Twitter AI Agent - 2026-06-01¶
1. What People Are Talking About¶
1.1 Context engineering turned into a production bottleneck 🡕¶
The center of gravity moved from abstract harness talk to concrete context operations. Five retained items supported this theme: a public harness taxonomy, a Box enterprise warning, a production OOM post, a reusable external context-management paper, and a codebase indexing tool that quantified wasted context.
@byanujpatel shared (235 likes, 12,861 views, 304 bookmarks) LangChain's public harness engineering article, which defines the harness as everything around the model and maps desired behaviors like durable storage, code execution, and long-horizon work to filesystems, bash, sandboxes, memory, and orchestration.

@levie argued (173 likes, 33 replies, 33,132 views, 203 bookmarks) that enterprise agents fail because critical context is fragmented across legacy systems, mismatched permissions, and tribal knowledge that never made it into machine-readable form. The strongest replies sharpened the ask: one operator said a Playwright abstraction over an archaic CMS made the system agent-friendly, while another said agents need "memory with receipts" so every fact can be traced to source and change history.
@arpit_bhayani wrote (150 likes, 5 replies, 6,244 views, 65 bookmarks) that the most common production failure in agentic systems is still OOM: tool outputs, API results, and full documents linger in memory until long conversations or higher load make the process fall over. His fixes — aggressive truncation, streaming, retrieval of only needed context, and externally persisted state — made the problem sound like classic systems engineering rather than model weakness.
@dair_ai highlighted (72 likes, 8 replies, 3,177 views, 54 bookmarks) AdaCoM, research on training a separate LLM to decide what context a frozen agent should keep or drop. The paper screenshot is the key evidence: it shows a reusable external context manager wrapped around the agent instead of yet another prompt-local patch.

@israfill promoted (13 likes, 4 replies) CodeGraph as a pre-indexed code knowledge graph for coding agents. The screenshot is more convincing than the pitch: without a repo graph, the agent wastes 3,847 tokens guessing; with it, the agent gets exact call sites and impact paths without extra search churn.

