Twitter AI Agent - 2026-05-26¶
1. What People Are Talking About¶
1.1 Skills became trainable products and reusable engineering assets 🡕¶
The strongest May 26 shift was that “skills” stopped looking like private prompt cargo and started looking like portable assets. In the high-signal set they appeared in three forms at once: sellable marketplace products, trainable external state for agents, and reusable engineering habits that install across runtimes. Compared with May 25’s emphasis on memory layers and harness glossaries, May 26 pushed the same idea into monetization, optimization, and distribution.
@Capafyai launched (373 likes, 227 replies, 254 quotes, 119,630 views) Capafy as a marketplace where skills built in Claude Code, Codex, or OpenClaw can run online while staying closed-source. The live Capafy site already lists expert agents for e-commerce ads, resume screening, social copy, PDF generation, and data analysis, and the Capafy-skills repo explains two client flows — Capafy-Publisher and Capafy-User — plus a key commercial distinction between closed-source Run Online modes and plain Download modes.
@koylanai argued (231 likes, 502 bookmarks, 55,849 views) that SkillOpt turns SKILL.md files into trainable parameters with held-out validation gates, bounded edit budgets, and cross-harness portability. The attached figure makes the thesis unusually concrete: accepted edits are small, validated, and reusable rather than broad rewrites. The SkillOpt repo and paper back that up with benchmark coverage across six tasks and reported gains including +24.8 points for GPT-5.5 in a Codex-style harness.
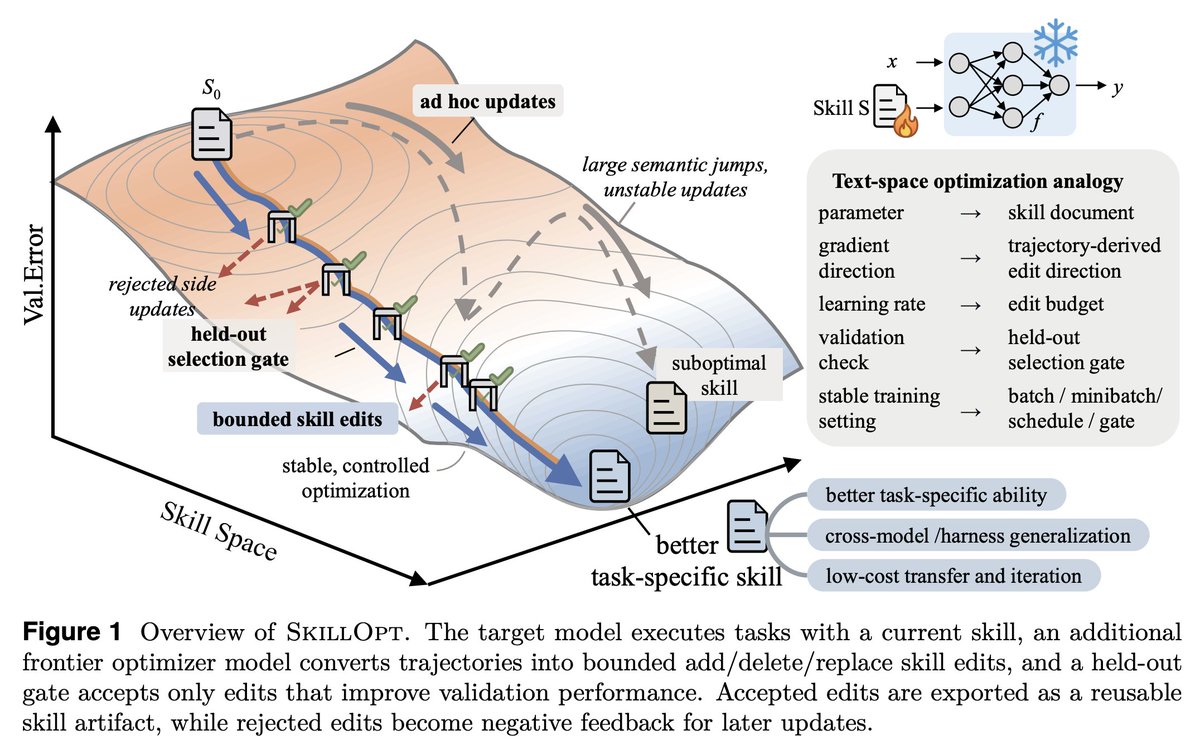
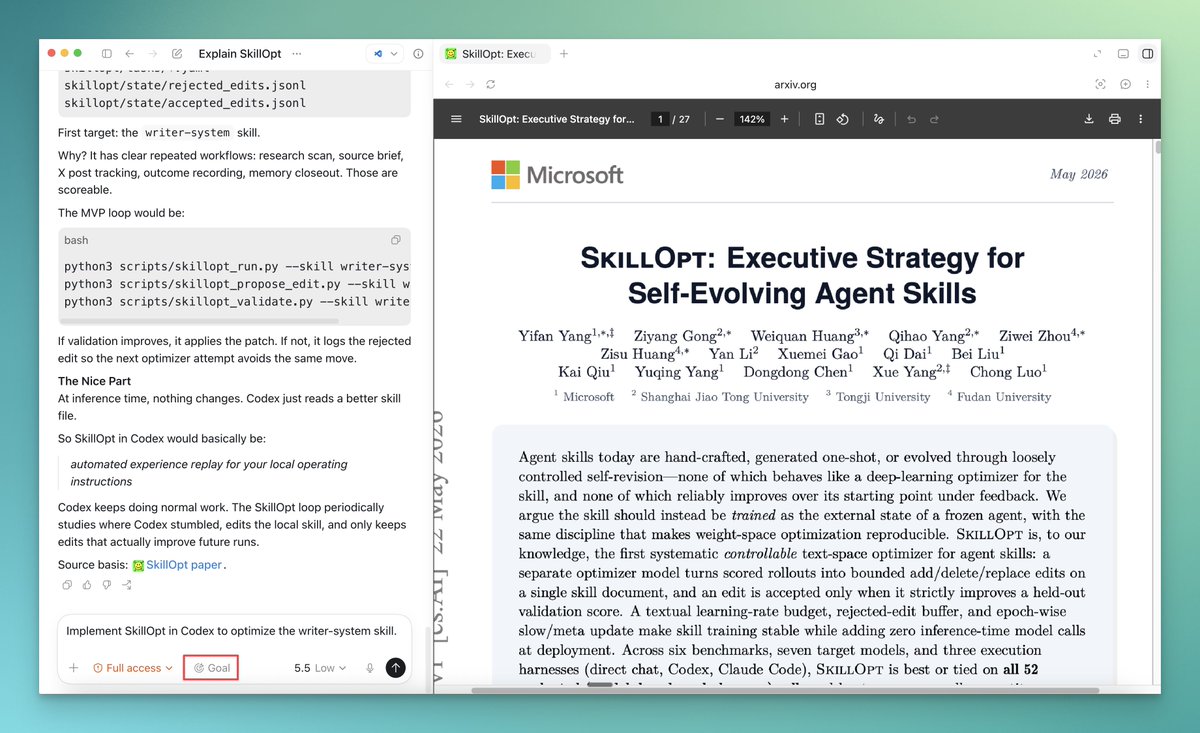
@daniel_mac8 translated (281 likes, 10 replies, 18,606 views, 343 bookmarks) that research idea into a working Codex habit: read the paper, enter /goal mode, and implement the loop in local config. The screenshot matters because it shows the paper on one side and a concrete script-and-goal workflow on the other, which turns “trainable skills” into an immediately actionable pattern for coding agents rather than another bookmark.
@HiTw93 packaged (47 likes, 9 replies, 10,160 views) Waza as eight engineering skills spanning planning, design, debugging, review, reading, writing, research, and health checks. The Waza repo shows install flows for Claude Code and Codex plus manual skill chaining, which makes the post more than a slogan about habits: it is a concrete cross-agent distribution story for reusable engineering behavior.

