Twitter AI Agent - 2026-06-01¶
1. 人们在讨论什么¶
1.1 上下文工程变成生产瓶颈 🡕¶
讨论重心从抽象的运行框架讨论,转向具体的上下文运维。至少有 5 条保留条目支撑了这一主题:一套公开的运行框架分类、一条来自 Box 的企业告警、一篇生产 OOM 帖子、一篇可复用外部上下文管理论文,以及一个量化了上下文浪费的代码库索引工具。
@byanujpatel 分享(235 次点赞、12,861 次浏览、304 次收藏)了 LangChain 的公开 运行框架工程文章,其中把运行框架定义为模型周围的一切,并把持久化存储、代码执行和长时程工作等目标行为,分别映射到文件系统、bash、沙箱、记忆和编排。

@levie 认为(173 次点赞、33 条回复、33,132 次浏览、203 次收藏),企业智能体之所以失败,是因为关键上下文散落在老旧系统、错配的权限和从未被整理成机器可读形式的部落知识里。最有力的回复进一步把诉求说清了:一位运营者说,在一个古老 CMS 之上套一层 Playwright 抽象后,系统才终于对智能体友好;另一位则说,智能体需要“有据可查的记忆”,这样每一条事实都能追溯到来源和变更历史。
@arpit_bhayani 写道(150 次点赞、5 条回复、6,244 次浏览、65 次收藏),智能体化系统在生产里最常见的失败仍然是 OOM:工具输出、API 结果和整份文档会一直滞留在内存里,直到对话变长或负载升高把进程压垮。他给出的修法——激进截断、流式处理、只检索需要的上下文,以及把状态持久化到外部——让这个问题听起来更像经典系统工程,而不是模型能力不足。
@dair_ai 重点提到(72 次点赞、8 条回复、3,177 次浏览、54 次收藏)AdaCoM,这项研究训练了一个独立的 LLM,来决定冻结的智能体该保留还是丢弃哪些上下文。论文截图是关键证据:它展示的不是又一个只在提示词局部打补丁的办法,而是包在智能体外部的可复用上下文管理器。

@israfill 推广(13 次点赞、4 条回复)CodeGraph,把它定位为面向编程智能体的预索引代码知识图谱。比宣传语更有说服力的是那张截图:没有仓库图谱时,智能体会白白浪费 3,847 个 token 去猜;有了它之后,智能体能直接拿到精确的调用点和影响路径,而无需额外搜索折腾。

讨论要点: 回复一再把门槛从“给智能体更多上下文”抬高到“给它新鲜的上下文、出处,以及正确的保留策略”。
与前日对比: 5 月 31 日把运行框架工程当成设计清单。6 月 1 日则把上下文交付、压缩和记忆外置变成了具体工作。
1.2 智能体模型发布开始变成带价格标签的基准表 🡕¶
两条强势的发布讨论串,都把智能体能力当成可度量的产品 SKU:多模态任务、长上下文,以及首发定价。讨论重点不再是品牌,而是某个模型能否以可用成本通过智能体特定基准测试。
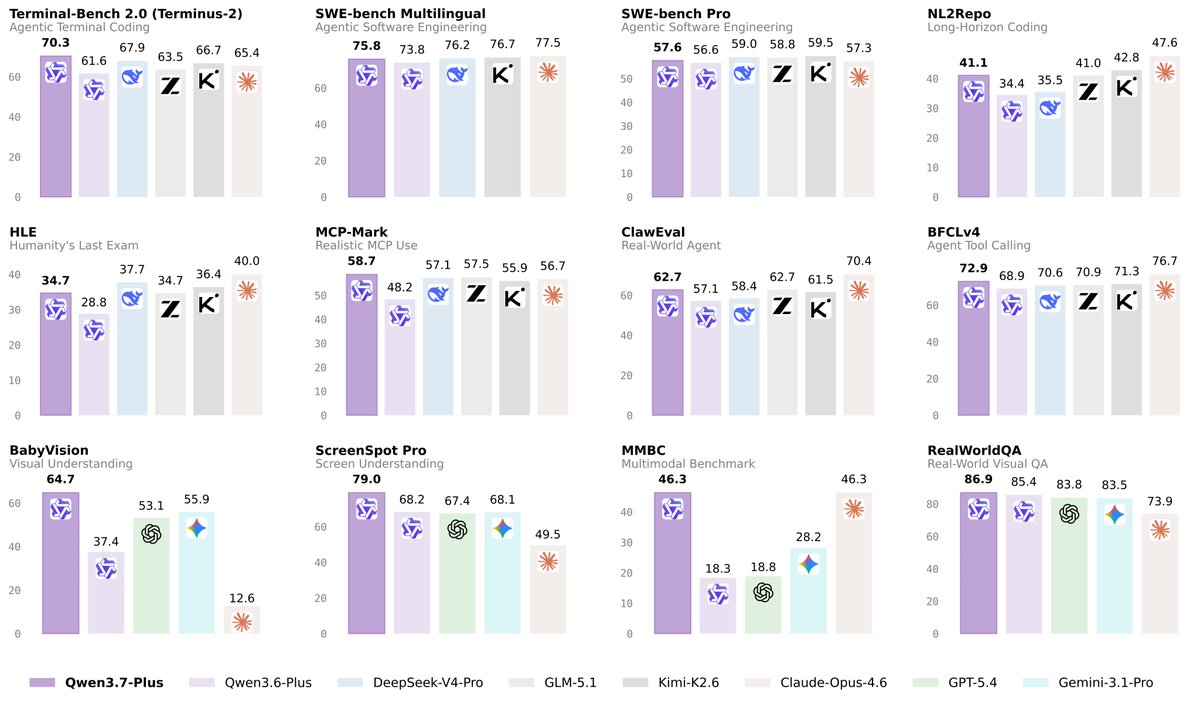