Discussion insight: Replies repeatedly moved the bar from "give the agent more context" to "give it fresh context, provenance, and the right retention policy."
Comparison to prior day: May 31 treated harness engineering as a design checklist. June 1 made context delivery, compression, and memory externalization the concrete work.
1.2 Agent model launches became benchmark tables with price tags 🡕¶
Two strong launch threads treated agent capability like a measurable product SKU: multimodal tasks, long context, and launch-day pricing. The conversation was less about brand and more about whether a model could clear agent-specific benchmarks at a usable cost.
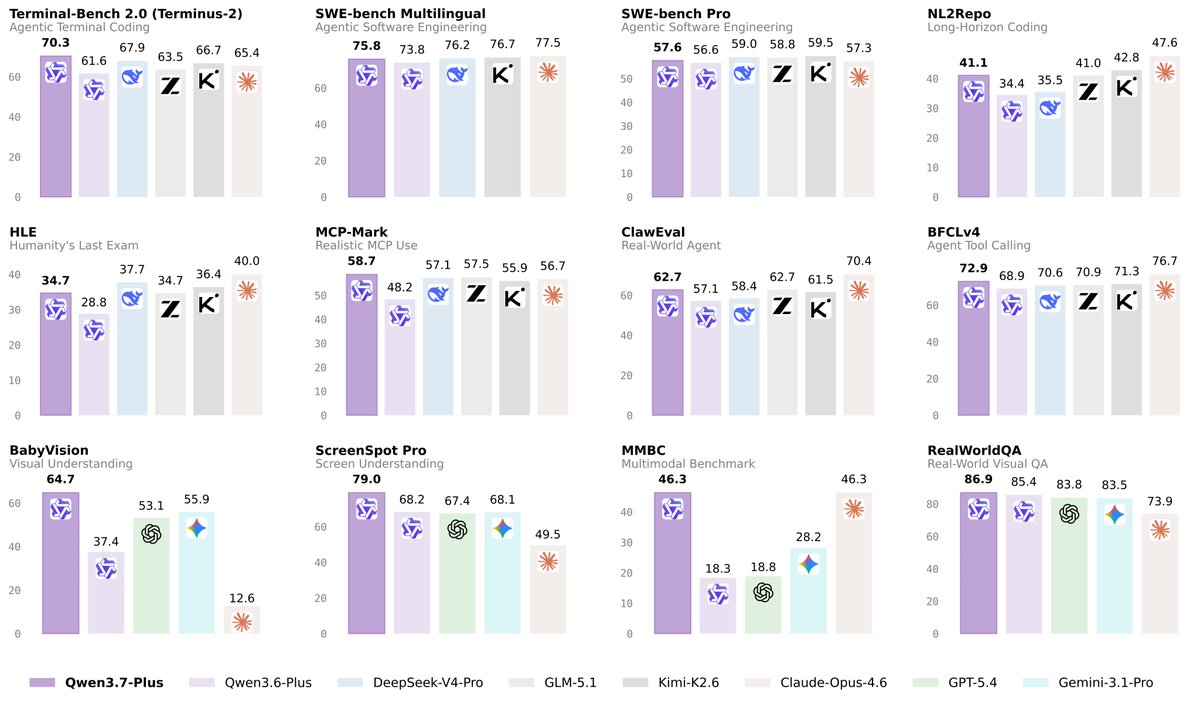
@Alibaba_Qwen launched (385 likes, 40 replies, 9,043 views, 54 bookmarks) Qwen3.7-Plus as a multimodal agent model spanning GUI and CLI work. The benchmark image compares it against Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro, and others across Terminal-Bench, SWE-bench variants, ClawEval, BFCLv4, ScreenSpot Pro, and related tasks, while the reply thread extends the launch with more benchmark notes and demos.
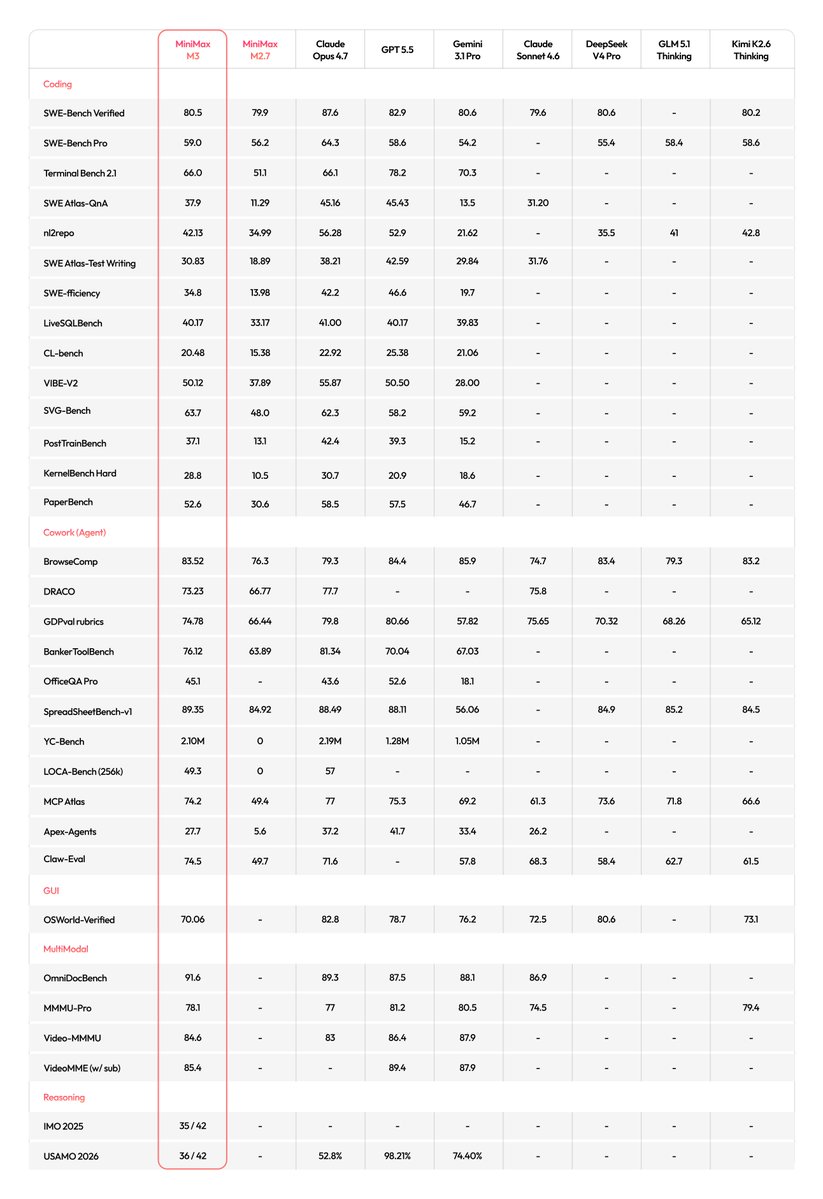
@Elaina43114880 summarized (15 likes, 259 views) MiniMax M3 as a frontier multimodal model with 1M context, computer-use support, and launch pricing starting at $0.60 per million input tokens for shorter contexts. The attached full benchmark table makes the claim concrete by placing M3 across coding, GUI, multimodal, and reasoning tasks instead of one cherry-picked score.
Discussion insight: Launch threads were judged less on slogan quality and more on whether they shipped a credible benchmark pack and price sheet on day one.
Comparison to prior day: May 31 focused more on workflow stacks and harness behavior. June 1 brought raw model competition back, but in agent-specific tables instead of generic leaderboard talk.
1.3 Skills started looking like delivery infrastructure, not prompt files 🡕¶
The strongest skills posts were about registries, hosted delivery, and secure runtimes. Four retained items supported this theme.