Discussion insight: The replies did not reward vague “self-improving agent” talk. They kept returning to per-skill measurement, bounded diffs, install surfaces, and whether a skill can be validated or sold without leaking the underlying know-how.
Comparison to prior day: On May 25, skills were mostly discussed as memory layers and reusable knowledge files. On May 26, the same substrate was treated more aggressively as something that can be trained, installed, and monetized.
1.2 Harness design moved from concept to governance and operability 🡕¶
The second major theme was that harness engineering became less about diagrams and more about control points: where policy is enforced, where state lives, and what breaks when an agent has real permissions or more than one user. The strongest posts paired research language with concrete implementation surfaces such as YAML policy kernels, Postgres-backed state, and composable memory layers.
@_vmlops highlighted (215 likes, 8 replies, 15,069 views, 364 bookmarks) Microsoft’s Agent Governance Toolkit as a deterministic layer that intercepts tool calls before they hit the wire, with YAML policies, identity, sandboxing, and tamper-evident logs. The AGT repo README explicitly frames prompt-level safety as a non-control surface, but the most substantive reply added an important limit: tool-call enforcement does not see malicious instructions inside the prompt or sensitive content in the output, so teams still need separate input/output defenses.
@dair_ai reframed (59 likes, 10 replies, 3,530 views, 54 bookmarks) the entire problem as “system scaling,” arguing that agent quality now emerges from memory, context construction, skill routing, orchestration, verification, and governance rather than model size alone. The paper image is important because it names three harness bottlenecks directly — context governance, trustworthy memory, and dynamic skill routing — and ties them to a reference harness, CheetahClaws, that the project page describes as Python-native and model-agnostic.

@Hey_Amiko said (9 likes, 190 views) OpenHermit exists because local files, secrets, and session state fall apart once an agent system goes beyond one user. The OpenHermit site and repo make the boundary explicit: internal state in PostgreSQL, external state in per-agent sandboxes, plus fleet-wide rollout commands for skills and MCP servers. @mattapperson released (94 likes, 7 replies, 11,134 views, 120 bookmarks) Noetic in the same spirit, with seven composable primitives and a multi-layer memory model that tries to make context boundaries readable instead of magical.
Discussion insight: The replies converged on the same boundary condition: prompts are not enough. Even optimistic posts were met with demands for versioned policies, explicit rollbacks, centralized state, and deterministic enforcement outside the model.
Comparison to prior day: May 25’s harness discussion was still dominated by explainers, diagrams, and resource maps. May 26 pushed the conversation down into runtime policy, fleet operations, and harness-level bottlenecks that have to be engineered directly.
1.3 Real-time agents picked up faster voice loops and visual front ends 🡕¶
A smaller but clear cluster focused on what agents look and sound like once the back-end loop gets fast enough. The common thread was not a new model release by itself, but wrappers around existing agents: lower-latency inference for conversation, dynamic canvases instead of fixed chat panes, and avatar layers that add visual presence without replacing the rest of the stack.
@kwindla reported (88 likes, 4 replies, 7,712 views, 56 bookmarks) that Cerebras-served Kimi K2.6 can run reasoning-enabled voice-agent turns in under 500ms, which matters because reasoning latency usually makes conversational agents feel unusable. The linked Cerebras blog claims 981 output tokens per second and a 29x faster time to final answer than the official Kimi endpoint, while Kwindla’s reply spells out the practical stack: Pipecat Smart Turn, Nemotron streaming ASR, Cerebras Kimi K2.6, and Kyutai Pocket TTS.
@pika_labs shared (128 likes, 18 replies, 6,985 views) “Generative UI,” a voice-controlled interface where the agent emits new HTML layouts every turn instead of filling a static shell. The linked generative-ui README says it is a local-only prototype built with OpenAI Realtime, the Pika MCP, and optional Google Workspace tools, and the replies stress that it is intentionally rough rather than production-ready.