@Alibaba_Qwen 发布(385 次点赞、40 条回复、9,043 次浏览、54 次收藏)了 Qwen3.7-Plus,把它定位成同时覆盖 GUI 和 CLI 工作的多模态智能体模型。基准图把它与 Claude Opus 4.6、GPT-5.4、Gemini 3.1 Pro 等模型在 Terminal-Bench、SWE-bench 各变体、ClawEval、BFCLv4、ScreenSpot Pro 等任务上做了对比,而回复串又用更多基准说明和演示来延展这次发布。
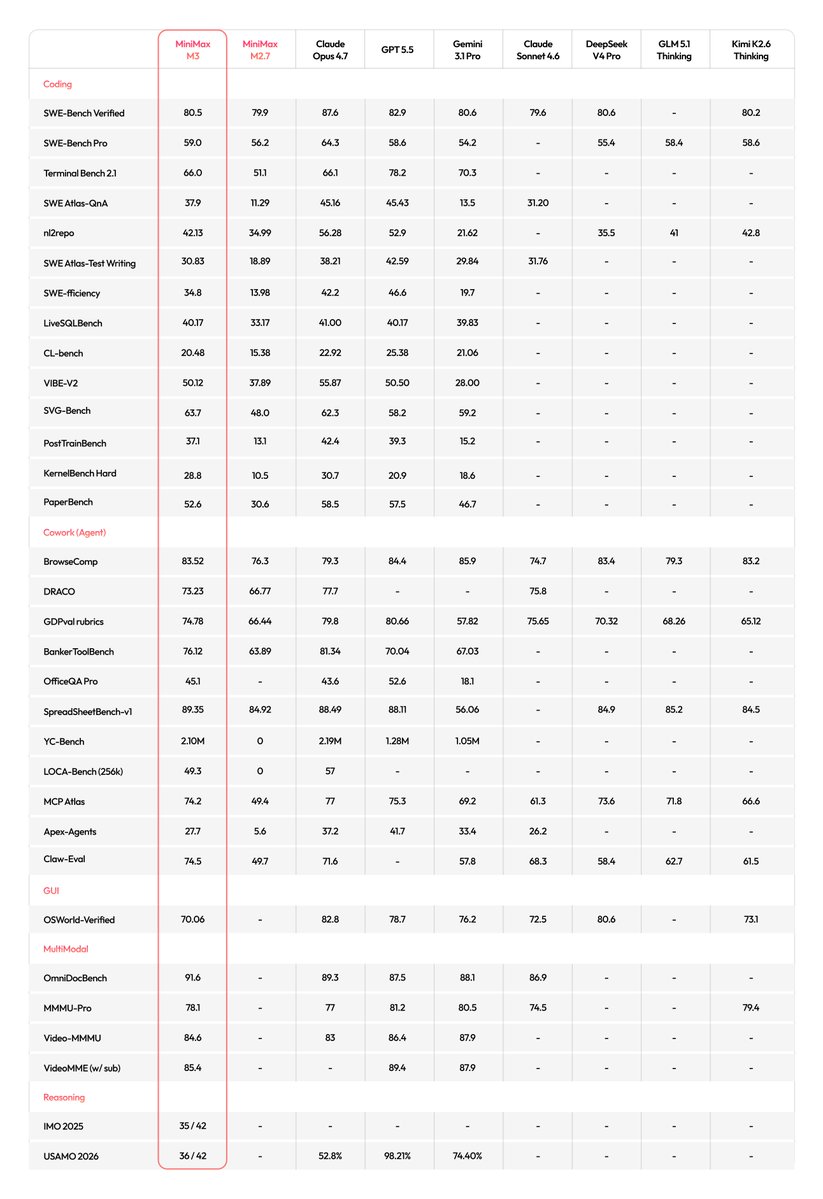
@Elaina43114880 总结(15 次点赞、259 次浏览)MiniMax M3,是一个具备 1M 上下文、支持电脑操作、短上下文输入价格从每百万 token 0.60 美元起的前沿多模态模型。附带的完整基准表让这个说法更具体,因为它把 M3 放在编程、GUI、多模态和推理任务里一起对比,而不是只挑一个好看的分数。
讨论要点: 发布贴的评判标准,越来越少取决于口号写得多好,而越来越取决于首日是否一并拿出一套可信的基准包和价格表。
与前日对比: 5 月 31 日更聚焦工作流栈和运行框架行为。6 月 1 日则把原始模型竞争重新拉回台前,只不过形式是智能体特定的表格,而不是泛泛的排行榜讨论。
1.3 技能开始更像交付基础设施,而不只是提示词文件 🡕¶
最强的一批技能帖子,谈的都是注册中心、托管式交付和安全运行时。至少有 4 条保留条目支撑了这一主题。
@NousResearch 宣布(392 次点赞、42 条回复、41,025 次浏览、78 次收藏),Hermes Agent 现在能运行在 RTX Spark 硬件上,也能运行在与 Microsoft 安全原语绑定的 NVIDIA OpenShell 运行时里。NVIDIA 的公开 OpenShell 资料把这个运行时描述为位于智能体与基础设施之间的沙箱、策略引擎和隐私路由器。
@shannholmberg 认为(20 次点赞、773 次浏览、11 次收藏),正是这一运行时层,让 Hermes 对那些能做出原型却过不了安全审查的团队,终于具备企业落地可能。那张图之所以重要,是因为它解释了原因:Hermes 的工作流、技能和记忆,都坐在隔离、审计、访问控制和与 Microsoft 集成的安全层之上。

@room_ashish 主推(8 次点赞、200 次浏览)Milkey,把它定位成一层托管的 MCP 技能层:智能体在运行时只拉取所需技能,而不是每次都把 20 条技能描述塞进提示词。产品页和截图让“token 膨胀”这个说法变得具体:一个共享技能层,可供 Cursor、Claude Code、Codex 和 Windsurf 使用,也不会再有本地提示词文件漂移。

@HuggingPapers 提到(21 次点赞、1,072 次浏览、14 次收藏)COLLEAGUE.SKILL——一个把聊天日志转成版本化智能体技能的项目。它的流程图把追踪记录接入、预设路由、双重蒸馏、工件写入和治理明确拆成各个阶段,这比“找个地方存一份提示词模板”要运营化得多。

@aiedge_ 贴出(19 次点赞、1,471 次浏览、33 次收藏)了官方 Hermes Skills Hub。公开页面还没完全加载出来,但仅从壳层就能看到跨各个注册中心已有 8.8 万+ 技能,这让“技能”的故事更像平台级目录管理,而不只是“一些模板”。
