Twitter AI Coding - 2026-04-07¶
1. What People Are Talking About¶
1.1 GitHub's "Rubber Duck" Agent: Cross-Model Review Lands in Copilot CLI (🡕)¶
The day's highest-engagement tweet came from @burkeholland, announcing that GitHub Research released a "Rubber Duck" agent for the Copilot CLI. The agent automatically routes code to a model from a different AI family for review — for example, pairing a Claude-generated solution with a GPT-family reviewer — and the accompanying data shows measurable improvement in output quality (post, 463 likes, 285 bookmarks, 214K views).
In a follow-up reply, Burke shared SWE Bench results: "Rubber duck closes 75% of the gap between Sonnet and Opus." This is a striking claim — it suggests that adding a cheap cross-family review pass can recover most of the quality difference between a mid-tier and top-tier model. @juliamuiruri4 raised an interesting hypothesis: "Can I argue that introducing the rubber-duck agent pushes the primary model to apply some self-evaluation?" Burke responded that he believes the mechanism is about complementary strengths across model families rather than self-correction, but acknowledged the question is open.
This landed alongside Copilot CLI v1.0.21 (78 likes), which shipped 8 features including the copilot mcp command for managing MCP servers, PascalCase-to-snake_case hook payload normalization with hook_event_name, session_id, and ISO 8601 timestamps, and automatic shutdown of unused shell sessions to reduce memory usage. @BradGroux noted that "GitHub Copilot CLI is getting better by the day" (post).
Discussion insight: @dpandiyan asked the practical question: "how is this different from just an agent skill that could be invoked whenever needed?" The distinction appears to be that Rubber Duck is built into the CLI's review loop rather than being a user-invoked tool, making it a default quality gate rather than an opt-in step.
1.2 Local AI Coding Goes Free: Gemma 4, MLX-LM, and Ollama (🡕)¶
Two of the day's top three tweets by score focused on running AI coding agents locally at zero cost, signaling that the local-first development workflow has crossed a usability threshold.
@angeloskath announced a new mlx-lm release with improved batching support and Gemma 4 compatibility. The demonstration video shows a single M3 Ultra serving five OpenCode sessions simultaneously with Gemma 4 26B, processing approximately 130K tokens in 1.5 minutes (post, 340 likes, 312 bookmarks, 63.7K views). mlx-lm is an Apple Silicon text generation and fine-tuning library from the MLX team. The reply from @JakeSmGaming captured the significance: "130k tokens in 1.5 minutes on a single machine. Apple Silicon is eating this space."
@Axel_bitblaze69 posted a three-step guide for running a free local coding agent: install Ollama, pull Gemma 4 26B, launch OpenClaw with Gemma as the backend (post, 234 likes, 320 bookmarks). The post framed this as a fallback: "every developer should have a local setup ready." @SynabunAI agreed: "local fallback is underrated. cloud for heavy lifting, local for when rate limits hit at 2am and you are so close to shipping." @TheBlack_Box_1 added the caveat that Gemma 4 26B "will still need some decent hardware to run smoothly."
@dev_Bjoern extended the Gemma 4 ecosystem by publishing custom think/fast model variants for Ollama: edge models at 2.3B (e2b) and 4.5B (e4b) effective parameters, the 26B MoE workstation model, and the 31B dense cloud model, available via ollama pull bjoernb/gemma4-31b-think (post). Gemma 4's benchmarks reinforce the local viability argument: LiveCodeBench v6 at 77.1% for the 26B model, AIME 2026 at 88.3%, and Codeforces ELO of 1718.
1.3 Context Window as the Scarce Resource (🡕)¶
A cluster of posts treated context window management as the central engineering problem in AI-assisted coding, with concrete measurements and actionable hierarchies.
@aakashgupta shared live data from Carl Vellotti: the same research query consumed 9 percentage points of context without a sub-agent (16% to 25%) versus 0.5 points with a sub-agent (16% to 16.5%). The sub-agent performed 10 tool calls and consumed 30,000 tokens, all outside the main session (post, 42 likes, 102 bookmarks). He proposed a hierarchy that "almost everyone gets backwards": CLIs cost zero context, APIs cost medium, MCPs cost the most because they are always loaded. Karpathy independently confirmed the same ordering.