@AiwithYasir amplified (59 likes, 11,420 views) LiveAvatar’s plug-in path for LiveKit, Pipecat, Agora, and VisionAgent. The LiveKit LiveAvatar docs describe it as a Python avatar session layered into an existing voice app, which reinforces the day’s larger pattern: multimodal presence is being added as a wrapper around the current agent stack, not treated as a separate stack.
Discussion insight: These posts assumed the core agent already exists. The work is shifting toward latency, visual composition, and presence layers that make the same underlying agent feel more conversational and less terminal-bound.
Comparison to prior day: Voice and UI signals were more visible on May 26 than on May 25. The move was from general “voice agent” enthusiasm toward concrete claims about sub-500ms loops, dynamic canvases, and avatar plug-ins.
2. What Frustrates People¶
Prompt-only security keeps failing at the exact moment people need trust¶
Severity: High. @RoundtableSpace recommended (50 likes, 14 replies, 37,788 views) a single Claude prompt for security review, but the replies all cut the same way: @Trish_DIntel said the model cannot reliably identify what it would fall for, @OraclesTech argued that the same model vulnerable to prompt injection cannot guard itself, and @0xDawny called for code audits instead of prompt fixes. The AGT thread sharpened the same frustration from the opposite direction: @_vmlops surfaced (215 likes, 8 replies, 15,069 views, 364 bookmarks) deterministic tool-call governance, but a detailed reply still said teams need separate prompt and output defenses. @tom_doerr shared (17 likes, 8 replies, 1,242 views, 22 bookmarks) Cisco’s Skill Scanner as a best-effort response, and even that thread immediately asked whether it can catch multi-step exfiltration. People are coping by layering scanners, policy kernels, and manual review outside the model. Worth building for: yes.
Single-user file layouts do not survive production¶
Severity: High. @Hey_Amiko wrote (9 likes, 190 views) that once an agent framework goes beyond one user, local files scatter, secrets leak, and scaling becomes “SSH-and-pray.” @dair_ai argued (59 likes, 10 replies, 3,530 views, 54 bookmarks) that context governance, trustworthy memory, and dynamic skill routing are the real system-scaling bottlenecks, and @mattapperson released (94 likes, 7 replies, 11,134 views, 120 bookmarks) Noetic with explicit memory and control-flow primitives rather than hidden framework behavior. The visible workaround is to centralize internal state, isolate workspaces, and add rollout surfaces for skills, secrets, and MCP servers. Worth building for: yes.
Reasoning still makes voice agents feel slow¶
Severity: Medium. @kwindla reported (88 likes, 4 replies, 7,712 views, 56 bookmarks) that reasoning-mode latency is a real pain point for voice agents, and framed Kimi K2.6’s speed as the reason it becomes usable. The practical workaround in the reply thread is a stack-level one, not a single-model one: Pipecat Smart Turn, streaming ASR, fast inference, and TTS tuned together so the user does not wait through the model’s thinking. Worth building for: yes — the pain is concrete, measurable, and tied directly to user experience.
Builders are losing time to vocabulary sprawl¶
Severity: Medium. @adithya_s_k complained (55 likes, 5 replies, 2,855 views, 28 bookmarks) that terms like harness, scaffold, context engineering, and agentic workflows are being used as if everyone agrees on them, even when they mean different things in practice. The replies mostly thanked the glossary post for creating a base standard rather than disagreeing with the complaint. This is softer than the security and scaling pain, but it still taxes tool evaluation, onboarding, and framework comparisons. Worth building for: maybe.
3. What People Wish Existed¶
Verifiers for open-ended agent work¶
The clearest need in the data is a gate that can judge writing, design, strategy, and security behavior as rigorously as a benchmark judges code. @koylanai wrote (231 likes, 502 bookmarks, 55,849 views) that verification is the bottleneck because benchmark auto-graders do not transfer to open-ended work, and the AGT plus Roundtable threads show the same gap on security: teams can intercept tool calls, but they still lack dependable prompt, input, and output evaluators. @tom_doerr shared (17 likes, 8 replies, 1,242 views, 22 bookmarks) Skill Scanner as a partial answer, but its own README calls it best-effort and the replies immediately ask about multi-step exfiltration. Opportunity: direct.
