Twitter AI Coding - 2026-04-09¶
1. What People Are Talking About¶
1.1 Codebase-Aware Agents Challenge the "Grep and Pray" Paradigm 🡕¶
The day's highest-engagement post came from @BniWael, who launched SoulForge (524 likes, 834 bookmarks, 57K views) with a direct attack on how current coding agents navigate repositories: "Everyone's fighting over Claude Code vs Codex vs OpenCode. Meanwhile their tokens are burning because the agent is grep-ing the entire repo and praying on every prompt, with 0 architectural knowledge of the codebase."
SoulForge's core thesis is that agent performance is bottlenecked by orientation work, not model capability. The tool builds a live dependency graph of the codebase on startup — every file, symbol, and import ranked by importance, enriched with git history, updated in real time. When the agent needs context, it performs surgical reads (extracting a single function from a 500-line file) rather than dumping entire files into the context window. The open-source repo (525 stars, TypeScript) ships with a 4-tier code intelligence stack: LSP, ts-morph, tree-sitter, and regex fallback. An embedded Neovim instance provides go-to-definition, references, and call hierarchy — the same intelligence an IDE has, not pattern-matching approximations.
The benchmark claim is specific: same bug, same Claude Opus 4.6, same repo — 6m22s vs 11m18s (1.8x faster), $1.70 vs $3.52 (2.1x cheaper). Multi-agent dispatch runs parallel explore, code, and search agents with a shared context bus so agents do not duplicate work or create file conflicts. Model routing lets users assign Opus for planning, Gemini for research, Haiku for quick edits, and local models via Ollama for throwaway tasks.
Additional features include multi-tab sessions (up to 5 concurrent) with per-tab model assignment and git coordination, $0 compaction (context state tracked live, compaction fires without an additional LLM call), lifecycle hooks compatible with Claude Code's .claude/settings.json format, and an installable skills registry browsable via Ctrl+S. The tool supports 20+ providers including Anthropic, OpenAI, Google, and local models via Ollama.
A reply from @yabsssai pushed on what "architectural knowledge" means concretely for cost reduction — the answer is that the dependency graph eliminates the exploration turns that dominate most agent sessions. Another reply tagged @ThePrimeagen, noting the embedded Neovim integration.
1.2 OpenAI Adds $100/Month Pro Tier as Codex Pricing Crystallizes 🡕¶
OpenAI introduced a new middle-tier pricing plan that dominated the pricing conversation. @Cointelegraph broke the news (115 likes, 14.8K views): a $100/month ChatGPT Pro tier offering 5x more Codex usage than the $20/month Plus plan, targeting high-intensity AI coding workflows. @MacRumors confirmed the details (93 likes, 23.6K views): the existing $200/month Pro tier provides 20x usage, and a launch promotion gives $100 subscribers 10x Plus usage through May 31.
The pricing now mirrors Anthropic's structure exactly: $20, $100, and $200 tiers. OpenAI is also "rebalancing" Plus Codex usage to support more sessions spread across the week rather than longer sessions in a single day — a shift that suggests heavy users were exhausting daily quotas and churning.
@DjaniWhaleSkul offered the skeptical take: "On the graph, it was clear that OpenAI would change things with Codex once they secured the user base." A reply to the Cointelegraph post from @cosmosdigitalz argued "ChatGPT wants to compete with Claude but Claude is already way ahead." Another from @DjaniWhaleSkul predicted that pricing would eventually make hiring a human developer competitive again.
1.3 Mobile Agent Control and Multi-Model Orchestration Go Mainstream 🡕¶
@damnGruz posted the day's second-highest engagement with Lunel (518 likes, 544 bookmarks, 68K views), an open-source iOS app for running Codex, OpenCode, Claude Code, and full development environments from a phone. The post quote-tweeted @theo, who had asked "I want to control my agents from my phone. What workflows do you want?" — Lunel was the immediate, working answer. Europe availability is in progress per a follow-up reply.
On the multi-model front, @acolombiadev demonstrated running Claude Opus 4.6, GPT 5.4, and Gemini 3 simultaneously via GitHub Copilot CLI (127 likes, 85 bookmarks), with a main agent synthesizing their independent code reviews. The technique was learned from @Ryan_Hecht on the GitHub Checkout YouTube show. @josephficara confirmed in a reply that "the council of LLM review is our team's standard practice" — they codify the multi-model review into agent skills that generate inline PR feedback and markdown analysis reports.