讨论要点: 对上周以及昨天那些“技能膨胀”抱怨的回应,不是“手动修剪”,而是“按需加载、发布到共享注册中心,并把治理放到模型之外的运行时里”。
与前日对比: 5 月 31 日聚焦默认启用的技能太多。6 月 1 日则转向托管注册中心、可移植技能,以及安全的运行时交付。
1.4 “智能体经济”类帖子终于出现小规模真实闭环,但信任仍然滞后 🡕¶
市场和支付类讨论串,比前几天更有运营细节:真实打款、结算前审阅流程、可移植的结账技能,以及钱包签名消息。但回复始终在绕同样几层缺失:证据、声誉,以及足够多的交易对手,市场才会真正有用。
@tetsuoarena 发布(37 次点赞、5 条回复、713 次浏览)AgenC Marketplace,在 Solana 主网上开启早期访问;它给出了一条明确流程:发布任务、让智能体认领、审阅结果、验收后结算。这条帖子少见地把安全护栏讲得很细:涉及资金流转的步骤需要人工批准,二进制文件要做 SHA-256 校验,还直接给 Claude Code、Codex 和 Hermes 用户提供了操作指引。
@tetsuoai 报告(144 次点赞、28 条回复、5,833 次浏览、31 次收藏),有一个智能体在主网上完成了一单市场任务,并收到了 0.20 SOL 的报酬。最有用的回复并没有欢呼,而是要证据,这说明这些系统仍要弥合信任缺口。
@Unibase_AI 宣布(235 次点赞、3 条回复、12,946 次浏览),AllScale Checkout 已加入 BitAgent 的 ERC-8183 技能生态,提供可移植流程来完成凭据设置、服务端签名、意图创建、状态轮询、webhook 验证和调试。这是当天最清晰的智能体商业化帖子之一,因为它说的是实际支付操作,而不只是喊一个“市场”名词。
@Signa_Agent 介绍(8 次点赞、5 条回复、550 次浏览)SIGNA,把它定位成 Base 上的一层钱包签名消息系统,让不同框架上的智能体不再被 API key 孤岛割裂。公开网站用 Base 钱包、XMTP 收件箱、Google A2A 传输兼容,以及可选的按次收取 USDC 来支撑这个表述。
@aashatwt 做了(42 次点赞、11 条回复、1,485 次浏览)AgentLance:一个 CEO 智能体负责拆解工作,专业智能体在经过验证的隔离环境里竞标。最有力的回复立刻点出了尚未解决的一层:隔离环境或许能证明执行发生过,但市场仍然需要可移植的声誉,这样智能体才能知道上一次到底是谁真正交付了结果。
另一个更小但很说明问题的构建者备注,来自 @Ahmedhaq01 说(18 次点赞、12 条回复、224 次浏览),自己开始在 Arc 上做一个 AI 智能体市场,后来转向了别处,因为生态里智能体还不够多,还撑不起一个真正有价值的市场。
讨论要点: 讨论已经越过“智能体能不能付钱”,开始追问“对面能不能被发现、验证和信任”。
与前日对比: 更早的市场讨论还偏投机。6 月 1 日加入了真实结算、结账原语和钱包签名传输,但也让声誉和流动性缺口更难回避。
2. 令人困扰的问题¶
上下文蔓延会把好看的 demo 变成失败的生产智能体¶