@NousResearch announced (392 likes, 42 replies, 41,025 views, 78 bookmarks) that Hermes Agent now runs on RTX Spark hardware and inside NVIDIA's OpenShell runtime tied to Microsoft's security primitives. NVIDIA's public OpenShell materials describe the runtime as a sandbox, policy engine, and privacy router that sits between agents and infrastructure.
@shannholmberg argued (20 likes, 773 views, 11 bookmarks) that this runtime layer is what makes Hermes enterprise-ready for teams that could prototype agents but not clear security review. The diagram matters because it shows why: Hermes workflows, skills, and memory sit above isolation, audit, access control, and Microsoft-integrated security.

@room_ashish pitched (8 likes, 200 views) Milkey as a hosted MCP skills layer so agents fetch only what they need at runtime instead of shipping 20 skill descriptions in every prompt. The product page and screenshot make the token-bloat claim concrete: one shared skills layer for Cursor, Claude Code, Codex, and Windsurf with no local prompt-file drift.

@HuggingPapers pointed to (21 likes, 1,072 views, 14 bookmarks) COLLEAGUE.SKILL, a project that turns chat logs into versioned agent skills. The pipeline image shows trace intake, preset routing, dual distillation, artifact writing, and governance as explicit stages, which is a much more operational model than "save a prompt template somewhere."

@aiedge_ linked (19 likes, 1,471 views, 33 bookmarks) the official Hermes Skills Hub. The public page was still loading, but even its shell showed 88k+ skills across every registry, which pushes the skills story from "some templates" toward platform-scale catalog management.
Discussion insight: The response to last week's and yesterday's skill-bloat complaints was not "prune by hand." It was "load on demand, publish to shared registries, and govern the runtime outside the model."
Comparison to prior day: May 31 focused on too many default-enabled skills. June 1 focused on hosted registries, portable skills, and secure runtime delivery.
1.4 Agent-economy posts finally showed small live loops, but trust still lagged 🡕¶
Marketplace and payment threads had more operational substance than on prior days: live payouts, review-before-settlement flows, portable checkout skills, and wallet-signed messaging. But the replies kept circling the same missing layers: evidence, reputation, and enough counterparties to make the market useful.