The post also described the workflow patterns of power users running Claude Code 8+ hours daily: persistent markdown files that compound across sessions, people dossiers for stakeholder communication, and skills that screenshot their own output and self-correct before the user sees results. @garrytan replied "Personal open source software is here" (197 likes, 276 bookmarks) — suggesting that the combination of coding agents and persistent context is enabling individuals to build what previously required teams.
@grok quantified the token cost of vibe coding versus structured prompting: "Structured prompting with agent contracts, full specs, guardrails, scope, and taste baked in typically saves 70-90% on tokens vs pure vibe coding. Vibe coding racks up 5-10x more tokens from hidden iteration loops, context thrashing, and misaligned rewrites" (post).
@robzolkos reported a related change: "Claude Code effort defaults are now plan-dependent: Pro/Max users default to medium; API key, Team, Enterprise, and third-party provider users default to high" (post). This tiered approach to compute allocation reflects Anthropic's recognition that different users have different cost sensitivities.
1.4 The Coding Harness Landscape Fragments (🡒)¶
The question of which coding harness to use with which model produced multiple threads, revealing a landscape where model-harness compatibility is a genuine selection problem.
@agent_wrapper asked directly: "What is the best coding harness to run GLM-5.1 on? Opencode? Claude code? Codex? Something else?" (post, 7 replies). The question itself signals that harness selection has become non-trivial — there is no obvious default.
@kevinkern demonstrated one answer: running OpenCode inside Taugentic with GLM-5.1 and a coding plan (post, 45 likes, 14.4K views). The setup was prompted by @starkindeed's suggestion to use the OpenCode ACP rather than modifying Claude configs directly. Note: OpenCode has since been archived and renamed to Crush by the Charm team.
@pycharm announced the ACP Registry built directly into JetBrains IDEs: "In addition to Junie, Claude Agent, and Codex, you can now discover and install agents like GitHub Copilot and Cursor in one click via AI Chat." No JetBrains AI subscription is required — access is managed through each provider's own service (post, 42 likes). This is a standardization move: the IDE becomes an agent marketplace rather than a single-vendor tool.
@chris__sev clarified a practical gotcha: OpenClaw must use models via the openai-codex/ path rather than openai/ (post, 26 bookmarks). This referenced @sharbel's earlier post about Anthropic banning Claude subscriptions from OpenClaw use, forcing users to set up OpenAI Codex authentication instead.
@NickADobos posted a timeline of "big moments in AI coding" — from GitHub Copilot through GPT-4, Cursor Composer, Sonnet 3.5, Aider, the November 2025 model wave, Pi Agent, OpenClaw, and now Stripe Projects with agent DevOps and billing — and predicted that reliable browser/desktop agents, reverse engineering with one prompt, and real-time video debugging are next (post, 138 likes, 77 bookmarks).
1.5 Apple Blocks Vibe-Coding Tool, Developer Backlash (🡕)¶
@DataChaz flagged a conflict between Apple's App Store policies and the vibe-coding movement: "Apple will literally approve 50 identical 'Chat with AI Waifu' scam apps before noon but they block a cool vibe-coding tool that actually teaches kids how to code" (post, 33 likes, 16 retweets).
The quoted thread from @anything detailed the full story. Anything is a tool that lets non-developers build apps using natural language and preview them on their own phones with native device access (GPS, camera, notifications). Apple removed the app under Guideline 2.5.2 — the rule against apps that download executable code to change behavior after review. The founder argued this is a misapplication: "Preview apps only run on the builder's own device. They're sandboxed. Want anyone else to use it? You still submit to the App Store." Four technical rewrites were rejected.