严重程度:高。@levie 认为(173 次点赞、33 条回复、33,132 次浏览、203 次收藏),企业智能体会坏在碎片化系统、错配权限和没有被记录下来的部落知识上。@arpit_bhayani 写道(150 次点赞、5 条回复、6,244 次浏览、65 次收藏),OOM 仍是最常见的生产失败,因为智能体把过多工具输出和文档状态留在内存里;而 @israfill 展示(13 次点赞、4 条回复)了一张前后对比图,说明 CodeGraph 如何去掉 3,847 个 token 的盲目代码库搜索浪费。人们的应对方式,是在遗留系统上套 Playwright 抽象、激进截断、做仓库索引,以及引入 AdaCoM 这样的外部上下文管理器。这值得构建,因为痛点会直接表现为失败、token 浪费,以及在编程和知识工作智能体里都得靠手工善后。
企业部署仍卡在运行时安全与治理上¶
严重程度:高。@NousResearch 宣布(392 次点赞、42 条回复、41,025 次浏览、78 次收藏)Hermes Agent 支持 OpenShell,而 @shannholmberg 认为(20 次点赞、773 次浏览、11 次收藏),正是这一运行时层最终让企业部署成为可能。@codebrandes 贴出(66 次点赞、13 条回复、3,913 次浏览)Gate AI 的构建者文章,其中说提示词注入、秘密泄露和被劫持的工具调用,仍是日常智能体用户真正的攻击面。人们的应对方式,是把安全护栏从模型内部挪到沙箱、策略引擎、代理网关和可审计运行时上。这值得构建,因为一旦智能体拿到 shell 访问、工具和持久状态,只靠提示词防线显然不够。
静态技能包既浪费 token,也会造成配置漂移¶
严重程度:中高。@room_ashish 主推(8 次点赞、200 次浏览)Milkey,核心抱怨就是智能体每次请求都要读完整套技能描述。@aiedge_ 贴出(19 次点赞、1,471 次浏览、33 次收藏)官方 Hermes Skills Hub,其公开壳层已经在跨注册中心加载 8.8 万+ 技能;@HuggingPapers 则提到(21 次点赞、1,072 次浏览、14 次收藏)COLLEAGUE.SKILL 的多阶段蒸馏流程。绕行方案已经很清楚:把技能托管在服务端,通过 MCP 在运行时解析,并围绕共享注册中心做标准化,而不是在项目之间复制提示词文件。这值得构建,因为代价会立刻体现在提示词长度、配置重复,以及跨工具行为不一致上。
市场仍缺少足够的信任与深度,难以形成流动性¶
严重程度:中高。@tetsuoai 报告(144 次点赞、28 条回复、5,833 次浏览、31 次收藏),AgenC 上已经出现真实打款,但最早的一批回复之一问的就是证据。@aashatwt 做了(42 次点赞、11 条回复、1,485 次浏览)AgentLance,而最有力的回复立刻指出,跨市场可移植的声誉仍未解决。更直接的是,@Ahmedhaq01 说(18 次点赞、12 条回复、224 次浏览),自己已经因为生态仍太早期、还没有足够多智能体来让市场变得有价值,而放弃了一个智能体市场方向。这值得构建,因为核心流程如今已经存在,但可重复的信任、发现机制和供给仍然很弱。
3. 人们期望的功能¶
带出处凭证且保持新鲜的可移植上下文¶