Production control planes for fleets, not just solo agents¶
People want agents that keep state, secrets, schedules, and skills operable once there are teams or customers involved. @Hey_Amiko described (9 likes, 190 views) OpenHermit as the fix for one-user file sprawl, @mattapperson positioned (94 likes, 7 replies, 11,134 views, 120 bookmarks) Noetic as a customizable harness with explicit primitives and memory layers, and @dair_ai argued (59 likes, 10 replies, 3,530 views, 54 bookmarks) that system scaling is now the real bottleneck. This is a practical need with working partial answers already in the market, so the opportunity is real but likely competitive. Opportunity: direct and competitive.
Closed-source distribution and payments for expert skills¶
Capafy’s launch pitch only makes sense because the underlying need already exists: people have built valuable skills in Claude Code, Codex, and OpenClaw, but do not want to publish the files for free. @Capafyai framed (373 likes, 227 replies, 254 quotes, 119,630 views) the answer as closed-source Run Online skills that users can call directly or connect to through another agent. The need is practical and money-shaped rather than aspirational: protect the know-how, expose the result, and let someone pay for access. Opportunity: direct and competitive.
Visual presence that plugs into existing voice stacks¶
The multimodal posts point to a specific product wish: add a face or a canvas without rebuilding the agent from scratch. @AiwithYasir amplified (59 likes, 11,420 views) LiveAvatar as a layer on top of LiveKit, Pipecat, Agora, and VisionAgent, while @pika_labs showed (128 likes, 18 replies, 6,985 views) a dynamic HTML surface driven by the same conversation loop. The need is still emerging, but it is already concrete enough that builders are packaging plug-ins and experiments rather than just speculating about multimodal agents. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| SkillOpt | Skill optimization | (+) | Bounded edits, held-out validation, cross-harness transfer, zero inference-time cost at deployment | Needs auto-gradable tasks; open-ended verification remains weak |
| Capafy | Skill marketplace | (+/-) | Closed-source run-online skills, browser access, agent-to-agent usage, supports Claude Code/Codex/OpenClaw | Launch-stage trust and marketplace quality are still unproven |
| Agent Governance Toolkit | Governance / security | (+/-) | Deterministic tool-call enforcement, YAML policy engine, identity, sandboxing, audit logs | Public Preview; does not inspect prompt/input/output content by itself |
| Noetic | Harness framework | (+/-) | Seven composable primitives, readable control flow, pluggable memory, eval support | Early alpha, small public footprint, docs still rough |
| Waza | Skill pack | (+) | Eight focused engineering habits, cross-agent installation, no telemetry, explicit review/debug loops | Manual chaining and user discipline still matter |
| OpenHermit | Agent infrastructure | (+) | Postgres-backed state, per-agent sandboxes, channels, schedules, fleet-wide rollout controls | Requires database and sandbox operations that solo-agent tools avoid |
| Pipecat + Cerebras Kimi K2.6 | Voice agent stack | (+) | Sub-500ms turns, reasoning remains usable for voice, clear stack composition from ASR to TTS | Performance claim is tied to a tuned benchmark stack, not a default setup |
| LiveAvatar | Avatar plugin | (+/-) | Adds real-time avatar sessions to existing voice apps without stack replacement | Extra plugin/API-key layer, little operator feedback in the thread |
| Pika Generative UI | Experimental interface | (+/-) | Dynamic HTML layouts, live canvas, broad MCP creative tool surface | Rough experiment, local-only prototype, depends on Pika MCP and Realtime APIs |
| Skill Scanner | Security scanner | (+/-) | Static, YARA, LLM, and behavioral analysis plus CI/CD and pre-commit support | Best-effort only; replies question multi-step exfiltration coverage |
