Twitter AI 编程 - 2026-04-07¶
1. 人们在讨论什么¶
1.1 GitHub 的 “Rubber Duck” 智能体:跨模型审查进入 Copilot CLI(🡕)¶
当天互动量最高的推文来自 @burkeholland。他宣布 GitHub Research 为 Copilot CLI 发布了一个 “Rubber Duck” 智能体。该智能体会自动把代码交给另一个 AI 家族的模型审查——例如,用 GPT 家族模型审查 Claude 生成的方案——随附数据也显示输出质量有可衡量的提升(推文,463 点赞,285 收藏,214K 浏览)。
在后续回复中,Burke 分享了 SWE Bench 结果:“Rubber Duck 缩小了 Sonnet 和 Opus 之间 75% 的差距。” 这个说法相当醒目——它意味着加上一轮低成本的跨家族审查,就能补回中档模型与顶级模型之间大部分质量差距。@juliamuiruri4 提出了一个有意思的假设:“我能否说,引入 rubber-duck 智能体会推动主模型做一些自我评估?” Burke 回应说,他认为机制更多来自不同模型家族之间的互补优势,而不是自我纠错,但也承认这个问题仍然开放。
这与 Copilot CLI v1.0.21(78 点赞)同时出现。该版本发布了 8 项功能,包括用于管理 MCP 服务器的 copilot mcp 命令,将 PascalCase 转为 snake_case 的 hook payload 标准化(包含 hook_event_name、session_id 和 ISO 8601 时间戳),以及自动关闭未使用的 shell 会话来降低内存占用。@BradGroux 指出,“GitHub Copilot CLI 每天都在变得更好”(推文)。
讨论要点: @dpandiyan 问了一个很实际的问题:“这和一个可在需要时调用的智能体技能有什么区别?” 区别似乎在于,Rubber Duck 内置在 CLI 的审查循环里,而不是一个由用户主动调用的工具;它更像默认质量门,而不是可选步骤。
1.2 本地 AI 编程免费化:Gemma 4、MLX-LM 与 Ollama(🡕)¶
当天按分数排名前三的推文中,有两条聚焦于零成本在本地运行 AI 编程智能体,说明 local-first 开发工作流已经越过可用性门槛。
@angeloskath 宣布 mlx-lm 发布新版本,改进了 batching 支持,并兼容 Gemma 4。演示视频显示,单台 M3 Ultra 同时用 Gemma 4 26B 服务 5 个 OpenCode 会话,在 1.5 分钟内处理约 130K tokens(推文,340 点赞,312 收藏,63.7K 浏览)。mlx-lm 是 MLX 团队面向 Apple Silicon 的文本生成与微调库。@JakeSmGaming 的回复抓住了重点:“单机 1.5 分钟处理 130k tokens。Apple Silicon 正在吃下这块空间。”
@Axel_bitblaze69 发布了一份三步指南,用于运行免费的本地编程智能体:安装 Ollama,拉取 Gemma 4 26B,用 Gemma 作为后端启动 OpenClaw(推文,234 点赞,320 收藏)。这条推文把它定位成备用方案:“每个开发者都应该准备一套本地环境。” @SynabunAI 表示同意:“本地备用方案被低估了。重活交给云端;凌晨 2 点限流、离发版只差一步时,就靠本地。” @TheBlack_Box_1 则补充了限制:Gemma 4 26B “要流畅运行,仍然需要像样的硬件。”
