more autonomy. @lawrencecchen built cmux because a human needs to know when and where an agent wants to talk, @tom_doerr shared Hermes War Room to make delegation and kanban state visible from a browser, and @wyckoffweb wrote that users should always know whether a task is funded, assigned, submitted, locked, or ready for review. Existing products partially address this with dashboards and notifications, but the underlying need is broader: a clear work surface that makes many agents legible to one operator. Opportunity: direct.
Local-language voice agents that keep humans on approval duty¶
@dadbodshuffl built (56 likes, 6 replies, 4,743 views, 37 bookmarks) a Gujarati, Hindi, and English voice-shopping agent that uses deterministic runtime steps for browser actions and only updates the Blinkit cart after explicit approval. The replies immediately shifted from “cool demo” to concrete use cases: @buildwithsid wanted something similar for his mother, and @ankit_auth said he could imagine the same pattern for a rural manufacturing business. Partial answers exist in voice stacks and browser tools, but the combination of local language, runtime determinism, and explicit approvals is still rare. Opportunity: emerging.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Harness engineering | Method | (+) | Makes agent behavior explicit through instructions, persistent state, verification gates, and session lifecycle | Can sprawl into extra orchestration work if teams over-design the loop |
AGENTS.md |
Repo instruction file | (+) | Repo-specific architecture, commands, and conventions reduce exploration detours; the arXiv study reported 28.64% lower median runtime and 16.58% fewer output tokens | Only works when kept current; authoring and maintenance become their own job |
| Understand Anything | Code graph / onboarding | (+/-) | Interactive graph, business-domain views, guided tours, and quick installs across major agents | Replies warned stale indexes can mislead agents; large graphs still need freshness discipline |
| CodeGraph | Code graph / indexing | (+) | Pre-indexed local graph; README advertises lower cost, tokens, time, and tool calls across seven codebases | Requires upfront indexing and the benchmark claims are project-supplied |
| GBrain | Memory layer | (+/-) | Typed knowledge graph, hybrid retrieval, overnight dedupe, and a voice-ready personal-agent surface | Auto-ingestion still needs human quality gates and more infrastructure than prompt-only setups |
| Mnemosyne | Memory plugin | (+) | Hybrid vector plus text search and entity recall for Hermes sessions | Narrow ecosystem fit and limited public evidence outside a reply thread |
| Hermes Agent | Agent runtime | (+/-) | Multi-profile delegation, SOUL.md and skills, kanban, and an active add-on ecosystem | Built-in memory can be hit-or-miss on long sessions; visibility often comes from add-ons |
| cmux | Terminal UI / notifications | (+) | Pane notifications, sidebar metadata, in-app browser, and session restore for many concurrent agents | macOS-only and most useful only once a team is already juggling many sessions |
| Browser Harness | Browser automation | (+) | Self-healing harness can pick better paths than the literal UI flow | Public evidence is still demo-heavy and behavior can feel opaque |
| Local open stack (Qwen 3, Ollama, CrewAI, Cline, Browser Use, ChromaDB, Whisper, HF Spaces, OpenRouter, MCP) | Local/open stack | (+/-) | Low subscription cost and broad coverage from model to browser to speech | Hidden costs are wiring time, laptop limits, routing choices, and uneven model quality |
| mimeo | Skill authoring | (+) | Automates source discovery, verification, critique, and SKILL.md or AGENTS.md output |
Early project; artifact quality still depends on source selection and model behavior |
| Dispatch | Agent marketplace | (+/-) | Funded tasks, clear status, review before payout, and reputation accumulation | Still early and testnet-based; trust and dispute handling are not proven |