最强的需求不是“给我一个更大的窗口”,而是“给我不会过时、能标明来源,也不会把智能体撑爆的上下文”。Levie 的企业讨论串、Arpit Bhayani 的 OOM 帖子、AdaCoM 的可复用上下文管理器,以及 CodeGraph 的仓库索引,都指向同一个缺口。这是一个现实需求,而不是愿景,因为人们已经在手工搭抽象层和记忆层来补这个洞。机会:直接。
可跨智能体工作的运行时加载技能层¶
Milkey、Hermes Skills Hub 和 COLLEAGUE.SKILL 都说明,用户想要的是一个共享技能面:按需加载、可跨工具携带,而且不必在项目之间复制提示词文件夹。这种需求更偏运营,而不是情绪层面的:更低的 token 消耗、更少的配置漂移,以及更好的治理。机会:直接。
跨框架智能体消息、身份与声誉¶
SIGNA 的切入点,是每个智能体现在仍像孤岛一样,而 AgenC 和 AgentLance 则说明,支付闭环可以先于信任层跑起来。Ahmedhaq01 的转向把这个未满足需求说得很直白:在智能体能跨框架彼此发现、验证和信任之前,很多市场都会继续很薄。机会:直接且具竞争性。
可检查的追踪记录与可恢复的会话¶
agent-trace、ActiveGraph、LiteParse 和 Memory Forge RS 分别在解决同一个问题的不同部分:团队想要可回放的追踪记录、精确到源级别的审计轨迹,以及一种在上下文变坏后不必把长会话从零重来的恢复方式。这是非常现实的可靠性需求,而且对工作流价值很明确。机会:直接。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| 运行框架工程模式 | 方法 | (+) | 给团队一张共享地图,把目标行为映射到文件系统、工具、沙箱、记忆和编排 | 只有和具体的上下文、成本、验证控制结合起来,才不会继续停留在抽象层 |
| CodeGraph | 代码智能 / MCP | (+) | 本地语义索引、符号搜索、影响分析、更少工具调用,并广泛支持编程智能体 | 需要按项目建立索引,而且公开节省数据目前仍主要来自厂商自己的基准集 |
| AdaCoM | 上下文管理研究 | (+) | 为冻结智能体提供可复用的外部上下文裁剪;模型无关,而不局限于提示词局部 | 增加了一层管理器,也暴露出忠实度与可靠性之间的取舍 |
| Qwen3.7-Plus | 多模态 LLM | (+) | 统一 GUI/CLI 任务、首发就给出强势的智能体与多模态基准图,并且 API 可用 | 仅以 API 形式首发,而且前沿赛道异常拥挤 |
| MiniMax M3 | 多模态 / 开放权重 LLM | (+) | 1M 上下文、覆盖编程/GUI/推理任务的大表格基准,以及激进的 API 定价 | 首发时技术报告和开放权重都还未到位 |
| OpenShell | 安全运行时 | (+) | 提供沙箱、策略引擎、隐私路由,以及一套可信的企业部署叙事 | 把复杂度转移到了运行时策略、审批流和环境配置上 |
| Milkey | 技能交付 / MCP | (+) | 运行时加载的共享技能、没有本地提示词漂移、能跨多个编程智能体共用一层 | 属于托管服务,对注册中心和认证基础设施形成中心化依赖 |