@dev_Bjoern 进一步扩展了 Gemma 4 生态,为 Ollama 发布了自定义 think/fast 模型变体:2.3B(e2b)和 4.5B(e4b)有效参数的边缘模型、26B MoE 工作站模型,以及 31B dense cloud 模型,可通过 ollama pull bjoernb/gemma4-31b-think 获取(推文)。Gemma 4 的基准也强化了本地可行性的论点:26B 模型在 LiveCodeBench v6 上达到 77.1%,AIME 2026 达到 88.3%,Codeforces ELO 为 1718。
1.3 上下文窗口成为稀缺资源(🡕)¶
一组推文把上下文窗口管理视为 AI 辅助编程中的核心工程问题,并给出了具体测量和可执行的层级判断。
@aakashgupta 分享了来自 Carl Vellotti 的实时数据:同一个研究查询,在不使用子智能体时消耗了 9 个百分点的上下文(16% 到 25%),使用子智能体时只消耗 0.5 个百分点(16% 到 16.5%)。该子智能体执行了 10 次工具调用,消耗 30,000 tokens,全部发生在主会话之外(推文,42 点赞,102 收藏)。他提出了一个“几乎每个人都弄反了”的层级:CLIs 的上下文成本为零,APIs 为中等,MCPs 成本最高,因为它们总是被加载。Karpathy 也独立确认了同样的排序。
这条推文还描述了每天使用 Claude Code 8 小时以上的高级用户工作流:跨会话不断累积的持久 markdown 文件,用于干系人沟通的人员档案,以及能截取自身输出并在用户看到结果前自我修正的技能。@garrytan 回复“个人开源软件时代来了”(197 点赞,276 收藏),暗示编程智能体与持久上下文结合后,个人正在构建过去需要团队才能做出来的软件。
@grok 量化了 vibe coding 与结构化提示之间的 token 成本差异:“把智能体契约、完整规格、安全护栏、范围和审美标准都写进结构化提示,通常能比纯 vibe coding 节省 70-90% 的 tokens。纯 vibe coding 会因为隐藏迭代循环、上下文抖动和不对齐的重写,多消耗 5-10 倍 tokens”(推文)。
@robzolkos 报告了一项变化:“Claude Code 的 effort 默认值现在取决于计划:Pro/Max 用户默认 medium;API key、Team、Enterprise 和第三方提供商用户默认 high”(推文)。这种按档位分配计算强度的做法,反映出 Anthropic 已经意识到不同用户对成本的敏感度不同。
1.4 编程运行框架版图碎片化(🡒)¶
围绕“哪个模型该搭配哪个编程运行框架”产生了多条讨论串,显示模型与运行框架的兼容性已经成为真实的选型问题。
@agent_wrapper 直接发问:“运行 GLM-5.1 最好的编程运行框架是什么?Opencode?Claude code?Codex?还是别的?”(推文,7 条回复)。这个问题本身就说明运行框架选择已经不再简单——并不存在一个显而易见的默认答案。
@kevinkern 展示了一个答案:在 Taugentic 中用 GLM-5.1 和一份编程计划运行 OpenCode(推文,45 点赞,14.4K 浏览)。这个设置来自 @starkindeed 的建议:使用 OpenCode ACP,而不是直接修改 Claude 配置。注:OpenCode 后来已被 Charm 团队归档,并改名为 Crush。
@pycharm 宣布 ACP Registry 直接内置到 JetBrains IDEs:“除了 Junie、Claude Agent 和 Codex,你现在也可以通过 AI Chat 一键发现并安装 GitHub Copilot、Cursor 等智能体。” 这不需要 JetBrains AI 订阅——访问权限由各提供商自己的服务管理(推文,42 点赞)。这是一次标准化动作:IDE 正在变成智能体市场,而不是单一供应商工具。