@tetsuoarena launched (37 likes, 5 replies, 713 views) AgenC Marketplace in early access on Solana mainnet, with a specific loop for posting tasks, letting an agent claim them, reviewing the result, and settling on acceptance. The post is unusually detailed about safety rails: human approval on money-moving steps, SHA-256 binary verification, and direct guidance for Claude Code, Codex, and Hermes users.
@tetsuoai reported (144 likes, 28 replies, 5,833 views, 31 bookmarks) that an agent completed a marketplace job and got paid 0.20 SOL on mainnet. The most useful reply did not cheer — it asked for evidence, which shows the trust gap these systems still have to close.
@Unibase_AI announced (235 likes, 3 replies, 12,946 views) that AllScale Checkout joined BitAgent's ERC-8183 skill ecosystem, with portable flows for credential setup, server-side signing, intent creation, status polling, webhook verification, and debugging. This was one of the clearest agent-commerce posts because it named actual payment operations instead of only naming a marketplace.
@Signa_Agent described (8 likes, 5 replies, 550 views) SIGNA as a wallet-signed messaging layer on Base so agents on different frameworks can talk without API-key silos. The public site backs that framing with Base wallets, XMTP inboxes, Google A2A transport compatibility, and optional USDC-per-call pricing.
@aashatwt built (42 likes, 11 replies, 1,485 views) AgentLance, where a CEO agent decomposes work and specialist agents bid in verified enclaves. The strongest reply immediately named the unresolved layer: enclaves may prove execution, but marketplaces still need portable reputation so an agent can know who actually shipped last time.
A smaller but revealing builder note came from @Ahmedhaq01 saying (18 likes, 12 replies, 224 views) he started building an AI agent marketplace on Arc and then pivoted because the ecosystem did not yet have enough agents to make the marketplace truly valuable.
Discussion insight: The discourse has moved past "can an agent pay?" to "can the other side be discovered, verified, and trusted?"
Comparison to prior day: Earlier marketplace chatter leaned speculative. June 1 added live settlement, checkout primitives, and wallet-signed transport, while making the reputation and liquidity gaps harder to ignore.
2. What Frustrates People¶
Context sprawl turns good demos into failing production agents¶
Severity: High. @levie argued (173 likes, 33 replies, 33,132 views, 203 bookmarks) that enterprise agents break on fragmented systems, mismatched permissions, and unrecorded tribal knowledge. @arpit_bhayani wrote (150 likes, 5 replies, 6,244 views, 65 bookmarks) that OOM is still the most common production failure because agents keep too much tool output and document state in memory, while @israfill showed (13 likes, 4 replies) a before/after screenshot where CodeGraph removes 3,847 wasted tokens of blind codebase search. People are coping with Playwright abstractions over legacy systems, aggressive truncation, repo indexing, and external context managers such as AdaCoM. This is worth building for because the pain appears as direct failures, token waste, and manual cleanup in both coding and knowledge-work agents.
Enterprise deployment still stalls on runtime security and governance¶
Severity: High. @NousResearch announced (392 likes, 42 replies, 41,025 views, 78 bookmarks) OpenShell support for Hermes Agent, and @shannholmberg argued (20 likes, 773 views, 11 bookmarks) that the runtime layer is what finally makes enterprise deployment possible. @codebrandes linked (66 likes, 13 replies, 3,913 views) Gate AI's builder essay, which says prompt injection, secret leakage, and hijacked tool calls are still the real attack surface for day-to-day agent users. People are coping by moving guardrails outside the model into sandboxes, policy engines, proxy gateways, and auditable runtimes. This is worth building for because prompt-only defense is visibly not enough once agents hold shell access, tools, and persistent state.