| Gate AI | 安全网关 | (+/-) | 在不改工作流的前提下拦截提示词注入、隐藏秘密、压缩提示词,并加入可验证审计日志 | 公开基准叙事主要由厂商自己发布,而且产品仍处于私测阶段 |
| agent-trace | 可观测 / 评估 | (+) | 支持回放 diff、CI 回归闸门、OTLP 导出、工作区隔离和 HTML 回放 | 相比更通用的可观测工具,采用证据仍偏早期 |
| ActiveGraph | 状态 / 追踪运行时 | (+) | 支持回放、分叉、diff、追加式事件日志和可持久图状态,适合长时间运行的智能体 | 相比更简单的循环 + 记忆方案,架构开销更大 |
| LiteParse | 文档解析器 | (+) | 本地解析,返回边界框和截图,便于形成精确到源级别的审计轨迹 | 在最难的版式和扫描件上,本地解析仍不如云端解析器 |
整体舆论更偏好那些能减少上下文浪费、把控制放到模型之外,并让人能事后检查智能体行为的工具。迁移方向很清楚:从静态技能文件夹转向运行时加载的注册中心,从只靠提示词的安全护栏转向策略运行时和流量网关,从盲目的文件搜索循环转向语义索引和可回放的追踪记录。Qwen3.7-Plus 和 MiniMax M3 也都不是被当作抽象的前沿模型品牌来评判,而是被当成“基准 + 价格”的产品包来比较。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| CodeGraph | Colby McHenry | 面向编程智能体的预索引代码知识图谱和 MCP 层 | 编程智能体从零发现代码结构时会浪费 token | 本地语义索引、MCP 集成、Claude Code/Codex/Cursor/Hermes 等的智能体自动配置 | 已发布 | 仓库, 帖子 |
| Gate AI | Constellation | 即插即用网关,负责扫描智能体/模型流量、拦截提示词注入、隐藏秘密、压缩提示词并写入可验证审计日志 | 小团队想要智能体安全与成本控制,但不想走企业采购流程,也不想重写工作流 | API 代理、压缩、prompt-cache 注入、区块链支撑的审计轨迹 | Beta | 网站, 博客, 帖子 |
| AgenC Marketplace | @tetsuoarena | 基于 Solana 的市场,让智能体认领付费任务、提交结果,并在审阅后完成结算 | 智能体到智能体的工作需要审批、结算,以及可用的运营流程 | Solana 主网、钱包流程、审阅后结算、支持 Claude Code/Codex/Hermes | Beta | 帖子 |
| SIGNA | @Signa_Agent | Base 上为智能体提供的钱包签名消息和 A2A 传输层,可选按次收取 USDC | 不同框架上的智能体仍无法干净地相互发消息或付款 | Base、XMTP、Google A2A、ERC-8004、USDC/x402 | 已发布 | 网站, 帖子 |
| agent-trace | @Siddhant_K_code | 全会话追踪与评估工具,支持回放 diff 和 CI 回归检查 | PR 和日志解释不了智能体在一次运行里到底做了什么 | Python、Claude hooks、MCP 代理、OTLP 导出、GitHub Actions | Beta | 仓库, 帖子 |