@kjehiel flagged a practical issue: "Gemini models are gone from copilot cli. It was working fine few weeks ago." Model availability instability across platforms is becoming a recurring friction point.
1.4 The Developer Identity Question Sharpens 🡒¶
@brandenflasch asked a deceptively simple question that generated substantive replies: "In the age of building with Codex and Claude Code, what makes someone a software developer / engineer vs not?" (10 likes, 7 replies, 2.2K views).
@ChadMoran provided the most-liked reply (22 likes): "Being able to reason about and debug the code yourself. I think we're headed where there is a new 'product engineer' role happening. Those who are able to describe (effectively) what they want and get good results. I think Software Engineers and Product Managers are combining." @brian_henderson drew the analogy to music: "Many can create music with tools. More skill breadth can lead to being a successful music artist."
@jamwt staked out a related position in a separate, high-engagement reply to @martin_casado (141 likes, 26K views): "This is why people need to use e.g. cursor and opencode. Do not let the labs own the services. Hot take, but we should also pay API prices for tokens. And use composer 2. Loss leadering better applications into dust will end really poorly for consumers in the long run." The concern is that subsidized pricing from labs will destroy independent tooling, leaving developers locked into vendor ecosystems.
2. What Frustrates People¶
Google Antigravity Reliability Failures at Premium Prices (Severity: High)¶
@dongqubo posted a screenshot of repeated server errors on Google AI Ultra at $250/month: four consecutive Continue attempts (36s, 5s, 5s, 55s), all returning "Our servers are experiencing high traffic right now." The user reports this is not an isolated incident — "This is every day, all day, for weeks. Antigravity is unusable."

@Yashavanth_g_h hit a different failure mode: exhausting model quotas in 5 minutes. The settings screenshot reveals the full model roster available through Antigravity — Gemini 3.1 Pro, Gemini 3 Flash, Claude Sonnet 4.6 (Thinking), Claude Opus 4.6 (Thinking), and GPT-OSS 120B — with varying refresh windows from 5 hours to 5 days.

@MATEOINRL uses Antigravity for free alongside Codex but acknowledged "Google messed up antigravity big time."
Coerced Data Consent at Google AI Training Events (Severity: Medium)¶
@danicuki described being forced to accept broad data collection to use Antigravity at a Google AI training session: "'Do I need to accept this to continue?' Answer: 'Yes.' Then: 'Google already has all your data anyway.'" The complaint is less about the policy and more about the social dynamics — being made to feel unreasonable for asking about privacy in front of 40 developers. "We've normalized surveillance so much that asking for boundaries now sounds unreasonable."

GitHub Training AI on Copilot User Data (Severity: Medium)¶
@gthimmes flagged that "GitHub will now train AI models on Copilot data from Free, Pro, and Pro+ users. Opted in by default." The concern: "The tool you use to write code is learning from how you write code, whether you agreed to it or not."
Rate Limiting Across All Platforms (Severity: Medium)¶
Rate limits surfaced as a cross-cutting frustration. @MelansonIndus responded to the Copilot CLI multi-model demo with "and then u get rate limited after a few request." Antigravity users report 5-minute quota exhaustion. The pattern: every platform offers impressive capabilities gated behind usage limits that heavy users hit almost immediately.
3. What People Wish Existed¶
Reliable Infrastructure at Premium Pricing¶
The gap between what users pay and what they receive is stark. Google AI Ultra at $250/month delivers constant server errors. OpenAI's response — adding a $100 tier — addresses pricing granularity but not the underlying reliability that power users need. Heavy coding sessions demand sustained, predictable throughput, not tiered access to capacity that may or may not be available.
Model-Agnostic Agent Portability¶
@brennoferrari's obsidian-mind v4 solves this for persistent memory — the same vault, hooks, and commands work across Claude Code, Codex CLI, and Gemini CLI. The broader desire is for all agent tooling to be portable: hit Claude's rate limit mid-session, switch to Gemini, keep working. @jamwt's call to "not let the labs own the services" and use API pricing reflects the same need. @carlsue described a pragmatic split: "Recommend using opus as a code review or architect and Codex to write actual running code."
Agent-Collaborative Terminal Workflows¶
@MrOcelot1976 described a multi-agent terminal workflow where agents collaborate in the same terminal using Claude-Code-Base search on GitHub: "Fun watching them message back and forth. Their strengths compliment each other. And they get along." @bedesqui noted that OpenCode's web UI combined with Tailscale enables connecting to localhost on any device by alias — a lightweight alternative to dedicated mobile apps for remote agent access.