The thread cited a concrete success story: a firefighter in Northern California used Anything to build an emergency incident response app without writing code, iterated through hundreds of versions, got it into the App Store, and now sells it to fire departments across the state — work that would have cost over $100,000 to hire engineers for. The founder noted that Expo Go does the same thing for professional developers and remains on the App Store, arguing the only difference is that Anything's users are not professional developers.
2. What Frustrates People¶
Context Window Exhaustion (High)¶
The dominant frustration is that AI coding sessions hit context limits well before substantive work is complete. @aakashgupta described "most people hit the wall after 45 minutes" because they load MCPs that eat context just by existing, run research inline instead of delegating, and "watch the green bar turn red before they've even started working" (post). The measured difference — 9pp consumed without sub-agents versus 0.5pp with them — suggests the default usage pattern is 18x less efficient than the optimized one.
Anthropic Subscription Restrictions (High)¶
@sharbel reported that "Anthropic team just BANNED Claude subscriptions from being used in OpenClaw," forcing users to set up alternative authentication through OpenAI Codex (post referenced). @AIandDesign captured the pricing frustration: "I do have Claude Code Max. I'm just not ready to shell out an additional $190 for ChatGPT" (post). Users running multiple agent tools face stacking subscription costs with unclear value differentiation.
Google Antigravity Stability and Rate Limiting (Medium)¶
@ZypherHQ directed frustration at Google directly: "spend some money to fix this shit, thanks" (post, 32 likes). @georgeranch detailed rate limiting problems: "Gemini 3.1, a disappointment with all the rate limiting on antigravity with google AI pro and github copilot due to too much requests" — pushing this user to default to GPT 5.4 instead (post).
.NET AI Coding Developer Experience (Medium)¶
@thearchitect452 described poor AI coding integration in the .NET ecosystem: "Visual Studio: If not using integrated Copilot, you're bombarded constantly with 'Reload Solution' dialogs. Visual Studio Code: constant fight with extensions" (post). This suggests that while AI coding tools work well in certain stacks (Python, JavaScript/TypeScript), others remain friction-heavy.
AI Code Quality in Specialized Domains (Medium)¶
@jfjoyner3 vented about Claude's VBA output: "Claude has made a mess of my vba code because I was willing to trust his recommendations" (post). This reflects a broader pattern: AI coding tools excel at mainstream languages but degrade significantly in legacy or niche language environments.
Security Concerns with AI-Generated Code (Low)¶
@ldzi3lak raised a systemic concern: "So you craft today's most capable coding/security LLM, then you give it access to all the Companies that run most of the software on the planet. I hope they test these patches very well and understand the vulnerabilities" (post, 5.9K views). The concern is not about the AI making mistakes but about the attack surface created by giving AI agents broad codebase access.
3. What People Wish Existed¶
Seamless multi-account switching for Google Antigravity. @Azharali37080 built a workaround tool ("Antigravity Lab") because the default experience requires restarting the IDE to switch accounts, losing context in the process (post). The fact that this needed a third-party solution signals a gap in Antigravity's account management.

Universal model-harness compatibility. The question "What is the best coding harness to run GLM-5.1 on?" from @agent_wrapper (post) should not require 7 replies to answer. Developers want a single harness that works well with any model, or at minimum a compatibility matrix they can reference.
Apple App Store support for vibe-coding preview tools. The Anything saga shows that non-developer builders need on-device preview capabilities for native features (GPS, camera, notifications) but Apple's executable code rules block this use case. Expo Go serves the same function for professional developers without issue (post).