| ActiveGraph | @yoheinakajima | 事件溯源图运行时,让团队能回放、分叉和 diff 智能体运行 | 长时间运行的智能体需要可持久、可检查的状态,而不是不透明日志 | Python 3.11+、追加式事件日志、图运行时、回放/分叉/diff | 已发布 | 网站, 帖子 |
| LiteParse v2 | @jerryjliu0 | 快速本地解析器,返回文本、边界框和截图,供智能体工作流使用 | 智能体需要能指回精确源区域的文档解析 | Rust、PDFium、Tesseract、Node/Python/WASM 绑定、截图生成 | 已发布 | 仓库, 帖子 |
| Memory Forge RS | @DanKornas | 本地桌面应用,让用户编辑 AI 编程助手的会话历史,而不是重启 | 坏掉的上下文会迫使用户丢掉长会话,从头再来 | Tauri v2、React 19、Rust、TypeScript | Beta | 仓库, 帖子 |
CodeGraph 和 Gate AI 之所以突出,是因为它们都包在现有智能体外层,而不是要求用户换到全新的智能体。前者把代码库上下文和语义查找产品化,后者把模型 API 周围的在线安全、提示词压缩和可审计性产品化。
AgenC 和 SIGNA 展示出新兴商业栈正在分成两层。AgenC 负责任务发布、审阅和结算,SIGNA 则聚焦跨框架身份、消息和支付通道;Unibase 关于 AllScale checkout 技能的帖子则说明,支付工作流已经开始被模块化成可移植技能。
agent-trace、ActiveGraph、LiteParse 和 Memory Forge RS 反映出第二种构建模式:团队正在让智能体工作变得可检查、可回放、有源可依,或可编辑,而不只是继续提高自主性。这是一个很强的信号,说明可观测性和恢复能力正在变成各自独立的产品类别。
6. 新动态与亮点¶
技能目录开始更像分发平台¶
@aiedge_ 贴出(19 次点赞、1,471 次浏览、33 次收藏)了官方 Hermes Skills Hub,其公开壳层已经在跨所有注册中心加载 8.8 万+ 技能。与此同时,@HuggingPapers 提到(21 次点赞、1,072 次浏览、14 次收藏)COLLEAGUE.SKILL 拥有一个包含 215 个技能的社区展示页。真正值得注意的变化,不只是技能存在,而是它们开始像平台层一样被编目、版本化和分发。
安全产品开始同时售卖保护与效率¶
@codebrandes 贴出(66 次点赞、13 条回复、3,913 次浏览)Gate AI 的构建者文章,而公开产品站点把提示词注入拦截、秘密隐藏与 20%+ 的 token 节省、感知缓存的压缩放在一起售卖。再加上 OpenShell/Hermes 这套运行时叙事,安全看起来不再像企业事后的补丁,而更像核心智能体运行时与成本栈的一部分。
可追溯性开始更接近智能体产品的一等公民功能¶