Agent Benchmarking Without Credit Walls¶
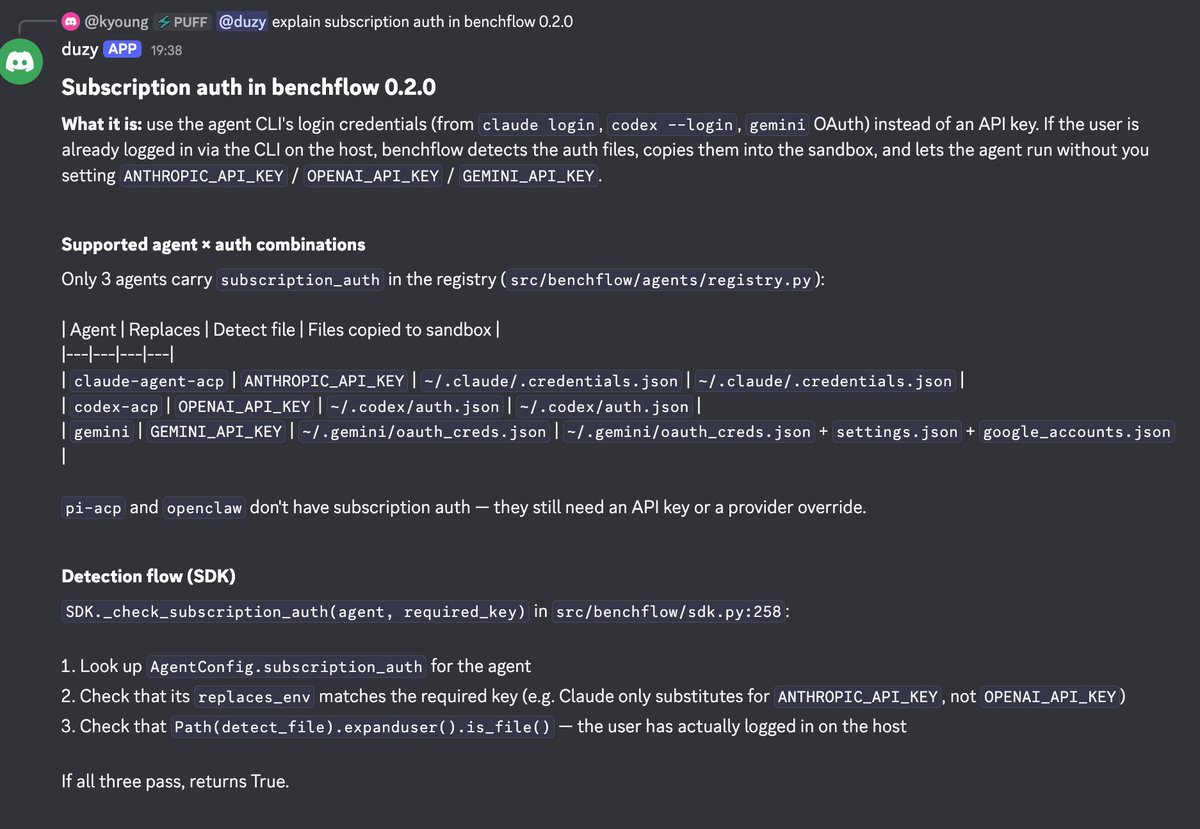
@xdotli previewed benchflow 0.2.0, which solves the problem of running benchmarks against subscription-based agents. The tool detects CLI login credentials (claude login, codex --login, gemini OAuth) on the host and injects them into sandboxed benchmark environments, eliminating the need for separate API keys.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| SoulForge | Coding Agent | Positive | Live dependency graph, 1.8x faster/2.1x cheaper on benchmarks, embedded Neovim, multi-agent dispatch, 33 languages | 525 stars, newer entrant, Neovim dependency |
| Lunel | Mobile Agent Control | Positive | Run Codex/OpenCode/Claude Code from phone, open source, iOS app | No Europe availability yet, GitHub repo not publicly discoverable |
| GitHub Copilot CLI | Agent Orchestration | Positive | Run Claude Opus 4.6 + GPT 5.4 + Gemini 3 simultaneously, synthesize reviews | Rate limiting on multi-model runs, Gemini models intermittently unavailable |
| Claude Code | Coding Agent | Mixed | New Monitor tool for background scripts, strong coding output | Rate limits, vendor lock-in concerns |
| OpenAI Codex | Coding Agent | Mixed | New $100 tier with 5x usage, broad integration (Shopify, Cursor, VS Code) | Plus tier "rebalanced" to spread usage, pricing escalation concerns |
| Google Antigravity | Coding Platform | Negative | Free tier available, multi-model access (Gemini, Claude, GPT-OSS) | Severe reliability issues at $250/month, coerced data consent, 5-minute quota exhaustion |
| obsidian-mind | Agent Memory | Positive | Persistent memory vault for 3 agents, 1,866 GitHub stars, session/standup/dump commands | Requires Obsidian, Python dependency |
| benchflow | Benchmarking | Positive | Subscription auth (no API keys needed), Docker-based, WebArena/SWE-Bench support | Early stage (v0.2.0), limited agent support |
| OpenCode | Coding Agent | Positive | Open source, web UI, Tailscale-compatible for remote access | Smaller ecosystem than Claude Code/Codex |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| SoulForge | @BniWael | Codebase-aware coding agent with live dependency graph | Agents waste turns on orientation instead of real work | TypeScript, Neovim, LSP, tree-sitter | Shipped | GitHub |
| Lunel | @damnGruz | Mobile app to control coding agents from phone | No way to manage Codex/Claude Code/OpenCode sessions on mobile | iOS, open source | Shipped | Post |
| obsidian-mind v4 | @brennoferrari | Obsidian vault giving AI agents persistent memory across sessions | Agents forget context between sessions, re-explain everything | Python, Obsidian, Claude Code/Codex CLI/Gemini CLI hooks | Shipped | GitHub |