@chris__sev 澄清了一个实际坑点:OpenClaw 必须通过 openai-codex/ 路径使用模型,而不是 openai/(推文,26 收藏)。这引用的是 @sharbel 之前关于 Anthropic 禁止 Claude 订阅用于 OpenClaw 的推文,迫使用户改为配置 OpenAI Codex 认证。
@NickADobos 发布了一条“AI 编程重大时刻”时间线——从 GitHub Copilot、GPT-4、Cursor Composer、Sonnet 3.5、Aider、2025 年 11 月的模型浪潮、Pi Agent、OpenClaw,到现在带有 agent DevOps 与 billing 的 Stripe Projects——并预测可靠的浏览器/桌面智能体、一条提示跑通逆向工程、实时视频调试将是下一步(推文,138 点赞,77 收藏)。
1.5 Apple 封锁 vibe-coding 工具,引发开发者反弹(🡕)¶
@DataChaz 指出 Apple 的 App Store 政策与 vibe-coding 运动发生冲突:“Apple 上午还没过完就能批准 50 个一模一样的‘Chat with AI Waifu’骗局 app,却封掉一个真正教孩子写代码的酷炫 vibe-coding 工具”(推文,33 点赞,16 转发)。
来自 @anything 的引用讨论串讲述了完整经过。Anything 是一款让非开发者用自然语言构建 app 的工具,并允许他们在自己的手机上预览,且可访问原生设备能力(GPS、摄像头、通知)。Apple 依据 Guideline 2.5.2 下架了该 app——该规则禁止 app 下载可执行代码并在审核后改变行为。创始人认为这是误用:“预览 app 只在构建者自己的设备上运行。它们在沙箱里。想让别人使用?你仍然要提交到 App Store。” 四次技术重写都被拒绝。
该讨论串引用了一个具体成功案例:北加州一名消防员用 Anything 构建了一款紧急事故响应 app,没有写代码,迭代了数百个版本,上架 App Store 后现在卖给全州的消防部门——如果聘请工程师来做,成本会超过 $100,000。创始人指出,Expo Go 为专业开发者提供同样能力,并且仍在 App Store 上;他认为唯一区别只是 Anything 的用户不是专业开发者。
2. 令人困扰的问题¶
上下文窗口耗尽(High)¶
最主要的挫败感在于,AI 编程会话在真正推进实质工作前就撞上上下文限制。@aakashgupta 描述说,“大多数人 45 分钟后就撞墙”,原因是他们加载了光是存在就会吃上下文的 MCPs,在主会话里直接做研究而不是委派出去,并且“还没开始干活,就看着绿色进度条变红”(推文)。实测差异——不使用子智能体消耗 9pp,使用后只消耗 0.5pp——意味着默认用法的效率比优化用法低 18 倍。
Anthropic 订阅限制(High)¶
@sharbel 报告称,“Anthropic 团队刚刚禁止 Claude 订阅用于 OpenClaw”,迫使用户改用 OpenAI Codex 走替代认证(引用推文)。@AIandDesign 抓住了价格层面的挫败感:“我确实有 Claude Code Max。只是还没准备好再为 ChatGPT 掏 $190”(推文)。运行多个智能体工具的用户面对的是叠加订阅成本,但不同工具之间的价值差异并不清晰。
Google Antigravity 稳定性与限流(Medium)¶
@ZypherHQ 直接把不满指向 Google:“花点钱把这个问题修好,谢谢”(推文,32 点赞)。@georgeranch 详细描述了限流问题:“Gemini 3.1 令人失望,Antigravity 配 Google AI Pro 和 GitHub Copilot 时请求太多,限流到处都是”——这让该用户转而默认使用 GPT 5.4(推文)。