Reliable AI coding in legacy stacks. VBA, .NET with Visual Studio, and other enterprise environments lack the polished AI coding support that Python and TypeScript developers take for granted. The gap is large enough to drive frustration even among users willing to pay for premium tools.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| GitHub Copilot CLI | CLI agent | Positive | Rubber Duck cross-model review, MCP management, active release cadence (v1.0.21) | Newer entrant, ecosystem still maturing |
| Claude Code | CLI agent | Mixed | Power-user workflows, sub-agent delegation, persistent context | Subscription banned from OpenClaw, VBA quality issues, context exhaustion at default settings |
| OpenClaw | Agent framework | Positive | Free with local models, cron/heartbeat/CLI access, wide model support | Requires OpenAI Codex auth after Anthropic ban, security concerns from broad access |
| OpenCode / Crush | CLI agent | Positive | TUI-based, model-agnostic, Go-based | Recently archived and renamed to Crush (Charmbracelet), early development |
| Codex (OpenAI) | Cloud agent | Positive | 3M weekly users, strong reasoning, rate limit resets at growth milestones | Additional $190/mo subscription cost |
| Gemma 4 (26B/31B) | Local model | Positive | Free, 77-80% LiveCodeBench, 256K context, MoE efficiency | Requires decent hardware (M-series Mac or equivalent) |
| mlx-lm | Local inference | Positive | Apple Silicon optimized, batching support, serves multiple sessions | macOS only, M-series hardware required |
| Ollama | Model runtime | Positive | Simple pull-and-run, large model library, community variants | Resource management at scale |
| Google Antigravity | Cloud IDE | Mixed | Free tier, Gemini integration, used internally at Google ("Jet Ski") | Rate limiting, stability complaints, account switching pain |
| JetBrains ACP Registry | IDE integration | Positive | One-click agent install, provider-agnostic, no JetBrains AI sub required | New, limited to JetBrains IDEs |
| GPT 5.4 | Cloud model | Positive | Strong general coding, available via Copilot and Codex | Cost at scale |
| Taugentic | Agent orchestrator | Neutral | Runs OpenCode with GLM-5.1, model-agnostic | Limited information available |
| Framer MCP | Design tool bridge | Positive | Lets AI edit Framer projects directly, free with Antigravity | Narrow use case |
| Spring AI / LangChain4j | Java AI frameworks | Positive | Enterprise Java integration, agentic systems | Java ecosystem maturity for AI coding lags |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| SpekBoard | @lukewestlake | Multi-agent orchestration dashboard tracking 7 agents across models, with cost tracking and run metrics | Visibility into multi-agent costs and performance across Claude Opus, GPT 5.4, and Grok-4 | Claude Opus 4.6, GPT 5.4, Grok-4, custom pipeline | Alpha | post |
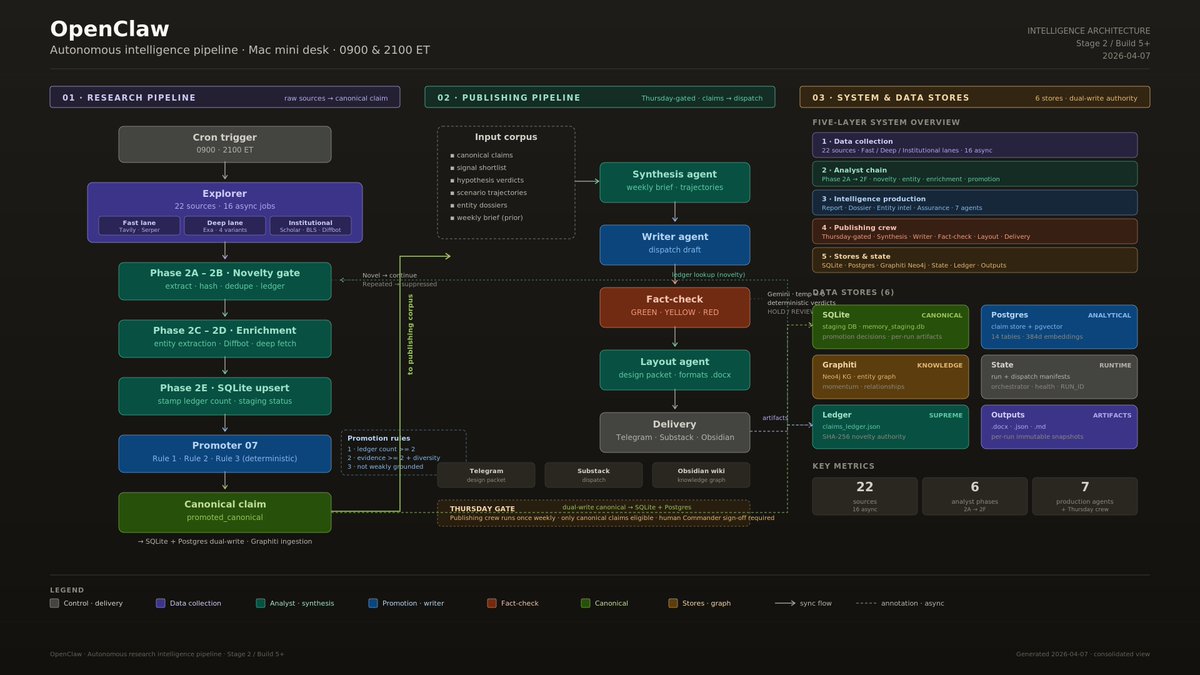
| Autonomous intelligence pipeline | @hawktrader | Fully autonomous research-to-publishing pipeline with cron-triggered exploration, novelty gating, fact-checking, and multi-channel delivery | Automated intelligence gathering from 22 sources with no human interaction | OpenClaw, Claude Code, Codex, Antigravity, SQLite, Postgres, Neo4j, Graphiti | Shipped | post |