| benchflow 0.2.0 | @xdotli | AI benchmark runtime with subscription credential passthrough | LLM credit walls block benchmark runs | Python, Docker | Beta | GitHub |
| VoxHeart | @MrShiLLi | Voxel game with procedural generation, building, trains, electricity | Making a game for his kids using AI coding | Claude Code | Alpha | Post |
| Sober Tracking App | @MarcusFurrelius | Sobriety tracker on Algorand blockchain | Personal recovery milestone (9+ years sober) | Google Gemini, Antigravity, VibeKit | Alpha | Post |
6. New and Notable¶
OpenAI $100/month Pro Tier. A new middle pricing option for Codex sits between the $20 Plus and $200 Pro plans. Provides 5x Plus usage with a launch promo doubling that to 10x through May 31. Signals that heavy Codex users were outgrowing Plus but not willing to jump to $200. Pricing now exactly mirrors Anthropic's tier structure. Source
Claude Code Monitor Tool. Announced by @noahzweben at Anthropic: Claude can now create background scripts that wake the agent when needed. Use cases include following logs for errors, polling PRs, and other event-driven workflows. @obie called it a "HUGE NEW CLAUDE CODE FEATURE" (17 likes, 16 bookmarks, 5.8K views) and @CodedVibes noted the significance: "it doesn't wait for you anymore. it watches and acts on its own." This shifts Claude Code from a reactive tool to a proactive monitor, with major token savings from eliminating polling loops. The architectural pattern — background scripts that trigger agent wake-ups based on external events rather than continuous polling — is the same pattern that production monitoring systems adopted years ago, now arriving in AI coding tools.
Shopify AI Toolkit. Shopify launched integrations with Claude Code, Codex, Cursor, and VS Code for store management. @AskMattCaron, an SEO specialist, issued an immediate caution: "please do not just click 'SEO optimize' and expect good outcomes." His concern is specific — 90% of Shopify stores have keyword cannibalization where multiple pages compete for the same terms, collections overlap with blog posts, and landing pages nobody remembers creating quietly steal authority. AI-generated SEO copy layered on top of that mess reinforces the problem. "An accelerator on a broken foundation just gets you to the wrong destination faster." The warning extends beyond Shopify: as AI toolkits integrate into platforms with existing content debt, naive automation can compound structural problems faster than manual processes ever could. @Pepecash_sol anticipated the collision: "shopify sellers about to discover vibe coding and nobody is ready for that."
Anything Vibe Coding Marketplace. @chrisjarou highlighted the launch of a marketplace from Anything where vibe-coded apps can be bought, remixed, and sold. This is the first instance of a secondary market forming around AI-generated applications as tradeable artifacts.