.NET AI 编程开发者体验(Medium)¶
@thearchitect452 描述了 .NET 生态里糟糕的 AI 编程集成:“Visual Studio:如果不用集成的 Copilot,就会不停被‘Reload Solution’弹窗轰炸。Visual Studio Code:一直在和扩展搏斗”(推文)。这说明 AI 编程工具在某些技术栈(Python、JavaScript/TypeScript)中运转良好,但其他栈仍然摩擦很大。
专门领域中的 AI 代码质量(Medium)¶
@jfjoyner3 抱怨 Claude 的 VBA 输出:“我愿意相信 Claude 的建议,结果它把我的 vba 代码弄得一团糟”(推文)。这反映出一个更广泛的模式:AI 编程工具在主流语言上表现突出,但在遗留或小众语言环境中质量明显下降。
AI 生成代码的安全担忧(Low)¶
@ldzi3lak 提出了系统性担忧:“你打造出当今最强的编程/安全 LLM,然后让它访问那些运行着地球上大多数软件的公司。我希望他们非常认真地测试这些补丁,并真正理解其中的漏洞”(推文,5.9K 浏览)。担忧的重点不只是 AI 会犯错,而是让 AI 智能体拥有广泛代码库访问权本身会创造新的攻击面。
3. 人们期望的功能¶
Google Antigravity 的无缝多账号切换。 @Azharali37080 构建了一个权宜工具(“Antigravity Lab”),因为默认体验要求重启 IDE 才能切换账号,并且会丢失上下文(推文)。这需要第三方方案,本身就暴露了 Antigravity 账号管理上的缺口。

通用的模型与运行框架兼容性。 @agent_wrapper 的问题“运行 GLM-5.1 最好的编程运行框架是什么?”(推文)不应该需要 7 条回复才能回答。开发者想要一个能良好适配任何模型的单一运行框架,或者至少需要一份可以查阅的兼容性矩阵。
Apple App Store 对 vibe-coding 预览工具的支持。 Anything 事件表明,非开发者构建者需要在真机上预览原生功能(GPS、摄像头、通知),但 Apple 的可执行代码规则挡住了这个使用场景。Expo Go 为专业开发者提供同样能力,却没有遇到问题(推文)。
遗留技术栈中的可靠 AI 编程。 VBA、带 Visual Studio 的 .NET,以及其他企业环境缺少 Python 和 TypeScript 开发者已经习以为常的成熟 AI 编程支持。这个差距大到即使用户愿意为高级工具付费,也会产生明显挫败感。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| GitHub Copilot CLI | CLI 智能体 | 正面 | Rubber Duck 跨模型审查、MCP 管理、活跃发布节奏(v1.0.21) | 新进入者,生态仍在成熟 |
| Claude Code | CLI 智能体 | 褒贬不一 | 高级用户工作流、子智能体委派、持久上下文 | 订阅不能用于 OpenClaw、VBA 质量问题、默认设置下上下文耗尽 |
| OpenClaw | 智能体框架 | 正面 | 可配合本地模型免费使用,支持 cron/heartbeat/CLI 访问,模型支持广 | Anthropic 禁止后需要 OpenAI Codex 认证,广泛访问带来安全担忧 |
| OpenCode / Crush | CLI 智能体 | 正面 | 基于 TUI、模型无关、Go 编写 | Charm 团队近期将其归档并改名为 Crush(Charmbracelet),仍处早期开发 |
| Codex (OpenAI) | 云端智能体 | 正面 | 每周 3M 用户、推理能力强、增长里程碑触发限流重置 | 额外 $190/月订阅成本 |