The most positively received tools were the ones that externalized state: repo instructions, pre-indexed graphs, typed memory layers, and notification surfaces. Sentiment turned mixed as soon as freshness or operational overhead entered the picture — graphs go stale, memory layers ingest slop, local stacks melt laptops, and orchestration surfaces add work unless they reduce it. The migration pattern was away from raw prompt tweaks and invisible background agents toward repo-level instruction files, graph and index layers, and human-facing control rooms. Competitive tension is clearest in repo understanding: Understand Anything emphasizes business logic and guided tours, while CodeGraph emphasizes lower tokens and fewer tool calls from a pre-indexed local graph.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| GBrain v0.40.0 | @garrytan | Adds Gemini Live voice to a persistent OpenClaw/Hermes brain | Personal agents forget cross-session context and lack a natural interface | GBrain, Gemini Live, OpenClaw/Hermes, typed knowledge graph, hybrid retrieval | Alpha | tweet, repo |
| Understand Anything | Lum1104 | Turns a codebase into an interactive graph with business-domain views and guided tours | Agents reread repos and lack structural or business context | TypeScript, multi-agent analysis pipeline, interactive dashboard, plugin installs | Shipped | tweet, site, repo |
| Orchestration War Room | Naroh091 | Browser dashboard over Hermes delegation and kanban | Multi-agent fleets are hard to observe from raw terminal sessions | Vue, Node, Hermes CLI, browser dashboard | Beta | tweet, repo |
| cmux | @lawrencecchen | Ghostty-based terminal with notifications, browser panes, and session restore for coding agents | Operators need to know which parallel agent needs attention and keep long-lived sessions manageable | Swift, AppKit, libghostty, in-app browser, session restore | Shipped | tweet, repo |
| mimeo | @DanKornas | Generates SKILL.md or AGENTS.md from an expert's public corpus with verification and critique |
Writing good agent defaults by hand takes too long | Python, Parallel Search API, OpenRouter, optional Whisper | Alpha | tweet, repo |
| Dispatch | @wyckoffweb | Agent marketplace with funded tasks, review, payout, and reputation | Agents need a real work layer, not just a chat box | Arc testnet, USDC, live frontend and backend, task contracts | Beta | tweet, site |
| Blinkit local-language voice shopper | @dadbodshuffl | Takes Gujarati, Hindi, or English voice requests, drives Blinkit in a browser, and waits for approval before cart changes | Non-English users need hands-free commerce without surrendering control | Sarvam Saarika, Saaras, Sarvam Translate, local runtime, Playwright, Blinkit | Alpha | tweet |
@Saboo_Shubham_ surfaced (63 likes, 13 replies, 4,975 views, 135 bookmarks) the most representative build pattern of the day: externalizing hidden context into something an operator can inspect. Understand Anything does that with a graph plus business-domain view, while GBrain does it with a typed memory layer and mimeo does it with explicit SKILL.md or AGENTS.md artifacts. These are different products, but they all move agent state out of a long prompt and into a structure that can be revisited, versioned, or audited.
@wyckoffweb described (62 likes, 16 replies, 3,085 views, 8 bookmarks) Dispatch as a real work layer where tasks are funded, assigned, reviewed, and only then paid out. The quoted earlier thread made the distinction explicit: the point is not to list agents but to give them task history, payout logic, and reputation that compound across completed jobs.

Hermes War Room and cmux attack the same bottleneck from opposite ends: one gives a browser control room over delegation and kanban, the other gives a terminal-native notification layer when many agents are running in parallel. @dadbodshuffl added (56 likes, 6 replies, 4,743 views, 37 bookmarks) the clearest approval pattern in the dataset by letting runtime code handle browser actions and only committing the cart update after explicit approval. The repeated pattern across May 23's builds was not “more autonomy at any cost”; it was more explicit state, clearer handoffs, and tighter approval boundaries around real actions.
6. New and Notable¶
The AGENTS.md study put hard numbers on repo instruction files¶
@IntuitMachine pointed (5 likes, 2 replies, 266 views, 11 bookmarks) to the new arXiv paper on repository-level instruction files for coding agents. The abstract matters because it turns a folk best practice into measured evidence: across 10 repositories and 124 pull requests, the AGENTS.md condition produced 28.64% lower median runtime and 16.58% lower output-token usage while keeping comparable task completion behavior. That is the clearest quantitative support in the dataset for repo-specific agent instructions as an efficiency primitive rather than mere documentation hygiene.