Static skill packs waste tokens and create setup drift¶
Severity: Medium-High. @room_ashish pitched (8 likes, 200 views) Milkey specifically around the complaint that agents read every skill description on every request. @aiedge_ linked (19 likes, 1,471 views, 33 bookmarks) the official Hermes Skills Hub, whose public shell was already loading 88k+ skills across registries, and @HuggingPapers pointed to (21 likes, 1,072 views, 14 bookmarks) COLLEAGUE.SKILL's multi-stage distillation pipeline. The workaround pattern is clear: host skills server-side, resolve them over MCP at runtime, and standardize around shared registries instead of copying prompt files between projects. This is worth building for because the cost is immediate in prompt length, setup duplication, and inconsistent behavior across tools.
Marketplaces still lack enough trust and depth to feel liquid¶
Severity: Medium-High. @tetsuoai reported (144 likes, 28 replies, 5,833 views, 31 bookmarks) a live payout on AgenC, but one of the first replies asked for evidence. @aashatwt built (42 likes, 11 replies, 1,485 views) AgentLance, and the strongest reply immediately said reputation portability across marketplaces was still unsolved. Most bluntly, @Ahmedhaq01 said (18 likes, 12 replies, 224 views) he pivoted away from an agent marketplace because the ecosystem was still too early and did not yet have enough agents to make the marketplace valuable. This is worth building for because the core flows now exist, but repeatable trust, discovery, and supply are still weak.
3. What People Wish Existed¶
Portable context with receipts and freshness¶
The strongest request was not "give me a bigger window." It was "give me context that stays current, cites its source, and does not blow up the agent." Levie's enterprise thread, Arpit Bhayani's OOM post, AdaCoM's reusable context manager, and CodeGraph's repo index all point to the same gap. This is a practical need, not an aspirational one, because people are already building manual abstractions and memory layers to compensate. Opportunity: direct.
Runtime-loaded skill layers that work across agents¶
Milkey, the Hermes Skills Hub, and COLLEAGUE.SKILL all suggest that users want one shared skill surface that loads on demand, carries across tools, and does not force them to copy prompt folders between projects. The need is operational rather than emotional: lower token spend, less setup drift, and better governance. Opportunity: direct.
Cross-framework agent messaging, identity, and reputation¶
SIGNA's pitch starts from the complaint that every agent still lives on an island, while AgenC and AgentLance show that payment loops can run before the trust layer is solved. Ahmedhaq01's marketplace pivot makes the unmet need explicit: until agents can discover, verify, and trust each other across frameworks, many markets will stay thin. Opportunity: direct and competitive.
Inspectable traces and recoverable sessions¶
agent-trace, ActiveGraph, LiteParse, and Memory Forge RS all solve different parts of the same problem: teams want replayable traces, exact source-level audit trails, and a way to recover from bad context without restarting long sessions from zero. This is a practical reliability need with clear workflow value. Opportunity: direct.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Harness engineering patterns | Method | (+) | Gives teams a shared map from desired behaviors to filesystems, tools, sandboxes, memory, and orchestration | Still abstract until paired with concrete controls for context, cost, and verification |
| CodeGraph | Code intelligence / MCP | (+) | Local semantic index, symbol search, impact analysis, fewer tool calls, broad coding-agent support | Requires per-project indexing, and public savings claims still come from the vendor's own benchmark set |
| AdaCoM | Context management research | (+) | Reusable external context pruning for frozen agents; model-agnostic instead of prompt-local | Adds a manager layer and exposes a fidelity-versus-reliability trade-off |
| Qwen3.7-Plus | Multimodal LLM | (+) | Unified GUI/CLI tasks, strong agent and multimodal benchmark showing at launch, API availability | API-only launch and a very crowded frontier field |
| MiniMax M3 | Multimodal / open-weight LLM | (+) | 1M context, broad benchmark table across coding/GUI/reasoning tasks, aggressive API pricing | Technical report and open weights were still pending at launch |
| OpenShell | Secure runtime | (+) | Sandbox, policy engine, privacy router, and a credible enterprise deployment story for existing agents | Pushes complexity into runtime policy, approvals, and environment setup |
| Milkey | Skills delivery / MCP | (+) | Runtime-loaded shared skills, no local prompt drift, one layer across multiple coding agents | Hosted service with central dependency on registry/auth infrastructure |