| Gemma 4 (26B/31B) | 本地模型 | 正面 | 免费、77-80% LiveCodeBench、256K 上下文、MoE 效率 | 需要较好的硬件(M-series Mac 或同等设备) |
| mlx-lm | 本地推理 | 正面 | 针对 Apple Silicon 优化、支持 batching、可服务多个会话 | 仅 macOS,需要 M-series 硬件 |
| Ollama | 模型运行时 | 正面 | 简单 pull-and-run、大模型库、社区变体丰富 | 大规模下的资源管理 |
| Google Antigravity | 云端 IDE | 褒贬不一 | 免费层、Gemini 集成、Google 内部使用(“Jet Ski”) | 限流、稳定性投诉、账号切换痛点 |
| JetBrains ACP Registry | IDE 集成 | 正面 | 一键安装智能体、提供商无关、不需要 JetBrains AI 订阅 | 新功能,仅限 JetBrains IDEs |
| GPT 5.4 | 云端模型 | 正面 | 通用编程能力强,可通过 Copilot 和 Codex 使用 | 规模化使用成本高 |
| Taugentic | 智能体编排器 | 中性 | 使用 GLM-5.1 运行 OpenCode,模型无关 | 可用信息有限 |
| Framer MCP | 设计工具桥接 | 正面 | 让 AI 直接编辑 Framer 项目,可免费配合 Antigravity 使用 | 使用场景较窄 |
| Spring AI / LangChain4j | Java AI 框架 | 正面 | 企业 Java 集成、智能体化系统 | Java 生态在 AI 编程上的成熟度滞后 |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| SpekBoard | @lukewestlake | 多智能体编排仪表盘,跨模型追踪 7 个智能体,并显示成本与运行指标 | 了解 Claude Opus、GPT 5.4、Grok-4 等多智能体的成本与性能 | Claude Opus 4.6、GPT 5.4、Grok-4、自定义 pipeline | Alpha | 推文 |
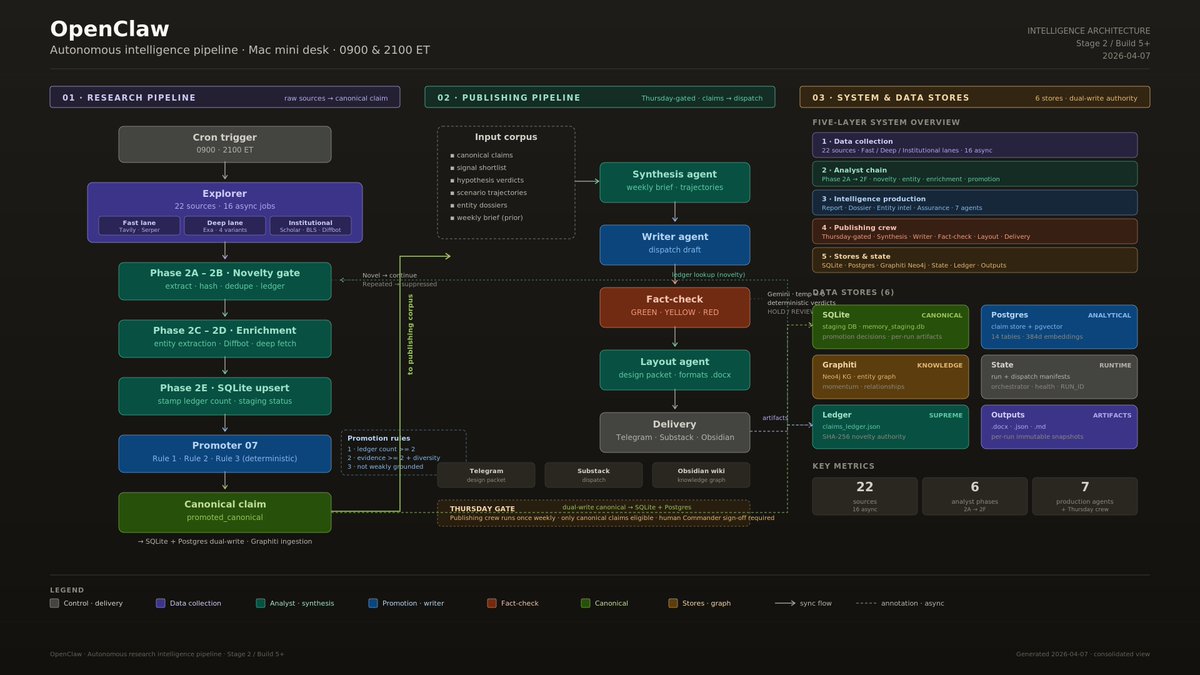
| Autonomous intelligence pipeline | @hawktrader | 全自动 research-to-publishing pipeline,含 cron 触发探索、新颖性筛选、事实核查和多渠道分发 | 无需人工交互,从 22 个来源自动收集情报 | OpenClaw、Claude Code、Codex、Antigravity、SQLite、Postgres、Neo4j、Graphiti | Shipped | 推文 |
| Antigravity Lab | @Azharali37080 | 无需重启 IDE 即可切换 Google Antigravity 账号的桌面工具 | 切换账号会丢失 IDE 上下文的痛点 | Cloud server、多账号管理 | Shipped (v1.0.17) | 推文 |
| Gemma 4 think/fast variants | @dev_Bjoern | 面向 Gemma 4 全尺寸家族的自定义 Ollama 模型文件,含 think/fast 模式 | Ollama 上缺少 Gemma 4 的 think-mode 配置 | Ollama、Gemma 4 (e2b/e4b/26b/31b) | Shipped | 推文 |