Overall satisfaction favored tools that make structure explicit rather than implicit. @koylanai described (231 likes, 502 bookmarks, 55,849 views) SkillOpt as disciplined skill training, @HiTw93 packaged (47 likes, 9 replies, 10,160 views) Waza as explicit engineering habits, and @Hey_Amiko split (9 likes, 190 views) state from workspaces in OpenHermit. Mixed sentiment concentrated where safety and UX are still incomplete: @_vmlops promoted (215 likes, 8 replies, 15,069 views, 364 bookmarks) deterministic governance, but the replies immediately asked for prompt/output coverage, while @pika_labs called (128 likes, 18 replies, 6,985 views) Generative UI an experiment and @kwindla made (88 likes, 4 replies, 7,712 views, 56 bookmarks) clear that voice usability still depends on tight end-to-end latency. The migration pattern was consistent across the day: from prompt-only behavior toward installable skills and eval loops, from local files toward centralized state plus sandboxes, and from text-only agents toward voice and visual wrappers.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Capafy | @Capafyai | Marketplace where expert skills run online as closed-source agents or can be sold as downloads | Monetizes and distributes proprietary agent skills without immediately giving away the logic | Python, web marketplace, Claude Code/Codex/OpenClaw clients | Beta | site, repo, post |
| Noetic | @mattapperson | TypeScript harness built from seven composable primitives and pluggable memory | Lets developers build custom harnesses without black-box framework behavior | TypeScript, Bun, step primitives, memory layers, eval tooling | Alpha | site, repo, post |
| OpenHermit | @Hey_Amiko | Platform for deploying fleets of agents with centralized state and per-agent sandboxes | Fixes multi-user scaling, secret sprawl, and fleet-wide skill rollout | TypeScript, Hono, PostgreSQL, Docker/E2B/Daytona | Beta | site, repo, post |
| Waza | @HiTw93 | Cross-agent skill pack for planning, debugging, design, review, research, and health checks | Turns tacit engineering habits into reusable agent commands | Markdown skills, helper scripts, npx skills, Claude Code/Codex/Cursor/Pi |
Shipped | repo, post |
| Agent Governance Toolkit | @_vmlops | Policy layer that enforces rules before tool calls execute | Blocks unsafe actions, adds provenance, and inserts human approval gates | Python package, YAML policy engine, TS/.NET/Rust/Go SDKs | Beta | repo, post |
| Pika Generative UI | @pika_labs | Voice-controlled interface that generates new HTML layouts on each turn | Replaces rigid chat panes with context-specific visual compositions | JavaScript, OpenAI Realtime, Pika MCP, optional Google Workspace | Alpha | repo, post |
| Skill Scanner | @tom_doerr | Scanner for prompt injection, data exfiltration, and malicious code patterns in agent skills | Adds pre-deploy security review for skill packs and agent instructions | Python, YAML/YARA, LLM analysis, behavioral dataflow, SARIF | Beta | repo, post |
Capafy, Waza, and SkillOpt show the same repeated build pattern from three different angles: sell the skill, install the skill, or train the skill. @Capafyai launched (373 likes, 227 replies, 254 quotes, 119,630 views) the marketplace form, @HiTw93 packaged (47 likes, 9 replies, 10,160 views) the reusable engineering-habits form, and @koylanai described (231 likes, 502 bookmarks, 55,849 views) the trainable optimization form. The shared trigger is dissatisfaction with generic agent output and a desire for durable, inspectable behavior.
OpenHermit, Noetic, and AGT cover the operational side of the same trend. They all assume the agent loop already exists; the hard part is now state, permissions, rollout, and recovery once the system leaves a single-user laptop. Pika Generative UI adds a front-end branch to that pattern by treating layout as another agent output surface, while Skill Scanner shows that skill security is already becoming its own build category rather than an afterthought.
6. New and Notable¶
Skill files got a real training loop¶
@koylanai argued (231 likes, 502 bookmarks, 55,849 views) that SkillOpt treats SKILL.md as trainable external state with bounded edits and held-out validation, and @daniel_mac8 showed (281 likes, 10 replies, 18,606 views, 343 bookmarks) how that loop can be pulled directly into Codex with /goal mode. That pairing matters because it turns a research result into a practical workflow the same day.