First OpenAI Codex Meetup in Mexico. @_javierivero organized and hosted the first Codex community event in Mexico (130 likes), featuring talks on building "factories" for task availability using tools including Claude Code, Codex, Cursor, and others. The event signals Codex community formation outside the US.
"Claude Code Developer" Job Posting at $150K. @startaicompany posted a fully remote position seeking an "AI Native Claude Code developer" with $150K base plus equity. The job title itself — defining the role by the tool rather than the language or framework — marks a shift in how AI-native development roles are being framed.
7. Where the Opportunities Are¶
[+++] Codebase Intelligence Layer. SoulForge's traction (4,881 engagement score, 834 bookmarks) demonstrates intense demand for agents that understand code structure before acting. The dependency graph approach — ranking files by importance, tracking symbol relationships, performing surgical reads — cuts agent cost roughly in half. Every coding agent today could benefit from this layer, yet most still default to grep-based discovery. Building a standalone codebase intelligence service that plugs into any agent (not just a specific CLI tool) addresses the broadest market. The fact that SoulForge ships with 20+ provider integrations and model routing suggests the intelligence layer, not the model, is the defensible component.
[++] Agent Subscription Credential Management. benchflow 0.2.0 solves a narrow but growing problem: running coding agents in sandboxes using subscription credentials rather than API keys. As more developers use Claude Code, Codex, and Gemini CLI on subscription plans (not raw API access), any tool that needs to invoke these agents in automated or benchmarking contexts hits a credential wall. A generalized credential broker that detects, rotates, and injects subscription auth across containerized environments has applications beyond benchmarking — CI/CD pipelines, agent-to-agent delegation, and sandbox orchestration all face the same constraint.
[++] Mobile-First Agent Orchestration. Lunel's engagement (3,376 score, 544 bookmarks on 68K views) shows that controlling coding agents from a phone is not a nice-to-have — it was the immediate answer to a question from a creator with 800K+ followers. The gap between "agent running on a server" and "developer away from their desk" is expanding as agents take longer on complex tasks. Notification, approval, and steering interfaces designed for mobile (not shrunken terminals) have clear product space. Europe availability is already requested.
[+] AI Tool Reliability Monitoring. The contrast between Google Antigravity's pricing ($250/month) and its reliability (constant server errors, 5-minute quota exhaustion) creates demand for independent monitoring of AI coding tool uptime, throughput, and quota consumption. An "Is It Down" service specifically for AI coding platforms — tracking Codex quota resets, Antigravity server availability, Claude rate limits, and Gemini model availability across different access points — would serve the growing population of developers whose workflows depend on these services staying up. The data from such a service would also inform purchasing decisions: today, users cannot compare reliability across the $20-$250 pricing spectrum before committing.
[+] Platform-Aware AI Automation Guardrails. The Shopify AI Toolkit launch and @AskMattCaron's immediate warning about keyword cannibalization reveal an opportunity for AI tooling that understands platform-specific constraints before executing. A Shopify-aware agent that audits for competing pages, duplicate meta titles, and redirect chains before generating new content would prevent the "accelerator on a broken foundation" failure mode. The same pattern applies to any platform where AI automation can compound existing structural problems — WordPress SEO, AWS infrastructure-as-code, and database schema migrations all have domain-specific preconditions that generic AI tools ignore.
8. Takeaways¶
The loudest signal today is that agent intelligence is moving from the model to the infrastructure around it. SoulForge's 2x performance improvement comes not from a better model but from a better understanding of the codebase the model operates on. obsidian-mind gives agents memory that persists across sessions and across providers. benchflow gives agents credentials that work in sandboxes. These are all infrastructure plays that make existing models more effective, and they are gaining traction faster than the models themselves are improving.
Pricing convergence is accelerating. OpenAI's new $100 tier perfectly mirrors Anthropic's Max 5x plan. Both companies have landed on $20/$100/$200 as the natural tiers for individual developers, power users, and teams. Google remains the outlier at $250/month with significantly worse reliability, creating a window for competitors to capture frustrated Antigravity users who want multi-model access without the infrastructure instability.
The developer identity question is no longer philosophical. When a job posting titles the role "Claude Code Developer" at $150K, and community members seriously debate whether using Codex makes you an engineer, the redefinition of software development roles is underway. The emerging consensus — from @ChadMoran's "product engineer" framing to @jamwt's insistence on API-price transparency — is that the value is shifting from code production to code reasoning, and from tool usage to tool independence.