| Gate AI | Security gateway | (+/-) | Blocks prompt injection, redacts secrets, compresses prompts, and adds verifiable audit logs without changing the agent workflow | Public benchmark story is vendor-published and the product remained in private beta |
| agent-trace | Observability / eval | (+) | Replay diff, CI regression gates, OTLP export, workspace isolation, and HTML replays | Early project with less adoption evidence than more general observability tooling |
| ActiveGraph | State / trace runtime | (+) | Replay, fork, diff, append-only event log, and durable graph state for long-running agents | More architectural overhead than simpler loop-and-memory setups |
| LiteParse | Document parser | (+) | Local parsing with bounding boxes and screenshots for exact source-level audit trails | Local parsing still loses to cloud parsers on the hardest layouts and scans |
Overall sentiment favored tools that reduce wasted context, move control outside the model, and make agent behavior inspectable after the fact. The migration pattern ran from static skill folders toward runtime-loaded registries, from prompt-only guardrails toward policy runtimes and traffic gateways, and from blind file-search loops toward semantic indices and replayable traces. Qwen3.7-Plus and MiniMax M3 were also judged as benchmark-and-price packages rather than as abstract frontier-model brands.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| CodeGraph | Colby McHenry | Pre-indexed code knowledge graph and MCP layer for coding agents | Coding agents waste tokens discovering code structure from scratch | Local semantic index, MCP integration, agent auto-config for Claude Code/Codex/Cursor/Hermes and others | Shipped | repo, tweet |
| Gate AI | Constellation | Drop-in gateway that scans agent/model traffic, blocks prompt injection, redacts secrets, compresses prompts, and writes verifiable audit logs | Smaller teams want agent security and cost control without enterprise procurement or workflow rewrites | API proxy, compression, prompt-cache injection, blockchain-backed audit trail | Beta | site, blog, tweet |
| AgenC Marketplace | @tetsuoarena | Solana marketplace where agents claim paid tasks, submit results, and settle after review | Agent-to-agent work needs approval, settlement, and a usable operator flow | Solana mainnet, wallet flow, review-before-settlement, Claude Code/Codex/Hermes support | Beta | post |
| SIGNA | @Signa_Agent | Wallet-signed messaging and A2A transport layer for agents on Base with optional USDC-per-call pricing | Agents on different frameworks still cannot message or pay each other cleanly | Base, XMTP, Google A2A, ERC-8004, USDC/x402 | Shipped | site, post |
| agent-trace | @Siddhant_K_code | Full-session tracing and eval tool with replay diff and CI regression checks | PRs and logs do not explain what an agent actually did during a run | Python, Claude hooks, MCP proxy, OTLP export, GitHub Actions | Beta | repo, post |
| ActiveGraph | @yoheinakajima | Event-sourced graph runtime that lets teams replay, fork, and diff agent runs | Long-running agents need durable, inspectable state instead of opaque logs | Python 3.11+, append-only event log, graph runtime, replay/fork/diff | Shipped | site, post |
| LiteParse v2 | @jerryjliu0 | Fast local parser that returns text, bounding boxes, and screenshots for agent workflows | Agents need document parsing that can point back to exact source regions | Rust, PDFium, Tesseract, Node/Python/WASM bindings, screenshot generation | Shipped | repo, post |
| Memory Forge RS | @DanKornas | Local desktop app for editing AI coding-assistant session history instead of restarting | Bad context currently forces users to throw away long sessions and start over | Tauri v2, React 19, Rust, TypeScript | Beta | repo, post |
CodeGraph and Gate AI stood out because both wrap existing agents instead of asking users to switch to a brand-new agent. One productizes codebase context and semantic lookup; the other productizes inline security, prompt compression, and auditability around the model API.
AgenC and SIGNA show the emerging commerce stack splitting into two layers. AgenC handles task posting, review, and settlement, while SIGNA focuses on cross-framework identity, messaging, and payment rails; Unibase's AllScale checkout-skill post suggests payment workflows are already being modularized into portable skills.
agent-trace, ActiveGraph, LiteParse, and Memory Forge RS reflect a second build pattern: teams are making agent work inspectable, replayable, source-grounded, or editable instead of only trying to make the agent more autonomous. That is a strong signal that observability and recovery are becoming product categories of their own.