Agentic Harness Engineering turned harness tuning into an observable closed loop¶
@TheDawningRoad shared (6 likes, 6 retweets, 37 views) the AHE paper and repo for self-evolving coding-agent harnesses. The paper's distinctive claim is structural, not rhetorical: it breaks harness improvement into component observability, experience observability, and decision observability, then reports a GPT-5.4 Terminal-Bench 2 pass@1 lift from 69.7% to 77.0% over 10 iterations; the repo README further says the system later ranked third on Terminal-Bench 2.0 with GPT-5.5. That made AHE the day's most substantive low-engagement artifact.
DAIR made agent skills the first lesson in a new agentic-engineering curriculum¶
@omarsar0 launched (97 likes, 6 replies, 8,484 views, 123 bookmarks) a new series on Agentic Engineering and explicitly started with Agent Skills. The public labs page currently advertises “Build Your First Agent Skill,” with context engineering, multi-agent systems, and long-running agents positioned as the next modules. That is notable because it shows skills and harness work solidifying into a curriculum, not just a stream of disconnected builder threads.
7. Where the Opportunities Are¶
[+++] Skill-ingestion security and pre-inference sandboxing — Evidence from sections 1, 2, and 3 all points the same way: skill files are becoming load-bearing, but the AlexFinn thread and its replies say current “analyze then rebuild” workflows can still be compromised during ingestion. Demand was explicit, the pain is immediate, and the dataset did not surface a trusted default solution.
[+++] Fresh repo context plus durable task-state infrastructure — Understand Anything, CodeGraph, the AGENTS.md paper, and AHE all attack the same problem from different angles: agents reread too much, forget too much, or operate on stale structure. The reply from @Bushmaster18523 widened the need from retrieval to durable decisions and evidence across handoffs. That combination of pain, ROI, and repeated builder effort makes this the strongest opportunity on the page.
[++] Auditable authoring and lifecycle management for SKILL.md and AGENTS.md — Dan Kornas's mimeo project, DAIR's new labs, and the AGENTS.md efficiency paper all suggest instruction files are becoming a real software surface with measurable payoff. The missing layer is not only generation but review, diffing, provenance, and safe rollout of those files over time.
[++] Human control rooms for multi-agent work — Hermes War Room, cmux, and Dispatch all exist because people want to know which agent is working, blocked, waiting, or ready for review without parsing logs by hand. Several teams are already building here, so the opportunity is less greenfield than skill security, but the demand signal is unmistakable.
[+] Local-language voice agents with approval-first runtime design — The dadbodshuffl build and its replies show a practical, underserved corner of the market: voice interfaces in local languages, deterministic runtime steps for the risky parts, and explicit approval before state changes. The evidence is still emerging, but the downstream user requests were immediate and concrete.
8. Takeaways¶
- Harness engineering is being treated as repo infrastructure, not model folklore. The day's strongest evidence came from explicit scaffolding artifacts —
_vmlopson harness components and costs, Akshay's prompt/context/harness taxonomy, and theAGENTS.mdpaper on runtime and token savings — rather than from claims about bigger context windows alone. (source) - Instruction files are now both a performance lever and an attack surface.
SKILL.mdandAGENTS.mdare becoming standard enough to benchmark, teach, and auto-generate, but the AlexFinn thread showed the ingestion path is still dangerously under-solved. (source) - The next memory gains come from provenance, expiry, and visibility, not just more storage. The remember/cite/forget framing, the typed gBrain architecture, and the Mnemosyne workaround all pointed to the same lesson: undifferentiated memory accumulates faster than it clarifies. (source)
- Builders are wrapping agents in human-facing state surfaces before trusting them with real work. Dispatch's review-before-payout flow, Hermes War Room's browser dashboard, cmux's notification rings, and dadbodshuffl's explicit approval before cart updates all make the same design bet: visibility comes before autonomy. (source)
- Orchestration complexity is now a product risk in its own right. Even on a day full of control rooms and harness tools, one of the highest-engagement tweets was ThePrimeagen saying manual deep thought feels saner than “frenetic agent orchestration,” with simonlast independently warning that simpler is usually better. (source)