| Framer MCP + Antigravity guide | @vivekdesignss | 让 AI 直接编辑 Framer 项目的分步指南 | 无需付费方案即可把设计工具接入 AI 编程智能体 | Framer MCP、Google Antigravity | Shipped | 推文 |
| Build Your AI Startup Team workshop | @BradGroux | 面向创业者的实操 workshop,教授构建 5 个自主 agents | 弥合 AI 工具与创业教育之间的差距 | OpenClaw、Copilot CLI | RFC (May 2) | 推文 |


6. 新动态与亮点¶
Copilot CLI v1.0.21 发布 MCP 管理与 Rubber Duck 审查。 该版本新增 copilot mcp 命令,可从 CLI 管理 MCP 服务器;新增 hook payload 标准化,将字段转为 snake_case 并带上 ISO 8601 时间戳;还会清理未使用的 shell 会话以自动降低内存占用。Rubber Duck 跨模型审查智能体是头条功能,SWE Bench 数据显示它能补上 Sonnet-Opus 差距的 75%(发布推文)。
Codex 达到每周 300 万用户。 @thsottiaux 宣布这一里程碑;不到一个月前还是 200 万,并且在达到 10M 之前,每新增 1M 用户都会重置限流。@trekedge 将 Codex 定位为“最适合这项工作的智能体”,并把它与其他 vibe-coding 产品区分开来(推文,里程碑推文)。
JetBrains 发布 ACP Registry,成为智能体无关市场。 ACP Registry 允许开发者直接从 IDE 中一键发现并安装 AI 智能体(Junie、Claude Agent、Codex、Copilot、Cursor),且不需要 JetBrains AI 订阅。这是一次标准化押注:IDE 成为竞争性智能体提供商的中立平台(推文)。
mlx-lm batching 更新让多会话本地推理成为可能。 更新后的库展示了在单台 M3 Ultra 上同时运行 5 个 Gemma 4 26B 编程会话,并在 1.5 分钟内处理 130K tokens。这让纯本地 AI 编程工作流首次在多会话规模上具备实用性(推文)。
Claude Code effort 默认值现在按计划分层。 Pro/Max 用户默认 medium effort;API key、Team、Enterprise 与第三方提供商用户默认 high。这反映出 Anthropic 正在按客户经济模型划分计算资源(推文)。
Sundar Pichai 确认 Google 内部使用 Antigravity。 在 @Marie_Haynes 总结的近期访谈中,Pichai 透露 Google 把内部 Antigravity 实例称为 “Jet Ski”,并且 Search 团队就在前一周开始使用。他称 OpenClaw 这样的 agentic systems 是“未来”,并估计全球已有 0.1% 的人生活在这个未来里(推文)。
AI Engineer London week 开始。 @Infoxicador 报道了第一天 GitHub 社交活动和 OpenAI 伦敦办公室的情况,@reach_vb 在那里分享了 Codex Spark(推文)。与此同时,JDConf(Apr 8-9)由 @msdev 推广,重点是使用 Spring AI、LangChain4j 和 Microsoft Foundry 构建 agentic Java systems(推文,196 点赞)。

7. 机会在哪里¶
[+++] 上下文高效的智能体架构。 朴素与优化后的上下文使用之间存在 18 倍效率差距(每个研究任务 9pp vs 0.5pp),这个差距非常大。能够自动委派给子智能体、强制执行上下文预算,或压缩 MCP payloads 的工具,在每天撞上上下文墙的开发者群体中有很大的可触达市场。CLI-over-API-over-MCP 这个层级还没有内置到任何工具的默认行为里。