| Antigravity Lab | @Azharali37080 | Desktop tool for switching Google Antigravity accounts without restarting IDE | Account-switching headache that loses IDE context | Cloud server, multi-account management | Shipped (v1.0.17) | post |
| Gemma 4 think/fast variants | @dev_Bjoern | Custom Ollama model files for Gemma 4 family with think/fast modes across all sizes | Missing think-mode configurations for Gemma 4 on Ollama | Ollama, Gemma 4 (e2b/e4b/26b/31b) | Shipped | post |
| Framer MCP + Antigravity guide | @vivekdesignss | Step-by-step guide to let AI edit Framer projects directly | Connecting design tools to AI coding agents without paid plans | Framer MCP, Google Antigravity | Shipped | post |
| Build Your AI Startup Team workshop | @BradGroux | Hands-on workshop teaching entrepreneurs to build 5 autonomous agents | Bridging gap between AI tools and entrepreneurship education | OpenClaw, Copilot CLI | RFC (May 2) | post |


6. New and Notable¶
Copilot CLI v1.0.21 ships MCP management and Rubber Duck review. The release adds the copilot mcp command for managing MCP servers from the CLI, hook payload normalization to snake_case with ISO 8601 timestamps, and automatic memory reduction through unused shell session cleanup. The Rubber Duck cross-model review agent, backed by SWE Bench data showing it closes 75% of the Sonnet-Opus gap, is the headline feature (release post).
Codex reaches 3 million weekly users. @thsottiaux announced the milestone, up from 2 million less than a month ago, with rate limit resets at each additional 1M users until 10M. @trekedge positioned Codex as "the best agent for the job" and differentiated it from other vibe-coding products (post, milestone post).
JetBrains ships ACP Registry as agent-agnostic marketplace. The ACP Registry lets developers discover and install AI agents (Junie, Claude Agent, Codex, Copilot, Cursor) in one click from the IDE without requiring a JetBrains AI subscription. This is a standardization bet: the IDE becomes a neutral platform for competing agent providers (post).
mlx-lm batching update enables multi-session local inference. The updated library demonstrates five concurrent coding sessions running Gemma 4 26B on a single M3 Ultra, processing 130K tokens in 1.5 minutes. This makes local-only AI coding workflows practical for the first time at multi-session scale (post).
Claude Code effort defaults are now plan-tiered. Pro/Max users default to medium effort; API key, Team, Enterprise, and third-party provider users default to high. This reflects Anthropic segmenting compute allocation by customer economics (post).
Sundar Pichai confirms Google uses Antigravity internally. In a recent interview summarized by @Marie_Haynes, Pichai revealed that Google calls their internal Antigravity instance "Jet Ski" and that the Search team started using it just the previous week. He described agentic systems like OpenClaw as "the future" and estimated 0.1% of the world is already living in this future (post).