6. New and Notable¶
Skills catalogs started to look like distribution platforms¶
@aiedge_ linked (19 likes, 1,471 views, 33 bookmarks) the official Hermes Skills Hub, whose public shell was already loading 88k+ skills across every registry. In parallel, @HuggingPapers surfaced (21 likes, 1,072 views, 14 bookmarks) COLLEAGUE.SKILL's 215-skill community gallery. The notable shift is not just that skills exist, but that they are being cataloged, versioned, and distributed like a platform layer.
Security products started selling both protection and efficiency¶
@codebrandes linked (66 likes, 13 replies, 3,913 views) Gate AI's builder essay, and the public product site pairs prompt-injection blocking and secret redaction with 20%+ token savings and cache-aware compression. Together with the OpenShell/Hermes runtime push, that made security look less like an enterprise afterthought and more like part of the core agent runtime and cost stack.
Traceability moved closer to first-class agent UX¶
@Siddhant_K_code released (23 likes, 8 replies, 1,501 views) agent-trace into the GitHub Actions Marketplace, @yoheinakajima showed (14 likes, 3 replies, 2,264 views) a coding agent flattened into one event-log trace, and @jerryjliu0 argued (7 likes, 2 replies, 1,912 views, 14 bookmarks) that bounding boxes matter because agents should cite exact source regions. The notable shift is that traceability is moving from hidden debug output to something products now present as a user-facing feature.
7. Where the Opportunities Are¶
[+++] Context operating systems for production agents — The strongest evidence cluster comes from Aaron Levie's enterprise context thread, Arpit Bhayani's OOM note, AdaCoM's reusable context-manager post, and CodeGraph's codebase index pitch. The unmet need is not raw token volume; it is freshness, provenance, compression, retrieval, and failure-resistant memory across both code and business context.
[++] Runtime-loaded skill delivery and governance — Milkey, the Hermes Skills Hub, COLLEAGUE.SKILL, and the OpenShell/Hermes runtime story all point to the same opening: teams want skills distributed like infrastructure, loaded on demand, and governed outside the model.
[++] Auditable traces and recovery tooling — agent-trace, ActiveGraph, LiteParse, and Memory Forge RS all attack the same problem from different angles: operators need replay, diff, source-level evidence, and recovery paths when an agent run goes bad.
[+] Cross-framework agent commerce and reputation — AgenC Marketplace, SIGNA, AllScale Checkout on BitAgent, and AgentLance show that payment and messaging loops are starting to work. The emerging gap is portable trust: proof of execution, reputation, and enough counterparties to make these markets liquid.
8. Takeaways¶
- Context handling is now the main systems bottleneck for serious agents. Levie's enterprise warning, Arpit Bhayani's OOM post, AdaCoM's external context manager, and CodeGraph's indexed repo graph all point to the same shift: performance now depends on what the agent sees, keeps, and drops. (source)
- Agent model launches are being judged as benchmark-and-pricing packages, not just brand moments. Qwen3.7-Plus and MiniMax M3 both arrived with wide benchmark tables, multimodal claims, and concrete API economics. (source)
- Skills are becoming a distribution and runtime problem. OpenShell, Milkey, the Hermes Skills Hub, and COLLEAGUE.SKILL all frame skills as governed, hosted, versioned infrastructure rather than loose prompt files. (source)
- Agent commerce is no longer hypothetical, but it is still early. AgenC and SIGNA show live settlement and wallet-signed transport, while AgentLance's replies and Ahmedhaq01's pivot show that reputation and liquidity are still missing layers. (source)
- Inspectability is becoming its own product surface. agent-trace, ActiveGraph, LiteParse, and Memory Forge RS all assume that users need to replay, diff, cite, or even edit agent history instead of trusting opaque runs. (source)