@Siddhant_K_code 将(23 次点赞、8 条回复、1,501 次浏览)agent-trace 发布到 GitHub Actions Marketplace;@yoheinakajima 展示(14 次点赞、3 条回复、2,264 次浏览)了如何把一个编程智能体压平成一条事件日志追踪;@jerryjliu0 则认为(7 次点赞、2 条回复、1,912 次浏览、14 次收藏),边界框之所以重要,是因为智能体应该能引用精确的源区域。真正值得注意的变化,是可追溯性正从隐藏的调试输出,走向被产品当作面向用户的功能来展示。
7. 机会在哪里¶
[+++] 面向生产智能体的上下文操作系统 —— 最强的证据簇来自 Aaron Levie 的企业上下文讨论串、Arpit Bhayani 的 OOM 说明、AdaCoM 的可复用上下文管理器帖子,以及 CodeGraph 的代码库索引主张。未被满足的需求不是原始 token 体量,而是新鲜度、出处、压缩、检索,以及能跨代码与业务上下文抗失败的记忆。
[++] 运行时加载的技能交付与治理 —— Milkey、Hermes Skills Hub、COLLEAGUE.SKILL 和 OpenShell/Hermes 运行时叙事 都指向同一个入口:团队希望技能像基础设施一样被分发、按需加载,并在模型之外被治理。
[++] 可审计的追踪记录与恢复工具 —— agent-trace、ActiveGraph、LiteParse 和 Memory Forge RS 从不同角度攻击的是同一个问题:运营者需要在智能体运行出错时,拥有回放、diff、源级证据和恢复路径。
[+] 跨框架智能体商业化与声誉 —— AgenC Marketplace、SIGNA、BitAgent 上的 AllScale Checkout 和 AgentLance 表明,支付和消息闭环已经开始能跑。正在显现的缺口,是可移植的信任:执行证明、声誉,以及足够多的交易对手,市场才会真正形成流动性。
8. 要点总结¶
- 上下文处理已经成了严肃智能体的主要系统瓶颈。 Levie 的企业告警、Arpit Bhayani 的 OOM 帖子、AdaCoM 的外部上下文管理器,以及 CodeGraph 的索引仓库图谱,都指向同一个变化:性能现在取决于智能体看到了什么、保留了什么,又丢掉了什么。 (source)
- 智能体模型发布正被当成“基准 + 定价”的产品包来评判,而不只是品牌事件。 Qwen3.7-Plus 和 MiniMax M3 都带着大范围基准表、多模态主张和具体 API 经济学一起亮相。 (source)
- 技能正在变成一个分发与运行时问题。 OpenShell、Milkey、Hermes Skills Hub 和 COLLEAGUE.SKILL 都把技能描述成受治理、可托管、可版本化的基础设施,而不再是零散的提示词文件。 (source)
- 智能体商业化不再只是设想,但仍很早期。 AgenC 和 SIGNA 展示了真实结算与钱包签名传输,而 AgentLance 的回复和 Ahmedhaq01 的转向则说明,声誉与流动性仍是缺失层。 (source)
- 可检查性正在成为独立的产品面。 agent-trace、ActiveGraph、LiteParse 和 Memory Forge RS 都在假设,用户需要回放、diff、引用,甚至编辑智能体历史,而不是相信一次不透明的运行。 (source)