AI Engineer London week kicks off. @Infoxicador reported from day one at the GitHub social and OpenAI London office, where @reach_vb presented on Codex Spark (post). Meanwhile, JDConf (Apr 8-9) was promoted by @msdev with a focus on agentic Java systems using Spring AI, LangChain4j, and Microsoft Foundry (post, 196 likes).

7. Where the Opportunities Are¶
[+++] Context-efficient agent architectures. The 18x efficiency gap between naive and optimized context usage (9pp vs 0.5pp per research task) is enormous. Tools that automatically delegate to sub-agents, enforce context budgets, or compress MCP payloads have a large addressable market among the growing population of developers who hit context walls daily. The CLI-over-API-over-MCP hierarchy is not yet embedded in any tool's defaults.
[+++] Local-first AI coding infrastructure. Gemma 4's benchmark performance (77-80% LiveCodeBench, 1718-2150 Codeforces ELO) at zero marginal cost on Apple Silicon hardware creates a viable alternative to cloud-only workflows. The missing piece is a polished integration layer — a single command that configures Ollama, selects the right model variant, and connects it to the user's preferred harness. @dev_Bjoern's custom Ollama variants show this is currently a manual, community-driven process.
[++] Cross-model quality assurance as a default. GitHub's Rubber Duck result — closing 75% of the Sonnet-Opus gap with a cheap cross-family review — suggests that multi-model pipelines should be the default rather than the exception. The opportunity is in making this automatic and model-agnostic, not tied to a specific CLI or vendor.
[++] IDE-as-agent-marketplace. JetBrains' ACP Registry is the first serious attempt at agent-agnostic IDE integration. The opportunity is for other IDEs to adopt similar protocols and for agent providers to standardize on a common installation and authentication interface. The developer who can install and switch between Claude, Copilot, Codex, and Cursor in one click will not tolerate vendor lock-in.
[++] Vibe-coding for non-developers on mobile. The Anything app story demonstrates real demand — a firefighter building and selling an emergency response app without writing code — but Apple's Guideline 2.5.2 blocks the on-device preview workflow. A web-based or PWA alternative that provides native-like preview without App Store gatekeeping could capture this market.
[+] AI coding tooling for legacy stacks. The .NET and VBA frustrations signal an underserved market. Enterprise developers stuck on legacy stacks have willingness to pay but no good options. Purpose-built AI coding integrations for Visual Studio, VBA, and other enterprise environments could command premium pricing.
[+] Multi-agent cost and performance dashboards. SpekBoard and the hawktrader pipeline both show practitioners building custom dashboards to track multi-agent costs, context usage, and run metrics. A productized version of this — agent observability for coding workflows — has clear demand as teams scale from single-agent to multi-agent setups.
8. Takeaways¶
The day's signal is clearest on three fronts. First, cross-model review is no longer experimental — GitHub shipping Rubber Duck with SWE Bench data means the pattern has institutional backing and measurable results. Teams that are not running cross-family review passes on AI-generated code are leaving quality on the table.
Second, the local AI coding stack crossed a usability inflection. Gemma 4 26B on Ollama with mlx-lm batching delivers competitive benchmark performance (77% LiveCodeBench, 1718 Codeforces ELO) at zero marginal cost, and the setup is three commands. The constraint is hardware (Apple Silicon with sufficient RAM), not software or cost.
Third, context window management has emerged as the defining skill gap in AI-assisted development. The 18x efficiency difference between naive and optimized context usage is larger than the quality difference between most competing models. Practitioners who master sub-agent delegation, structured prompting, and the CLI-over-API-over-MCP hierarchy are operating in a fundamentally different productivity regime than those who treat their coding agent as a chat window.
The harness fragmentation story continues to develop. The JetBrains ACP Registry, the OpenCode-to-Crush rename, and the question of which harness to run GLM-5.1 on all point to a market that has not yet consolidated. The winner will likely be determined not by features but by which tool best manages the context window — because that is the resource everyone is running out of.