[+++] 本地优先 AI 编程基础设施。 Gemma 4 在 Apple Silicon 硬件上以零边际成本达到基准竞争力(77-80% LiveCodeBench、1718-2150 Codeforces ELO),为纯云端工作流提供了可行替代。缺的环节是打磨过的集成层——一个命令就能配置 Ollama、选择正确模型变体,并接入用户偏好的运行框架。@dev_Bjoern 的自定义 Ollama 变体说明,目前这仍是手工驱动的社区流程。
[++] 默认启用跨模型质量保证。 GitHub 的 Rubber Duck 结果——通过低成本跨家族审查补上 Sonnet-Opus 差距的 75%——说明多模型流程应该成为默认,而不是例外。机会在于把它做成自动且模型无关,而不是绑定在某个 CLI 或供应商上。
[++] IDE 即智能体市场。 JetBrains 的 ACP Registry 是首次认真尝试做智能体无关 IDE 集成。机会在于其他 IDE 采用类似协议,并让智能体提供商在共同的安装与认证接口上标准化。能一键安装并在 Claude、Copilot、Codex、Cursor 之间切换的开发者,不会再接受供应商锁定。
[++] 面向非开发者的移动端 vibe-coding。 Anything app 的故事证明了真实需求——一名消防员无需写代码就构建并销售应急响应 app——但 Apple 的 Guideline 2.5.2 阻挡了真机预览工作流。一个基于 Web 或 PWA 的替代方案,如果能提供类原生预览且绕开 App Store 审核门槛,就可能拿下这个市场。
[+] 面向遗留技术栈的 AI 编程工具。 .NET 与 VBA 的挫败感说明这里存在服务不足的市场。困在遗留技术栈中的企业开发者愿意付费,却缺少好选择。为 Visual Studio、VBA 和其他企业环境打造的专用 AI 编程集成,可以支撑溢价定价。
[+] 多智能体成本与性能仪表盘。 SpekBoard 和 hawktrader pipeline 都表明,实践者正在构建自定义仪表盘来追踪多智能体成本、上下文使用与运行指标。这个能力的产品化版本——面向编程工作流的智能体可观测性——在团队从单智能体扩展到多智能体时有明确需求。
8. 要点总结¶
当天信号在三个方向上最清晰。第一,跨模型审查不再是实验——GitHub 发布带有 SWE Bench 数据的 Rubber Duck,意味着这一模式获得机构背书,也有可衡量结果。没有对 AI 生成代码运行跨家族审查轮次的团队,正在白白放弃质量。
第二,本地 AI 编程栈越过了可用性拐点。Ollama 上的 Gemma 4 26B 配合 mlx-lm batching,以零边际成本提供了有竞争力的基准表现(77% LiveCodeBench、1718 Codeforces ELO),设置只需要 3 条命令。约束是硬件(带足够 RAM 的 Apple Silicon),不是软件或成本。
第三,上下文窗口管理已经成为 AI 辅助开发中的决定性技能缺口。朴素与优化后上下文使用之间的 18 倍效率差异,比多数竞品模型之间的质量差异还大。掌握子智能体委派、结构化提示和 CLI-over-API-over-MCP 层级的实践者,已经处在一个与把编程智能体当聊天窗口使用的人完全不同的生产力区间。
运行框架碎片化的故事仍在发展。JetBrains ACP Registry、OpenCode 到 Crush 的改名,以及“GLM-5.1 应该跑在哪个运行框架上”的问题,都指向一个尚未整合的市场。赢家很可能不是由功能决定,而是由哪个工具最擅长管理上下文窗口决定——因为这是所有人都在耗尽的资源。