Prompt self-audits lost credibility fast¶
The sharpest discussion pattern was not a launch but a rebuttal. @RoundtableSpace proposed (50 likes, 14 replies, 37,788 views) a one-prompt security review for Claude agents, and the replies immediately said the model cannot reliably detect the prompt-injection vectors it would itself miss. That made @_vmlops sharing (215 likes, 8 replies, 15,069 views, 364 bookmarks) a deterministic governance kernel more notable than it would have been in isolation.
Agent interfaces started escaping the chat box¶
@pika_labs introduced (128 likes, 18 replies, 6,985 views) a generative HTML canvas that changes layout every turn, while @AiwithYasir amplified (59 likes, 11,420 views) LiveAvatar as a few-line add-on for existing voice stacks. Together with @kwindla showing (88 likes, 4 replies, 7,712 views, 56 bookmarks) sub-500ms voice-agent turns, the signal is that front-end experimentation is finally catching up to model speed.
7. Where the Opportunities Are¶
[+++] Open-ended verifier layers for agents and skills — @koylanai called out (231 likes, 502 bookmarks, 55,849 views) verification as the bottleneck, @RoundtableSpace provoked (50 likes, 14 replies, 37,788 views) a thread showing why self-audit prompts do not earn trust, and @tom_doerr shared (17 likes, 8 replies, 1,242 views, 22 bookmarks) a best-effort scanner whose replies immediately asked about deeper coverage. The opportunity is strong because it appears in security, skill optimization, and eval tooling all at once.
[+++] Operable multi-user agent infrastructure — @Hey_Amiko described (9 likes, 190 views) the one-user file problem directly, @dair_ai named (59 likes, 10 replies, 3,530 views, 54 bookmarks) context governance, trustworthy memory, and dynamic skill routing as the bottlenecks, and @mattapperson released (94 likes, 7 replies, 11,134 views, 120 bookmarks) Noetic around explicit primitives and memory boundaries. The signal is strong because the pain is operational, not aspirational.
[++] Closed-source skill distribution and monetization — @Capafyai launched (373 likes, 227 replies, 254 quotes, 119,630 views) a marketplace built around closed-source Run Online skills, while Waza and SkillOpt show adjacent demand for installable and trainable skill artifacts. The opportunity is moderate because the need is obvious, but marketplace trust, quality control, and pricing power are still unsettled.
[+] Voice-agent presence layers — @kwindla showed (88 likes, 4 replies, 7,712 views, 56 bookmarks) that faster reasoning changes voice usability, @pika_labs experimented (128 likes, 18 replies, 6,985 views) with dynamic canvases, and @AiwithYasir pointed to (59 likes, 11,420 views) plug-in avatar support for existing stacks. The signal is emerging rather than dominant, but the UX surface is clearly opening up.
8. Takeaways¶
- Skills are becoming a first-class product surface. Capafy’s marketplace launch and Waza’s installable engineering habits both treat skills as durable assets rather than personal prompt files. (Capafy, Waza)
- Skill optimization is moving from intuition to disciplined training. SkillOpt’s bounded edits and held-out gates, plus the Codex
/goalimplementation pattern, show that agent behavior is starting to be improved like a reusable artifact rather than re-prompted ad hoc. (SkillOpt discussion, Codex workflow) - The harness is now where quality and trust are won or lost. The CheetahClaws paper explicitly names context governance, trustworthy memory, and dynamic skill routing as bottlenecks, while AGT pushes policy enforcement below the prompt layer. (system scaling, AGT)
- Prompt-only security advice is losing credibility. The strongest reaction in the security threads was not excitement but pushback that models cannot reliably audit their own prompt-injection weaknesses, which keeps demand high for scanners, policy kernels, and other external controls. (security prompt thread, Skill Scanner)
- As latency drops, agent builders are spending more time on presence and interface. Sub-500ms voice turns, dynamic HTML layouts, and avatar plug-ins all point to the same next step: make the same agent feel faster, more visual, and more human-facing. (Kimi voice stack, Pika Generative UI, LiveAvatar)